diff --git a/.github/workflows/tests.yml b/.github/workflows/tests.yml
new file mode 100644
index 0000000..9ed9138
--- /dev/null
+++ b/.github/workflows/tests.yml
@@ -0,0 +1,82 @@
+name: tests
+
+on:
+ push:
+ paths-ignore:
+ - "*.md"
+ pull_request:
+ types: [opened, synchronize, reopened, edited]
+ paths-ignore:
+ - "*.md"
+
+env:
+ MODULE_NAME: 'sense2vec'
+ RUN_MYPY: 'false'
+
+jobs:
+ tests:
+ name: Test
+ if: github.repository_owner == 'explosion'
+ strategy:
+ fail-fast: false
+ matrix:
+ os: [ubuntu-latest, windows-latest, macos-latest]
+ python_version: ["3.7", "3.8", "3.9", "3.10", "3.11"]
+ include:
+ - os: windows-2019
+ python_version: "3.6"
+ - os: ubuntu-20.04
+ python_version: "3.6"
+ runs-on: ${{ matrix.os }}
+
+ steps:
+ - name: Check out repo
+ uses: actions/checkout@v3
+
+ - name: Configure Python version
+ uses: actions/setup-python@v4
+ with:
+ python-version: ${{ matrix.python_version }}
+ architecture: x64
+
+ - name: Build sdist
+ run: |
+ python -m pip install -U build pip setuptools
+ python -m pip install -U -r requirements.txt
+ python -m build --sdist
+
+ - name: Run mypy
+ shell: bash
+ if: ${{ env.RUN_MYPY == 'true' }}
+ run: |
+ python -m mypy $MODULE_NAME
+
+ - name: Delete source directory
+ shell: bash
+ run: |
+ rm -rf $MODULE_NAME
+
+ - name: Uninstall all packages
+ run: |
+ python -m pip freeze > installed.txt
+ python -m pip uninstall -y -r installed.txt
+
+ - name: Install from sdist
+ shell: bash
+ run: |
+ SDIST=$(python -c "import os;print(os.listdir('./dist')[-1])" 2>&1)
+ pip install dist/$SDIST
+
+ - name: Test import
+ shell: bash
+ run: |
+ python -c "import $MODULE_NAME" -Werror
+
+ - name: Install test requirements
+ run: |
+ python -m pip install -U -r requirements.txt
+
+ - name: Run tests
+ shell: bash
+ run: |
+ python -m pytest --pyargs $MODULE_NAME -Werror
diff --git a/.gitignore b/.gitignore
index 1dbc687..bd0e174 100644
--- a/.gitignore
+++ b/.gitignore
@@ -1,3 +1,12 @@
+tmp/
+cythonize.dat
+*.cpp
+.pytest_cache
+.vscode
+.mypy_cache
+.prettierrc
+.python-version
+
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
@@ -8,6 +17,7 @@ __pycache__/
# Distribution / packaging
.Python
+.env/
env/
build/
develop-eggs/
@@ -60,3 +70,6 @@ target/
#Ipython Notebook
.ipynb_checkpoints
+
+# Pycharm project files
+/.idea/
diff --git a/.travis.yml b/.travis.yml
deleted file mode 100644
index de2a2d6..0000000
--- a/.travis.yml
+++ /dev/null
@@ -1,14 +0,0 @@
-language: python
-
-python:
- - "2.7"
- - "3.4"
- - "3.5"
-
-install:
- - pip install -U numpy
- - pip install -r requirements.txt
- - pip install -e .
-
-script:
- - python -m pytest sense2vec
diff --git a/LICENSE b/LICENSE
index ddd22e2..d78a24b 100644
--- a/LICENSE
+++ b/LICENSE
@@ -1,7 +1,6 @@
The MIT License (MIT)
-Copyright (C) 2016 spaCy GmbH
- 2016 ExplosionAI UG (haftungsbeschränkt)
+Copyright (C) 2019-2023 ExplosionAI GmbH
Permission is hereby granted, free of charge, to any person obtaining a copy
of this software and associated documentation files (the "Software"), to deal
diff --git a/MANIFEST.in b/MANIFEST.in
index e15d9de..9017ba7 100644
--- a/MANIFEST.in
+++ b/MANIFEST.in
@@ -1,4 +1,3 @@
-recursive-include include *.h
-include buildbot.json
include LICENSE
-include README.rst
+include README.md
+include sense2vec/tests/data/*
diff --git a/README.md b/README.md
new file mode 100644
index 0000000..94c6a1e
--- /dev/null
+++ b/README.md
@@ -0,0 +1,972 @@
+ +
+# sense2vec: Contextually-keyed word vectors
+
+sense2vec ([Trask et. al](https://arxiv.org/abs/1511.06388), 2015) is a nice
+twist on [word2vec](https://en.wikipedia.org/wiki/Word2vec) that lets you learn
+more interesting and detailed word vectors. This library is a simple Python
+implementation for loading, querying and training sense2vec models. For more
+details, check out
+[our blog post](https://explosion.ai/blog/sense2vec-reloaded). To explore the
+semantic similarities across all Reddit comments of 2015 and 2019, see the
+[interactive demo](https://demos.explosion.ai/sense2vec).
+
+🦆 **Version 2.0 (for spaCy v3) out now!**
+[Read the release notes here.](https://github.com/explosion/sense2vec/releases/)
+
+[](https://github.com/explosion/sense2vec/actions/workflows/tests.yml)
+[](https://github.com/explosion/sense2vec/releases)
+[](https://pypi.org/project/sense2vec/)
+[](https://github.com/ambv/black)
+
+## ✨ Features
+
+
+
+- Query **vectors for multi-word phrases** based on part-of-speech tags and
+ entity labels.
+- spaCy **pipeline component** and **extension attributes**.
+- Fully **serializable** so you can easily ship your sense2vec vectors with your
+ spaCy model packages.
+- Optional **caching of nearest neighbors** for super fast "most similar"
+ queries.
+- **Train your own vectors** using a pretrained spaCy model, raw text and
+ [GloVe](https://github.com/stanfordnlp/GloVe) or Word2Vec via
+ [fastText](https://github.com/facebookresearch/fastText)
+ ([details](#-training-your-own-sense2vec-vectors)).
+- [Prodigy](https://prodi.gy) **annotation recipes** for evaluating models,
+ creating lists of similar multi-word phrases and converting them to match
+ patterns, e.g. for rule-based NER or to bootstrap NER annotation
+ ([details & examples](#-prodigy-recipes)).
+
+## 🚀 Quickstart
+
+### Standalone usage
+
+```python
+from sense2vec import Sense2Vec
+
+s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
+query = "natural_language_processing|NOUN"
+assert query in s2v
+vector = s2v[query]
+freq = s2v.get_freq(query)
+most_similar = s2v.most_similar(query, n=3)
+# [('machine_learning|NOUN', 0.8986967),
+# ('computer_vision|NOUN', 0.8636297),
+# ('deep_learning|NOUN', 0.8573361)]
+```
+
+### Usage as a spaCy pipeline component
+
+> ⚠️ Note that this example describes usage with
+> [spaCy v3](https://spacy.io/usage/v3). For usage with spaCy v2, download
+> `sense2vec==1.0.3` and check out the
+> [`v1.x`](https://github.com/explosion/sense2vec/tree/v1.x) branch of this
+> repo.
+
+```python
+import spacy
+
+nlp = spacy.load("en_core_web_sm")
+s2v = nlp.add_pipe("sense2vec")
+s2v.from_disk("/path/to/s2v_reddit_2015_md")
+
+doc = nlp("A sentence about natural language processing.")
+assert doc[3:6].text == "natural language processing"
+freq = doc[3:6]._.s2v_freq
+vector = doc[3:6]._.s2v_vec
+most_similar = doc[3:6]._.s2v_most_similar(3)
+# [(('machine learning', 'NOUN'), 0.8986967),
+# (('computer vision', 'NOUN'), 0.8636297),
+# (('deep learning', 'NOUN'), 0.8573361)]
+```
+
+### Interactive demos
+
+
+
+# sense2vec: Contextually-keyed word vectors
+
+sense2vec ([Trask et. al](https://arxiv.org/abs/1511.06388), 2015) is a nice
+twist on [word2vec](https://en.wikipedia.org/wiki/Word2vec) that lets you learn
+more interesting and detailed word vectors. This library is a simple Python
+implementation for loading, querying and training sense2vec models. For more
+details, check out
+[our blog post](https://explosion.ai/blog/sense2vec-reloaded). To explore the
+semantic similarities across all Reddit comments of 2015 and 2019, see the
+[interactive demo](https://demos.explosion.ai/sense2vec).
+
+🦆 **Version 2.0 (for spaCy v3) out now!**
+[Read the release notes here.](https://github.com/explosion/sense2vec/releases/)
+
+[](https://github.com/explosion/sense2vec/actions/workflows/tests.yml)
+[](https://github.com/explosion/sense2vec/releases)
+[](https://pypi.org/project/sense2vec/)
+[](https://github.com/ambv/black)
+
+## ✨ Features
+
+
+
+- Query **vectors for multi-word phrases** based on part-of-speech tags and
+ entity labels.
+- spaCy **pipeline component** and **extension attributes**.
+- Fully **serializable** so you can easily ship your sense2vec vectors with your
+ spaCy model packages.
+- Optional **caching of nearest neighbors** for super fast "most similar"
+ queries.
+- **Train your own vectors** using a pretrained spaCy model, raw text and
+ [GloVe](https://github.com/stanfordnlp/GloVe) or Word2Vec via
+ [fastText](https://github.com/facebookresearch/fastText)
+ ([details](#-training-your-own-sense2vec-vectors)).
+- [Prodigy](https://prodi.gy) **annotation recipes** for evaluating models,
+ creating lists of similar multi-word phrases and converting them to match
+ patterns, e.g. for rule-based NER or to bootstrap NER annotation
+ ([details & examples](#-prodigy-recipes)).
+
+## 🚀 Quickstart
+
+### Standalone usage
+
+```python
+from sense2vec import Sense2Vec
+
+s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
+query = "natural_language_processing|NOUN"
+assert query in s2v
+vector = s2v[query]
+freq = s2v.get_freq(query)
+most_similar = s2v.most_similar(query, n=3)
+# [('machine_learning|NOUN', 0.8986967),
+# ('computer_vision|NOUN', 0.8636297),
+# ('deep_learning|NOUN', 0.8573361)]
+```
+
+### Usage as a spaCy pipeline component
+
+> ⚠️ Note that this example describes usage with
+> [spaCy v3](https://spacy.io/usage/v3). For usage with spaCy v2, download
+> `sense2vec==1.0.3` and check out the
+> [`v1.x`](https://github.com/explosion/sense2vec/tree/v1.x) branch of this
+> repo.
+
+```python
+import spacy
+
+nlp = spacy.load("en_core_web_sm")
+s2v = nlp.add_pipe("sense2vec")
+s2v.from_disk("/path/to/s2v_reddit_2015_md")
+
+doc = nlp("A sentence about natural language processing.")
+assert doc[3:6].text == "natural language processing"
+freq = doc[3:6]._.s2v_freq
+vector = doc[3:6]._.s2v_vec
+most_similar = doc[3:6]._.s2v_most_similar(3)
+# [(('machine learning', 'NOUN'), 0.8986967),
+# (('computer vision', 'NOUN'), 0.8636297),
+# (('deep learning', 'NOUN'), 0.8573361)]
+```
+
+### Interactive demos
+
+ +
+To try out our pretrained vectors trained on Reddit comments, check out the
+[interactive sense2vec demo](https://explosion.ai/demos/sense2vec).
+
+This repo also includes a [Streamlit](https://streamlit.io) demo script for
+exploring vectors and the most similar phrases. After installing `streamlit`,
+you can run the script with `streamlit run` and **one or more paths to
+pretrained vectors** as **positional arguments** on the command line. For
+example:
+
+```bash
+pip install streamlit
+streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors
+```
+
+### Pretrained vectors
+
+To use the vectors, download the archive(s) and pass the extracted directory to
+`Sense2Vec.from_disk` or `Sense2VecComponent.from_disk`. The vector files are
+**attached to the GitHub release**. Large files have been split into multi-part
+downloads.
+
+| Vectors | Size | Description | 📥 Download (zipped) |
+| -------------------- | -----: | ---------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `s2v_reddit_2019_lg` | 4 GB | Reddit comments 2019 (01-07) | [part 1](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2019_lg.tar.gz.001), [part 2](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2019_lg.tar.gz.002), [part 3](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2019_lg.tar.gz.003) |
+| `s2v_reddit_2015_md` | 573 MB | Reddit comments 2015 | [part 1](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2015_md.tar.gz) |
+
+To merge the multi-part archives, you can run the following:
+
+```bash
+cat s2v_reddit_2019_lg.tar.gz.* > s2v_reddit_2019_lg.tar.gz
+```
+
+## ⏳ Installation & Setup
+
+sense2vec releases are available on pip:
+
+```bash
+pip install sense2vec
+```
+
+To use pretrained vectors, download
+[one of the vector packages](#pretrained-vectors), unpack the `.tar.gz` archive
+and point `from_disk` to the extracted data directory:
+
+```python
+from sense2vec import Sense2Vec
+s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
+```
+
+## 👩💻 Usage
+
+### Usage with spaCy v3
+
+The easiest way to use the library and vectors is to plug it into your spaCy
+pipeline. The `sense2vec` package exposes a `Sense2VecComponent`, which can be
+initialised with the shared vocab and added to your spaCy pipeline as a
+[custom pipeline component](https://spacy.io/usage/processing-pipelines#custom-components).
+By default, components are added to the _end of the pipeline_, which is the
+recommended position for this component, since it needs access to the dependency
+parse and, if available, named entities.
+
+```python
+import spacy
+from sense2vec import Sense2VecComponent
+
+nlp = spacy.load("en_core_web_sm")
+s2v = nlp.add_pipe("sense2vec")
+s2v.from_disk("/path/to/s2v_reddit_2015_md")
+```
+
+The component will add several
+[extension attributes and methods](https://spacy.io/usage/processing-pipelines#custom-components-attributes)
+to spaCy's `Token` and `Span` objects that let you retrieve vectors and
+frequencies, as well as most similar terms.
+
+```python
+doc = nlp("A sentence about natural language processing.")
+assert doc[3:6].text == "natural language processing"
+freq = doc[3:6]._.s2v_freq
+vector = doc[3:6]._.s2v_vec
+most_similar = doc[3:6]._.s2v_most_similar(3)
+```
+
+For entities, the entity labels are used as the "sense" (instead of the token's
+part-of-speech tag):
+
+```python
+doc = nlp("A sentence about Facebook and Google.")
+for ent in doc.ents:
+ assert ent._.in_s2v
+ most_similar = ent._.s2v_most_similar(3)
+```
+
+#### Available attributes
+
+The following extension attributes are exposed on the `Doc` object via the `._`
+property:
+
+| Name | Attribute Type | Type | Description |
+| ------------- | -------------- | ---- | ----------------------------------------------------------------------------------- |
+| `s2v_phrases` | property | list | All sense2vec-compatible phrases in the given `Doc` (noun phrases, named entities). |
+
+The following attributes are available via the `._` property of `Token` and
+`Span` objects – for example `token._.in_s2v`:
+
+| Name | Attribute Type | Return Type | Description |
+| ------------------ | -------------- | ------------------ | ---------------------------------------------------------------------------------- |
+| `in_s2v` | property | bool | Whether a key exists in the vector map. |
+| `s2v_key` | property | unicode | The sense2vec key of the given object, e.g. `"duck NOUN"`. |
+| `s2v_vec` | property | `ndarray[float32]` | The vector of the given key. |
+| `s2v_freq` | property | int | The frequency of the given key. |
+| `s2v_other_senses` | property | list | Available other senses, e.g. `"duck\|VERB"` for `"duck\|NOUN"`. |
+| `s2v_most_similar` | method | list | Get the `n` most similar terms. Returns a list of `((word, sense), score)` tuples. |
+| `s2v_similarity` | method | float | Get the similarity to another `Token` or `Span`. |
+
+> ⚠️ **A note on span attributes:** Under the hood, entities in `doc.ents` are
+> `Span` objects. This is why the pipeline component also adds attributes and
+> methods to spans and not just tokens. However, it's not recommended to use the
+> sense2vec attributes on arbitrary slices of the document, since the model
+> likely won't have a key for the respective text. `Span` objects also don't
+> have a part-of-speech tag, so if no entity label is present, the "sense"
+> defaults to the root's part-of-speech tag.
+
+#### Adding sense2vec to a trained pipeline
+
+If you're training and packaging a spaCy pipeline and want to include a
+sense2vec component in it, you can load in the data via the
+[`[initialize]` block](https://spacy.io/usage/training#config-lifecycle) of the
+training config:
+
+```ini
+[initialize.components]
+
+[initialize.components.sense2vec]
+data_path = "/path/to/s2v_reddit_2015_md"
+```
+
+### Standalone usage
+
+You can also use the underlying `Sense2Vec` class directly and load in the
+vectors using the `from_disk` method. See below for the available API methods.
+
+```python
+from sense2vec import Sense2Vec
+s2v = Sense2Vec().from_disk("/path/to/reddit_vectors-1.1.0")
+most_similar = s2v.most_similar("natural_language_processing|NOUN", n=10)
+```
+
+> ⚠️ **Important note:** To look up entries in the vectors table, the keys need
+> to follow the scheme of `phrase_text|SENSE` (note the `_` instead of spaces
+> and the `|` before the tag or label) – for example, `machine_learning|NOUN`.
+> Also note that the underlying vector table is case-sensitive.
+
+## 🎛 API
+
+### class `Sense2Vec`
+
+The standalone `Sense2Vec` object that holds the vectors, strings and
+frequencies.
+
+#### method `Sense2Vec.__init__`
+
+Initialize the `Sense2Vec` object.
+
+| Argument | Type | Description |
+| -------------- | --------------------------- | ---------------------------------------------------------------------------------------------------------------------- |
+| `shape` | tuple | The vector shape. Defaults to `(1000, 128)`. |
+| `strings` | `spacy.strings.StringStore` | Optional string store. Will be created if it doesn't exist. |
+| `senses` | list | Optional list of all available senses. Used in methods that generate the best sense or other senses. |
+| `vectors_name` | unicode | Optional name to assign to the `Vectors` table, to prevent clashes. Defaults to `"sense2vec"`. |
+| `overrides` | dict | Optional custom functions to use, mapped to names registered via the registry, e.g. `{"make_key": "custom_make_key"}`. |
+| **RETURNS** | `Sense2Vec` | The newly constructed object. |
+
+```python
+s2v = Sense2Vec(shape=(300, 128), senses=["VERB", "NOUN"])
+```
+
+#### method `Sense2Vec.__len__`
+
+The number of rows in the vectors table.
+
+| Argument | Type | Description |
+| ----------- | ---- | ---------------------------------------- |
+| **RETURNS** | int | The number of rows in the vectors table. |
+
+```python
+s2v = Sense2Vec(shape=(300, 128))
+assert len(s2v) == 300
+```
+
+#### method `Sense2Vec.__contains__`
+
+Check if a key is in the vectors table.
+
+| Argument | Type | Description |
+| ----------- | ------------- | -------------------------------- |
+| `key` | unicode / int | The key to look up. |
+| **RETURNS** | bool | Whether the key is in the table. |
+
+```python
+s2v = Sense2Vec(shape=(10, 4))
+s2v.add("avocado|NOUN", numpy.asarray([4, 2, 2, 2], dtype=numpy.float32))
+assert "avocado|NOUN" in s2v
+assert "avocado|VERB" not in s2v
+```
+
+#### method `Sense2Vec.__getitem__`
+
+Retrieve a vector for a given key. Returns None if the key is not in the table.
+
+| Argument | Type | Description |
+| ----------- | --------------- | --------------------- |
+| `key` | unicode / int | The key to look up. |
+| **RETURNS** | `numpy.ndarray` | The vector or `None`. |
+
+```python
+vec = s2v["avocado|NOUN"]
+```
+
+#### method `Sense2Vec.__setitem__`
+
+Set a vector for a given key. Will raise an error if the key doesn't exist. To
+add a new entry, use `Sense2Vec.add`.
+
+| Argument | Type | Description |
+| -------- | --------------- | ------------------ |
+| `key` | unicode / int | The key. |
+| `vector` | `numpy.ndarray` | The vector to set. |
+
+```python
+vec = s2v["avocado|NOUN"]
+s2v["avacado|NOUN"] = vec
+```
+
+#### method `Sense2Vec.add`
+
+Add a new vector to the table.
+
+| Argument | Type | Description |
+| -------- | --------------- | ------------------------------------------------------------ |
+| `key` | unicode / int | The key to add. |
+| `vector` | `numpy.ndarray` | The vector to add. |
+| `freq` | int | Optional frequency count. Used to find best matching senses. |
+
+```python
+vec = s2v["avocado|NOUN"]
+s2v.add("🥑|NOUN", vec, 1234)
+```
+
+#### method `Sense2Vec.get_freq`
+
+Get the frequency count for a given key.
+
+| Argument | Type | Description |
+| ----------- | ------------- | ------------------------------------------------- |
+| `key` | unicode / int | The key to look up. |
+| `default` | - | Default value to return if no frequency is found. |
+| **RETURNS** | int | The frequency count. |
+
+```python
+vec = s2v["avocado|NOUN"]
+s2v.add("🥑|NOUN", vec, 1234)
+assert s2v.get_freq("🥑|NOUN") == 1234
+```
+
+#### method `Sense2Vec.set_freq`
+
+Set a frequency count for a given key.
+
+| Argument | Type | Description |
+| -------- | ------------- | ----------------------------- |
+| `key` | unicode / int | The key to set the count for. |
+| `freq` | int | The frequency count. |
+
+```python
+s2v.set_freq("avocado|NOUN", 104294)
+```
+
+#### method `Sense2Vec.__iter__`, `Sense2Vec.items`
+
+Iterate over the entries in the vectors table.
+
+| Argument | Type | Description |
+| ---------- | ----- | ----------------------------------------- |
+| **YIELDS** | tuple | String key and vector pairs in the table. |
+
+```python
+for key, vec in s2v:
+ print(key, vec)
+
+for key, vec in s2v.items():
+ print(key, vec)
+```
+
+#### method `Sense2Vec.keys`
+
+Iterate over the keys in the table.
+
+| Argument | Type | Description |
+| ---------- | ------- | ----------------------------- |
+| **YIELDS** | unicode | The string keys in the table. |
+
+```python
+all_keys = list(s2v.keys())
+```
+
+#### method `Sense2Vec.values`
+
+Iterate over the vectors in the table.
+
+| Argument | Type | Description |
+| ---------- | --------------- | ------------------------- |
+| **YIELDS** | `numpy.ndarray` | The vectors in the table. |
+
+```python
+all_vecs = list(s2v.values())
+```
+
+#### property `Sense2Vec.senses`
+
+The available senses in the table, e.g. `"NOUN"` or `"VERB"` (added at
+initialization).
+
+| Argument | Type | Description |
+| ----------- | ---- | --------------------- |
+| **RETURNS** | list | The available senses. |
+
+```python
+s2v = Sense2Vec(senses=["VERB", "NOUN"])
+assert "VERB" in s2v.senses
+```
+
+#### property `Sense2vec.frequencies`
+
+The frequencies of the keys in the table, in descending order.
+
+| Argument | Type | Description |
+| ----------- | ---- | -------------------------------------------------- |
+| **RETURNS** | list | The `(key, freq)` tuples by frequency, descending. |
+
+```python
+most_frequent = s2v.frequencies[:10]
+key, score = s2v.frequencies[0]
+```
+
+#### method `Sense2vec.similarity`
+
+Make a semantic similarity estimate of two keys or two sets of keys. The default
+estimate is cosine similarity using an average of vectors.
+
+| Argument | Type | Description |
+| ----------- | ------------------------ | ----------------------------------- |
+| `keys_a` | unicode / int / iterable | The string or integer key(s). |
+| `keys_b` | unicode / int / iterable | The other string or integer key(s). |
+| **RETURNS** | float | The similarity score. |
+
+```python
+keys_a = ["machine_learning|NOUN", "natural_language_processing|NOUN"]
+keys_b = ["computer_vision|NOUN", "object_detection|NOUN"]
+print(s2v.similarity(keys_a, keys_b))
+assert s2v.similarity("machine_learning|NOUN", "machine_learning|NOUN") == 1.0
+```
+
+#### method `Sense2Vec.most_similar`
+
+Get the most similar entries in the table. If more than one key is provided, the
+average of the vectors is used. To make this method faster, see the
+[script for precomputing a cache](scripts/06_precompute_cache.py) of the nearest
+neighbors.
+
+| Argument | Type | Description |
+| ------------ | ------------------------- | ------------------------------------------------------- |
+| `keys` | unicode / int / iterable | The string or integer key(s) to compare to. |
+| `n` | int | The number of similar keys to return. Defaults to `10`. |
+| `batch_size` | int | The batch size to use. Defaults to `16`. |
+| **RETURNS** | list | The `(key, score)` tuples of the most similar vectors. |
+
+```python
+most_similar = s2v.most_similar("natural_language_processing|NOUN", n=3)
+# [('machine_learning|NOUN', 0.8986967),
+# ('computer_vision|NOUN', 0.8636297),
+# ('deep_learning|NOUN', 0.8573361)]
+```
+
+#### method `Sense2Vec.get_other_senses`
+
+Find other entries for the same word with a different sense, e.g. `"duck|VERB"`
+for `"duck|NOUN"`.
+
+| Argument | Type | Description |
+| ------------- | ------------- | ----------------------------------------------------------------- |
+| `key` | unicode / int | The key to check. |
+| `ignore_case` | bool | Check for uppercase, lowercase and titlecase. Defaults to `True`. |
+| **RETURNS** | list | The string keys of other entries with different senses. |
+
+```python
+other_senses = s2v.get_other_senses("duck|NOUN")
+# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ']
+```
+
+#### method `Sense2Vec.get_best_sense`
+
+Find the best-matching sense for a given word based on the available senses and
+frequency counts. Returns `None` if no match is found.
+
+| Argument | Type | Description |
+| ------------- | ------- | ------------------------------------------------------------------------------------------------------- |
+| `word` | unicode | The word to check. |
+| `senses` | list | Optional list of senses to limit the search to. If not set / empty, all senses in the vectors are used. |
+| `ignore_case` | bool | Check for uppercase, lowercase and titlecase. Defaults to `True`. |
+| **RETURNS** | unicode | The best-matching key or None. |
+
+```python
+assert s2v.get_best_sense("duck") == "duck|NOUN"
+assert s2v.get_best_sense("duck", ["VERB", "ADJ"]) == "duck|VERB"
+```
+
+#### method `Sense2Vec.to_bytes`
+
+Serialize a `Sense2Vec` object to a bytestring.
+
+| Argument | Type | Description |
+| ----------- | ----- | ----------------------------------------- |
+| `exclude` | list | Names of serialization fields to exclude. |
+| **RETURNS** | bytes | The serialized `Sense2Vec` object. |
+
+```python
+s2v_bytes = s2v.to_bytes()
+```
+
+#### method `Sense2Vec.from_bytes`
+
+Load a `Sense2Vec` object from a bytestring.
+
+| Argument | Type | Description |
+| ------------ | ----------- | ----------------------------------------- |
+| `bytes_data` | bytes | The data to load. |
+| `exclude` | list | Names of serialization fields to exclude. |
+| **RETURNS** | `Sense2Vec` | The loaded object. |
+
+```python
+s2v_bytes = s2v.to_bytes()
+new_s2v = Sense2Vec().from_bytes(s2v_bytes)
+```
+
+#### method `Sense2Vec.to_disk`
+
+Serialize a `Sense2Vec` object to a directory.
+
+| Argument | Type | Description |
+| --------- | ---------------- | ----------------------------------------- |
+| `path` | unicode / `Path` | The path. |
+| `exclude` | list | Names of serialization fields to exclude. |
+
+```python
+s2v.to_disk("/path/to/sense2vec")
+```
+
+#### method `Sense2Vec.from_disk`
+
+Load a `Sense2Vec` object from a directory.
+
+| Argument | Type | Description |
+| ----------- | ---------------- | ----------------------------------------- |
+| `path` | unicode / `Path` | The path to load from |
+| `exclude` | list | Names of serialization fields to exclude. |
+| **RETURNS** | `Sense2Vec` | The loaded object. |
+
+```python
+s2v.to_disk("/path/to/sense2vec")
+new_s2v = Sense2Vec().from_disk("/path/to/sense2vec")
+```
+
+---
+
+### class `Sense2VecComponent`
+
+The pipeline component to add sense2vec to spaCy pipelines.
+
+#### method `Sense2VecComponent.__init__`
+
+Initialize the pipeline component.
+
+| Argument | Type | Description |
+| --------------- | --------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
+| `vocab` | `Vocab` | The shared `Vocab`. Mostly used for the shared `StringStore`. |
+| `shape` | tuple | The vector shape. |
+| `merge_phrases` | bool | Whether to merge sense2vec phrases into one token. Defaults to `False`. |
+| `lemmatize` | bool | Always look up lemmas if available in the vectors, otherwise default to original word. Defaults to `False`. |
+| `overrides` | Optional custom functions to use, mapped to names registred via the registry, e.g. `{"make_key": "custom_make_key"}`. |
+| **RETURNS** | `Sense2VecComponent` | The newly constructed object. |
+
+```python
+s2v = Sense2VecComponent(nlp.vocab)
+```
+
+#### classmethod `Sense2VecComponent.from_nlp`
+
+Initialize the component from an nlp object. Mostly used as the component
+factory for the entry point (see setup.cfg) and to auto-register via the
+`@spacy.component` decorator.
+
+| Argument | Type | Description |
+| ----------- | -------------------- | ----------------------------- |
+| `nlp` | `Language` | The `nlp` object. |
+| `**cfg` | - | Optional config parameters. |
+| **RETURNS** | `Sense2VecComponent` | The newly constructed object. |
+
+```python
+s2v = Sense2VecComponent.from_nlp(nlp)
+```
+
+#### method `Sense2VecComponent.__call__`
+
+Process a `Doc` object with the component. Typically only called as part of the
+spaCy pipeline and not directly.
+
+| Argument | Type | Description |
+| ----------- | ----- | ------------------------ |
+| `doc` | `Doc` | The document to process. |
+| **RETURNS** | `Doc` | the processed document. |
+
+#### method `Sense2Vec.init_component`
+
+Register the component-specific extension attributes here and only if the
+component is added to the pipeline and used – otherwise, tokens will still get
+the attributes even if the component is only created and not added.
+
+#### method `Sense2VecComponent.to_bytes`
+
+Serialize the component to a bytestring. Also called when the component is added
+to the pipeline and you run `nlp.to_bytes`.
+
+| Argument | Type | Description |
+| ----------- | ----- | ------------------------- |
+| **RETURNS** | bytes | The serialized component. |
+
+#### method `Sense2VecComponent.from_bytes`
+
+Load a component from a bytestring. Also called when you run `nlp.from_bytes`.
+
+| Argument | Type | Description |
+| ------------ | -------------------- | ------------------ |
+| `bytes_data` | bytes | The data to load. |
+| **RETURNS** | `Sense2VecComponent` | The loaded object. |
+
+#### method `Sense2VecComponent.to_disk`
+
+Serialize the component to a directory. Also called when the component is added
+to the pipeline and you run `nlp.to_disk`.
+
+| Argument | Type | Description |
+| -------- | ---------------- | ----------- |
+| `path` | unicode / `Path` | The path. |
+
+#### method `Sense2VecComponent.from_disk`
+
+Load a `Sense2Vec` object from a directory. Also called when you run
+`nlp.from_disk`.
+
+| Argument | Type | Description |
+| ----------- | -------------------- | --------------------- |
+| `path` | unicode / `Path` | The path to load from |
+| **RETURNS** | `Sense2VecComponent` | The loaded object. |
+
+---
+
+### class `registry`
+
+Function registry (powered by
+[`catalogue`](https://github.com/explosion/catalogue)) to easily customize the
+functions used to generate keys and phrases. Allows you to decorate and name
+custom functions, swap them out and serialize the custom names when you save out
+the model. The following registry options are available:
+
+| Name | Description |
+| ------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `registry.make_key` | Given a `word` and `sense`, return a string of the key, e.g. `"word\|sense".` |
+| `registry.split_key` | Given a string key, return a `(word, sense)` tuple. |
+| `registry.make_spacy_key` | Given a spaCy object (`Token` or `Span`) and a boolean `prefer_ents` keyword argument (whether to prefer the entity label for single tokens), return a `(word, sense)` tuple. Used in extension attributes to generate a key for tokens and spans. |
+| `registry.get_phrases` | Given a spaCy `Doc`, return a list of `Span` objects used for sense2vec phrases (typically noun phrases and named entities). |
+| `registry.merge_phrases` | Given a spaCy `Doc`, get all sense2vec phrases and merge them into single tokens. |
+
+Each registry has a `register` method that can be used as a function decorator
+and takes one argument, the name of the custom function.
+
+```python
+from sense2vec import registry
+
+@registry.make_key.register("custom")
+def custom_make_key(word, sense):
+ return f"{word}###{sense}"
+
+@registry.split_key.register("custom")
+def custom_split_key(key):
+ word, sense = key.split("###")
+ return word, sense
+```
+
+When initializing the `Sense2Vec` object, you can now pass in a dictionary of
+overrides with the names of your custom registered functions.
+
+```python
+overrides = {"make_key": "custom", "split_key": "custom"}
+s2v = Sense2Vec(overrides=overrides)
+```
+
+This makes it easy to experiment with different strategies and serializing the
+strategies as plain strings (instead of having to pass around and/or pickle the
+functions themselves).
+
+## 🚂 Training your own sense2vec vectors
+
+The [`/scripts`](/scripts) directory contains command line utilities for
+preprocessing text and training your own vectors.
+
+### Requirements
+
+To train your own sense2vec vectors, you'll need the following:
+
+- A **very large** source of raw text (ideally more than you'd use for word2vec,
+ since the senses make the vocabulary more sparse). We recommend at least 1
+ billion words.
+- A [pretrained spaCy model](https://spacy.io/models) that assigns
+ part-of-speech tags, dependencies and named entities, and populates the
+ `doc.noun_chunks`. If the language you need doesn't provide a built in
+ [syntax iterator for noun phrases](https://spacy.io/usage/adding-languages#syntax-iterators),
+ you'll need to write your own. (The `doc.noun_chunks` and `doc.ents` are what
+ sense2vec uses to determine what's a phrase.)
+- [GloVe](https://github.com/stanfordnlp/GloVe) or
+ [fastText](https://github.com/facebookresearch/fastText) installed and built.
+ You should be able to clone the repo and run `make` in the respective
+ directory.
+
+### Step-by-step process
+
+The training process is split up into several steps to allow you to resume at
+any given point. Processing scripts are designed to operate on single files,
+making it easy to parallellize the work. The scripts in this repo require either
+[Glove](https://github.com/stanfordnlp/GloVe) or
+[fastText](https://github.com/facebookresearch/fastText) which you need to clone
+and `make`.
+
+For Fasttext, the scripts will require the path to the created binary file. If
+you're working on Windows, you can build with `cmake`, or alternatively use the
+`.exe` file from this **unofficial** repo with FastText binary builds for
+Windows: https://github.com/xiamx/fastText/releases.
+
+| | Script | Description |
+| ------ | -------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **1.** | [`01_parse.py`](scripts/01_parse.py) | Use spaCy to parse the raw text and output binary collections of `Doc` objects (see [`DocBin`](https://spacy.io/api/docbin)). |
+| **2.** | [`02_preprocess.py`](scripts/02_preprocess.py) | Load a collection of parsed `Doc` objects produced in the previous step and output text files in the sense2vec format (one sentence per line and merged phrases with senses). |
+| **3.** | [`03_glove_build_counts.py`](scripts/03_glove_build_counts.py) | Use [GloVe](https://github.com/stanfordnlp/GloVe) to build the vocabulary and counts. Skip this step if you're using Word2Vec via [FastText](https://github.com/facebookresearch/fastText). |
+| **4.** | [`04_glove_train_vectors.py`](scripts/04_glove_train_vectors.py)
+
+To try out our pretrained vectors trained on Reddit comments, check out the
+[interactive sense2vec demo](https://explosion.ai/demos/sense2vec).
+
+This repo also includes a [Streamlit](https://streamlit.io) demo script for
+exploring vectors and the most similar phrases. After installing `streamlit`,
+you can run the script with `streamlit run` and **one or more paths to
+pretrained vectors** as **positional arguments** on the command line. For
+example:
+
+```bash
+pip install streamlit
+streamlit run https://raw.githubusercontent.com/explosion/sense2vec/master/scripts/streamlit_sense2vec.py /path/to/vectors
+```
+
+### Pretrained vectors
+
+To use the vectors, download the archive(s) and pass the extracted directory to
+`Sense2Vec.from_disk` or `Sense2VecComponent.from_disk`. The vector files are
+**attached to the GitHub release**. Large files have been split into multi-part
+downloads.
+
+| Vectors | Size | Description | 📥 Download (zipped) |
+| -------------------- | -----: | ---------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `s2v_reddit_2019_lg` | 4 GB | Reddit comments 2019 (01-07) | [part 1](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2019_lg.tar.gz.001), [part 2](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2019_lg.tar.gz.002), [part 3](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2019_lg.tar.gz.003) |
+| `s2v_reddit_2015_md` | 573 MB | Reddit comments 2015 | [part 1](https://github.com/explosion/sense2vec/releases/download/v1.0.0/s2v_reddit_2015_md.tar.gz) |
+
+To merge the multi-part archives, you can run the following:
+
+```bash
+cat s2v_reddit_2019_lg.tar.gz.* > s2v_reddit_2019_lg.tar.gz
+```
+
+## ⏳ Installation & Setup
+
+sense2vec releases are available on pip:
+
+```bash
+pip install sense2vec
+```
+
+To use pretrained vectors, download
+[one of the vector packages](#pretrained-vectors), unpack the `.tar.gz` archive
+and point `from_disk` to the extracted data directory:
+
+```python
+from sense2vec import Sense2Vec
+s2v = Sense2Vec().from_disk("/path/to/s2v_reddit_2015_md")
+```
+
+## 👩💻 Usage
+
+### Usage with spaCy v3
+
+The easiest way to use the library and vectors is to plug it into your spaCy
+pipeline. The `sense2vec` package exposes a `Sense2VecComponent`, which can be
+initialised with the shared vocab and added to your spaCy pipeline as a
+[custom pipeline component](https://spacy.io/usage/processing-pipelines#custom-components).
+By default, components are added to the _end of the pipeline_, which is the
+recommended position for this component, since it needs access to the dependency
+parse and, if available, named entities.
+
+```python
+import spacy
+from sense2vec import Sense2VecComponent
+
+nlp = spacy.load("en_core_web_sm")
+s2v = nlp.add_pipe("sense2vec")
+s2v.from_disk("/path/to/s2v_reddit_2015_md")
+```
+
+The component will add several
+[extension attributes and methods](https://spacy.io/usage/processing-pipelines#custom-components-attributes)
+to spaCy's `Token` and `Span` objects that let you retrieve vectors and
+frequencies, as well as most similar terms.
+
+```python
+doc = nlp("A sentence about natural language processing.")
+assert doc[3:6].text == "natural language processing"
+freq = doc[3:6]._.s2v_freq
+vector = doc[3:6]._.s2v_vec
+most_similar = doc[3:6]._.s2v_most_similar(3)
+```
+
+For entities, the entity labels are used as the "sense" (instead of the token's
+part-of-speech tag):
+
+```python
+doc = nlp("A sentence about Facebook and Google.")
+for ent in doc.ents:
+ assert ent._.in_s2v
+ most_similar = ent._.s2v_most_similar(3)
+```
+
+#### Available attributes
+
+The following extension attributes are exposed on the `Doc` object via the `._`
+property:
+
+| Name | Attribute Type | Type | Description |
+| ------------- | -------------- | ---- | ----------------------------------------------------------------------------------- |
+| `s2v_phrases` | property | list | All sense2vec-compatible phrases in the given `Doc` (noun phrases, named entities). |
+
+The following attributes are available via the `._` property of `Token` and
+`Span` objects – for example `token._.in_s2v`:
+
+| Name | Attribute Type | Return Type | Description |
+| ------------------ | -------------- | ------------------ | ---------------------------------------------------------------------------------- |
+| `in_s2v` | property | bool | Whether a key exists in the vector map. |
+| `s2v_key` | property | unicode | The sense2vec key of the given object, e.g. `"duck NOUN"`. |
+| `s2v_vec` | property | `ndarray[float32]` | The vector of the given key. |
+| `s2v_freq` | property | int | The frequency of the given key. |
+| `s2v_other_senses` | property | list | Available other senses, e.g. `"duck\|VERB"` for `"duck\|NOUN"`. |
+| `s2v_most_similar` | method | list | Get the `n` most similar terms. Returns a list of `((word, sense), score)` tuples. |
+| `s2v_similarity` | method | float | Get the similarity to another `Token` or `Span`. |
+
+> ⚠️ **A note on span attributes:** Under the hood, entities in `doc.ents` are
+> `Span` objects. This is why the pipeline component also adds attributes and
+> methods to spans and not just tokens. However, it's not recommended to use the
+> sense2vec attributes on arbitrary slices of the document, since the model
+> likely won't have a key for the respective text. `Span` objects also don't
+> have a part-of-speech tag, so if no entity label is present, the "sense"
+> defaults to the root's part-of-speech tag.
+
+#### Adding sense2vec to a trained pipeline
+
+If you're training and packaging a spaCy pipeline and want to include a
+sense2vec component in it, you can load in the data via the
+[`[initialize]` block](https://spacy.io/usage/training#config-lifecycle) of the
+training config:
+
+```ini
+[initialize.components]
+
+[initialize.components.sense2vec]
+data_path = "/path/to/s2v_reddit_2015_md"
+```
+
+### Standalone usage
+
+You can also use the underlying `Sense2Vec` class directly and load in the
+vectors using the `from_disk` method. See below for the available API methods.
+
+```python
+from sense2vec import Sense2Vec
+s2v = Sense2Vec().from_disk("/path/to/reddit_vectors-1.1.0")
+most_similar = s2v.most_similar("natural_language_processing|NOUN", n=10)
+```
+
+> ⚠️ **Important note:** To look up entries in the vectors table, the keys need
+> to follow the scheme of `phrase_text|SENSE` (note the `_` instead of spaces
+> and the `|` before the tag or label) – for example, `machine_learning|NOUN`.
+> Also note that the underlying vector table is case-sensitive.
+
+## 🎛 API
+
+### class `Sense2Vec`
+
+The standalone `Sense2Vec` object that holds the vectors, strings and
+frequencies.
+
+#### method `Sense2Vec.__init__`
+
+Initialize the `Sense2Vec` object.
+
+| Argument | Type | Description |
+| -------------- | --------------------------- | ---------------------------------------------------------------------------------------------------------------------- |
+| `shape` | tuple | The vector shape. Defaults to `(1000, 128)`. |
+| `strings` | `spacy.strings.StringStore` | Optional string store. Will be created if it doesn't exist. |
+| `senses` | list | Optional list of all available senses. Used in methods that generate the best sense or other senses. |
+| `vectors_name` | unicode | Optional name to assign to the `Vectors` table, to prevent clashes. Defaults to `"sense2vec"`. |
+| `overrides` | dict | Optional custom functions to use, mapped to names registered via the registry, e.g. `{"make_key": "custom_make_key"}`. |
+| **RETURNS** | `Sense2Vec` | The newly constructed object. |
+
+```python
+s2v = Sense2Vec(shape=(300, 128), senses=["VERB", "NOUN"])
+```
+
+#### method `Sense2Vec.__len__`
+
+The number of rows in the vectors table.
+
+| Argument | Type | Description |
+| ----------- | ---- | ---------------------------------------- |
+| **RETURNS** | int | The number of rows in the vectors table. |
+
+```python
+s2v = Sense2Vec(shape=(300, 128))
+assert len(s2v) == 300
+```
+
+#### method `Sense2Vec.__contains__`
+
+Check if a key is in the vectors table.
+
+| Argument | Type | Description |
+| ----------- | ------------- | -------------------------------- |
+| `key` | unicode / int | The key to look up. |
+| **RETURNS** | bool | Whether the key is in the table. |
+
+```python
+s2v = Sense2Vec(shape=(10, 4))
+s2v.add("avocado|NOUN", numpy.asarray([4, 2, 2, 2], dtype=numpy.float32))
+assert "avocado|NOUN" in s2v
+assert "avocado|VERB" not in s2v
+```
+
+#### method `Sense2Vec.__getitem__`
+
+Retrieve a vector for a given key. Returns None if the key is not in the table.
+
+| Argument | Type | Description |
+| ----------- | --------------- | --------------------- |
+| `key` | unicode / int | The key to look up. |
+| **RETURNS** | `numpy.ndarray` | The vector or `None`. |
+
+```python
+vec = s2v["avocado|NOUN"]
+```
+
+#### method `Sense2Vec.__setitem__`
+
+Set a vector for a given key. Will raise an error if the key doesn't exist. To
+add a new entry, use `Sense2Vec.add`.
+
+| Argument | Type | Description |
+| -------- | --------------- | ------------------ |
+| `key` | unicode / int | The key. |
+| `vector` | `numpy.ndarray` | The vector to set. |
+
+```python
+vec = s2v["avocado|NOUN"]
+s2v["avacado|NOUN"] = vec
+```
+
+#### method `Sense2Vec.add`
+
+Add a new vector to the table.
+
+| Argument | Type | Description |
+| -------- | --------------- | ------------------------------------------------------------ |
+| `key` | unicode / int | The key to add. |
+| `vector` | `numpy.ndarray` | The vector to add. |
+| `freq` | int | Optional frequency count. Used to find best matching senses. |
+
+```python
+vec = s2v["avocado|NOUN"]
+s2v.add("🥑|NOUN", vec, 1234)
+```
+
+#### method `Sense2Vec.get_freq`
+
+Get the frequency count for a given key.
+
+| Argument | Type | Description |
+| ----------- | ------------- | ------------------------------------------------- |
+| `key` | unicode / int | The key to look up. |
+| `default` | - | Default value to return if no frequency is found. |
+| **RETURNS** | int | The frequency count. |
+
+```python
+vec = s2v["avocado|NOUN"]
+s2v.add("🥑|NOUN", vec, 1234)
+assert s2v.get_freq("🥑|NOUN") == 1234
+```
+
+#### method `Sense2Vec.set_freq`
+
+Set a frequency count for a given key.
+
+| Argument | Type | Description |
+| -------- | ------------- | ----------------------------- |
+| `key` | unicode / int | The key to set the count for. |
+| `freq` | int | The frequency count. |
+
+```python
+s2v.set_freq("avocado|NOUN", 104294)
+```
+
+#### method `Sense2Vec.__iter__`, `Sense2Vec.items`
+
+Iterate over the entries in the vectors table.
+
+| Argument | Type | Description |
+| ---------- | ----- | ----------------------------------------- |
+| **YIELDS** | tuple | String key and vector pairs in the table. |
+
+```python
+for key, vec in s2v:
+ print(key, vec)
+
+for key, vec in s2v.items():
+ print(key, vec)
+```
+
+#### method `Sense2Vec.keys`
+
+Iterate over the keys in the table.
+
+| Argument | Type | Description |
+| ---------- | ------- | ----------------------------- |
+| **YIELDS** | unicode | The string keys in the table. |
+
+```python
+all_keys = list(s2v.keys())
+```
+
+#### method `Sense2Vec.values`
+
+Iterate over the vectors in the table.
+
+| Argument | Type | Description |
+| ---------- | --------------- | ------------------------- |
+| **YIELDS** | `numpy.ndarray` | The vectors in the table. |
+
+```python
+all_vecs = list(s2v.values())
+```
+
+#### property `Sense2Vec.senses`
+
+The available senses in the table, e.g. `"NOUN"` or `"VERB"` (added at
+initialization).
+
+| Argument | Type | Description |
+| ----------- | ---- | --------------------- |
+| **RETURNS** | list | The available senses. |
+
+```python
+s2v = Sense2Vec(senses=["VERB", "NOUN"])
+assert "VERB" in s2v.senses
+```
+
+#### property `Sense2vec.frequencies`
+
+The frequencies of the keys in the table, in descending order.
+
+| Argument | Type | Description |
+| ----------- | ---- | -------------------------------------------------- |
+| **RETURNS** | list | The `(key, freq)` tuples by frequency, descending. |
+
+```python
+most_frequent = s2v.frequencies[:10]
+key, score = s2v.frequencies[0]
+```
+
+#### method `Sense2vec.similarity`
+
+Make a semantic similarity estimate of two keys or two sets of keys. The default
+estimate is cosine similarity using an average of vectors.
+
+| Argument | Type | Description |
+| ----------- | ------------------------ | ----------------------------------- |
+| `keys_a` | unicode / int / iterable | The string or integer key(s). |
+| `keys_b` | unicode / int / iterable | The other string or integer key(s). |
+| **RETURNS** | float | The similarity score. |
+
+```python
+keys_a = ["machine_learning|NOUN", "natural_language_processing|NOUN"]
+keys_b = ["computer_vision|NOUN", "object_detection|NOUN"]
+print(s2v.similarity(keys_a, keys_b))
+assert s2v.similarity("machine_learning|NOUN", "machine_learning|NOUN") == 1.0
+```
+
+#### method `Sense2Vec.most_similar`
+
+Get the most similar entries in the table. If more than one key is provided, the
+average of the vectors is used. To make this method faster, see the
+[script for precomputing a cache](scripts/06_precompute_cache.py) of the nearest
+neighbors.
+
+| Argument | Type | Description |
+| ------------ | ------------------------- | ------------------------------------------------------- |
+| `keys` | unicode / int / iterable | The string or integer key(s) to compare to. |
+| `n` | int | The number of similar keys to return. Defaults to `10`. |
+| `batch_size` | int | The batch size to use. Defaults to `16`. |
+| **RETURNS** | list | The `(key, score)` tuples of the most similar vectors. |
+
+```python
+most_similar = s2v.most_similar("natural_language_processing|NOUN", n=3)
+# [('machine_learning|NOUN', 0.8986967),
+# ('computer_vision|NOUN', 0.8636297),
+# ('deep_learning|NOUN', 0.8573361)]
+```
+
+#### method `Sense2Vec.get_other_senses`
+
+Find other entries for the same word with a different sense, e.g. `"duck|VERB"`
+for `"duck|NOUN"`.
+
+| Argument | Type | Description |
+| ------------- | ------------- | ----------------------------------------------------------------- |
+| `key` | unicode / int | The key to check. |
+| `ignore_case` | bool | Check for uppercase, lowercase and titlecase. Defaults to `True`. |
+| **RETURNS** | list | The string keys of other entries with different senses. |
+
+```python
+other_senses = s2v.get_other_senses("duck|NOUN")
+# ['duck|VERB', 'Duck|ORG', 'Duck|VERB', 'Duck|PERSON', 'Duck|ADJ']
+```
+
+#### method `Sense2Vec.get_best_sense`
+
+Find the best-matching sense for a given word based on the available senses and
+frequency counts. Returns `None` if no match is found.
+
+| Argument | Type | Description |
+| ------------- | ------- | ------------------------------------------------------------------------------------------------------- |
+| `word` | unicode | The word to check. |
+| `senses` | list | Optional list of senses to limit the search to. If not set / empty, all senses in the vectors are used. |
+| `ignore_case` | bool | Check for uppercase, lowercase and titlecase. Defaults to `True`. |
+| **RETURNS** | unicode | The best-matching key or None. |
+
+```python
+assert s2v.get_best_sense("duck") == "duck|NOUN"
+assert s2v.get_best_sense("duck", ["VERB", "ADJ"]) == "duck|VERB"
+```
+
+#### method `Sense2Vec.to_bytes`
+
+Serialize a `Sense2Vec` object to a bytestring.
+
+| Argument | Type | Description |
+| ----------- | ----- | ----------------------------------------- |
+| `exclude` | list | Names of serialization fields to exclude. |
+| **RETURNS** | bytes | The serialized `Sense2Vec` object. |
+
+```python
+s2v_bytes = s2v.to_bytes()
+```
+
+#### method `Sense2Vec.from_bytes`
+
+Load a `Sense2Vec` object from a bytestring.
+
+| Argument | Type | Description |
+| ------------ | ----------- | ----------------------------------------- |
+| `bytes_data` | bytes | The data to load. |
+| `exclude` | list | Names of serialization fields to exclude. |
+| **RETURNS** | `Sense2Vec` | The loaded object. |
+
+```python
+s2v_bytes = s2v.to_bytes()
+new_s2v = Sense2Vec().from_bytes(s2v_bytes)
+```
+
+#### method `Sense2Vec.to_disk`
+
+Serialize a `Sense2Vec` object to a directory.
+
+| Argument | Type | Description |
+| --------- | ---------------- | ----------------------------------------- |
+| `path` | unicode / `Path` | The path. |
+| `exclude` | list | Names of serialization fields to exclude. |
+
+```python
+s2v.to_disk("/path/to/sense2vec")
+```
+
+#### method `Sense2Vec.from_disk`
+
+Load a `Sense2Vec` object from a directory.
+
+| Argument | Type | Description |
+| ----------- | ---------------- | ----------------------------------------- |
+| `path` | unicode / `Path` | The path to load from |
+| `exclude` | list | Names of serialization fields to exclude. |
+| **RETURNS** | `Sense2Vec` | The loaded object. |
+
+```python
+s2v.to_disk("/path/to/sense2vec")
+new_s2v = Sense2Vec().from_disk("/path/to/sense2vec")
+```
+
+---
+
+### class `Sense2VecComponent`
+
+The pipeline component to add sense2vec to spaCy pipelines.
+
+#### method `Sense2VecComponent.__init__`
+
+Initialize the pipeline component.
+
+| Argument | Type | Description |
+| --------------- | --------------------------------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
+| `vocab` | `Vocab` | The shared `Vocab`. Mostly used for the shared `StringStore`. |
+| `shape` | tuple | The vector shape. |
+| `merge_phrases` | bool | Whether to merge sense2vec phrases into one token. Defaults to `False`. |
+| `lemmatize` | bool | Always look up lemmas if available in the vectors, otherwise default to original word. Defaults to `False`. |
+| `overrides` | Optional custom functions to use, mapped to names registred via the registry, e.g. `{"make_key": "custom_make_key"}`. |
+| **RETURNS** | `Sense2VecComponent` | The newly constructed object. |
+
+```python
+s2v = Sense2VecComponent(nlp.vocab)
+```
+
+#### classmethod `Sense2VecComponent.from_nlp`
+
+Initialize the component from an nlp object. Mostly used as the component
+factory for the entry point (see setup.cfg) and to auto-register via the
+`@spacy.component` decorator.
+
+| Argument | Type | Description |
+| ----------- | -------------------- | ----------------------------- |
+| `nlp` | `Language` | The `nlp` object. |
+| `**cfg` | - | Optional config parameters. |
+| **RETURNS** | `Sense2VecComponent` | The newly constructed object. |
+
+```python
+s2v = Sense2VecComponent.from_nlp(nlp)
+```
+
+#### method `Sense2VecComponent.__call__`
+
+Process a `Doc` object with the component. Typically only called as part of the
+spaCy pipeline and not directly.
+
+| Argument | Type | Description |
+| ----------- | ----- | ------------------------ |
+| `doc` | `Doc` | The document to process. |
+| **RETURNS** | `Doc` | the processed document. |
+
+#### method `Sense2Vec.init_component`
+
+Register the component-specific extension attributes here and only if the
+component is added to the pipeline and used – otherwise, tokens will still get
+the attributes even if the component is only created and not added.
+
+#### method `Sense2VecComponent.to_bytes`
+
+Serialize the component to a bytestring. Also called when the component is added
+to the pipeline and you run `nlp.to_bytes`.
+
+| Argument | Type | Description |
+| ----------- | ----- | ------------------------- |
+| **RETURNS** | bytes | The serialized component. |
+
+#### method `Sense2VecComponent.from_bytes`
+
+Load a component from a bytestring. Also called when you run `nlp.from_bytes`.
+
+| Argument | Type | Description |
+| ------------ | -------------------- | ------------------ |
+| `bytes_data` | bytes | The data to load. |
+| **RETURNS** | `Sense2VecComponent` | The loaded object. |
+
+#### method `Sense2VecComponent.to_disk`
+
+Serialize the component to a directory. Also called when the component is added
+to the pipeline and you run `nlp.to_disk`.
+
+| Argument | Type | Description |
+| -------- | ---------------- | ----------- |
+| `path` | unicode / `Path` | The path. |
+
+#### method `Sense2VecComponent.from_disk`
+
+Load a `Sense2Vec` object from a directory. Also called when you run
+`nlp.from_disk`.
+
+| Argument | Type | Description |
+| ----------- | -------------------- | --------------------- |
+| `path` | unicode / `Path` | The path to load from |
+| **RETURNS** | `Sense2VecComponent` | The loaded object. |
+
+---
+
+### class `registry`
+
+Function registry (powered by
+[`catalogue`](https://github.com/explosion/catalogue)) to easily customize the
+functions used to generate keys and phrases. Allows you to decorate and name
+custom functions, swap them out and serialize the custom names when you save out
+the model. The following registry options are available:
+
+| Name | Description |
+| ------------------------- | -------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `registry.make_key` | Given a `word` and `sense`, return a string of the key, e.g. `"word\|sense".` |
+| `registry.split_key` | Given a string key, return a `(word, sense)` tuple. |
+| `registry.make_spacy_key` | Given a spaCy object (`Token` or `Span`) and a boolean `prefer_ents` keyword argument (whether to prefer the entity label for single tokens), return a `(word, sense)` tuple. Used in extension attributes to generate a key for tokens and spans. |
+| `registry.get_phrases` | Given a spaCy `Doc`, return a list of `Span` objects used for sense2vec phrases (typically noun phrases and named entities). |
+| `registry.merge_phrases` | Given a spaCy `Doc`, get all sense2vec phrases and merge them into single tokens. |
+
+Each registry has a `register` method that can be used as a function decorator
+and takes one argument, the name of the custom function.
+
+```python
+from sense2vec import registry
+
+@registry.make_key.register("custom")
+def custom_make_key(word, sense):
+ return f"{word}###{sense}"
+
+@registry.split_key.register("custom")
+def custom_split_key(key):
+ word, sense = key.split("###")
+ return word, sense
+```
+
+When initializing the `Sense2Vec` object, you can now pass in a dictionary of
+overrides with the names of your custom registered functions.
+
+```python
+overrides = {"make_key": "custom", "split_key": "custom"}
+s2v = Sense2Vec(overrides=overrides)
+```
+
+This makes it easy to experiment with different strategies and serializing the
+strategies as plain strings (instead of having to pass around and/or pickle the
+functions themselves).
+
+## 🚂 Training your own sense2vec vectors
+
+The [`/scripts`](/scripts) directory contains command line utilities for
+preprocessing text and training your own vectors.
+
+### Requirements
+
+To train your own sense2vec vectors, you'll need the following:
+
+- A **very large** source of raw text (ideally more than you'd use for word2vec,
+ since the senses make the vocabulary more sparse). We recommend at least 1
+ billion words.
+- A [pretrained spaCy model](https://spacy.io/models) that assigns
+ part-of-speech tags, dependencies and named entities, and populates the
+ `doc.noun_chunks`. If the language you need doesn't provide a built in
+ [syntax iterator for noun phrases](https://spacy.io/usage/adding-languages#syntax-iterators),
+ you'll need to write your own. (The `doc.noun_chunks` and `doc.ents` are what
+ sense2vec uses to determine what's a phrase.)
+- [GloVe](https://github.com/stanfordnlp/GloVe) or
+ [fastText](https://github.com/facebookresearch/fastText) installed and built.
+ You should be able to clone the repo and run `make` in the respective
+ directory.
+
+### Step-by-step process
+
+The training process is split up into several steps to allow you to resume at
+any given point. Processing scripts are designed to operate on single files,
+making it easy to parallellize the work. The scripts in this repo require either
+[Glove](https://github.com/stanfordnlp/GloVe) or
+[fastText](https://github.com/facebookresearch/fastText) which you need to clone
+and `make`.
+
+For Fasttext, the scripts will require the path to the created binary file. If
+you're working on Windows, you can build with `cmake`, or alternatively use the
+`.exe` file from this **unofficial** repo with FastText binary builds for
+Windows: https://github.com/xiamx/fastText/releases.
+
+| | Script | Description |
+| ------ | -------------------------------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| **1.** | [`01_parse.py`](scripts/01_parse.py) | Use spaCy to parse the raw text and output binary collections of `Doc` objects (see [`DocBin`](https://spacy.io/api/docbin)). |
+| **2.** | [`02_preprocess.py`](scripts/02_preprocess.py) | Load a collection of parsed `Doc` objects produced in the previous step and output text files in the sense2vec format (one sentence per line and merged phrases with senses). |
+| **3.** | [`03_glove_build_counts.py`](scripts/03_glove_build_counts.py) | Use [GloVe](https://github.com/stanfordnlp/GloVe) to build the vocabulary and counts. Skip this step if you're using Word2Vec via [FastText](https://github.com/facebookresearch/fastText). |
+| **4.** | [`04_glove_train_vectors.py`](scripts/04_glove_train_vectors.py)
[`04_fasttext_train_vectors.py`](scripts/04_fasttext_train_vectors.py) | Use [GloVe](https://github.com/stanfordnlp/GloVe) or [FastText](https://github.com/facebookresearch/fastText) to train vectors. |
+| **5.** | [`05_export.py`](scripts/05_export.py) | Load the vectors and frequencies and output a sense2vec component that can be loaded via `Sense2Vec.from_disk`. |
+| **6.** | [`06_precompute_cache.py`](scripts/06_precompute_cache.py) | **Optional:** Precompute nearest-neighbor queries for every entry in the vocab to make `Sense2Vec.most_similar` faster. |
+
+For more detailed documentation of the scripts, check out the source or run them
+with `--help`. For example, `python scripts/01_parse.py --help`.
+
+## 🍳 Prodigy recipes
+
+This package also seamlessly integrates with the [Prodigy](https://prodi.gy)
+annotation tool and exposes recipes for using sense2vec vectors to quickly
+generate lists of multi-word phrases and bootstrap NER annotations. To use a
+recipe, `sense2vec` needs to be installed in the same environment as Prodigy.
+For an example of a real-world use case, check out this
+[NER project](https://github.com/explosion/projects/tree/master/ner-fashion-brands)
+with downloadable datasets.
+
+The following recipes are available – see below for more detailed docs.
+
+| Recipe | Description |
+| ------------------------------------------------------------------- | -------------------------------------------------------------------- |
+| [`sense2vec.teach`](#recipe-sense2vecteach) | Bootstrap a terminology list using sense2vec. |
+| [`sense2vec.to-patterns`](#recipe-sense2vecto-patterns) | Convert phrases dataset to token-based match patterns. |
+| [`sense2vec.eval`](#recipe-sense2veceval) | Evaluate a sense2vec model by asking about phrase triples. |
+| [`sense2vec.eval-most-similar`](#recipe-sense2veceval-most-similar) | Evaluate a sense2vec model by correcting the most similar entries. |
+| [`sense2vec.eval-ab`](#recipe-sense2veceval-ab) | Perform an A/B evaluation of two pretrained sense2vec vector models. |
+
+### recipe `sense2vec.teach`
+
+Bootstrap a terminology list using sense2vec. Prodigy will suggest similar terms
+based on the most similar phrases from sense2vec, and the suggestions will be
+adjusted as you annotate and accept similar phrases. For each seed term, the
+best matching sense according to the sense2vec vectors will be used.
+
+```bash
+prodigy sense2vec.teach [dataset] [vectors_path] [--seeds] [--threshold]
+[--n-similar] [--batch-size] [--resume]
+```
+
+| Argument | Type | Description |
+| -------------------- | ---------- | ----------------------------------------- |
+| `dataset` | positional | Dataset to save annotations to. |
+| `vectors_path` | positional | Path to pretrained sense2vec vectors. |
+| `--seeds`, `-s` | option | One or more comma-separated seed phrases. |
+| `--threshold`, `-t` | option | Similarity threshold. Defaults to `0.85`. |
+| `--n-similar`, `-n` | option | Number of similar items to get at once. |
+| `--batch-size`, `-b` | option | Batch size for submitting annotations. |
+| `--resume`, `-R` | flag | Resume from an existing phrases dataset. |
+
+#### Example
+
+```bash
+prodigy sense2vec.teach tech_phrases /path/to/s2v_reddit_2015_md
+--seeds "natural language processing, machine learning, artificial intelligence"
+```
+
+### recipe `sense2vec.to-patterns`
+
+Convert a dataset of phrases collected with `sense2vec.teach` to token-based
+match patterns that can be used with
+[spaCy's `EntityRuler`](https://spacy.io/usage/rule-based-matching#entityruler)
+or recipes like `ner.match`. If no output file is specified, the patterns are
+written to stdout. The examples are tokenized so that multi-token terms are
+represented correctly, e.g.:
+`{"label": "SHOE_BRAND", "pattern": [{ "LOWER": "new" }, { "LOWER": "balance" }]}`.
+
+```bash
+prodigy sense2vec.to-patterns [dataset] [spacy_model] [label] [--output-file]
+[--case-sensitive] [--dry]
+```
+
+| Argument | Type | Description |
+| ------------------------- | ---------- | -------------------------------------------- |
+| `dataset` | positional | Phrase dataset to convert. |
+| `spacy_model` | positional | spaCy model for tokenization. |
+| `label` | positional | Label to apply to all patterns. |
+| `--output-file`, `-o` | option | Optional output file. Defaults to stdout. |
+| `--case-sensitive`, `-CS` | flag | Make patterns case-sensitive. |
+| `--dry`, `-D` | flag | Perform a dry run and don't output anything. |
+
+#### Example
+
+```bash
+prodigy sense2vec.to-patterns tech_phrases en_core_web_sm TECHNOLOGY
+--output-file /path/to/patterns.jsonl
+```
+
+### recipe `sense2vec.eval`
+
+Evaluate a sense2vec model by asking about phrase triples: is word A more
+similar to word B, or to word C? If the human mostly agrees with the model, the
+vectors model is good. The recipe will only ask about vectors with the same
+sense and supports different example selection strategies.
+
+```bash
+prodigy sense2vec.eval [dataset] [vectors_path] [--strategy] [--senses]
+[--exclude-senses] [--n-freq] [--threshold] [--batch-size] [--eval-whole]
+[--eval-only] [--show-scores]
+```
+
+| Argument | Type | Description |
+| ------------------------- | ---------- | ------------------------------------------------------------------------------------------------------------- |
+| `dataset` | positional | Dataset to save annotations to. |
+| `vectors_path` | positional | Path to pretrained sense2vec vectors. |
+| `--strategy`, `-st` | option | Example selection strategy. `most similar` (default) or `random`. |
+| `--senses`, `-s` | option | Comma-separated list of senses to limit the selection to. If not set, all senses in the vectors will be used. |
+| `--exclude-senses`, `-es` | option | Comma-separated list of senses to exclude. See `prodigy_recipes.EVAL_EXCLUDE_SENSES` fro the defaults. |
+| `--n-freq`, `-f` | option | Number of most frequent entries to limit to. |
+| `--threshold`, `-t` | option | Minimum similarity threshold to consider examples. |
+| `--batch-size`, `-b` | option | Batch size to use. |
+| `--eval-whole`, `-E` | flag | Evaluate the whole dataset instead of the current session. |
+| `--eval-only`, `-O` | flag | Don't annotate, only evaluate the current dataset. |
+| `--show-scores`, `-S` | flag | Show all scores for debugging. |
+
+#### Strategies
+
+| Name | Description |
+| -------------------- | --------------------------------------------------------------------------------------------------------------------------------------------------------------------- |
+| `most_similar` | Pick a random word from a random sense and get its most similar entries of the same sense. Ask about the similarity to the last and middle entry from that selection. |
+| `most_least_similar` | Pick a random word from a random sense and get the least similar entry from its most similar entries, and then the last most similar entry of that. |
+| `random` | Pick a random sample of 3 words from the same random sense. |
+
+#### Example
+
+```bash
+prodigy sense2vec.eval vectors_eval /path/to/s2v_reddit_2015_md
+--senses NOUN,ORG,PRODUCT --threshold 0.5
+```
+
+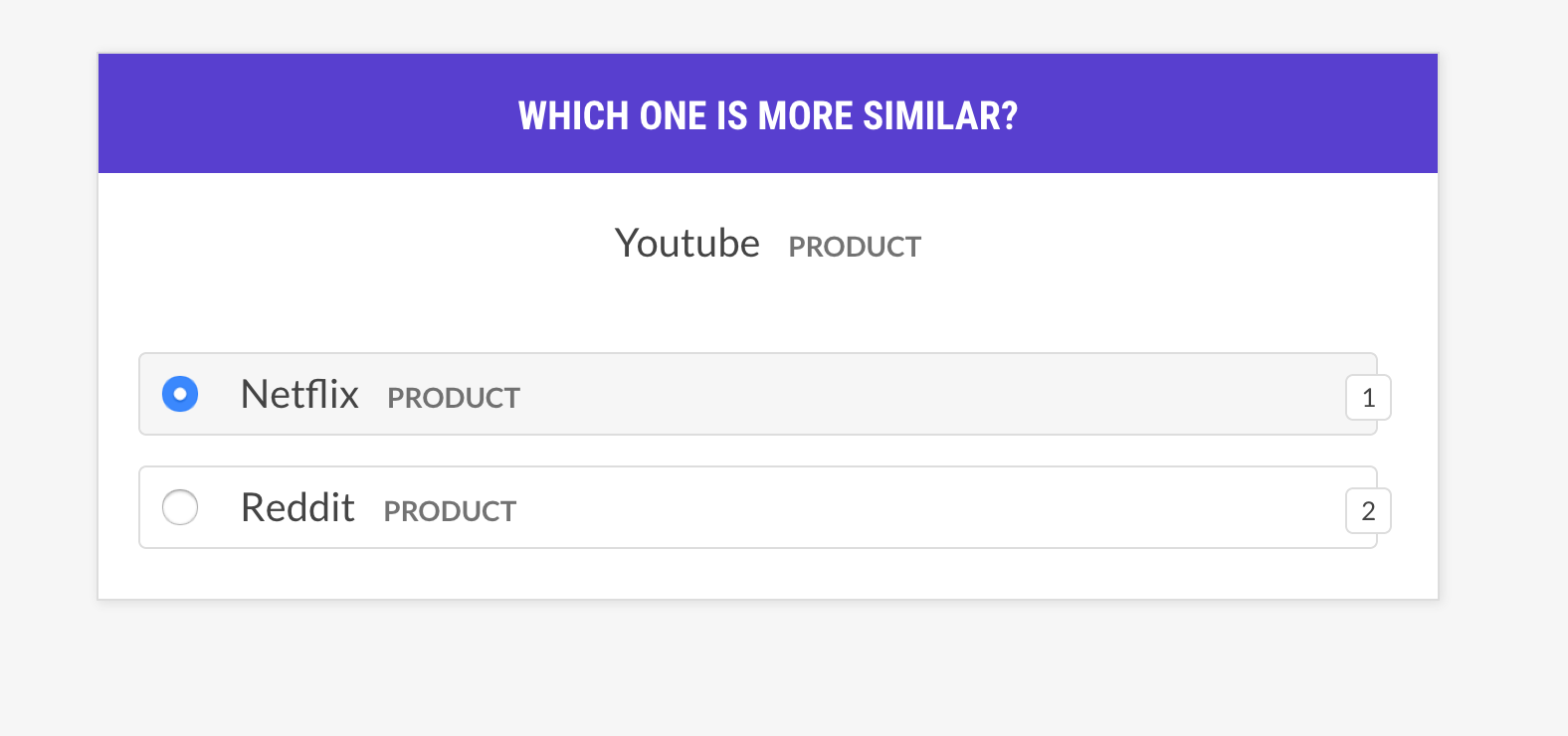
+
+### recipe `sense2vec.eval-most-similar`
+
+Evaluate a vectors model by looking at the most similar entries it returns for a
+random phrase and unselecting the mistakes.
+
+```bash
+prodigy sense2vec.eval [dataset] [vectors_path] [--senses] [--exclude-senses]
+[--n-freq] [--n-similar] [--batch-size] [--eval-whole] [--eval-only]
+[--show-scores]
+```
+
+| Argument | Type | Description |
+| ------------------------- | ---------- | ------------------------------------------------------------------------------------------------------------- |
+| `dataset` | positional | Dataset to save annotations to. |
+| `vectors_path` | positional | Path to pretrained sense2vec vectors. |
+| `--senses`, `-s` | option | Comma-separated list of senses to limit the selection to. If not set, all senses in the vectors will be used. |
+| `--exclude-senses`, `-es` | option | Comma-separated list of senses to exclude. See `prodigy_recipes.EVAL_EXCLUDE_SENSES` fro the defaults. |
+| `--n-freq`, `-f` | option | Number of most frequent entries to limit to. |
+| `--n-similar`, `-n` | option | Number of similar items to check. Defaults to `10`. |
+| `--batch-size`, `-b` | option | Batch size to use. |
+| `--eval-whole`, `-E` | flag | Evaluate the whole dataset instead of the current session. |
+| `--eval-only`, `-O` | flag | Don't annotate, only evaluate the current dataset. |
+| `--show-scores`, `-S` | flag | Show all scores for debugging. |
+
+```bash
+prodigy sense2vec.eval-most-similar vectors_eval_sim /path/to/s2v_reddit_2015_md
+--senses NOUN,ORG,PRODUCT
+```
+
+### recipe `sense2vec.eval-ab`
+
+Perform an A/B evaluation of two pretrained sense2vec vector models by comparing
+the most similar entries they return for a random phrase. The UI shows two
+randomized options with the most similar entries of each model and highlights
+the phrases that differ. At the end of the annotation session the overall stats
+and preferred model are shown.
+
+```bash
+prodigy sense2vec.eval [dataset] [vectors_path_a] [vectors_path_b] [--senses]
+[--exclude-senses] [--n-freq] [--n-similar] [--batch-size] [--eval-whole]
+[--eval-only] [--show-mapping]
+```
+
+| Argument | Type | Description |
+| ------------------------- | ---------- | ------------------------------------------------------------------------------------------------------------- |
+| `dataset` | positional | Dataset to save annotations to. |
+| `vectors_path_a` | positional | Path to pretrained sense2vec vectors. |
+| `vectors_path_b` | positional | Path to pretrained sense2vec vectors. |
+| `--senses`, `-s` | option | Comma-separated list of senses to limit the selection to. If not set, all senses in the vectors will be used. |
+| `--exclude-senses`, `-es` | option | Comma-separated list of senses to exclude. See `prodigy_recipes.EVAL_EXCLUDE_SENSES` fro the defaults. |
+| `--n-freq`, `-f` | option | Number of most frequent entries to limit to. |
+| `--n-similar`, `-n` | option | Number of similar items to check. Defaults to `10`. |
+| `--batch-size`, `-b` | option | Batch size to use. |
+| `--eval-whole`, `-E` | flag | Evaluate the whole dataset instead of the current session. |
+| `--eval-only`, `-O` | flag | Don't annotate, only evaluate the current dataset. |
+| `--show-mapping`, `-S` | flag | Show which models are option 1 and option 2 in the UI (for debugging). |
+
+```bash
+prodigy sense2vec.eval-ab vectors_eval_sim /path/to/s2v_reddit_2015_md /path/to/s2v_reddit_2019_md --senses NOUN,ORG,PRODUCT
+```
+
+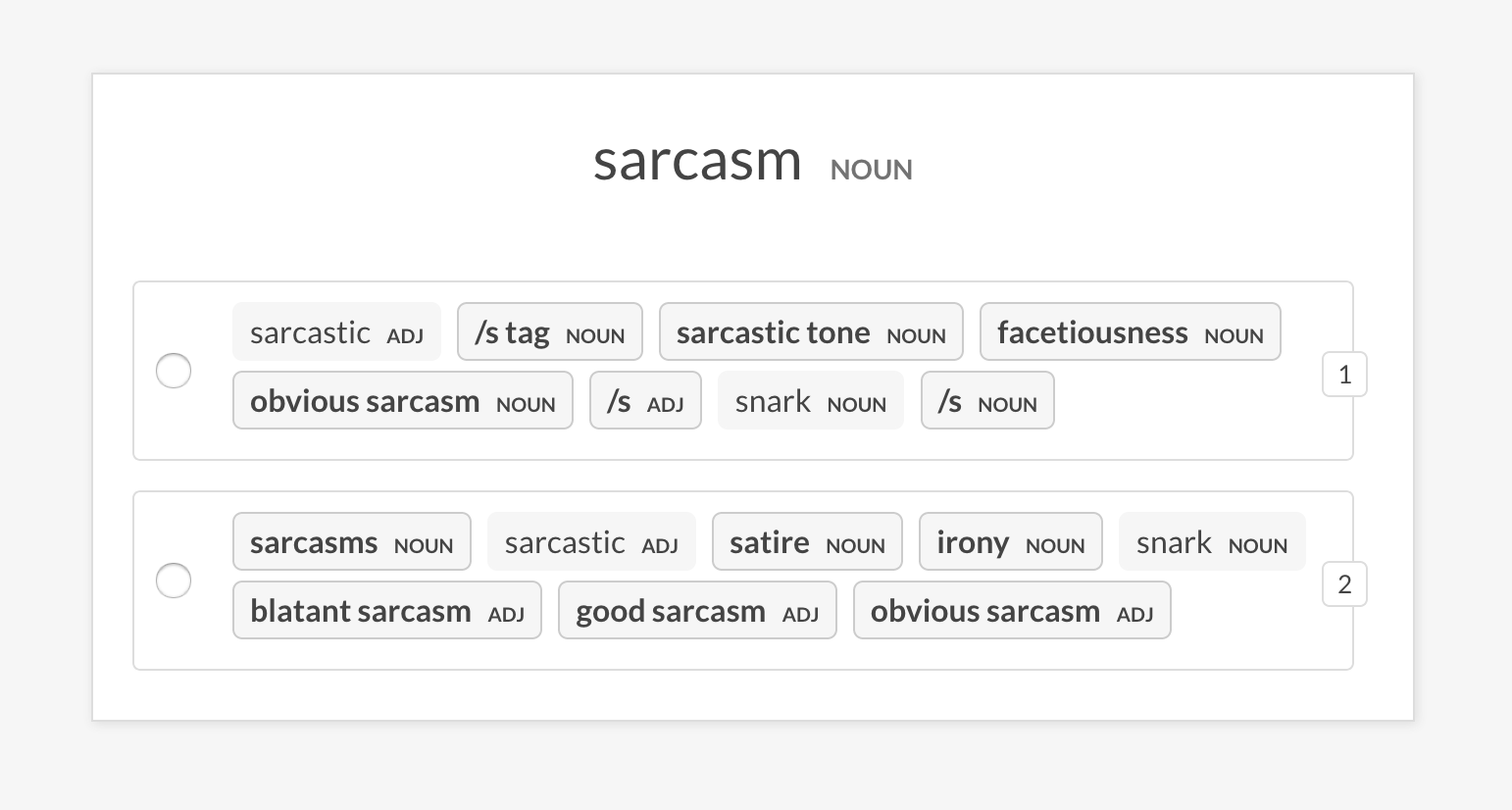
+
+## Pretrained vectors
+
+The pretrained Reddit vectors support the following "senses", either
+part-of-speech tags or entity labels. For more details, see spaCy's
+[annotation scheme overview](https://spacy.io/api/annotation).
+
+| Tag | Description | Examples |
+| ------- | ------------------------- | ------------------------------------ |
+| `ADJ` | adjective | big, old, green |
+| `ADP` | adposition | in, to, during |
+| `ADV` | adverb | very, tomorrow, down, where |
+| `AUX` | auxiliary | is, has (done), will (do) |
+| `CONJ` | conjunction | and, or, but |
+| `DET` | determiner | a, an, the |
+| `INTJ` | interjection | psst, ouch, bravo, hello |
+| `NOUN` | noun | girl, cat, tree, air, beauty |
+| `NUM` | numeral | 1, 2017, one, seventy-seven, MMXIV |
+| `PART` | particle | 's, not |
+| `PRON` | pronoun | I, you, he, she, myself, somebody |
+| `PROPN` | proper noun | Mary, John, London, NATO, HBO |
+| `PUNCT` | punctuation | , ? ( ) |
+| `SCONJ` | subordinating conjunction | if, while, that |
+| `SYM` | symbol | \$, %, =, :), 😝 |
+| `VERB` | verb | run, runs, running, eat, ate, eating |
+
+| Entity Label | Description |
+| ------------- | ---------------------------------------------------- |
+| `PERSON` | People, including fictional. |
+| `NORP` | Nationalities or religious or political groups. |
+| `FACILITY` | Buildings, airports, highways, bridges, etc. |
+| `ORG` | Companies, agencies, institutions, etc. |
+| `GPE` | Countries, cities, states. |
+| `LOC` | Non-GPE locations, mountain ranges, bodies of water. |
+| `PRODUCT` | Objects, vehicles, foods, etc. (Not services.) |
+| `EVENT` | Named hurricanes, battles, wars, sports events, etc. |
+| `WORK_OF_ART` | Titles of books, songs, etc. |
+| `LANGUAGE` | Any named language. |
diff --git a/README.rst b/README.rst
deleted file mode 100644
index 7b94950..0000000
--- a/README.rst
+++ /dev/null
@@ -1,76 +0,0 @@
-sense2vec: Use spaCy to go beyond vanilla word2vec
-**************************************************
-
-Read about sense2vec in our `blog post `_. You can try an online demo of the technology `here `_ and use the open-source `REST server `_.
-
-.. image:: https://travis-ci.org/explosion/sense2vec.svg?branch=master
- :target: https://travis-ci.org/explosion/sense2vec
- :alt: Build Status
-
-.. image:: https://img.shields.io/pypi/v/sense2vec.svg
- :target: https://pypi.python.org/pypi/sense2vec
- :alt: pypi Version
-
-
-Overview
-========
-
-There are three relevant files in this repository:
-
-``bin/merge_text.py``
------------------
-
-This script pre-processes text using spaCy, so that the sense2vec model can be trained using Gensim.
-
-``bin/train_word2vec.py``
----------------------
-
-This script reads a directory of text files, and then trains a word2vec model using Gensim. The script includes its own
-vocabulary counting code, because Gensim's vocabulary count is a bit slow for our large, sparse vocabulary.
-
-``sense2vec/vectors.pyx``
----------------------
-
-To serve the similarity queries, we wrote a small vector-store class in Cython. This made it easier to add an efficient
-cache in front of the service. It also less memory than Gensim's Word2Vec class, as it doesn't hold the keys as Python
-unicode strings.
-
-Similarity queries could be faster, if we had made all vectors contiguous in memory, instead of holding them
-as an array of pointers. However, we wanted to allow a ``.borrow()`` method, so that vectors can be added to the store
-by reference, without copying the data.
-
-Installation
-============
-
-Until there is a PyPI release you can install sense2vec by:
-
-1. cloning the repository
-2. run ``pip install -r requirements.txt``
-3. ``pip install -e .``
-4. install the latest model via ``sputnik --name sense2vec --repository-url http://index.spacy.io install reddit_vectors``
-
-You might also be tempted to simply run ``pip install -e git+git://github.com/spacy-io/sense2vec.git#egg=sense2vec`` instead of steps 1-3, but it expects `Cython `_ to be present.
-
-Usage
-=====
-
-.. code:: python
-
- import sense2vec
- model = sense2vec.load()
- freq, query_vector = model["natural_language_processing|NOUN"]
- model.most_similar(query_vector, n=3)
-
-.. code:: python
-
- (['natural_language_processing|NOUN', 'machine_learning|NOUN', 'computer_vision|NOUN'], )
-
-For additional performance experimental support for BLAS can be enabled by setting the `USE_BLAS` environment variable before installing (e.g. ``USE_BLAS=1 pip install ...``). This requires an up-to-date BLAS/OpenBlas/Atlas installation.
-
-Support
-=======
-
-* CPython 2.6, 2.7, 3.3, 3.4, 3.5 (only 64 bit)
-* OSX
-* Linux
-* Windows
diff --git a/bin/cythonize.py b/bin/cythonize.py
deleted file mode 100755
index 2c18ae8..0000000
--- a/bin/cythonize.py
+++ /dev/null
@@ -1,199 +0,0 @@
-#!/usr/bin/env python
-""" cythonize
-
-Cythonize pyx files into C files as needed.
-
-Usage: cythonize [root_dir]
-
-Default [root_dir] is 'spacy'.
-
-Checks pyx files to see if they have been changed relative to their
-corresponding C files. If they have, then runs cython on these files to
-recreate the C files.
-
-The script thinks that the pyx files have changed relative to the C files
-by comparing hashes stored in a database file.
-
-Simple script to invoke Cython (and Tempita) on all .pyx (.pyx.in)
-files; while waiting for a proper build system. Uses file hashes to
-figure out if rebuild is needed.
-
-For now, this script should be run by developers when changing Cython files
-only, and the resulting C files checked in, so that end-users (and Python-only
-developers) do not get the Cython/Tempita dependencies.
-
-Originally written by Dag Sverre Seljebotn, and copied here from:
-
-https://raw.github.com/dagss/private-scipy-refactor/cythonize/cythonize.py
-
-Note: this script does not check any of the dependent C libraries; it only
-operates on the Cython .pyx files.
-"""
-
-from __future__ import division, print_function, absolute_import
-
-import os
-import re
-import sys
-import hashlib
-import subprocess
-
-HASH_FILE = 'cythonize.dat'
-DEFAULT_ROOT = 'spacy'
-VENDOR = 'spaCy'
-
-# WindowsError is not defined on unix systems
-try:
- WindowsError
-except NameError:
- WindowsError = None
-
-#
-# Rules
-#
-def process_pyx(fromfile, tofile):
- try:
- from Cython.Compiler.Version import version as cython_version
- from distutils.version import LooseVersion
- if LooseVersion(cython_version) < LooseVersion('0.19'):
- raise Exception('Building %s requires Cython >= 0.19' % VENDOR)
-
- except ImportError:
- pass
-
- flags = ['--fast-fail']
- if tofile.endswith('.cpp'):
- flags += ['--cplus']
-
- try:
- try:
- r = subprocess.call(['cython'] + flags + ["-o", tofile, fromfile])
- if r != 0:
- raise Exception('Cython failed')
- except OSError:
- # There are ways of installing Cython that don't result in a cython
- # executable on the path, see gh-2397.
- r = subprocess.call([sys.executable, '-c',
- 'import sys; from Cython.Compiler.Main import '
- 'setuptools_main as main; sys.exit(main())'] + flags +
- ["-o", tofile, fromfile])
- if r != 0:
- raise Exception('Cython failed')
- except OSError:
- raise OSError('Cython needs to be installed')
-
-def process_tempita_pyx(fromfile, tofile):
- try:
- try:
- from Cython import Tempita as tempita
- except ImportError:
- import tempita
- except ImportError:
- raise Exception('Building %s requires Tempita: '
- 'pip install --user Tempita' % VENDOR)
- with open(fromfile, "r") as f:
- tmpl = f.read()
- pyxcontent = tempita.sub(tmpl)
- assert fromfile.endswith('.pyx.in')
- pyxfile = fromfile[:-len('.pyx.in')] + '.pyx'
- with open(pyxfile, "w") as f:
- f.write(pyxcontent)
- process_pyx(pyxfile, tofile)
-
-rules = {
- # fromext : function
- '.pyx' : process_pyx,
- '.pyx.in' : process_tempita_pyx
- }
-#
-# Hash db
-#
-def load_hashes(filename):
- # Return { filename : (sha1 of input, sha1 of output) }
- if os.path.isfile(filename):
- hashes = {}
- with open(filename, 'r') as f:
- for line in f:
- filename, inhash, outhash = line.split()
- hashes[filename] = (inhash, outhash)
- else:
- hashes = {}
- return hashes
-
-def save_hashes(hash_db, filename):
- with open(filename, 'w') as f:
- for key, value in sorted(hash_db.items()):
- f.write("%s %s %s\n" % (key, value[0], value[1]))
-
-def sha1_of_file(filename):
- h = hashlib.sha1()
- with open(filename, "rb") as f:
- h.update(f.read())
- return h.hexdigest()
-
-#
-# Main program
-#
-
-def normpath(path):
- path = path.replace(os.sep, '/')
- if path.startswith('./'):
- path = path[2:]
- return path
-
-def get_hash(frompath, topath):
- from_hash = sha1_of_file(frompath)
- to_hash = sha1_of_file(topath) if os.path.exists(topath) else None
- return (from_hash, to_hash)
-
-def process(path, fromfile, tofile, processor_function, hash_db):
- fullfrompath = os.path.join(path, fromfile)
- fulltopath = os.path.join(path, tofile)
- current_hash = get_hash(fullfrompath, fulltopath)
- if current_hash == hash_db.get(normpath(fullfrompath), None):
- print('%s has not changed' % fullfrompath)
- return
-
- orig_cwd = os.getcwd()
- try:
- os.chdir(path)
- print('Processing %s' % fullfrompath)
- processor_function(fromfile, tofile)
- finally:
- os.chdir(orig_cwd)
- # changed target file, recompute hash
- current_hash = get_hash(fullfrompath, fulltopath)
- # store hash in db
- hash_db[normpath(fullfrompath)] = current_hash
-
-
-def find_process_files(root_dir):
- hash_db = load_hashes(HASH_FILE)
- for cur_dir, dirs, files in os.walk(root_dir):
- for filename in files:
- in_file = os.path.join(cur_dir, filename + ".in")
- if filename.endswith('.pyx') and os.path.isfile(in_file):
- continue
- for fromext, function in rules.items():
- if filename.endswith(fromext):
- toext = ".cpp"
- # with open(os.path.join(cur_dir, filename), 'rb') as f:
- # data = f.read()
- # m = re.search(br"^\s*#\s*distutils:\s*language\s*=\s*c\+\+\s*$", data, re.I|re.M)
- # if m:
- # toext = ".cxx"
- fromfile = filename
- tofile = filename[:-len(fromext)] + toext
- process(cur_dir, fromfile, tofile, function, hash_db)
- save_hashes(hash_db, HASH_FILE)
-
-def main():
- try:
- root_dir = sys.argv[1]
- except IndexError:
- root_dir = DEFAULT_ROOT
- find_process_files(root_dir)
-
-
-if __name__ == '__main__':
- main()
\ No newline at end of file
diff --git a/bin/gensim2sense.py b/bin/gensim2sense.py
deleted file mode 100644
index c6541c2..0000000
--- a/bin/gensim2sense.py
+++ /dev/null
@@ -1,30 +0,0 @@
-from sense2vec.vectors import VectorMap
-from gensim.models import Word2Vec
-import plac
-
-@plac.annotations(
- gensim_model_path=("Location of gensim's .bin file"),
- out_dir=("Location of output directory"),
- min_count=("Min count", "option", "m", int),
-)
-def main(gensim_model_path, out_dir, min_count=None):
- """Convert a gensim.models.Word2Vec file to VectorMap format"""
-
- gensim_model = Word2Vec.load(gensim_model_path)
- vector_map = VectorMap(128)
-
- if min_count is None:
- min_count = gensim_model.min_count
-
- for string in gensim_model.vocab:
- vocab = gensim_model.vocab[string]
- freq, idx = vocab.count, vocab.index
- if freq < min_count:
- continue
- vector = gensim_model.syn0[idx]
- vector_map.borrow(string, freq, vector)
-
- vector_map.save(out_dir)
-
-if __name__ == '__main__':
- plac.call(main)
\ No newline at end of file
diff --git a/bin/merge_text.py b/bin/merge_text.py
deleted file mode 100644
index 8390442..0000000
--- a/bin/merge_text.py
+++ /dev/null
@@ -1,140 +0,0 @@
-from __future__ import print_function, unicode_literals, division
-import io
-import bz2
-import logging
-from toolz import partition
-from os import path
-import os
-import re
-
-import spacy.en
-from preshed.counter import PreshCounter
-from spacy.tokens.doc import Doc
-
-from joblib import Parallel, delayed
-import plac
-try:
- import ujson as json
-except ImportError:
- import json
-
-
-LABELS = {
- 'ENT': 'ENT',
- 'PERSON': 'ENT',
- 'NORP': 'ENT',
- 'FAC': 'ENT',
- 'ORG': 'ENT',
- 'GPE': 'ENT',
- 'LOC': 'ENT',
- 'LAW': 'ENT',
- 'PRODUCT': 'ENT',
- 'EVENT': 'ENT',
- 'WORK_OF_ART': 'ENT',
- 'LANGUAGE': 'ENT',
- 'DATE': 'DATE',
- 'TIME': 'TIME',
- 'PERCENT': 'PERCENT',
- 'MONEY': 'MONEY',
- 'QUANTITY': 'QUANTITY',
- 'ORDINAL': 'ORDINAL',
- 'CARDINAL': 'CARDINAL'
-}
-
-
-def parallelize(func, iterator, n_jobs, extra):
- extra = tuple(extra)
- return Parallel(n_jobs=n_jobs)(delayed(func)(*(item + extra)) for item in iterator)
-
-
-def iter_comments(loc):
- with bz2.BZ2File(loc) as file_:
- for i, line in enumerate(file_):
- yield ujson.loads(line)['body']
-
-
-pre_format_re = re.compile(r'^[\`\*\~]')
-post_format_re = re.compile(r'[\`\*\~]$')
-url_re = re.compile(r'\[([^]]+)\]\(%%URL\)')
-link_re = re.compile(r'\[([^]]+)\]\(https?://[^\)]+\)')
-def strip_meta(text):
- text = link_re.sub(r'\1', text)
- text = text.replace('>', '>').replace('<', '<')
- text = pre_format_re.sub('', text)
- text = post_format_re.sub('', text)
- return text
-
-
-def load_and_transform(batch_id, in_loc, out_dir):
- out_loc = path.join(out_dir, '%d.txt' % batch_id)
- if path.exists(out_loc):
- return None
- print('Batch', batch_id)
- nlp = spacy.en.English(parser=False, tagger=False, matcher=False, entity=False)
- with io.open(out_loc, 'w', encoding='utf8') as out_file:
- with io.open(in_loc, 'rb') as in_file:
- for byte_string in Doc.read_bytes(in_file):
- doc = Doc(nlp.vocab).from_bytes(byte_string)
- doc.is_parsed = True
- out_file.write(transform_doc(doc))
-
-
-def parse_and_transform(batch_id, input_, out_dir):
- out_loc = path.join(out_dir, '%d.txt' % batch_id)
- if path.exists(out_loc):
- return None
- print('Batch', batch_id)
- nlp = spacy.en.English()
- nlp.matcher = None
- with io.open(out_loc, 'w', encoding='utf8') as file_:
- for text in input_:
- file_.write(transform_doc(nlp(strip_meta(text))))
-
-
-def transform_doc(doc):
- for ent in doc.ents:
- ent.merge(ent.root.tag_, ent.text, LABELS[ent.label_])
- for np in doc.noun_chunks:
- while len(np) > 1 and np[0].dep_ not in ('advmod', 'amod', 'compound'):
- np = np[1:]
- np.merge(np.root.tag_, np.text, np.root.ent_type_)
- strings = []
- for sent in doc.sents:
- if sent.text.strip():
- strings.append(' '.join(represent_word(w) for w in sent if not w.is_space))
- if strings:
- return '\n'.join(strings) + '\n'
- else:
- return ''
-
-
-def represent_word(word):
- if word.like_url:
- return '%%URL|X'
- text = re.sub(r'\s', '_', word.text)
- tag = LABELS.get(word.ent_type_, word.pos_)
- if not tag:
- tag = '?'
- return text + '|' + tag
-
-
-@plac.annotations(
- in_loc=("Location of input file"),
- out_dir=("Location of input file"),
- n_workers=("Number of workers", "option", "n", int),
- load_parses=("Load parses from binary", "flag", "b"),
-)
-def main(in_loc, out_dir, n_workers=4, load_parses=False):
- if not path.exists(out_dir):
- path.join(out_dir)
- if load_parses:
- jobs = [path.join(in_loc, fn) for fn in os.listdir(in_loc)]
- do_work = load_and_transform
- else:
- jobs = partition(200000, iter_comments(in_loc))
- do_work = parse_and_transform
- parallelize(do_work, enumerate(jobs), n_workers, [out_dir])
-
-
-if __name__ == '__main__':
- plac.call(main)
diff --git a/bin/push-tag.sh b/bin/push-tag.sh
new file mode 100755
index 0000000..ae2dced
--- /dev/null
+++ b/bin/push-tag.sh
@@ -0,0 +1,15 @@
+#!/usr/bin/env bash
+
+set -e
+
+# Insist repository is clean
+git diff-index --quiet HEAD
+
+git checkout $1
+git pull origin $1
+git push origin $1
+
+version=$(grep "version = " setup.cfg)
+version=${version/version = }
+git tag "v$version"
+git push origin "v$version"
diff --git a/bin/train_word2vec.py b/bin/train_word2vec.py
deleted file mode 100644
index 78245dd..0000000
--- a/bin/train_word2vec.py
+++ /dev/null
@@ -1,110 +0,0 @@
-from __future__ import print_function, unicode_literals, division
-import io
-import bz2
-import logging
-from os import path
-import os
-import random
-from collections import defaultdict
-
-import plac
-try:
- import ujson as json
-except ImportError:
- import json
-from gensim.models import Word2Vec
-from preshed.counter import PreshCounter
-from spacy.strings import hash_string
-
-logger = logging.getLogger(__name__)
-
-
-class Corpus(object):
- def __init__(self, directory, min_freq=10):
- self.directory = directory
- self.counts = PreshCounter()
- self.strings = {}
- self.min_freq = min_freq
-
- def count_doc(self, words):
- # Get counts for this document
- doc_counts = PreshCounter()
- doc_strings = {}
- for word in words:
- key = hash_string(word)
- doc_counts.inc(key, 1)
- doc_strings[key] = word
-
- n = 0
- for key, count in doc_counts:
- self.counts.inc(key, count)
- # TODO: Why doesn't inc return this? =/
- corpus_count = self.counts[key]
- # Remember the string when we exceed min count
- if corpus_count >= self.min_freq and (corpus_count - count) < self.min_freq:
- self.strings[key] = doc_strings[key]
- n += count
- return n
-
- def __iter__(self):
- for text_loc in iter_dir(self.directory):
- with io.open(text_loc, 'r', encoding='utf8') as file_:
- sent_strs = list(file_)
- random.shuffle(sent_strs)
- for sent_str in sent_strs:
- yield sent_str.split()
-
-
-def iter_dir(loc):
- for fn in os.listdir(loc):
- if path.isdir(path.join(loc, fn)):
- for sub in os.listdir(path.join(loc, fn)):
- yield path.join(loc, fn, sub)
- else:
- yield path.join(loc, fn)
-
-@plac.annotations(
- in_dir=("Location of input directory"),
- out_loc=("Location of output file"),
- n_workers=("Number of workers", "option", "n", int),
- size=("Dimension of the word vectors", "option", "d", int),
- window=("Context window size", "option", "w", int),
- min_count=("Min count", "option", "m", int),
- negative=("Number of negative samples", "option", "g", int),
- nr_iter=("Number of iterations", "option", "i", int),
-)
-def main(in_dir, out_loc, negative=5, n_workers=4, window=5, size=128, min_count=10, nr_iter=2):
- logging.basicConfig(format='%(asctime)s : %(levelname)s : %(message)s', level=logging.INFO)
- model = Word2Vec(
- size=size,
- window=window,
- min_count=min_count,
- workers=n_workers,
- sample=1e-5,
- negative=negative
- )
- corpus = Corpus(in_dir)
- total_words = 0
- total_sents = 0
- for text_no, text_loc in enumerate(iter_dir(corpus.directory)):
- with io.open(text_loc, 'r', encoding='utf8') as file_:
- text = file_.read()
- total_sents += text.count('\n')
- total_words += corpus.count_doc(text.split())
- logger.info("PROGRESS: at batch #%i, processed %i words, keeping %i word types",
- text_no, total_words, len(corpus.strings))
- model.corpus_count = total_sents
- model.raw_vocab = defaultdict(int)
- for key, string in corpus.strings.items():
- model.raw_vocab[string] = corpus.counts[key]
- model.scale_vocab()
- model.finalize_vocab()
- model.iter = nr_iter
- model.train(corpus)
-
- model.save(out_loc)
-
-
-if __name__ == '__main__':
- plac.call(main)
-
diff --git a/buildbot.json b/buildbot.json
deleted file mode 100644
index d67fa4a..0000000
--- a/buildbot.json
+++ /dev/null
@@ -1,26 +0,0 @@
-{
- "build": {
- "sdist": [
- "pip install -r requirements.txt",
- "pip install \"numpy<1.8\"",
- "python setup.py sdist"
- ],
- "install": [
- "pip install -v source.tar.gz"
- ],
- "wheel": [
- "python untar.py source.tar.gz .",
- "pip install \"numpy<1.8\"",
- "python setup.py bdist_wheel",
- "python cpdist.py dist"
- ]
- },
- "test": {
- "after": ["install", "wheel"],
- "run": [
- "python -m sense2vec.download --force"
- ],
- "package": "sense2vec",
- "args": "--tb=native -x --models"
- }
-}
diff --git a/include/cblas_shim.h b/include/cblas_shim.h
deleted file mode 100644
index 96c9b90..0000000
--- a/include/cblas_shim.h
+++ /dev/null
@@ -1,76 +0,0 @@
-#ifdef __cplusplus
-extern "C"
-{
-#endif // __cplusplus
-#ifdef USE_BLAS
-#include
-
-int _use_blas()
-{
- return 1;
-}
-#else // USE_BLAS
-#include
-
-#if defined(_MSC_VER)
-#define ALIGNAS(byte_alignment) __declspec(align(byte_alignment))
-#elif defined(__GNUC__)
-#define ALIGNAS(byte_alignment) __attribute__((aligned(byte_alignment)))
-#endif
-
-float cblas_snrm2(const int N, const float *m1, const int incX)
-{
- if (N % 4 != 0) {
- fprintf(stderr, "cblas_snrm2() expects N to be a multiple of 4.\n");
- exit(EXIT_FAILURE);
- }
-
- float norm = 0;
- ALIGNAS(16) float z[4];
- __m128 X;
- __m128 Z = _mm_setzero_ps();
-
- for (int i=0; i 1000
-#pragma once
-#endif
-
-#if _MSC_VER >= 1600 // [
-#include
-#else // ] _MSC_VER >= 1600 [
-
-#include
-
-// For Visual Studio 6 in C++ mode and for many Visual Studio versions when
-// compiling for ARM we should wrap include with 'extern "C++" {}'
-// or compiler give many errors like this:
-// error C2733: second C linkage of overloaded function 'wmemchr' not allowed
-#ifdef __cplusplus
-extern "C" {
-#endif
-# include
-#ifdef __cplusplus
-}
-#endif
-
-// Define _W64 macros to mark types changing their size, like intptr_t.
-#ifndef _W64
-# if !defined(__midl) && (defined(_X86_) || defined(_M_IX86)) && _MSC_VER >= 1300
-# define _W64 __w64
-# else
-# define _W64
-# endif
-#endif
-
-
-// 7.18.1 Integer types
-
-// 7.18.1.1 Exact-width integer types
-
-// Visual Studio 6 and Embedded Visual C++ 4 doesn't
-// realize that, e.g. char has the same size as __int8
-// so we give up on __intX for them.
-#if (_MSC_VER < 1300)
- typedef signed char int8_t;
- typedef signed short int16_t;
- typedef signed int int32_t;
- typedef unsigned char uint8_t;
- typedef unsigned short uint16_t;
- typedef unsigned int uint32_t;
-#else
- typedef signed __int8 int8_t;
- typedef signed __int16 int16_t;
- typedef signed __int32 int32_t;
- typedef unsigned __int8 uint8_t;
- typedef unsigned __int16 uint16_t;
- typedef unsigned __int32 uint32_t;
-#endif
-typedef signed __int64 int64_t;
-typedef unsigned __int64 uint64_t;
-
-
-// 7.18.1.2 Minimum-width integer types
-typedef int8_t int_least8_t;
-typedef int16_t int_least16_t;
-typedef int32_t int_least32_t;
-typedef int64_t int_least64_t;
-typedef uint8_t uint_least8_t;
-typedef uint16_t uint_least16_t;
-typedef uint32_t uint_least32_t;
-typedef uint64_t uint_least64_t;
-
-// 7.18.1.3 Fastest minimum-width integer types
-typedef int8_t int_fast8_t;
-typedef int16_t int_fast16_t;
-typedef int32_t int_fast32_t;
-typedef int64_t int_fast64_t;
-typedef uint8_t uint_fast8_t;
-typedef uint16_t uint_fast16_t;
-typedef uint32_t uint_fast32_t;
-typedef uint64_t uint_fast64_t;
-
-// 7.18.1.4 Integer types capable of holding object pointers
-#ifdef _WIN64 // [
- typedef signed __int64 intptr_t;
- typedef unsigned __int64 uintptr_t;
-#else // _WIN64 ][
- typedef _W64 signed int intptr_t;
- typedef _W64 unsigned int uintptr_t;
-#endif // _WIN64 ]
-
-// 7.18.1.5 Greatest-width integer types
-typedef int64_t intmax_t;
-typedef uint64_t uintmax_t;
-
-
-// 7.18.2 Limits of specified-width integer types
-
-#if !defined(__cplusplus) || defined(__STDC_LIMIT_MACROS) // [ See footnote 220 at page 257 and footnote 221 at page 259
-
-// 7.18.2.1 Limits of exact-width integer types
-#define INT8_MIN ((int8_t)_I8_MIN)
-#define INT8_MAX _I8_MAX
-#define INT16_MIN ((int16_t)_I16_MIN)
-#define INT16_MAX _I16_MAX
-#define INT32_MIN ((int32_t)_I32_MIN)
-#define INT32_MAX _I32_MAX
-#define INT64_MIN ((int64_t)_I64_MIN)
-#define INT64_MAX _I64_MAX
-#define UINT8_MAX _UI8_MAX
-#define UINT16_MAX _UI16_MAX
-#define UINT32_MAX _UI32_MAX
-#define UINT64_MAX _UI64_MAX
-
-// 7.18.2.2 Limits of minimum-width integer types
-#define INT_LEAST8_MIN INT8_MIN
-#define INT_LEAST8_MAX INT8_MAX
-#define INT_LEAST16_MIN INT16_MIN
-#define INT_LEAST16_MAX INT16_MAX
-#define INT_LEAST32_MIN INT32_MIN
-#define INT_LEAST32_MAX INT32_MAX
-#define INT_LEAST64_MIN INT64_MIN
-#define INT_LEAST64_MAX INT64_MAX
-#define UINT_LEAST8_MAX UINT8_MAX
-#define UINT_LEAST16_MAX UINT16_MAX
-#define UINT_LEAST32_MAX UINT32_MAX
-#define UINT_LEAST64_MAX UINT64_MAX
-
-// 7.18.2.3 Limits of fastest minimum-width integer types
-#define INT_FAST8_MIN INT8_MIN
-#define INT_FAST8_MAX INT8_MAX
-#define INT_FAST16_MIN INT16_MIN
-#define INT_FAST16_MAX INT16_MAX
-#define INT_FAST32_MIN INT32_MIN
-#define INT_FAST32_MAX INT32_MAX
-#define INT_FAST64_MIN INT64_MIN
-#define INT_FAST64_MAX INT64_MAX
-#define UINT_FAST8_MAX UINT8_MAX
-#define UINT_FAST16_MAX UINT16_MAX
-#define UINT_FAST32_MAX UINT32_MAX
-#define UINT_FAST64_MAX UINT64_MAX
-
-// 7.18.2.4 Limits of integer types capable of holding object pointers
-#ifdef _WIN64 // [
-# define INTPTR_MIN INT64_MIN
-# define INTPTR_MAX INT64_MAX
-# define UINTPTR_MAX UINT64_MAX
-#else // _WIN64 ][
-# define INTPTR_MIN INT32_MIN
-# define INTPTR_MAX INT32_MAX
-# define UINTPTR_MAX UINT32_MAX
-#endif // _WIN64 ]
-
-// 7.18.2.5 Limits of greatest-width integer types
-#define INTMAX_MIN INT64_MIN
-#define INTMAX_MAX INT64_MAX
-#define UINTMAX_MAX UINT64_MAX
-
-// 7.18.3 Limits of other integer types
-
-#ifdef _WIN64 // [
-# define PTRDIFF_MIN _I64_MIN
-# define PTRDIFF_MAX _I64_MAX
-#else // _WIN64 ][
-# define PTRDIFF_MIN _I32_MIN
-# define PTRDIFF_MAX _I32_MAX
-#endif // _WIN64 ]
-
-#define SIG_ATOMIC_MIN INT_MIN
-#define SIG_ATOMIC_MAX INT_MAX
-
-#ifndef SIZE_MAX // [
-# ifdef _WIN64 // [
-# define SIZE_MAX _UI64_MAX
-# else // _WIN64 ][
-# define SIZE_MAX _UI32_MAX
-# endif // _WIN64 ]
-#endif // SIZE_MAX ]
-
-// WCHAR_MIN and WCHAR_MAX are also defined in
-#ifndef WCHAR_MIN // [
-# define WCHAR_MIN 0
-#endif // WCHAR_MIN ]
-#ifndef WCHAR_MAX // [
-# define WCHAR_MAX _UI16_MAX
-#endif // WCHAR_MAX ]
-
-#define WINT_MIN 0
-#define WINT_MAX _UI16_MAX
-
-#endif // __STDC_LIMIT_MACROS ]
-
-
-// 7.18.4 Limits of other integer types
-
-#if !defined(__cplusplus) || defined(__STDC_CONSTANT_MACROS) // [ See footnote 224 at page 260
-
-// 7.18.4.1 Macros for minimum-width integer constants
-
-#define INT8_C(val) val##i8
-#define INT16_C(val) val##i16
-#define INT32_C(val) val##i32
-#define INT64_C(val) val##i64
-
-#define UINT8_C(val) val##ui8
-#define UINT16_C(val) val##ui16
-#define UINT32_C(val) val##ui32
-#define UINT64_C(val) val##ui64
-
-// 7.18.4.2 Macros for greatest-width integer constants
-// These #ifndef's are needed to prevent collisions with .
-// Check out Issue 9 for the details.
-#ifndef INTMAX_C // [
-# define INTMAX_C INT64_C
-#endif // INTMAX_C ]
-#ifndef UINTMAX_C // [
-# define UINTMAX_C UINT64_C
-#endif // UINTMAX_C ]
-
-#endif // __STDC_CONSTANT_MACROS ]
-
-#endif // _MSC_VER >= 1600 ]
-
-#endif // _MSC_STDINT_H_ ]
diff --git a/include/murmurhash/MurmurHash2.h b/include/murmurhash/MurmurHash2.h
deleted file mode 100644
index 6d7ccf4..0000000
--- a/include/murmurhash/MurmurHash2.h
+++ /dev/null
@@ -1,22 +0,0 @@
-//-----------------------------------------------------------------------------
-// MurmurHash2 was written by Austin Appleby, and is placed in the public
-// domain. The author hereby disclaims copyright to this source code.
-
-#ifndef _MURMURHASH2_H_
-#define _MURMURHASH2_H_
-
-#include
-
-//-----------------------------------------------------------------------------
-
-uint32_t MurmurHash2 ( const void * key, int len, uint32_t seed );
-uint64_t MurmurHash64A ( const void * key, int len, uint64_t seed );
-uint64_t MurmurHash64B ( const void * key, int len, uint64_t seed );
-uint32_t MurmurHash2A ( const void * key, int len, uint32_t seed );
-uint32_t MurmurHashNeutral2 ( const void * key, int len, uint32_t seed );
-uint32_t MurmurHashAligned2 ( const void * key, int len, uint32_t seed );
-
-//-----------------------------------------------------------------------------
-
-#endif // _MURMURHASH2_H_
-
diff --git a/include/murmurhash/MurmurHash3.h b/include/murmurhash/MurmurHash3.h
deleted file mode 100644
index 9b4c3c9..0000000
--- a/include/murmurhash/MurmurHash3.h
+++ /dev/null
@@ -1,28 +0,0 @@
-//-----------------------------------------------------------------------------
-// MurmurHash3 was written by Austin Appleby, and is placed in the public
-// domain. The author hereby disclaims copyright to this source code.
-
-#ifndef _MURMURHASH3_H_
-#define _MURMURHASH3_H_
-
-#include
-
-//-----------------------------------------------------------------------------
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-
-void MurmurHash3_x86_32 ( const void * key, int len, uint32_t seed, void * out );
-
-void MurmurHash3_x86_128 ( const void * key, int len, uint32_t seed, void * out );
-
-void MurmurHash3_x64_128 ( const void * key, int len, uint32_t seed, void * out );
-
-#ifdef __cplusplus
-}
-#endif
-
-//-----------------------------------------------------------------------------
-
-#endif // _MURMURHASH3_H_
diff --git a/include/numpy/__multiarray_api.h b/include/numpy/__multiarray_api.h
deleted file mode 100644
index c949d73..0000000
--- a/include/numpy/__multiarray_api.h
+++ /dev/null
@@ -1,1686 +0,0 @@
-
-#ifdef _MULTIARRAYMODULE
-
-typedef struct {
- PyObject_HEAD
- npy_bool obval;
-} PyBoolScalarObject;
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
-extern NPY_NO_EXPORT PyTypeObject PyArrayMapIter_Type;
-extern NPY_NO_EXPORT PyTypeObject PyArrayNeighborhoodIter_Type;
-extern NPY_NO_EXPORT PyBoolScalarObject _PyArrayScalar_BoolValues[2];
-#else
-NPY_NO_EXPORT PyTypeObject PyArrayMapIter_Type;
-NPY_NO_EXPORT PyTypeObject PyArrayNeighborhoodIter_Type;
-NPY_NO_EXPORT PyBoolScalarObject _PyArrayScalar_BoolValues[2];
-#endif
-
-NPY_NO_EXPORT unsigned int PyArray_GetNDArrayCVersion \
- (void);
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyBigArray_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyBigArray_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyArray_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyArray_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyArrayDescr_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyArrayDescr_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyArrayFlags_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyArrayFlags_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyArrayIter_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyArrayIter_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyArrayMultiIter_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyArrayMultiIter_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT int NPY_NUMUSERTYPES;
-#else
- NPY_NO_EXPORT int NPY_NUMUSERTYPES;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyBoolArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyBoolArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
-extern NPY_NO_EXPORT PyBoolScalarObject _PyArrayScalar_BoolValues[2];
-#else
-NPY_NO_EXPORT PyBoolScalarObject _PyArrayScalar_BoolValues[2];
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyGenericArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyGenericArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyNumberArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyNumberArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyIntegerArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyIntegerArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PySignedIntegerArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PySignedIntegerArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyUnsignedIntegerArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyUnsignedIntegerArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyInexactArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyInexactArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyFloatingArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyFloatingArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyComplexFloatingArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyComplexFloatingArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyFlexibleArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyFlexibleArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyCharacterArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyCharacterArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyByteArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyByteArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyShortArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyShortArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyIntArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyIntArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyLongArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyLongArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyLongLongArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyLongLongArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyUByteArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyUByteArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyUShortArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyUShortArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyUIntArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyUIntArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyULongArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyULongArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyULongLongArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyULongLongArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyFloatArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyFloatArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyDoubleArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyDoubleArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyLongDoubleArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyLongDoubleArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyCFloatArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyCFloatArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyCDoubleArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyCDoubleArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyCLongDoubleArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyCLongDoubleArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyObjectArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyObjectArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyStringArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyStringArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyUnicodeArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyUnicodeArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyVoidArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyVoidArrType_Type;
-#endif
-
-NPY_NO_EXPORT int PyArray_SetNumericOps \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_GetNumericOps \
- (void);
-NPY_NO_EXPORT int PyArray_INCREF \
- (PyArrayObject *);
-NPY_NO_EXPORT int PyArray_XDECREF \
- (PyArrayObject *);
-NPY_NO_EXPORT void PyArray_SetStringFunction \
- (PyObject *, int);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrFromType \
- (int);
-NPY_NO_EXPORT PyObject * PyArray_TypeObjectFromType \
- (int);
-NPY_NO_EXPORT char * PyArray_Zero \
- (PyArrayObject *);
-NPY_NO_EXPORT char * PyArray_One \
- (PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_CastToType \
- (PyArrayObject *, PyArray_Descr *, int);
-NPY_NO_EXPORT int PyArray_CastTo \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT int PyArray_CastAnyTo \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT int PyArray_CanCastSafely \
- (int, int);
-NPY_NO_EXPORT npy_bool PyArray_CanCastTo \
- (PyArray_Descr *, PyArray_Descr *);
-NPY_NO_EXPORT int PyArray_ObjectType \
- (PyObject *, int);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrFromObject \
- (PyObject *, PyArray_Descr *);
-NPY_NO_EXPORT PyArrayObject ** PyArray_ConvertToCommonType \
- (PyObject *, int *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrFromScalar \
- (PyObject *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrFromTypeObject \
- (PyObject *);
-NPY_NO_EXPORT npy_intp PyArray_Size \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_Scalar \
- (void *, PyArray_Descr *, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_FromScalar \
- (PyObject *, PyArray_Descr *);
-NPY_NO_EXPORT void PyArray_ScalarAsCtype \
- (PyObject *, void *);
-NPY_NO_EXPORT int PyArray_CastScalarToCtype \
- (PyObject *, void *, PyArray_Descr *);
-NPY_NO_EXPORT int PyArray_CastScalarDirect \
- (PyObject *, PyArray_Descr *, void *, int);
-NPY_NO_EXPORT PyObject * PyArray_ScalarFromObject \
- (PyObject *);
-NPY_NO_EXPORT PyArray_VectorUnaryFunc * PyArray_GetCastFunc \
- (PyArray_Descr *, int);
-NPY_NO_EXPORT PyObject * PyArray_FromDims \
- (int, int *, int);
-NPY_NO_EXPORT PyObject * PyArray_FromDimsAndDataAndDescr \
- (int, int *, PyArray_Descr *, char *);
-NPY_NO_EXPORT PyObject * PyArray_FromAny \
- (PyObject *, PyArray_Descr *, int, int, int, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_EnsureArray \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_EnsureAnyArray \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_FromFile \
- (FILE *, PyArray_Descr *, npy_intp, char *);
-NPY_NO_EXPORT PyObject * PyArray_FromString \
- (char *, npy_intp, PyArray_Descr *, npy_intp, char *);
-NPY_NO_EXPORT PyObject * PyArray_FromBuffer \
- (PyObject *, PyArray_Descr *, npy_intp, npy_intp);
-NPY_NO_EXPORT PyObject * PyArray_FromIter \
- (PyObject *, PyArray_Descr *, npy_intp);
-NPY_NO_EXPORT PyObject * PyArray_Return \
- (PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_GetField \
- (PyArrayObject *, PyArray_Descr *, int);
-NPY_NO_EXPORT int PyArray_SetField \
- (PyArrayObject *, PyArray_Descr *, int, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_Byteswap \
- (PyArrayObject *, npy_bool);
-NPY_NO_EXPORT PyObject * PyArray_Resize \
- (PyArrayObject *, PyArray_Dims *, int, NPY_ORDER);
-NPY_NO_EXPORT int PyArray_MoveInto \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT int PyArray_CopyInto \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT int PyArray_CopyAnyInto \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT int PyArray_CopyObject \
- (PyArrayObject *, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_NewCopy \
- (PyArrayObject *, NPY_ORDER);
-NPY_NO_EXPORT PyObject * PyArray_ToList \
- (PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_ToString \
- (PyArrayObject *, NPY_ORDER);
-NPY_NO_EXPORT int PyArray_ToFile \
- (PyArrayObject *, FILE *, char *, char *);
-NPY_NO_EXPORT int PyArray_Dump \
- (PyObject *, PyObject *, int);
-NPY_NO_EXPORT PyObject * PyArray_Dumps \
- (PyObject *, int);
-NPY_NO_EXPORT int PyArray_ValidType \
- (int);
-NPY_NO_EXPORT void PyArray_UpdateFlags \
- (PyArrayObject *, int);
-NPY_NO_EXPORT PyObject * PyArray_New \
- (PyTypeObject *, int, npy_intp *, int, npy_intp *, void *, int, int, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_NewFromDescr \
- (PyTypeObject *, PyArray_Descr *, int, npy_intp *, npy_intp *, void *, int, PyObject *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrNew \
- (PyArray_Descr *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrNewFromType \
- (int);
-NPY_NO_EXPORT double PyArray_GetPriority \
- (PyObject *, double);
-NPY_NO_EXPORT PyObject * PyArray_IterNew \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_MultiIterNew \
- (int, ...);
-NPY_NO_EXPORT int PyArray_PyIntAsInt \
- (PyObject *);
-NPY_NO_EXPORT npy_intp PyArray_PyIntAsIntp \
- (PyObject *);
-NPY_NO_EXPORT int PyArray_Broadcast \
- (PyArrayMultiIterObject *);
-NPY_NO_EXPORT void PyArray_FillObjectArray \
- (PyArrayObject *, PyObject *);
-NPY_NO_EXPORT int PyArray_FillWithScalar \
- (PyArrayObject *, PyObject *);
-NPY_NO_EXPORT npy_bool PyArray_CheckStrides \
- (int, int, npy_intp, npy_intp, npy_intp *, npy_intp *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_DescrNewByteorder \
- (PyArray_Descr *, char);
-NPY_NO_EXPORT PyObject * PyArray_IterAllButAxis \
- (PyObject *, int *);
-NPY_NO_EXPORT PyObject * PyArray_CheckFromAny \
- (PyObject *, PyArray_Descr *, int, int, int, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_FromArray \
- (PyArrayObject *, PyArray_Descr *, int);
-NPY_NO_EXPORT PyObject * PyArray_FromInterface \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_FromStructInterface \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_FromArrayAttr \
- (PyObject *, PyArray_Descr *, PyObject *);
-NPY_NO_EXPORT NPY_SCALARKIND PyArray_ScalarKind \
- (int, PyArrayObject **);
-NPY_NO_EXPORT int PyArray_CanCoerceScalar \
- (int, int, NPY_SCALARKIND);
-NPY_NO_EXPORT PyObject * PyArray_NewFlagsObject \
- (PyObject *);
-NPY_NO_EXPORT npy_bool PyArray_CanCastScalar \
- (PyTypeObject *, PyTypeObject *);
-NPY_NO_EXPORT int PyArray_CompareUCS4 \
- (npy_ucs4 *, npy_ucs4 *, size_t);
-NPY_NO_EXPORT int PyArray_RemoveSmallest \
- (PyArrayMultiIterObject *);
-NPY_NO_EXPORT int PyArray_ElementStrides \
- (PyObject *);
-NPY_NO_EXPORT void PyArray_Item_INCREF \
- (char *, PyArray_Descr *);
-NPY_NO_EXPORT void PyArray_Item_XDECREF \
- (char *, PyArray_Descr *);
-NPY_NO_EXPORT PyObject * PyArray_FieldNames \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_Transpose \
- (PyArrayObject *, PyArray_Dims *);
-NPY_NO_EXPORT PyObject * PyArray_TakeFrom \
- (PyArrayObject *, PyObject *, int, PyArrayObject *, NPY_CLIPMODE);
-NPY_NO_EXPORT PyObject * PyArray_PutTo \
- (PyArrayObject *, PyObject*, PyObject *, NPY_CLIPMODE);
-NPY_NO_EXPORT PyObject * PyArray_PutMask \
- (PyArrayObject *, PyObject*, PyObject*);
-NPY_NO_EXPORT PyObject * PyArray_Repeat \
- (PyArrayObject *, PyObject *, int);
-NPY_NO_EXPORT PyObject * PyArray_Choose \
- (PyArrayObject *, PyObject *, PyArrayObject *, NPY_CLIPMODE);
-NPY_NO_EXPORT int PyArray_Sort \
- (PyArrayObject *, int, NPY_SORTKIND);
-NPY_NO_EXPORT PyObject * PyArray_ArgSort \
- (PyArrayObject *, int, NPY_SORTKIND);
-NPY_NO_EXPORT PyObject * PyArray_SearchSorted \
- (PyArrayObject *, PyObject *, NPY_SEARCHSIDE, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_ArgMax \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_ArgMin \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Reshape \
- (PyArrayObject *, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_Newshape \
- (PyArrayObject *, PyArray_Dims *, NPY_ORDER);
-NPY_NO_EXPORT PyObject * PyArray_Squeeze \
- (PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_View \
- (PyArrayObject *, PyArray_Descr *, PyTypeObject *);
-NPY_NO_EXPORT PyObject * PyArray_SwapAxes \
- (PyArrayObject *, int, int);
-NPY_NO_EXPORT PyObject * PyArray_Max \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Min \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Ptp \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Mean \
- (PyArrayObject *, int, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Trace \
- (PyArrayObject *, int, int, int, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Diagonal \
- (PyArrayObject *, int, int, int);
-NPY_NO_EXPORT PyObject * PyArray_Clip \
- (PyArrayObject *, PyObject *, PyObject *, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Conjugate \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Nonzero \
- (PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Std \
- (PyArrayObject *, int, int, PyArrayObject *, int);
-NPY_NO_EXPORT PyObject * PyArray_Sum \
- (PyArrayObject *, int, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_CumSum \
- (PyArrayObject *, int, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Prod \
- (PyArrayObject *, int, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_CumProd \
- (PyArrayObject *, int, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_All \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Any \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Compress \
- (PyArrayObject *, PyObject *, int, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_Flatten \
- (PyArrayObject *, NPY_ORDER);
-NPY_NO_EXPORT PyObject * PyArray_Ravel \
- (PyArrayObject *, NPY_ORDER);
-NPY_NO_EXPORT npy_intp PyArray_MultiplyList \
- (npy_intp *, int);
-NPY_NO_EXPORT int PyArray_MultiplyIntList \
- (int *, int);
-NPY_NO_EXPORT void * PyArray_GetPtr \
- (PyArrayObject *, npy_intp*);
-NPY_NO_EXPORT int PyArray_CompareLists \
- (npy_intp *, npy_intp *, int);
-NPY_NO_EXPORT int PyArray_AsCArray \
- (PyObject **, void *, npy_intp *, int, PyArray_Descr*);
-NPY_NO_EXPORT int PyArray_As1D \
- (PyObject **, char **, int *, int);
-NPY_NO_EXPORT int PyArray_As2D \
- (PyObject **, char ***, int *, int *, int);
-NPY_NO_EXPORT int PyArray_Free \
- (PyObject *, void *);
-NPY_NO_EXPORT int PyArray_Converter \
- (PyObject *, PyObject **);
-NPY_NO_EXPORT int PyArray_IntpFromSequence \
- (PyObject *, npy_intp *, int);
-NPY_NO_EXPORT PyObject * PyArray_Concatenate \
- (PyObject *, int);
-NPY_NO_EXPORT PyObject * PyArray_InnerProduct \
- (PyObject *, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_MatrixProduct \
- (PyObject *, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_CopyAndTranspose \
- (PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_Correlate \
- (PyObject *, PyObject *, int);
-NPY_NO_EXPORT int PyArray_TypestrConvert \
- (int, int);
-NPY_NO_EXPORT int PyArray_DescrConverter \
- (PyObject *, PyArray_Descr **);
-NPY_NO_EXPORT int PyArray_DescrConverter2 \
- (PyObject *, PyArray_Descr **);
-NPY_NO_EXPORT int PyArray_IntpConverter \
- (PyObject *, PyArray_Dims *);
-NPY_NO_EXPORT int PyArray_BufferConverter \
- (PyObject *, PyArray_Chunk *);
-NPY_NO_EXPORT int PyArray_AxisConverter \
- (PyObject *, int *);
-NPY_NO_EXPORT int PyArray_BoolConverter \
- (PyObject *, npy_bool *);
-NPY_NO_EXPORT int PyArray_ByteorderConverter \
- (PyObject *, char *);
-NPY_NO_EXPORT int PyArray_OrderConverter \
- (PyObject *, NPY_ORDER *);
-NPY_NO_EXPORT unsigned char PyArray_EquivTypes \
- (PyArray_Descr *, PyArray_Descr *);
-NPY_NO_EXPORT PyObject * PyArray_Zeros \
- (int, npy_intp *, PyArray_Descr *, int);
-NPY_NO_EXPORT PyObject * PyArray_Empty \
- (int, npy_intp *, PyArray_Descr *, int);
-NPY_NO_EXPORT PyObject * PyArray_Where \
- (PyObject *, PyObject *, PyObject *);
-NPY_NO_EXPORT PyObject * PyArray_Arange \
- (double, double, double, int);
-NPY_NO_EXPORT PyObject * PyArray_ArangeObj \
- (PyObject *, PyObject *, PyObject *, PyArray_Descr *);
-NPY_NO_EXPORT int PyArray_SortkindConverter \
- (PyObject *, NPY_SORTKIND *);
-NPY_NO_EXPORT PyObject * PyArray_LexSort \
- (PyObject *, int);
-NPY_NO_EXPORT PyObject * PyArray_Round \
- (PyArrayObject *, int, PyArrayObject *);
-NPY_NO_EXPORT unsigned char PyArray_EquivTypenums \
- (int, int);
-NPY_NO_EXPORT int PyArray_RegisterDataType \
- (PyArray_Descr *);
-NPY_NO_EXPORT int PyArray_RegisterCastFunc \
- (PyArray_Descr *, int, PyArray_VectorUnaryFunc *);
-NPY_NO_EXPORT int PyArray_RegisterCanCast \
- (PyArray_Descr *, int, NPY_SCALARKIND);
-NPY_NO_EXPORT void PyArray_InitArrFuncs \
- (PyArray_ArrFuncs *);
-NPY_NO_EXPORT PyObject * PyArray_IntTupleFromIntp \
- (int, npy_intp *);
-NPY_NO_EXPORT int PyArray_TypeNumFromName \
- (char *);
-NPY_NO_EXPORT int PyArray_ClipmodeConverter \
- (PyObject *, NPY_CLIPMODE *);
-NPY_NO_EXPORT int PyArray_OutputConverter \
- (PyObject *, PyArrayObject **);
-NPY_NO_EXPORT PyObject * PyArray_BroadcastToShape \
- (PyObject *, npy_intp *, int);
-NPY_NO_EXPORT void _PyArray_SigintHandler \
- (int);
-NPY_NO_EXPORT void* _PyArray_GetSigintBuf \
- (void);
-NPY_NO_EXPORT int PyArray_DescrAlignConverter \
- (PyObject *, PyArray_Descr **);
-NPY_NO_EXPORT int PyArray_DescrAlignConverter2 \
- (PyObject *, PyArray_Descr **);
-NPY_NO_EXPORT int PyArray_SearchsideConverter \
- (PyObject *, void *);
-NPY_NO_EXPORT PyObject * PyArray_CheckAxis \
- (PyArrayObject *, int *, int);
-NPY_NO_EXPORT npy_intp PyArray_OverflowMultiplyList \
- (npy_intp *, int);
-NPY_NO_EXPORT int PyArray_CompareString \
- (char *, char *, size_t);
-NPY_NO_EXPORT PyObject * PyArray_MultiIterFromObjects \
- (PyObject **, int, int, ...);
-NPY_NO_EXPORT int PyArray_GetEndianness \
- (void);
-NPY_NO_EXPORT unsigned int PyArray_GetNDArrayCFeatureVersion \
- (void);
-NPY_NO_EXPORT PyObject * PyArray_Correlate2 \
- (PyObject *, PyObject *, int);
-NPY_NO_EXPORT PyObject* PyArray_NeighborhoodIterNew \
- (PyArrayIterObject *, npy_intp *, int, PyArrayObject*);
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyTimeIntegerArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyTimeIntegerArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyDatetimeArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyDatetimeArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyTimedeltaArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyTimedeltaArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyHalfArrType_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyHalfArrType_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject NpyIter_Type;
-#else
- NPY_NO_EXPORT PyTypeObject NpyIter_Type;
-#endif
-
-NPY_NO_EXPORT void PyArray_SetDatetimeParseFunction \
- (PyObject *);
-NPY_NO_EXPORT void PyArray_DatetimeToDatetimeStruct \
- (npy_datetime, NPY_DATETIMEUNIT, npy_datetimestruct *);
-NPY_NO_EXPORT void PyArray_TimedeltaToTimedeltaStruct \
- (npy_timedelta, NPY_DATETIMEUNIT, npy_timedeltastruct *);
-NPY_NO_EXPORT npy_datetime PyArray_DatetimeStructToDatetime \
- (NPY_DATETIMEUNIT, npy_datetimestruct *);
-NPY_NO_EXPORT npy_datetime PyArray_TimedeltaStructToTimedelta \
- (NPY_DATETIMEUNIT, npy_timedeltastruct *);
-NPY_NO_EXPORT NpyIter * NpyIter_New \
- (PyArrayObject *, npy_uint32, NPY_ORDER, NPY_CASTING, PyArray_Descr*);
-NPY_NO_EXPORT NpyIter * NpyIter_MultiNew \
- (int, PyArrayObject **, npy_uint32, NPY_ORDER, NPY_CASTING, npy_uint32 *, PyArray_Descr **);
-NPY_NO_EXPORT NpyIter * NpyIter_AdvancedNew \
- (int, PyArrayObject **, npy_uint32, NPY_ORDER, NPY_CASTING, npy_uint32 *, PyArray_Descr **, int, int **, npy_intp *, npy_intp);
-NPY_NO_EXPORT NpyIter * NpyIter_Copy \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_Deallocate \
- (NpyIter *);
-NPY_NO_EXPORT npy_bool NpyIter_HasDelayedBufAlloc \
- (NpyIter *);
-NPY_NO_EXPORT npy_bool NpyIter_HasExternalLoop \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_EnableExternalLoop \
- (NpyIter *);
-NPY_NO_EXPORT npy_intp * NpyIter_GetInnerStrideArray \
- (NpyIter *);
-NPY_NO_EXPORT npy_intp * NpyIter_GetInnerLoopSizePtr \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_Reset \
- (NpyIter *, char **);
-NPY_NO_EXPORT int NpyIter_ResetBasePointers \
- (NpyIter *, char **, char **);
-NPY_NO_EXPORT int NpyIter_ResetToIterIndexRange \
- (NpyIter *, npy_intp, npy_intp, char **);
-NPY_NO_EXPORT int NpyIter_GetNDim \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_GetNOp \
- (NpyIter *);
-NPY_NO_EXPORT NpyIter_IterNextFunc * NpyIter_GetIterNext \
- (NpyIter *, char **);
-NPY_NO_EXPORT npy_intp NpyIter_GetIterSize \
- (NpyIter *);
-NPY_NO_EXPORT void NpyIter_GetIterIndexRange \
- (NpyIter *, npy_intp *, npy_intp *);
-NPY_NO_EXPORT npy_intp NpyIter_GetIterIndex \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_GotoIterIndex \
- (NpyIter *, npy_intp);
-NPY_NO_EXPORT npy_bool NpyIter_HasMultiIndex \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_GetShape \
- (NpyIter *, npy_intp *);
-NPY_NO_EXPORT NpyIter_GetMultiIndexFunc * NpyIter_GetGetMultiIndex \
- (NpyIter *, char **);
-NPY_NO_EXPORT int NpyIter_GotoMultiIndex \
- (NpyIter *, npy_intp *);
-NPY_NO_EXPORT int NpyIter_RemoveMultiIndex \
- (NpyIter *);
-NPY_NO_EXPORT npy_bool NpyIter_HasIndex \
- (NpyIter *);
-NPY_NO_EXPORT npy_bool NpyIter_IsBuffered \
- (NpyIter *);
-NPY_NO_EXPORT npy_bool NpyIter_IsGrowInner \
- (NpyIter *);
-NPY_NO_EXPORT npy_intp NpyIter_GetBufferSize \
- (NpyIter *);
-NPY_NO_EXPORT npy_intp * NpyIter_GetIndexPtr \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_GotoIndex \
- (NpyIter *, npy_intp);
-NPY_NO_EXPORT char ** NpyIter_GetDataPtrArray \
- (NpyIter *);
-NPY_NO_EXPORT PyArray_Descr ** NpyIter_GetDescrArray \
- (NpyIter *);
-NPY_NO_EXPORT PyArrayObject ** NpyIter_GetOperandArray \
- (NpyIter *);
-NPY_NO_EXPORT PyArrayObject * NpyIter_GetIterView \
- (NpyIter *, npy_intp);
-NPY_NO_EXPORT void NpyIter_GetReadFlags \
- (NpyIter *, char *);
-NPY_NO_EXPORT void NpyIter_GetWriteFlags \
- (NpyIter *, char *);
-NPY_NO_EXPORT void NpyIter_DebugPrint \
- (NpyIter *);
-NPY_NO_EXPORT npy_bool NpyIter_IterationNeedsAPI \
- (NpyIter *);
-NPY_NO_EXPORT void NpyIter_GetInnerFixedStrideArray \
- (NpyIter *, npy_intp *);
-NPY_NO_EXPORT int NpyIter_RemoveAxis \
- (NpyIter *, int);
-NPY_NO_EXPORT npy_intp * NpyIter_GetAxisStrideArray \
- (NpyIter *, int);
-NPY_NO_EXPORT npy_bool NpyIter_RequiresBuffering \
- (NpyIter *);
-NPY_NO_EXPORT char ** NpyIter_GetInitialDataPtrArray \
- (NpyIter *);
-NPY_NO_EXPORT int NpyIter_CreateCompatibleStrides \
- (NpyIter *, npy_intp, npy_intp *);
-NPY_NO_EXPORT int PyArray_CastingConverter \
- (PyObject *, NPY_CASTING *);
-NPY_NO_EXPORT npy_intp PyArray_CountNonzero \
- (PyArrayObject *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_PromoteTypes \
- (PyArray_Descr *, PyArray_Descr *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_MinScalarType \
- (PyArrayObject *);
-NPY_NO_EXPORT PyArray_Descr * PyArray_ResultType \
- (npy_intp, PyArrayObject **, npy_intp, PyArray_Descr **);
-NPY_NO_EXPORT npy_bool PyArray_CanCastArrayTo \
- (PyArrayObject *, PyArray_Descr *, NPY_CASTING);
-NPY_NO_EXPORT npy_bool PyArray_CanCastTypeTo \
- (PyArray_Descr *, PyArray_Descr *, NPY_CASTING);
-NPY_NO_EXPORT PyArrayObject * PyArray_EinsteinSum \
- (char *, npy_intp, PyArrayObject **, PyArray_Descr *, NPY_ORDER, NPY_CASTING, PyArrayObject *);
-NPY_NO_EXPORT PyObject * PyArray_NewLikeArray \
- (PyArrayObject *, NPY_ORDER, PyArray_Descr *, int);
-NPY_NO_EXPORT int PyArray_GetArrayParamsFromObject \
- (PyObject *, PyArray_Descr *, npy_bool, PyArray_Descr **, int *, npy_intp *, PyArrayObject **, PyObject *);
-NPY_NO_EXPORT int PyArray_ConvertClipmodeSequence \
- (PyObject *, NPY_CLIPMODE *, int);
-NPY_NO_EXPORT PyObject * PyArray_MatrixProduct2 \
- (PyObject *, PyObject *, PyArrayObject*);
-NPY_NO_EXPORT npy_bool NpyIter_IsFirstVisit \
- (NpyIter *, int);
-NPY_NO_EXPORT int PyArray_SetBaseObject \
- (PyArrayObject *, PyObject *);
-NPY_NO_EXPORT void PyArray_CreateSortedStridePerm \
- (int, npy_intp *, npy_stride_sort_item *);
-NPY_NO_EXPORT void PyArray_RemoveAxesInPlace \
- (PyArrayObject *, npy_bool *);
-NPY_NO_EXPORT void PyArray_DebugPrint \
- (PyArrayObject *);
-NPY_NO_EXPORT int PyArray_FailUnlessWriteable \
- (PyArrayObject *, const char *);
-NPY_NO_EXPORT int PyArray_SetUpdateIfCopyBase \
- (PyArrayObject *, PyArrayObject *);
-NPY_NO_EXPORT void * PyDataMem_NEW \
- (size_t);
-NPY_NO_EXPORT void PyDataMem_FREE \
- (void *);
-NPY_NO_EXPORT void * PyDataMem_RENEW \
- (void *, size_t);
-NPY_NO_EXPORT PyDataMem_EventHookFunc * PyDataMem_SetEventHook \
- (PyDataMem_EventHookFunc *, void *, void **);
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT NPY_CASTING NPY_DEFAULT_ASSIGN_CASTING;
-#else
- NPY_NO_EXPORT NPY_CASTING NPY_DEFAULT_ASSIGN_CASTING;
-#endif
-
-
-#else
-
-#if defined(PY_ARRAY_UNIQUE_SYMBOL)
-#define PyArray_API PY_ARRAY_UNIQUE_SYMBOL
-#endif
-
-#if defined(NO_IMPORT) || defined(NO_IMPORT_ARRAY)
-extern void **PyArray_API;
-#else
-#if defined(PY_ARRAY_UNIQUE_SYMBOL)
-void **PyArray_API;
-#else
-static void **PyArray_API=NULL;
-#endif
-#endif
-
-#define PyArray_GetNDArrayCVersion \
- (*(unsigned int (*)(void)) \
- PyArray_API[0])
-#define PyBigArray_Type (*(PyTypeObject *)PyArray_API[1])
-#define PyArray_Type (*(PyTypeObject *)PyArray_API[2])
-#define PyArrayDescr_Type (*(PyTypeObject *)PyArray_API[3])
-#define PyArrayFlags_Type (*(PyTypeObject *)PyArray_API[4])
-#define PyArrayIter_Type (*(PyTypeObject *)PyArray_API[5])
-#define PyArrayMultiIter_Type (*(PyTypeObject *)PyArray_API[6])
-#define NPY_NUMUSERTYPES (*(int *)PyArray_API[7])
-#define PyBoolArrType_Type (*(PyTypeObject *)PyArray_API[8])
-#define _PyArrayScalar_BoolValues ((PyBoolScalarObject *)PyArray_API[9])
-#define PyGenericArrType_Type (*(PyTypeObject *)PyArray_API[10])
-#define PyNumberArrType_Type (*(PyTypeObject *)PyArray_API[11])
-#define PyIntegerArrType_Type (*(PyTypeObject *)PyArray_API[12])
-#define PySignedIntegerArrType_Type (*(PyTypeObject *)PyArray_API[13])
-#define PyUnsignedIntegerArrType_Type (*(PyTypeObject *)PyArray_API[14])
-#define PyInexactArrType_Type (*(PyTypeObject *)PyArray_API[15])
-#define PyFloatingArrType_Type (*(PyTypeObject *)PyArray_API[16])
-#define PyComplexFloatingArrType_Type (*(PyTypeObject *)PyArray_API[17])
-#define PyFlexibleArrType_Type (*(PyTypeObject *)PyArray_API[18])
-#define PyCharacterArrType_Type (*(PyTypeObject *)PyArray_API[19])
-#define PyByteArrType_Type (*(PyTypeObject *)PyArray_API[20])
-#define PyShortArrType_Type (*(PyTypeObject *)PyArray_API[21])
-#define PyIntArrType_Type (*(PyTypeObject *)PyArray_API[22])
-#define PyLongArrType_Type (*(PyTypeObject *)PyArray_API[23])
-#define PyLongLongArrType_Type (*(PyTypeObject *)PyArray_API[24])
-#define PyUByteArrType_Type (*(PyTypeObject *)PyArray_API[25])
-#define PyUShortArrType_Type (*(PyTypeObject *)PyArray_API[26])
-#define PyUIntArrType_Type (*(PyTypeObject *)PyArray_API[27])
-#define PyULongArrType_Type (*(PyTypeObject *)PyArray_API[28])
-#define PyULongLongArrType_Type (*(PyTypeObject *)PyArray_API[29])
-#define PyFloatArrType_Type (*(PyTypeObject *)PyArray_API[30])
-#define PyDoubleArrType_Type (*(PyTypeObject *)PyArray_API[31])
-#define PyLongDoubleArrType_Type (*(PyTypeObject *)PyArray_API[32])
-#define PyCFloatArrType_Type (*(PyTypeObject *)PyArray_API[33])
-#define PyCDoubleArrType_Type (*(PyTypeObject *)PyArray_API[34])
-#define PyCLongDoubleArrType_Type (*(PyTypeObject *)PyArray_API[35])
-#define PyObjectArrType_Type (*(PyTypeObject *)PyArray_API[36])
-#define PyStringArrType_Type (*(PyTypeObject *)PyArray_API[37])
-#define PyUnicodeArrType_Type (*(PyTypeObject *)PyArray_API[38])
-#define PyVoidArrType_Type (*(PyTypeObject *)PyArray_API[39])
-#define PyArray_SetNumericOps \
- (*(int (*)(PyObject *)) \
- PyArray_API[40])
-#define PyArray_GetNumericOps \
- (*(PyObject * (*)(void)) \
- PyArray_API[41])
-#define PyArray_INCREF \
- (*(int (*)(PyArrayObject *)) \
- PyArray_API[42])
-#define PyArray_XDECREF \
- (*(int (*)(PyArrayObject *)) \
- PyArray_API[43])
-#define PyArray_SetStringFunction \
- (*(void (*)(PyObject *, int)) \
- PyArray_API[44])
-#define PyArray_DescrFromType \
- (*(PyArray_Descr * (*)(int)) \
- PyArray_API[45])
-#define PyArray_TypeObjectFromType \
- (*(PyObject * (*)(int)) \
- PyArray_API[46])
-#define PyArray_Zero \
- (*(char * (*)(PyArrayObject *)) \
- PyArray_API[47])
-#define PyArray_One \
- (*(char * (*)(PyArrayObject *)) \
- PyArray_API[48])
-#define PyArray_CastToType \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Descr *, int)) \
- PyArray_API[49])
-#define PyArray_CastTo \
- (*(int (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[50])
-#define PyArray_CastAnyTo \
- (*(int (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[51])
-#define PyArray_CanCastSafely \
- (*(int (*)(int, int)) \
- PyArray_API[52])
-#define PyArray_CanCastTo \
- (*(npy_bool (*)(PyArray_Descr *, PyArray_Descr *)) \
- PyArray_API[53])
-#define PyArray_ObjectType \
- (*(int (*)(PyObject *, int)) \
- PyArray_API[54])
-#define PyArray_DescrFromObject \
- (*(PyArray_Descr * (*)(PyObject *, PyArray_Descr *)) \
- PyArray_API[55])
-#define PyArray_ConvertToCommonType \
- (*(PyArrayObject ** (*)(PyObject *, int *)) \
- PyArray_API[56])
-#define PyArray_DescrFromScalar \
- (*(PyArray_Descr * (*)(PyObject *)) \
- PyArray_API[57])
-#define PyArray_DescrFromTypeObject \
- (*(PyArray_Descr * (*)(PyObject *)) \
- PyArray_API[58])
-#define PyArray_Size \
- (*(npy_intp (*)(PyObject *)) \
- PyArray_API[59])
-#define PyArray_Scalar \
- (*(PyObject * (*)(void *, PyArray_Descr *, PyObject *)) \
- PyArray_API[60])
-#define PyArray_FromScalar \
- (*(PyObject * (*)(PyObject *, PyArray_Descr *)) \
- PyArray_API[61])
-#define PyArray_ScalarAsCtype \
- (*(void (*)(PyObject *, void *)) \
- PyArray_API[62])
-#define PyArray_CastScalarToCtype \
- (*(int (*)(PyObject *, void *, PyArray_Descr *)) \
- PyArray_API[63])
-#define PyArray_CastScalarDirect \
- (*(int (*)(PyObject *, PyArray_Descr *, void *, int)) \
- PyArray_API[64])
-#define PyArray_ScalarFromObject \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[65])
-#define PyArray_GetCastFunc \
- (*(PyArray_VectorUnaryFunc * (*)(PyArray_Descr *, int)) \
- PyArray_API[66])
-#define PyArray_FromDims \
- (*(PyObject * (*)(int, int *, int)) \
- PyArray_API[67])
-#define PyArray_FromDimsAndDataAndDescr \
- (*(PyObject * (*)(int, int *, PyArray_Descr *, char *)) \
- PyArray_API[68])
-#define PyArray_FromAny \
- (*(PyObject * (*)(PyObject *, PyArray_Descr *, int, int, int, PyObject *)) \
- PyArray_API[69])
-#define PyArray_EnsureArray \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[70])
-#define PyArray_EnsureAnyArray \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[71])
-#define PyArray_FromFile \
- (*(PyObject * (*)(FILE *, PyArray_Descr *, npy_intp, char *)) \
- PyArray_API[72])
-#define PyArray_FromString \
- (*(PyObject * (*)(char *, npy_intp, PyArray_Descr *, npy_intp, char *)) \
- PyArray_API[73])
-#define PyArray_FromBuffer \
- (*(PyObject * (*)(PyObject *, PyArray_Descr *, npy_intp, npy_intp)) \
- PyArray_API[74])
-#define PyArray_FromIter \
- (*(PyObject * (*)(PyObject *, PyArray_Descr *, npy_intp)) \
- PyArray_API[75])
-#define PyArray_Return \
- (*(PyObject * (*)(PyArrayObject *)) \
- PyArray_API[76])
-#define PyArray_GetField \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Descr *, int)) \
- PyArray_API[77])
-#define PyArray_SetField \
- (*(int (*)(PyArrayObject *, PyArray_Descr *, int, PyObject *)) \
- PyArray_API[78])
-#define PyArray_Byteswap \
- (*(PyObject * (*)(PyArrayObject *, npy_bool)) \
- PyArray_API[79])
-#define PyArray_Resize \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Dims *, int, NPY_ORDER)) \
- PyArray_API[80])
-#define PyArray_MoveInto \
- (*(int (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[81])
-#define PyArray_CopyInto \
- (*(int (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[82])
-#define PyArray_CopyAnyInto \
- (*(int (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[83])
-#define PyArray_CopyObject \
- (*(int (*)(PyArrayObject *, PyObject *)) \
- PyArray_API[84])
-#define PyArray_NewCopy \
- (*(PyObject * (*)(PyArrayObject *, NPY_ORDER)) \
- PyArray_API[85])
-#define PyArray_ToList \
- (*(PyObject * (*)(PyArrayObject *)) \
- PyArray_API[86])
-#define PyArray_ToString \
- (*(PyObject * (*)(PyArrayObject *, NPY_ORDER)) \
- PyArray_API[87])
-#define PyArray_ToFile \
- (*(int (*)(PyArrayObject *, FILE *, char *, char *)) \
- PyArray_API[88])
-#define PyArray_Dump \
- (*(int (*)(PyObject *, PyObject *, int)) \
- PyArray_API[89])
-#define PyArray_Dumps \
- (*(PyObject * (*)(PyObject *, int)) \
- PyArray_API[90])
-#define PyArray_ValidType \
- (*(int (*)(int)) \
- PyArray_API[91])
-#define PyArray_UpdateFlags \
- (*(void (*)(PyArrayObject *, int)) \
- PyArray_API[92])
-#define PyArray_New \
- (*(PyObject * (*)(PyTypeObject *, int, npy_intp *, int, npy_intp *, void *, int, int, PyObject *)) \
- PyArray_API[93])
-#define PyArray_NewFromDescr \
- (*(PyObject * (*)(PyTypeObject *, PyArray_Descr *, int, npy_intp *, npy_intp *, void *, int, PyObject *)) \
- PyArray_API[94])
-#define PyArray_DescrNew \
- (*(PyArray_Descr * (*)(PyArray_Descr *)) \
- PyArray_API[95])
-#define PyArray_DescrNewFromType \
- (*(PyArray_Descr * (*)(int)) \
- PyArray_API[96])
-#define PyArray_GetPriority \
- (*(double (*)(PyObject *, double)) \
- PyArray_API[97])
-#define PyArray_IterNew \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[98])
-#define PyArray_MultiIterNew \
- (*(PyObject * (*)(int, ...)) \
- PyArray_API[99])
-#define PyArray_PyIntAsInt \
- (*(int (*)(PyObject *)) \
- PyArray_API[100])
-#define PyArray_PyIntAsIntp \
- (*(npy_intp (*)(PyObject *)) \
- PyArray_API[101])
-#define PyArray_Broadcast \
- (*(int (*)(PyArrayMultiIterObject *)) \
- PyArray_API[102])
-#define PyArray_FillObjectArray \
- (*(void (*)(PyArrayObject *, PyObject *)) \
- PyArray_API[103])
-#define PyArray_FillWithScalar \
- (*(int (*)(PyArrayObject *, PyObject *)) \
- PyArray_API[104])
-#define PyArray_CheckStrides \
- (*(npy_bool (*)(int, int, npy_intp, npy_intp, npy_intp *, npy_intp *)) \
- PyArray_API[105])
-#define PyArray_DescrNewByteorder \
- (*(PyArray_Descr * (*)(PyArray_Descr *, char)) \
- PyArray_API[106])
-#define PyArray_IterAllButAxis \
- (*(PyObject * (*)(PyObject *, int *)) \
- PyArray_API[107])
-#define PyArray_CheckFromAny \
- (*(PyObject * (*)(PyObject *, PyArray_Descr *, int, int, int, PyObject *)) \
- PyArray_API[108])
-#define PyArray_FromArray \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Descr *, int)) \
- PyArray_API[109])
-#define PyArray_FromInterface \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[110])
-#define PyArray_FromStructInterface \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[111])
-#define PyArray_FromArrayAttr \
- (*(PyObject * (*)(PyObject *, PyArray_Descr *, PyObject *)) \
- PyArray_API[112])
-#define PyArray_ScalarKind \
- (*(NPY_SCALARKIND (*)(int, PyArrayObject **)) \
- PyArray_API[113])
-#define PyArray_CanCoerceScalar \
- (*(int (*)(int, int, NPY_SCALARKIND)) \
- PyArray_API[114])
-#define PyArray_NewFlagsObject \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[115])
-#define PyArray_CanCastScalar \
- (*(npy_bool (*)(PyTypeObject *, PyTypeObject *)) \
- PyArray_API[116])
-#define PyArray_CompareUCS4 \
- (*(int (*)(npy_ucs4 *, npy_ucs4 *, size_t)) \
- PyArray_API[117])
-#define PyArray_RemoveSmallest \
- (*(int (*)(PyArrayMultiIterObject *)) \
- PyArray_API[118])
-#define PyArray_ElementStrides \
- (*(int (*)(PyObject *)) \
- PyArray_API[119])
-#define PyArray_Item_INCREF \
- (*(void (*)(char *, PyArray_Descr *)) \
- PyArray_API[120])
-#define PyArray_Item_XDECREF \
- (*(void (*)(char *, PyArray_Descr *)) \
- PyArray_API[121])
-#define PyArray_FieldNames \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[122])
-#define PyArray_Transpose \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Dims *)) \
- PyArray_API[123])
-#define PyArray_TakeFrom \
- (*(PyObject * (*)(PyArrayObject *, PyObject *, int, PyArrayObject *, NPY_CLIPMODE)) \
- PyArray_API[124])
-#define PyArray_PutTo \
- (*(PyObject * (*)(PyArrayObject *, PyObject*, PyObject *, NPY_CLIPMODE)) \
- PyArray_API[125])
-#define PyArray_PutMask \
- (*(PyObject * (*)(PyArrayObject *, PyObject*, PyObject*)) \
- PyArray_API[126])
-#define PyArray_Repeat \
- (*(PyObject * (*)(PyArrayObject *, PyObject *, int)) \
- PyArray_API[127])
-#define PyArray_Choose \
- (*(PyObject * (*)(PyArrayObject *, PyObject *, PyArrayObject *, NPY_CLIPMODE)) \
- PyArray_API[128])
-#define PyArray_Sort \
- (*(int (*)(PyArrayObject *, int, NPY_SORTKIND)) \
- PyArray_API[129])
-#define PyArray_ArgSort \
- (*(PyObject * (*)(PyArrayObject *, int, NPY_SORTKIND)) \
- PyArray_API[130])
-#define PyArray_SearchSorted \
- (*(PyObject * (*)(PyArrayObject *, PyObject *, NPY_SEARCHSIDE, PyObject *)) \
- PyArray_API[131])
-#define PyArray_ArgMax \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[132])
-#define PyArray_ArgMin \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[133])
-#define PyArray_Reshape \
- (*(PyObject * (*)(PyArrayObject *, PyObject *)) \
- PyArray_API[134])
-#define PyArray_Newshape \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Dims *, NPY_ORDER)) \
- PyArray_API[135])
-#define PyArray_Squeeze \
- (*(PyObject * (*)(PyArrayObject *)) \
- PyArray_API[136])
-#define PyArray_View \
- (*(PyObject * (*)(PyArrayObject *, PyArray_Descr *, PyTypeObject *)) \
- PyArray_API[137])
-#define PyArray_SwapAxes \
- (*(PyObject * (*)(PyArrayObject *, int, int)) \
- PyArray_API[138])
-#define PyArray_Max \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[139])
-#define PyArray_Min \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[140])
-#define PyArray_Ptp \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[141])
-#define PyArray_Mean \
- (*(PyObject * (*)(PyArrayObject *, int, int, PyArrayObject *)) \
- PyArray_API[142])
-#define PyArray_Trace \
- (*(PyObject * (*)(PyArrayObject *, int, int, int, int, PyArrayObject *)) \
- PyArray_API[143])
-#define PyArray_Diagonal \
- (*(PyObject * (*)(PyArrayObject *, int, int, int)) \
- PyArray_API[144])
-#define PyArray_Clip \
- (*(PyObject * (*)(PyArrayObject *, PyObject *, PyObject *, PyArrayObject *)) \
- PyArray_API[145])
-#define PyArray_Conjugate \
- (*(PyObject * (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[146])
-#define PyArray_Nonzero \
- (*(PyObject * (*)(PyArrayObject *)) \
- PyArray_API[147])
-#define PyArray_Std \
- (*(PyObject * (*)(PyArrayObject *, int, int, PyArrayObject *, int)) \
- PyArray_API[148])
-#define PyArray_Sum \
- (*(PyObject * (*)(PyArrayObject *, int, int, PyArrayObject *)) \
- PyArray_API[149])
-#define PyArray_CumSum \
- (*(PyObject * (*)(PyArrayObject *, int, int, PyArrayObject *)) \
- PyArray_API[150])
-#define PyArray_Prod \
- (*(PyObject * (*)(PyArrayObject *, int, int, PyArrayObject *)) \
- PyArray_API[151])
-#define PyArray_CumProd \
- (*(PyObject * (*)(PyArrayObject *, int, int, PyArrayObject *)) \
- PyArray_API[152])
-#define PyArray_All \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[153])
-#define PyArray_Any \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[154])
-#define PyArray_Compress \
- (*(PyObject * (*)(PyArrayObject *, PyObject *, int, PyArrayObject *)) \
- PyArray_API[155])
-#define PyArray_Flatten \
- (*(PyObject * (*)(PyArrayObject *, NPY_ORDER)) \
- PyArray_API[156])
-#define PyArray_Ravel \
- (*(PyObject * (*)(PyArrayObject *, NPY_ORDER)) \
- PyArray_API[157])
-#define PyArray_MultiplyList \
- (*(npy_intp (*)(npy_intp *, int)) \
- PyArray_API[158])
-#define PyArray_MultiplyIntList \
- (*(int (*)(int *, int)) \
- PyArray_API[159])
-#define PyArray_GetPtr \
- (*(void * (*)(PyArrayObject *, npy_intp*)) \
- PyArray_API[160])
-#define PyArray_CompareLists \
- (*(int (*)(npy_intp *, npy_intp *, int)) \
- PyArray_API[161])
-#define PyArray_AsCArray \
- (*(int (*)(PyObject **, void *, npy_intp *, int, PyArray_Descr*)) \
- PyArray_API[162])
-#define PyArray_As1D \
- (*(int (*)(PyObject **, char **, int *, int)) \
- PyArray_API[163])
-#define PyArray_As2D \
- (*(int (*)(PyObject **, char ***, int *, int *, int)) \
- PyArray_API[164])
-#define PyArray_Free \
- (*(int (*)(PyObject *, void *)) \
- PyArray_API[165])
-#define PyArray_Converter \
- (*(int (*)(PyObject *, PyObject **)) \
- PyArray_API[166])
-#define PyArray_IntpFromSequence \
- (*(int (*)(PyObject *, npy_intp *, int)) \
- PyArray_API[167])
-#define PyArray_Concatenate \
- (*(PyObject * (*)(PyObject *, int)) \
- PyArray_API[168])
-#define PyArray_InnerProduct \
- (*(PyObject * (*)(PyObject *, PyObject *)) \
- PyArray_API[169])
-#define PyArray_MatrixProduct \
- (*(PyObject * (*)(PyObject *, PyObject *)) \
- PyArray_API[170])
-#define PyArray_CopyAndTranspose \
- (*(PyObject * (*)(PyObject *)) \
- PyArray_API[171])
-#define PyArray_Correlate \
- (*(PyObject * (*)(PyObject *, PyObject *, int)) \
- PyArray_API[172])
-#define PyArray_TypestrConvert \
- (*(int (*)(int, int)) \
- PyArray_API[173])
-#define PyArray_DescrConverter \
- (*(int (*)(PyObject *, PyArray_Descr **)) \
- PyArray_API[174])
-#define PyArray_DescrConverter2 \
- (*(int (*)(PyObject *, PyArray_Descr **)) \
- PyArray_API[175])
-#define PyArray_IntpConverter \
- (*(int (*)(PyObject *, PyArray_Dims *)) \
- PyArray_API[176])
-#define PyArray_BufferConverter \
- (*(int (*)(PyObject *, PyArray_Chunk *)) \
- PyArray_API[177])
-#define PyArray_AxisConverter \
- (*(int (*)(PyObject *, int *)) \
- PyArray_API[178])
-#define PyArray_BoolConverter \
- (*(int (*)(PyObject *, npy_bool *)) \
- PyArray_API[179])
-#define PyArray_ByteorderConverter \
- (*(int (*)(PyObject *, char *)) \
- PyArray_API[180])
-#define PyArray_OrderConverter \
- (*(int (*)(PyObject *, NPY_ORDER *)) \
- PyArray_API[181])
-#define PyArray_EquivTypes \
- (*(unsigned char (*)(PyArray_Descr *, PyArray_Descr *)) \
- PyArray_API[182])
-#define PyArray_Zeros \
- (*(PyObject * (*)(int, npy_intp *, PyArray_Descr *, int)) \
- PyArray_API[183])
-#define PyArray_Empty \
- (*(PyObject * (*)(int, npy_intp *, PyArray_Descr *, int)) \
- PyArray_API[184])
-#define PyArray_Where \
- (*(PyObject * (*)(PyObject *, PyObject *, PyObject *)) \
- PyArray_API[185])
-#define PyArray_Arange \
- (*(PyObject * (*)(double, double, double, int)) \
- PyArray_API[186])
-#define PyArray_ArangeObj \
- (*(PyObject * (*)(PyObject *, PyObject *, PyObject *, PyArray_Descr *)) \
- PyArray_API[187])
-#define PyArray_SortkindConverter \
- (*(int (*)(PyObject *, NPY_SORTKIND *)) \
- PyArray_API[188])
-#define PyArray_LexSort \
- (*(PyObject * (*)(PyObject *, int)) \
- PyArray_API[189])
-#define PyArray_Round \
- (*(PyObject * (*)(PyArrayObject *, int, PyArrayObject *)) \
- PyArray_API[190])
-#define PyArray_EquivTypenums \
- (*(unsigned char (*)(int, int)) \
- PyArray_API[191])
-#define PyArray_RegisterDataType \
- (*(int (*)(PyArray_Descr *)) \
- PyArray_API[192])
-#define PyArray_RegisterCastFunc \
- (*(int (*)(PyArray_Descr *, int, PyArray_VectorUnaryFunc *)) \
- PyArray_API[193])
-#define PyArray_RegisterCanCast \
- (*(int (*)(PyArray_Descr *, int, NPY_SCALARKIND)) \
- PyArray_API[194])
-#define PyArray_InitArrFuncs \
- (*(void (*)(PyArray_ArrFuncs *)) \
- PyArray_API[195])
-#define PyArray_IntTupleFromIntp \
- (*(PyObject * (*)(int, npy_intp *)) \
- PyArray_API[196])
-#define PyArray_TypeNumFromName \
- (*(int (*)(char *)) \
- PyArray_API[197])
-#define PyArray_ClipmodeConverter \
- (*(int (*)(PyObject *, NPY_CLIPMODE *)) \
- PyArray_API[198])
-#define PyArray_OutputConverter \
- (*(int (*)(PyObject *, PyArrayObject **)) \
- PyArray_API[199])
-#define PyArray_BroadcastToShape \
- (*(PyObject * (*)(PyObject *, npy_intp *, int)) \
- PyArray_API[200])
-#define _PyArray_SigintHandler \
- (*(void (*)(int)) \
- PyArray_API[201])
-#define _PyArray_GetSigintBuf \
- (*(void* (*)(void)) \
- PyArray_API[202])
-#define PyArray_DescrAlignConverter \
- (*(int (*)(PyObject *, PyArray_Descr **)) \
- PyArray_API[203])
-#define PyArray_DescrAlignConverter2 \
- (*(int (*)(PyObject *, PyArray_Descr **)) \
- PyArray_API[204])
-#define PyArray_SearchsideConverter \
- (*(int (*)(PyObject *, void *)) \
- PyArray_API[205])
-#define PyArray_CheckAxis \
- (*(PyObject * (*)(PyArrayObject *, int *, int)) \
- PyArray_API[206])
-#define PyArray_OverflowMultiplyList \
- (*(npy_intp (*)(npy_intp *, int)) \
- PyArray_API[207])
-#define PyArray_CompareString \
- (*(int (*)(char *, char *, size_t)) \
- PyArray_API[208])
-#define PyArray_MultiIterFromObjects \
- (*(PyObject * (*)(PyObject **, int, int, ...)) \
- PyArray_API[209])
-#define PyArray_GetEndianness \
- (*(int (*)(void)) \
- PyArray_API[210])
-#define PyArray_GetNDArrayCFeatureVersion \
- (*(unsigned int (*)(void)) \
- PyArray_API[211])
-#define PyArray_Correlate2 \
- (*(PyObject * (*)(PyObject *, PyObject *, int)) \
- PyArray_API[212])
-#define PyArray_NeighborhoodIterNew \
- (*(PyObject* (*)(PyArrayIterObject *, npy_intp *, int, PyArrayObject*)) \
- PyArray_API[213])
-#define PyTimeIntegerArrType_Type (*(PyTypeObject *)PyArray_API[214])
-#define PyDatetimeArrType_Type (*(PyTypeObject *)PyArray_API[215])
-#define PyTimedeltaArrType_Type (*(PyTypeObject *)PyArray_API[216])
-#define PyHalfArrType_Type (*(PyTypeObject *)PyArray_API[217])
-#define NpyIter_Type (*(PyTypeObject *)PyArray_API[218])
-#define PyArray_SetDatetimeParseFunction \
- (*(void (*)(PyObject *)) \
- PyArray_API[219])
-#define PyArray_DatetimeToDatetimeStruct \
- (*(void (*)(npy_datetime, NPY_DATETIMEUNIT, npy_datetimestruct *)) \
- PyArray_API[220])
-#define PyArray_TimedeltaToTimedeltaStruct \
- (*(void (*)(npy_timedelta, NPY_DATETIMEUNIT, npy_timedeltastruct *)) \
- PyArray_API[221])
-#define PyArray_DatetimeStructToDatetime \
- (*(npy_datetime (*)(NPY_DATETIMEUNIT, npy_datetimestruct *)) \
- PyArray_API[222])
-#define PyArray_TimedeltaStructToTimedelta \
- (*(npy_datetime (*)(NPY_DATETIMEUNIT, npy_timedeltastruct *)) \
- PyArray_API[223])
-#define NpyIter_New \
- (*(NpyIter * (*)(PyArrayObject *, npy_uint32, NPY_ORDER, NPY_CASTING, PyArray_Descr*)) \
- PyArray_API[224])
-#define NpyIter_MultiNew \
- (*(NpyIter * (*)(int, PyArrayObject **, npy_uint32, NPY_ORDER, NPY_CASTING, npy_uint32 *, PyArray_Descr **)) \
- PyArray_API[225])
-#define NpyIter_AdvancedNew \
- (*(NpyIter * (*)(int, PyArrayObject **, npy_uint32, NPY_ORDER, NPY_CASTING, npy_uint32 *, PyArray_Descr **, int, int **, npy_intp *, npy_intp)) \
- PyArray_API[226])
-#define NpyIter_Copy \
- (*(NpyIter * (*)(NpyIter *)) \
- PyArray_API[227])
-#define NpyIter_Deallocate \
- (*(int (*)(NpyIter *)) \
- PyArray_API[228])
-#define NpyIter_HasDelayedBufAlloc \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[229])
-#define NpyIter_HasExternalLoop \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[230])
-#define NpyIter_EnableExternalLoop \
- (*(int (*)(NpyIter *)) \
- PyArray_API[231])
-#define NpyIter_GetInnerStrideArray \
- (*(npy_intp * (*)(NpyIter *)) \
- PyArray_API[232])
-#define NpyIter_GetInnerLoopSizePtr \
- (*(npy_intp * (*)(NpyIter *)) \
- PyArray_API[233])
-#define NpyIter_Reset \
- (*(int (*)(NpyIter *, char **)) \
- PyArray_API[234])
-#define NpyIter_ResetBasePointers \
- (*(int (*)(NpyIter *, char **, char **)) \
- PyArray_API[235])
-#define NpyIter_ResetToIterIndexRange \
- (*(int (*)(NpyIter *, npy_intp, npy_intp, char **)) \
- PyArray_API[236])
-#define NpyIter_GetNDim \
- (*(int (*)(NpyIter *)) \
- PyArray_API[237])
-#define NpyIter_GetNOp \
- (*(int (*)(NpyIter *)) \
- PyArray_API[238])
-#define NpyIter_GetIterNext \
- (*(NpyIter_IterNextFunc * (*)(NpyIter *, char **)) \
- PyArray_API[239])
-#define NpyIter_GetIterSize \
- (*(npy_intp (*)(NpyIter *)) \
- PyArray_API[240])
-#define NpyIter_GetIterIndexRange \
- (*(void (*)(NpyIter *, npy_intp *, npy_intp *)) \
- PyArray_API[241])
-#define NpyIter_GetIterIndex \
- (*(npy_intp (*)(NpyIter *)) \
- PyArray_API[242])
-#define NpyIter_GotoIterIndex \
- (*(int (*)(NpyIter *, npy_intp)) \
- PyArray_API[243])
-#define NpyIter_HasMultiIndex \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[244])
-#define NpyIter_GetShape \
- (*(int (*)(NpyIter *, npy_intp *)) \
- PyArray_API[245])
-#define NpyIter_GetGetMultiIndex \
- (*(NpyIter_GetMultiIndexFunc * (*)(NpyIter *, char **)) \
- PyArray_API[246])
-#define NpyIter_GotoMultiIndex \
- (*(int (*)(NpyIter *, npy_intp *)) \
- PyArray_API[247])
-#define NpyIter_RemoveMultiIndex \
- (*(int (*)(NpyIter *)) \
- PyArray_API[248])
-#define NpyIter_HasIndex \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[249])
-#define NpyIter_IsBuffered \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[250])
-#define NpyIter_IsGrowInner \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[251])
-#define NpyIter_GetBufferSize \
- (*(npy_intp (*)(NpyIter *)) \
- PyArray_API[252])
-#define NpyIter_GetIndexPtr \
- (*(npy_intp * (*)(NpyIter *)) \
- PyArray_API[253])
-#define NpyIter_GotoIndex \
- (*(int (*)(NpyIter *, npy_intp)) \
- PyArray_API[254])
-#define NpyIter_GetDataPtrArray \
- (*(char ** (*)(NpyIter *)) \
- PyArray_API[255])
-#define NpyIter_GetDescrArray \
- (*(PyArray_Descr ** (*)(NpyIter *)) \
- PyArray_API[256])
-#define NpyIter_GetOperandArray \
- (*(PyArrayObject ** (*)(NpyIter *)) \
- PyArray_API[257])
-#define NpyIter_GetIterView \
- (*(PyArrayObject * (*)(NpyIter *, npy_intp)) \
- PyArray_API[258])
-#define NpyIter_GetReadFlags \
- (*(void (*)(NpyIter *, char *)) \
- PyArray_API[259])
-#define NpyIter_GetWriteFlags \
- (*(void (*)(NpyIter *, char *)) \
- PyArray_API[260])
-#define NpyIter_DebugPrint \
- (*(void (*)(NpyIter *)) \
- PyArray_API[261])
-#define NpyIter_IterationNeedsAPI \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[262])
-#define NpyIter_GetInnerFixedStrideArray \
- (*(void (*)(NpyIter *, npy_intp *)) \
- PyArray_API[263])
-#define NpyIter_RemoveAxis \
- (*(int (*)(NpyIter *, int)) \
- PyArray_API[264])
-#define NpyIter_GetAxisStrideArray \
- (*(npy_intp * (*)(NpyIter *, int)) \
- PyArray_API[265])
-#define NpyIter_RequiresBuffering \
- (*(npy_bool (*)(NpyIter *)) \
- PyArray_API[266])
-#define NpyIter_GetInitialDataPtrArray \
- (*(char ** (*)(NpyIter *)) \
- PyArray_API[267])
-#define NpyIter_CreateCompatibleStrides \
- (*(int (*)(NpyIter *, npy_intp, npy_intp *)) \
- PyArray_API[268])
-#define PyArray_CastingConverter \
- (*(int (*)(PyObject *, NPY_CASTING *)) \
- PyArray_API[269])
-#define PyArray_CountNonzero \
- (*(npy_intp (*)(PyArrayObject *)) \
- PyArray_API[270])
-#define PyArray_PromoteTypes \
- (*(PyArray_Descr * (*)(PyArray_Descr *, PyArray_Descr *)) \
- PyArray_API[271])
-#define PyArray_MinScalarType \
- (*(PyArray_Descr * (*)(PyArrayObject *)) \
- PyArray_API[272])
-#define PyArray_ResultType \
- (*(PyArray_Descr * (*)(npy_intp, PyArrayObject **, npy_intp, PyArray_Descr **)) \
- PyArray_API[273])
-#define PyArray_CanCastArrayTo \
- (*(npy_bool (*)(PyArrayObject *, PyArray_Descr *, NPY_CASTING)) \
- PyArray_API[274])
-#define PyArray_CanCastTypeTo \
- (*(npy_bool (*)(PyArray_Descr *, PyArray_Descr *, NPY_CASTING)) \
- PyArray_API[275])
-#define PyArray_EinsteinSum \
- (*(PyArrayObject * (*)(char *, npy_intp, PyArrayObject **, PyArray_Descr *, NPY_ORDER, NPY_CASTING, PyArrayObject *)) \
- PyArray_API[276])
-#define PyArray_NewLikeArray \
- (*(PyObject * (*)(PyArrayObject *, NPY_ORDER, PyArray_Descr *, int)) \
- PyArray_API[277])
-#define PyArray_GetArrayParamsFromObject \
- (*(int (*)(PyObject *, PyArray_Descr *, npy_bool, PyArray_Descr **, int *, npy_intp *, PyArrayObject **, PyObject *)) \
- PyArray_API[278])
-#define PyArray_ConvertClipmodeSequence \
- (*(int (*)(PyObject *, NPY_CLIPMODE *, int)) \
- PyArray_API[279])
-#define PyArray_MatrixProduct2 \
- (*(PyObject * (*)(PyObject *, PyObject *, PyArrayObject*)) \
- PyArray_API[280])
-#define NpyIter_IsFirstVisit \
- (*(npy_bool (*)(NpyIter *, int)) \
- PyArray_API[281])
-#define PyArray_SetBaseObject \
- (*(int (*)(PyArrayObject *, PyObject *)) \
- PyArray_API[282])
-#define PyArray_CreateSortedStridePerm \
- (*(void (*)(int, npy_intp *, npy_stride_sort_item *)) \
- PyArray_API[283])
-#define PyArray_RemoveAxesInPlace \
- (*(void (*)(PyArrayObject *, npy_bool *)) \
- PyArray_API[284])
-#define PyArray_DebugPrint \
- (*(void (*)(PyArrayObject *)) \
- PyArray_API[285])
-#define PyArray_FailUnlessWriteable \
- (*(int (*)(PyArrayObject *, const char *)) \
- PyArray_API[286])
-#define PyArray_SetUpdateIfCopyBase \
- (*(int (*)(PyArrayObject *, PyArrayObject *)) \
- PyArray_API[287])
-#define PyDataMem_NEW \
- (*(void * (*)(size_t)) \
- PyArray_API[288])
-#define PyDataMem_FREE \
- (*(void (*)(void *)) \
- PyArray_API[289])
-#define PyDataMem_RENEW \
- (*(void * (*)(void *, size_t)) \
- PyArray_API[290])
-#define PyDataMem_SetEventHook \
- (*(PyDataMem_EventHookFunc * (*)(PyDataMem_EventHookFunc *, void *, void **)) \
- PyArray_API[291])
-#define NPY_DEFAULT_ASSIGN_CASTING (*(NPY_CASTING *)PyArray_API[292])
-
-#if !defined(NO_IMPORT_ARRAY) && !defined(NO_IMPORT)
-static int
-_import_array(void)
-{
- int st;
- PyObject *numpy = PyImport_ImportModule("numpy.core.multiarray");
- PyObject *c_api = NULL;
-
- if (numpy == NULL) {
- PyErr_SetString(PyExc_ImportError, "numpy.core.multiarray failed to import");
- return -1;
- }
- c_api = PyObject_GetAttrString(numpy, "_ARRAY_API");
- Py_DECREF(numpy);
- if (c_api == NULL) {
- PyErr_SetString(PyExc_AttributeError, "_ARRAY_API not found");
- return -1;
- }
-
-#if PY_VERSION_HEX >= 0x03000000
- if (!PyCapsule_CheckExact(c_api)) {
- PyErr_SetString(PyExc_RuntimeError, "_ARRAY_API is not PyCapsule object");
- Py_DECREF(c_api);
- return -1;
- }
- PyArray_API = (void **)PyCapsule_GetPointer(c_api, NULL);
-#else
- if (!PyCObject_Check(c_api)) {
- PyErr_SetString(PyExc_RuntimeError, "_ARRAY_API is not PyCObject object");
- Py_DECREF(c_api);
- return -1;
- }
- PyArray_API = (void **)PyCObject_AsVoidPtr(c_api);
-#endif
- Py_DECREF(c_api);
- if (PyArray_API == NULL) {
- PyErr_SetString(PyExc_RuntimeError, "_ARRAY_API is NULL pointer");
- return -1;
- }
-
- /* Perform runtime check of C API version */
- if (NPY_VERSION != PyArray_GetNDArrayCVersion()) {
- PyErr_Format(PyExc_RuntimeError, "module compiled against "\
- "ABI version %x but this version of numpy is %x", \
- (int) NPY_VERSION, (int) PyArray_GetNDArrayCVersion());
- return -1;
- }
- if (NPY_FEATURE_VERSION > PyArray_GetNDArrayCFeatureVersion()) {
- PyErr_Format(PyExc_RuntimeError, "module compiled against "\
- "API version %x but this version of numpy is %x", \
- (int) NPY_FEATURE_VERSION, (int) PyArray_GetNDArrayCFeatureVersion());
- return -1;
- }
-
- /*
- * Perform runtime check of endianness and check it matches the one set by
- * the headers (npy_endian.h) as a safeguard
- */
- st = PyArray_GetEndianness();
- if (st == NPY_CPU_UNKNOWN_ENDIAN) {
- PyErr_Format(PyExc_RuntimeError, "FATAL: module compiled as unknown endian");
- return -1;
- }
-#if NPY_BYTE_ORDER == NPY_BIG_ENDIAN
- if (st != NPY_CPU_BIG) {
- PyErr_Format(PyExc_RuntimeError, "FATAL: module compiled as "\
- "big endian, but detected different endianness at runtime");
- return -1;
- }
-#elif NPY_BYTE_ORDER == NPY_LITTLE_ENDIAN
- if (st != NPY_CPU_LITTLE) {
- PyErr_Format(PyExc_RuntimeError, "FATAL: module compiled as "\
- "little endian, but detected different endianness at runtime");
- return -1;
- }
-#endif
-
- return 0;
-}
-
-#if PY_VERSION_HEX >= 0x03000000
-#define NUMPY_IMPORT_ARRAY_RETVAL NULL
-#else
-#define NUMPY_IMPORT_ARRAY_RETVAL
-#endif
-
-#define import_array() {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, "numpy.core.multiarray failed to import"); return NUMPY_IMPORT_ARRAY_RETVAL; } }
-
-#define import_array1(ret) {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, "numpy.core.multiarray failed to import"); return ret; } }
-
-#define import_array2(msg, ret) {if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, msg); return ret; } }
-
-#endif
-
-#endif
diff --git a/include/numpy/__ufunc_api.h b/include/numpy/__ufunc_api.h
deleted file mode 100644
index fd81d07..0000000
--- a/include/numpy/__ufunc_api.h
+++ /dev/null
@@ -1,323 +0,0 @@
-
-#ifdef _UMATHMODULE
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
-extern NPY_NO_EXPORT PyTypeObject PyUFunc_Type;
-#else
-NPY_NO_EXPORT PyTypeObject PyUFunc_Type;
-#endif
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- extern NPY_NO_EXPORT PyTypeObject PyUFunc_Type;
-#else
- NPY_NO_EXPORT PyTypeObject PyUFunc_Type;
-#endif
-
-NPY_NO_EXPORT PyObject * PyUFunc_FromFuncAndData \
- (PyUFuncGenericFunction *, void **, char *, int, int, int, int, char *, char *, int);
-NPY_NO_EXPORT int PyUFunc_RegisterLoopForType \
- (PyUFuncObject *, int, PyUFuncGenericFunction, int *, void *);
-NPY_NO_EXPORT int PyUFunc_GenericFunction \
- (PyUFuncObject *, PyObject *, PyObject *, PyArrayObject **);
-NPY_NO_EXPORT void PyUFunc_f_f_As_d_d \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_d_d \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_f_f \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_g_g \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_F_F_As_D_D \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_F_F \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_D_D \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_G_G \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_O_O \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_ff_f_As_dd_d \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_ff_f \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_dd_d \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_gg_g \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_FF_F_As_DD_D \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_DD_D \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_FF_F \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_GG_G \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_OO_O \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_O_O_method \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_OO_O_method \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_On_Om \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT int PyUFunc_GetPyValues \
- (char *, int *, int *, PyObject **);
-NPY_NO_EXPORT int PyUFunc_checkfperr \
- (int, PyObject *, int *);
-NPY_NO_EXPORT void PyUFunc_clearfperr \
- (void);
-NPY_NO_EXPORT int PyUFunc_getfperr \
- (void);
-NPY_NO_EXPORT int PyUFunc_handlefperr \
- (int, PyObject *, int, int *);
-NPY_NO_EXPORT int PyUFunc_ReplaceLoopBySignature \
- (PyUFuncObject *, PyUFuncGenericFunction, int *, PyUFuncGenericFunction *);
-NPY_NO_EXPORT PyObject * PyUFunc_FromFuncAndDataAndSignature \
- (PyUFuncGenericFunction *, void **, char *, int, int, int, int, char *, char *, int, const char *);
-NPY_NO_EXPORT int PyUFunc_SetUsesArraysAsData \
- (void **, size_t);
-NPY_NO_EXPORT void PyUFunc_e_e \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_e_e_As_f_f \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_e_e_As_d_d \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_ee_e \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_ee_e_As_ff_f \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT void PyUFunc_ee_e_As_dd_d \
- (char **, npy_intp *, npy_intp *, void *);
-NPY_NO_EXPORT int PyUFunc_DefaultTypeResolver \
- (PyUFuncObject *, NPY_CASTING, PyArrayObject **, PyObject *, PyArray_Descr **);
-NPY_NO_EXPORT int PyUFunc_ValidateCasting \
- (PyUFuncObject *, NPY_CASTING, PyArrayObject **, PyArray_Descr **);
-
-#else
-
-#if defined(PY_UFUNC_UNIQUE_SYMBOL)
-#define PyUFunc_API PY_UFUNC_UNIQUE_SYMBOL
-#endif
-
-#if defined(NO_IMPORT) || defined(NO_IMPORT_UFUNC)
-extern void **PyUFunc_API;
-#else
-#if defined(PY_UFUNC_UNIQUE_SYMBOL)
-void **PyUFunc_API;
-#else
-static void **PyUFunc_API=NULL;
-#endif
-#endif
-
-#define PyUFunc_Type (*(PyTypeObject *)PyUFunc_API[0])
-#define PyUFunc_FromFuncAndData \
- (*(PyObject * (*)(PyUFuncGenericFunction *, void **, char *, int, int, int, int, char *, char *, int)) \
- PyUFunc_API[1])
-#define PyUFunc_RegisterLoopForType \
- (*(int (*)(PyUFuncObject *, int, PyUFuncGenericFunction, int *, void *)) \
- PyUFunc_API[2])
-#define PyUFunc_GenericFunction \
- (*(int (*)(PyUFuncObject *, PyObject *, PyObject *, PyArrayObject **)) \
- PyUFunc_API[3])
-#define PyUFunc_f_f_As_d_d \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[4])
-#define PyUFunc_d_d \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[5])
-#define PyUFunc_f_f \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[6])
-#define PyUFunc_g_g \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[7])
-#define PyUFunc_F_F_As_D_D \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[8])
-#define PyUFunc_F_F \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[9])
-#define PyUFunc_D_D \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[10])
-#define PyUFunc_G_G \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[11])
-#define PyUFunc_O_O \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[12])
-#define PyUFunc_ff_f_As_dd_d \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[13])
-#define PyUFunc_ff_f \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[14])
-#define PyUFunc_dd_d \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[15])
-#define PyUFunc_gg_g \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[16])
-#define PyUFunc_FF_F_As_DD_D \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[17])
-#define PyUFunc_DD_D \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[18])
-#define PyUFunc_FF_F \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[19])
-#define PyUFunc_GG_G \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[20])
-#define PyUFunc_OO_O \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[21])
-#define PyUFunc_O_O_method \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[22])
-#define PyUFunc_OO_O_method \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[23])
-#define PyUFunc_On_Om \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[24])
-#define PyUFunc_GetPyValues \
- (*(int (*)(char *, int *, int *, PyObject **)) \
- PyUFunc_API[25])
-#define PyUFunc_checkfperr \
- (*(int (*)(int, PyObject *, int *)) \
- PyUFunc_API[26])
-#define PyUFunc_clearfperr \
- (*(void (*)(void)) \
- PyUFunc_API[27])
-#define PyUFunc_getfperr \
- (*(int (*)(void)) \
- PyUFunc_API[28])
-#define PyUFunc_handlefperr \
- (*(int (*)(int, PyObject *, int, int *)) \
- PyUFunc_API[29])
-#define PyUFunc_ReplaceLoopBySignature \
- (*(int (*)(PyUFuncObject *, PyUFuncGenericFunction, int *, PyUFuncGenericFunction *)) \
- PyUFunc_API[30])
-#define PyUFunc_FromFuncAndDataAndSignature \
- (*(PyObject * (*)(PyUFuncGenericFunction *, void **, char *, int, int, int, int, char *, char *, int, const char *)) \
- PyUFunc_API[31])
-#define PyUFunc_SetUsesArraysAsData \
- (*(int (*)(void **, size_t)) \
- PyUFunc_API[32])
-#define PyUFunc_e_e \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[33])
-#define PyUFunc_e_e_As_f_f \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[34])
-#define PyUFunc_e_e_As_d_d \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[35])
-#define PyUFunc_ee_e \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[36])
-#define PyUFunc_ee_e_As_ff_f \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[37])
-#define PyUFunc_ee_e_As_dd_d \
- (*(void (*)(char **, npy_intp *, npy_intp *, void *)) \
- PyUFunc_API[38])
-#define PyUFunc_DefaultTypeResolver \
- (*(int (*)(PyUFuncObject *, NPY_CASTING, PyArrayObject **, PyObject *, PyArray_Descr **)) \
- PyUFunc_API[39])
-#define PyUFunc_ValidateCasting \
- (*(int (*)(PyUFuncObject *, NPY_CASTING, PyArrayObject **, PyArray_Descr **)) \
- PyUFunc_API[40])
-
-static int
-_import_umath(void)
-{
- PyObject *numpy = PyImport_ImportModule("numpy.core.umath");
- PyObject *c_api = NULL;
-
- if (numpy == NULL) {
- PyErr_SetString(PyExc_ImportError, "numpy.core.umath failed to import");
- return -1;
- }
- c_api = PyObject_GetAttrString(numpy, "_UFUNC_API");
- Py_DECREF(numpy);
- if (c_api == NULL) {
- PyErr_SetString(PyExc_AttributeError, "_UFUNC_API not found");
- return -1;
- }
-
-#if PY_VERSION_HEX >= 0x03000000
- if (!PyCapsule_CheckExact(c_api)) {
- PyErr_SetString(PyExc_RuntimeError, "_UFUNC_API is not PyCapsule object");
- Py_DECREF(c_api);
- return -1;
- }
- PyUFunc_API = (void **)PyCapsule_GetPointer(c_api, NULL);
-#else
- if (!PyCObject_Check(c_api)) {
- PyErr_SetString(PyExc_RuntimeError, "_UFUNC_API is not PyCObject object");
- Py_DECREF(c_api);
- return -1;
- }
- PyUFunc_API = (void **)PyCObject_AsVoidPtr(c_api);
-#endif
- Py_DECREF(c_api);
- if (PyUFunc_API == NULL) {
- PyErr_SetString(PyExc_RuntimeError, "_UFUNC_API is NULL pointer");
- return -1;
- }
- return 0;
-}
-
-#if PY_VERSION_HEX >= 0x03000000
-#define NUMPY_IMPORT_UMATH_RETVAL NULL
-#else
-#define NUMPY_IMPORT_UMATH_RETVAL
-#endif
-
-#define import_umath() \
- do {\
- UFUNC_NOFPE\
- if (_import_umath() < 0) {\
- PyErr_Print();\
- PyErr_SetString(PyExc_ImportError,\
- "numpy.core.umath failed to import");\
- return NUMPY_IMPORT_UMATH_RETVAL;\
- }\
- } while(0)
-
-#define import_umath1(ret) \
- do {\
- UFUNC_NOFPE\
- if (_import_umath() < 0) {\
- PyErr_Print();\
- PyErr_SetString(PyExc_ImportError,\
- "numpy.core.umath failed to import");\
- return ret;\
- }\
- } while(0)
-
-#define import_umath2(ret, msg) \
- do {\
- UFUNC_NOFPE\
- if (_import_umath() < 0) {\
- PyErr_Print();\
- PyErr_SetString(PyExc_ImportError, msg);\
- return ret;\
- }\
- } while(0)
-
-#define import_ufunc() \
- do {\
- UFUNC_NOFPE\
- if (_import_umath() < 0) {\
- PyErr_Print();\
- PyErr_SetString(PyExc_ImportError,\
- "numpy.core.umath failed to import");\
- }\
- } while(0)
-
-#endif
diff --git a/include/numpy/_neighborhood_iterator_imp.h b/include/numpy/_neighborhood_iterator_imp.h
deleted file mode 100644
index e8860cb..0000000
--- a/include/numpy/_neighborhood_iterator_imp.h
+++ /dev/null
@@ -1,90 +0,0 @@
-#ifndef _NPY_INCLUDE_NEIGHBORHOOD_IMP
-#error You should not include this header directly
-#endif
-/*
- * Private API (here for inline)
- */
-static NPY_INLINE int
-_PyArrayNeighborhoodIter_IncrCoord(PyArrayNeighborhoodIterObject* iter);
-
-/*
- * Update to next item of the iterator
- *
- * Note: this simply increment the coordinates vector, last dimension
- * incremented first , i.e, for dimension 3
- * ...
- * -1, -1, -1
- * -1, -1, 0
- * -1, -1, 1
- * ....
- * -1, 0, -1
- * -1, 0, 0
- * ....
- * 0, -1, -1
- * 0, -1, 0
- * ....
- */
-#define _UPDATE_COORD_ITER(c) \
- wb = iter->coordinates[c] < iter->bounds[c][1]; \
- if (wb) { \
- iter->coordinates[c] += 1; \
- return 0; \
- } \
- else { \
- iter->coordinates[c] = iter->bounds[c][0]; \
- }
-
-static NPY_INLINE int
-_PyArrayNeighborhoodIter_IncrCoord(PyArrayNeighborhoodIterObject* iter)
-{
- npy_intp i, wb;
-
- for (i = iter->nd - 1; i >= 0; --i) {
- _UPDATE_COORD_ITER(i)
- }
-
- return 0;
-}
-
-/*
- * Version optimized for 2d arrays, manual loop unrolling
- */
-static NPY_INLINE int
-_PyArrayNeighborhoodIter_IncrCoord2D(PyArrayNeighborhoodIterObject* iter)
-{
- npy_intp wb;
-
- _UPDATE_COORD_ITER(1)
- _UPDATE_COORD_ITER(0)
-
- return 0;
-}
-#undef _UPDATE_COORD_ITER
-
-/*
- * Advance to the next neighbour
- */
-static NPY_INLINE int
-PyArrayNeighborhoodIter_Next(PyArrayNeighborhoodIterObject* iter)
-{
- _PyArrayNeighborhoodIter_IncrCoord (iter);
- iter->dataptr = iter->translate((PyArrayIterObject*)iter, iter->coordinates);
-
- return 0;
-}
-
-/*
- * Reset functions
- */
-static NPY_INLINE int
-PyArrayNeighborhoodIter_Reset(PyArrayNeighborhoodIterObject* iter)
-{
- npy_intp i;
-
- for (i = 0; i < iter->nd; ++i) {
- iter->coordinates[i] = iter->bounds[i][0];
- }
- iter->dataptr = iter->translate((PyArrayIterObject*)iter, iter->coordinates);
-
- return 0;
-}
diff --git a/include/numpy/_numpyconfig.h b/include/numpy/_numpyconfig.h
deleted file mode 100644
index d55ffc3..0000000
--- a/include/numpy/_numpyconfig.h
+++ /dev/null
@@ -1,29 +0,0 @@
-#define NPY_SIZEOF_SHORT SIZEOF_SHORT
-#define NPY_SIZEOF_INT SIZEOF_INT
-#define NPY_SIZEOF_LONG SIZEOF_LONG
-#define NPY_SIZEOF_FLOAT 4
-#define NPY_SIZEOF_COMPLEX_FLOAT 8
-#define NPY_SIZEOF_DOUBLE 8
-#define NPY_SIZEOF_COMPLEX_DOUBLE 16
-#define NPY_SIZEOF_LONGDOUBLE 16
-#define NPY_SIZEOF_COMPLEX_LONGDOUBLE 32
-#define NPY_SIZEOF_PY_INTPTR_T 8
-#define NPY_SIZEOF_PY_LONG_LONG 8
-#define NPY_SIZEOF_LONGLONG 8
-#define NPY_NO_SMP 0
-#define NPY_HAVE_DECL_ISNAN
-#define NPY_HAVE_DECL_ISINF
-#define NPY_HAVE_DECL_ISFINITE
-#define NPY_HAVE_DECL_SIGNBIT
-#define NPY_USE_C99_COMPLEX 1
-#define NPY_HAVE_COMPLEX_DOUBLE 1
-#define NPY_HAVE_COMPLEX_FLOAT 1
-#define NPY_HAVE_COMPLEX_LONG_DOUBLE 1
-#define NPY_USE_C99_FORMATS 1
-#define NPY_VISIBILITY_HIDDEN __attribute__((visibility("hidden")))
-#define NPY_ABI_VERSION 0x01000009
-#define NPY_API_VERSION 0x00000007
-
-#ifndef __STDC_FORMAT_MACROS
-#define __STDC_FORMAT_MACROS 1
-#endif
diff --git a/include/numpy/arrayobject.h b/include/numpy/arrayobject.h
deleted file mode 100644
index a84766f..0000000
--- a/include/numpy/arrayobject.h
+++ /dev/null
@@ -1,22 +0,0 @@
-
-/* This expects the following variables to be defined (besides
- the usual ones from pyconfig.h
-
- SIZEOF_LONG_DOUBLE -- sizeof(long double) or sizeof(double) if no
- long double is present on platform.
- CHAR_BIT -- number of bits in a char (usually 8)
- (should be in limits.h)
-
-*/
-
-#ifndef Py_ARRAYOBJECT_H
-#define Py_ARRAYOBJECT_H
-
-#include "ndarrayobject.h"
-#include "npy_interrupt.h"
-
-#ifdef NPY_NO_PREFIX
-#include "noprefix.h"
-#endif
-
-#endif
diff --git a/include/numpy/arrayscalars.h b/include/numpy/arrayscalars.h
deleted file mode 100644
index 64450e7..0000000
--- a/include/numpy/arrayscalars.h
+++ /dev/null
@@ -1,175 +0,0 @@
-#ifndef _NPY_ARRAYSCALARS_H_
-#define _NPY_ARRAYSCALARS_H_
-
-#ifndef _MULTIARRAYMODULE
-typedef struct {
- PyObject_HEAD
- npy_bool obval;
-} PyBoolScalarObject;
-#endif
-
-
-typedef struct {
- PyObject_HEAD
- signed char obval;
-} PyByteScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- short obval;
-} PyShortScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- int obval;
-} PyIntScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- long obval;
-} PyLongScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_longlong obval;
-} PyLongLongScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- unsigned char obval;
-} PyUByteScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- unsigned short obval;
-} PyUShortScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- unsigned int obval;
-} PyUIntScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- unsigned long obval;
-} PyULongScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_ulonglong obval;
-} PyULongLongScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_half obval;
-} PyHalfScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- float obval;
-} PyFloatScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- double obval;
-} PyDoubleScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_longdouble obval;
-} PyLongDoubleScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_cfloat obval;
-} PyCFloatScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_cdouble obval;
-} PyCDoubleScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- npy_clongdouble obval;
-} PyCLongDoubleScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- PyObject * obval;
-} PyObjectScalarObject;
-
-typedef struct {
- PyObject_HEAD
- npy_datetime obval;
- PyArray_DatetimeMetaData obmeta;
-} PyDatetimeScalarObject;
-
-typedef struct {
- PyObject_HEAD
- npy_timedelta obval;
- PyArray_DatetimeMetaData obmeta;
-} PyTimedeltaScalarObject;
-
-
-typedef struct {
- PyObject_HEAD
- char obval;
-} PyScalarObject;
-
-#define PyStringScalarObject PyStringObject
-#define PyUnicodeScalarObject PyUnicodeObject
-
-typedef struct {
- PyObject_VAR_HEAD
- char *obval;
- PyArray_Descr *descr;
- int flags;
- PyObject *base;
-} PyVoidScalarObject;
-
-/* Macros
- PyScalarObject
- PyArrType_Type
- are defined in ndarrayobject.h
-*/
-
-#define PyArrayScalar_False ((PyObject *)(&(_PyArrayScalar_BoolValues[0])))
-#define PyArrayScalar_True ((PyObject *)(&(_PyArrayScalar_BoolValues[1])))
-#define PyArrayScalar_FromLong(i) \
- ((PyObject *)(&(_PyArrayScalar_BoolValues[((i)!=0)])))
-#define PyArrayScalar_RETURN_BOOL_FROM_LONG(i) \
- return Py_INCREF(PyArrayScalar_FromLong(i)), \
- PyArrayScalar_FromLong(i)
-#define PyArrayScalar_RETURN_FALSE \
- return Py_INCREF(PyArrayScalar_False), \
- PyArrayScalar_False
-#define PyArrayScalar_RETURN_TRUE \
- return Py_INCREF(PyArrayScalar_True), \
- PyArrayScalar_True
-
-#define PyArrayScalar_New(cls) \
- Py##cls##ArrType_Type.tp_alloc(&Py##cls##ArrType_Type, 0)
-#define PyArrayScalar_VAL(obj, cls) \
- ((Py##cls##ScalarObject *)obj)->obval
-#define PyArrayScalar_ASSIGN(obj, cls, val) \
- PyArrayScalar_VAL(obj, cls) = val
-
-#endif
diff --git a/include/numpy/halffloat.h b/include/numpy/halffloat.h
deleted file mode 100644
index 944f0ea..0000000
--- a/include/numpy/halffloat.h
+++ /dev/null
@@ -1,69 +0,0 @@
-#ifndef __NPY_HALFFLOAT_H__
-#define __NPY_HALFFLOAT_H__
-
-#include
-#include
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-/*
- * Half-precision routines
- */
-
-/* Conversions */
-float npy_half_to_float(npy_half h);
-double npy_half_to_double(npy_half h);
-npy_half npy_float_to_half(float f);
-npy_half npy_double_to_half(double d);
-/* Comparisons */
-int npy_half_eq(npy_half h1, npy_half h2);
-int npy_half_ne(npy_half h1, npy_half h2);
-int npy_half_le(npy_half h1, npy_half h2);
-int npy_half_lt(npy_half h1, npy_half h2);
-int npy_half_ge(npy_half h1, npy_half h2);
-int npy_half_gt(npy_half h1, npy_half h2);
-/* faster *_nonan variants for when you know h1 and h2 are not NaN */
-int npy_half_eq_nonan(npy_half h1, npy_half h2);
-int npy_half_lt_nonan(npy_half h1, npy_half h2);
-int npy_half_le_nonan(npy_half h1, npy_half h2);
-/* Miscellaneous functions */
-int npy_half_iszero(npy_half h);
-int npy_half_isnan(npy_half h);
-int npy_half_isinf(npy_half h);
-int npy_half_isfinite(npy_half h);
-int npy_half_signbit(npy_half h);
-npy_half npy_half_copysign(npy_half x, npy_half y);
-npy_half npy_half_spacing(npy_half h);
-npy_half npy_half_nextafter(npy_half x, npy_half y);
-
-/*
- * Half-precision constants
- */
-
-#define NPY_HALF_ZERO (0x0000u)
-#define NPY_HALF_PZERO (0x0000u)
-#define NPY_HALF_NZERO (0x8000u)
-#define NPY_HALF_ONE (0x3c00u)
-#define NPY_HALF_NEGONE (0xbc00u)
-#define NPY_HALF_PINF (0x7c00u)
-#define NPY_HALF_NINF (0xfc00u)
-#define NPY_HALF_NAN (0x7e00u)
-
-#define NPY_MAX_HALF (0x7bffu)
-
-/*
- * Bit-level conversions
- */
-
-npy_uint16 npy_floatbits_to_halfbits(npy_uint32 f);
-npy_uint16 npy_doublebits_to_halfbits(npy_uint64 d);
-npy_uint32 npy_halfbits_to_floatbits(npy_uint16 h);
-npy_uint64 npy_halfbits_to_doublebits(npy_uint16 h);
-
-#ifdef __cplusplus
-}
-#endif
-
-#endif
diff --git a/include/numpy/multiarray_api.txt b/include/numpy/multiarray_api.txt
deleted file mode 100644
index 7e588f0..0000000
--- a/include/numpy/multiarray_api.txt
+++ /dev/null
@@ -1,2375 +0,0 @@
-
-===========
-Numpy C-API
-===========
-::
-
- unsigned int
- PyArray_GetNDArrayCVersion(void )
-
-
-Included at the very first so not auto-grabbed and thus not labeled.
-
-::
-
- int
- PyArray_SetNumericOps(PyObject *dict)
-
-Set internal structure with number functions that all arrays will use
-
-::
-
- PyObject *
- PyArray_GetNumericOps(void )
-
-Get dictionary showing number functions that all arrays will use
-
-::
-
- int
- PyArray_INCREF(PyArrayObject *mp)
-
-For object arrays, increment all internal references.
-
-::
-
- int
- PyArray_XDECREF(PyArrayObject *mp)
-
-Decrement all internal references for object arrays.
-(or arrays with object fields)
-
-::
-
- void
- PyArray_SetStringFunction(PyObject *op, int repr)
-
-Set the array print function to be a Python function.
-
-::
-
- PyArray_Descr *
- PyArray_DescrFromType(int type)
-
-Get the PyArray_Descr structure for a type.
-
-::
-
- PyObject *
- PyArray_TypeObjectFromType(int type)
-
-Get a typeobject from a type-number -- can return NULL.
-
-New reference
-
-::
-
- char *
- PyArray_Zero(PyArrayObject *arr)
-
-Get pointer to zero of correct type for array.
-
-::
-
- char *
- PyArray_One(PyArrayObject *arr)
-
-Get pointer to one of correct type for array
-
-::
-
- PyObject *
- PyArray_CastToType(PyArrayObject *arr, PyArray_Descr *dtype, int
- is_f_order)
-
-For backward compatibility
-
-Cast an array using typecode structure.
-steals reference to at --- cannot be NULL
-
-This function always makes a copy of arr, even if the dtype
-doesn't change.
-
-::
-
- int
- PyArray_CastTo(PyArrayObject *out, PyArrayObject *mp)
-
-Cast to an already created array.
-
-::
-
- int
- PyArray_CastAnyTo(PyArrayObject *out, PyArrayObject *mp)
-
-Cast to an already created array. Arrays don't have to be "broadcastable"
-Only requirement is they have the same number of elements.
-
-::
-
- int
- PyArray_CanCastSafely(int fromtype, int totype)
-
-Check the type coercion rules.
-
-::
-
- npy_bool
- PyArray_CanCastTo(PyArray_Descr *from, PyArray_Descr *to)
-
-leaves reference count alone --- cannot be NULL
-
-PyArray_CanCastTypeTo is equivalent to this, but adds a 'casting'
-parameter.
-
-::
-
- int
- PyArray_ObjectType(PyObject *op, int minimum_type)
-
-Return the typecode of the array a Python object would be converted to
-
-Returns the type number the result should have, or NPY_NOTYPE on error.
-
-::
-
- PyArray_Descr *
- PyArray_DescrFromObject(PyObject *op, PyArray_Descr *mintype)
-
-new reference -- accepts NULL for mintype
-
-::
-
- PyArrayObject **
- PyArray_ConvertToCommonType(PyObject *op, int *retn)
-
-
-::
-
- PyArray_Descr *
- PyArray_DescrFromScalar(PyObject *sc)
-
-Return descr object from array scalar.
-
-New reference
-
-::
-
- PyArray_Descr *
- PyArray_DescrFromTypeObject(PyObject *type)
-
-
-::
-
- npy_intp
- PyArray_Size(PyObject *op)
-
-Compute the size of an array (in number of items)
-
-::
-
- PyObject *
- PyArray_Scalar(void *data, PyArray_Descr *descr, PyObject *base)
-
-Get scalar-equivalent to a region of memory described by a descriptor.
-
-::
-
- PyObject *
- PyArray_FromScalar(PyObject *scalar, PyArray_Descr *outcode)
-
-Get 0-dim array from scalar
-
-0-dim array from array-scalar object
-always contains a copy of the data
-unless outcode is NULL, it is of void type and the referrer does
-not own it either.
-
-steals reference to outcode
-
-::
-
- void
- PyArray_ScalarAsCtype(PyObject *scalar, void *ctypeptr)
-
-Convert to c-type
-
-no error checking is performed -- ctypeptr must be same type as scalar
-in case of flexible type, the data is not copied
-into ctypeptr which is expected to be a pointer to pointer
-
-::
-
- int
- PyArray_CastScalarToCtype(PyObject *scalar, void
- *ctypeptr, PyArray_Descr *outcode)
-
-Cast Scalar to c-type
-
-The output buffer must be large-enough to receive the value
-Even for flexible types which is different from ScalarAsCtype
-where only a reference for flexible types is returned
-
-This may not work right on narrow builds for NumPy unicode scalars.
-
-::
-
- int
- PyArray_CastScalarDirect(PyObject *scalar, PyArray_Descr
- *indescr, void *ctypeptr, int outtype)
-
-Cast Scalar to c-type
-
-::
-
- PyObject *
- PyArray_ScalarFromObject(PyObject *object)
-
-Get an Array Scalar From a Python Object
-
-Returns NULL if unsuccessful but error is only set if another error occurred.
-Currently only Numeric-like object supported.
-
-::
-
- PyArray_VectorUnaryFunc *
- PyArray_GetCastFunc(PyArray_Descr *descr, int type_num)
-
-Get a cast function to cast from the input descriptor to the
-output type_number (must be a registered data-type).
-Returns NULL if un-successful.
-
-::
-
- PyObject *
- PyArray_FromDims(int nd, int *d, int type)
-
-Construct an empty array from dimensions and typenum
-
-::
-
- PyObject *
- PyArray_FromDimsAndDataAndDescr(int nd, int *d, PyArray_Descr
- *descr, char *data)
-
-Like FromDimsAndData but uses the Descr structure instead of typecode
-as input.
-
-::
-
- PyObject *
- PyArray_FromAny(PyObject *op, PyArray_Descr *newtype, int
- min_depth, int max_depth, int flags, PyObject
- *context)
-
-Does not check for NPY_ARRAY_ENSURECOPY and NPY_ARRAY_NOTSWAPPED in flags
-Steals a reference to newtype --- which can be NULL
-
-::
-
- PyObject *
- PyArray_EnsureArray(PyObject *op)
-
-This is a quick wrapper around PyArray_FromAny(op, NULL, 0, 0, ENSUREARRAY)
-that special cases Arrays and PyArray_Scalars up front
-It *steals a reference* to the object
-It also guarantees that the result is PyArray_Type
-Because it decrefs op if any conversion needs to take place
-so it can be used like PyArray_EnsureArray(some_function(...))
-
-::
-
- PyObject *
- PyArray_EnsureAnyArray(PyObject *op)
-
-
-::
-
- PyObject *
- PyArray_FromFile(FILE *fp, PyArray_Descr *dtype, npy_intp num, char
- *sep)
-
-
-Given a ``FILE *`` pointer ``fp``, and a ``PyArray_Descr``, return an
-array corresponding to the data encoded in that file.
-
-If the dtype is NULL, the default array type is used (double).
-If non-null, the reference is stolen.
-
-The number of elements to read is given as ``num``; if it is < 0, then
-then as many as possible are read.
-
-If ``sep`` is NULL or empty, then binary data is assumed, else
-text data, with ``sep`` as the separator between elements. Whitespace in
-the separator matches any length of whitespace in the text, and a match
-for whitespace around the separator is added.
-
-For memory-mapped files, use the buffer interface. No more data than
-necessary is read by this routine.
-
-::
-
- PyObject *
- PyArray_FromString(char *data, npy_intp slen, PyArray_Descr
- *dtype, npy_intp num, char *sep)
-
-
-Given a pointer to a string ``data``, a string length ``slen``, and
-a ``PyArray_Descr``, return an array corresponding to the data
-encoded in that string.
-
-If the dtype is NULL, the default array type is used (double).
-If non-null, the reference is stolen.
-
-If ``slen`` is < 0, then the end of string is used for text data.
-It is an error for ``slen`` to be < 0 for binary data (since embedded NULLs
-would be the norm).
-
-The number of elements to read is given as ``num``; if it is < 0, then
-then as many as possible are read.
-
-If ``sep`` is NULL or empty, then binary data is assumed, else
-text data, with ``sep`` as the separator between elements. Whitespace in
-the separator matches any length of whitespace in the text, and a match
-for whitespace around the separator is added.
-
-::
-
- PyObject *
- PyArray_FromBuffer(PyObject *buf, PyArray_Descr *type, npy_intp
- count, npy_intp offset)
-
-
-::
-
- PyObject *
- PyArray_FromIter(PyObject *obj, PyArray_Descr *dtype, npy_intp count)
-
-
-steals a reference to dtype (which cannot be NULL)
-
-::
-
- PyObject *
- PyArray_Return(PyArrayObject *mp)
-
-
-Return either an array or the appropriate Python object if the array
-is 0d and matches a Python type.
-
-::
-
- PyObject *
- PyArray_GetField(PyArrayObject *self, PyArray_Descr *typed, int
- offset)
-
-Get a subset of bytes from each element of the array
-
-::
-
- int
- PyArray_SetField(PyArrayObject *self, PyArray_Descr *dtype, int
- offset, PyObject *val)
-
-Set a subset of bytes from each element of the array
-
-::
-
- PyObject *
- PyArray_Byteswap(PyArrayObject *self, npy_bool inplace)
-
-
-::
-
- PyObject *
- PyArray_Resize(PyArrayObject *self, PyArray_Dims *newshape, int
- refcheck, NPY_ORDER order)
-
-Resize (reallocate data). Only works if nothing else is referencing this
-array and it is contiguous. If refcheck is 0, then the reference count is
-not checked and assumed to be 1. You still must own this data and have no
-weak-references and no base object.
-
-::
-
- int
- PyArray_MoveInto(PyArrayObject *dst, PyArrayObject *src)
-
-Move the memory of one array into another, allowing for overlapping data.
-
-Returns 0 on success, negative on failure.
-
-::
-
- int
- PyArray_CopyInto(PyArrayObject *dst, PyArrayObject *src)
-
-Copy an Array into another array.
-Broadcast to the destination shape if necessary.
-
-Returns 0 on success, -1 on failure.
-
-::
-
- int
- PyArray_CopyAnyInto(PyArrayObject *dst, PyArrayObject *src)
-
-Copy an Array into another array -- memory must not overlap
-Does not require src and dest to have "broadcastable" shapes
-(only the same number of elements).
-
-TODO: For NumPy 2.0, this could accept an order parameter which
-only allows NPY_CORDER and NPY_FORDER. Could also rename
-this to CopyAsFlat to make the name more intuitive.
-
-Returns 0 on success, -1 on error.
-
-::
-
- int
- PyArray_CopyObject(PyArrayObject *dest, PyObject *src_object)
-
-
-::
-
- PyObject *
- PyArray_NewCopy(PyArrayObject *obj, NPY_ORDER order)
-
-Copy an array.
-
-::
-
- PyObject *
- PyArray_ToList(PyArrayObject *self)
-
-To List
-
-::
-
- PyObject *
- PyArray_ToString(PyArrayObject *self, NPY_ORDER order)
-
-
-::
-
- int
- PyArray_ToFile(PyArrayObject *self, FILE *fp, char *sep, char *format)
-
-To File
-
-::
-
- int
- PyArray_Dump(PyObject *self, PyObject *file, int protocol)
-
-
-::
-
- PyObject *
- PyArray_Dumps(PyObject *self, int protocol)
-
-
-::
-
- int
- PyArray_ValidType(int type)
-
-Is the typenum valid?
-
-::
-
- void
- PyArray_UpdateFlags(PyArrayObject *ret, int flagmask)
-
-Update Several Flags at once.
-
-::
-
- PyObject *
- PyArray_New(PyTypeObject *subtype, int nd, npy_intp *dims, int
- type_num, npy_intp *strides, void *data, int itemsize, int
- flags, PyObject *obj)
-
-Generic new array creation routine.
-
-::
-
- PyObject *
- PyArray_NewFromDescr(PyTypeObject *subtype, PyArray_Descr *descr, int
- nd, npy_intp *dims, npy_intp *strides, void
- *data, int flags, PyObject *obj)
-
-Generic new array creation routine.
-
-steals a reference to descr (even on failure)
-
-::
-
- PyArray_Descr *
- PyArray_DescrNew(PyArray_Descr *base)
-
-base cannot be NULL
-
-::
-
- PyArray_Descr *
- PyArray_DescrNewFromType(int type_num)
-
-
-::
-
- double
- PyArray_GetPriority(PyObject *obj, double default_)
-
-Get Priority from object
-
-::
-
- PyObject *
- PyArray_IterNew(PyObject *obj)
-
-Get Iterator.
-
-::
-
- PyObject *
- PyArray_MultiIterNew(int n, ... )
-
-Get MultiIterator,
-
-::
-
- int
- PyArray_PyIntAsInt(PyObject *o)
-
-
-::
-
- npy_intp
- PyArray_PyIntAsIntp(PyObject *o)
-
-
-::
-
- int
- PyArray_Broadcast(PyArrayMultiIterObject *mit)
-
-
-::
-
- void
- PyArray_FillObjectArray(PyArrayObject *arr, PyObject *obj)
-
-Assumes contiguous
-
-::
-
- int
- PyArray_FillWithScalar(PyArrayObject *arr, PyObject *obj)
-
-
-::
-
- npy_bool
- PyArray_CheckStrides(int elsize, int nd, npy_intp numbytes, npy_intp
- offset, npy_intp *dims, npy_intp *newstrides)
-
-
-::
-
- PyArray_Descr *
- PyArray_DescrNewByteorder(PyArray_Descr *self, char newendian)
-
-
-returns a copy of the PyArray_Descr structure with the byteorder
-altered:
-no arguments: The byteorder is swapped (in all subfields as well)
-single argument: The byteorder is forced to the given state
-(in all subfields as well)
-
-Valid states: ('big', '>') or ('little' or '<')
-('native', or '=')
-
-If a descr structure with | is encountered it's own
-byte-order is not changed but any fields are:
-
-
-Deep bytorder change of a data-type descriptor
-Leaves reference count of self unchanged --- does not DECREF self ***
-
-::
-
- PyObject *
- PyArray_IterAllButAxis(PyObject *obj, int *inaxis)
-
-Get Iterator that iterates over all but one axis (don't use this with
-PyArray_ITER_GOTO1D). The axis will be over-written if negative
-with the axis having the smallest stride.
-
-::
-
- PyObject *
- PyArray_CheckFromAny(PyObject *op, PyArray_Descr *descr, int
- min_depth, int max_depth, int requires, PyObject
- *context)
-
-steals a reference to descr -- accepts NULL
-
-::
-
- PyObject *
- PyArray_FromArray(PyArrayObject *arr, PyArray_Descr *newtype, int
- flags)
-
-steals reference to newtype --- acc. NULL
-
-::
-
- PyObject *
- PyArray_FromInterface(PyObject *origin)
-
-
-::
-
- PyObject *
- PyArray_FromStructInterface(PyObject *input)
-
-
-::
-
- PyObject *
- PyArray_FromArrayAttr(PyObject *op, PyArray_Descr *typecode, PyObject
- *context)
-
-
-::
-
- NPY_SCALARKIND
- PyArray_ScalarKind(int typenum, PyArrayObject **arr)
-
-ScalarKind
-
-Returns the scalar kind of a type number, with an
-optional tweak based on the scalar value itself.
-If no scalar is provided, it returns INTPOS_SCALAR
-for both signed and unsigned integers, otherwise
-it checks the sign of any signed integer to choose
-INTNEG_SCALAR when appropriate.
-
-::
-
- int
- PyArray_CanCoerceScalar(int thistype, int neededtype, NPY_SCALARKIND
- scalar)
-
-
-Determines whether the data type 'thistype', with
-scalar kind 'scalar', can be coerced into 'neededtype'.
-
-::
-
- PyObject *
- PyArray_NewFlagsObject(PyObject *obj)
-
-
-Get New ArrayFlagsObject
-
-::
-
- npy_bool
- PyArray_CanCastScalar(PyTypeObject *from, PyTypeObject *to)
-
-See if array scalars can be cast.
-
-TODO: For NumPy 2.0, add a NPY_CASTING parameter.
-
-::
-
- int
- PyArray_CompareUCS4(npy_ucs4 *s1, npy_ucs4 *s2, size_t len)
-
-
-::
-
- int
- PyArray_RemoveSmallest(PyArrayMultiIterObject *multi)
-
-Adjusts previously broadcasted iterators so that the axis with
-the smallest sum of iterator strides is not iterated over.
-Returns dimension which is smallest in the range [0,multi->nd).
-A -1 is returned if multi->nd == 0.
-
-don't use with PyArray_ITER_GOTO1D because factors are not adjusted
-
-::
-
- int
- PyArray_ElementStrides(PyObject *obj)
-
-
-::
-
- void
- PyArray_Item_INCREF(char *data, PyArray_Descr *descr)
-
-
-::
-
- void
- PyArray_Item_XDECREF(char *data, PyArray_Descr *descr)
-
-
-::
-
- PyObject *
- PyArray_FieldNames(PyObject *fields)
-
-Return the tuple of ordered field names from a dictionary.
-
-::
-
- PyObject *
- PyArray_Transpose(PyArrayObject *ap, PyArray_Dims *permute)
-
-Return Transpose.
-
-::
-
- PyObject *
- PyArray_TakeFrom(PyArrayObject *self0, PyObject *indices0, int
- axis, PyArrayObject *out, NPY_CLIPMODE clipmode)
-
-Take
-
-::
-
- PyObject *
- PyArray_PutTo(PyArrayObject *self, PyObject*values0, PyObject
- *indices0, NPY_CLIPMODE clipmode)
-
-Put values into an array
-
-::
-
- PyObject *
- PyArray_PutMask(PyArrayObject *self, PyObject*values0, PyObject*mask0)
-
-Put values into an array according to a mask.
-
-::
-
- PyObject *
- PyArray_Repeat(PyArrayObject *aop, PyObject *op, int axis)
-
-Repeat the array.
-
-::
-
- PyObject *
- PyArray_Choose(PyArrayObject *ip, PyObject *op, PyArrayObject
- *out, NPY_CLIPMODE clipmode)
-
-
-::
-
- int
- PyArray_Sort(PyArrayObject *op, int axis, NPY_SORTKIND which)
-
-Sort an array in-place
-
-::
-
- PyObject *
- PyArray_ArgSort(PyArrayObject *op, int axis, NPY_SORTKIND which)
-
-ArgSort an array
-
-::
-
- PyObject *
- PyArray_SearchSorted(PyArrayObject *op1, PyObject *op2, NPY_SEARCHSIDE
- side, PyObject *perm)
-
-
-Search the sorted array op1 for the location of the items in op2. The
-result is an array of indexes, one for each element in op2, such that if
-the item were to be inserted in op1 just before that index the array
-would still be in sorted order.
-
-Parameters
-----------
-op1 : PyArrayObject *
-Array to be searched, must be 1-D.
-op2 : PyObject *
-Array of items whose insertion indexes in op1 are wanted
-side : {NPY_SEARCHLEFT, NPY_SEARCHRIGHT}
-If NPY_SEARCHLEFT, return first valid insertion indexes
-If NPY_SEARCHRIGHT, return last valid insertion indexes
-perm : PyObject *
-Permutation array that sorts op1 (optional)
-
-Returns
--------
-ret : PyObject *
-New reference to npy_intp array containing indexes where items in op2
-could be validly inserted into op1. NULL on error.
-
-Notes
------
-Binary search is used to find the indexes.
-
-::
-
- PyObject *
- PyArray_ArgMax(PyArrayObject *op, int axis, PyArrayObject *out)
-
-ArgMax
-
-::
-
- PyObject *
- PyArray_ArgMin(PyArrayObject *op, int axis, PyArrayObject *out)
-
-ArgMin
-
-::
-
- PyObject *
- PyArray_Reshape(PyArrayObject *self, PyObject *shape)
-
-Reshape
-
-::
-
- PyObject *
- PyArray_Newshape(PyArrayObject *self, PyArray_Dims *newdims, NPY_ORDER
- order)
-
-New shape for an array
-
-::
-
- PyObject *
- PyArray_Squeeze(PyArrayObject *self)
-
-
-return a new view of the array object with all of its unit-length
-dimensions squeezed out if needed, otherwise
-return the same array.
-
-::
-
- PyObject *
- PyArray_View(PyArrayObject *self, PyArray_Descr *type, PyTypeObject
- *pytype)
-
-View
-steals a reference to type -- accepts NULL
-
-::
-
- PyObject *
- PyArray_SwapAxes(PyArrayObject *ap, int a1, int a2)
-
-SwapAxes
-
-::
-
- PyObject *
- PyArray_Max(PyArrayObject *ap, int axis, PyArrayObject *out)
-
-Max
-
-::
-
- PyObject *
- PyArray_Min(PyArrayObject *ap, int axis, PyArrayObject *out)
-
-Min
-
-::
-
- PyObject *
- PyArray_Ptp(PyArrayObject *ap, int axis, PyArrayObject *out)
-
-Ptp
-
-::
-
- PyObject *
- PyArray_Mean(PyArrayObject *self, int axis, int rtype, PyArrayObject
- *out)
-
-Mean
-
-::
-
- PyObject *
- PyArray_Trace(PyArrayObject *self, int offset, int axis1, int
- axis2, int rtype, PyArrayObject *out)
-
-Trace
-
-::
-
- PyObject *
- PyArray_Diagonal(PyArrayObject *self, int offset, int axis1, int
- axis2)
-
-Diagonal
-
-In NumPy versions prior to 1.7, this function always returned a copy of
-the diagonal array. In 1.7, the code has been updated to compute a view
-onto 'self', but it still copies this array before returning, as well as
-setting the internal WARN_ON_WRITE flag. In a future version, it will
-simply return a view onto self.
-
-::
-
- PyObject *
- PyArray_Clip(PyArrayObject *self, PyObject *min, PyObject
- *max, PyArrayObject *out)
-
-Clip
-
-::
-
- PyObject *
- PyArray_Conjugate(PyArrayObject *self, PyArrayObject *out)
-
-Conjugate
-
-::
-
- PyObject *
- PyArray_Nonzero(PyArrayObject *self)
-
-Nonzero
-
-TODO: In NumPy 2.0, should make the iteration order a parameter.
-
-::
-
- PyObject *
- PyArray_Std(PyArrayObject *self, int axis, int rtype, PyArrayObject
- *out, int variance)
-
-Set variance to 1 to by-pass square-root calculation and return variance
-Std
-
-::
-
- PyObject *
- PyArray_Sum(PyArrayObject *self, int axis, int rtype, PyArrayObject
- *out)
-
-Sum
-
-::
-
- PyObject *
- PyArray_CumSum(PyArrayObject *self, int axis, int rtype, PyArrayObject
- *out)
-
-CumSum
-
-::
-
- PyObject *
- PyArray_Prod(PyArrayObject *self, int axis, int rtype, PyArrayObject
- *out)
-
-Prod
-
-::
-
- PyObject *
- PyArray_CumProd(PyArrayObject *self, int axis, int
- rtype, PyArrayObject *out)
-
-CumProd
-
-::
-
- PyObject *
- PyArray_All(PyArrayObject *self, int axis, PyArrayObject *out)
-
-All
-
-::
-
- PyObject *
- PyArray_Any(PyArrayObject *self, int axis, PyArrayObject *out)
-
-Any
-
-::
-
- PyObject *
- PyArray_Compress(PyArrayObject *self, PyObject *condition, int
- axis, PyArrayObject *out)
-
-Compress
-
-::
-
- PyObject *
- PyArray_Flatten(PyArrayObject *a, NPY_ORDER order)
-
-Flatten
-
-::
-
- PyObject *
- PyArray_Ravel(PyArrayObject *arr, NPY_ORDER order)
-
-Ravel
-Returns a contiguous array
-
-::
-
- npy_intp
- PyArray_MultiplyList(npy_intp *l1, int n)
-
-Multiply a List
-
-::
-
- int
- PyArray_MultiplyIntList(int *l1, int n)
-
-Multiply a List of ints
-
-::
-
- void *
- PyArray_GetPtr(PyArrayObject *obj, npy_intp*ind)
-
-Produce a pointer into array
-
-::
-
- int
- PyArray_CompareLists(npy_intp *l1, npy_intp *l2, int n)
-
-Compare Lists
-
-::
-
- int
- PyArray_AsCArray(PyObject **op, void *ptr, npy_intp *dims, int
- nd, PyArray_Descr*typedescr)
-
-Simulate a C-array
-steals a reference to typedescr -- can be NULL
-
-::
-
- int
- PyArray_As1D(PyObject **op, char **ptr, int *d1, int typecode)
-
-Convert to a 1D C-array
-
-::
-
- int
- PyArray_As2D(PyObject **op, char ***ptr, int *d1, int *d2, int
- typecode)
-
-Convert to a 2D C-array
-
-::
-
- int
- PyArray_Free(PyObject *op, void *ptr)
-
-Free pointers created if As2D is called
-
-::
-
- int
- PyArray_Converter(PyObject *object, PyObject **address)
-
-
-Useful to pass as converter function for O& processing in PyArgs_ParseTuple.
-
-This conversion function can be used with the "O&" argument for
-PyArg_ParseTuple. It will immediately return an object of array type
-or will convert to a NPY_ARRAY_CARRAY any other object.
-
-If you use PyArray_Converter, you must DECREF the array when finished
-as you get a new reference to it.
-
-::
-
- int
- PyArray_IntpFromSequence(PyObject *seq, npy_intp *vals, int maxvals)
-
-PyArray_IntpFromSequence
-Returns the number of dimensions or -1 if an error occurred.
-vals must be large enough to hold maxvals
-
-::
-
- PyObject *
- PyArray_Concatenate(PyObject *op, int axis)
-
-Concatenate
-
-Concatenate an arbitrary Python sequence into an array.
-op is a python object supporting the sequence interface.
-Its elements will be concatenated together to form a single
-multidimensional array. If axis is NPY_MAXDIMS or bigger, then
-each sequence object will be flattened before concatenation
-
-::
-
- PyObject *
- PyArray_InnerProduct(PyObject *op1, PyObject *op2)
-
-Numeric.innerproduct(a,v)
-
-::
-
- PyObject *
- PyArray_MatrixProduct(PyObject *op1, PyObject *op2)
-
-Numeric.matrixproduct(a,v)
-just like inner product but does the swapaxes stuff on the fly
-
-::
-
- PyObject *
- PyArray_CopyAndTranspose(PyObject *op)
-
-Copy and Transpose
-
-Could deprecate this function, as there isn't a speed benefit over
-calling Transpose and then Copy.
-
-::
-
- PyObject *
- PyArray_Correlate(PyObject *op1, PyObject *op2, int mode)
-
-Numeric.correlate(a1,a2,mode)
-
-::
-
- int
- PyArray_TypestrConvert(int itemsize, int gentype)
-
-Typestr converter
-
-::
-
- int
- PyArray_DescrConverter(PyObject *obj, PyArray_Descr **at)
-
-Get typenum from an object -- None goes to NPY_DEFAULT_TYPE
-This function takes a Python object representing a type and converts it
-to a the correct PyArray_Descr * structure to describe the type.
-
-Many objects can be used to represent a data-type which in NumPy is
-quite a flexible concept.
-
-This is the central code that converts Python objects to
-Type-descriptor objects that are used throughout numpy.
-
-Returns a new reference in *at, but the returned should not be
-modified as it may be one of the canonical immutable objects or
-a reference to the input obj.
-
-::
-
- int
- PyArray_DescrConverter2(PyObject *obj, PyArray_Descr **at)
-
-Get typenum from an object -- None goes to NULL
-
-::
-
- int
- PyArray_IntpConverter(PyObject *obj, PyArray_Dims *seq)
-
-Get intp chunk from sequence
-
-This function takes a Python sequence object and allocates and
-fills in an intp array with the converted values.
-
-Remember to free the pointer seq.ptr when done using
-PyDimMem_FREE(seq.ptr)**
-
-::
-
- int
- PyArray_BufferConverter(PyObject *obj, PyArray_Chunk *buf)
-
-Get buffer chunk from object
-
-this function takes a Python object which exposes the (single-segment)
-buffer interface and returns a pointer to the data segment
-
-You should increment the reference count by one of buf->base
-if you will hang on to a reference
-
-You only get a borrowed reference to the object. Do not free the
-memory...
-
-::
-
- int
- PyArray_AxisConverter(PyObject *obj, int *axis)
-
-Get axis from an object (possibly None) -- a converter function,
-
-See also PyArray_ConvertMultiAxis, which also handles a tuple of axes.
-
-::
-
- int
- PyArray_BoolConverter(PyObject *object, npy_bool *val)
-
-Convert an object to true / false
-
-::
-
- int
- PyArray_ByteorderConverter(PyObject *obj, char *endian)
-
-Convert object to endian
-
-::
-
- int
- PyArray_OrderConverter(PyObject *object, NPY_ORDER *val)
-
-Convert an object to FORTRAN / C / ANY / KEEP
-
-::
-
- unsigned char
- PyArray_EquivTypes(PyArray_Descr *type1, PyArray_Descr *type2)
-
-
-This function returns true if the two typecodes are
-equivalent (same basic kind and same itemsize).
-
-::
-
- PyObject *
- PyArray_Zeros(int nd, npy_intp *dims, PyArray_Descr *type, int
- is_f_order)
-
-Zeros
-
-steal a reference
-accepts NULL type
-
-::
-
- PyObject *
- PyArray_Empty(int nd, npy_intp *dims, PyArray_Descr *type, int
- is_f_order)
-
-Empty
-
-accepts NULL type
-steals referenct to type
-
-::
-
- PyObject *
- PyArray_Where(PyObject *condition, PyObject *x, PyObject *y)
-
-Where
-
-::
-
- PyObject *
- PyArray_Arange(double start, double stop, double step, int type_num)
-
-Arange,
-
-::
-
- PyObject *
- PyArray_ArangeObj(PyObject *start, PyObject *stop, PyObject
- *step, PyArray_Descr *dtype)
-
-
-ArangeObj,
-
-this doesn't change the references
-
-::
-
- int
- PyArray_SortkindConverter(PyObject *obj, NPY_SORTKIND *sortkind)
-
-Convert object to sort kind
-
-::
-
- PyObject *
- PyArray_LexSort(PyObject *sort_keys, int axis)
-
-LexSort an array providing indices that will sort a collection of arrays
-lexicographically. The first key is sorted on first, followed by the second key
--- requires that arg"merge"sort is available for each sort_key
-
-Returns an index array that shows the indexes for the lexicographic sort along
-the given axis.
-
-::
-
- PyObject *
- PyArray_Round(PyArrayObject *a, int decimals, PyArrayObject *out)
-
-Round
-
-::
-
- unsigned char
- PyArray_EquivTypenums(int typenum1, int typenum2)
-
-
-::
-
- int
- PyArray_RegisterDataType(PyArray_Descr *descr)
-
-Register Data type
-Does not change the reference count of descr
-
-::
-
- int
- PyArray_RegisterCastFunc(PyArray_Descr *descr, int
- totype, PyArray_VectorUnaryFunc *castfunc)
-
-Register Casting Function
-Replaces any function currently stored.
-
-::
-
- int
- PyArray_RegisterCanCast(PyArray_Descr *descr, int
- totype, NPY_SCALARKIND scalar)
-
-Register a type number indicating that a descriptor can be cast
-to it safely
-
-::
-
- void
- PyArray_InitArrFuncs(PyArray_ArrFuncs *f)
-
-Initialize arrfuncs to NULL
-
-::
-
- PyObject *
- PyArray_IntTupleFromIntp(int len, npy_intp *vals)
-
-PyArray_IntTupleFromIntp
-
-::
-
- int
- PyArray_TypeNumFromName(char *str)
-
-
-::
-
- int
- PyArray_ClipmodeConverter(PyObject *object, NPY_CLIPMODE *val)
-
-Convert an object to NPY_RAISE / NPY_CLIP / NPY_WRAP
-
-::
-
- int
- PyArray_OutputConverter(PyObject *object, PyArrayObject **address)
-
-Useful to pass as converter function for O& processing in
-PyArgs_ParseTuple for output arrays
-
-::
-
- PyObject *
- PyArray_BroadcastToShape(PyObject *obj, npy_intp *dims, int nd)
-
-Get Iterator broadcast to a particular shape
-
-::
-
- void
- _PyArray_SigintHandler(int signum)
-
-
-::
-
- void*
- _PyArray_GetSigintBuf(void )
-
-
-::
-
- int
- PyArray_DescrAlignConverter(PyObject *obj, PyArray_Descr **at)
-
-
-Get type-descriptor from an object forcing alignment if possible
-None goes to DEFAULT type.
-
-any object with the .fields attribute and/or .itemsize attribute (if the
-.fields attribute does not give the total size -- i.e. a partial record
-naming). If itemsize is given it must be >= size computed from fields
-
-The .fields attribute must return a convertible dictionary if present.
-Result inherits from NPY_VOID.
-
-::
-
- int
- PyArray_DescrAlignConverter2(PyObject *obj, PyArray_Descr **at)
-
-
-Get type-descriptor from an object forcing alignment if possible
-None goes to NULL.
-
-::
-
- int
- PyArray_SearchsideConverter(PyObject *obj, void *addr)
-
-Convert object to searchsorted side
-
-::
-
- PyObject *
- PyArray_CheckAxis(PyArrayObject *arr, int *axis, int flags)
-
-PyArray_CheckAxis
-
-check that axis is valid
-convert 0-d arrays to 1-d arrays
-
-::
-
- npy_intp
- PyArray_OverflowMultiplyList(npy_intp *l1, int n)
-
-Multiply a List of Non-negative numbers with over-flow detection.
-
-::
-
- int
- PyArray_CompareString(char *s1, char *s2, size_t len)
-
-
-::
-
- PyObject *
- PyArray_MultiIterFromObjects(PyObject **mps, int n, int nadd, ... )
-
-Get MultiIterator from array of Python objects and any additional
-
-PyObject **mps -- array of PyObjects
-int n - number of PyObjects in the array
-int nadd - number of additional arrays to include in the iterator.
-
-Returns a multi-iterator object.
-
-::
-
- int
- PyArray_GetEndianness(void )
-
-
-::
-
- unsigned int
- PyArray_GetNDArrayCFeatureVersion(void )
-
-Returns the built-in (at compilation time) C API version
-
-::
-
- PyObject *
- PyArray_Correlate2(PyObject *op1, PyObject *op2, int mode)
-
-correlate(a1,a2,mode)
-
-This function computes the usual correlation (correlate(a1, a2) !=
-correlate(a2, a1), and conjugate the second argument for complex inputs
-
-::
-
- PyObject*
- PyArray_NeighborhoodIterNew(PyArrayIterObject *x, npy_intp
- *bounds, int mode, PyArrayObject*fill)
-
-A Neighborhood Iterator object.
-
-::
-
- void
- PyArray_SetDatetimeParseFunction(PyObject *op)
-
-This function is scheduled to be removed
-
-TO BE REMOVED - NOT USED INTERNALLY.
-
-::
-
- void
- PyArray_DatetimeToDatetimeStruct(npy_datetime val, NPY_DATETIMEUNIT
- fr, npy_datetimestruct *result)
-
-Fill the datetime struct from the value and resolution unit.
-
-TO BE REMOVED - NOT USED INTERNALLY.
-
-::
-
- void
- PyArray_TimedeltaToTimedeltaStruct(npy_timedelta val, NPY_DATETIMEUNIT
- fr, npy_timedeltastruct *result)
-
-Fill the timedelta struct from the timedelta value and resolution unit.
-
-TO BE REMOVED - NOT USED INTERNALLY.
-
-::
-
- npy_datetime
- PyArray_DatetimeStructToDatetime(NPY_DATETIMEUNIT
- fr, npy_datetimestruct *d)
-
-Create a datetime value from a filled datetime struct and resolution unit.
-
-TO BE REMOVED - NOT USED INTERNALLY.
-
-::
-
- npy_datetime
- PyArray_TimedeltaStructToTimedelta(NPY_DATETIMEUNIT
- fr, npy_timedeltastruct *d)
-
-Create a timdelta value from a filled timedelta struct and resolution unit.
-
-TO BE REMOVED - NOT USED INTERNALLY.
-
-::
-
- NpyIter *
- NpyIter_New(PyArrayObject *op, npy_uint32 flags, NPY_ORDER
- order, NPY_CASTING casting, PyArray_Descr*dtype)
-
-Allocate a new iterator for one array object.
-
-::
-
- NpyIter *
- NpyIter_MultiNew(int nop, PyArrayObject **op_in, npy_uint32
- flags, NPY_ORDER order, NPY_CASTING
- casting, npy_uint32 *op_flags, PyArray_Descr
- **op_request_dtypes)
-
-Allocate a new iterator for more than one array object, using
-standard NumPy broadcasting rules and the default buffer size.
-
-::
-
- NpyIter *
- NpyIter_AdvancedNew(int nop, PyArrayObject **op_in, npy_uint32
- flags, NPY_ORDER order, NPY_CASTING
- casting, npy_uint32 *op_flags, PyArray_Descr
- **op_request_dtypes, int oa_ndim, int
- **op_axes, npy_intp *itershape, npy_intp
- buffersize)
-
-Allocate a new iterator for multiple array objects, and advanced
-options for controlling the broadcasting, shape, and buffer size.
-
-::
-
- NpyIter *
- NpyIter_Copy(NpyIter *iter)
-
-Makes a copy of the iterator
-
-::
-
- int
- NpyIter_Deallocate(NpyIter *iter)
-
-Deallocate an iterator
-
-::
-
- npy_bool
- NpyIter_HasDelayedBufAlloc(NpyIter *iter)
-
-Whether the buffer allocation is being delayed
-
-::
-
- npy_bool
- NpyIter_HasExternalLoop(NpyIter *iter)
-
-Whether the iterator handles the inner loop
-
-::
-
- int
- NpyIter_EnableExternalLoop(NpyIter *iter)
-
-Removes the inner loop handling (so HasExternalLoop returns true)
-
-::
-
- npy_intp *
- NpyIter_GetInnerStrideArray(NpyIter *iter)
-
-Get the array of strides for the inner loop (when HasExternalLoop is true)
-
-This function may be safely called without holding the Python GIL.
-
-::
-
- npy_intp *
- NpyIter_GetInnerLoopSizePtr(NpyIter *iter)
-
-Get a pointer to the size of the inner loop (when HasExternalLoop is true)
-
-This function may be safely called without holding the Python GIL.
-
-::
-
- int
- NpyIter_Reset(NpyIter *iter, char **errmsg)
-
-Resets the iterator to its initial state
-
-If errmsg is non-NULL, it should point to a variable which will
-receive the error message, and no Python exception will be set.
-This is so that the function can be called from code not holding
-the GIL.
-
-::
-
- int
- NpyIter_ResetBasePointers(NpyIter *iter, char **baseptrs, char
- **errmsg)
-
-Resets the iterator to its initial state, with new base data pointers.
-This function requires great caution.
-
-If errmsg is non-NULL, it should point to a variable which will
-receive the error message, and no Python exception will be set.
-This is so that the function can be called from code not holding
-the GIL.
-
-::
-
- int
- NpyIter_ResetToIterIndexRange(NpyIter *iter, npy_intp istart, npy_intp
- iend, char **errmsg)
-
-Resets the iterator to a new iterator index range
-
-If errmsg is non-NULL, it should point to a variable which will
-receive the error message, and no Python exception will be set.
-This is so that the function can be called from code not holding
-the GIL.
-
-::
-
- int
- NpyIter_GetNDim(NpyIter *iter)
-
-Gets the number of dimensions being iterated
-
-::
-
- int
- NpyIter_GetNOp(NpyIter *iter)
-
-Gets the number of operands being iterated
-
-::
-
- NpyIter_IterNextFunc *
- NpyIter_GetIterNext(NpyIter *iter, char **errmsg)
-
-Compute the specialized iteration function for an iterator
-
-If errmsg is non-NULL, it should point to a variable which will
-receive the error message, and no Python exception will be set.
-This is so that the function can be called from code not holding
-the GIL.
-
-::
-
- npy_intp
- NpyIter_GetIterSize(NpyIter *iter)
-
-Gets the number of elements being iterated
-
-::
-
- void
- NpyIter_GetIterIndexRange(NpyIter *iter, npy_intp *istart, npy_intp
- *iend)
-
-Gets the range of iteration indices being iterated
-
-::
-
- npy_intp
- NpyIter_GetIterIndex(NpyIter *iter)
-
-Gets the current iteration index
-
-::
-
- int
- NpyIter_GotoIterIndex(NpyIter *iter, npy_intp iterindex)
-
-Sets the iterator position to the specified iterindex,
-which matches the iteration order of the iterator.
-
-Returns NPY_SUCCEED on success, NPY_FAIL on failure.
-
-::
-
- npy_bool
- NpyIter_HasMultiIndex(NpyIter *iter)
-
-Whether the iterator is tracking a multi-index
-
-::
-
- int
- NpyIter_GetShape(NpyIter *iter, npy_intp *outshape)
-
-Gets the broadcast shape if a multi-index is being tracked by the iterator,
-otherwise gets the shape of the iteration as Fortran-order
-(fastest-changing index first).
-
-The reason Fortran-order is returned when a multi-index
-is not enabled is that this is providing a direct view into how
-the iterator traverses the n-dimensional space. The iterator organizes
-its memory from fastest index to slowest index, and when
-a multi-index is enabled, it uses a permutation to recover the original
-order.
-
-Returns NPY_SUCCEED or NPY_FAIL.
-
-::
-
- NpyIter_GetMultiIndexFunc *
- NpyIter_GetGetMultiIndex(NpyIter *iter, char **errmsg)
-
-Compute a specialized get_multi_index function for the iterator
-
-If errmsg is non-NULL, it should point to a variable which will
-receive the error message, and no Python exception will be set.
-This is so that the function can be called from code not holding
-the GIL.
-
-::
-
- int
- NpyIter_GotoMultiIndex(NpyIter *iter, npy_intp *multi_index)
-
-Sets the iterator to the specified multi-index, which must have the
-correct number of entries for 'ndim'. It is only valid
-when NPY_ITER_MULTI_INDEX was passed to the constructor. This operation
-fails if the multi-index is out of bounds.
-
-Returns NPY_SUCCEED on success, NPY_FAIL on failure.
-
-::
-
- int
- NpyIter_RemoveMultiIndex(NpyIter *iter)
-
-Removes multi-index support from an iterator.
-
-Returns NPY_SUCCEED or NPY_FAIL.
-
-::
-
- npy_bool
- NpyIter_HasIndex(NpyIter *iter)
-
-Whether the iterator is tracking an index
-
-::
-
- npy_bool
- NpyIter_IsBuffered(NpyIter *iter)
-
-Whether the iterator is buffered
-
-::
-
- npy_bool
- NpyIter_IsGrowInner(NpyIter *iter)
-
-Whether the inner loop can grow if buffering is unneeded
-
-::
-
- npy_intp
- NpyIter_GetBufferSize(NpyIter *iter)
-
-Gets the size of the buffer, or 0 if buffering is not enabled
-
-::
-
- npy_intp *
- NpyIter_GetIndexPtr(NpyIter *iter)
-
-Get a pointer to the index, if it is being tracked
-
-::
-
- int
- NpyIter_GotoIndex(NpyIter *iter, npy_intp flat_index)
-
-If the iterator is tracking an index, sets the iterator
-to the specified index.
-
-Returns NPY_SUCCEED on success, NPY_FAIL on failure.
-
-::
-
- char **
- NpyIter_GetDataPtrArray(NpyIter *iter)
-
-Get the array of data pointers (1 per object being iterated)
-
-This function may be safely called without holding the Python GIL.
-
-::
-
- PyArray_Descr **
- NpyIter_GetDescrArray(NpyIter *iter)
-
-Get the array of data type pointers (1 per object being iterated)
-
-::
-
- PyArrayObject **
- NpyIter_GetOperandArray(NpyIter *iter)
-
-Get the array of objects being iterated
-
-::
-
- PyArrayObject *
- NpyIter_GetIterView(NpyIter *iter, npy_intp i)
-
-Returns a view to the i-th object with the iterator's internal axes
-
-::
-
- void
- NpyIter_GetReadFlags(NpyIter *iter, char *outreadflags)
-
-Gets an array of read flags (1 per object being iterated)
-
-::
-
- void
- NpyIter_GetWriteFlags(NpyIter *iter, char *outwriteflags)
-
-Gets an array of write flags (1 per object being iterated)
-
-::
-
- void
- NpyIter_DebugPrint(NpyIter *iter)
-
-For debugging
-
-::
-
- npy_bool
- NpyIter_IterationNeedsAPI(NpyIter *iter)
-
-Whether the iteration loop, and in particular the iternext()
-function, needs API access. If this is true, the GIL must
-be retained while iterating.
-
-::
-
- void
- NpyIter_GetInnerFixedStrideArray(NpyIter *iter, npy_intp *out_strides)
-
-Get an array of strides which are fixed. Any strides which may
-change during iteration receive the value NPY_MAX_INTP. Once
-the iterator is ready to iterate, call this to get the strides
-which will always be fixed in the inner loop, then choose optimized
-inner loop functions which take advantage of those fixed strides.
-
-This function may be safely called without holding the Python GIL.
-
-::
-
- int
- NpyIter_RemoveAxis(NpyIter *iter, int axis)
-
-Removes an axis from iteration. This requires that NPY_ITER_MULTI_INDEX
-was set for iterator creation, and does not work if buffering is
-enabled. This function also resets the iterator to its initial state.
-
-Returns NPY_SUCCEED or NPY_FAIL.
-
-::
-
- npy_intp *
- NpyIter_GetAxisStrideArray(NpyIter *iter, int axis)
-
-Gets the array of strides for the specified axis.
-If the iterator is tracking a multi-index, gets the strides
-for the axis specified, otherwise gets the strides for
-the iteration axis as Fortran order (fastest-changing axis first).
-
-Returns NULL if an error occurs.
-
-::
-
- npy_bool
- NpyIter_RequiresBuffering(NpyIter *iter)
-
-Whether the iteration could be done with no buffering.
-
-::
-
- char **
- NpyIter_GetInitialDataPtrArray(NpyIter *iter)
-
-Get the array of data pointers (1 per object being iterated),
-directly into the arrays (never pointing to a buffer), for starting
-unbuffered iteration. This always returns the addresses for the
-iterator position as reset to iterator index 0.
-
-These pointers are different from the pointers accepted by
-NpyIter_ResetBasePointers, because the direction along some
-axes may have been reversed, requiring base offsets.
-
-This function may be safely called without holding the Python GIL.
-
-::
-
- int
- NpyIter_CreateCompatibleStrides(NpyIter *iter, npy_intp
- itemsize, npy_intp *outstrides)
-
-Builds a set of strides which are the same as the strides of an
-output array created using the NPY_ITER_ALLOCATE flag, where NULL
-was passed for op_axes. This is for data packed contiguously,
-but not necessarily in C or Fortran order. This should be used
-together with NpyIter_GetShape and NpyIter_GetNDim.
-
-A use case for this function is to match the shape and layout of
-the iterator and tack on one or more dimensions. For example,
-in order to generate a vector per input value for a numerical gradient,
-you pass in ndim*itemsize for itemsize, then add another dimension to
-the end with size ndim and stride itemsize. To do the Hessian matrix,
-you do the same thing but add two dimensions, or take advantage of
-the symmetry and pack it into 1 dimension with a particular encoding.
-
-This function may only be called if the iterator is tracking a multi-index
-and if NPY_ITER_DONT_NEGATE_STRIDES was used to prevent an axis from
-being iterated in reverse order.
-
-If an array is created with this method, simply adding 'itemsize'
-for each iteration will traverse the new array matching the
-iterator.
-
-Returns NPY_SUCCEED or NPY_FAIL.
-
-::
-
- int
- PyArray_CastingConverter(PyObject *obj, NPY_CASTING *casting)
-
-Convert any Python object, *obj*, to an NPY_CASTING enum.
-
-::
-
- npy_intp
- PyArray_CountNonzero(PyArrayObject *self)
-
-Counts the number of non-zero elements in the array.
-
-Returns -1 on error.
-
-::
-
- PyArray_Descr *
- PyArray_PromoteTypes(PyArray_Descr *type1, PyArray_Descr *type2)
-
-Produces the smallest size and lowest kind type to which both
-input types can be cast.
-
-::
-
- PyArray_Descr *
- PyArray_MinScalarType(PyArrayObject *arr)
-
-If arr is a scalar (has 0 dimensions) with a built-in number data type,
-finds the smallest type size/kind which can still represent its data.
-Otherwise, returns the array's data type.
-
-
-::
-
- PyArray_Descr *
- PyArray_ResultType(npy_intp narrs, PyArrayObject **arr, npy_intp
- ndtypes, PyArray_Descr **dtypes)
-
-Produces the result type of a bunch of inputs, using the UFunc
-type promotion rules. Use this function when you have a set of
-input arrays, and need to determine an output array dtype.
-
-If all the inputs are scalars (have 0 dimensions) or the maximum "kind"
-of the scalars is greater than the maximum "kind" of the arrays, does
-a regular type promotion.
-
-Otherwise, does a type promotion on the MinScalarType
-of all the inputs. Data types passed directly are treated as array
-types.
-
-
-::
-
- npy_bool
- PyArray_CanCastArrayTo(PyArrayObject *arr, PyArray_Descr
- *to, NPY_CASTING casting)
-
-Returns 1 if the array object may be cast to the given data type using
-the casting rule, 0 otherwise. This differs from PyArray_CanCastTo in
-that it handles scalar arrays (0 dimensions) specially, by checking
-their value.
-
-::
-
- npy_bool
- PyArray_CanCastTypeTo(PyArray_Descr *from, PyArray_Descr
- *to, NPY_CASTING casting)
-
-Returns true if data of type 'from' may be cast to data of type
-'to' according to the rule 'casting'.
-
-::
-
- PyArrayObject *
- PyArray_EinsteinSum(char *subscripts, npy_intp nop, PyArrayObject
- **op_in, PyArray_Descr *dtype, NPY_ORDER
- order, NPY_CASTING casting, PyArrayObject *out)
-
-This function provides summation of array elements according to
-the Einstein summation convention. For example:
-- trace(a) -> einsum("ii", a)
-- transpose(a) -> einsum("ji", a)
-- multiply(a,b) -> einsum(",", a, b)
-- inner(a,b) -> einsum("i,i", a, b)
-- outer(a,b) -> einsum("i,j", a, b)
-- matvec(a,b) -> einsum("ij,j", a, b)
-- matmat(a,b) -> einsum("ij,jk", a, b)
-
-subscripts: The string of subscripts for einstein summation.
-nop: The number of operands
-op_in: The array of operands
-dtype: Either NULL, or the data type to force the calculation as.
-order: The order for the calculation/the output axes.
-casting: What kind of casts should be permitted.
-out: Either NULL, or an array into which the output should be placed.
-
-By default, the labels get placed in alphabetical order
-at the end of the output. So, if c = einsum("i,j", a, b)
-then c[i,j] == a[i]*b[j], but if c = einsum("j,i", a, b)
-then c[i,j] = a[j]*b[i].
-
-Alternatively, you can control the output order or prevent
-an axis from being summed/force an axis to be summed by providing
-indices for the output. This allows us to turn 'trace' into
-'diag', for example.
-- diag(a) -> einsum("ii->i", a)
-- sum(a, axis=0) -> einsum("i...->", a)
-
-Subscripts at the beginning and end may be specified by
-putting an ellipsis "..." in the middle. For example,
-the function einsum("i...i", a) takes the diagonal of
-the first and last dimensions of the operand, and
-einsum("ij...,jk...->ik...") takes the matrix product using
-the first two indices of each operand instead of the last two.
-
-When there is only one operand, no axes being summed, and
-no output parameter, this function returns a view
-into the operand instead of making a copy.
-
-::
-
- PyObject *
- PyArray_NewLikeArray(PyArrayObject *prototype, NPY_ORDER
- order, PyArray_Descr *dtype, int subok)
-
-Creates a new array with the same shape as the provided one,
-with possible memory layout order and data type changes.
-
-prototype - The array the new one should be like.
-order - NPY_CORDER - C-contiguous result.
-NPY_FORTRANORDER - Fortran-contiguous result.
-NPY_ANYORDER - Fortran if prototype is Fortran, C otherwise.
-NPY_KEEPORDER - Keeps the axis ordering of prototype.
-dtype - If not NULL, overrides the data type of the result.
-subok - If 1, use the prototype's array subtype, otherwise
-always create a base-class array.
-
-NOTE: If dtype is not NULL, steals the dtype reference.
-
-::
-
- int
- PyArray_GetArrayParamsFromObject(PyObject *op, PyArray_Descr
- *requested_dtype, npy_bool
- writeable, PyArray_Descr
- **out_dtype, int *out_ndim, npy_intp
- *out_dims, PyArrayObject
- **out_arr, PyObject *context)
-
-Retrieves the array parameters for viewing/converting an arbitrary
-PyObject* to a NumPy array. This allows the "innate type and shape"
-of Python list-of-lists to be discovered without
-actually converting to an array.
-
-In some cases, such as structured arrays and the __array__ interface,
-a data type needs to be used to make sense of the object. When
-this is needed, provide a Descr for 'requested_dtype', otherwise
-provide NULL. This reference is not stolen. Also, if the requested
-dtype doesn't modify the interpretation of the input, out_dtype will
-still get the "innate" dtype of the object, not the dtype passed
-in 'requested_dtype'.
-
-If writing to the value in 'op' is desired, set the boolean
-'writeable' to 1. This raises an error when 'op' is a scalar, list
-of lists, or other non-writeable 'op'.
-
-Result: When success (0 return value) is returned, either out_arr
-is filled with a non-NULL PyArrayObject and
-the rest of the parameters are untouched, or out_arr is
-filled with NULL, and the rest of the parameters are
-filled.
-
-Typical usage:
-
-PyArrayObject *arr = NULL;
-PyArray_Descr *dtype = NULL;
-int ndim = 0;
-npy_intp dims[NPY_MAXDIMS];
-
-if (PyArray_GetArrayParamsFromObject(op, NULL, 1, &dtype,
-&ndim, &dims, &arr, NULL) < 0) {
-return NULL;
-}
-if (arr == NULL) {
-... validate/change dtype, validate flags, ndim, etc ...
-// Could make custom strides here too
-arr = PyArray_NewFromDescr(&PyArray_Type, dtype, ndim,
-dims, NULL,
-is_f_order ? NPY_ARRAY_F_CONTIGUOUS : 0,
-NULL);
-if (arr == NULL) {
-return NULL;
-}
-if (PyArray_CopyObject(arr, op) < 0) {
-Py_DECREF(arr);
-return NULL;
-}
-}
-else {
-... in this case the other parameters weren't filled, just
-validate and possibly copy arr itself ...
-}
-... use arr ...
-
-::
-
- int
- PyArray_ConvertClipmodeSequence(PyObject *object, NPY_CLIPMODE
- *modes, int n)
-
-Convert an object to an array of n NPY_CLIPMODE values.
-This is intended to be used in functions where a different mode
-could be applied to each axis, like in ravel_multi_index.
-
-::
-
- PyObject *
- PyArray_MatrixProduct2(PyObject *op1, PyObject
- *op2, PyArrayObject*out)
-
-Numeric.matrixproduct(a,v,out)
-just like inner product but does the swapaxes stuff on the fly
-
-::
-
- npy_bool
- NpyIter_IsFirstVisit(NpyIter *iter, int iop)
-
-Checks to see whether this is the first time the elements
-of the specified reduction operand which the iterator points at are
-being seen for the first time. The function returns
-a reasonable answer for reduction operands and when buffering is
-disabled. The answer may be incorrect for buffered non-reduction
-operands.
-
-This function is intended to be used in EXTERNAL_LOOP mode only,
-and will produce some wrong answers when that mode is not enabled.
-
-If this function returns true, the caller should also
-check the inner loop stride of the operand, because if
-that stride is 0, then only the first element of the innermost
-external loop is being visited for the first time.
-
-WARNING: For performance reasons, 'iop' is not bounds-checked,
-it is not confirmed that 'iop' is actually a reduction
-operand, and it is not confirmed that EXTERNAL_LOOP
-mode is enabled. These checks are the responsibility of
-the caller, and should be done outside of any inner loops.
-
-::
-
- int
- PyArray_SetBaseObject(PyArrayObject *arr, PyObject *obj)
-
-Sets the 'base' attribute of the array. This steals a reference
-to 'obj'.
-
-Returns 0 on success, -1 on failure.
-
-::
-
- void
- PyArray_CreateSortedStridePerm(int ndim, npy_intp
- *strides, npy_stride_sort_item
- *out_strideperm)
-
-
-This function populates the first ndim elements
-of strideperm with sorted descending by their absolute values.
-For example, the stride array (4, -2, 12) becomes
-[(2, 12), (0, 4), (1, -2)].
-
-::
-
- void
- PyArray_RemoveAxesInPlace(PyArrayObject *arr, npy_bool *flags)
-
-
-Removes the axes flagged as True from the array,
-modifying it in place. If an axis flagged for removal
-has a shape entry bigger than one, this effectively selects
-index zero for that axis.
-
-WARNING: If an axis flagged for removal has a shape equal to zero,
-the array will point to invalid memory. The caller must
-validate this!
-
-For example, this can be used to remove the reduction axes
-from a reduction result once its computation is complete.
-
-::
-
- void
- PyArray_DebugPrint(PyArrayObject *obj)
-
-Prints the raw data of the ndarray in a form useful for debugging
-low-level C issues.
-
-::
-
- int
- PyArray_FailUnlessWriteable(PyArrayObject *obj, const char *name)
-
-
-This function does nothing if obj is writeable, and raises an exception
-(and returns -1) if obj is not writeable. It may also do other
-house-keeping, such as issuing warnings on arrays which are transitioning
-to become views. Always call this function at some point before writing to
-an array.
-
-'name' is a name for the array, used to give better error
-messages. Something like "assignment destination", "output array", or even
-just "array".
-
-::
-
- int
- PyArray_SetUpdateIfCopyBase(PyArrayObject *arr, PyArrayObject *base)
-
-
-Precondition: 'arr' is a copy of 'base' (though possibly with different
-strides, ordering, etc.). This function sets the UPDATEIFCOPY flag and the
-->base pointer on 'arr', so that when 'arr' is destructed, it will copy any
-changes back to 'base'.
-
-Steals a reference to 'base'.
-
-Returns 0 on success, -1 on failure.
-
-::
-
- void *
- PyDataMem_NEW(size_t size)
-
-Allocates memory for array data.
-
-::
-
- void
- PyDataMem_FREE(void *ptr)
-
-Free memory for array data.
-
-::
-
- void *
- PyDataMem_RENEW(void *ptr, size_t size)
-
-Reallocate/resize memory for array data.
-
-::
-
- PyDataMem_EventHookFunc *
- PyDataMem_SetEventHook(PyDataMem_EventHookFunc *newhook, void
- *user_data, void **old_data)
-
-Sets the allocation event hook for numpy array data.
-Takes a PyDataMem_EventHookFunc *, which has the signature:
-void hook(void *old, void *new, size_t size, void *user_data).
-Also takes a void *user_data, and void **old_data.
-
-Returns a pointer to the previous hook or NULL. If old_data is
-non-NULL, the previous user_data pointer will be copied to it.
-
-If not NULL, hook will be called at the end of each PyDataMem_NEW/FREE/RENEW:
-result = PyDataMem_NEW(size) -> (*hook)(NULL, result, size, user_data)
-PyDataMem_FREE(ptr) -> (*hook)(ptr, NULL, 0, user_data)
-result = PyDataMem_RENEW(ptr, size) -> (*hook)(ptr, result, size, user_data)
-
-When the hook is called, the GIL will be held by the calling
-thread. The hook should be written to be reentrant, if it performs
-operations that might cause new allocation events (such as the
-creation/descruction numpy objects, or creating/destroying Python
-objects which might cause a gc)
-
diff --git a/include/numpy/ndarrayobject.h b/include/numpy/ndarrayobject.h
deleted file mode 100644
index f00dd77..0000000
--- a/include/numpy/ndarrayobject.h
+++ /dev/null
@@ -1,244 +0,0 @@
-/*
- * DON'T INCLUDE THIS DIRECTLY.
- */
-
-#ifndef NPY_NDARRAYOBJECT_H
-#define NPY_NDARRAYOBJECT_H
-#ifdef __cplusplus
-#define CONFUSE_EMACS {
-#define CONFUSE_EMACS2 }
-extern "C" CONFUSE_EMACS
-#undef CONFUSE_EMACS
-#undef CONFUSE_EMACS2
-/* ... otherwise a semi-smart identer (like emacs) tries to indent
- everything when you're typing */
-#endif
-
-#include "ndarraytypes.h"
-
-/* Includes the "function" C-API -- these are all stored in a
- list of pointers --- one for each file
- The two lists are concatenated into one in multiarray.
-
- They are available as import_array()
-*/
-
-#include "__multiarray_api.h"
-
-
-/* C-API that requries previous API to be defined */
-
-#define PyArray_DescrCheck(op) (((PyObject*)(op))->ob_type==&PyArrayDescr_Type)
-
-#define PyArray_Check(op) PyObject_TypeCheck(op, &PyArray_Type)
-#define PyArray_CheckExact(op) (((PyObject*)(op))->ob_type == &PyArray_Type)
-
-#define PyArray_HasArrayInterfaceType(op, type, context, out) \
- ((((out)=PyArray_FromStructInterface(op)) != Py_NotImplemented) || \
- (((out)=PyArray_FromInterface(op)) != Py_NotImplemented) || \
- (((out)=PyArray_FromArrayAttr(op, type, context)) != \
- Py_NotImplemented))
-
-#define PyArray_HasArrayInterface(op, out) \
- PyArray_HasArrayInterfaceType(op, NULL, NULL, out)
-
-#define PyArray_IsZeroDim(op) (PyArray_Check(op) && \
- (PyArray_NDIM((PyArrayObject *)op) == 0))
-
-#define PyArray_IsScalar(obj, cls) \
- (PyObject_TypeCheck(obj, &Py##cls##ArrType_Type))
-
-#define PyArray_CheckScalar(m) (PyArray_IsScalar(m, Generic) || \
- PyArray_IsZeroDim(m))
-
-#define PyArray_IsPythonNumber(obj) \
- (PyInt_Check(obj) || PyFloat_Check(obj) || PyComplex_Check(obj) || \
- PyLong_Check(obj) || PyBool_Check(obj))
-
-#define PyArray_IsPythonScalar(obj) \
- (PyArray_IsPythonNumber(obj) || PyString_Check(obj) || \
- PyUnicode_Check(obj))
-
-#define PyArray_IsAnyScalar(obj) \
- (PyArray_IsScalar(obj, Generic) || PyArray_IsPythonScalar(obj))
-
-#define PyArray_CheckAnyScalar(obj) (PyArray_IsPythonScalar(obj) || \
- PyArray_CheckScalar(obj))
-
-#define PyArray_IsIntegerScalar(obj) (PyInt_Check(obj) \
- || PyLong_Check(obj) \
- || PyArray_IsScalar((obj), Integer))
-
-
-#define PyArray_GETCONTIGUOUS(m) (PyArray_ISCONTIGUOUS(m) ? \
- Py_INCREF(m), (m) : \
- (PyArrayObject *)(PyArray_Copy(m)))
-
-#define PyArray_SAMESHAPE(a1,a2) ((PyArray_NDIM(a1) == PyArray_NDIM(a2)) && \
- PyArray_CompareLists(PyArray_DIMS(a1), \
- PyArray_DIMS(a2), \
- PyArray_NDIM(a1)))
-
-#define PyArray_SIZE(m) PyArray_MultiplyList(PyArray_DIMS(m), PyArray_NDIM(m))
-#define PyArray_NBYTES(m) (PyArray_ITEMSIZE(m) * PyArray_SIZE(m))
-#define PyArray_FROM_O(m) PyArray_FromAny(m, NULL, 0, 0, 0, NULL)
-
-#define PyArray_FROM_OF(m,flags) PyArray_CheckFromAny(m, NULL, 0, 0, flags, \
- NULL)
-
-#define PyArray_FROM_OT(m,type) PyArray_FromAny(m, \
- PyArray_DescrFromType(type), 0, 0, 0, NULL);
-
-#define PyArray_FROM_OTF(m, type, flags) \
- PyArray_FromAny(m, PyArray_DescrFromType(type), 0, 0, \
- (((flags) & NPY_ARRAY_ENSURECOPY) ? \
- ((flags) | NPY_ARRAY_DEFAULT) : (flags)), NULL)
-
-#define PyArray_FROMANY(m, type, min, max, flags) \
- PyArray_FromAny(m, PyArray_DescrFromType(type), min, max, \
- (((flags) & NPY_ARRAY_ENSURECOPY) ? \
- (flags) | NPY_ARRAY_DEFAULT : (flags)), NULL)
-
-#define PyArray_ZEROS(m, dims, type, is_f_order) \
- PyArray_Zeros(m, dims, PyArray_DescrFromType(type), is_f_order)
-
-#define PyArray_EMPTY(m, dims, type, is_f_order) \
- PyArray_Empty(m, dims, PyArray_DescrFromType(type), is_f_order)
-
-#define PyArray_FILLWBYTE(obj, val) memset(PyArray_DATA(obj), val, \
- PyArray_NBYTES(obj))
-
-#define PyArray_REFCOUNT(obj) (((PyObject *)(obj))->ob_refcnt)
-#define NPY_REFCOUNT PyArray_REFCOUNT
-#define NPY_MAX_ELSIZE (2 * NPY_SIZEOF_LONGDOUBLE)
-
-#define PyArray_ContiguousFromAny(op, type, min_depth, max_depth) \
- PyArray_FromAny(op, PyArray_DescrFromType(type), min_depth, \
- max_depth, NPY_ARRAY_DEFAULT, NULL)
-
-#define PyArray_EquivArrTypes(a1, a2) \
- PyArray_EquivTypes(PyArray_DESCR(a1), PyArray_DESCR(a2))
-
-#define PyArray_EquivByteorders(b1, b2) \
- (((b1) == (b2)) || (PyArray_ISNBO(b1) == PyArray_ISNBO(b2)))
-
-#define PyArray_SimpleNew(nd, dims, typenum) \
- PyArray_New(&PyArray_Type, nd, dims, typenum, NULL, NULL, 0, 0, NULL)
-
-#define PyArray_SimpleNewFromData(nd, dims, typenum, data) \
- PyArray_New(&PyArray_Type, nd, dims, typenum, NULL, \
- data, 0, NPY_ARRAY_CARRAY, NULL)
-
-#define PyArray_SimpleNewFromDescr(nd, dims, descr) \
- PyArray_NewFromDescr(&PyArray_Type, descr, nd, dims, \
- NULL, NULL, 0, NULL)
-
-#define PyArray_ToScalar(data, arr) \
- PyArray_Scalar(data, PyArray_DESCR(arr), (PyObject *)arr)
-
-
-/* These might be faster without the dereferencing of obj
- going on inside -- of course an optimizing compiler should
- inline the constants inside a for loop making it a moot point
-*/
-
-#define PyArray_GETPTR1(obj, i) ((void *)(PyArray_BYTES(obj) + \
- (i)*PyArray_STRIDES(obj)[0]))
-
-#define PyArray_GETPTR2(obj, i, j) ((void *)(PyArray_BYTES(obj) + \
- (i)*PyArray_STRIDES(obj)[0] + \
- (j)*PyArray_STRIDES(obj)[1]))
-
-#define PyArray_GETPTR3(obj, i, j, k) ((void *)(PyArray_BYTES(obj) + \
- (i)*PyArray_STRIDES(obj)[0] + \
- (j)*PyArray_STRIDES(obj)[1] + \
- (k)*PyArray_STRIDES(obj)[2]))
-
-#define PyArray_GETPTR4(obj, i, j, k, l) ((void *)(PyArray_BYTES(obj) + \
- (i)*PyArray_STRIDES(obj)[0] + \
- (j)*PyArray_STRIDES(obj)[1] + \
- (k)*PyArray_STRIDES(obj)[2] + \
- (l)*PyArray_STRIDES(obj)[3]))
-
-static NPY_INLINE void
-PyArray_XDECREF_ERR(PyArrayObject *arr)
-{
- if (arr != NULL) {
- if (PyArray_FLAGS(arr) & NPY_ARRAY_UPDATEIFCOPY) {
- PyArrayObject *base = (PyArrayObject *)PyArray_BASE(arr);
- PyArray_ENABLEFLAGS(base, NPY_ARRAY_WRITEABLE);
- PyArray_CLEARFLAGS(arr, NPY_ARRAY_UPDATEIFCOPY);
- }
- Py_DECREF(arr);
- }
-}
-
-#define PyArray_DESCR_REPLACE(descr) do { \
- PyArray_Descr *_new_; \
- _new_ = PyArray_DescrNew(descr); \
- Py_XDECREF(descr); \
- descr = _new_; \
- } while(0)
-
-/* Copy should always return contiguous array */
-#define PyArray_Copy(obj) PyArray_NewCopy(obj, NPY_CORDER)
-
-#define PyArray_FromObject(op, type, min_depth, max_depth) \
- PyArray_FromAny(op, PyArray_DescrFromType(type), min_depth, \
- max_depth, NPY_ARRAY_BEHAVED | \
- NPY_ARRAY_ENSUREARRAY, NULL)
-
-#define PyArray_ContiguousFromObject(op, type, min_depth, max_depth) \
- PyArray_FromAny(op, PyArray_DescrFromType(type), min_depth, \
- max_depth, NPY_ARRAY_DEFAULT | \
- NPY_ARRAY_ENSUREARRAY, NULL)
-
-#define PyArray_CopyFromObject(op, type, min_depth, max_depth) \
- PyArray_FromAny(op, PyArray_DescrFromType(type), min_depth, \
- max_depth, NPY_ARRAY_ENSURECOPY | \
- NPY_ARRAY_DEFAULT | \
- NPY_ARRAY_ENSUREARRAY, NULL)
-
-#define PyArray_Cast(mp, type_num) \
- PyArray_CastToType(mp, PyArray_DescrFromType(type_num), 0)
-
-#define PyArray_Take(ap, items, axis) \
- PyArray_TakeFrom(ap, items, axis, NULL, NPY_RAISE)
-
-#define PyArray_Put(ap, items, values) \
- PyArray_PutTo(ap, items, values, NPY_RAISE)
-
-/* Compatibility with old Numeric stuff -- don't use in new code */
-
-#define PyArray_FromDimsAndData(nd, d, type, data) \
- PyArray_FromDimsAndDataAndDescr(nd, d, PyArray_DescrFromType(type), \
- data)
-
-
-/*
- Check to see if this key in the dictionary is the "title"
- entry of the tuple (i.e. a duplicate dictionary entry in the fields
- dict.
-*/
-
-#define NPY_TITLE_KEY(key, value) ((PyTuple_GET_SIZE((value))==3) && \
- (PyTuple_GET_ITEM((value), 2) == (key)))
-
-
-/* Define python version independent deprecation macro */
-
-#if PY_VERSION_HEX >= 0x02050000
-#define DEPRECATE(msg) PyErr_WarnEx(PyExc_DeprecationWarning,msg,1)
-#define DEPRECATE_FUTUREWARNING(msg) PyErr_WarnEx(PyExc_FutureWarning,msg,1)
-#else
-#define DEPRECATE(msg) PyErr_Warn(PyExc_DeprecationWarning,msg)
-#define DEPRECATE_FUTUREWARNING(msg) PyErr_Warn(PyExc_FutureWarning,msg)
-#endif
-
-
-#ifdef __cplusplus
-}
-#endif
-
-
-#endif /* NPY_NDARRAYOBJECT_H */
diff --git a/include/numpy/ndarraytypes.h b/include/numpy/ndarraytypes.h
deleted file mode 100644
index 04d037e..0000000
--- a/include/numpy/ndarraytypes.h
+++ /dev/null
@@ -1,1731 +0,0 @@
-#ifndef NDARRAYTYPES_H
-#define NDARRAYTYPES_H
-
-/* numpyconfig.h is auto-generated by the installer */
-#include "numpyconfig.h"
-
-#include "npy_common.h"
-#include "npy_endian.h"
-#include "npy_cpu.h"
-#include "utils.h"
-
-#ifdef NPY_ENABLE_SEPARATE_COMPILATION
- #define NPY_NO_EXPORT NPY_VISIBILITY_HIDDEN
-#else
- #define NPY_NO_EXPORT static
-#endif
-
-/* Only use thread if configured in config and python supports it */
-#if defined WITH_THREAD && !NPY_NO_SMP
- #define NPY_ALLOW_THREADS 1
-#else
- #define NPY_ALLOW_THREADS 0
-#endif
-
-
-
-/*
- * There are several places in the code where an array of dimensions
- * is allocated statically. This is the size of that static
- * allocation.
- *
- * The array creation itself could have arbitrary dimensions but all
- * the places where static allocation is used would need to be changed
- * to dynamic (including inside of several structures)
- */
-
-#define NPY_MAXDIMS 32
-#define NPY_MAXARGS 32
-
-/* Used for Converter Functions "O&" code in ParseTuple */
-#define NPY_FAIL 0
-#define NPY_SUCCEED 1
-
-/*
- * Binary compatibility version number. This number is increased
- * whenever the C-API is changed such that binary compatibility is
- * broken, i.e. whenever a recompile of extension modules is needed.
- */
-#define NPY_VERSION NPY_ABI_VERSION
-
-/*
- * Minor API version. This number is increased whenever a change is
- * made to the C-API -- whether it breaks binary compatibility or not.
- * Some changes, such as adding a function pointer to the end of the
- * function table, can be made without breaking binary compatibility.
- * In this case, only the NPY_FEATURE_VERSION (*not* NPY_VERSION)
- * would be increased. Whenever binary compatibility is broken, both
- * NPY_VERSION and NPY_FEATURE_VERSION should be increased.
- */
-#define NPY_FEATURE_VERSION NPY_API_VERSION
-
-enum NPY_TYPES { NPY_BOOL=0,
- NPY_BYTE, NPY_UBYTE,
- NPY_SHORT, NPY_USHORT,
- NPY_INT, NPY_UINT,
- NPY_LONG, NPY_ULONG,
- NPY_LONGLONG, NPY_ULONGLONG,
- NPY_FLOAT, NPY_DOUBLE, NPY_LONGDOUBLE,
- NPY_CFLOAT, NPY_CDOUBLE, NPY_CLONGDOUBLE,
- NPY_OBJECT=17,
- NPY_STRING, NPY_UNICODE,
- NPY_VOID,
- /*
- * New 1.6 types appended, may be integrated
- * into the above in 2.0.
- */
- NPY_DATETIME, NPY_TIMEDELTA, NPY_HALF,
-
- NPY_NTYPES,
- NPY_NOTYPE,
- NPY_CHAR, /* special flag */
- NPY_USERDEF=256, /* leave room for characters */
-
- /* The number of types not including the new 1.6 types */
- NPY_NTYPES_ABI_COMPATIBLE=21
-};
-
-/* basetype array priority */
-#define NPY_PRIORITY 0.0
-
-/* default subtype priority */
-#define NPY_SUBTYPE_PRIORITY 1.0
-
-/* default scalar priority */
-#define NPY_SCALAR_PRIORITY -1000000.0
-
-/* How many floating point types are there (excluding half) */
-#define NPY_NUM_FLOATTYPE 3
-
-/*
- * These characters correspond to the array type and the struct
- * module
- */
-
-enum NPY_TYPECHAR {
- NPY_BOOLLTR = '?',
- NPY_BYTELTR = 'b',
- NPY_UBYTELTR = 'B',
- NPY_SHORTLTR = 'h',
- NPY_USHORTLTR = 'H',
- NPY_INTLTR = 'i',
- NPY_UINTLTR = 'I',
- NPY_LONGLTR = 'l',
- NPY_ULONGLTR = 'L',
- NPY_LONGLONGLTR = 'q',
- NPY_ULONGLONGLTR = 'Q',
- NPY_HALFLTR = 'e',
- NPY_FLOATLTR = 'f',
- NPY_DOUBLELTR = 'd',
- NPY_LONGDOUBLELTR = 'g',
- NPY_CFLOATLTR = 'F',
- NPY_CDOUBLELTR = 'D',
- NPY_CLONGDOUBLELTR = 'G',
- NPY_OBJECTLTR = 'O',
- NPY_STRINGLTR = 'S',
- NPY_STRINGLTR2 = 'a',
- NPY_UNICODELTR = 'U',
- NPY_VOIDLTR = 'V',
- NPY_DATETIMELTR = 'M',
- NPY_TIMEDELTALTR = 'm',
- NPY_CHARLTR = 'c',
-
- /*
- * No Descriptor, just a define -- this let's
- * Python users specify an array of integers
- * large enough to hold a pointer on the
- * platform
- */
- NPY_INTPLTR = 'p',
- NPY_UINTPLTR = 'P',
-
- /*
- * These are for dtype 'kinds', not dtype 'typecodes'
- * as the above are for.
- */
- NPY_GENBOOLLTR ='b',
- NPY_SIGNEDLTR = 'i',
- NPY_UNSIGNEDLTR = 'u',
- NPY_FLOATINGLTR = 'f',
- NPY_COMPLEXLTR = 'c'
-};
-
-typedef enum {
- NPY_QUICKSORT=0,
- NPY_HEAPSORT=1,
- NPY_MERGESORT=2
-} NPY_SORTKIND;
-#define NPY_NSORTS (NPY_MERGESORT + 1)
-
-
-typedef enum {
- NPY_SEARCHLEFT=0,
- NPY_SEARCHRIGHT=1
-} NPY_SEARCHSIDE;
-#define NPY_NSEARCHSIDES (NPY_SEARCHRIGHT + 1)
-
-
-typedef enum {
- NPY_NOSCALAR=-1,
- NPY_BOOL_SCALAR,
- NPY_INTPOS_SCALAR,
- NPY_INTNEG_SCALAR,
- NPY_FLOAT_SCALAR,
- NPY_COMPLEX_SCALAR,
- NPY_OBJECT_SCALAR
-} NPY_SCALARKIND;
-#define NPY_NSCALARKINDS (NPY_OBJECT_SCALAR + 1)
-
-/* For specifying array memory layout or iteration order */
-typedef enum {
- /* Fortran order if inputs are all Fortran, C otherwise */
- NPY_ANYORDER=-1,
- /* C order */
- NPY_CORDER=0,
- /* Fortran order */
- NPY_FORTRANORDER=1,
- /* An order as close to the inputs as possible */
- NPY_KEEPORDER=2
-} NPY_ORDER;
-
-/* For specifying allowed casting in operations which support it */
-typedef enum {
- /* Only allow identical types */
- NPY_NO_CASTING=0,
- /* Allow identical and byte swapped types */
- NPY_EQUIV_CASTING=1,
- /* Only allow safe casts */
- NPY_SAFE_CASTING=2,
- /* Allow safe casts or casts within the same kind */
- NPY_SAME_KIND_CASTING=3,
- /* Allow any casts */
- NPY_UNSAFE_CASTING=4,
-
- /*
- * Temporary internal definition only, will be removed in upcoming
- * release, see below
- * */
- NPY_INTERNAL_UNSAFE_CASTING_BUT_WARN_UNLESS_SAME_KIND = 100,
-} NPY_CASTING;
-
-typedef enum {
- NPY_CLIP=0,
- NPY_WRAP=1,
- NPY_RAISE=2
-} NPY_CLIPMODE;
-
-/* The special not-a-time (NaT) value */
-#define NPY_DATETIME_NAT NPY_MIN_INT64
-
-/*
- * Upper bound on the length of a DATETIME ISO 8601 string
- * YEAR: 21 (64-bit year)
- * MONTH: 3
- * DAY: 3
- * HOURS: 3
- * MINUTES: 3
- * SECONDS: 3
- * ATTOSECONDS: 1 + 3*6
- * TIMEZONE: 5
- * NULL TERMINATOR: 1
- */
-#define NPY_DATETIME_MAX_ISO8601_STRLEN (21+3*5+1+3*6+6+1)
-
-typedef enum {
- NPY_FR_Y = 0, /* Years */
- NPY_FR_M = 1, /* Months */
- NPY_FR_W = 2, /* Weeks */
- /* Gap where 1.6 NPY_FR_B (value 3) was */
- NPY_FR_D = 4, /* Days */
- NPY_FR_h = 5, /* hours */
- NPY_FR_m = 6, /* minutes */
- NPY_FR_s = 7, /* seconds */
- NPY_FR_ms = 8, /* milliseconds */
- NPY_FR_us = 9, /* microseconds */
- NPY_FR_ns = 10,/* nanoseconds */
- NPY_FR_ps = 11,/* picoseconds */
- NPY_FR_fs = 12,/* femtoseconds */
- NPY_FR_as = 13,/* attoseconds */
- NPY_FR_GENERIC = 14 /* Generic, unbound units, can convert to anything */
-} NPY_DATETIMEUNIT;
-
-/*
- * NOTE: With the NPY_FR_B gap for 1.6 ABI compatibility, NPY_DATETIME_NUMUNITS
- * is technically one more than the actual number of units.
- */
-#define NPY_DATETIME_NUMUNITS (NPY_FR_GENERIC + 1)
-#define NPY_DATETIME_DEFAULTUNIT NPY_FR_GENERIC
-
-/*
- * Business day conventions for mapping invalid business
- * days to valid business days.
- */
-typedef enum {
- /* Go forward in time to the following business day. */
- NPY_BUSDAY_FORWARD,
- NPY_BUSDAY_FOLLOWING = NPY_BUSDAY_FORWARD,
- /* Go backward in time to the preceding business day. */
- NPY_BUSDAY_BACKWARD,
- NPY_BUSDAY_PRECEDING = NPY_BUSDAY_BACKWARD,
- /*
- * Go forward in time to the following business day, unless it
- * crosses a month boundary, in which case go backward
- */
- NPY_BUSDAY_MODIFIEDFOLLOWING,
- /*
- * Go backward in time to the preceding business day, unless it
- * crosses a month boundary, in which case go forward.
- */
- NPY_BUSDAY_MODIFIEDPRECEDING,
- /* Produce a NaT for non-business days. */
- NPY_BUSDAY_NAT,
- /* Raise an exception for non-business days. */
- NPY_BUSDAY_RAISE
-} NPY_BUSDAY_ROLL;
-
-/************************************************************
- * NumPy Auxiliary Data for inner loops, sort functions, etc.
- ************************************************************/
-
-/*
- * When creating an auxiliary data struct, this should always appear
- * as the first member, like this:
- *
- * typedef struct {
- * NpyAuxData base;
- * double constant;
- * } constant_multiplier_aux_data;
- */
-typedef struct NpyAuxData_tag NpyAuxData;
-
-/* Function pointers for freeing or cloning auxiliary data */
-typedef void (NpyAuxData_FreeFunc) (NpyAuxData *);
-typedef NpyAuxData *(NpyAuxData_CloneFunc) (NpyAuxData *);
-
-struct NpyAuxData_tag {
- NpyAuxData_FreeFunc *free;
- NpyAuxData_CloneFunc *clone;
- /* To allow for a bit of expansion without breaking the ABI */
- void *reserved[2];
-};
-
-/* Macros to use for freeing and cloning auxiliary data */
-#define NPY_AUXDATA_FREE(auxdata) \
- do { \
- if ((auxdata) != NULL) { \
- (auxdata)->free(auxdata); \
- } \
- } while(0)
-#define NPY_AUXDATA_CLONE(auxdata) \
- ((auxdata)->clone(auxdata))
-
-#define NPY_ERR(str) fprintf(stderr, #str); fflush(stderr);
-#define NPY_ERR2(str) fprintf(stderr, str); fflush(stderr);
-
-#define NPY_STRINGIFY(x) #x
-#define NPY_TOSTRING(x) NPY_STRINGIFY(x)
-
- /*
- * Macros to define how array, and dimension/strides data is
- * allocated.
- */
-
- /* Data buffer - PyDataMem_NEW/FREE/RENEW are in multiarraymodule.c */
-
-#define NPY_USE_PYMEM 1
-
-#if NPY_USE_PYMEM == 1
-#define PyArray_malloc PyMem_Malloc
-#define PyArray_free PyMem_Free
-#define PyArray_realloc PyMem_Realloc
-#else
-#define PyArray_malloc malloc
-#define PyArray_free free
-#define PyArray_realloc realloc
-#endif
-
-/* Dimensions and strides */
-#define PyDimMem_NEW(size) \
- ((npy_intp *)PyArray_malloc(size*sizeof(npy_intp)))
-
-#define PyDimMem_FREE(ptr) PyArray_free(ptr)
-
-#define PyDimMem_RENEW(ptr,size) \
- ((npy_intp *)PyArray_realloc(ptr,size*sizeof(npy_intp)))
-
-/* forward declaration */
-struct _PyArray_Descr;
-
-/* These must deal with unaligned and swapped data if necessary */
-typedef PyObject * (PyArray_GetItemFunc) (void *, void *);
-typedef int (PyArray_SetItemFunc)(PyObject *, void *, void *);
-
-typedef void (PyArray_CopySwapNFunc)(void *, npy_intp, void *, npy_intp,
- npy_intp, int, void *);
-
-typedef void (PyArray_CopySwapFunc)(void *, void *, int, void *);
-typedef npy_bool (PyArray_NonzeroFunc)(void *, void *);
-
-
-/*
- * These assume aligned and notswapped data -- a buffer will be used
- * before or contiguous data will be obtained
- */
-
-typedef int (PyArray_CompareFunc)(const void *, const void *, void *);
-typedef int (PyArray_ArgFunc)(void*, npy_intp, npy_intp*, void *);
-
-typedef void (PyArray_DotFunc)(void *, npy_intp, void *, npy_intp, void *,
- npy_intp, void *);
-
-typedef void (PyArray_VectorUnaryFunc)(void *, void *, npy_intp, void *,
- void *);
-
-/*
- * XXX the ignore argument should be removed next time the API version
- * is bumped. It used to be the separator.
- */
-typedef int (PyArray_ScanFunc)(FILE *fp, void *dptr,
- char *ignore, struct _PyArray_Descr *);
-typedef int (PyArray_FromStrFunc)(char *s, void *dptr, char **endptr,
- struct _PyArray_Descr *);
-
-typedef int (PyArray_FillFunc)(void *, npy_intp, void *);
-
-typedef int (PyArray_SortFunc)(void *, npy_intp, void *);
-typedef int (PyArray_ArgSortFunc)(void *, npy_intp *, npy_intp, void *);
-
-typedef int (PyArray_FillWithScalarFunc)(void *, npy_intp, void *, void *);
-
-typedef int (PyArray_ScalarKindFunc)(void *);
-
-typedef void (PyArray_FastClipFunc)(void *in, npy_intp n_in, void *min,
- void *max, void *out);
-typedef void (PyArray_FastPutmaskFunc)(void *in, void *mask, npy_intp n_in,
- void *values, npy_intp nv);
-typedef int (PyArray_FastTakeFunc)(void *dest, void *src, npy_intp *indarray,
- npy_intp nindarray, npy_intp n_outer,
- npy_intp m_middle, npy_intp nelem,
- NPY_CLIPMODE clipmode);
-
-typedef struct {
- npy_intp *ptr;
- int len;
-} PyArray_Dims;
-
-typedef struct {
- /*
- * Functions to cast to most other standard types
- * Can have some NULL entries. The types
- * DATETIME, TIMEDELTA, and HALF go into the castdict
- * even though they are built-in.
- */
- PyArray_VectorUnaryFunc *cast[NPY_NTYPES_ABI_COMPATIBLE];
-
- /* The next four functions *cannot* be NULL */
-
- /*
- * Functions to get and set items with standard Python types
- * -- not array scalars
- */
- PyArray_GetItemFunc *getitem;
- PyArray_SetItemFunc *setitem;
-
- /*
- * Copy and/or swap data. Memory areas may not overlap
- * Use memmove first if they might
- */
- PyArray_CopySwapNFunc *copyswapn;
- PyArray_CopySwapFunc *copyswap;
-
- /*
- * Function to compare items
- * Can be NULL
- */
- PyArray_CompareFunc *compare;
-
- /*
- * Function to select largest
- * Can be NULL
- */
- PyArray_ArgFunc *argmax;
-
- /*
- * Function to compute dot product
- * Can be NULL
- */
- PyArray_DotFunc *dotfunc;
-
- /*
- * Function to scan an ASCII file and
- * place a single value plus possible separator
- * Can be NULL
- */
- PyArray_ScanFunc *scanfunc;
-
- /*
- * Function to read a single value from a string
- * and adjust the pointer; Can be NULL
- */
- PyArray_FromStrFunc *fromstr;
-
- /*
- * Function to determine if data is zero or not
- * If NULL a default version is
- * used at Registration time.
- */
- PyArray_NonzeroFunc *nonzero;
-
- /*
- * Used for arange.
- * Can be NULL.
- */
- PyArray_FillFunc *fill;
-
- /*
- * Function to fill arrays with scalar values
- * Can be NULL
- */
- PyArray_FillWithScalarFunc *fillwithscalar;
-
- /*
- * Sorting functions
- * Can be NULL
- */
- PyArray_SortFunc *sort[NPY_NSORTS];
- PyArray_ArgSortFunc *argsort[NPY_NSORTS];
-
- /*
- * Dictionary of additional casting functions
- * PyArray_VectorUnaryFuncs
- * which can be populated to support casting
- * to other registered types. Can be NULL
- */
- PyObject *castdict;
-
- /*
- * Functions useful for generalizing
- * the casting rules.
- * Can be NULL;
- */
- PyArray_ScalarKindFunc *scalarkind;
- int **cancastscalarkindto;
- int *cancastto;
-
- PyArray_FastClipFunc *fastclip;
- PyArray_FastPutmaskFunc *fastputmask;
- PyArray_FastTakeFunc *fasttake;
-
- /*
- * Function to select smallest
- * Can be NULL
- */
- PyArray_ArgFunc *argmin;
-
-} PyArray_ArrFuncs;
-
-/* The item must be reference counted when it is inserted or extracted. */
-#define NPY_ITEM_REFCOUNT 0x01
-/* Same as needing REFCOUNT */
-#define NPY_ITEM_HASOBJECT 0x01
-/* Convert to list for pickling */
-#define NPY_LIST_PICKLE 0x02
-/* The item is a POINTER */
-#define NPY_ITEM_IS_POINTER 0x04
-/* memory needs to be initialized for this data-type */
-#define NPY_NEEDS_INIT 0x08
-/* operations need Python C-API so don't give-up thread. */
-#define NPY_NEEDS_PYAPI 0x10
-/* Use f.getitem when extracting elements of this data-type */
-#define NPY_USE_GETITEM 0x20
-/* Use f.setitem when setting creating 0-d array from this data-type.*/
-#define NPY_USE_SETITEM 0x40
-/* A sticky flag specifically for structured arrays */
-#define NPY_ALIGNED_STRUCT 0x80
-
-/*
- *These are inherited for global data-type if any data-types in the
- * field have them
- */
-#define NPY_FROM_FIELDS (NPY_NEEDS_INIT | NPY_LIST_PICKLE | \
- NPY_ITEM_REFCOUNT | NPY_NEEDS_PYAPI)
-
-#define NPY_OBJECT_DTYPE_FLAGS (NPY_LIST_PICKLE | NPY_USE_GETITEM | \
- NPY_ITEM_IS_POINTER | NPY_ITEM_REFCOUNT | \
- NPY_NEEDS_INIT | NPY_NEEDS_PYAPI)
-
-#define PyDataType_FLAGCHK(dtype, flag) \
- (((dtype)->flags & (flag)) == (flag))
-
-#define PyDataType_REFCHK(dtype) \
- PyDataType_FLAGCHK(dtype, NPY_ITEM_REFCOUNT)
-
-typedef struct _PyArray_Descr {
- PyObject_HEAD
- /*
- * the type object representing an
- * instance of this type -- should not
- * be two type_numbers with the same type
- * object.
- */
- PyTypeObject *typeobj;
- /* kind for this type */
- char kind;
- /* unique-character representing this type */
- char type;
- /*
- * '>' (big), '<' (little), '|'
- * (not-applicable), or '=' (native).
- */
- char byteorder;
- /* flags describing data type */
- char flags;
- /* number representing this type */
- int type_num;
- /* element size (itemsize) for this type */
- int elsize;
- /* alignment needed for this type */
- int alignment;
- /*
- * Non-NULL if this type is
- * is an array (C-contiguous)
- * of some other type
- */
- struct _arr_descr *subarray;
- /*
- * The fields dictionary for this type
- * For statically defined descr this
- * is always Py_None
- */
- PyObject *fields;
- /*
- * An ordered tuple of field names or NULL
- * if no fields are defined
- */
- PyObject *names;
- /*
- * a table of functions specific for each
- * basic data descriptor
- */
- PyArray_ArrFuncs *f;
- /* Metadata about this dtype */
- PyObject *metadata;
- /*
- * Metadata specific to the C implementation
- * of the particular dtype. This was added
- * for NumPy 1.7.0.
- */
- NpyAuxData *c_metadata;
-} PyArray_Descr;
-
-typedef struct _arr_descr {
- PyArray_Descr *base;
- PyObject *shape; /* a tuple */
-} PyArray_ArrayDescr;
-
-/*
- * The main array object structure.
- *
- * It has been recommended to use the inline functions defined below
- * (PyArray_DATA and friends) to access fields here for a number of
- * releases. Direct access to the members themselves is deprecated.
- * To ensure that your code does not use deprecated access,
- * #define NPY_NO_DEPRECATED_API NPY_1_7_VERSION
- * (or NPY_1_8_VERSION or higher as required).
- */
-/* This struct will be moved to a private header in a future release */
-typedef struct tagPyArrayObject_fields {
- PyObject_HEAD
- /* Pointer to the raw data buffer */
- char *data;
- /* The number of dimensions, also called 'ndim' */
- int nd;
- /* The size in each dimension, also called 'shape' */
- npy_intp *dimensions;
- /*
- * Number of bytes to jump to get to the
- * next element in each dimension
- */
- npy_intp *strides;
- /*
- * This object is decref'd upon
- * deletion of array. Except in the
- * case of UPDATEIFCOPY which has
- * special handling.
- *
- * For views it points to the original
- * array, collapsed so no chains of
- * views occur.
- *
- * For creation from buffer object it
- * points to an object that shold be
- * decref'd on deletion
- *
- * For UPDATEIFCOPY flag this is an
- * array to-be-updated upon deletion
- * of this one
- */
- PyObject *base;
- /* Pointer to type structure */
- PyArray_Descr *descr;
- /* Flags describing array -- see below */
- int flags;
- /* For weak references */
- PyObject *weakreflist;
-} PyArrayObject_fields;
-
-/*
- * To hide the implementation details, we only expose
- * the Python struct HEAD.
- */
-#if !(defined(NPY_NO_DEPRECATED_API) && (NPY_API_VERSION <= NPY_NO_DEPRECATED_API))
-/*
- * Can't put this in npy_deprecated_api.h like the others.
- * PyArrayObject field access is deprecated as of NumPy 1.7.
- */
-typedef PyArrayObject_fields PyArrayObject;
-#else
-typedef struct tagPyArrayObject {
- PyObject_HEAD
-} PyArrayObject;
-#endif
-
-#define NPY_SIZEOF_PYARRAYOBJECT (sizeof(PyArrayObject_fields))
-
-/* Array Flags Object */
-typedef struct PyArrayFlagsObject {
- PyObject_HEAD
- PyObject *arr;
- int flags;
-} PyArrayFlagsObject;
-
-/* Mirrors buffer object to ptr */
-
-typedef struct {
- PyObject_HEAD
- PyObject *base;
- void *ptr;
- npy_intp len;
- int flags;
-} PyArray_Chunk;
-
-typedef struct {
- NPY_DATETIMEUNIT base;
- int num;
-} PyArray_DatetimeMetaData;
-
-typedef struct {
- NpyAuxData base;
- PyArray_DatetimeMetaData meta;
-} PyArray_DatetimeDTypeMetaData;
-
-/*
- * This structure contains an exploded view of a date-time value.
- * NaT is represented by year == NPY_DATETIME_NAT.
- */
-typedef struct {
- npy_int64 year;
- npy_int32 month, day, hour, min, sec, us, ps, as;
-} npy_datetimestruct;
-
-/* This is not used internally. */
-typedef struct {
- npy_int64 day;
- npy_int32 sec, us, ps, as;
-} npy_timedeltastruct;
-
-typedef int (PyArray_FinalizeFunc)(PyArrayObject *, PyObject *);
-
-/*
- * Means c-style contiguous (last index varies the fastest). The data
- * elements right after each other.
- *
- * This flag may be requested in constructor functions.
- * This flag may be tested for in PyArray_FLAGS(arr).
- */
-#define NPY_ARRAY_C_CONTIGUOUS 0x0001
-
-/*
- * Set if array is a contiguous Fortran array: the first index varies
- * the fastest in memory (strides array is reverse of C-contiguous
- * array)
- *
- * This flag may be requested in constructor functions.
- * This flag may be tested for in PyArray_FLAGS(arr).
- */
-#define NPY_ARRAY_F_CONTIGUOUS 0x0002
-
-/*
- * Note: all 0-d arrays are C_CONTIGUOUS and F_CONTIGUOUS. If a
- * 1-d array is C_CONTIGUOUS it is also F_CONTIGUOUS
- */
-
-/*
- * If set, the array owns the data: it will be free'd when the array
- * is deleted.
- *
- * This flag may be tested for in PyArray_FLAGS(arr).
- */
-#define NPY_ARRAY_OWNDATA 0x0004
-
-/*
- * An array never has the next four set; they're only used as parameter
- * flags to the the various FromAny functions
- *
- * This flag may be requested in constructor functions.
- */
-
-/* Cause a cast to occur regardless of whether or not it is safe. */
-#define NPY_ARRAY_FORCECAST 0x0010
-
-/*
- * Always copy the array. Returned arrays are always CONTIGUOUS,
- * ALIGNED, and WRITEABLE.
- *
- * This flag may be requested in constructor functions.
- */
-#define NPY_ARRAY_ENSURECOPY 0x0020
-
-/*
- * Make sure the returned array is a base-class ndarray
- *
- * This flag may be requested in constructor functions.
- */
-#define NPY_ARRAY_ENSUREARRAY 0x0040
-
-/*
- * Make sure that the strides are in units of the element size Needed
- * for some operations with record-arrays.
- *
- * This flag may be requested in constructor functions.
- */
-#define NPY_ARRAY_ELEMENTSTRIDES 0x0080
-
-/*
- * Array data is aligned on the appropiate memory address for the type
- * stored according to how the compiler would align things (e.g., an
- * array of integers (4 bytes each) starts on a memory address that's
- * a multiple of 4)
- *
- * This flag may be requested in constructor functions.
- * This flag may be tested for in PyArray_FLAGS(arr).
- */
-#define NPY_ARRAY_ALIGNED 0x0100
-
-/*
- * Array data has the native endianness
- *
- * This flag may be requested in constructor functions.
- */
-#define NPY_ARRAY_NOTSWAPPED 0x0200
-
-/*
- * Array data is writeable
- *
- * This flag may be requested in constructor functions.
- * This flag may be tested for in PyArray_FLAGS(arr).
- */
-#define NPY_ARRAY_WRITEABLE 0x0400
-
-/*
- * If this flag is set, then base contains a pointer to an array of
- * the same size that should be updated with the current contents of
- * this array when this array is deallocated
- *
- * This flag may be requested in constructor functions.
- * This flag may be tested for in PyArray_FLAGS(arr).
- */
-#define NPY_ARRAY_UPDATEIFCOPY 0x1000
-
-/*
- * NOTE: there are also internal flags defined in multiarray/arrayobject.h,
- * which start at bit 31 and work down.
- */
-
-#define NPY_ARRAY_BEHAVED (NPY_ARRAY_ALIGNED | \
- NPY_ARRAY_WRITEABLE)
-#define NPY_ARRAY_BEHAVED_NS (NPY_ARRAY_ALIGNED | \
- NPY_ARRAY_WRITEABLE | \
- NPY_ARRAY_NOTSWAPPED)
-#define NPY_ARRAY_CARRAY (NPY_ARRAY_C_CONTIGUOUS | \
- NPY_ARRAY_BEHAVED)
-#define NPY_ARRAY_CARRAY_RO (NPY_ARRAY_C_CONTIGUOUS | \
- NPY_ARRAY_ALIGNED)
-#define NPY_ARRAY_FARRAY (NPY_ARRAY_F_CONTIGUOUS | \
- NPY_ARRAY_BEHAVED)
-#define NPY_ARRAY_FARRAY_RO (NPY_ARRAY_F_CONTIGUOUS | \
- NPY_ARRAY_ALIGNED)
-#define NPY_ARRAY_DEFAULT (NPY_ARRAY_CARRAY)
-#define NPY_ARRAY_IN_ARRAY (NPY_ARRAY_CARRAY_RO)
-#define NPY_ARRAY_OUT_ARRAY (NPY_ARRAY_CARRAY)
-#define NPY_ARRAY_INOUT_ARRAY (NPY_ARRAY_CARRAY | \
- NPY_ARRAY_UPDATEIFCOPY)
-#define NPY_ARRAY_IN_FARRAY (NPY_ARRAY_FARRAY_RO)
-#define NPY_ARRAY_OUT_FARRAY (NPY_ARRAY_FARRAY)
-#define NPY_ARRAY_INOUT_FARRAY (NPY_ARRAY_FARRAY | \
- NPY_ARRAY_UPDATEIFCOPY)
-
-#define NPY_ARRAY_UPDATE_ALL (NPY_ARRAY_C_CONTIGUOUS | \
- NPY_ARRAY_F_CONTIGUOUS | \
- NPY_ARRAY_ALIGNED)
-
-/* This flag is for the array interface, not PyArrayObject */
-#define NPY_ARR_HAS_DESCR 0x0800
-
-
-
-
-/*
- * Size of internal buffers used for alignment Make BUFSIZE a multiple
- * of sizeof(npy_cdouble) -- usually 16 so that ufunc buffers are aligned
- */
-#define NPY_MIN_BUFSIZE ((int)sizeof(npy_cdouble))
-#define NPY_MAX_BUFSIZE (((int)sizeof(npy_cdouble))*1000000)
-#define NPY_BUFSIZE 8192
-/* buffer stress test size: */
-/*#define NPY_BUFSIZE 17*/
-
-#define PyArray_MAX(a,b) (((a)>(b))?(a):(b))
-#define PyArray_MIN(a,b) (((a)<(b))?(a):(b))
-#define PyArray_CLT(p,q) ((((p).real==(q).real) ? ((p).imag < (q).imag) : \
- ((p).real < (q).real)))
-#define PyArray_CGT(p,q) ((((p).real==(q).real) ? ((p).imag > (q).imag) : \
- ((p).real > (q).real)))
-#define PyArray_CLE(p,q) ((((p).real==(q).real) ? ((p).imag <= (q).imag) : \
- ((p).real <= (q).real)))
-#define PyArray_CGE(p,q) ((((p).real==(q).real) ? ((p).imag >= (q).imag) : \
- ((p).real >= (q).real)))
-#define PyArray_CEQ(p,q) (((p).real==(q).real) && ((p).imag == (q).imag))
-#define PyArray_CNE(p,q) (((p).real!=(q).real) || ((p).imag != (q).imag))
-
-/*
- * C API: consists of Macros and functions. The MACROS are defined
- * here.
- */
-
-
-#define PyArray_ISCONTIGUOUS(m) PyArray_CHKFLAGS(m, NPY_ARRAY_C_CONTIGUOUS)
-#define PyArray_ISWRITEABLE(m) PyArray_CHKFLAGS(m, NPY_ARRAY_WRITEABLE)
-#define PyArray_ISALIGNED(m) PyArray_CHKFLAGS(m, NPY_ARRAY_ALIGNED)
-
-#define PyArray_IS_C_CONTIGUOUS(m) PyArray_CHKFLAGS(m, NPY_ARRAY_C_CONTIGUOUS)
-#define PyArray_IS_F_CONTIGUOUS(m) PyArray_CHKFLAGS(m, NPY_ARRAY_F_CONTIGUOUS)
-
-#if NPY_ALLOW_THREADS
-#define NPY_BEGIN_ALLOW_THREADS Py_BEGIN_ALLOW_THREADS
-#define NPY_END_ALLOW_THREADS Py_END_ALLOW_THREADS
-#define NPY_BEGIN_THREADS_DEF PyThreadState *_save=NULL;
-#define NPY_BEGIN_THREADS do {_save = PyEval_SaveThread();} while (0);
-#define NPY_END_THREADS do {if (_save) PyEval_RestoreThread(_save);} while (0);
-
-#define NPY_BEGIN_THREADS_DESCR(dtype) \
- do {if (!(PyDataType_FLAGCHK(dtype, NPY_NEEDS_PYAPI))) \
- NPY_BEGIN_THREADS;} while (0);
-
-#define NPY_END_THREADS_DESCR(dtype) \
- do {if (!(PyDataType_FLAGCHK(dtype, NPY_NEEDS_PYAPI))) \
- NPY_END_THREADS; } while (0);
-
-#define NPY_ALLOW_C_API_DEF PyGILState_STATE __save__;
-#define NPY_ALLOW_C_API do {__save__ = PyGILState_Ensure();} while (0);
-#define NPY_DISABLE_C_API do {PyGILState_Release(__save__);} while (0);
-#else
-#define NPY_BEGIN_ALLOW_THREADS
-#define NPY_END_ALLOW_THREADS
-#define NPY_BEGIN_THREADS_DEF
-#define NPY_BEGIN_THREADS
-#define NPY_END_THREADS
-#define NPY_BEGIN_THREADS_DESCR(dtype)
-#define NPY_END_THREADS_DESCR(dtype)
-#define NPY_ALLOW_C_API_DEF
-#define NPY_ALLOW_C_API
-#define NPY_DISABLE_C_API
-#endif
-
-/**********************************
- * The nditer object, added in 1.6
- **********************************/
-
-/* The actual structure of the iterator is an internal detail */
-typedef struct NpyIter_InternalOnly NpyIter;
-
-/* Iterator function pointers that may be specialized */
-typedef int (NpyIter_IterNextFunc)(NpyIter *iter);
-typedef void (NpyIter_GetMultiIndexFunc)(NpyIter *iter,
- npy_intp *outcoords);
-
-/*** Global flags that may be passed to the iterator constructors ***/
-
-/* Track an index representing C order */
-#define NPY_ITER_C_INDEX 0x00000001
-/* Track an index representing Fortran order */
-#define NPY_ITER_F_INDEX 0x00000002
-/* Track a multi-index */
-#define NPY_ITER_MULTI_INDEX 0x00000004
-/* User code external to the iterator does the 1-dimensional innermost loop */
-#define NPY_ITER_EXTERNAL_LOOP 0x00000008
-/* Convert all the operands to a common data type */
-#define NPY_ITER_COMMON_DTYPE 0x00000010
-/* Operands may hold references, requiring API access during iteration */
-#define NPY_ITER_REFS_OK 0x00000020
-/* Zero-sized operands should be permitted, iteration checks IterSize for 0 */
-#define NPY_ITER_ZEROSIZE_OK 0x00000040
-/* Permits reductions (size-0 stride with dimension size > 1) */
-#define NPY_ITER_REDUCE_OK 0x00000080
-/* Enables sub-range iteration */
-#define NPY_ITER_RANGED 0x00000100
-/* Enables buffering */
-#define NPY_ITER_BUFFERED 0x00000200
-/* When buffering is enabled, grows the inner loop if possible */
-#define NPY_ITER_GROWINNER 0x00000400
-/* Delay allocation of buffers until first Reset* call */
-#define NPY_ITER_DELAY_BUFALLOC 0x00000800
-/* When NPY_KEEPORDER is specified, disable reversing negative-stride axes */
-#define NPY_ITER_DONT_NEGATE_STRIDES 0x00001000
-
-/*** Per-operand flags that may be passed to the iterator constructors ***/
-
-/* The operand will be read from and written to */
-#define NPY_ITER_READWRITE 0x00010000
-/* The operand will only be read from */
-#define NPY_ITER_READONLY 0x00020000
-/* The operand will only be written to */
-#define NPY_ITER_WRITEONLY 0x00040000
-/* The operand's data must be in native byte order */
-#define NPY_ITER_NBO 0x00080000
-/* The operand's data must be aligned */
-#define NPY_ITER_ALIGNED 0x00100000
-/* The operand's data must be contiguous (within the inner loop) */
-#define NPY_ITER_CONTIG 0x00200000
-/* The operand may be copied to satisfy requirements */
-#define NPY_ITER_COPY 0x00400000
-/* The operand may be copied with UPDATEIFCOPY to satisfy requirements */
-#define NPY_ITER_UPDATEIFCOPY 0x00800000
-/* Allocate the operand if it is NULL */
-#define NPY_ITER_ALLOCATE 0x01000000
-/* If an operand is allocated, don't use any subtype */
-#define NPY_ITER_NO_SUBTYPE 0x02000000
-/* This is a virtual array slot, operand is NULL but temporary data is there */
-#define NPY_ITER_VIRTUAL 0x04000000
-/* Require that the dimension match the iterator dimensions exactly */
-#define NPY_ITER_NO_BROADCAST 0x08000000
-/* A mask is being used on this array, affects buffer -> array copy */
-#define NPY_ITER_WRITEMASKED 0x10000000
-/* This array is the mask for all WRITEMASKED operands */
-#define NPY_ITER_ARRAYMASK 0x20000000
-
-#define NPY_ITER_GLOBAL_FLAGS 0x0000ffff
-#define NPY_ITER_PER_OP_FLAGS 0xffff0000
-
-
-/*****************************
- * Basic iterator object
- *****************************/
-
-/* FWD declaration */
-typedef struct PyArrayIterObject_tag PyArrayIterObject;
-
-/*
- * type of the function which translates a set of coordinates to a
- * pointer to the data
- */
-typedef char* (*npy_iter_get_dataptr_t)(PyArrayIterObject* iter, npy_intp*);
-
-struct PyArrayIterObject_tag {
- PyObject_HEAD
- int nd_m1; /* number of dimensions - 1 */
- npy_intp index, size;
- npy_intp coordinates[NPY_MAXDIMS];/* N-dimensional loop */
- npy_intp dims_m1[NPY_MAXDIMS]; /* ao->dimensions - 1 */
- npy_intp strides[NPY_MAXDIMS]; /* ao->strides or fake */
- npy_intp backstrides[NPY_MAXDIMS];/* how far to jump back */
- npy_intp factors[NPY_MAXDIMS]; /* shape factors */
- PyArrayObject *ao;
- char *dataptr; /* pointer to current item*/
- npy_bool contiguous;
-
- npy_intp bounds[NPY_MAXDIMS][2];
- npy_intp limits[NPY_MAXDIMS][2];
- npy_intp limits_sizes[NPY_MAXDIMS];
- npy_iter_get_dataptr_t translate;
-} ;
-
-
-/* Iterator API */
-#define PyArrayIter_Check(op) PyObject_TypeCheck(op, &PyArrayIter_Type)
-
-#define _PyAIT(it) ((PyArrayIterObject *)(it))
-#define PyArray_ITER_RESET(it) do { \
- _PyAIT(it)->index = 0; \
- _PyAIT(it)->dataptr = PyArray_BYTES(_PyAIT(it)->ao); \
- memset(_PyAIT(it)->coordinates, 0, \
- (_PyAIT(it)->nd_m1+1)*sizeof(npy_intp)); \
-} while (0)
-
-#define _PyArray_ITER_NEXT1(it) do { \
- (it)->dataptr += _PyAIT(it)->strides[0]; \
- (it)->coordinates[0]++; \
-} while (0)
-
-#define _PyArray_ITER_NEXT2(it) do { \
- if ((it)->coordinates[1] < (it)->dims_m1[1]) { \
- (it)->coordinates[1]++; \
- (it)->dataptr += (it)->strides[1]; \
- } \
- else { \
- (it)->coordinates[1] = 0; \
- (it)->coordinates[0]++; \
- (it)->dataptr += (it)->strides[0] - \
- (it)->backstrides[1]; \
- } \
-} while (0)
-
-#define _PyArray_ITER_NEXT3(it) do { \
- if ((it)->coordinates[2] < (it)->dims_m1[2]) { \
- (it)->coordinates[2]++; \
- (it)->dataptr += (it)->strides[2]; \
- } \
- else { \
- (it)->coordinates[2] = 0; \
- (it)->dataptr -= (it)->backstrides[2]; \
- if ((it)->coordinates[1] < (it)->dims_m1[1]) { \
- (it)->coordinates[1]++; \
- (it)->dataptr += (it)->strides[1]; \
- } \
- else { \
- (it)->coordinates[1] = 0; \
- (it)->coordinates[0]++; \
- (it)->dataptr += (it)->strides[0] \
- (it)->backstrides[1]; \
- } \
- } \
-} while (0)
-
-#define PyArray_ITER_NEXT(it) do { \
- _PyAIT(it)->index++; \
- if (_PyAIT(it)->nd_m1 == 0) { \
- _PyArray_ITER_NEXT1(_PyAIT(it)); \
- } \
- else if (_PyAIT(it)->contiguous) \
- _PyAIT(it)->dataptr += PyArray_DESCR(_PyAIT(it)->ao)->elsize; \
- else if (_PyAIT(it)->nd_m1 == 1) { \
- _PyArray_ITER_NEXT2(_PyAIT(it)); \
- } \
- else { \
- int __npy_i; \
- for (__npy_i=_PyAIT(it)->nd_m1; __npy_i >= 0; __npy_i--) { \
- if (_PyAIT(it)->coordinates[__npy_i] < \
- _PyAIT(it)->dims_m1[__npy_i]) { \
- _PyAIT(it)->coordinates[__npy_i]++; \
- _PyAIT(it)->dataptr += \
- _PyAIT(it)->strides[__npy_i]; \
- break; \
- } \
- else { \
- _PyAIT(it)->coordinates[__npy_i] = 0; \
- _PyAIT(it)->dataptr -= \
- _PyAIT(it)->backstrides[__npy_i]; \
- } \
- } \
- } \
-} while (0)
-
-#define PyArray_ITER_GOTO(it, destination) do { \
- int __npy_i; \
- _PyAIT(it)->index = 0; \
- _PyAIT(it)->dataptr = PyArray_BYTES(_PyAIT(it)->ao); \
- for (__npy_i = _PyAIT(it)->nd_m1; __npy_i>=0; __npy_i--) { \
- if (destination[__npy_i] < 0) { \
- destination[__npy_i] += \
- _PyAIT(it)->dims_m1[__npy_i]+1; \
- } \
- _PyAIT(it)->dataptr += destination[__npy_i] * \
- _PyAIT(it)->strides[__npy_i]; \
- _PyAIT(it)->coordinates[__npy_i] = \
- destination[__npy_i]; \
- _PyAIT(it)->index += destination[__npy_i] * \
- ( __npy_i==_PyAIT(it)->nd_m1 ? 1 : \
- _PyAIT(it)->dims_m1[__npy_i+1]+1) ; \
- } \
-} while (0)
-
-#define PyArray_ITER_GOTO1D(it, ind) do { \
- int __npy_i; \
- npy_intp __npy_ind = (npy_intp) (ind); \
- if (__npy_ind < 0) __npy_ind += _PyAIT(it)->size; \
- _PyAIT(it)->index = __npy_ind; \
- if (_PyAIT(it)->nd_m1 == 0) { \
- _PyAIT(it)->dataptr = PyArray_BYTES(_PyAIT(it)->ao) + \
- __npy_ind * _PyAIT(it)->strides[0]; \
- } \
- else if (_PyAIT(it)->contiguous) \
- _PyAIT(it)->dataptr = PyArray_BYTES(_PyAIT(it)->ao) + \
- __npy_ind * PyArray_DESCR(_PyAIT(it)->ao)->elsize; \
- else { \
- _PyAIT(it)->dataptr = PyArray_BYTES(_PyAIT(it)->ao); \
- for (__npy_i = 0; __npy_i<=_PyAIT(it)->nd_m1; \
- __npy_i++) { \
- _PyAIT(it)->dataptr += \
- (__npy_ind / _PyAIT(it)->factors[__npy_i]) \
- * _PyAIT(it)->strides[__npy_i]; \
- __npy_ind %= _PyAIT(it)->factors[__npy_i]; \
- } \
- } \
-} while (0)
-
-#define PyArray_ITER_DATA(it) ((void *)(_PyAIT(it)->dataptr))
-
-#define PyArray_ITER_NOTDONE(it) (_PyAIT(it)->index < _PyAIT(it)->size)
-
-
-/*
- * Any object passed to PyArray_Broadcast must be binary compatible
- * with this structure.
- */
-
-typedef struct {
- PyObject_HEAD
- int numiter; /* number of iters */
- npy_intp size; /* broadcasted size */
- npy_intp index; /* current index */
- int nd; /* number of dims */
- npy_intp dimensions[NPY_MAXDIMS]; /* dimensions */
- PyArrayIterObject *iters[NPY_MAXARGS]; /* iterators */
-} PyArrayMultiIterObject;
-
-#define _PyMIT(m) ((PyArrayMultiIterObject *)(m))
-#define PyArray_MultiIter_RESET(multi) do { \
- int __npy_mi; \
- _PyMIT(multi)->index = 0; \
- for (__npy_mi=0; __npy_mi < _PyMIT(multi)->numiter; __npy_mi++) { \
- PyArray_ITER_RESET(_PyMIT(multi)->iters[__npy_mi]); \
- } \
-} while (0)
-
-#define PyArray_MultiIter_NEXT(multi) do { \
- int __npy_mi; \
- _PyMIT(multi)->index++; \
- for (__npy_mi=0; __npy_mi < _PyMIT(multi)->numiter; __npy_mi++) { \
- PyArray_ITER_NEXT(_PyMIT(multi)->iters[__npy_mi]); \
- } \
-} while (0)
-
-#define PyArray_MultiIter_GOTO(multi, dest) do { \
- int __npy_mi; \
- for (__npy_mi=0; __npy_mi < _PyMIT(multi)->numiter; __npy_mi++) { \
- PyArray_ITER_GOTO(_PyMIT(multi)->iters[__npy_mi], dest); \
- } \
- _PyMIT(multi)->index = _PyMIT(multi)->iters[0]->index; \
-} while (0)
-
-#define PyArray_MultiIter_GOTO1D(multi, ind) do { \
- int __npy_mi; \
- for (__npy_mi=0; __npy_mi < _PyMIT(multi)->numiter; __npy_mi++) { \
- PyArray_ITER_GOTO1D(_PyMIT(multi)->iters[__npy_mi], ind); \
- } \
- _PyMIT(multi)->index = _PyMIT(multi)->iters[0]->index; \
-} while (0)
-
-#define PyArray_MultiIter_DATA(multi, i) \
- ((void *)(_PyMIT(multi)->iters[i]->dataptr))
-
-#define PyArray_MultiIter_NEXTi(multi, i) \
- PyArray_ITER_NEXT(_PyMIT(multi)->iters[i])
-
-#define PyArray_MultiIter_NOTDONE(multi) \
- (_PyMIT(multi)->index < _PyMIT(multi)->size)
-
-/* Store the information needed for fancy-indexing over an array */
-
-typedef struct {
- PyObject_HEAD
- /*
- * Multi-iterator portion --- needs to be present in this
- * order to work with PyArray_Broadcast
- */
-
- int numiter; /* number of index-array
- iterators */
- npy_intp size; /* size of broadcasted
- result */
- npy_intp index; /* current index */
- int nd; /* number of dims */
- npy_intp dimensions[NPY_MAXDIMS]; /* dimensions */
- PyArrayIterObject *iters[NPY_MAXDIMS]; /* index object
- iterators */
- PyArrayIterObject *ait; /* flat Iterator for
- underlying array */
-
- /* flat iterator for subspace (when numiter < nd) */
- PyArrayIterObject *subspace;
-
- /*
- * if subspace iteration, then this is the array of axes in
- * the underlying array represented by the index objects
- */
- int iteraxes[NPY_MAXDIMS];
- /*
- * if subspace iteration, the these are the coordinates to the
- * start of the subspace.
- */
- npy_intp bscoord[NPY_MAXDIMS];
-
- PyObject *indexobj; /* creating obj */
- int consec;
- char *dataptr;
-
-} PyArrayMapIterObject;
-
-enum {
- NPY_NEIGHBORHOOD_ITER_ZERO_PADDING,
- NPY_NEIGHBORHOOD_ITER_ONE_PADDING,
- NPY_NEIGHBORHOOD_ITER_CONSTANT_PADDING,
- NPY_NEIGHBORHOOD_ITER_CIRCULAR_PADDING,
- NPY_NEIGHBORHOOD_ITER_MIRROR_PADDING
-};
-
-typedef struct {
- PyObject_HEAD
-
- /*
- * PyArrayIterObject part: keep this in this exact order
- */
- int nd_m1; /* number of dimensions - 1 */
- npy_intp index, size;
- npy_intp coordinates[NPY_MAXDIMS];/* N-dimensional loop */
- npy_intp dims_m1[NPY_MAXDIMS]; /* ao->dimensions - 1 */
- npy_intp strides[NPY_MAXDIMS]; /* ao->strides or fake */
- npy_intp backstrides[NPY_MAXDIMS];/* how far to jump back */
- npy_intp factors[NPY_MAXDIMS]; /* shape factors */
- PyArrayObject *ao;
- char *dataptr; /* pointer to current item*/
- npy_bool contiguous;
-
- npy_intp bounds[NPY_MAXDIMS][2];
- npy_intp limits[NPY_MAXDIMS][2];
- npy_intp limits_sizes[NPY_MAXDIMS];
- npy_iter_get_dataptr_t translate;
-
- /*
- * New members
- */
- npy_intp nd;
-
- /* Dimensions is the dimension of the array */
- npy_intp dimensions[NPY_MAXDIMS];
-
- /*
- * Neighborhood points coordinates are computed relatively to the
- * point pointed by _internal_iter
- */
- PyArrayIterObject* _internal_iter;
- /*
- * To keep a reference to the representation of the constant value
- * for constant padding
- */
- char* constant;
-
- int mode;
-} PyArrayNeighborhoodIterObject;
-
-/*
- * Neighborhood iterator API
- */
-
-/* General: those work for any mode */
-static NPY_INLINE int
-PyArrayNeighborhoodIter_Reset(PyArrayNeighborhoodIterObject* iter);
-static NPY_INLINE int
-PyArrayNeighborhoodIter_Next(PyArrayNeighborhoodIterObject* iter);
-#if 0
-static NPY_INLINE int
-PyArrayNeighborhoodIter_Next2D(PyArrayNeighborhoodIterObject* iter);
-#endif
-
-/*
- * Include inline implementations - functions defined there are not
- * considered public API
- */
-#define _NPY_INCLUDE_NEIGHBORHOOD_IMP
-#include "_neighborhood_iterator_imp.h"
-#undef _NPY_INCLUDE_NEIGHBORHOOD_IMP
-
-/* The default array type */
-#define NPY_DEFAULT_TYPE NPY_DOUBLE
-
-/*
- * All sorts of useful ways to look into a PyArrayObject. It is recommended
- * to use PyArrayObject * objects instead of always casting from PyObject *,
- * for improved type checking.
- *
- * In many cases here the macro versions of the accessors are deprecated,
- * but can't be immediately changed to inline functions because the
- * preexisting macros accept PyObject * and do automatic casts. Inline
- * functions accepting PyArrayObject * provides for some compile-time
- * checking of correctness when working with these objects in C.
- */
-
-#define PyArray_ISONESEGMENT(m) (PyArray_NDIM(m) == 0 || \
- PyArray_CHKFLAGS(m, NPY_ARRAY_C_CONTIGUOUS) || \
- PyArray_CHKFLAGS(m, NPY_ARRAY_F_CONTIGUOUS))
-
-#define PyArray_ISFORTRAN(m) (PyArray_CHKFLAGS(m, NPY_ARRAY_F_CONTIGUOUS) && \
- (PyArray_NDIM(m) > 1))
-
-#define PyArray_FORTRAN_IF(m) ((PyArray_CHKFLAGS(m, NPY_ARRAY_F_CONTIGUOUS) ? \
- NPY_ARRAY_F_CONTIGUOUS : 0))
-
-#if (defined(NPY_NO_DEPRECATED_API) && (NPY_API_VERSION <= NPY_NO_DEPRECATED_API))
-/*
- * Changing access macros into functions, to allow for future hiding
- * of the internal memory layout. This later hiding will allow the 2.x series
- * to change the internal representation of arrays without affecting
- * ABI compatibility.
- */
-
-static NPY_INLINE int
-PyArray_NDIM(const PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->nd;
-}
-
-static NPY_INLINE void *
-PyArray_DATA(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->data;
-}
-
-static NPY_INLINE char *
-PyArray_BYTES(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->data;
-}
-
-static NPY_INLINE npy_intp *
-PyArray_DIMS(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->dimensions;
-}
-
-static NPY_INLINE npy_intp *
-PyArray_STRIDES(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->strides;
-}
-
-static NPY_INLINE npy_intp
-PyArray_DIM(const PyArrayObject *arr, int idim)
-{
- return ((PyArrayObject_fields *)arr)->dimensions[idim];
-}
-
-static NPY_INLINE npy_intp
-PyArray_STRIDE(const PyArrayObject *arr, int istride)
-{
- return ((PyArrayObject_fields *)arr)->strides[istride];
-}
-
-static NPY_INLINE PyObject *
-PyArray_BASE(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->base;
-}
-
-static NPY_INLINE PyArray_Descr *
-PyArray_DESCR(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->descr;
-}
-
-static NPY_INLINE int
-PyArray_FLAGS(const PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->flags;
-}
-
-static NPY_INLINE npy_intp
-PyArray_ITEMSIZE(const PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->descr->elsize;
-}
-
-static NPY_INLINE int
-PyArray_TYPE(const PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->descr->type_num;
-}
-
-static NPY_INLINE int
-PyArray_CHKFLAGS(const PyArrayObject *arr, int flags)
-{
- return (PyArray_FLAGS(arr) & flags) == flags;
-}
-
-static NPY_INLINE PyObject *
-PyArray_GETITEM(const PyArrayObject *arr, const char *itemptr)
-{
- return ((PyArrayObject_fields *)arr)->descr->f->getitem(
- (void *)itemptr, (PyArrayObject *)arr);
-}
-
-static NPY_INLINE int
-PyArray_SETITEM(PyArrayObject *arr, char *itemptr, PyObject *v)
-{
- return ((PyArrayObject_fields *)arr)->descr->f->setitem(
- v, itemptr, arr);
-}
-
-#else
-
-/* These macros are deprecated as of NumPy 1.7. */
-#define PyArray_NDIM(obj) (((PyArrayObject_fields *)(obj))->nd)
-#define PyArray_BYTES(obj) (((PyArrayObject_fields *)(obj))->data)
-#define PyArray_DATA(obj) ((void *)((PyArrayObject_fields *)(obj))->data)
-#define PyArray_DIMS(obj) (((PyArrayObject_fields *)(obj))->dimensions)
-#define PyArray_STRIDES(obj) (((PyArrayObject_fields *)(obj))->strides)
-#define PyArray_DIM(obj,n) (PyArray_DIMS(obj)[n])
-#define PyArray_STRIDE(obj,n) (PyArray_STRIDES(obj)[n])
-#define PyArray_BASE(obj) (((PyArrayObject_fields *)(obj))->base)
-#define PyArray_DESCR(obj) (((PyArrayObject_fields *)(obj))->descr)
-#define PyArray_FLAGS(obj) (((PyArrayObject_fields *)(obj))->flags)
-#define PyArray_CHKFLAGS(m, FLAGS) \
- ((((PyArrayObject_fields *)(m))->flags & (FLAGS)) == (FLAGS))
-#define PyArray_ITEMSIZE(obj) \
- (((PyArrayObject_fields *)(obj))->descr->elsize)
-#define PyArray_TYPE(obj) \
- (((PyArrayObject_fields *)(obj))->descr->type_num)
-#define PyArray_GETITEM(obj,itemptr) \
- PyArray_DESCR(obj)->f->getitem((char *)(itemptr), \
- (PyArrayObject *)(obj))
-
-#define PyArray_SETITEM(obj,itemptr,v) \
- PyArray_DESCR(obj)->f->setitem((PyObject *)(v), \
- (char *)(itemptr), \
- (PyArrayObject *)(obj))
-#endif
-
-static NPY_INLINE PyArray_Descr *
-PyArray_DTYPE(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->descr;
-}
-
-static NPY_INLINE npy_intp *
-PyArray_SHAPE(PyArrayObject *arr)
-{
- return ((PyArrayObject_fields *)arr)->dimensions;
-}
-
-/*
- * Enables the specified array flags. Does no checking,
- * assumes you know what you're doing.
- */
-static NPY_INLINE void
-PyArray_ENABLEFLAGS(PyArrayObject *arr, int flags)
-{
- ((PyArrayObject_fields *)arr)->flags |= flags;
-}
-
-/*
- * Clears the specified array flags. Does no checking,
- * assumes you know what you're doing.
- */
-static NPY_INLINE void
-PyArray_CLEARFLAGS(PyArrayObject *arr, int flags)
-{
- ((PyArrayObject_fields *)arr)->flags &= ~flags;
-}
-
-#define PyTypeNum_ISBOOL(type) ((type) == NPY_BOOL)
-
-#define PyTypeNum_ISUNSIGNED(type) (((type) == NPY_UBYTE) || \
- ((type) == NPY_USHORT) || \
- ((type) == NPY_UINT) || \
- ((type) == NPY_ULONG) || \
- ((type) == NPY_ULONGLONG))
-
-#define PyTypeNum_ISSIGNED(type) (((type) == NPY_BYTE) || \
- ((type) == NPY_SHORT) || \
- ((type) == NPY_INT) || \
- ((type) == NPY_LONG) || \
- ((type) == NPY_LONGLONG))
-
-#define PyTypeNum_ISINTEGER(type) (((type) >= NPY_BYTE) && \
- ((type) <= NPY_ULONGLONG))
-
-#define PyTypeNum_ISFLOAT(type) ((((type) >= NPY_FLOAT) && \
- ((type) <= NPY_LONGDOUBLE)) || \
- ((type) == NPY_HALF))
-
-#define PyTypeNum_ISNUMBER(type) (((type) <= NPY_CLONGDOUBLE) || \
- ((type) == NPY_HALF))
-
-#define PyTypeNum_ISSTRING(type) (((type) == NPY_STRING) || \
- ((type) == NPY_UNICODE))
-
-#define PyTypeNum_ISCOMPLEX(type) (((type) >= NPY_CFLOAT) && \
- ((type) <= NPY_CLONGDOUBLE))
-
-#define PyTypeNum_ISPYTHON(type) (((type) == NPY_LONG) || \
- ((type) == NPY_DOUBLE) || \
- ((type) == NPY_CDOUBLE) || \
- ((type) == NPY_BOOL) || \
- ((type) == NPY_OBJECT ))
-
-#define PyTypeNum_ISFLEXIBLE(type) (((type) >=NPY_STRING) && \
- ((type) <=NPY_VOID))
-
-#define PyTypeNum_ISDATETIME(type) (((type) >=NPY_DATETIME) && \
- ((type) <=NPY_TIMEDELTA))
-
-#define PyTypeNum_ISUSERDEF(type) (((type) >= NPY_USERDEF) && \
- ((type) < NPY_USERDEF+ \
- NPY_NUMUSERTYPES))
-
-#define PyTypeNum_ISEXTENDED(type) (PyTypeNum_ISFLEXIBLE(type) || \
- PyTypeNum_ISUSERDEF(type))
-
-#define PyTypeNum_ISOBJECT(type) ((type) == NPY_OBJECT)
-
-
-#define PyDataType_ISBOOL(obj) PyTypeNum_ISBOOL(_PyADt(obj))
-#define PyDataType_ISUNSIGNED(obj) PyTypeNum_ISUNSIGNED(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISSIGNED(obj) PyTypeNum_ISSIGNED(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISINTEGER(obj) PyTypeNum_ISINTEGER(((PyArray_Descr*)(obj))->type_num )
-#define PyDataType_ISFLOAT(obj) PyTypeNum_ISFLOAT(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISNUMBER(obj) PyTypeNum_ISNUMBER(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISSTRING(obj) PyTypeNum_ISSTRING(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISCOMPLEX(obj) PyTypeNum_ISCOMPLEX(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISPYTHON(obj) PyTypeNum_ISPYTHON(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISFLEXIBLE(obj) PyTypeNum_ISFLEXIBLE(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISDATETIME(obj) PyTypeNum_ISDATETIME(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISUSERDEF(obj) PyTypeNum_ISUSERDEF(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISEXTENDED(obj) PyTypeNum_ISEXTENDED(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_ISOBJECT(obj) PyTypeNum_ISOBJECT(((PyArray_Descr*)(obj))->type_num)
-#define PyDataType_HASFIELDS(obj) (((PyArray_Descr *)(obj))->names != NULL)
-#define PyDataType_HASSUBARRAY(dtype) ((dtype)->subarray != NULL)
-
-#define PyArray_ISBOOL(obj) PyTypeNum_ISBOOL(PyArray_TYPE(obj))
-#define PyArray_ISUNSIGNED(obj) PyTypeNum_ISUNSIGNED(PyArray_TYPE(obj))
-#define PyArray_ISSIGNED(obj) PyTypeNum_ISSIGNED(PyArray_TYPE(obj))
-#define PyArray_ISINTEGER(obj) PyTypeNum_ISINTEGER(PyArray_TYPE(obj))
-#define PyArray_ISFLOAT(obj) PyTypeNum_ISFLOAT(PyArray_TYPE(obj))
-#define PyArray_ISNUMBER(obj) PyTypeNum_ISNUMBER(PyArray_TYPE(obj))
-#define PyArray_ISSTRING(obj) PyTypeNum_ISSTRING(PyArray_TYPE(obj))
-#define PyArray_ISCOMPLEX(obj) PyTypeNum_ISCOMPLEX(PyArray_TYPE(obj))
-#define PyArray_ISPYTHON(obj) PyTypeNum_ISPYTHON(PyArray_TYPE(obj))
-#define PyArray_ISFLEXIBLE(obj) PyTypeNum_ISFLEXIBLE(PyArray_TYPE(obj))
-#define PyArray_ISDATETIME(obj) PyTypeNum_ISDATETIME(PyArray_TYPE(obj))
-#define PyArray_ISUSERDEF(obj) PyTypeNum_ISUSERDEF(PyArray_TYPE(obj))
-#define PyArray_ISEXTENDED(obj) PyTypeNum_ISEXTENDED(PyArray_TYPE(obj))
-#define PyArray_ISOBJECT(obj) PyTypeNum_ISOBJECT(PyArray_TYPE(obj))
-#define PyArray_HASFIELDS(obj) PyDataType_HASFIELDS(PyArray_DESCR(obj))
-
- /*
- * FIXME: This should check for a flag on the data-type that
- * states whether or not it is variable length. Because the
- * ISFLEXIBLE check is hard-coded to the built-in data-types.
- */
-#define PyArray_ISVARIABLE(obj) PyTypeNum_ISFLEXIBLE(PyArray_TYPE(obj))
-
-#define PyArray_SAFEALIGNEDCOPY(obj) (PyArray_ISALIGNED(obj) && !PyArray_ISVARIABLE(obj))
-
-
-#define NPY_LITTLE '<'
-#define NPY_BIG '>'
-#define NPY_NATIVE '='
-#define NPY_SWAP 's'
-#define NPY_IGNORE '|'
-
-#if NPY_BYTE_ORDER == NPY_BIG_ENDIAN
-#define NPY_NATBYTE NPY_BIG
-#define NPY_OPPBYTE NPY_LITTLE
-#else
-#define NPY_NATBYTE NPY_LITTLE
-#define NPY_OPPBYTE NPY_BIG
-#endif
-
-#define PyArray_ISNBO(arg) ((arg) != NPY_OPPBYTE)
-#define PyArray_IsNativeByteOrder PyArray_ISNBO
-#define PyArray_ISNOTSWAPPED(m) PyArray_ISNBO(PyArray_DESCR(m)->byteorder)
-#define PyArray_ISBYTESWAPPED(m) (!PyArray_ISNOTSWAPPED(m))
-
-#define PyArray_FLAGSWAP(m, flags) (PyArray_CHKFLAGS(m, flags) && \
- PyArray_ISNOTSWAPPED(m))
-
-#define PyArray_ISCARRAY(m) PyArray_FLAGSWAP(m, NPY_ARRAY_CARRAY)
-#define PyArray_ISCARRAY_RO(m) PyArray_FLAGSWAP(m, NPY_ARRAY_CARRAY_RO)
-#define PyArray_ISFARRAY(m) PyArray_FLAGSWAP(m, NPY_ARRAY_FARRAY)
-#define PyArray_ISFARRAY_RO(m) PyArray_FLAGSWAP(m, NPY_ARRAY_FARRAY_RO)
-#define PyArray_ISBEHAVED(m) PyArray_FLAGSWAP(m, NPY_ARRAY_BEHAVED)
-#define PyArray_ISBEHAVED_RO(m) PyArray_FLAGSWAP(m, NPY_ARRAY_ALIGNED)
-
-
-#define PyDataType_ISNOTSWAPPED(d) PyArray_ISNBO(((PyArray_Descr *)(d))->byteorder)
-#define PyDataType_ISBYTESWAPPED(d) (!PyDataType_ISNOTSWAPPED(d))
-
-/************************************************************
- * A struct used by PyArray_CreateSortedStridePerm, new in 1.7.
- ************************************************************/
-
-typedef struct {
- npy_intp perm, stride;
-} npy_stride_sort_item;
-
-/************************************************************
- * This is the form of the struct that's returned pointed by the
- * PyCObject attribute of an array __array_struct__. See
- * http://docs.scipy.org/doc/numpy/reference/arrays.interface.html for the full
- * documentation.
- ************************************************************/
-typedef struct {
- int two; /*
- * contains the integer 2 as a sanity
- * check
- */
-
- int nd; /* number of dimensions */
-
- char typekind; /*
- * kind in array --- character code of
- * typestr
- */
-
- int itemsize; /* size of each element */
-
- int flags; /*
- * how should be data interpreted. Valid
- * flags are CONTIGUOUS (1), F_CONTIGUOUS (2),
- * ALIGNED (0x100), NOTSWAPPED (0x200), and
- * WRITEABLE (0x400). ARR_HAS_DESCR (0x800)
- * states that arrdescr field is present in
- * structure
- */
-
- npy_intp *shape; /*
- * A length-nd array of shape
- * information
- */
-
- npy_intp *strides; /* A length-nd array of stride information */
-
- void *data; /* A pointer to the first element of the array */
-
- PyObject *descr; /*
- * A list of fields or NULL (ignored if flags
- * does not have ARR_HAS_DESCR flag set)
- */
-} PyArrayInterface;
-
-/*
- * This is a function for hooking into the PyDataMem_NEW/FREE/RENEW functions.
- * See the documentation for PyDataMem_SetEventHook.
- */
-typedef void (PyDataMem_EventHookFunc)(void *inp, void *outp, size_t size,
- void *user_data);
-
-#if !(defined(NPY_NO_DEPRECATED_API) && (NPY_API_VERSION <= NPY_NO_DEPRECATED_API))
-#include "npy_deprecated_api.h"
-#endif
-
-#endif /* NPY_ARRAYTYPES_H */
diff --git a/include/numpy/noprefix.h b/include/numpy/noprefix.h
deleted file mode 100644
index b3e5748..0000000
--- a/include/numpy/noprefix.h
+++ /dev/null
@@ -1,209 +0,0 @@
-#ifndef NPY_NOPREFIX_H
-#define NPY_NOPREFIX_H
-
-/*
- * You can directly include noprefix.h as a backward
- * compatibility measure
- */
-#ifndef NPY_NO_PREFIX
-#include "ndarrayobject.h"
-#include "npy_interrupt.h"
-#endif
-
-#define SIGSETJMP NPY_SIGSETJMP
-#define SIGLONGJMP NPY_SIGLONGJMP
-#define SIGJMP_BUF NPY_SIGJMP_BUF
-
-#define MAX_DIMS NPY_MAXDIMS
-
-#define longlong npy_longlong
-#define ulonglong npy_ulonglong
-#define Bool npy_bool
-#define longdouble npy_longdouble
-#define byte npy_byte
-
-#ifndef _BSD_SOURCE
-#define ushort npy_ushort
-#define uint npy_uint
-#define ulong npy_ulong
-#endif
-
-#define ubyte npy_ubyte
-#define ushort npy_ushort
-#define uint npy_uint
-#define ulong npy_ulong
-#define cfloat npy_cfloat
-#define cdouble npy_cdouble
-#define clongdouble npy_clongdouble
-#define Int8 npy_int8
-#define UInt8 npy_uint8
-#define Int16 npy_int16
-#define UInt16 npy_uint16
-#define Int32 npy_int32
-#define UInt32 npy_uint32
-#define Int64 npy_int64
-#define UInt64 npy_uint64
-#define Int128 npy_int128
-#define UInt128 npy_uint128
-#define Int256 npy_int256
-#define UInt256 npy_uint256
-#define Float16 npy_float16
-#define Complex32 npy_complex32
-#define Float32 npy_float32
-#define Complex64 npy_complex64
-#define Float64 npy_float64
-#define Complex128 npy_complex128
-#define Float80 npy_float80
-#define Complex160 npy_complex160
-#define Float96 npy_float96
-#define Complex192 npy_complex192
-#define Float128 npy_float128
-#define Complex256 npy_complex256
-#define intp npy_intp
-#define uintp npy_uintp
-#define datetime npy_datetime
-#define timedelta npy_timedelta
-
-#define SIZEOF_INTP NPY_SIZEOF_INTP
-#define SIZEOF_UINTP NPY_SIZEOF_UINTP
-#define SIZEOF_DATETIME NPY_SIZEOF_DATETIME
-#define SIZEOF_TIMEDELTA NPY_SIZEOF_TIMEDELTA
-
-#define LONGLONG_FMT NPY_LONGLONG_FMT
-#define ULONGLONG_FMT NPY_ULONGLONG_FMT
-#define LONGLONG_SUFFIX NPY_LONGLONG_SUFFIX
-#define ULONGLONG_SUFFIX NPY_ULONGLONG_SUFFIX
-
-#define MAX_INT8 127
-#define MIN_INT8 -128
-#define MAX_UINT8 255
-#define MAX_INT16 32767
-#define MIN_INT16 -32768
-#define MAX_UINT16 65535
-#define MAX_INT32 2147483647
-#define MIN_INT32 (-MAX_INT32 - 1)
-#define MAX_UINT32 4294967295U
-#define MAX_INT64 LONGLONG_SUFFIX(9223372036854775807)
-#define MIN_INT64 (-MAX_INT64 - LONGLONG_SUFFIX(1))
-#define MAX_UINT64 ULONGLONG_SUFFIX(18446744073709551615)
-#define MAX_INT128 LONGLONG_SUFFIX(85070591730234615865843651857942052864)
-#define MIN_INT128 (-MAX_INT128 - LONGLONG_SUFFIX(1))
-#define MAX_UINT128 ULONGLONG_SUFFIX(170141183460469231731687303715884105728)
-#define MAX_INT256 LONGLONG_SUFFIX(57896044618658097711785492504343953926634992332820282019728792003956564819967)
-#define MIN_INT256 (-MAX_INT256 - LONGLONG_SUFFIX(1))
-#define MAX_UINT256 ULONGLONG_SUFFIX(115792089237316195423570985008687907853269984665640564039457584007913129639935)
-
-#define MAX_BYTE NPY_MAX_BYTE
-#define MIN_BYTE NPY_MIN_BYTE
-#define MAX_UBYTE NPY_MAX_UBYTE
-#define MAX_SHORT NPY_MAX_SHORT
-#define MIN_SHORT NPY_MIN_SHORT
-#define MAX_USHORT NPY_MAX_USHORT
-#define MAX_INT NPY_MAX_INT
-#define MIN_INT NPY_MIN_INT
-#define MAX_UINT NPY_MAX_UINT
-#define MAX_LONG NPY_MAX_LONG
-#define MIN_LONG NPY_MIN_LONG
-#define MAX_ULONG NPY_MAX_ULONG
-#define MAX_LONGLONG NPY_MAX_LONGLONG
-#define MIN_LONGLONG NPY_MIN_LONGLONG
-#define MAX_ULONGLONG NPY_MAX_ULONGLONG
-#define MIN_DATETIME NPY_MIN_DATETIME
-#define MAX_DATETIME NPY_MAX_DATETIME
-#define MIN_TIMEDELTA NPY_MIN_TIMEDELTA
-#define MAX_TIMEDELTA NPY_MAX_TIMEDELTA
-
-#define SIZEOF_LONGDOUBLE NPY_SIZEOF_LONGDOUBLE
-#define SIZEOF_LONGLONG NPY_SIZEOF_LONGLONG
-#define SIZEOF_HALF NPY_SIZEOF_HALF
-#define BITSOF_BOOL NPY_BITSOF_BOOL
-#define BITSOF_CHAR NPY_BITSOF_CHAR
-#define BITSOF_SHORT NPY_BITSOF_SHORT
-#define BITSOF_INT NPY_BITSOF_INT
-#define BITSOF_LONG NPY_BITSOF_LONG
-#define BITSOF_LONGLONG NPY_BITSOF_LONGLONG
-#define BITSOF_HALF NPY_BITSOF_HALF
-#define BITSOF_FLOAT NPY_BITSOF_FLOAT
-#define BITSOF_DOUBLE NPY_BITSOF_DOUBLE
-#define BITSOF_LONGDOUBLE NPY_BITSOF_LONGDOUBLE
-#define BITSOF_DATETIME NPY_BITSOF_DATETIME
-#define BITSOF_TIMEDELTA NPY_BITSOF_TIMEDELTA
-
-#define _pya_malloc PyArray_malloc
-#define _pya_free PyArray_free
-#define _pya_realloc PyArray_realloc
-
-#define BEGIN_THREADS_DEF NPY_BEGIN_THREADS_DEF
-#define BEGIN_THREADS NPY_BEGIN_THREADS
-#define END_THREADS NPY_END_THREADS
-#define ALLOW_C_API_DEF NPY_ALLOW_C_API_DEF
-#define ALLOW_C_API NPY_ALLOW_C_API
-#define DISABLE_C_API NPY_DISABLE_C_API
-
-#define PY_FAIL NPY_FAIL
-#define PY_SUCCEED NPY_SUCCEED
-
-#ifndef TRUE
-#define TRUE NPY_TRUE
-#endif
-
-#ifndef FALSE
-#define FALSE NPY_FALSE
-#endif
-
-#define LONGDOUBLE_FMT NPY_LONGDOUBLE_FMT
-
-#define CONTIGUOUS NPY_CONTIGUOUS
-#define C_CONTIGUOUS NPY_C_CONTIGUOUS
-#define FORTRAN NPY_FORTRAN
-#define F_CONTIGUOUS NPY_F_CONTIGUOUS
-#define OWNDATA NPY_OWNDATA
-#define FORCECAST NPY_FORCECAST
-#define ENSURECOPY NPY_ENSURECOPY
-#define ENSUREARRAY NPY_ENSUREARRAY
-#define ELEMENTSTRIDES NPY_ELEMENTSTRIDES
-#define ALIGNED NPY_ALIGNED
-#define NOTSWAPPED NPY_NOTSWAPPED
-#define WRITEABLE NPY_WRITEABLE
-#define UPDATEIFCOPY NPY_UPDATEIFCOPY
-#define ARR_HAS_DESCR NPY_ARR_HAS_DESCR
-#define BEHAVED NPY_BEHAVED
-#define BEHAVED_NS NPY_BEHAVED_NS
-#define CARRAY NPY_CARRAY
-#define CARRAY_RO NPY_CARRAY_RO
-#define FARRAY NPY_FARRAY
-#define FARRAY_RO NPY_FARRAY_RO
-#define DEFAULT NPY_DEFAULT
-#define IN_ARRAY NPY_IN_ARRAY
-#define OUT_ARRAY NPY_OUT_ARRAY
-#define INOUT_ARRAY NPY_INOUT_ARRAY
-#define IN_FARRAY NPY_IN_FARRAY
-#define OUT_FARRAY NPY_OUT_FARRAY
-#define INOUT_FARRAY NPY_INOUT_FARRAY
-#define UPDATE_ALL NPY_UPDATE_ALL
-
-#define OWN_DATA NPY_OWNDATA
-#define BEHAVED_FLAGS NPY_BEHAVED
-#define BEHAVED_FLAGS_NS NPY_BEHAVED_NS
-#define CARRAY_FLAGS_RO NPY_CARRAY_RO
-#define CARRAY_FLAGS NPY_CARRAY
-#define FARRAY_FLAGS NPY_FARRAY
-#define FARRAY_FLAGS_RO NPY_FARRAY_RO
-#define DEFAULT_FLAGS NPY_DEFAULT
-#define UPDATE_ALL_FLAGS NPY_UPDATE_ALL_FLAGS
-
-#ifndef MIN
-#define MIN PyArray_MIN
-#endif
-#ifndef MAX
-#define MAX PyArray_MAX
-#endif
-#define MAX_INTP NPY_MAX_INTP
-#define MIN_INTP NPY_MIN_INTP
-#define MAX_UINTP NPY_MAX_UINTP
-#define INTP_FMT NPY_INTP_FMT
-
-#define REFCOUNT PyArray_REFCOUNT
-#define MAX_ELSIZE NPY_MAX_ELSIZE
-
-#endif
diff --git a/include/numpy/npy_3kcompat.h b/include/numpy/npy_3kcompat.h
deleted file mode 100644
index d0cd9ac..0000000
--- a/include/numpy/npy_3kcompat.h
+++ /dev/null
@@ -1,417 +0,0 @@
-/*
- * This is a convenience header file providing compatibility utilities
- * for supporting Python 2 and Python 3 in the same code base.
- *
- * If you want to use this for your own projects, it's recommended to make a
- * copy of it. Although the stuff below is unlikely to change, we don't provide
- * strong backwards compatibility guarantees at the moment.
- */
-
-#ifndef _NPY_3KCOMPAT_H_
-#define _NPY_3KCOMPAT_H_
-
-#include
-#include
-
-#if PY_VERSION_HEX >= 0x03000000
-#ifndef NPY_PY3K
-#define NPY_PY3K 1
-#endif
-#endif
-
-#include "numpy/npy_common.h"
-#include "numpy/ndarrayobject.h"
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-/*
- * PyInt -> PyLong
- */
-
-#if defined(NPY_PY3K)
-/* Return True only if the long fits in a C long */
-static NPY_INLINE int PyInt_Check(PyObject *op) {
- int overflow = 0;
- if (!PyLong_Check(op)) {
- return 0;
- }
- PyLong_AsLongAndOverflow(op, &overflow);
- return (overflow == 0);
-}
-
-#define PyInt_FromLong PyLong_FromLong
-#define PyInt_AsLong PyLong_AsLong
-#define PyInt_AS_LONG PyLong_AsLong
-#define PyInt_AsSsize_t PyLong_AsSsize_t
-
-/* NOTE:
- *
- * Since the PyLong type is very different from the fixed-range PyInt,
- * we don't define PyInt_Type -> PyLong_Type.
- */
-#endif /* NPY_PY3K */
-
-/*
- * PyString -> PyBytes
- */
-
-#if defined(NPY_PY3K)
-
-#define PyString_Type PyBytes_Type
-#define PyString_Check PyBytes_Check
-#define PyStringObject PyBytesObject
-#define PyString_FromString PyBytes_FromString
-#define PyString_FromStringAndSize PyBytes_FromStringAndSize
-#define PyString_AS_STRING PyBytes_AS_STRING
-#define PyString_AsStringAndSize PyBytes_AsStringAndSize
-#define PyString_FromFormat PyBytes_FromFormat
-#define PyString_Concat PyBytes_Concat
-#define PyString_ConcatAndDel PyBytes_ConcatAndDel
-#define PyString_AsString PyBytes_AsString
-#define PyString_GET_SIZE PyBytes_GET_SIZE
-#define PyString_Size PyBytes_Size
-
-#define PyUString_Type PyUnicode_Type
-#define PyUString_Check PyUnicode_Check
-#define PyUStringObject PyUnicodeObject
-#define PyUString_FromString PyUnicode_FromString
-#define PyUString_FromStringAndSize PyUnicode_FromStringAndSize
-#define PyUString_FromFormat PyUnicode_FromFormat
-#define PyUString_Concat PyUnicode_Concat2
-#define PyUString_ConcatAndDel PyUnicode_ConcatAndDel
-#define PyUString_GET_SIZE PyUnicode_GET_SIZE
-#define PyUString_Size PyUnicode_Size
-#define PyUString_InternFromString PyUnicode_InternFromString
-#define PyUString_Format PyUnicode_Format
-
-#else
-
-#define PyBytes_Type PyString_Type
-#define PyBytes_Check PyString_Check
-#define PyBytesObject PyStringObject
-#define PyBytes_FromString PyString_FromString
-#define PyBytes_FromStringAndSize PyString_FromStringAndSize
-#define PyBytes_AS_STRING PyString_AS_STRING
-#define PyBytes_AsStringAndSize PyString_AsStringAndSize
-#define PyBytes_FromFormat PyString_FromFormat
-#define PyBytes_Concat PyString_Concat
-#define PyBytes_ConcatAndDel PyString_ConcatAndDel
-#define PyBytes_AsString PyString_AsString
-#define PyBytes_GET_SIZE PyString_GET_SIZE
-#define PyBytes_Size PyString_Size
-
-#define PyUString_Type PyString_Type
-#define PyUString_Check PyString_Check
-#define PyUStringObject PyStringObject
-#define PyUString_FromString PyString_FromString
-#define PyUString_FromStringAndSize PyString_FromStringAndSize
-#define PyUString_FromFormat PyString_FromFormat
-#define PyUString_Concat PyString_Concat
-#define PyUString_ConcatAndDel PyString_ConcatAndDel
-#define PyUString_GET_SIZE PyString_GET_SIZE
-#define PyUString_Size PyString_Size
-#define PyUString_InternFromString PyString_InternFromString
-#define PyUString_Format PyString_Format
-
-#endif /* NPY_PY3K */
-
-
-static NPY_INLINE void
-PyUnicode_ConcatAndDel(PyObject **left, PyObject *right)
-{
- PyObject *newobj;
- newobj = PyUnicode_Concat(*left, right);
- Py_DECREF(*left);
- Py_DECREF(right);
- *left = newobj;
-}
-
-static NPY_INLINE void
-PyUnicode_Concat2(PyObject **left, PyObject *right)
-{
- PyObject *newobj;
- newobj = PyUnicode_Concat(*left, right);
- Py_DECREF(*left);
- *left = newobj;
-}
-
-/*
- * PyFile_* compatibility
- */
-#if defined(NPY_PY3K)
-
-/*
- * Get a FILE* handle to the file represented by the Python object
- */
-static NPY_INLINE FILE*
-npy_PyFile_Dup(PyObject *file, char *mode)
-{
- int fd, fd2;
- PyObject *ret, *os;
- Py_ssize_t pos;
- FILE *handle;
- /* Flush first to ensure things end up in the file in the correct order */
- ret = PyObject_CallMethod(file, "flush", "");
- if (ret == NULL) {
- return NULL;
- }
- Py_DECREF(ret);
- fd = PyObject_AsFileDescriptor(file);
- if (fd == -1) {
- return NULL;
- }
- os = PyImport_ImportModule("os");
- if (os == NULL) {
- return NULL;
- }
- ret = PyObject_CallMethod(os, "dup", "i", fd);
- Py_DECREF(os);
- if (ret == NULL) {
- return NULL;
- }
- fd2 = PyNumber_AsSsize_t(ret, NULL);
- Py_DECREF(ret);
-#ifdef _WIN32
- handle = _fdopen(fd2, mode);
-#else
- handle = fdopen(fd2, mode);
-#endif
- if (handle == NULL) {
- PyErr_SetString(PyExc_IOError,
- "Getting a FILE* from a Python file object failed");
- }
- ret = PyObject_CallMethod(file, "tell", "");
- if (ret == NULL) {
- fclose(handle);
- return NULL;
- }
- pos = PyNumber_AsSsize_t(ret, PyExc_OverflowError);
- Py_DECREF(ret);
- if (PyErr_Occurred()) {
- fclose(handle);
- return NULL;
- }
- npy_fseek(handle, pos, SEEK_SET);
- return handle;
-}
-
-/*
- * Close the dup-ed file handle, and seek the Python one to the current position
- */
-static NPY_INLINE int
-npy_PyFile_DupClose(PyObject *file, FILE* handle)
-{
- PyObject *ret;
- Py_ssize_t position;
- position = npy_ftell(handle);
- fclose(handle);
-
- ret = PyObject_CallMethod(file, "seek", NPY_SSIZE_T_PYFMT "i", position, 0);
- if (ret == NULL) {
- return -1;
- }
- Py_DECREF(ret);
- return 0;
-}
-
-static NPY_INLINE int
-npy_PyFile_Check(PyObject *file)
-{
- int fd;
- fd = PyObject_AsFileDescriptor(file);
- if (fd == -1) {
- PyErr_Clear();
- return 0;
- }
- return 1;
-}
-
-#else
-
-#define npy_PyFile_Dup(file, mode) PyFile_AsFile(file)
-#define npy_PyFile_DupClose(file, handle) (0)
-#define npy_PyFile_Check PyFile_Check
-
-#endif
-
-static NPY_INLINE PyObject*
-npy_PyFile_OpenFile(PyObject *filename, const char *mode)
-{
- PyObject *open;
- open = PyDict_GetItemString(PyEval_GetBuiltins(), "open");
- if (open == NULL) {
- return NULL;
- }
- return PyObject_CallFunction(open, "Os", filename, mode);
-}
-
-static NPY_INLINE int
-npy_PyFile_CloseFile(PyObject *file)
-{
- PyObject *ret;
-
- ret = PyObject_CallMethod(file, "close", NULL);
- if (ret == NULL) {
- return -1;
- }
- Py_DECREF(ret);
- return 0;
-}
-
-/*
- * PyObject_Cmp
- */
-#if defined(NPY_PY3K)
-static NPY_INLINE int
-PyObject_Cmp(PyObject *i1, PyObject *i2, int *cmp)
-{
- int v;
- v = PyObject_RichCompareBool(i1, i2, Py_LT);
- if (v == 0) {
- *cmp = -1;
- return 1;
- }
- else if (v == -1) {
- return -1;
- }
-
- v = PyObject_RichCompareBool(i1, i2, Py_GT);
- if (v == 0) {
- *cmp = 1;
- return 1;
- }
- else if (v == -1) {
- return -1;
- }
-
- v = PyObject_RichCompareBool(i1, i2, Py_EQ);
- if (v == 0) {
- *cmp = 0;
- return 1;
- }
- else {
- *cmp = 0;
- return -1;
- }
-}
-#endif
-
-/*
- * PyCObject functions adapted to PyCapsules.
- *
- * The main job here is to get rid of the improved error handling
- * of PyCapsules. It's a shame...
- */
-#if PY_VERSION_HEX >= 0x03000000
-
-static NPY_INLINE PyObject *
-NpyCapsule_FromVoidPtr(void *ptr, void (*dtor)(PyObject *))
-{
- PyObject *ret = PyCapsule_New(ptr, NULL, dtor);
- if (ret == NULL) {
- PyErr_Clear();
- }
- return ret;
-}
-
-static NPY_INLINE PyObject *
-NpyCapsule_FromVoidPtrAndDesc(void *ptr, void* context, void (*dtor)(PyObject *))
-{
- PyObject *ret = NpyCapsule_FromVoidPtr(ptr, dtor);
- if (ret != NULL && PyCapsule_SetContext(ret, context) != 0) {
- PyErr_Clear();
- Py_DECREF(ret);
- ret = NULL;
- }
- return ret;
-}
-
-static NPY_INLINE void *
-NpyCapsule_AsVoidPtr(PyObject *obj)
-{
- void *ret = PyCapsule_GetPointer(obj, NULL);
- if (ret == NULL) {
- PyErr_Clear();
- }
- return ret;
-}
-
-static NPY_INLINE void *
-NpyCapsule_GetDesc(PyObject *obj)
-{
- return PyCapsule_GetContext(obj);
-}
-
-static NPY_INLINE int
-NpyCapsule_Check(PyObject *ptr)
-{
- return PyCapsule_CheckExact(ptr);
-}
-
-static NPY_INLINE void
-simple_capsule_dtor(PyObject *cap)
-{
- PyArray_free(PyCapsule_GetPointer(cap, NULL));
-}
-
-#else
-
-static NPY_INLINE PyObject *
-NpyCapsule_FromVoidPtr(void *ptr, void (*dtor)(void *))
-{
- return PyCObject_FromVoidPtr(ptr, dtor);
-}
-
-static NPY_INLINE PyObject *
-NpyCapsule_FromVoidPtrAndDesc(void *ptr, void* context,
- void (*dtor)(void *, void *))
-{
- return PyCObject_FromVoidPtrAndDesc(ptr, context, dtor);
-}
-
-static NPY_INLINE void *
-NpyCapsule_AsVoidPtr(PyObject *ptr)
-{
- return PyCObject_AsVoidPtr(ptr);
-}
-
-static NPY_INLINE void *
-NpyCapsule_GetDesc(PyObject *obj)
-{
- return PyCObject_GetDesc(obj);
-}
-
-static NPY_INLINE int
-NpyCapsule_Check(PyObject *ptr)
-{
- return PyCObject_Check(ptr);
-}
-
-static NPY_INLINE void
-simple_capsule_dtor(void *ptr)
-{
- PyArray_free(ptr);
-}
-
-#endif
-
-/*
- * Hash value compatibility.
- * As of Python 3.2 hash values are of type Py_hash_t.
- * Previous versions use C long.
- */
-#if PY_VERSION_HEX < 0x03020000
-typedef long npy_hash_t;
-#define NPY_SIZEOF_HASH_T NPY_SIZEOF_LONG
-#else
-typedef Py_hash_t npy_hash_t;
-#define NPY_SIZEOF_HASH_T NPY_SIZEOF_INTP
-#endif
-
-#ifdef __cplusplus
-}
-#endif
-
-#endif /* _NPY_3KCOMPAT_H_ */
diff --git a/include/numpy/npy_common.h b/include/numpy/npy_common.h
deleted file mode 100644
index 7fca7e2..0000000
--- a/include/numpy/npy_common.h
+++ /dev/null
@@ -1,930 +0,0 @@
-#ifndef _NPY_COMMON_H_
-#define _NPY_COMMON_H_
-
-/* numpconfig.h is auto-generated */
-#include "numpyconfig.h"
-
-#if defined(_MSC_VER)
- #define NPY_INLINE __inline
-#elif defined(__GNUC__)
- #if defined(__STRICT_ANSI__)
- #define NPY_INLINE __inline__
- #else
- #define NPY_INLINE inline
- #endif
-#else
- #define NPY_INLINE
-#endif
-
-/* Enable 64 bit file position support on win-amd64. Ticket #1660 */
-#if defined(_MSC_VER) && defined(_WIN64) && (_MSC_VER > 1400)
- #define npy_fseek _fseeki64
- #define npy_ftell _ftelli64
-#else
- #define npy_fseek fseek
- #define npy_ftell ftell
-#endif
-
-/* enums for detected endianness */
-enum {
- NPY_CPU_UNKNOWN_ENDIAN,
- NPY_CPU_LITTLE,
- NPY_CPU_BIG
-};
-
-/*
- * This is to typedef npy_intp to the appropriate pointer size for
- * this platform. Py_intptr_t, Py_uintptr_t are defined in pyport.h.
- */
-typedef Py_intptr_t npy_intp;
-typedef Py_uintptr_t npy_uintp;
-#define NPY_SIZEOF_CHAR 1
-#define NPY_SIZEOF_BYTE 1
-#define NPY_SIZEOF_INTP NPY_SIZEOF_PY_INTPTR_T
-#define NPY_SIZEOF_UINTP NPY_SIZEOF_PY_INTPTR_T
-#define NPY_SIZEOF_CFLOAT NPY_SIZEOF_COMPLEX_FLOAT
-#define NPY_SIZEOF_CDOUBLE NPY_SIZEOF_COMPLEX_DOUBLE
-#define NPY_SIZEOF_CLONGDOUBLE NPY_SIZEOF_COMPLEX_LONGDOUBLE
-
-#ifdef constchar
-#undef constchar
-#endif
-
-#if (PY_VERSION_HEX < 0x02050000)
- #ifndef PY_SSIZE_T_MIN
- typedef int Py_ssize_t;
- #define PY_SSIZE_T_MAX INT_MAX
- #define PY_SSIZE_T_MIN INT_MIN
- #endif
-#define NPY_SSIZE_T_PYFMT "i"
-#define constchar const char
-#else
-#define NPY_SSIZE_T_PYFMT "n"
-#define constchar char
-#endif
-
-/* NPY_INTP_FMT Note:
- * Unlike the other NPY_*_FMT macros which are used with
- * PyOS_snprintf, NPY_INTP_FMT is used with PyErr_Format and
- * PyString_Format. These functions use different formatting
- * codes which are portably specified according to the Python
- * documentation. See ticket #1795.
- *
- * On Windows x64, the LONGLONG formatter should be used, but
- * in Python 2.6 the %lld formatter is not supported. In this
- * case we work around the problem by using the %zd formatter.
- */
-#if NPY_SIZEOF_PY_INTPTR_T == NPY_SIZEOF_INT
- #define NPY_INTP NPY_INT
- #define NPY_UINTP NPY_UINT
- #define PyIntpArrType_Type PyIntArrType_Type
- #define PyUIntpArrType_Type PyUIntArrType_Type
- #define NPY_MAX_INTP NPY_MAX_INT
- #define NPY_MIN_INTP NPY_MIN_INT
- #define NPY_MAX_UINTP NPY_MAX_UINT
- #define NPY_INTP_FMT "d"
-#elif NPY_SIZEOF_PY_INTPTR_T == NPY_SIZEOF_LONG
- #define NPY_INTP NPY_LONG
- #define NPY_UINTP NPY_ULONG
- #define PyIntpArrType_Type PyLongArrType_Type
- #define PyUIntpArrType_Type PyULongArrType_Type
- #define NPY_MAX_INTP NPY_MAX_LONG
- #define NPY_MIN_INTP NPY_MIN_LONG
- #define NPY_MAX_UINTP NPY_MAX_ULONG
- #define NPY_INTP_FMT "ld"
-#elif defined(PY_LONG_LONG) && (NPY_SIZEOF_PY_INTPTR_T == NPY_SIZEOF_LONGLONG)
- #define NPY_INTP NPY_LONGLONG
- #define NPY_UINTP NPY_ULONGLONG
- #define PyIntpArrType_Type PyLongLongArrType_Type
- #define PyUIntpArrType_Type PyULongLongArrType_Type
- #define NPY_MAX_INTP NPY_MAX_LONGLONG
- #define NPY_MIN_INTP NPY_MIN_LONGLONG
- #define NPY_MAX_UINTP NPY_MAX_ULONGLONG
- #if (PY_VERSION_HEX >= 0x02070000)
- #define NPY_INTP_FMT "lld"
- #else
- #define NPY_INTP_FMT "zd"
- #endif
-#endif
-
-/*
- * We can only use C99 formats for npy_int_p if it is the same as
- * intp_t, hence the condition on HAVE_UNITPTR_T
- */
-#if (NPY_USE_C99_FORMATS) == 1 \
- && (defined HAVE_UINTPTR_T) \
- && (defined HAVE_INTTYPES_H)
- #include
- #undef NPY_INTP_FMT
- #define NPY_INTP_FMT PRIdPTR
-#endif
-
-
-/*
- * Some platforms don't define bool, long long, or long double.
- * Handle that here.
- */
-#define NPY_BYTE_FMT "hhd"
-#define NPY_UBYTE_FMT "hhu"
-#define NPY_SHORT_FMT "hd"
-#define NPY_USHORT_FMT "hu"
-#define NPY_INT_FMT "d"
-#define NPY_UINT_FMT "u"
-#define NPY_LONG_FMT "ld"
-#define NPY_ULONG_FMT "lu"
-#define NPY_HALF_FMT "g"
-#define NPY_FLOAT_FMT "g"
-#define NPY_DOUBLE_FMT "g"
-
-
-#ifdef PY_LONG_LONG
-typedef PY_LONG_LONG npy_longlong;
-typedef unsigned PY_LONG_LONG npy_ulonglong;
-# ifdef _MSC_VER
-# define NPY_LONGLONG_FMT "I64d"
-# define NPY_ULONGLONG_FMT "I64u"
-# elif defined(__APPLE__) || defined(__FreeBSD__)
-/* "%Ld" only parses 4 bytes -- "L" is floating modifier on MacOS X/BSD */
-# define NPY_LONGLONG_FMT "lld"
-# define NPY_ULONGLONG_FMT "llu"
-/*
- another possible variant -- *quad_t works on *BSD, but is deprecated:
- #define LONGLONG_FMT "qd"
- #define ULONGLONG_FMT "qu"
-*/
-# else
-# define NPY_LONGLONG_FMT "Ld"
-# define NPY_ULONGLONG_FMT "Lu"
-# endif
-# ifdef _MSC_VER
-# define NPY_LONGLONG_SUFFIX(x) (x##i64)
-# define NPY_ULONGLONG_SUFFIX(x) (x##Ui64)
-# else
-# define NPY_LONGLONG_SUFFIX(x) (x##LL)
-# define NPY_ULONGLONG_SUFFIX(x) (x##ULL)
-# endif
-#else
-typedef long npy_longlong;
-typedef unsigned long npy_ulonglong;
-# define NPY_LONGLONG_SUFFIX(x) (x##L)
-# define NPY_ULONGLONG_SUFFIX(x) (x##UL)
-#endif
-
-
-typedef unsigned char npy_bool;
-#define NPY_FALSE 0
-#define NPY_TRUE 1
-
-
-#if NPY_SIZEOF_LONGDOUBLE == NPY_SIZEOF_DOUBLE
- typedef double npy_longdouble;
- #define NPY_LONGDOUBLE_FMT "g"
-#else
- typedef long double npy_longdouble;
- #define NPY_LONGDOUBLE_FMT "Lg"
-#endif
-
-#ifndef Py_USING_UNICODE
-#error Must use Python with unicode enabled.
-#endif
-
-
-typedef signed char npy_byte;
-typedef unsigned char npy_ubyte;
-typedef unsigned short npy_ushort;
-typedef unsigned int npy_uint;
-typedef unsigned long npy_ulong;
-
-/* These are for completeness */
-typedef char npy_char;
-typedef short npy_short;
-typedef int npy_int;
-typedef long npy_long;
-typedef float npy_float;
-typedef double npy_double;
-
-/*
- * Disabling C99 complex usage: a lot of C code in numpy/scipy rely on being
- * able to do .real/.imag. Will have to convert code first.
- */
-#if 0
-#if defined(NPY_USE_C99_COMPLEX) && defined(NPY_HAVE_COMPLEX_DOUBLE)
-typedef complex npy_cdouble;
-#else
-typedef struct { double real, imag; } npy_cdouble;
-#endif
-
-#if defined(NPY_USE_C99_COMPLEX) && defined(NPY_HAVE_COMPLEX_FLOAT)
-typedef complex float npy_cfloat;
-#else
-typedef struct { float real, imag; } npy_cfloat;
-#endif
-
-#if defined(NPY_USE_C99_COMPLEX) && defined(NPY_HAVE_COMPLEX_LONG_DOUBLE)
-typedef complex long double npy_clongdouble;
-#else
-typedef struct {npy_longdouble real, imag;} npy_clongdouble;
-#endif
-#endif
-#if NPY_SIZEOF_COMPLEX_DOUBLE != 2 * NPY_SIZEOF_DOUBLE
-#error npy_cdouble definition is not compatible with C99 complex definition ! \
- Please contact Numpy maintainers and give detailed information about your \
- compiler and platform
-#endif
-typedef struct { double real, imag; } npy_cdouble;
-
-#if NPY_SIZEOF_COMPLEX_FLOAT != 2 * NPY_SIZEOF_FLOAT
-#error npy_cfloat definition is not compatible with C99 complex definition ! \
- Please contact Numpy maintainers and give detailed information about your \
- compiler and platform
-#endif
-typedef struct { float real, imag; } npy_cfloat;
-
-#if NPY_SIZEOF_COMPLEX_LONGDOUBLE != 2 * NPY_SIZEOF_LONGDOUBLE
-#error npy_clongdouble definition is not compatible with C99 complex definition ! \
- Please contact Numpy maintainers and give detailed information about your \
- compiler and platform
-#endif
-typedef struct { npy_longdouble real, imag; } npy_clongdouble;
-
-/*
- * numarray-style bit-width typedefs
- */
-#define NPY_MAX_INT8 127
-#define NPY_MIN_INT8 -128
-#define NPY_MAX_UINT8 255
-#define NPY_MAX_INT16 32767
-#define NPY_MIN_INT16 -32768
-#define NPY_MAX_UINT16 65535
-#define NPY_MAX_INT32 2147483647
-#define NPY_MIN_INT32 (-NPY_MAX_INT32 - 1)
-#define NPY_MAX_UINT32 4294967295U
-#define NPY_MAX_INT64 NPY_LONGLONG_SUFFIX(9223372036854775807)
-#define NPY_MIN_INT64 (-NPY_MAX_INT64 - NPY_LONGLONG_SUFFIX(1))
-#define NPY_MAX_UINT64 NPY_ULONGLONG_SUFFIX(18446744073709551615)
-#define NPY_MAX_INT128 NPY_LONGLONG_SUFFIX(85070591730234615865843651857942052864)
-#define NPY_MIN_INT128 (-NPY_MAX_INT128 - NPY_LONGLONG_SUFFIX(1))
-#define NPY_MAX_UINT128 NPY_ULONGLONG_SUFFIX(170141183460469231731687303715884105728)
-#define NPY_MAX_INT256 NPY_LONGLONG_SUFFIX(57896044618658097711785492504343953926634992332820282019728792003956564819967)
-#define NPY_MIN_INT256 (-NPY_MAX_INT256 - NPY_LONGLONG_SUFFIX(1))
-#define NPY_MAX_UINT256 NPY_ULONGLONG_SUFFIX(115792089237316195423570985008687907853269984665640564039457584007913129639935)
-#define NPY_MIN_DATETIME NPY_MIN_INT64
-#define NPY_MAX_DATETIME NPY_MAX_INT64
-#define NPY_MIN_TIMEDELTA NPY_MIN_INT64
-#define NPY_MAX_TIMEDELTA NPY_MAX_INT64
-
- /* Need to find the number of bits for each type and
- make definitions accordingly.
-
- C states that sizeof(char) == 1 by definition
-
- So, just using the sizeof keyword won't help.
-
- It also looks like Python itself uses sizeof(char) quite a
- bit, which by definition should be 1 all the time.
-
- Idea: Make Use of CHAR_BIT which should tell us how many
- BITS per CHARACTER
- */
-
- /* Include platform definitions -- These are in the C89/90 standard */
-#include
-#define NPY_MAX_BYTE SCHAR_MAX
-#define NPY_MIN_BYTE SCHAR_MIN
-#define NPY_MAX_UBYTE UCHAR_MAX
-#define NPY_MAX_SHORT SHRT_MAX
-#define NPY_MIN_SHORT SHRT_MIN
-#define NPY_MAX_USHORT USHRT_MAX
-#define NPY_MAX_INT INT_MAX
-#ifndef INT_MIN
-#define INT_MIN (-INT_MAX - 1)
-#endif
-#define NPY_MIN_INT INT_MIN
-#define NPY_MAX_UINT UINT_MAX
-#define NPY_MAX_LONG LONG_MAX
-#define NPY_MIN_LONG LONG_MIN
-#define NPY_MAX_ULONG ULONG_MAX
-
-#define NPY_SIZEOF_HALF 2
-#define NPY_SIZEOF_DATETIME 8
-#define NPY_SIZEOF_TIMEDELTA 8
-
-#define NPY_BITSOF_BOOL (sizeof(npy_bool) * CHAR_BIT)
-#define NPY_BITSOF_CHAR CHAR_BIT
-#define NPY_BITSOF_BYTE (NPY_SIZEOF_BYTE * CHAR_BIT)
-#define NPY_BITSOF_SHORT (NPY_SIZEOF_SHORT * CHAR_BIT)
-#define NPY_BITSOF_INT (NPY_SIZEOF_INT * CHAR_BIT)
-#define NPY_BITSOF_LONG (NPY_SIZEOF_LONG * CHAR_BIT)
-#define NPY_BITSOF_LONGLONG (NPY_SIZEOF_LONGLONG * CHAR_BIT)
-#define NPY_BITSOF_INTP (NPY_SIZEOF_INTP * CHAR_BIT)
-#define NPY_BITSOF_HALF (NPY_SIZEOF_HALF * CHAR_BIT)
-#define NPY_BITSOF_FLOAT (NPY_SIZEOF_FLOAT * CHAR_BIT)
-#define NPY_BITSOF_DOUBLE (NPY_SIZEOF_DOUBLE * CHAR_BIT)
-#define NPY_BITSOF_LONGDOUBLE (NPY_SIZEOF_LONGDOUBLE * CHAR_BIT)
-#define NPY_BITSOF_CFLOAT (NPY_SIZEOF_CFLOAT * CHAR_BIT)
-#define NPY_BITSOF_CDOUBLE (NPY_SIZEOF_CDOUBLE * CHAR_BIT)
-#define NPY_BITSOF_CLONGDOUBLE (NPY_SIZEOF_CLONGDOUBLE * CHAR_BIT)
-#define NPY_BITSOF_DATETIME (NPY_SIZEOF_DATETIME * CHAR_BIT)
-#define NPY_BITSOF_TIMEDELTA (NPY_SIZEOF_TIMEDELTA * CHAR_BIT)
-
-#if NPY_BITSOF_LONG == 8
-#define NPY_INT8 NPY_LONG
-#define NPY_UINT8 NPY_ULONG
- typedef long npy_int8;
- typedef unsigned long npy_uint8;
-#define PyInt8ScalarObject PyLongScalarObject
-#define PyInt8ArrType_Type PyLongArrType_Type
-#define PyUInt8ScalarObject PyULongScalarObject
-#define PyUInt8ArrType_Type PyULongArrType_Type
-#define NPY_INT8_FMT NPY_LONG_FMT
-#define NPY_UINT8_FMT NPY_ULONG_FMT
-#elif NPY_BITSOF_LONG == 16
-#define NPY_INT16 NPY_LONG
-#define NPY_UINT16 NPY_ULONG
- typedef long npy_int16;
- typedef unsigned long npy_uint16;
-#define PyInt16ScalarObject PyLongScalarObject
-#define PyInt16ArrType_Type PyLongArrType_Type
-#define PyUInt16ScalarObject PyULongScalarObject
-#define PyUInt16ArrType_Type PyULongArrType_Type
-#define NPY_INT16_FMT NPY_LONG_FMT
-#define NPY_UINT16_FMT NPY_ULONG_FMT
-#elif NPY_BITSOF_LONG == 32
-#define NPY_INT32 NPY_LONG
-#define NPY_UINT32 NPY_ULONG
- typedef long npy_int32;
- typedef unsigned long npy_uint32;
- typedef unsigned long npy_ucs4;
-#define PyInt32ScalarObject PyLongScalarObject
-#define PyInt32ArrType_Type PyLongArrType_Type
-#define PyUInt32ScalarObject PyULongScalarObject
-#define PyUInt32ArrType_Type PyULongArrType_Type
-#define NPY_INT32_FMT NPY_LONG_FMT
-#define NPY_UINT32_FMT NPY_ULONG_FMT
-#elif NPY_BITSOF_LONG == 64
-#define NPY_INT64 NPY_LONG
-#define NPY_UINT64 NPY_ULONG
- typedef long npy_int64;
- typedef unsigned long npy_uint64;
-#define PyInt64ScalarObject PyLongScalarObject
-#define PyInt64ArrType_Type PyLongArrType_Type
-#define PyUInt64ScalarObject PyULongScalarObject
-#define PyUInt64ArrType_Type PyULongArrType_Type
-#define NPY_INT64_FMT NPY_LONG_FMT
-#define NPY_UINT64_FMT NPY_ULONG_FMT
-#define MyPyLong_FromInt64 PyLong_FromLong
-#define MyPyLong_AsInt64 PyLong_AsLong
-#elif NPY_BITSOF_LONG == 128
-#define NPY_INT128 NPY_LONG
-#define NPY_UINT128 NPY_ULONG
- typedef long npy_int128;
- typedef unsigned long npy_uint128;
-#define PyInt128ScalarObject PyLongScalarObject
-#define PyInt128ArrType_Type PyLongArrType_Type
-#define PyUInt128ScalarObject PyULongScalarObject
-#define PyUInt128ArrType_Type PyULongArrType_Type
-#define NPY_INT128_FMT NPY_LONG_FMT
-#define NPY_UINT128_FMT NPY_ULONG_FMT
-#endif
-
-#if NPY_BITSOF_LONGLONG == 8
-# ifndef NPY_INT8
-# define NPY_INT8 NPY_LONGLONG
-# define NPY_UINT8 NPY_ULONGLONG
- typedef npy_longlong npy_int8;
- typedef npy_ulonglong npy_uint8;
-# define PyInt8ScalarObject PyLongLongScalarObject
-# define PyInt8ArrType_Type PyLongLongArrType_Type
-# define PyUInt8ScalarObject PyULongLongScalarObject
-# define PyUInt8ArrType_Type PyULongLongArrType_Type
-#define NPY_INT8_FMT NPY_LONGLONG_FMT
-#define NPY_UINT8_FMT NPY_ULONGLONG_FMT
-# endif
-# define NPY_MAX_LONGLONG NPY_MAX_INT8
-# define NPY_MIN_LONGLONG NPY_MIN_INT8
-# define NPY_MAX_ULONGLONG NPY_MAX_UINT8
-#elif NPY_BITSOF_LONGLONG == 16
-# ifndef NPY_INT16
-# define NPY_INT16 NPY_LONGLONG
-# define NPY_UINT16 NPY_ULONGLONG
- typedef npy_longlong npy_int16;
- typedef npy_ulonglong npy_uint16;
-# define PyInt16ScalarObject PyLongLongScalarObject
-# define PyInt16ArrType_Type PyLongLongArrType_Type
-# define PyUInt16ScalarObject PyULongLongScalarObject
-# define PyUInt16ArrType_Type PyULongLongArrType_Type
-#define NPY_INT16_FMT NPY_LONGLONG_FMT
-#define NPY_UINT16_FMT NPY_ULONGLONG_FMT
-# endif
-# define NPY_MAX_LONGLONG NPY_MAX_INT16
-# define NPY_MIN_LONGLONG NPY_MIN_INT16
-# define NPY_MAX_ULONGLONG NPY_MAX_UINT16
-#elif NPY_BITSOF_LONGLONG == 32
-# ifndef NPY_INT32
-# define NPY_INT32 NPY_LONGLONG
-# define NPY_UINT32 NPY_ULONGLONG
- typedef npy_longlong npy_int32;
- typedef npy_ulonglong npy_uint32;
- typedef npy_ulonglong npy_ucs4;
-# define PyInt32ScalarObject PyLongLongScalarObject
-# define PyInt32ArrType_Type PyLongLongArrType_Type
-# define PyUInt32ScalarObject PyULongLongScalarObject
-# define PyUInt32ArrType_Type PyULongLongArrType_Type
-#define NPY_INT32_FMT NPY_LONGLONG_FMT
-#define NPY_UINT32_FMT NPY_ULONGLONG_FMT
-# endif
-# define NPY_MAX_LONGLONG NPY_MAX_INT32
-# define NPY_MIN_LONGLONG NPY_MIN_INT32
-# define NPY_MAX_ULONGLONG NPY_MAX_UINT32
-#elif NPY_BITSOF_LONGLONG == 64
-# ifndef NPY_INT64
-# define NPY_INT64 NPY_LONGLONG
-# define NPY_UINT64 NPY_ULONGLONG
- typedef npy_longlong npy_int64;
- typedef npy_ulonglong npy_uint64;
-# define PyInt64ScalarObject PyLongLongScalarObject
-# define PyInt64ArrType_Type PyLongLongArrType_Type
-# define PyUInt64ScalarObject PyULongLongScalarObject
-# define PyUInt64ArrType_Type PyULongLongArrType_Type
-#define NPY_INT64_FMT NPY_LONGLONG_FMT
-#define NPY_UINT64_FMT NPY_ULONGLONG_FMT
-# define MyPyLong_FromInt64 PyLong_FromLongLong
-# define MyPyLong_AsInt64 PyLong_AsLongLong
-# endif
-# define NPY_MAX_LONGLONG NPY_MAX_INT64
-# define NPY_MIN_LONGLONG NPY_MIN_INT64
-# define NPY_MAX_ULONGLONG NPY_MAX_UINT64
-#elif NPY_BITSOF_LONGLONG == 128
-# ifndef NPY_INT128
-# define NPY_INT128 NPY_LONGLONG
-# define NPY_UINT128 NPY_ULONGLONG
- typedef npy_longlong npy_int128;
- typedef npy_ulonglong npy_uint128;
-# define PyInt128ScalarObject PyLongLongScalarObject
-# define PyInt128ArrType_Type PyLongLongArrType_Type
-# define PyUInt128ScalarObject PyULongLongScalarObject
-# define PyUInt128ArrType_Type PyULongLongArrType_Type
-#define NPY_INT128_FMT NPY_LONGLONG_FMT
-#define NPY_UINT128_FMT NPY_ULONGLONG_FMT
-# endif
-# define NPY_MAX_LONGLONG NPY_MAX_INT128
-# define NPY_MIN_LONGLONG NPY_MIN_INT128
-# define NPY_MAX_ULONGLONG NPY_MAX_UINT128
-#elif NPY_BITSOF_LONGLONG == 256
-# define NPY_INT256 NPY_LONGLONG
-# define NPY_UINT256 NPY_ULONGLONG
- typedef npy_longlong npy_int256;
- typedef npy_ulonglong npy_uint256;
-# define PyInt256ScalarObject PyLongLongScalarObject
-# define PyInt256ArrType_Type PyLongLongArrType_Type
-# define PyUInt256ScalarObject PyULongLongScalarObject
-# define PyUInt256ArrType_Type PyULongLongArrType_Type
-#define NPY_INT256_FMT NPY_LONGLONG_FMT
-#define NPY_UINT256_FMT NPY_ULONGLONG_FMT
-# define NPY_MAX_LONGLONG NPY_MAX_INT256
-# define NPY_MIN_LONGLONG NPY_MIN_INT256
-# define NPY_MAX_ULONGLONG NPY_MAX_UINT256
-#endif
-
-#if NPY_BITSOF_INT == 8
-#ifndef NPY_INT8
-#define NPY_INT8 NPY_INT
-#define NPY_UINT8 NPY_UINT
- typedef int npy_int8;
- typedef unsigned int npy_uint8;
-# define PyInt8ScalarObject PyIntScalarObject
-# define PyInt8ArrType_Type PyIntArrType_Type
-# define PyUInt8ScalarObject PyUIntScalarObject
-# define PyUInt8ArrType_Type PyUIntArrType_Type
-#define NPY_INT8_FMT NPY_INT_FMT
-#define NPY_UINT8_FMT NPY_UINT_FMT
-#endif
-#elif NPY_BITSOF_INT == 16
-#ifndef NPY_INT16
-#define NPY_INT16 NPY_INT
-#define NPY_UINT16 NPY_UINT
- typedef int npy_int16;
- typedef unsigned int npy_uint16;
-# define PyInt16ScalarObject PyIntScalarObject
-# define PyInt16ArrType_Type PyIntArrType_Type
-# define PyUInt16ScalarObject PyIntUScalarObject
-# define PyUInt16ArrType_Type PyIntUArrType_Type
-#define NPY_INT16_FMT NPY_INT_FMT
-#define NPY_UINT16_FMT NPY_UINT_FMT
-#endif
-#elif NPY_BITSOF_INT == 32
-#ifndef NPY_INT32
-#define NPY_INT32 NPY_INT
-#define NPY_UINT32 NPY_UINT
- typedef int npy_int32;
- typedef unsigned int npy_uint32;
- typedef unsigned int npy_ucs4;
-# define PyInt32ScalarObject PyIntScalarObject
-# define PyInt32ArrType_Type PyIntArrType_Type
-# define PyUInt32ScalarObject PyUIntScalarObject
-# define PyUInt32ArrType_Type PyUIntArrType_Type
-#define NPY_INT32_FMT NPY_INT_FMT
-#define NPY_UINT32_FMT NPY_UINT_FMT
-#endif
-#elif NPY_BITSOF_INT == 64
-#ifndef NPY_INT64
-#define NPY_INT64 NPY_INT
-#define NPY_UINT64 NPY_UINT
- typedef int npy_int64;
- typedef unsigned int npy_uint64;
-# define PyInt64ScalarObject PyIntScalarObject
-# define PyInt64ArrType_Type PyIntArrType_Type
-# define PyUInt64ScalarObject PyUIntScalarObject
-# define PyUInt64ArrType_Type PyUIntArrType_Type
-#define NPY_INT64_FMT NPY_INT_FMT
-#define NPY_UINT64_FMT NPY_UINT_FMT
-# define MyPyLong_FromInt64 PyLong_FromLong
-# define MyPyLong_AsInt64 PyLong_AsLong
-#endif
-#elif NPY_BITSOF_INT == 128
-#ifndef NPY_INT128
-#define NPY_INT128 NPY_INT
-#define NPY_UINT128 NPY_UINT
- typedef int npy_int128;
- typedef unsigned int npy_uint128;
-# define PyInt128ScalarObject PyIntScalarObject
-# define PyInt128ArrType_Type PyIntArrType_Type
-# define PyUInt128ScalarObject PyUIntScalarObject
-# define PyUInt128ArrType_Type PyUIntArrType_Type
-#define NPY_INT128_FMT NPY_INT_FMT
-#define NPY_UINT128_FMT NPY_UINT_FMT
-#endif
-#endif
-
-#if NPY_BITSOF_SHORT == 8
-#ifndef NPY_INT8
-#define NPY_INT8 NPY_SHORT
-#define NPY_UINT8 NPY_USHORT
- typedef short npy_int8;
- typedef unsigned short npy_uint8;
-# define PyInt8ScalarObject PyShortScalarObject
-# define PyInt8ArrType_Type PyShortArrType_Type
-# define PyUInt8ScalarObject PyUShortScalarObject
-# define PyUInt8ArrType_Type PyUShortArrType_Type
-#define NPY_INT8_FMT NPY_SHORT_FMT
-#define NPY_UINT8_FMT NPY_USHORT_FMT
-#endif
-#elif NPY_BITSOF_SHORT == 16
-#ifndef NPY_INT16
-#define NPY_INT16 NPY_SHORT
-#define NPY_UINT16 NPY_USHORT
- typedef short npy_int16;
- typedef unsigned short npy_uint16;
-# define PyInt16ScalarObject PyShortScalarObject
-# define PyInt16ArrType_Type PyShortArrType_Type
-# define PyUInt16ScalarObject PyUShortScalarObject
-# define PyUInt16ArrType_Type PyUShortArrType_Type
-#define NPY_INT16_FMT NPY_SHORT_FMT
-#define NPY_UINT16_FMT NPY_USHORT_FMT
-#endif
-#elif NPY_BITSOF_SHORT == 32
-#ifndef NPY_INT32
-#define NPY_INT32 NPY_SHORT
-#define NPY_UINT32 NPY_USHORT
- typedef short npy_int32;
- typedef unsigned short npy_uint32;
- typedef unsigned short npy_ucs4;
-# define PyInt32ScalarObject PyShortScalarObject
-# define PyInt32ArrType_Type PyShortArrType_Type
-# define PyUInt32ScalarObject PyUShortScalarObject
-# define PyUInt32ArrType_Type PyUShortArrType_Type
-#define NPY_INT32_FMT NPY_SHORT_FMT
-#define NPY_UINT32_FMT NPY_USHORT_FMT
-#endif
-#elif NPY_BITSOF_SHORT == 64
-#ifndef NPY_INT64
-#define NPY_INT64 NPY_SHORT
-#define NPY_UINT64 NPY_USHORT
- typedef short npy_int64;
- typedef unsigned short npy_uint64;
-# define PyInt64ScalarObject PyShortScalarObject
-# define PyInt64ArrType_Type PyShortArrType_Type
-# define PyUInt64ScalarObject PyUShortScalarObject
-# define PyUInt64ArrType_Type PyUShortArrType_Type
-#define NPY_INT64_FMT NPY_SHORT_FMT
-#define NPY_UINT64_FMT NPY_USHORT_FMT
-# define MyPyLong_FromInt64 PyLong_FromLong
-# define MyPyLong_AsInt64 PyLong_AsLong
-#endif
-#elif NPY_BITSOF_SHORT == 128
-#ifndef NPY_INT128
-#define NPY_INT128 NPY_SHORT
-#define NPY_UINT128 NPY_USHORT
- typedef short npy_int128;
- typedef unsigned short npy_uint128;
-# define PyInt128ScalarObject PyShortScalarObject
-# define PyInt128ArrType_Type PyShortArrType_Type
-# define PyUInt128ScalarObject PyUShortScalarObject
-# define PyUInt128ArrType_Type PyUShortArrType_Type
-#define NPY_INT128_FMT NPY_SHORT_FMT
-#define NPY_UINT128_FMT NPY_USHORT_FMT
-#endif
-#endif
-
-
-#if NPY_BITSOF_CHAR == 8
-#ifndef NPY_INT8
-#define NPY_INT8 NPY_BYTE
-#define NPY_UINT8 NPY_UBYTE
- typedef signed char npy_int8;
- typedef unsigned char npy_uint8;
-# define PyInt8ScalarObject PyByteScalarObject
-# define PyInt8ArrType_Type PyByteArrType_Type
-# define PyUInt8ScalarObject PyUByteScalarObject
-# define PyUInt8ArrType_Type PyUByteArrType_Type
-#define NPY_INT8_FMT NPY_BYTE_FMT
-#define NPY_UINT8_FMT NPY_UBYTE_FMT
-#endif
-#elif NPY_BITSOF_CHAR == 16
-#ifndef NPY_INT16
-#define NPY_INT16 NPY_BYTE
-#define NPY_UINT16 NPY_UBYTE
- typedef signed char npy_int16;
- typedef unsigned char npy_uint16;
-# define PyInt16ScalarObject PyByteScalarObject
-# define PyInt16ArrType_Type PyByteArrType_Type
-# define PyUInt16ScalarObject PyUByteScalarObject
-# define PyUInt16ArrType_Type PyUByteArrType_Type
-#define NPY_INT16_FMT NPY_BYTE_FMT
-#define NPY_UINT16_FMT NPY_UBYTE_FMT
-#endif
-#elif NPY_BITSOF_CHAR == 32
-#ifndef NPY_INT32
-#define NPY_INT32 NPY_BYTE
-#define NPY_UINT32 NPY_UBYTE
- typedef signed char npy_int32;
- typedef unsigned char npy_uint32;
- typedef unsigned char npy_ucs4;
-# define PyInt32ScalarObject PyByteScalarObject
-# define PyInt32ArrType_Type PyByteArrType_Type
-# define PyUInt32ScalarObject PyUByteScalarObject
-# define PyUInt32ArrType_Type PyUByteArrType_Type
-#define NPY_INT32_FMT NPY_BYTE_FMT
-#define NPY_UINT32_FMT NPY_UBYTE_FMT
-#endif
-#elif NPY_BITSOF_CHAR == 64
-#ifndef NPY_INT64
-#define NPY_INT64 NPY_BYTE
-#define NPY_UINT64 NPY_UBYTE
- typedef signed char npy_int64;
- typedef unsigned char npy_uint64;
-# define PyInt64ScalarObject PyByteScalarObject
-# define PyInt64ArrType_Type PyByteArrType_Type
-# define PyUInt64ScalarObject PyUByteScalarObject
-# define PyUInt64ArrType_Type PyUByteArrType_Type
-#define NPY_INT64_FMT NPY_BYTE_FMT
-#define NPY_UINT64_FMT NPY_UBYTE_FMT
-# define MyPyLong_FromInt64 PyLong_FromLong
-# define MyPyLong_AsInt64 PyLong_AsLong
-#endif
-#elif NPY_BITSOF_CHAR == 128
-#ifndef NPY_INT128
-#define NPY_INT128 NPY_BYTE
-#define NPY_UINT128 NPY_UBYTE
- typedef signed char npy_int128;
- typedef unsigned char npy_uint128;
-# define PyInt128ScalarObject PyByteScalarObject
-# define PyInt128ArrType_Type PyByteArrType_Type
-# define PyUInt128ScalarObject PyUByteScalarObject
-# define PyUInt128ArrType_Type PyUByteArrType_Type
-#define NPY_INT128_FMT NPY_BYTE_FMT
-#define NPY_UINT128_FMT NPY_UBYTE_FMT
-#endif
-#endif
-
-
-
-#if NPY_BITSOF_DOUBLE == 32
-#ifndef NPY_FLOAT32
-#define NPY_FLOAT32 NPY_DOUBLE
-#define NPY_COMPLEX64 NPY_CDOUBLE
- typedef double npy_float32;
- typedef npy_cdouble npy_complex64;
-# define PyFloat32ScalarObject PyDoubleScalarObject
-# define PyComplex64ScalarObject PyCDoubleScalarObject
-# define PyFloat32ArrType_Type PyDoubleArrType_Type
-# define PyComplex64ArrType_Type PyCDoubleArrType_Type
-#define NPY_FLOAT32_FMT NPY_DOUBLE_FMT
-#define NPY_COMPLEX64_FMT NPY_CDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_DOUBLE == 64
-#ifndef NPY_FLOAT64
-#define NPY_FLOAT64 NPY_DOUBLE
-#define NPY_COMPLEX128 NPY_CDOUBLE
- typedef double npy_float64;
- typedef npy_cdouble npy_complex128;
-# define PyFloat64ScalarObject PyDoubleScalarObject
-# define PyComplex128ScalarObject PyCDoubleScalarObject
-# define PyFloat64ArrType_Type PyDoubleArrType_Type
-# define PyComplex128ArrType_Type PyCDoubleArrType_Type
-#define NPY_FLOAT64_FMT NPY_DOUBLE_FMT
-#define NPY_COMPLEX128_FMT NPY_CDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_DOUBLE == 80
-#ifndef NPY_FLOAT80
-#define NPY_FLOAT80 NPY_DOUBLE
-#define NPY_COMPLEX160 NPY_CDOUBLE
- typedef double npy_float80;
- typedef npy_cdouble npy_complex160;
-# define PyFloat80ScalarObject PyDoubleScalarObject
-# define PyComplex160ScalarObject PyCDoubleScalarObject
-# define PyFloat80ArrType_Type PyDoubleArrType_Type
-# define PyComplex160ArrType_Type PyCDoubleArrType_Type
-#define NPY_FLOAT80_FMT NPY_DOUBLE_FMT
-#define NPY_COMPLEX160_FMT NPY_CDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_DOUBLE == 96
-#ifndef NPY_FLOAT96
-#define NPY_FLOAT96 NPY_DOUBLE
-#define NPY_COMPLEX192 NPY_CDOUBLE
- typedef double npy_float96;
- typedef npy_cdouble npy_complex192;
-# define PyFloat96ScalarObject PyDoubleScalarObject
-# define PyComplex192ScalarObject PyCDoubleScalarObject
-# define PyFloat96ArrType_Type PyDoubleArrType_Type
-# define PyComplex192ArrType_Type PyCDoubleArrType_Type
-#define NPY_FLOAT96_FMT NPY_DOUBLE_FMT
-#define NPY_COMPLEX192_FMT NPY_CDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_DOUBLE == 128
-#ifndef NPY_FLOAT128
-#define NPY_FLOAT128 NPY_DOUBLE
-#define NPY_COMPLEX256 NPY_CDOUBLE
- typedef double npy_float128;
- typedef npy_cdouble npy_complex256;
-# define PyFloat128ScalarObject PyDoubleScalarObject
-# define PyComplex256ScalarObject PyCDoubleScalarObject
-# define PyFloat128ArrType_Type PyDoubleArrType_Type
-# define PyComplex256ArrType_Type PyCDoubleArrType_Type
-#define NPY_FLOAT128_FMT NPY_DOUBLE_FMT
-#define NPY_COMPLEX256_FMT NPY_CDOUBLE_FMT
-#endif
-#endif
-
-
-
-#if NPY_BITSOF_FLOAT == 32
-#ifndef NPY_FLOAT32
-#define NPY_FLOAT32 NPY_FLOAT
-#define NPY_COMPLEX64 NPY_CFLOAT
- typedef float npy_float32;
- typedef npy_cfloat npy_complex64;
-# define PyFloat32ScalarObject PyFloatScalarObject
-# define PyComplex64ScalarObject PyCFloatScalarObject
-# define PyFloat32ArrType_Type PyFloatArrType_Type
-# define PyComplex64ArrType_Type PyCFloatArrType_Type
-#define NPY_FLOAT32_FMT NPY_FLOAT_FMT
-#define NPY_COMPLEX64_FMT NPY_CFLOAT_FMT
-#endif
-#elif NPY_BITSOF_FLOAT == 64
-#ifndef NPY_FLOAT64
-#define NPY_FLOAT64 NPY_FLOAT
-#define NPY_COMPLEX128 NPY_CFLOAT
- typedef float npy_float64;
- typedef npy_cfloat npy_complex128;
-# define PyFloat64ScalarObject PyFloatScalarObject
-# define PyComplex128ScalarObject PyCFloatScalarObject
-# define PyFloat64ArrType_Type PyFloatArrType_Type
-# define PyComplex128ArrType_Type PyCFloatArrType_Type
-#define NPY_FLOAT64_FMT NPY_FLOAT_FMT
-#define NPY_COMPLEX128_FMT NPY_CFLOAT_FMT
-#endif
-#elif NPY_BITSOF_FLOAT == 80
-#ifndef NPY_FLOAT80
-#define NPY_FLOAT80 NPY_FLOAT
-#define NPY_COMPLEX160 NPY_CFLOAT
- typedef float npy_float80;
- typedef npy_cfloat npy_complex160;
-# define PyFloat80ScalarObject PyFloatScalarObject
-# define PyComplex160ScalarObject PyCFloatScalarObject
-# define PyFloat80ArrType_Type PyFloatArrType_Type
-# define PyComplex160ArrType_Type PyCFloatArrType_Type
-#define NPY_FLOAT80_FMT NPY_FLOAT_FMT
-#define NPY_COMPLEX160_FMT NPY_CFLOAT_FMT
-#endif
-#elif NPY_BITSOF_FLOAT == 96
-#ifndef NPY_FLOAT96
-#define NPY_FLOAT96 NPY_FLOAT
-#define NPY_COMPLEX192 NPY_CFLOAT
- typedef float npy_float96;
- typedef npy_cfloat npy_complex192;
-# define PyFloat96ScalarObject PyFloatScalarObject
-# define PyComplex192ScalarObject PyCFloatScalarObject
-# define PyFloat96ArrType_Type PyFloatArrType_Type
-# define PyComplex192ArrType_Type PyCFloatArrType_Type
-#define NPY_FLOAT96_FMT NPY_FLOAT_FMT
-#define NPY_COMPLEX192_FMT NPY_CFLOAT_FMT
-#endif
-#elif NPY_BITSOF_FLOAT == 128
-#ifndef NPY_FLOAT128
-#define NPY_FLOAT128 NPY_FLOAT
-#define NPY_COMPLEX256 NPY_CFLOAT
- typedef float npy_float128;
- typedef npy_cfloat npy_complex256;
-# define PyFloat128ScalarObject PyFloatScalarObject
-# define PyComplex256ScalarObject PyCFloatScalarObject
-# define PyFloat128ArrType_Type PyFloatArrType_Type
-# define PyComplex256ArrType_Type PyCFloatArrType_Type
-#define NPY_FLOAT128_FMT NPY_FLOAT_FMT
-#define NPY_COMPLEX256_FMT NPY_CFLOAT_FMT
-#endif
-#endif
-
-/* half/float16 isn't a floating-point type in C */
-#define NPY_FLOAT16 NPY_HALF
-typedef npy_uint16 npy_half;
-typedef npy_half npy_float16;
-
-#if NPY_BITSOF_LONGDOUBLE == 32
-#ifndef NPY_FLOAT32
-#define NPY_FLOAT32 NPY_LONGDOUBLE
-#define NPY_COMPLEX64 NPY_CLONGDOUBLE
- typedef npy_longdouble npy_float32;
- typedef npy_clongdouble npy_complex64;
-# define PyFloat32ScalarObject PyLongDoubleScalarObject
-# define PyComplex64ScalarObject PyCLongDoubleScalarObject
-# define PyFloat32ArrType_Type PyLongDoubleArrType_Type
-# define PyComplex64ArrType_Type PyCLongDoubleArrType_Type
-#define NPY_FLOAT32_FMT NPY_LONGDOUBLE_FMT
-#define NPY_COMPLEX64_FMT NPY_CLONGDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_LONGDOUBLE == 64
-#ifndef NPY_FLOAT64
-#define NPY_FLOAT64 NPY_LONGDOUBLE
-#define NPY_COMPLEX128 NPY_CLONGDOUBLE
- typedef npy_longdouble npy_float64;
- typedef npy_clongdouble npy_complex128;
-# define PyFloat64ScalarObject PyLongDoubleScalarObject
-# define PyComplex128ScalarObject PyCLongDoubleScalarObject
-# define PyFloat64ArrType_Type PyLongDoubleArrType_Type
-# define PyComplex128ArrType_Type PyCLongDoubleArrType_Type
-#define NPY_FLOAT64_FMT NPY_LONGDOUBLE_FMT
-#define NPY_COMPLEX128_FMT NPY_CLONGDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_LONGDOUBLE == 80
-#ifndef NPY_FLOAT80
-#define NPY_FLOAT80 NPY_LONGDOUBLE
-#define NPY_COMPLEX160 NPY_CLONGDOUBLE
- typedef npy_longdouble npy_float80;
- typedef npy_clongdouble npy_complex160;
-# define PyFloat80ScalarObject PyLongDoubleScalarObject
-# define PyComplex160ScalarObject PyCLongDoubleScalarObject
-# define PyFloat80ArrType_Type PyLongDoubleArrType_Type
-# define PyComplex160ArrType_Type PyCLongDoubleArrType_Type
-#define NPY_FLOAT80_FMT NPY_LONGDOUBLE_FMT
-#define NPY_COMPLEX160_FMT NPY_CLONGDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_LONGDOUBLE == 96
-#ifndef NPY_FLOAT96
-#define NPY_FLOAT96 NPY_LONGDOUBLE
-#define NPY_COMPLEX192 NPY_CLONGDOUBLE
- typedef npy_longdouble npy_float96;
- typedef npy_clongdouble npy_complex192;
-# define PyFloat96ScalarObject PyLongDoubleScalarObject
-# define PyComplex192ScalarObject PyCLongDoubleScalarObject
-# define PyFloat96ArrType_Type PyLongDoubleArrType_Type
-# define PyComplex192ArrType_Type PyCLongDoubleArrType_Type
-#define NPY_FLOAT96_FMT NPY_LONGDOUBLE_FMT
-#define NPY_COMPLEX192_FMT NPY_CLONGDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_LONGDOUBLE == 128
-#ifndef NPY_FLOAT128
-#define NPY_FLOAT128 NPY_LONGDOUBLE
-#define NPY_COMPLEX256 NPY_CLONGDOUBLE
- typedef npy_longdouble npy_float128;
- typedef npy_clongdouble npy_complex256;
-# define PyFloat128ScalarObject PyLongDoubleScalarObject
-# define PyComplex256ScalarObject PyCLongDoubleScalarObject
-# define PyFloat128ArrType_Type PyLongDoubleArrType_Type
-# define PyComplex256ArrType_Type PyCLongDoubleArrType_Type
-#define NPY_FLOAT128_FMT NPY_LONGDOUBLE_FMT
-#define NPY_COMPLEX256_FMT NPY_CLONGDOUBLE_FMT
-#endif
-#elif NPY_BITSOF_LONGDOUBLE == 256
-#define NPY_FLOAT256 NPY_LONGDOUBLE
-#define NPY_COMPLEX512 NPY_CLONGDOUBLE
- typedef npy_longdouble npy_float256;
- typedef npy_clongdouble npy_complex512;
-# define PyFloat256ScalarObject PyLongDoubleScalarObject
-# define PyComplex512ScalarObject PyCLongDoubleScalarObject
-# define PyFloat256ArrType_Type PyLongDoubleArrType_Type
-# define PyComplex512ArrType_Type PyCLongDoubleArrType_Type
-#define NPY_FLOAT256_FMT NPY_LONGDOUBLE_FMT
-#define NPY_COMPLEX512_FMT NPY_CLONGDOUBLE_FMT
-#endif
-
-/* datetime typedefs */
-typedef npy_int64 npy_timedelta;
-typedef npy_int64 npy_datetime;
-#define NPY_DATETIME_FMT NPY_INT64_FMT
-#define NPY_TIMEDELTA_FMT NPY_INT64_FMT
-
-/* End of typedefs for numarray style bit-width names */
-
-#endif
-
diff --git a/include/numpy/npy_cpu.h b/include/numpy/npy_cpu.h
deleted file mode 100644
index 9707a7a..0000000
--- a/include/numpy/npy_cpu.h
+++ /dev/null
@@ -1,109 +0,0 @@
-/*
- * This set (target) cpu specific macros:
- * - Possible values:
- * NPY_CPU_X86
- * NPY_CPU_AMD64
- * NPY_CPU_PPC
- * NPY_CPU_PPC64
- * NPY_CPU_SPARC
- * NPY_CPU_S390
- * NPY_CPU_IA64
- * NPY_CPU_HPPA
- * NPY_CPU_ALPHA
- * NPY_CPU_ARMEL
- * NPY_CPU_ARMEB
- * NPY_CPU_SH_LE
- * NPY_CPU_SH_BE
- */
-#ifndef _NPY_CPUARCH_H_
-#define _NPY_CPUARCH_H_
-
-#include "numpyconfig.h"
-
-#if defined( __i386__ ) || defined(i386) || defined(_M_IX86)
- /*
- * __i386__ is defined by gcc and Intel compiler on Linux,
- * _M_IX86 by VS compiler,
- * i386 by Sun compilers on opensolaris at least
- */
- #define NPY_CPU_X86
-#elif defined(__x86_64__) || defined(__amd64__) || defined(__x86_64) || defined(_M_AMD64)
- /*
- * both __x86_64__ and __amd64__ are defined by gcc
- * __x86_64 defined by sun compiler on opensolaris at least
- * _M_AMD64 defined by MS compiler
- */
- #define NPY_CPU_AMD64
-#elif defined(__ppc__) || defined(__powerpc__) || defined(_ARCH_PPC)
- /*
- * __ppc__ is defined by gcc, I remember having seen __powerpc__ once,
- * but can't find it ATM
- * _ARCH_PPC is used by at least gcc on AIX
- */
- #define NPY_CPU_PPC
-#elif defined(__ppc64__)
- #define NPY_CPU_PPC64
-#elif defined(__sparc__) || defined(__sparc)
- /* __sparc__ is defined by gcc and Forte (e.g. Sun) compilers */
- #define NPY_CPU_SPARC
-#elif defined(__s390__)
- #define NPY_CPU_S390
-#elif defined(__ia64)
- #define NPY_CPU_IA64
-#elif defined(__hppa)
- #define NPY_CPU_HPPA
-#elif defined(__alpha__)
- #define NPY_CPU_ALPHA
-#elif defined(__arm__) && defined(__ARMEL__)
- #define NPY_CPU_ARMEL
-#elif defined(__arm__) && defined(__ARMEB__)
- #define NPY_CPU_ARMEB
-#elif defined(__sh__) && defined(__LITTLE_ENDIAN__)
- #define NPY_CPU_SH_LE
-#elif defined(__sh__) && defined(__BIG_ENDIAN__)
- #define NPY_CPU_SH_BE
-#elif defined(__MIPSEL__)
- #define NPY_CPU_MIPSEL
-#elif defined(__MIPSEB__)
- #define NPY_CPU_MIPSEB
-#elif defined(__aarch64__)
- #define NPY_CPU_AARCH64
-#else
- #error Unknown CPU, please report this to numpy maintainers with \
- information about your platform (OS, CPU and compiler)
-#endif
-
-/*
- This "white-lists" the architectures that we know don't require
- pointer alignment. We white-list, since the memcpy version will
- work everywhere, whereas assignment will only work where pointer
- dereferencing doesn't require alignment.
-
- TODO: There may be more architectures we can white list.
-*/
-#if defined(NPY_CPU_X86) || defined(NPY_CPU_AMD64)
- #define NPY_COPY_PYOBJECT_PTR(dst, src) (*((PyObject **)(dst)) = *((PyObject **)(src)))
-#else
- #if NPY_SIZEOF_PY_INTPTR_T == 4
- #define NPY_COPY_PYOBJECT_PTR(dst, src) \
- ((char*)(dst))[0] = ((char*)(src))[0]; \
- ((char*)(dst))[1] = ((char*)(src))[1]; \
- ((char*)(dst))[2] = ((char*)(src))[2]; \
- ((char*)(dst))[3] = ((char*)(src))[3];
- #elif NPY_SIZEOF_PY_INTPTR_T == 8
- #define NPY_COPY_PYOBJECT_PTR(dst, src) \
- ((char*)(dst))[0] = ((char*)(src))[0]; \
- ((char*)(dst))[1] = ((char*)(src))[1]; \
- ((char*)(dst))[2] = ((char*)(src))[2]; \
- ((char*)(dst))[3] = ((char*)(src))[3]; \
- ((char*)(dst))[4] = ((char*)(src))[4]; \
- ((char*)(dst))[5] = ((char*)(src))[5]; \
- ((char*)(dst))[6] = ((char*)(src))[6]; \
- ((char*)(dst))[7] = ((char*)(src))[7];
- #else
- #error Unknown architecture, please report this to numpy maintainers with \
- information about your platform (OS, CPU and compiler)
- #endif
-#endif
-
-#endif
diff --git a/include/numpy/npy_deprecated_api.h b/include/numpy/npy_deprecated_api.h
deleted file mode 100644
index c27b4a4..0000000
--- a/include/numpy/npy_deprecated_api.h
+++ /dev/null
@@ -1,129 +0,0 @@
-#ifndef _NPY_DEPRECATED_API_H
-#define _NPY_DEPRECATED_API_H
-
-#if defined(_WIN32)
-#define _WARN___STR2__(x) #x
-#define _WARN___STR1__(x) _WARN___STR2__(x)
-#define _WARN___LOC__ __FILE__ "(" _WARN___STR1__(__LINE__) ") : Warning Msg: "
-#pragma message(_WARN___LOC__"Using deprecated NumPy API, disable it by " \
- "#defining NPY_NO_DEPRECATED_API NPY_1_7_API_VERSION")
-#elif defined(__GNUC__)
-#warning "Using deprecated NumPy API, disable it by #defining NPY_NO_DEPRECATED_API NPY_1_7_API_VERSION"
-#endif
-/* TODO: How to do this warning message for other compilers? */
-
-/*
- * This header exists to collect all dangerous/deprecated NumPy API.
- *
- * This is an attempt to remove bad API, the proliferation of macros,
- * and namespace pollution currently produced by the NumPy headers.
- */
-
-#if defined(NPY_NO_DEPRECATED_API)
-#error Should never include npy_deprecated_api directly.
-#endif
-
-/* These array flags are deprecated as of NumPy 1.7 */
-#define NPY_CONTIGUOUS NPY_ARRAY_C_CONTIGUOUS
-#define NPY_FORTRAN NPY_ARRAY_F_CONTIGUOUS
-
-/*
- * The consistent NPY_ARRAY_* names which don't pollute the NPY_*
- * namespace were added in NumPy 1.7.
- *
- * These versions of the carray flags are deprecated, but
- * probably should only be removed after two releases instead of one.
- */
-#define NPY_C_CONTIGUOUS NPY_ARRAY_C_CONTIGUOUS
-#define NPY_F_CONTIGUOUS NPY_ARRAY_F_CONTIGUOUS
-#define NPY_OWNDATA NPY_ARRAY_OWNDATA
-#define NPY_FORCECAST NPY_ARRAY_FORCECAST
-#define NPY_ENSURECOPY NPY_ARRAY_ENSURECOPY
-#define NPY_ENSUREARRAY NPY_ARRAY_ENSUREARRAY
-#define NPY_ELEMENTSTRIDES NPY_ARRAY_ELEMENTSTRIDES
-#define NPY_ALIGNED NPY_ARRAY_ALIGNED
-#define NPY_NOTSWAPPED NPY_ARRAY_NOTSWAPPED
-#define NPY_WRITEABLE NPY_ARRAY_WRITEABLE
-#define NPY_UPDATEIFCOPY NPY_ARRAY_UPDATEIFCOPY
-#define NPY_BEHAVED NPY_ARRAY_BEHAVED
-#define NPY_BEHAVED_NS NPY_ARRAY_BEHAVED_NS
-#define NPY_CARRAY NPY_ARRAY_CARRAY
-#define NPY_CARRAY_RO NPY_ARRAY_CARRAY_RO
-#define NPY_FARRAY NPY_ARRAY_FARRAY
-#define NPY_FARRAY_RO NPY_ARRAY_FARRAY_RO
-#define NPY_DEFAULT NPY_ARRAY_DEFAULT
-#define NPY_IN_ARRAY NPY_ARRAY_IN_ARRAY
-#define NPY_OUT_ARRAY NPY_ARRAY_OUT_ARRAY
-#define NPY_INOUT_ARRAY NPY_ARRAY_INOUT_ARRAY
-#define NPY_IN_FARRAY NPY_ARRAY_IN_FARRAY
-#define NPY_OUT_FARRAY NPY_ARRAY_OUT_FARRAY
-#define NPY_INOUT_FARRAY NPY_ARRAY_INOUT_FARRAY
-#define NPY_UPDATE_ALL NPY_ARRAY_UPDATE_ALL
-
-/* This way of accessing the default type is deprecated as of NumPy 1.7 */
-#define PyArray_DEFAULT NPY_DEFAULT_TYPE
-
-/* These DATETIME bits aren't used internally */
-#if PY_VERSION_HEX >= 0x03000000
-#define PyDataType_GetDatetimeMetaData(descr) \
- ((descr->metadata == NULL) ? NULL : \
- ((PyArray_DatetimeMetaData *)(PyCapsule_GetPointer( \
- PyDict_GetItemString( \
- descr->metadata, NPY_METADATA_DTSTR), NULL))))
-#else
-#define PyDataType_GetDatetimeMetaData(descr) \
- ((descr->metadata == NULL) ? NULL : \
- ((PyArray_DatetimeMetaData *)(PyCObject_AsVoidPtr( \
- PyDict_GetItemString(descr->metadata, NPY_METADATA_DTSTR)))))
-#endif
-
-/*
- * Deprecated as of NumPy 1.7, this kind of shortcut doesn't
- * belong in the public API.
- */
-#define NPY_AO PyArrayObject
-
-/*
- * Deprecated as of NumPy 1.7, an all-lowercase macro doesn't
- * belong in the public API.
- */
-#define fortran fortran_
-
-/*
- * Deprecated as of NumPy 1.7, as it is a namespace-polluting
- * macro.
- */
-#define FORTRAN_IF PyArray_FORTRAN_IF
-
-/* Deprecated as of NumPy 1.7, datetime64 uses c_metadata instead */
-#define NPY_METADATA_DTSTR "__timeunit__"
-
-/*
- * Deprecated as of NumPy 1.7.
- * The reasoning:
- * - These are for datetime, but there's no datetime "namespace".
- * - They just turn NPY_STR_ into "", which is just
- * making something simple be indirected.
- */
-#define NPY_STR_Y "Y"
-#define NPY_STR_M "M"
-#define NPY_STR_W "W"
-#define NPY_STR_D "D"
-#define NPY_STR_h "h"
-#define NPY_STR_m "m"
-#define NPY_STR_s "s"
-#define NPY_STR_ms "ms"
-#define NPY_STR_us "us"
-#define NPY_STR_ns "ns"
-#define NPY_STR_ps "ps"
-#define NPY_STR_fs "fs"
-#define NPY_STR_as "as"
-
-/*
- * The macros in old_defines.h are Deprecated as of NumPy 1.7 and will be
- * removed in the next major release.
- */
-#include "old_defines.h"
-
-
-#endif
diff --git a/include/numpy/npy_endian.h b/include/numpy/npy_endian.h
deleted file mode 100644
index 4e3349f..0000000
--- a/include/numpy/npy_endian.h
+++ /dev/null
@@ -1,46 +0,0 @@
-#ifndef _NPY_ENDIAN_H_
-#define _NPY_ENDIAN_H_
-
-/*
- * NPY_BYTE_ORDER is set to the same value as BYTE_ORDER set by glibc in
- * endian.h
- */
-
-#ifdef NPY_HAVE_ENDIAN_H
- /* Use endian.h if available */
- #include
-
- #define NPY_BYTE_ORDER __BYTE_ORDER
- #define NPY_LITTLE_ENDIAN __LITTLE_ENDIAN
- #define NPY_BIG_ENDIAN __BIG_ENDIAN
-#else
- /* Set endianness info using target CPU */
- #include "npy_cpu.h"
-
- #define NPY_LITTLE_ENDIAN 1234
- #define NPY_BIG_ENDIAN 4321
-
- #if defined(NPY_CPU_X86) \
- || defined(NPY_CPU_AMD64) \
- || defined(NPY_CPU_IA64) \
- || defined(NPY_CPU_ALPHA) \
- || defined(NPY_CPU_ARMEL) \
- || defined(NPY_CPU_AARCH64) \
- || defined(NPY_CPU_SH_LE) \
- || defined(NPY_CPU_MIPSEL)
- #define NPY_BYTE_ORDER NPY_LITTLE_ENDIAN
- #elif defined(NPY_CPU_PPC) \
- || defined(NPY_CPU_SPARC) \
- || defined(NPY_CPU_S390) \
- || defined(NPY_CPU_HPPA) \
- || defined(NPY_CPU_PPC64) \
- || defined(NPY_CPU_ARMEB) \
- || defined(NPY_CPU_SH_BE) \
- || defined(NPY_CPU_MIPSEB)
- #define NPY_BYTE_ORDER NPY_BIG_ENDIAN
- #else
- #error Unknown CPU: can not set endianness
- #endif
-#endif
-
-#endif
diff --git a/include/numpy/npy_interrupt.h b/include/numpy/npy_interrupt.h
deleted file mode 100644
index f71fd68..0000000
--- a/include/numpy/npy_interrupt.h
+++ /dev/null
@@ -1,117 +0,0 @@
-
-/* Signal handling:
-
-This header file defines macros that allow your code to handle
-interrupts received during processing. Interrupts that
-could reasonably be handled:
-
-SIGINT, SIGABRT, SIGALRM, SIGSEGV
-
-****Warning***************
-
-Do not allow code that creates temporary memory or increases reference
-counts of Python objects to be interrupted unless you handle it
-differently.
-
-**************************
-
-The mechanism for handling interrupts is conceptually simple:
-
- - replace the signal handler with our own home-grown version
- and store the old one.
- - run the code to be interrupted -- if an interrupt occurs
- the handler should basically just cause a return to the
- calling function for finish work.
- - restore the old signal handler
-
-Of course, every code that allows interrupts must account for
-returning via the interrupt and handle clean-up correctly. But,
-even still, the simple paradigm is complicated by at least three
-factors.
-
- 1) platform portability (i.e. Microsoft says not to use longjmp
- to return from signal handling. They have a __try and __except
- extension to C instead but what about mingw?).
-
- 2) how to handle threads: apparently whether signals are delivered to
- every thread of the process or the "invoking" thread is platform
- dependent. --- we don't handle threads for now.
-
- 3) do we need to worry about re-entrance. For now, assume the
- code will not call-back into itself.
-
-Ideas:
-
- 1) Start by implementing an approach that works on platforms that
- can use setjmp and longjmp functionality and does nothing
- on other platforms.
-
- 2) Ignore threads --- i.e. do not mix interrupt handling and threads
-
- 3) Add a default signal_handler function to the C-API but have the rest
- use macros.
-
-
-Simple Interface:
-
-
-In your C-extension: around a block of code you want to be interruptable
-with a SIGINT
-
-NPY_SIGINT_ON
-[code]
-NPY_SIGINT_OFF
-
-In order for this to work correctly, the
-[code] block must not allocate any memory or alter the reference count of any
-Python objects. In other words [code] must be interruptible so that continuation
-after NPY_SIGINT_OFF will only be "missing some computations"
-
-Interrupt handling does not work well with threads.
-
-*/
-
-/* Add signal handling macros
- Make the global variable and signal handler part of the C-API
-*/
-
-#ifndef NPY_INTERRUPT_H
-#define NPY_INTERRUPT_H
-
-#ifndef NPY_NO_SIGNAL
-
-#include
-#include
-
-#ifndef sigsetjmp
-
-#define NPY_SIGSETJMP(arg1, arg2) setjmp(arg1)
-#define NPY_SIGLONGJMP(arg1, arg2) longjmp(arg1, arg2)
-#define NPY_SIGJMP_BUF jmp_buf
-
-#else
-
-#define NPY_SIGSETJMP(arg1, arg2) sigsetjmp(arg1, arg2)
-#define NPY_SIGLONGJMP(arg1, arg2) siglongjmp(arg1, arg2)
-#define NPY_SIGJMP_BUF sigjmp_buf
-
-#endif
-
-# define NPY_SIGINT_ON { \
- PyOS_sighandler_t _npy_sig_save; \
- _npy_sig_save = PyOS_setsig(SIGINT, _PyArray_SigintHandler); \
- if (NPY_SIGSETJMP(*((NPY_SIGJMP_BUF *)_PyArray_GetSigintBuf()), \
- 1) == 0) { \
-
-# define NPY_SIGINT_OFF } \
- PyOS_setsig(SIGINT, _npy_sig_save); \
- }
-
-#else /* NPY_NO_SIGNAL */
-
-#define NPY_SIGINT_ON
-#define NPY_SIGINT_OFF
-
-#endif /* HAVE_SIGSETJMP */
-
-#endif /* NPY_INTERRUPT_H */
diff --git a/include/numpy/npy_math.h b/include/numpy/npy_math.h
deleted file mode 100644
index 7ae166e..0000000
--- a/include/numpy/npy_math.h
+++ /dev/null
@@ -1,438 +0,0 @@
-#ifndef __NPY_MATH_C99_H_
-#define __NPY_MATH_C99_H_
-
-#include
-#ifdef __SUNPRO_CC
-#include
-#endif
-#include
-
-/*
- * NAN and INFINITY like macros (same behavior as glibc for NAN, same as C99
- * for INFINITY)
- *
- * XXX: I should test whether INFINITY and NAN are available on the platform
- */
-NPY_INLINE static float __npy_inff(void)
-{
- const union { npy_uint32 __i; float __f;} __bint = {0x7f800000UL};
- return __bint.__f;
-}
-
-NPY_INLINE static float __npy_nanf(void)
-{
- const union { npy_uint32 __i; float __f;} __bint = {0x7fc00000UL};
- return __bint.__f;
-}
-
-NPY_INLINE static float __npy_pzerof(void)
-{
- const union { npy_uint32 __i; float __f;} __bint = {0x00000000UL};
- return __bint.__f;
-}
-
-NPY_INLINE static float __npy_nzerof(void)
-{
- const union { npy_uint32 __i; float __f;} __bint = {0x80000000UL};
- return __bint.__f;
-}
-
-#define NPY_INFINITYF __npy_inff()
-#define NPY_NANF __npy_nanf()
-#define NPY_PZEROF __npy_pzerof()
-#define NPY_NZEROF __npy_nzerof()
-
-#define NPY_INFINITY ((npy_double)NPY_INFINITYF)
-#define NPY_NAN ((npy_double)NPY_NANF)
-#define NPY_PZERO ((npy_double)NPY_PZEROF)
-#define NPY_NZERO ((npy_double)NPY_NZEROF)
-
-#define NPY_INFINITYL ((npy_longdouble)NPY_INFINITYF)
-#define NPY_NANL ((npy_longdouble)NPY_NANF)
-#define NPY_PZEROL ((npy_longdouble)NPY_PZEROF)
-#define NPY_NZEROL ((npy_longdouble)NPY_NZEROF)
-
-/*
- * Useful constants
- */
-#define NPY_E 2.718281828459045235360287471352662498 /* e */
-#define NPY_LOG2E 1.442695040888963407359924681001892137 /* log_2 e */
-#define NPY_LOG10E 0.434294481903251827651128918916605082 /* log_10 e */
-#define NPY_LOGE2 0.693147180559945309417232121458176568 /* log_e 2 */
-#define NPY_LOGE10 2.302585092994045684017991454684364208 /* log_e 10 */
-#define NPY_PI 3.141592653589793238462643383279502884 /* pi */
-#define NPY_PI_2 1.570796326794896619231321691639751442 /* pi/2 */
-#define NPY_PI_4 0.785398163397448309615660845819875721 /* pi/4 */
-#define NPY_1_PI 0.318309886183790671537767526745028724 /* 1/pi */
-#define NPY_2_PI 0.636619772367581343075535053490057448 /* 2/pi */
-#define NPY_EULER 0.577215664901532860606512090082402431 /* Euler constant */
-#define NPY_SQRT2 1.414213562373095048801688724209698079 /* sqrt(2) */
-#define NPY_SQRT1_2 0.707106781186547524400844362104849039 /* 1/sqrt(2) */
-
-#define NPY_Ef 2.718281828459045235360287471352662498F /* e */
-#define NPY_LOG2Ef 1.442695040888963407359924681001892137F /* log_2 e */
-#define NPY_LOG10Ef 0.434294481903251827651128918916605082F /* log_10 e */
-#define NPY_LOGE2f 0.693147180559945309417232121458176568F /* log_e 2 */
-#define NPY_LOGE10f 2.302585092994045684017991454684364208F /* log_e 10 */
-#define NPY_PIf 3.141592653589793238462643383279502884F /* pi */
-#define NPY_PI_2f 1.570796326794896619231321691639751442F /* pi/2 */
-#define NPY_PI_4f 0.785398163397448309615660845819875721F /* pi/4 */
-#define NPY_1_PIf 0.318309886183790671537767526745028724F /* 1/pi */
-#define NPY_2_PIf 0.636619772367581343075535053490057448F /* 2/pi */
-#define NPY_EULERf 0.577215664901532860606512090082402431F /* Euler constan*/
-#define NPY_SQRT2f 1.414213562373095048801688724209698079F /* sqrt(2) */
-#define NPY_SQRT1_2f 0.707106781186547524400844362104849039F /* 1/sqrt(2) */
-
-#define NPY_El 2.718281828459045235360287471352662498L /* e */
-#define NPY_LOG2El 1.442695040888963407359924681001892137L /* log_2 e */
-#define NPY_LOG10El 0.434294481903251827651128918916605082L /* log_10 e */
-#define NPY_LOGE2l 0.693147180559945309417232121458176568L /* log_e 2 */
-#define NPY_LOGE10l 2.302585092994045684017991454684364208L /* log_e 10 */
-#define NPY_PIl 3.141592653589793238462643383279502884L /* pi */
-#define NPY_PI_2l 1.570796326794896619231321691639751442L /* pi/2 */
-#define NPY_PI_4l 0.785398163397448309615660845819875721L /* pi/4 */
-#define NPY_1_PIl 0.318309886183790671537767526745028724L /* 1/pi */
-#define NPY_2_PIl 0.636619772367581343075535053490057448L /* 2/pi */
-#define NPY_EULERl 0.577215664901532860606512090082402431L /* Euler constan*/
-#define NPY_SQRT2l 1.414213562373095048801688724209698079L /* sqrt(2) */
-#define NPY_SQRT1_2l 0.707106781186547524400844362104849039L /* 1/sqrt(2) */
-
-/*
- * C99 double math funcs
- */
-double npy_sin(double x);
-double npy_cos(double x);
-double npy_tan(double x);
-double npy_sinh(double x);
-double npy_cosh(double x);
-double npy_tanh(double x);
-
-double npy_asin(double x);
-double npy_acos(double x);
-double npy_atan(double x);
-double npy_aexp(double x);
-double npy_alog(double x);
-double npy_asqrt(double x);
-double npy_afabs(double x);
-
-double npy_log(double x);
-double npy_log10(double x);
-double npy_exp(double x);
-double npy_sqrt(double x);
-
-double npy_fabs(double x);
-double npy_ceil(double x);
-double npy_fmod(double x, double y);
-double npy_floor(double x);
-
-double npy_expm1(double x);
-double npy_log1p(double x);
-double npy_hypot(double x, double y);
-double npy_acosh(double x);
-double npy_asinh(double xx);
-double npy_atanh(double x);
-double npy_rint(double x);
-double npy_trunc(double x);
-double npy_exp2(double x);
-double npy_log2(double x);
-
-double npy_atan2(double x, double y);
-double npy_pow(double x, double y);
-double npy_modf(double x, double* y);
-
-double npy_copysign(double x, double y);
-double npy_nextafter(double x, double y);
-double npy_spacing(double x);
-
-/*
- * IEEE 754 fpu handling. Those are guaranteed to be macros
- */
-#ifndef NPY_HAVE_DECL_ISNAN
- #define npy_isnan(x) ((x) != (x))
-#else
- #ifdef _MSC_VER
- #define npy_isnan(x) _isnan((x))
- #else
- #define npy_isnan(x) isnan((x))
- #endif
-#endif
-
-#ifndef NPY_HAVE_DECL_ISFINITE
- #ifdef _MSC_VER
- #define npy_isfinite(x) _finite((x))
- #else
- #define npy_isfinite(x) !npy_isnan((x) + (-x))
- #endif
-#else
- #define npy_isfinite(x) isfinite((x))
-#endif
-
-#ifndef NPY_HAVE_DECL_ISINF
- #define npy_isinf(x) (!npy_isfinite(x) && !npy_isnan(x))
-#else
- #ifdef _MSC_VER
- #define npy_isinf(x) (!_finite((x)) && !_isnan((x)))
- #else
- #define npy_isinf(x) isinf((x))
- #endif
-#endif
-
-#ifndef NPY_HAVE_DECL_SIGNBIT
- int _npy_signbit_f(float x);
- int _npy_signbit_d(double x);
- int _npy_signbit_ld(long double x);
- #define npy_signbit(x) \
- (sizeof (x) == sizeof (long double) ? _npy_signbit_ld (x) \
- : sizeof (x) == sizeof (double) ? _npy_signbit_d (x) \
- : _npy_signbit_f (x))
-#else
- #define npy_signbit(x) signbit((x))
-#endif
-
-/*
- * float C99 math functions
- */
-
-float npy_sinf(float x);
-float npy_cosf(float x);
-float npy_tanf(float x);
-float npy_sinhf(float x);
-float npy_coshf(float x);
-float npy_tanhf(float x);
-float npy_fabsf(float x);
-float npy_floorf(float x);
-float npy_ceilf(float x);
-float npy_rintf(float x);
-float npy_truncf(float x);
-float npy_sqrtf(float x);
-float npy_log10f(float x);
-float npy_logf(float x);
-float npy_expf(float x);
-float npy_expm1f(float x);
-float npy_asinf(float x);
-float npy_acosf(float x);
-float npy_atanf(float x);
-float npy_asinhf(float x);
-float npy_acoshf(float x);
-float npy_atanhf(float x);
-float npy_log1pf(float x);
-float npy_exp2f(float x);
-float npy_log2f(float x);
-
-float npy_atan2f(float x, float y);
-float npy_hypotf(float x, float y);
-float npy_powf(float x, float y);
-float npy_fmodf(float x, float y);
-
-float npy_modff(float x, float* y);
-
-float npy_copysignf(float x, float y);
-float npy_nextafterf(float x, float y);
-float npy_spacingf(float x);
-
-/*
- * float C99 math functions
- */
-
-npy_longdouble npy_sinl(npy_longdouble x);
-npy_longdouble npy_cosl(npy_longdouble x);
-npy_longdouble npy_tanl(npy_longdouble x);
-npy_longdouble npy_sinhl(npy_longdouble x);
-npy_longdouble npy_coshl(npy_longdouble x);
-npy_longdouble npy_tanhl(npy_longdouble x);
-npy_longdouble npy_fabsl(npy_longdouble x);
-npy_longdouble npy_floorl(npy_longdouble x);
-npy_longdouble npy_ceill(npy_longdouble x);
-npy_longdouble npy_rintl(npy_longdouble x);
-npy_longdouble npy_truncl(npy_longdouble x);
-npy_longdouble npy_sqrtl(npy_longdouble x);
-npy_longdouble npy_log10l(npy_longdouble x);
-npy_longdouble npy_logl(npy_longdouble x);
-npy_longdouble npy_expl(npy_longdouble x);
-npy_longdouble npy_expm1l(npy_longdouble x);
-npy_longdouble npy_asinl(npy_longdouble x);
-npy_longdouble npy_acosl(npy_longdouble x);
-npy_longdouble npy_atanl(npy_longdouble x);
-npy_longdouble npy_asinhl(npy_longdouble x);
-npy_longdouble npy_acoshl(npy_longdouble x);
-npy_longdouble npy_atanhl(npy_longdouble x);
-npy_longdouble npy_log1pl(npy_longdouble x);
-npy_longdouble npy_exp2l(npy_longdouble x);
-npy_longdouble npy_log2l(npy_longdouble x);
-
-npy_longdouble npy_atan2l(npy_longdouble x, npy_longdouble y);
-npy_longdouble npy_hypotl(npy_longdouble x, npy_longdouble y);
-npy_longdouble npy_powl(npy_longdouble x, npy_longdouble y);
-npy_longdouble npy_fmodl(npy_longdouble x, npy_longdouble y);
-
-npy_longdouble npy_modfl(npy_longdouble x, npy_longdouble* y);
-
-npy_longdouble npy_copysignl(npy_longdouble x, npy_longdouble y);
-npy_longdouble npy_nextafterl(npy_longdouble x, npy_longdouble y);
-npy_longdouble npy_spacingl(npy_longdouble x);
-
-/*
- * Non standard functions
- */
-double npy_deg2rad(double x);
-double npy_rad2deg(double x);
-double npy_logaddexp(double x, double y);
-double npy_logaddexp2(double x, double y);
-
-float npy_deg2radf(float x);
-float npy_rad2degf(float x);
-float npy_logaddexpf(float x, float y);
-float npy_logaddexp2f(float x, float y);
-
-npy_longdouble npy_deg2radl(npy_longdouble x);
-npy_longdouble npy_rad2degl(npy_longdouble x);
-npy_longdouble npy_logaddexpl(npy_longdouble x, npy_longdouble y);
-npy_longdouble npy_logaddexp2l(npy_longdouble x, npy_longdouble y);
-
-#define npy_degrees npy_rad2deg
-#define npy_degreesf npy_rad2degf
-#define npy_degreesl npy_rad2degl
-
-#define npy_radians npy_deg2rad
-#define npy_radiansf npy_deg2radf
-#define npy_radiansl npy_deg2radl
-
-/*
- * Complex declarations
- */
-
-/*
- * C99 specifies that complex numbers have the same representation as
- * an array of two elements, where the first element is the real part
- * and the second element is the imaginary part.
- */
-#define __NPY_CPACK_IMP(x, y, type, ctype) \
- union { \
- ctype z; \
- type a[2]; \
- } z1;; \
- \
- z1.a[0] = (x); \
- z1.a[1] = (y); \
- \
- return z1.z;
-
-static NPY_INLINE npy_cdouble npy_cpack(double x, double y)
-{
- __NPY_CPACK_IMP(x, y, double, npy_cdouble);
-}
-
-static NPY_INLINE npy_cfloat npy_cpackf(float x, float y)
-{
- __NPY_CPACK_IMP(x, y, float, npy_cfloat);
-}
-
-static NPY_INLINE npy_clongdouble npy_cpackl(npy_longdouble x, npy_longdouble y)
-{
- __NPY_CPACK_IMP(x, y, npy_longdouble, npy_clongdouble);
-}
-#undef __NPY_CPACK_IMP
-
-/*
- * Same remark as above, but in the other direction: extract first/second
- * member of complex number, assuming a C99-compatible representation
- *
- * Those are defineds as static inline, and such as a reasonable compiler would
- * most likely compile this to one or two instructions (on CISC at least)
- */
-#define __NPY_CEXTRACT_IMP(z, index, type, ctype) \
- union { \
- ctype z; \
- type a[2]; \
- } __z_repr; \
- __z_repr.z = z; \
- \
- return __z_repr.a[index];
-
-static NPY_INLINE double npy_creal(npy_cdouble z)
-{
- __NPY_CEXTRACT_IMP(z, 0, double, npy_cdouble);
-}
-
-static NPY_INLINE double npy_cimag(npy_cdouble z)
-{
- __NPY_CEXTRACT_IMP(z, 1, double, npy_cdouble);
-}
-
-static NPY_INLINE float npy_crealf(npy_cfloat z)
-{
- __NPY_CEXTRACT_IMP(z, 0, float, npy_cfloat);
-}
-
-static NPY_INLINE float npy_cimagf(npy_cfloat z)
-{
- __NPY_CEXTRACT_IMP(z, 1, float, npy_cfloat);
-}
-
-static NPY_INLINE npy_longdouble npy_creall(npy_clongdouble z)
-{
- __NPY_CEXTRACT_IMP(z, 0, npy_longdouble, npy_clongdouble);
-}
-
-static NPY_INLINE npy_longdouble npy_cimagl(npy_clongdouble z)
-{
- __NPY_CEXTRACT_IMP(z, 1, npy_longdouble, npy_clongdouble);
-}
-#undef __NPY_CEXTRACT_IMP
-
-/*
- * Double precision complex functions
- */
-double npy_cabs(npy_cdouble z);
-double npy_carg(npy_cdouble z);
-
-npy_cdouble npy_cexp(npy_cdouble z);
-npy_cdouble npy_clog(npy_cdouble z);
-npy_cdouble npy_cpow(npy_cdouble x, npy_cdouble y);
-
-npy_cdouble npy_csqrt(npy_cdouble z);
-
-npy_cdouble npy_ccos(npy_cdouble z);
-npy_cdouble npy_csin(npy_cdouble z);
-
-/*
- * Single precision complex functions
- */
-float npy_cabsf(npy_cfloat z);
-float npy_cargf(npy_cfloat z);
-
-npy_cfloat npy_cexpf(npy_cfloat z);
-npy_cfloat npy_clogf(npy_cfloat z);
-npy_cfloat npy_cpowf(npy_cfloat x, npy_cfloat y);
-
-npy_cfloat npy_csqrtf(npy_cfloat z);
-
-npy_cfloat npy_ccosf(npy_cfloat z);
-npy_cfloat npy_csinf(npy_cfloat z);
-
-/*
- * Extended precision complex functions
- */
-npy_longdouble npy_cabsl(npy_clongdouble z);
-npy_longdouble npy_cargl(npy_clongdouble z);
-
-npy_clongdouble npy_cexpl(npy_clongdouble z);
-npy_clongdouble npy_clogl(npy_clongdouble z);
-npy_clongdouble npy_cpowl(npy_clongdouble x, npy_clongdouble y);
-
-npy_clongdouble npy_csqrtl(npy_clongdouble z);
-
-npy_clongdouble npy_ccosl(npy_clongdouble z);
-npy_clongdouble npy_csinl(npy_clongdouble z);
-
-/*
- * Functions that set the floating point error
- * status word.
- */
-
-void npy_set_floatstatus_divbyzero(void);
-void npy_set_floatstatus_overflow(void);
-void npy_set_floatstatus_underflow(void);
-void npy_set_floatstatus_invalid(void);
-
-#endif
diff --git a/include/numpy/npy_no_deprecated_api.h b/include/numpy/npy_no_deprecated_api.h
deleted file mode 100644
index 6183dc2..0000000
--- a/include/numpy/npy_no_deprecated_api.h
+++ /dev/null
@@ -1,19 +0,0 @@
-/*
- * This include file is provided for inclusion in Cython *.pyd files where
- * one would like to define the NPY_NO_DEPRECATED_API macro. It can be
- * included by
- *
- * cdef extern from "npy_no_deprecated_api.h": pass
- *
- */
-#ifndef NPY_NO_DEPRECATED_API
-
-/* put this check here since there may be multiple includes in C extensions. */
-#if defined(NDARRAYTYPES_H) || defined(_NPY_DEPRECATED_API_H) || \
- defined(OLD_DEFINES_H)
-#error "npy_no_deprecated_api.h" must be first among numpy includes.
-#else
-#define NPY_NO_DEPRECATED_API NPY_API_VERSION
-#endif
-
-#endif
diff --git a/include/numpy/npy_os.h b/include/numpy/npy_os.h
deleted file mode 100644
index 9228c39..0000000
--- a/include/numpy/npy_os.h
+++ /dev/null
@@ -1,30 +0,0 @@
-#ifndef _NPY_OS_H_
-#define _NPY_OS_H_
-
-#if defined(linux) || defined(__linux) || defined(__linux__)
- #define NPY_OS_LINUX
-#elif defined(__FreeBSD__) || defined(__NetBSD__) || \
- defined(__OpenBSD__) || defined(__DragonFly__)
- #define NPY_OS_BSD
- #ifdef __FreeBSD__
- #define NPY_OS_FREEBSD
- #elif defined(__NetBSD__)
- #define NPY_OS_NETBSD
- #elif defined(__OpenBSD__)
- #define NPY_OS_OPENBSD
- #elif defined(__DragonFly__)
- #define NPY_OS_DRAGONFLY
- #endif
-#elif defined(sun) || defined(__sun)
- #define NPY_OS_SOLARIS
-#elif defined(__CYGWIN__)
- #define NPY_OS_CYGWIN
-#elif defined(_WIN32) || defined(__WIN32__) || defined(WIN32)
- #define NPY_OS_WIN32
-#elif defined(__APPLE__)
- #define NPY_OS_DARWIN
-#else
- #define NPY_OS_UNKNOWN
-#endif
-
-#endif
diff --git a/include/numpy/numpyconfig.h b/include/numpy/numpyconfig.h
deleted file mode 100644
index 401d19f..0000000
--- a/include/numpy/numpyconfig.h
+++ /dev/null
@@ -1,33 +0,0 @@
-#ifndef _NPY_NUMPYCONFIG_H_
-#define _NPY_NUMPYCONFIG_H_
-
-#include "_numpyconfig.h"
-
-/*
- * On Mac OS X, because there is only one configuration stage for all the archs
- * in universal builds, any macro which depends on the arch needs to be
- * harcoded
- */
-#ifdef __APPLE__
- #undef NPY_SIZEOF_LONG
- #undef NPY_SIZEOF_PY_INTPTR_T
-
- #ifdef __LP64__
- #define NPY_SIZEOF_LONG 8
- #define NPY_SIZEOF_PY_INTPTR_T 8
- #else
- #define NPY_SIZEOF_LONG 4
- #define NPY_SIZEOF_PY_INTPTR_T 4
- #endif
-#endif
-
-/**
- * To help with the NPY_NO_DEPRECATED_API macro, we include API version
- * numbers for specific versions of NumPy. To exclude all API that was
- * deprecated as of 1.7, add the following before #including any NumPy
- * headers:
- * #define NPY_NO_DEPRECATED_API NPY_1_7_API_VERSION
- */
-#define NPY_1_7_API_VERSION 0x00000007
-
-#endif
diff --git a/include/numpy/old_defines.h b/include/numpy/old_defines.h
deleted file mode 100644
index abf8159..0000000
--- a/include/numpy/old_defines.h
+++ /dev/null
@@ -1,187 +0,0 @@
-/* This header is deprecated as of NumPy 1.7 */
-#ifndef OLD_DEFINES_H
-#define OLD_DEFINES_H
-
-#if defined(NPY_NO_DEPRECATED_API) && NPY_NO_DEPRECATED_API >= NPY_1_7_API_VERSION
-#error The header "old_defines.h" is deprecated as of NumPy 1.7.
-#endif
-
-#define NDARRAY_VERSION NPY_VERSION
-
-#define PyArray_MIN_BUFSIZE NPY_MIN_BUFSIZE
-#define PyArray_MAX_BUFSIZE NPY_MAX_BUFSIZE
-#define PyArray_BUFSIZE NPY_BUFSIZE
-
-#define PyArray_PRIORITY NPY_PRIORITY
-#define PyArray_SUBTYPE_PRIORITY NPY_PRIORITY
-#define PyArray_NUM_FLOATTYPE NPY_NUM_FLOATTYPE
-
-#define NPY_MAX PyArray_MAX
-#define NPY_MIN PyArray_MIN
-
-#define PyArray_TYPES NPY_TYPES
-#define PyArray_BOOL NPY_BOOL
-#define PyArray_BYTE NPY_BYTE
-#define PyArray_UBYTE NPY_UBYTE
-#define PyArray_SHORT NPY_SHORT
-#define PyArray_USHORT NPY_USHORT
-#define PyArray_INT NPY_INT
-#define PyArray_UINT NPY_UINT
-#define PyArray_LONG NPY_LONG
-#define PyArray_ULONG NPY_ULONG
-#define PyArray_LONGLONG NPY_LONGLONG
-#define PyArray_ULONGLONG NPY_ULONGLONG
-#define PyArray_HALF NPY_HALF
-#define PyArray_FLOAT NPY_FLOAT
-#define PyArray_DOUBLE NPY_DOUBLE
-#define PyArray_LONGDOUBLE NPY_LONGDOUBLE
-#define PyArray_CFLOAT NPY_CFLOAT
-#define PyArray_CDOUBLE NPY_CDOUBLE
-#define PyArray_CLONGDOUBLE NPY_CLONGDOUBLE
-#define PyArray_OBJECT NPY_OBJECT
-#define PyArray_STRING NPY_STRING
-#define PyArray_UNICODE NPY_UNICODE
-#define PyArray_VOID NPY_VOID
-#define PyArray_DATETIME NPY_DATETIME
-#define PyArray_TIMEDELTA NPY_TIMEDELTA
-#define PyArray_NTYPES NPY_NTYPES
-#define PyArray_NOTYPE NPY_NOTYPE
-#define PyArray_CHAR NPY_CHAR
-#define PyArray_USERDEF NPY_USERDEF
-#define PyArray_NUMUSERTYPES NPY_NUMUSERTYPES
-
-#define PyArray_INTP NPY_INTP
-#define PyArray_UINTP NPY_UINTP
-
-#define PyArray_INT8 NPY_INT8
-#define PyArray_UINT8 NPY_UINT8
-#define PyArray_INT16 NPY_INT16
-#define PyArray_UINT16 NPY_UINT16
-#define PyArray_INT32 NPY_INT32
-#define PyArray_UINT32 NPY_UINT32
-
-#ifdef NPY_INT64
-#define PyArray_INT64 NPY_INT64
-#define PyArray_UINT64 NPY_UINT64
-#endif
-
-#ifdef NPY_INT128
-#define PyArray_INT128 NPY_INT128
-#define PyArray_UINT128 NPY_UINT128
-#endif
-
-#ifdef NPY_FLOAT16
-#define PyArray_FLOAT16 NPY_FLOAT16
-#define PyArray_COMPLEX32 NPY_COMPLEX32
-#endif
-
-#ifdef NPY_FLOAT80
-#define PyArray_FLOAT80 NPY_FLOAT80
-#define PyArray_COMPLEX160 NPY_COMPLEX160
-#endif
-
-#ifdef NPY_FLOAT96
-#define PyArray_FLOAT96 NPY_FLOAT96
-#define PyArray_COMPLEX192 NPY_COMPLEX192
-#endif
-
-#ifdef NPY_FLOAT128
-#define PyArray_FLOAT128 NPY_FLOAT128
-#define PyArray_COMPLEX256 NPY_COMPLEX256
-#endif
-
-#define PyArray_FLOAT32 NPY_FLOAT32
-#define PyArray_COMPLEX64 NPY_COMPLEX64
-#define PyArray_FLOAT64 NPY_FLOAT64
-#define PyArray_COMPLEX128 NPY_COMPLEX128
-
-
-#define PyArray_TYPECHAR NPY_TYPECHAR
-#define PyArray_BOOLLTR NPY_BOOLLTR
-#define PyArray_BYTELTR NPY_BYTELTR
-#define PyArray_UBYTELTR NPY_UBYTELTR
-#define PyArray_SHORTLTR NPY_SHORTLTR
-#define PyArray_USHORTLTR NPY_USHORTLTR
-#define PyArray_INTLTR NPY_INTLTR
-#define PyArray_UINTLTR NPY_UINTLTR
-#define PyArray_LONGLTR NPY_LONGLTR
-#define PyArray_ULONGLTR NPY_ULONGLTR
-#define PyArray_LONGLONGLTR NPY_LONGLONGLTR
-#define PyArray_ULONGLONGLTR NPY_ULONGLONGLTR
-#define PyArray_HALFLTR NPY_HALFLTR
-#define PyArray_FLOATLTR NPY_FLOATLTR
-#define PyArray_DOUBLELTR NPY_DOUBLELTR
-#define PyArray_LONGDOUBLELTR NPY_LONGDOUBLELTR
-#define PyArray_CFLOATLTR NPY_CFLOATLTR
-#define PyArray_CDOUBLELTR NPY_CDOUBLELTR
-#define PyArray_CLONGDOUBLELTR NPY_CLONGDOUBLELTR
-#define PyArray_OBJECTLTR NPY_OBJECTLTR
-#define PyArray_STRINGLTR NPY_STRINGLTR
-#define PyArray_STRINGLTR2 NPY_STRINGLTR2
-#define PyArray_UNICODELTR NPY_UNICODELTR
-#define PyArray_VOIDLTR NPY_VOIDLTR
-#define PyArray_DATETIMELTR NPY_DATETIMELTR
-#define PyArray_TIMEDELTALTR NPY_TIMEDELTALTR
-#define PyArray_CHARLTR NPY_CHARLTR
-#define PyArray_INTPLTR NPY_INTPLTR
-#define PyArray_UINTPLTR NPY_UINTPLTR
-#define PyArray_GENBOOLLTR NPY_GENBOOLLTR
-#define PyArray_SIGNEDLTR NPY_SIGNEDLTR
-#define PyArray_UNSIGNEDLTR NPY_UNSIGNEDLTR
-#define PyArray_FLOATINGLTR NPY_FLOATINGLTR
-#define PyArray_COMPLEXLTR NPY_COMPLEXLTR
-
-#define PyArray_QUICKSORT NPY_QUICKSORT
-#define PyArray_HEAPSORT NPY_HEAPSORT
-#define PyArray_MERGESORT NPY_MERGESORT
-#define PyArray_SORTKIND NPY_SORTKIND
-#define PyArray_NSORTS NPY_NSORTS
-
-#define PyArray_NOSCALAR NPY_NOSCALAR
-#define PyArray_BOOL_SCALAR NPY_BOOL_SCALAR
-#define PyArray_INTPOS_SCALAR NPY_INTPOS_SCALAR
-#define PyArray_INTNEG_SCALAR NPY_INTNEG_SCALAR
-#define PyArray_FLOAT_SCALAR NPY_FLOAT_SCALAR
-#define PyArray_COMPLEX_SCALAR NPY_COMPLEX_SCALAR
-#define PyArray_OBJECT_SCALAR NPY_OBJECT_SCALAR
-#define PyArray_SCALARKIND NPY_SCALARKIND
-#define PyArray_NSCALARKINDS NPY_NSCALARKINDS
-
-#define PyArray_ANYORDER NPY_ANYORDER
-#define PyArray_CORDER NPY_CORDER
-#define PyArray_FORTRANORDER NPY_FORTRANORDER
-#define PyArray_ORDER NPY_ORDER
-
-#define PyDescr_ISBOOL PyDataType_ISBOOL
-#define PyDescr_ISUNSIGNED PyDataType_ISUNSIGNED
-#define PyDescr_ISSIGNED PyDataType_ISSIGNED
-#define PyDescr_ISINTEGER PyDataType_ISINTEGER
-#define PyDescr_ISFLOAT PyDataType_ISFLOAT
-#define PyDescr_ISNUMBER PyDataType_ISNUMBER
-#define PyDescr_ISSTRING PyDataType_ISSTRING
-#define PyDescr_ISCOMPLEX PyDataType_ISCOMPLEX
-#define PyDescr_ISPYTHON PyDataType_ISPYTHON
-#define PyDescr_ISFLEXIBLE PyDataType_ISFLEXIBLE
-#define PyDescr_ISUSERDEF PyDataType_ISUSERDEF
-#define PyDescr_ISEXTENDED PyDataType_ISEXTENDED
-#define PyDescr_ISOBJECT PyDataType_ISOBJECT
-#define PyDescr_HASFIELDS PyDataType_HASFIELDS
-
-#define PyArray_LITTLE NPY_LITTLE
-#define PyArray_BIG NPY_BIG
-#define PyArray_NATIVE NPY_NATIVE
-#define PyArray_SWAP NPY_SWAP
-#define PyArray_IGNORE NPY_IGNORE
-
-#define PyArray_NATBYTE NPY_NATBYTE
-#define PyArray_OPPBYTE NPY_OPPBYTE
-
-#define PyArray_MAX_ELSIZE NPY_MAX_ELSIZE
-
-#define PyArray_USE_PYMEM NPY_USE_PYMEM
-
-#define PyArray_RemoveLargest PyArray_RemoveSmallest
-
-#define PyArray_UCS4 npy_ucs4
-
-#endif
diff --git a/include/numpy/oldnumeric.h b/include/numpy/oldnumeric.h
deleted file mode 100644
index 748f06d..0000000
--- a/include/numpy/oldnumeric.h
+++ /dev/null
@@ -1,23 +0,0 @@
-#include "arrayobject.h"
-
-#ifndef REFCOUNT
-# define REFCOUNT NPY_REFCOUNT
-# define MAX_ELSIZE 16
-#endif
-
-#define PyArray_UNSIGNED_TYPES
-#define PyArray_SBYTE NPY_BYTE
-#define PyArray_CopyArray PyArray_CopyInto
-#define _PyArray_multiply_list PyArray_MultiplyIntList
-#define PyArray_ISSPACESAVER(m) NPY_FALSE
-#define PyScalarArray_Check PyArray_CheckScalar
-
-#define CONTIGUOUS NPY_CONTIGUOUS
-#define OWN_DIMENSIONS 0
-#define OWN_STRIDES 0
-#define OWN_DATA NPY_OWNDATA
-#define SAVESPACE 0
-#define SAVESPACEBIT 0
-
-#undef import_array
-#define import_array() { if (_import_array() < 0) {PyErr_Print(); PyErr_SetString(PyExc_ImportError, "numpy.core.multiarray failed to import"); } }
diff --git a/include/numpy/ufunc_api.txt b/include/numpy/ufunc_api.txt
deleted file mode 100644
index 3365433..0000000
--- a/include/numpy/ufunc_api.txt
+++ /dev/null
@@ -1,312 +0,0 @@
-
-=================
-Numpy Ufunc C-API
-=================
-::
-
- PyObject *
- PyUFunc_FromFuncAndData(PyUFuncGenericFunction *func, void
- **data, char *types, int ntypes, int nin, int
- nout, int identity, char *name, char *doc, int
- check_return)
-
-
-::
-
- int
- PyUFunc_RegisterLoopForType(PyUFuncObject *ufunc, int
- usertype, PyUFuncGenericFunction
- function, int *arg_types, void *data)
-
-
-::
-
- int
- PyUFunc_GenericFunction(PyUFuncObject *ufunc, PyObject *args, PyObject
- *kwds, PyArrayObject **op)
-
-
-This generic function is called with the ufunc object, the arguments to it,
-and an array of (pointers to) PyArrayObjects which are NULL.
-
-'op' is an array of at least NPY_MAXARGS PyArrayObject *.
-
-::
-
- void
- PyUFunc_f_f_As_d_d(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_d_d(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_f_f(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_g_g(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_F_F_As_D_D(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_F_F(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_D_D(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_G_G(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_O_O(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_ff_f_As_dd_d(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_ff_f(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_dd_d(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_gg_g(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_FF_F_As_DD_D(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_DD_D(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_FF_F(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_GG_G(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_OO_O(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_O_O_method(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_OO_O_method(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_On_Om(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- int
- PyUFunc_GetPyValues(char *name, int *bufsize, int *errmask, PyObject
- **errobj)
-
-
-On return, if errobj is populated with a non-NULL value, the caller
-owns a new reference to errobj.
-
-::
-
- int
- PyUFunc_checkfperr(int errmask, PyObject *errobj, int *first)
-
-
-::
-
- void
- PyUFunc_clearfperr()
-
-
-::
-
- int
- PyUFunc_getfperr(void )
-
-
-::
-
- int
- PyUFunc_handlefperr(int errmask, PyObject *errobj, int retstatus, int
- *first)
-
-
-::
-
- int
- PyUFunc_ReplaceLoopBySignature(PyUFuncObject
- *func, PyUFuncGenericFunction
- newfunc, int
- *signature, PyUFuncGenericFunction
- *oldfunc)
-
-
-::
-
- PyObject *
- PyUFunc_FromFuncAndDataAndSignature(PyUFuncGenericFunction *func, void
- **data, char *types, int
- ntypes, int nin, int nout, int
- identity, char *name, char
- *doc, int check_return, const char
- *signature)
-
-
-::
-
- int
- PyUFunc_SetUsesArraysAsData(void **data, size_t i)
-
-
-::
-
- void
- PyUFunc_e_e(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_e_e_As_f_f(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_e_e_As_d_d(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_ee_e(char **args, npy_intp *dimensions, npy_intp *steps, void
- *func)
-
-
-::
-
- void
- PyUFunc_ee_e_As_ff_f(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- void
- PyUFunc_ee_e_As_dd_d(char **args, npy_intp *dimensions, npy_intp
- *steps, void *func)
-
-
-::
-
- int
- PyUFunc_DefaultTypeResolver(PyUFuncObject *ufunc, NPY_CASTING
- casting, PyArrayObject
- **operands, PyObject
- *type_tup, PyArray_Descr **out_dtypes)
-
-
-This function applies the default type resolution rules
-for the provided ufunc.
-
-Returns 0 on success, -1 on error.
-
-::
-
- int
- PyUFunc_ValidateCasting(PyUFuncObject *ufunc, NPY_CASTING
- casting, PyArrayObject
- **operands, PyArray_Descr **dtypes)
-
-
-Validates that the input operands can be cast to
-the input types, and the output types can be cast to
-the output operands where provided.
-
-Returns 0 on success, -1 (with exception raised) on validation failure.
-
diff --git a/include/numpy/ufuncobject.h b/include/numpy/ufuncobject.h
deleted file mode 100644
index 076dd88..0000000
--- a/include/numpy/ufuncobject.h
+++ /dev/null
@@ -1,448 +0,0 @@
-#ifndef Py_UFUNCOBJECT_H
-#define Py_UFUNCOBJECT_H
-
-#include
-
-#ifdef __cplusplus
-extern "C" {
-#endif
-
-/*
- * The legacy generic inner loop for a standard element-wise or
- * generalized ufunc.
- */
-typedef void (*PyUFuncGenericFunction)
- (char **args,
- npy_intp *dimensions,
- npy_intp *strides,
- void *innerloopdata);
-
-/*
- * The most generic one-dimensional inner loop for
- * a standard element-wise ufunc. This typedef is also
- * more consistent with the other NumPy function pointer typedefs
- * than PyUFuncGenericFunction.
- */
-typedef void (PyUFunc_StridedInnerLoopFunc)(
- char **dataptrs, npy_intp *strides,
- npy_intp count,
- NpyAuxData *innerloopdata);
-
-/*
- * The most generic one-dimensional inner loop for
- * a masked standard element-wise ufunc. "Masked" here means that it skips
- * doing calculations on any items for which the maskptr array has a true
- * value.
- */
-typedef void (PyUFunc_MaskedStridedInnerLoopFunc)(
- char **dataptrs, npy_intp *strides,
- char *maskptr, npy_intp mask_stride,
- npy_intp count,
- NpyAuxData *innerloopdata);
-
-/* Forward declaration for the type resolver and loop selector typedefs */
-struct _tagPyUFuncObject;
-
-/*
- * Given the operands for calling a ufunc, should determine the
- * calculation input and output data types and return an inner loop function.
- * This function should validate that the casting rule is being followed,
- * and fail if it is not.
- *
- * For backwards compatibility, the regular type resolution function does not
- * support auxiliary data with object semantics. The type resolution call
- * which returns a masked generic function returns a standard NpyAuxData
- * object, for which the NPY_AUXDATA_FREE and NPY_AUXDATA_CLONE macros
- * work.
- *
- * ufunc: The ufunc object.
- * casting: The 'casting' parameter provided to the ufunc.
- * operands: An array of length (ufunc->nin + ufunc->nout),
- * with the output parameters possibly NULL.
- * type_tup: Either NULL, or the type_tup passed to the ufunc.
- * out_dtypes: An array which should be populated with new
- * references to (ufunc->nin + ufunc->nout) new
- * dtypes, one for each input and output. These
- * dtypes should all be in native-endian format.
- *
- * Should return 0 on success, -1 on failure (with exception set),
- * or -2 if Py_NotImplemented should be returned.
- */
-typedef int (PyUFunc_TypeResolutionFunc)(
- struct _tagPyUFuncObject *ufunc,
- NPY_CASTING casting,
- PyArrayObject **operands,
- PyObject *type_tup,
- PyArray_Descr **out_dtypes);
-
-/*
- * Given an array of DTypes as returned by the PyUFunc_TypeResolutionFunc,
- * and an array of fixed strides (the array will contain NPY_MAX_INTP for
- * strides which are not necessarily fixed), returns an inner loop
- * with associated auxiliary data.
- *
- * For backwards compatibility, there is a variant of the inner loop
- * selection which returns an inner loop irrespective of the strides,
- * and with a void* static auxiliary data instead of an NpyAuxData *
- * dynamically allocatable auxiliary data.
- *
- * ufunc: The ufunc object.
- * dtypes: An array which has been populated with dtypes,
- * in most cases by the type resolution funciton
- * for the same ufunc.
- * fixed_strides: For each input/output, either the stride that
- * will be used every time the function is called
- * or NPY_MAX_INTP if the stride might change or
- * is not known ahead of time. The loop selection
- * function may use this stride to pick inner loops
- * which are optimized for contiguous or 0-stride
- * cases.
- * out_innerloop: Should be populated with the correct ufunc inner
- * loop for the given type.
- * out_innerloopdata: Should be populated with the void* data to
- * be passed into the out_innerloop function.
- * out_needs_api: If the inner loop needs to use the Python API,
- * should set the to 1, otherwise should leave
- * this untouched.
- */
-typedef int (PyUFunc_LegacyInnerLoopSelectionFunc)(
- struct _tagPyUFuncObject *ufunc,
- PyArray_Descr **dtypes,
- PyUFuncGenericFunction *out_innerloop,
- void **out_innerloopdata,
- int *out_needs_api);
-typedef int (PyUFunc_InnerLoopSelectionFunc)(
- struct _tagPyUFuncObject *ufunc,
- PyArray_Descr **dtypes,
- npy_intp *fixed_strides,
- PyUFunc_StridedInnerLoopFunc **out_innerloop,
- NpyAuxData **out_innerloopdata,
- int *out_needs_api);
-typedef int (PyUFunc_MaskedInnerLoopSelectionFunc)(
- struct _tagPyUFuncObject *ufunc,
- PyArray_Descr **dtypes,
- PyArray_Descr *mask_dtype,
- npy_intp *fixed_strides,
- npy_intp fixed_mask_stride,
- PyUFunc_MaskedStridedInnerLoopFunc **out_innerloop,
- NpyAuxData **out_innerloopdata,
- int *out_needs_api);
-
-typedef struct _tagPyUFuncObject {
- PyObject_HEAD
- /*
- * nin: Number of inputs
- * nout: Number of outputs
- * nargs: Always nin + nout (Why is it stored?)
- */
- int nin, nout, nargs;
-
- /* Identity for reduction, either PyUFunc_One or PyUFunc_Zero */
- int identity;
-
- /* Array of one-dimensional core loops */
- PyUFuncGenericFunction *functions;
- /* Array of funcdata that gets passed into the functions */
- void **data;
- /* The number of elements in 'functions' and 'data' */
- int ntypes;
-
- /* Does not appear to be used */
- int check_return;
-
- /* The name of the ufunc */
- char *name;
-
- /* Array of type numbers, of size ('nargs' * 'ntypes') */
- char *types;
-
- /* Documentation string */
- char *doc;
-
- void *ptr;
- PyObject *obj;
- PyObject *userloops;
-
- /* generalized ufunc parameters */
-
- /* 0 for scalar ufunc; 1 for generalized ufunc */
- int core_enabled;
- /* number of distinct dimension names in signature */
- int core_num_dim_ix;
-
- /*
- * dimension indices of input/output argument k are stored in
- * core_dim_ixs[core_offsets[k]..core_offsets[k]+core_num_dims[k]-1]
- */
-
- /* numbers of core dimensions of each argument */
- int *core_num_dims;
- /*
- * dimension indices in a flatted form; indices
- * are in the range of [0,core_num_dim_ix)
- */
- int *core_dim_ixs;
- /*
- * positions of 1st core dimensions of each
- * argument in core_dim_ixs
- */
- int *core_offsets;
- /* signature string for printing purpose */
- char *core_signature;
-
- /*
- * A function which resolves the types and fills an array
- * with the dtypes for the inputs and outputs.
- */
- PyUFunc_TypeResolutionFunc *type_resolver;
- /*
- * A function which returns an inner loop written for
- * NumPy 1.6 and earlier ufuncs. This is for backwards
- * compatibility, and may be NULL if inner_loop_selector
- * is specified.
- */
- PyUFunc_LegacyInnerLoopSelectionFunc *legacy_inner_loop_selector;
- /*
- * A function which returns an inner loop for the new mechanism
- * in NumPy 1.7 and later. If provided, this is used, otherwise
- * if NULL the legacy_inner_loop_selector is used instead.
- */
- PyUFunc_InnerLoopSelectionFunc *inner_loop_selector;
- /*
- * A function which returns a masked inner loop for the ufunc.
- */
- PyUFunc_MaskedInnerLoopSelectionFunc *masked_inner_loop_selector;
-} PyUFuncObject;
-
-#include "arrayobject.h"
-
-#define UFUNC_ERR_IGNORE 0
-#define UFUNC_ERR_WARN 1
-#define UFUNC_ERR_RAISE 2
-#define UFUNC_ERR_CALL 3
-#define UFUNC_ERR_PRINT 4
-#define UFUNC_ERR_LOG 5
-
- /* Python side integer mask */
-
-#define UFUNC_MASK_DIVIDEBYZERO 0x07
-#define UFUNC_MASK_OVERFLOW 0x3f
-#define UFUNC_MASK_UNDERFLOW 0x1ff
-#define UFUNC_MASK_INVALID 0xfff
-
-#define UFUNC_SHIFT_DIVIDEBYZERO 0
-#define UFUNC_SHIFT_OVERFLOW 3
-#define UFUNC_SHIFT_UNDERFLOW 6
-#define UFUNC_SHIFT_INVALID 9
-
-
-/* platform-dependent code translates floating point
- status to an integer sum of these values
-*/
-#define UFUNC_FPE_DIVIDEBYZERO 1
-#define UFUNC_FPE_OVERFLOW 2
-#define UFUNC_FPE_UNDERFLOW 4
-#define UFUNC_FPE_INVALID 8
-
-/* Error mode that avoids look-up (no checking) */
-#define UFUNC_ERR_DEFAULT 0
-
-#define UFUNC_OBJ_ISOBJECT 1
-#define UFUNC_OBJ_NEEDS_API 2
-
- /* Default user error mode */
-#define UFUNC_ERR_DEFAULT2 \
- (UFUNC_ERR_WARN << UFUNC_SHIFT_DIVIDEBYZERO) + \
- (UFUNC_ERR_WARN << UFUNC_SHIFT_OVERFLOW) + \
- (UFUNC_ERR_WARN << UFUNC_SHIFT_INVALID)
-
-#if NPY_ALLOW_THREADS
-#define NPY_LOOP_BEGIN_THREADS do {if (!(loop->obj & UFUNC_OBJ_NEEDS_API)) _save = PyEval_SaveThread();} while (0);
-#define NPY_LOOP_END_THREADS do {if (!(loop->obj & UFUNC_OBJ_NEEDS_API)) PyEval_RestoreThread(_save);} while (0);
-#else
-#define NPY_LOOP_BEGIN_THREADS
-#define NPY_LOOP_END_THREADS
-#endif
-
-/*
- * UFunc has unit of 1, and the order of operations can be reordered
- * This case allows reduction with multiple axes at once.
- */
-#define PyUFunc_One 1
-/*
- * UFunc has unit of 0, and the order of operations can be reordered
- * This case allows reduction with multiple axes at once.
- */
-#define PyUFunc_Zero 0
-/*
- * UFunc has no unit, and the order of operations cannot be reordered.
- * This case does not allow reduction with multiple axes at once.
- */
-#define PyUFunc_None -1
-/*
- * UFunc has no unit, and the order of operations can be reordered
- * This case allows reduction with multiple axes at once.
- */
-#define PyUFunc_ReorderableNone -2
-
-#define UFUNC_REDUCE 0
-#define UFUNC_ACCUMULATE 1
-#define UFUNC_REDUCEAT 2
-#define UFUNC_OUTER 3
-
-
-typedef struct {
- int nin;
- int nout;
- PyObject *callable;
-} PyUFunc_PyFuncData;
-
-/* A linked-list of function information for
- user-defined 1-d loops.
- */
-typedef struct _loop1d_info {
- PyUFuncGenericFunction func;
- void *data;
- int *arg_types;
- struct _loop1d_info *next;
-} PyUFunc_Loop1d;
-
-
-#include "__ufunc_api.h"
-
-#define UFUNC_PYVALS_NAME "UFUNC_PYVALS"
-
-#define UFUNC_CHECK_ERROR(arg) \
- do {if ((((arg)->obj & UFUNC_OBJ_NEEDS_API) && PyErr_Occurred()) || \
- ((arg)->errormask && \
- PyUFunc_checkfperr((arg)->errormask, \
- (arg)->errobj, \
- &(arg)->first))) \
- goto fail;} while (0)
-
-/* This code checks the IEEE status flags in a platform-dependent way */
-/* Adapted from Numarray */
-
-#if (defined(__unix__) || defined(unix)) && !defined(USG)
-#include
-#endif
-
-/* OSF/Alpha (Tru64) ---------------------------------------------*/
-#if defined(__osf__) && defined(__alpha)
-
-#include
-
-#define UFUNC_CHECK_STATUS(ret) { \
- unsigned long fpstatus; \
- \
- fpstatus = ieee_get_fp_control(); \
- /* clear status bits as well as disable exception mode if on */ \
- ieee_set_fp_control( 0 ); \
- ret = ((IEEE_STATUS_DZE & fpstatus) ? UFUNC_FPE_DIVIDEBYZERO : 0) \
- | ((IEEE_STATUS_OVF & fpstatus) ? UFUNC_FPE_OVERFLOW : 0) \
- | ((IEEE_STATUS_UNF & fpstatus) ? UFUNC_FPE_UNDERFLOW : 0) \
- | ((IEEE_STATUS_INV & fpstatus) ? UFUNC_FPE_INVALID : 0); \
- }
-
-/* MS Windows -----------------------------------------------------*/
-#elif defined(_MSC_VER)
-
-#include
-
- /* Clear the floating point exception default of Borland C++ */
-#if defined(__BORLANDC__)
-#define UFUNC_NOFPE _control87(MCW_EM, MCW_EM);
-#endif
-
-#define UFUNC_CHECK_STATUS(ret) { \
- int fpstatus = (int) _clearfp(); \
- \
- ret = ((SW_ZERODIVIDE & fpstatus) ? UFUNC_FPE_DIVIDEBYZERO : 0) \
- | ((SW_OVERFLOW & fpstatus) ? UFUNC_FPE_OVERFLOW : 0) \
- | ((SW_UNDERFLOW & fpstatus) ? UFUNC_FPE_UNDERFLOW : 0) \
- | ((SW_INVALID & fpstatus) ? UFUNC_FPE_INVALID : 0); \
- }
-
-/* Solaris --------------------------------------------------------*/
-/* --------ignoring SunOS ieee_flags approach, someone else can
-** deal with that! */
-#elif defined(sun) || defined(__BSD__) || defined(__OpenBSD__) || \
- (defined(__FreeBSD__) && (__FreeBSD_version < 502114)) || \
- defined(__NetBSD__)
-#include
-
-#define UFUNC_CHECK_STATUS(ret) { \
- int fpstatus; \
- \
- fpstatus = (int) fpgetsticky(); \
- ret = ((FP_X_DZ & fpstatus) ? UFUNC_FPE_DIVIDEBYZERO : 0) \
- | ((FP_X_OFL & fpstatus) ? UFUNC_FPE_OVERFLOW : 0) \
- | ((FP_X_UFL & fpstatus) ? UFUNC_FPE_UNDERFLOW : 0) \
- | ((FP_X_INV & fpstatus) ? UFUNC_FPE_INVALID : 0); \
- (void) fpsetsticky(0); \
- }
-
-#elif defined(__GLIBC__) || defined(__APPLE__) || \
- defined(__CYGWIN__) || defined(__MINGW32__) || \
- (defined(__FreeBSD__) && (__FreeBSD_version >= 502114))
-
-#if defined(__GLIBC__) || defined(__APPLE__) || \
- defined(__MINGW32__) || defined(__FreeBSD__)
-#include
-#elif defined(__CYGWIN__)
-#include "fenv/fenv.c"
-#endif
-
-#define UFUNC_CHECK_STATUS(ret) { \
- int fpstatus = (int) fetestexcept(FE_DIVBYZERO | FE_OVERFLOW | \
- FE_UNDERFLOW | FE_INVALID); \
- ret = ((FE_DIVBYZERO & fpstatus) ? UFUNC_FPE_DIVIDEBYZERO : 0) \
- | ((FE_OVERFLOW & fpstatus) ? UFUNC_FPE_OVERFLOW : 0) \
- | ((FE_UNDERFLOW & fpstatus) ? UFUNC_FPE_UNDERFLOW : 0) \
- | ((FE_INVALID & fpstatus) ? UFUNC_FPE_INVALID : 0); \
- (void) feclearexcept(FE_DIVBYZERO | FE_OVERFLOW | \
- FE_UNDERFLOW | FE_INVALID); \
-}
-
-#elif defined(_AIX)
-
-#include
-#include
-
-#define UFUNC_CHECK_STATUS(ret) { \
- fpflag_t fpstatus; \
- \
- fpstatus = fp_read_flag(); \
- ret = ((FP_DIV_BY_ZERO & fpstatus) ? UFUNC_FPE_DIVIDEBYZERO : 0) \
- | ((FP_OVERFLOW & fpstatus) ? UFUNC_FPE_OVERFLOW : 0) \
- | ((FP_UNDERFLOW & fpstatus) ? UFUNC_FPE_UNDERFLOW : 0) \
- | ((FP_INVALID & fpstatus) ? UFUNC_FPE_INVALID : 0); \
- fp_swap_flag(0); \
-}
-
-#else
-
-#define NO_FLOATING_POINT_SUPPORT
-#define UFUNC_CHECK_STATUS(ret) { \
- ret = 0; \
- }
-
-#endif
-
-/*
- * THESE MACROS ARE DEPRECATED.
- * Use npy_set_floatstatus_* in the npymath library.
- */
-#define generate_divbyzero_error() npy_set_floatstatus_divbyzero()
-#define generate_overflow_error() npy_set_floatstatus_overflow()
-
- /* Make sure it gets defined if it isn't already */
-#ifndef UFUNC_NOFPE
-#define UFUNC_NOFPE
-#endif
-
-
-#ifdef __cplusplus
-}
-#endif
-#endif /* !Py_UFUNCOBJECT_H */
diff --git a/include/numpy/utils.h b/include/numpy/utils.h
deleted file mode 100644
index cc968a3..0000000
--- a/include/numpy/utils.h
+++ /dev/null
@@ -1,19 +0,0 @@
-#ifndef __NUMPY_UTILS_HEADER__
-#define __NUMPY_UTILS_HEADER__
-
-#ifndef __COMP_NPY_UNUSED
- #if defined(__GNUC__)
- #define __COMP_NPY_UNUSED __attribute__ ((__unused__))
- # elif defined(__ICC)
- #define __COMP_NPY_UNUSED __attribute__ ((__unused__))
- #else
- #define __COMP_NPY_UNUSED
- #endif
-#endif
-
-/* Use this to tag a variable as not used. It will remove unused variable
- * warning on support platforms (see __COM_NPY_UNUSED) and mangle the variable
- * to avoid accidental use */
-#define NPY_UNUSED(x) (__NPY_UNUSED_TAGGED ## x) __COMP_NPY_UNUSED
-
-#endif
diff --git a/pyproject.toml b/pyproject.toml
new file mode 100644
index 0000000..40810cc
--- /dev/null
+++ b/pyproject.toml
@@ -0,0 +1,5 @@
+[build-system]
+requires = [
+ "setuptools",
+]
+build-backend = "setuptools.build_meta"
diff --git a/requirements-all.txt b/requirements-all.txt
deleted file mode 100644
index e497b38..0000000
--- a/requirements-all.txt
+++ /dev/null
@@ -1,12 +0,0 @@
-cython<0.24
-numpy>=1.7
-ujson>=1.34
-spacy>=0.100,<0.101
-preshed>=0.46,<0.47
-murmurhash>=0.26,<0.27
-cymem>=1.30,<1.32
-sputnik>=0.9.0,<0.10.0
-pytest
-joblib
-toolz
-gensim
diff --git a/requirements.txt b/requirements.txt
index 5daf2c0..093de33 100644
--- a/requirements.txt
+++ b/requirements.txt
@@ -1,9 +1,10 @@
-cython<0.24
-numpy>=1.7
-ujson>=1.34
-spacy>=0.100.0,<0.102.0
-preshed>=0.46,<0.47
-murmurhash>=0.26,<0.27
-cymem>=1.30,<1.32
-sputnik>=0.9.0,<0.10.0
-pytest
+# Our packages
+spacy>=3.0.0,<4.0.0
+wasabi>=0.8.1,<1.2.0
+srsly>=2.4.0,<3.0.0
+catalogue>=2.0.1,<2.1.0
+# Third-party dependencies
+numpy>=1.15.0
+importlib_metadata>=0.20; python_version < "3.8"
+# Development requirements
+pytest>=5.2.0,!=7.1.0
diff --git a/scripts/01_parse.py b/scripts/01_parse.py
new file mode 100644
index 0000000..2733286
--- /dev/null
+++ b/scripts/01_parse.py
@@ -0,0 +1,65 @@
+#!/usr/bin/env python
+import spacy
+from spacy.tokens import DocBin
+from wasabi import msg
+from pathlib import Path
+import tqdm
+import typer
+
+
+def main(
+ # fmt: off
+ in_file: str = typer.Argument(..., help="Path to input file"),
+ out_dir: str = typer.Argument(..., help="Path to output directory"),
+ spacy_model: str = typer.Argument("en_core_web_sm", help="Name of spaCy model to use"),
+ n_process: int = typer.Option(1, "--n-process", "-n", help="Number of processes (multiprocessing)"),
+ max_docs: int = typer.Option(10 ** 6, "--max-docs", "-m", help="Maximum docs per batch"),
+ # fmt: on
+):
+ """
+ Step 1: Parse raw text with spaCy
+
+ Expects an input file with one sentence per line and will output a .spacy
+ file of the parsed collection of Doc objects (DocBin).
+ """
+ input_path = Path(in_file)
+ output_path = Path(out_dir)
+ if not input_path.exists():
+ msg.fail("Can't find input file", in_file, exits=1)
+ if not output_path.exists():
+ output_path.mkdir(parents=True)
+ msg.good(f"Created output directory {out_dir}")
+ nlp = spacy.load(spacy_model)
+ msg.info(f"Using spaCy model {spacy_model}")
+ doc_bin = DocBin(attrs=["POS", "TAG", "DEP", "ENT_TYPE", "ENT_IOB"])
+ msg.text("Preprocessing text...")
+ count = 0
+ batch_num = 0
+ with input_path.open("r", encoding="utf8") as texts:
+ docs = nlp.pipe(texts, n_process=n_process)
+ for doc in tqdm.tqdm(docs, desc="Docs", unit=""):
+ if count < max_docs:
+ doc_bin.add(doc)
+ count += 1
+ else:
+ batch_num += 1
+ count = 0
+ msg.good(f"Processed {len(doc_bin)} docs")
+ doc_bin_bytes = doc_bin.to_bytes()
+ output_file = output_path / f"{input_path.stem}-{batch_num}.spacy"
+ with output_file.open("wb") as f:
+ f.write(doc_bin_bytes)
+ msg.good(f"Saved parsed docs to file", output_file.resolve())
+ doc_bin = DocBin(attrs=["POS", "TAG", "DEP", "ENT_TYPE", "ENT_IOB"])
+ batch_num += 1
+ output_file = output_path / f"{input_path.stem}-{batch_num}.spacy"
+ with output_file.open("wb") as f:
+ doc_bin_bytes = doc_bin.to_bytes()
+ f.write(doc_bin_bytes)
+ msg.good(
+ f"Complete. Saved final parsed docs to file", output_file.resolve()
+ )
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/02_preprocess.py b/scripts/02_preprocess.py
new file mode 100644
index 0000000..b61eeb0
--- /dev/null
+++ b/scripts/02_preprocess.py
@@ -0,0 +1,69 @@
+#!/usr/bin/env python
+from sense2vec.util import make_key, make_spacy_key, merge_phrases
+import spacy
+from spacy.tokens import DocBin
+from wasabi import msg
+from pathlib import Path
+import tqdm
+import typer
+
+
+def main(
+ # fmt: off
+ in_file: str = typer.Argument(..., help="Path to input file"),
+ out_dir: str = typer.Argument(..., help="Path to output directory"),
+ spacy_model: str = typer.Argument("en_core_web_sm", help="Name of spaCy model to use"),
+ n_process: int = typer.Option(1, "--n-process", "-n", help="Number of processes (multiprocessing)"),
+ # fmt: on
+):
+ """
+ Step 2: Preprocess text in sense2vec's format
+
+ Expects a binary .spacy input file consisting of the parsed Docs (DocBin)
+ and outputs a text file with one sentence per line in the expected sense2vec
+ format (merged noun phrases, concatenated phrases with underscores and
+ added "senses").
+
+ Example input:
+ Rats, mould and broken furniture: the scandal of the UK's refugee housing
+
+ Example output:
+ Rats|NOUN ,|PUNCT mould|NOUN and|CCONJ broken_furniture|NOUN :|PUNCT
+ the|DET scandal|NOUN of|ADP the|DET UK|GPE 's|PART refugee_housing|NOUN
+ """
+ input_path = Path(in_file)
+ output_path = Path(out_dir)
+ if not input_path.exists():
+ msg.fail("Can't find input file", in_file, exits=1)
+ if not output_path.exists():
+ output_path.mkdir(parents=True)
+ msg.good(f"Created output directory {out_dir}")
+ nlp = spacy.load(spacy_model)
+ msg.info(f"Using spaCy model {spacy_model}")
+ with input_path.open("rb") as f:
+ doc_bin_bytes = f.read()
+ doc_bin = DocBin().from_bytes(doc_bin_bytes)
+ msg.good(f"Loaded {len(doc_bin)} parsed docs")
+ docs = doc_bin.get_docs(nlp.vocab)
+ output_file = output_path / f"{input_path.stem}.s2v"
+ lines_count = 0
+ words_count = 0
+ with output_file.open("w", encoding="utf8") as f:
+ for doc in tqdm.tqdm(docs, desc="Docs", unit=""):
+ doc = merge_phrases(doc)
+ words = []
+ for token in doc:
+ if not token.is_space:
+ word, sense = make_spacy_key(token, prefer_ents=True)
+ words.append(make_key(word, sense))
+ f.write(" ".join(words) + "\n")
+ lines_count += 1
+ words_count += len(words)
+ msg.good(
+ f"Successfully preprocessed {lines_count} docs ({words_count} words)",
+ output_file.resolve(),
+ )
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/03_glove_build_counts.py b/scripts/03_glove_build_counts.py
new file mode 100644
index 0000000..9e093e3
--- /dev/null
+++ b/scripts/03_glove_build_counts.py
@@ -0,0 +1,84 @@
+#!/usr/bin/env python
+import os
+from pathlib import Path
+from wasabi import msg
+import typer
+
+
+def main(
+ # fmt: off
+ glove_dir: str = typer.Argument(..., help="Directory containing the GloVe build"),
+ in_dir: str = typer.Argument(..., help="Directory with preprocessed .s2v files"),
+ out_dir: str = typer.Argument(..., help="Path to output directory"),
+ min_count: int = typer.Option(5, "--min-count", "-c", help="Minimum count for inclusion in vocab"),
+ memory: float = typer.Option(4.0, "--memory", "-m", help="Soft limit for memory consumption, in GB"),
+ window_size: int = typer.Option(15, "--window-size", "-w", help="Number of context words on either side"),
+ verbose: int = typer.Option(2, "--verbose", "-v", help="Set verbosity: 0, 1, or 2"),
+ # fmt: on
+):
+ """
+ Step 3: Build vocabulary and frequency counts
+
+ Expects a directory of preprocessed .s2v input files and will use GloVe to
+ collect unigram counts and construct and shuffle cooccurrence data. See here
+ for installation instructions: https://github.com/stanfordnlp/GloVe
+
+ Note that this script will call into GloVe and expects you to pass in the
+ GloVe build directory (/build if you run the Makefile). The commands will
+ also be printed if you want to run them separately.
+ """
+ input_path = Path(in_dir)
+ output_path = Path(out_dir)
+ if not Path(glove_dir).exists():
+ msg.fail("Can't find GloVe build directory", glove_dir, exits=1)
+ if not input_path.exists() or not input_path.is_dir():
+ msg.fail("Not a valid input directory", in_dir, exits=1)
+ input_files = [str(fp) for fp in input_path.iterdir() if fp.suffix == ".s2v"]
+ if not input_files:
+ msg.fail("No .s2v files found in input directory", in_dir, exits=1)
+ msg.info(f"Using {len(input_files)} input files")
+ if not output_path.exists():
+ output_path.mkdir(parents=True)
+ msg.good(f"Created output directory {out_dir}")
+
+ vocab_file = output_path / f"vocab.txt"
+ cooc_file = output_path / f"cooccurrence.bin"
+ cooc_shuffle_file = output_path / f"cooccurrence.shuf.bin"
+
+ msg.info("Creating vocabulary counts")
+ cmd = (
+ f"cat {' '.join(input_files)} | {glove_dir}/vocab_count "
+ f"-min-count {min_count} -verbose {verbose} > {vocab_file}"
+ )
+ print(cmd)
+ vocab_cmd = os.system(cmd)
+ if vocab_cmd != 0 or not Path(vocab_file).exists():
+ msg.fail("Failed creating vocab counts", exits=1)
+ msg.good("Created vocab counts", vocab_file)
+
+ msg.info("Creating cooccurrence statistics")
+ cmd = (
+ f"cat {' '.join(input_files)} | {glove_dir}/cooccur -memory {memory} "
+ f"-vocab-file {vocab_file} -verbose {verbose} "
+ f"-window-size {window_size} > {cooc_file}"
+ )
+ print(cmd)
+ cooccur_cmd = os.system(cmd)
+ if cooccur_cmd != 0 or not Path(cooc_file).exists():
+ msg.fail("Failed creating cooccurrence statistics", exits=1)
+ msg.good("Created cooccurrence statistics", cooc_file)
+
+ msg.info("Shuffling cooccurrence file")
+ cmd = (
+ f"{glove_dir}/shuffle -memory {memory} -verbose {verbose} "
+ f"< {cooc_file} > {cooc_shuffle_file}"
+ )
+ print(cmd)
+ shuffle_cmd = os.system(cmd)
+ if shuffle_cmd != 0 or not Path(cooc_shuffle_file).exists():
+ msg.fail("Failed to shuffle cooccurrence file", exits=1)
+ msg.good("Shuffled cooccurrence file", cooc_shuffle_file)
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/04_fasttext_train_vectors.py b/scripts/04_fasttext_train_vectors.py
new file mode 100644
index 0000000..b0cc1a3
--- /dev/null
+++ b/scripts/04_fasttext_train_vectors.py
@@ -0,0 +1,135 @@
+#!/usr/bin/env python
+from typing import Optional
+from pathlib import Path
+from wasabi import msg
+import fasttext
+from errno import EPIPE
+import typer
+
+# python 04_fasttext_train_vectors.py /path/to/output/director/ -in /path/to/input/directory
+
+
+def main(
+ # fmt: off
+ out_dir: str = typer.Argument(..., help="Path to output directory"),
+ in_dir: Optional[str] = typer.Argument(None, help="Path to directory with preprocessed .s2v file(s)"),
+ n_threads: int = typer.Option(10, "--n-threads", "-t", help="Number of threads"),
+ min_count: int = typer.Option(50, "--min-count", "-c", help="Minimum count for inclusion in vocab"),
+ vector_size: int = typer.Option(300, "--vector-size", "-s", help="Dimension of word vector representations"),
+ epoch: int = typer.Option(5, "--epoch", "-e", help="Number of times the fastText model will loop over your data"),
+ save_fasttext_model: bool = typer.Option(False, "--save-fasttext-model", "-sv", help="Save fastText model to output directory as a binary file to avoid retraining"),
+ fasttext_filepath: Optional[str] = typer.Option(None, "--fasttext-filepath", "-ft", help="Path to saved fastText model .bin file"),
+ verbose: int = typer.Option(2, "--verbose", "-v", help="Set verbosity: 0, 1, or 2"),
+ # fmt: on
+):
+ """
+ Step 4: Train the vectors
+
+ Expects a directory of preprocessed .s2v input files, will concatenate them
+ (using a temporary file on disk) and will use fastText to train a word2vec
+ model. See here for installation instructions:
+ https://github.com/facebookresearch/fastText
+
+ Note that this script will call into fastText and expects you to pass in the
+ built fasttext binary. The command will also be printed if you want to run
+ it separately.
+ """
+ output_path = Path(out_dir)
+ if not output_path.exists():
+ output_path.mkdir(parents=True)
+ msg.good(f"Created output directory {out_dir}")
+
+ if fasttext_filepath:
+ msg.info("Loading fastText model vectors from .bin file")
+ if in_dir:
+ msg.warn(
+ f"Warning: Providing a fastText filepath overrides fastText vector training"
+ )
+ fasttext_filepath = Path(fasttext_filepath)
+ if (
+ not fasttext_filepath.exists()
+ or not fasttext_filepath.is_file()
+ or not (fasttext_filepath.suffix == ".bin")
+ ):
+ msg.fail(
+ "Error: fasttext_filepath expects a fastText model .bin file", exits=1
+ )
+ fasttext_model = fasttext.load_model(str(fasttext_filepath))
+ msg.good("Successfully loaded fastText model")
+ elif in_dir:
+ msg.info("Training fastText model vectors")
+ input_path = Path(in_dir)
+ # Check to see if fasttext_filepath exists
+ if not input_path.exists() or not input_path.is_dir():
+ msg.fail("Not a valid input directory", in_dir, exits=1)
+ tmp_path = input_path / "s2v_input.tmp"
+ input_files = [p for p in input_path.iterdir() if p.suffix == ".s2v"]
+ if not input_files:
+ msg.fail("Input directory contains no .s2v files", in_dir, exits=1)
+ # fastText expects only one input file and only reads from disk and not
+ # stdin, so we need to create a temporary file that concatenates the inputs
+ with tmp_path.open("a", encoding="utf8") as tmp_file:
+ for input_file in input_files:
+ with input_file.open("r", encoding="utf8") as f:
+ tmp_file.write(f.read())
+ msg.info("Created temporary merged input file", tmp_path)
+ fasttext_model = fasttext.train_unsupervised(
+ str(tmp_path),
+ thread=n_threads,
+ epoch=epoch,
+ dim=vector_size,
+ minn=0,
+ maxn=0,
+ minCount=min_count,
+ verbose=verbose,
+ )
+ msg.good("Successfully trained fastText model vectors")
+
+ tmp_path.unlink()
+ msg.good("Deleted temporary input file", tmp_path)
+ output_file = output_path / f"vectors_w2v_{vector_size}dim.bin"
+ if save_fasttext_model:
+ fasttext_model.save_model(str(output_file))
+ if not output_file.exists() or not output_file.is_file():
+ msg.fail("Failed to save fastText model to disk", output_file, exits=1)
+ msg.good("Successfully saved fastText model to disk", output_file)
+ else:
+ fasttext_model = None
+ msg.fail("Must provide an input directory or fastText binary filepath", exits=1)
+
+ msg.info("Creating vocabulary file")
+ vocab_file = output_path / "vocab.txt"
+ words, freqs = fasttext_model.get_words(include_freq=True)
+ with vocab_file.open("w", encoding="utf8") as f:
+ for i in range(len(words)):
+ f.write(words[i] + " " + str(freqs[i]) + " word\n")
+ if not vocab_file.exists() or not vocab_file.is_file():
+ msg.fail("Failed to create vocabulary", vocab_file, exits=1)
+ msg.good("Successfully created vocabulary file", vocab_file)
+
+ msg.info("Creating vectors file")
+ vectors_file = output_path / "vectors.txt"
+ # Adapted from https://github.com/facebookresearch/fastText/blob/master/python/doc/examples/bin_to_vec.py#L31
+ with vectors_file.open("w", encoding="utf-8") as file_out:
+ # the first line must contain the number of total words and vector dimension
+ file_out.write(
+ str(len(words)) + " " + str(fasttext_model.get_dimension()) + "\n"
+ )
+ # line by line, append vector to vectors file
+ for w in words:
+ v = fasttext_model.get_word_vector(w)
+ vstr = ""
+ for vi in v:
+ vstr += " " + str(vi)
+ try:
+ file_out.write(w + vstr + "\n")
+ except IOError as e:
+ if e.errno == EPIPE:
+ pass
+ if not vectors_file.exists() or not vectors_file.is_file():
+ msg.fail("Failed to create vectors file", vectors_file, exits=1)
+ msg.good("Successfully created vectors file", vectors_file)
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/04_glove_train_vectors.py b/scripts/04_glove_train_vectors.py
new file mode 100644
index 0000000..7a659ed
--- /dev/null
+++ b/scripts/04_glove_train_vectors.py
@@ -0,0 +1,57 @@
+#!/usr/bin/env python
+import os
+from pathlib import Path
+from wasabi import msg
+import typer
+
+
+def main(
+ # fmt: off
+ glove_dir: str = typer.Argument(..., help="Directory containing the GloVe build"),
+ in_file: str = typer.Argument(..., help="Input file (shuffled cooccurrences)"),
+ vocab_file: str = typer.Argument(..., help="Vocabulary file"),
+ out_dir: str = typer.Argument(..., help="Path to output directory"),
+ n_threads: int = typer.Option(8, "--n-threads", "-t", help="Number of threads"),
+ n_iter: int = typer.Option(15, "--n-iter", "-n", help="Number of iterations"),
+ x_max: int = typer.Option(10, "--x-max", "-x", help="Parameter specifying cutoff in weighting function"),
+ vector_size: int = typer.Option(128, "--vector-size", "-s", help="Dimension of word vector representations"),
+ verbose: int = typer.Option(2, "--verbose", "-v", help="Set verbosity: 0, 1, or 2"),
+ # fmt: on
+):
+ """
+ Step 4: Train the vectors
+
+ Expects a file containing the shuffled cooccurrences and a vocab file and
+ will output a plain-text vectors file.
+
+ Note that this script will call into GloVe and expects you to pass in the
+ GloVe build directory (/build if you run the Makefile). The commands will
+ also be printed if you want to run them separately.
+ """
+ output_path = Path(out_dir)
+ if not Path(glove_dir).exists():
+ msg.fail("Can't find GloVe build directory", glove_dir, exits=1)
+ if not Path(in_file).exists():
+ msg.fail("Can't find input file", in_file, exits=1)
+ if not Path(vocab_file).exists():
+ msg.fail("Can't find vocab file", vocab_file, exits=1)
+ if not output_path.exists():
+ output_path.mkdir(parents=True)
+ msg.good(f"Created output directory {out_dir}")
+ output_file = output_path / f"vectors_glove_{vector_size}dim"
+ msg.info("Training vectors")
+ cmd = (
+ f"{glove_dir}/glove -save-file {output_file} -threads {n_threads} "
+ f"-input-file {in_file} -x-max {x_max} -iter {n_iter} "
+ f"-vector-size {vector_size} -binary 0 -vocab-file {vocab_file} "
+ f"-verbose {verbose}"
+ )
+ print(cmd)
+ train_cmd = os.system(cmd)
+ if train_cmd != 0:
+ msg.fail("Failed training vectors", exits=1)
+ msg.good("Successfully trained vectors")
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/05_export.py b/scripts/05_export.py
new file mode 100644
index 0000000..450a283
--- /dev/null
+++ b/scripts/05_export.py
@@ -0,0 +1,149 @@
+#!/usr/bin/env python
+from collections import OrderedDict, defaultdict
+from sense2vec import Sense2Vec
+from sense2vec.util import split_key, cosine_similarity
+from pathlib import Path
+from wasabi import msg
+import numpy
+import typer
+
+
+def main(
+ # fmt: off
+ in_file: str = typer.Argument(..., help="Vectors file (text-based)"),
+ vocab_file: str = typer.Argument(..., help="Vocabulary file"),
+ out_dir: str = typer.Argument(..., help="Path to output directory"),
+ min_freq_ratio: float = typer.Option(0.0, "--min-freq-ratio", "-r", help="Frequency ratio threshold for discarding minority senses or casings"),
+ min_distance: float = typer.Option(0.0, "--min-distance", "-s", help="Similarity threshold for discarding redundant keys"),
+ # fmt: on
+):
+ """
+ Step 5: Export a sense2vec component
+
+ Expects a vectors.txt and a vocab file trained with GloVe and exports
+ a component that can be loaded with Sense2vec.from_disk.
+ """
+ input_path = Path(in_file)
+ vocab_path = Path(vocab_file)
+ output_path = Path(out_dir)
+ if not input_path.exists():
+ msg.fail("Can't find input file", in_file, exits=1)
+ if input_path.suffix == ".bin":
+ msg.fail("Need text-based vectors file, not binary", in_file, exits=1)
+ if not vocab_path.exists():
+ msg.fail("Can't find vocab file", vocab_file, exits=1)
+ if not output_path.exists():
+ output_path.mkdir(parents=True)
+ msg.good(f"Created output directory {out_dir}")
+ with input_path.open("r", encoding="utf8") as f:
+ (n_vectors, vector_size), f = _get_shape(f)
+ vectors_data = f.readlines()
+ with vocab_path.open("r", encoding="utf8") as f:
+ vocab = read_vocab(f)
+ vectors = {}
+ all_senses = set()
+ for item in vectors_data:
+ item = item.rstrip().rsplit(" ", vector_size)
+ key = item[0]
+ try:
+ _, sense = split_key(key)
+ except ValueError:
+ continue
+ vec = item[1:]
+ if len(vec) != vector_size:
+ msg.fail(f"Wrong vector size: {len(vec)} (expected {vector_size})", exits=1)
+ all_senses.add(sense)
+ vectors[key] = numpy.asarray(vec, dtype=numpy.float32)
+ discarded = set()
+ discarded.update(get_minority_keys(vocab, min_freq_ratio))
+ discarded.update(get_redundant_keys(vocab, vectors, min_distance))
+ n_vectors = len(vectors) - len(discarded)
+ s2v = Sense2Vec(shape=(n_vectors, vector_size), senses=list(all_senses))
+ for key, vector in vectors.items():
+ if key not in discarded:
+ s2v.add(key, vector)
+ s2v.set_freq(key, vocab[key])
+ msg.good("Created the sense2vec model")
+ msg.info(f"{n_vectors} vectors, {len(all_senses)} total senses")
+ s2v.to_disk(output_path)
+ msg.good("Saved model to directory", out_dir)
+
+
+def _get_shape(file_):
+ """Return a tuple with (number of entries, vector dimensions). Handle
+ both word2vec/FastText format, which has a header with this, or GloVe's
+ format, which doesn't."""
+ first_line = next(file_).replace("\ufeff", "").split()
+ if len(first_line) == 2:
+ return tuple(int(size) for size in first_line), file_
+ count = 1
+ for line in file_:
+ count += 1
+ file_.seek(0)
+ shape = (count, len(first_line) - 1)
+ return shape, file_
+
+
+def read_vocab(vocab_file):
+ freqs = OrderedDict()
+ for line in vocab_file:
+ item = line.rstrip()
+ if item.endswith(" word"): # for fastText vocabs
+ item = item[:-5]
+ try:
+ key, freq = item.rsplit(" ", 1)
+ except ValueError:
+ continue
+ freqs[key] = int(freq)
+ return freqs
+
+
+def get_minority_keys(freqs, min_ratio):
+ """Remove keys that are too infrequent relative to a main sense."""
+ by_word = defaultdict(list)
+ for key, freq in freqs.items():
+ try:
+ term, sense = split_key(key)
+ except ValueError:
+ continue
+ if freq:
+ by_word[term.lower()].append((freq, key))
+ discarded = []
+ for values in by_word.values():
+ if len(values) >= 2:
+ values.sort(reverse=True)
+ freq1, key1 = values[0]
+ for freq2, key2 in values[1:]:
+ ratio = freq2 / freq1
+ if ratio < min_ratio:
+ discarded.append(key2)
+ return discarded
+
+
+def get_redundant_keys(vocab, vectors, min_distance):
+ if min_distance <= 0.0:
+ return []
+ by_word = defaultdict(list)
+ for key, freq in vocab.items():
+ try:
+ term, sense = split_key(key)
+ except ValueError:
+ continue
+ term = term.split("_")[-1]
+ by_word[term.lower()].append((freq, key))
+ too_similar = []
+ for values in by_word.values():
+ if len(values) >= 2:
+ values.sort(reverse=True)
+ freq1, key1 = values[0]
+ vector1 = vectors[key1]
+ for freq2, key2 in values[1:]:
+ vector2 = vectors[key2]
+ sim = cosine_similarity(vector1, vector2)
+ if sim >= (1 - min_distance):
+ too_similar.append(key2)
+ return too_similar
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/06_precompute_cache.py b/scripts/06_precompute_cache.py
new file mode 100644
index 0000000..2272cf1
--- /dev/null
+++ b/scripts/06_precompute_cache.py
@@ -0,0 +1,146 @@
+#!/usr/bin/env python
+from typing import Optional
+import tqdm
+import numpy
+import srsly
+from wasabi import msg
+from pathlib import Path
+import typer
+
+
+def main(
+ # fmt: off
+ vectors: str = typer.Argument(..., help="Path to sense2vec component directory"),
+ gpu_id: int = typer.Option(-1, "--gpu-id", "-g", help="GPU device (-1 for CPU)"),
+ n_neighbors: int = typer.Option(100, "--n-neighbors", "-n", help="Number of neighbors to cache"),
+ batch_size: int = typer.Option(1024, "--batch-size", "-b", help="Batch size for to reduce memory usage"),
+ cutoff: int = typer.Option(0, "--cutoff", "-c", help="Limit neighbors to this many earliest rows"),
+ start: int = typer.Option(0, "--start", "-s", help="Index of vectors to start at"),
+ end: Optional[int] = typer.Option(None, "--end", "-e", help="Index of vectors to stop at"),
+ # fmt: on
+):
+ """
+ Step 6: Precompute nearest-neighbor queries (optional)
+
+ Precompute nearest-neighbor queries for every entry in the vocab to make
+ Sense2Vec.most_similar faster. The --cutoff option lets you define the
+ number of earliest rows to limit the neighbors to. For instance, if cutoff
+ is 100000, no word will have a nearest neighbor outside of the top 100k
+ vectors.
+ """
+ if gpu_id == -1:
+ xp = numpy
+ else:
+ import cupy as xp
+ import cupy.cuda.device
+
+ xp.take_along_axis = take_along_axis
+ device = cupy.cuda.device.Device(gpu_id)
+ cupy.cuda.get_cublas_handle()
+ device.use()
+ vectors_dir = Path(vectors)
+ vectors_file = vectors_dir / "vectors"
+ if not vectors_dir.is_dir() or not vectors_file.exists():
+ err = "Are you passing in the exported sense2vec directory containing a vectors file?"
+ msg.fail(f"Can't load vectors from {vectors}", err, exits=1)
+ with msg.loading(f"Loading vectors from {vectors}"):
+ vectors = xp.load(str(vectors_file))
+ msg.good(f"Loaded {vectors.shape[0]:,} vectors with dimension {vectors.shape[1]}")
+ norms = xp.linalg.norm(vectors, axis=1, keepdims=True)
+ norms[norms == 0] = 1
+ # Normalize to unit norm
+ vectors /= norms
+ if cutoff < 1:
+ cutoff = vectors.shape[0]
+ if end is None:
+ end = vectors.shape[0]
+ mean = float(norms.mean())
+ var = float(norms.var())
+ msg.good(f"Normalized (mean {mean:,.2f}, variance {var:,.2f})")
+ msg.info(f"Finding {n_neighbors:,} neighbors among {cutoff:,} most frequent")
+ n = min(n_neighbors, vectors.shape[0])
+ subset = vectors[:cutoff]
+ best_rows = xp.zeros((end - start, n), dtype="i")
+ scores = xp.zeros((end - start, n), dtype="f")
+ for i in tqdm.tqdm(list(range(start, end, batch_size))):
+ size = min(batch_size, end - i)
+ batch = vectors[i : i + size]
+ sims = xp.dot(batch, subset.T)
+ # Set self-similarities to -inf, so that we don't return them.
+ for j in range(size):
+ if i + j < sims.shape[1]:
+ sims[j, i + j] = -xp.inf
+ # This used to use argpartition, to do a partial sort...But this ended
+ # up being a ratsnest of terrible numpy crap. Just sorting the whole
+ # list isn't really slower, and it's much simpler to read.
+ ranks = xp.argsort(sims, axis=1)
+ batch_rows = ranks[:, -n:]
+ # Reverse
+ batch_rows = batch_rows[:, ::-1]
+ batch_scores = xp.take_along_axis(sims, batch_rows, axis=1)
+ best_rows[i : i + size] = batch_rows
+ scores[i : i + size] = batch_scores
+ msg.info("Saving output")
+ if not isinstance(best_rows, numpy.ndarray):
+ best_rows = best_rows.get()
+ if not isinstance(scores, numpy.ndarray):
+ scores = scores.get()
+ output = {
+ "indices": best_rows,
+ "scores": scores.astype("float16"),
+ "start": start,
+ "end": end,
+ "cutoff": cutoff,
+ }
+ output_file = vectors_dir / "cache"
+ with msg.loading("Saving output..."):
+ srsly.write_msgpack(output_file, output)
+ msg.good(f"Saved cache to {output_file}")
+
+
+# These functions are missing from cupy, but will be supported in cupy 7.
+def take_along_axis(a, indices, axis):
+ """Take values from the input array by matching 1d index and data slices.
+
+ Args:
+ a (cupy.ndarray): Array to extract elements.
+ indices (cupy.ndarray): Indices to take along each 1d slice of ``a``.
+ axis (int): The axis to take 1d slices along.
+
+ Returns:
+ cupy.ndarray: The indexed result.
+
+ .. seealso:: :func:`numpy.take_along_axis`
+ """
+ import cupy
+
+ if indices.dtype.kind not in ("i", "u"):
+ raise IndexError("`indices` must be an integer array")
+
+ if axis is None:
+ a = a.ravel()
+ axis = 0
+
+ ndim = a.ndim
+
+ if not (-ndim <= axis < ndim):
+ raise IndexError("Axis overrun")
+
+ axis %= a.ndim
+
+ if ndim != indices.ndim:
+ raise ValueError("`indices` and `a` must have the same number of dimensions")
+
+ fancy_index = []
+ for i, n in enumerate(a.shape):
+ if i == axis:
+ fancy_index.append(indices)
+ else:
+ ind_shape = (1,) * i + (-1,) + (1,) * (ndim - i - 1)
+ fancy_index.append(cupy.arange(n).reshape(ind_shape))
+
+ return a[fancy_index]
+
+
+if __name__ == "__main__":
+ typer.run(main)
diff --git a/scripts/requirements.txt b/scripts/requirements.txt
new file mode 100644
index 0000000..4f348f6
--- /dev/null
+++ b/scripts/requirements.txt
@@ -0,0 +1,3 @@
+typer>=0.3.0
+tqdm>=4.36.1,<5.0.0
+fasttext>=0.9.1
diff --git a/scripts/streamlit_sense2vec.py b/scripts/streamlit_sense2vec.py
new file mode 100644
index 0000000..da58e1a
--- /dev/null
+++ b/scripts/streamlit_sense2vec.py
@@ -0,0 +1,75 @@
+"""
+Streamlit script for visualizing most similar sense2vec entries
+
+Lets you look up words and an optional sense (sense with the highest frequency
+is used if "auto" is selected) and shows the N most similar phrases, their
+scores and their frequencies.
+
+To add vector models, you can pass one or more directory paths (containing the
+serialized sense2vec components) when you run it with "streamlit run":
+streamlit run streamlit_sense2vec.py /path/to/sense2vec /path/to/other_sense2vec
+"""
+import streamlit as st
+from sense2vec import Sense2Vec
+import sys
+
+SENSE2VEC_PATHS = list(sys.argv[1:])
+DEFAULT_WORD = "natural language processing"
+
+
+@st.cache(allow_output_mutation=True)
+def load_vectors(path):
+ return Sense2Vec().from_disk(path)
+
+
+st.sidebar.title("sense2vec")
+st.sidebar.markdown(
+ "Explore semantic similarities of multi-word phrases using "
+ "[`sense2vec`](https://github.com/explosion/sense2vec/)."
+)
+
+word = st.sidebar.text_input("Word", DEFAULT_WORD)
+sense_dropdown = st.sidebar.empty()
+n_similar = st.sidebar.slider("Max number of similar entries", 1, 100, value=20, step=1)
+show_senses = st.sidebar.checkbox("Distinguish results by sense")
+vectors_path = st.sidebar.selectbox("Vectors", SENSE2VEC_PATHS)
+
+if not vectors_path:
+ st.error(
+ f"""
+#### No vectors available
+You can pass one or more paths to this
+script on the command line. For example:
+```bash
+streamlit run {sys.argv[0]} /path/to/sense2vec /path/to/other_sense2vec
+```
+"""
+ )
+else:
+ s2v = load_vectors(vectors_path)
+ sense = sense_dropdown.selectbox("Sense", ["auto"] + s2v.senses)
+ key = s2v.get_best_sense(word) if sense == "auto" else s2v.make_key(word, sense)
+ st.header(f"{word} ({sense})")
+ if key is None or key not in s2v:
+ st.error(f"**Not found:** No vector available for '{word}' ({sense}).")
+ else:
+ most_similar = s2v.most_similar(key, n=n_similar)
+ rows = []
+ seen = set()
+ for sim_key, sim_score in most_similar:
+ sim_word, sim_sense = s2v.split_key(sim_key)
+ if not show_senses and sim_word in seen:
+ continue
+ seen.add(sim_word)
+ sim_freq = s2v.get_freq(sim_key)
+ if show_senses:
+ sim_word = f"{sim_word} `{sim_sense}`"
+ row = f"| {sim_word} | `{sim_score:.3f}` | {sim_freq:,} |"
+ rows.append(row)
+ table_rows = "\n".join(rows)
+ table = f"""
+ | Word | Similarity | Frequency |
+ | --- | ---: | ---: |
+ {table_rows}
+ """
+ st.markdown(table)
diff --git a/sense2vec/__init__.pxd b/sense2vec/__init__.pxd
deleted file mode 100644
index e69de29..0000000
diff --git a/sense2vec/__init__.py b/sense2vec/__init__.py
index d1b747d..e332fe4 100644
--- a/sense2vec/__init__.py
+++ b/sense2vec/__init__.py
@@ -1,9 +1,11 @@
-from . import util
-from .vectors import VectorMap
+from .sense2vec import Sense2Vec # noqa: F401
+from .component import Sense2VecComponent # noqa: F401
+from .util import importlib_metadata, registry # noqa: F401
+try:
+ # This needs to be imported in order for the entry points to be loaded
+ from . import prodigy_recipes # noqa: F401
+except ImportError:
+ pass
-def load(name=None, via=None):
- package = util.get_package_by_name(name, via=via)
- vector_map = VectorMap(128)
- vector_map.load(package.path)
- return vector_map
+__version__ = importlib_metadata.version(__name__)
diff --git a/sense2vec/about.py b/sense2vec/about.py
deleted file mode 100644
index f214aec..0000000
--- a/sense2vec/about.py
+++ /dev/null
@@ -1,14 +0,0 @@
-# inspired from:
-
-# https://python-packaging-user-guide.readthedocs.org/en/latest/single_source_version/
-# https://github.com/pypa/warehouse/blob/master/warehouse/__about__.py
-
-title = 'sense2vec'
-version = '0.6.0'
-summary = 'word2vec with NLP-specific tokens'
-uri = 'https://github.com/explosion/sense2vec'
-author = 'Matthew Honnibal'
-email = 'matt@explosion.ai'
-license = 'MIT'
-release = True
-default_model = 'reddit_vectors>=1.1.0,<1.2.0'
diff --git a/sense2vec/component.py b/sense2vec/component.py
new file mode 100644
index 0000000..6f74cdd
--- /dev/null
+++ b/sense2vec/component.py
@@ -0,0 +1,267 @@
+from typing import Tuple, Union, List, Dict, Callable, Iterable, Optional
+from spacy.language import Language
+from spacy.tokens import Doc, Token, Span
+from spacy.training import Example
+from spacy.vocab import Vocab
+from spacy.util import SimpleFrozenDict
+from pathlib import Path
+import numpy
+
+from .sense2vec import Sense2Vec
+from .util import registry
+
+
+@Language.factory(
+ "sense2vec",
+ requires=["token.pos", "token.dep", "token.ent_type", "token.ent_iob", "doc.ents"],
+ assigns=[
+ "doc._._s2v",
+ "doc._.s2v_phrases",
+ "token._.in_s2v",
+ "token._.s2v_key",
+ "token._.s2v_vec",
+ "token._.s2v_freq",
+ "token._.s2v_other_senses",
+ "token._.s2v_most_similar",
+ "token._.s2v_similarity",
+ "span._.in_s2v",
+ "span._.s2v_key",
+ "span._.s2v_vec",
+ "span._.s2v_freq",
+ "span._.s2v_other_senses",
+ "span._.s2v_most_similar",
+ "span._.s2v_similarity",
+ ],
+)
+def make_sense2vec(
+ nlp: Language,
+ name: str,
+ shape: Tuple[int, int] = (100, 128),
+ merge_phrases: bool = False,
+ lemmatize: bool = False,
+ overrides: Dict[str, str] = SimpleFrozenDict(),
+):
+ return Sense2VecComponent(
+ nlp.vocab,
+ shape=shape,
+ merge_phrases=merge_phrases,
+ lemmatize=lemmatize,
+ overrides=overrides,
+ )
+
+
+class Sense2VecComponent(object):
+ def __init__(
+ self,
+ vocab: Vocab = None,
+ shape: Tuple[int, int] = (1000, 128),
+ merge_phrases: bool = False,
+ lemmatize: bool = False,
+ overrides: Dict[str, str] = SimpleFrozenDict(),
+ **kwargs,
+ ):
+ """Initialize the pipeline component.
+
+ vocab (Vocab): The shared vocab. Mostly used for the shared StringStore.
+ shape (tuple): The vector shape.
+ merge_phrases (bool): Merge sense2vec phrases into one token.
+ lemmatize (bool): Always look up lemmas if available in the vectors,
+ otherwise default to original word.
+ overrides (dict): Optional custom functions to use, mapped to names
+ registered via the registry, e.g. {"make_key": "custom_make_key"}.
+ RETURNS (Sense2VecComponent): The newly constructed object.
+ """
+ self.first_run = True
+ self.merge_phrases = merge_phrases
+ self.s2v = Sense2Vec(shape=shape)
+ cfg = {
+ "make_spacy_key": "default",
+ "get_phrases": "default",
+ "merge_phrases": "default",
+ "lemmatize": lemmatize,
+ }
+ self.s2v.cfg.update(cfg)
+ self.s2v.cfg.update(overrides)
+
+ @classmethod
+ def from_nlp(cls, nlp: Language, **cfg):
+ """Initialize the component from an nlp object. Mostly used as the
+ component factory for the entry point (see setup.cfg).
+
+ nlp (Language): The nlp object.
+ **cfg: Optional config parameters.
+ RETURNS (Sense2VecComponent): The newly constructed object.
+ """
+ return cls(vocab=nlp.vocab, **cfg)
+
+ def __call__(self, doc: Doc) -> Doc:
+ """Process a Doc object with the component.
+
+ doc (Doc): The document to process.
+ RETURNS (Doc): The processed document.
+ """
+ if self.first_run:
+ self.init_component()
+ self.first_run = False
+ # Store reference to s2v object on Doc to make sure it's right
+ doc._._s2v = self.s2v
+ if self.merge_phrases:
+ merge_phrases_id = doc._._s2v.cfg.get("merge_phrases", "default")
+ merge_phrases = registry.merge_phrases.get(merge_phrases_id)
+ doc = merge_phrases(doc)
+ return doc
+
+ def init_component(self):
+ """Register the component-specific extension attributes here and only
+ if the component is added to the pipeline and used – otherwise, tokens
+ will still get the attributes even if the component is only created and
+ not added.
+ """
+ Doc.set_extension("_s2v", default=None)
+ Doc.set_extension("s2v_phrases", getter=self.get_phrases)
+ for obj in [Token, Span]:
+ obj.set_extension("s2v_key", getter=self.s2v_key)
+ obj.set_extension("in_s2v", getter=self.in_s2v)
+ obj.set_extension("s2v_vec", getter=self.s2v_vec)
+ obj.set_extension("s2v_freq", getter=self.s2v_freq)
+ obj.set_extension("s2v_other_senses", getter=self.s2v_other_senses)
+ obj.set_extension("s2v_most_similar", method=self.s2v_most_similar)
+ obj.set_extension("s2v_similarity", method=self.s2v_similarity)
+
+ def get_phrases(self, doc: Doc) -> List[Span]:
+ """Extension attribute getter. Compile a list of sense2vec phrases based
+ on a processed Doc: named entities and noun chunks without determiners.
+
+ doc (Doc): The Doc to get phrases from.
+ RETURNS (list): The phrases as a list of Span objects.
+ """
+ func = registry.get_phrases.get(doc._._s2v.cfg.get("get_phrases", "default"))
+ return func(doc)
+
+ def in_s2v(self, obj: Union[Token, Span]) -> bool:
+ """Extension attribute getter. Check if a token or span has a vector.
+
+ obj (Token / Span): The object the attribute is called on.
+ RETURNS (bool): Whether the key of that object is in the table.
+ """
+ return self.s2v_key(obj) in obj.doc._._s2v
+
+ def s2v_vec(self, obj: Union[Token, Span]) -> numpy.ndarray:
+ """Extension attribute getter. Get the vector for a given object.
+
+ obj (Token / Span): The object the attribute is called on.
+ RETURNS (numpy.ndarray): The vector.
+ """
+ return obj.doc._._s2v[self.s2v_key(obj)]
+
+ def s2v_freq(self, obj: Union[Token, Span]) -> int:
+ """Extension attribute getter. Get the frequency for a given object.
+
+ obj (Token / Span): The object the attribute is called on.
+ RETURNS (int): The frequency.
+ """
+ return obj.doc._._s2v.get_freq(self.s2v_key(obj))
+
+ def s2v_key(self, obj: Union[Token, Span]) -> str:
+ """Extension attribute getter and helper method. Create a Sense2Vec key
+ like "duck|NOUN" from a spaCy object.
+
+ obj (Token / Span): The object to create the key for.
+ RETURNS (unicode): The key.
+ """
+ make_space_key_id = obj.doc._._s2v.cfg.get("make_spacy_key", "default")
+ make_spacy_key = registry.make_spacy_key.get(make_space_key_id)
+ if obj.doc._._s2v.cfg.get("lemmatize", False):
+ lemma = make_spacy_key(obj, prefer_ents=self.merge_phrases, lemmatize=True)
+ lemma_key = obj.doc._._s2v.make_key(*lemma)
+ if lemma_key in obj.doc._._s2v:
+ return lemma_key
+ word, sense = make_spacy_key(obj, prefer_ents=self.merge_phrases)
+ return obj.doc._._s2v.make_key(word, sense)
+
+ def s2v_similarity(
+ self, obj: Union[Token, Span], other: Union[Token, Span]
+ ) -> float:
+ """Extension attribute method. Estimate the similarity of two objects.
+
+ obj (Token / Span): The object the attribute is called on.
+ other (Token / Span): The object to compare it to.
+ RETURNS (float): The similarity score.
+ """
+ if not isinstance(other, (Token, Span)):
+ msg = f"Can only get similarity of Token or Span, not {type(other)}"
+ raise ValueError(msg)
+ return obj.doc._._s2v.similarity(self.s2v_key(obj), self.s2v_key(other))
+
+ def s2v_most_similar(
+ self, obj: Union[Token, Span], n: int = 10
+ ) -> List[Tuple[Tuple[str, str], float]]:
+ """Extension attribute method. Get the most similar entries.
+
+ obj (Token / Span): The object the attribute is called on.
+ n (int): The number of similar entries to return.
+ RETURNS (list): The most similar entries as a list of
+ ((word, sense), score) tuples.
+ """
+ key = self.s2v_key(obj)
+ results = obj.doc._._s2v.most_similar([key], n=n)
+ return [(self.s2v.split_key(result), score) for result, score in results]
+
+ def s2v_other_senses(self, obj: Union[Token, Span]) -> List[str]:
+ """Extension attribute getter. Get other senses for an object.
+
+ obj (Token / Span): The object the attribute is called on.
+ RETURNS (list): A list of other senses.
+ """
+ key = self.s2v_key(obj)
+ return obj.doc._._s2v.get_other_senses(key)
+
+ def initialize(
+ self,
+ get_examples: Callable[[], Iterable[Example]],
+ *,
+ nlp: Optional[Language] = None,
+ data_path: Optional[str] = None
+ ):
+ """Initialize the component and load in data. Can be used to add the
+ component with vectors to a pipeline before training.
+
+ get_examples (Callable[[], Iterable[Example]]): Function that
+ returns a representative sample of gold-standard Example objects.
+ nlp (Language): The current nlp object the component is part of.
+ data_path (Optional[str]): Optional path to sense2vec model.
+ """
+ if data_path is not None:
+ self.from_disk(data_path)
+
+ def to_bytes(self) -> bytes:
+ """Serialize the component to a bytestring.
+
+ RETURNS (bytes): The serialized component.
+ """
+ return self.s2v.to_bytes(exclude=["strings"])
+
+ def from_bytes(self, bytes_data: bytes):
+ """Load the component from a bytestring.
+
+ bytes_data (bytes): The data to load.
+ RETURNS (Sense2VecComponent): The loaded object.
+ """
+ self.s2v = Sense2Vec().from_bytes(bytes_data)
+ return self
+
+ def to_disk(self, path: Union[str, Path]):
+ """Serialize the component to a directory.
+
+ path (unicode / Path): The path to save to.
+ """
+ self.s2v.to_disk(path, exclude=["strings"])
+
+ def from_disk(self, path: Union[str, Path]):
+ """Load the component from a directory.
+
+ path (unicode / Path): The path to load from.
+ RETURNS (Sense2VecComponent): The loaded object.
+ """
+ self.s2v = Sense2Vec().from_disk(path)
+ return self
diff --git a/sense2vec/download.py b/sense2vec/download.py
deleted file mode 100644
index 11e990b..0000000
--- a/sense2vec/download.py
+++ /dev/null
@@ -1,38 +0,0 @@
-from __future__ import print_function
-import sys
-
-import plac
-import sputnik
-from sputnik.package_list import (PackageNotFoundException,
- CompatiblePackageNotFoundException)
-
-from sense2vec import about
-
-
-@plac.annotations(
- force=("Force overwrite", "flag", "f", bool),
-)
-def main(force=False):
- if force:
- sputnik.purge(about.__title__, about.__version__)
-
- try:
- sputnik.package(about.__title__, about.__version__, about.__default_model__)
- print("Model already installed. Please run '%s --force to reinstall." % sys.argv[0], file=sys.stderr)
- sys.exit(1)
- except (PackageNotFoundException, CompatiblePackageNotFoundException):
- pass
-
- package = sputnik.install(about.__title__, about.__version__, about.__default_model__)
-
- try:
- sputnik.package(about.__title__, about.__version__, about.__default_model__)
- except (PackageNotFoundException, CompatiblePackageNotFoundException):
- print("Model failed to install. Please run '%s --force." % sys.argv[0], file=sys.stderr)
- sys.exit(1)
-
- print("Model successfully installed.", file=sys.stderr)
-
-
-if __name__ == '__main__':
- plac.call(main)
diff --git a/sense2vec/prodigy_recipes.py b/sense2vec/prodigy_recipes.py
new file mode 100644
index 0000000..64bee9d
--- /dev/null
+++ b/sense2vec/prodigy_recipes.py
@@ -0,0 +1,671 @@
+import prodigy
+from prodigy.components.db import connect
+from prodigy.util import log, split_string, set_hashes, TASK_HASH_ATTR, INPUT_HASH_ATTR
+import murmurhash
+from sense2vec import Sense2Vec
+import srsly
+import spacy
+import random
+from wasabi import msg
+from collections import defaultdict, Counter
+import copy
+import catalogue
+
+
+# fmt: off
+eval_strategies = catalogue.create("prodigy", "sense2vec.eval")
+EVAL_EXCLUDE_SENSES = ("SYM", "MONEY", "ORDINAL", "CARDINAL", "DATE", "TIME",
+ "PERCENT", "QUANTITY", "NUM", "X", "PUNCT")
+# fmt: on
+
+
+@prodigy.recipe(
+ "sense2vec.teach",
+ dataset=("Dataset to save annotations to", "positional", None, str),
+ vectors_path=("Path to pretrained sense2vec vectors", "positional", None, str),
+ seeds=("One or more comma-separated seed phrases", "option", "se", split_string),
+ threshold=("Similarity threshold for sense2vec", "option", "t", float),
+ n_similar=("Number of similar items to get at once", "option", "n", int),
+ batch_size=("Batch size for submitting annotations", "option", "bs", int),
+ case_sensitive=("Show the same terms with different casing", "flag", "CS", bool),
+ resume=("Resume from existing phrases dataset", "flag", "R", bool),
+)
+def teach(
+ dataset,
+ vectors_path,
+ seeds,
+ threshold=0.85,
+ n_similar=100,
+ batch_size=5,
+ case_sensitive=False,
+ resume=False,
+):
+ """
+ Bootstrap a terminology list using sense2vec. Prodigy will suggest similar
+ terms based on the the most similar phrases from sense2vec, and the
+ suggestions will be adjusted as you annotate and accept similar phrases. For
+ each seed term, the best matching sense according to the sense2vec vectors
+ will be used.
+
+ If no similar terms are found above the given threshold, the threshold is
+ lowered by 0.1 and similar terms are requested again.
+ """
+ log("RECIPE: Starting recipe sense2vec.teach", locals())
+ s2v = Sense2Vec().from_disk(vectors_path)
+ log("RECIPE: Loaded sense2vec vectors", vectors_path)
+ html_template = "{{word}}"
+ accept_keys = []
+ seen = set()
+ seed_tasks = []
+ for seed in seeds:
+ key = s2v.get_best_sense(seed)
+ if key is None:
+ msg.warn(f"Can't find seed term '{seed}' in vectors")
+ continue
+ accept_keys.append(key)
+ best_word, best_sense = s2v.split_key(key)
+ seen.add(best_word if case_sensitive else best_word.lower())
+ task = {
+ "text": key,
+ "word": best_word,
+ "sense": best_sense,
+ "meta": {"score": 1.0, "sense": best_sense},
+ "answer": "accept",
+ }
+ seed_tasks.append(set_hashes(task))
+ if len(accept_keys) == 0:
+ msg.fail(
+ "No seeds available. This typically happens if none of your seed "
+ "terms are found in the vectors. Try using more generic terms or "
+ "different vectors that cover the expressions you're looking for.",
+ exits=1,
+ )
+ print(f"Starting with seed keys: {accept_keys}")
+ DB = connect()
+ if dataset not in DB:
+ DB.add_dataset(dataset)
+ dataset_hashes = DB.get_task_hashes(dataset)
+ DB.add_examples(
+ [st for st in seed_tasks if st[TASK_HASH_ATTR] not in dataset_hashes],
+ datasets=[dataset],
+ )
+
+ if resume:
+ prev = DB.get_dataset(dataset)
+ prev_accept_keys = [eg["text"] for eg in prev if eg["answer"] == "accept"]
+ prev_words = [
+ eg["word"] if case_sensitive else eg["word"].lower() for eg in prev
+ ]
+ accept_keys += prev_accept_keys
+ seen.update(set(prev_words))
+ log(f"RECIPE: Resuming from {len(prev)} previous examples in dataset {dataset}")
+
+ def update(answers):
+ """Updates accept_keys so that the stream can find new phrases."""
+ log(f"RECIPE: Updating with {len(answers)} answers")
+ for answer in answers:
+ phrase = answer["text"]
+ if answer["answer"] == "accept":
+ accept_keys.append(phrase)
+
+ def get_stream():
+ """Continue querying sense2vec whenever we get a new phrase and
+ presenting examples to the user with a similarity above the threshold
+ parameter."""
+ nonlocal threshold
+ while True:
+ log(
+ f"RECIPE: Looking for {n_similar} phrases most similar to "
+ f"{len(accept_keys)} accepted keys"
+ )
+ most_similar = s2v.most_similar(accept_keys, n=n_similar)
+ log(f"RECIPE: Found {len(most_similar)} most similar phrases")
+ n_skipped = 0
+ n_duplicate = 0
+ for key, score in most_similar:
+ if score > threshold:
+ word, sense = s2v.split_key(key)
+ if (case_sensitive and word in seen) or (
+ not case_sensitive and word.lower() in seen
+ ):
+ n_duplicate += 1
+ continue
+ seen.add(word if case_sensitive else word.lower())
+ # Make sure the score is a regular float, otherwise server
+ # may fail when trying to serialize it to/from JSON
+ meta = {"score": float(score), "sense": sense}
+ yield {"text": key, "word": word, "sense": sense, "meta": meta}
+ else:
+ n_skipped += 1
+ if n_skipped:
+ log(f"RECIPE: Skipped {n_skipped} phrases below threshold {threshold}")
+ if n_skipped == len(most_similar) - n_duplicate:
+ # No most similar phrases were found that are above the
+ # threshold, so lower the threshold if it's not already 0 or
+ # return empty list so Prodigy shows "no tasks available"
+ new_threshold = threshold - 0.1
+ if new_threshold <= 0.0:
+ log(f"RECIPE: No suggestions for threshold {threshold:.2}")
+ return []
+ log(
+ f"RECIPE: Lowering threshold from {threshold:.2} to {new_threshold:.2}"
+ )
+ threshold = new_threshold
+
+ stream = get_stream()
+
+ return {
+ "view_id": "html",
+ "dataset": dataset,
+ "stream": stream,
+ "update": update,
+ "config": {"batch_size": batch_size, "html_template": html_template},
+ }
+
+
+@prodigy.recipe(
+ "sense2vec.to-patterns",
+ dataset=("Phrase dataset to convert", "positional", None, str),
+ spacy_model=("spaCy model or blank:en (for tokenization)", "positional", None, str),
+ label=("Label to apply to all patterns", "positional", None, str),
+ output_file=("Optional output file. Defaults to stdout", "option", "o", str),
+ case_sensitive=("Make patterns case-sensitive", "flag", "CS", bool),
+ dry=("Perform a dry run and don't output anything", "flag", "D", bool),
+)
+def to_patterns(
+ dataset, spacy_model, label, output_file="-", case_sensitive=False, dry=False
+):
+ """
+ Convert a dataset of phrases collected with sense2vec.teach to token-based
+ match patterns that can be used with spaCy's EntityRuler or recipes like
+ ner.match. If no output file is specified, the patterns are written to
+ stdout. The examples are tokenized so that multi-token terms are represented
+ correctly, e.g.:
+ {"label": "SHOE_BRAND", "pattern": [{"LOWER": "new"}, {"LOWER": "balance"}]}
+
+ For tokenization, you can either pass in the name of a spaCy model (e.g. if
+ you're using a model with custom tokenization), or "blank:" plus the
+ language code you want to use, e.g. blank:en or blank:de. Make sure to use
+ the same language / tokenizer you're planning to use at runtime – otherwise
+ your patterns may not match.
+ """
+ log("RECIPE: Starting recipe sense2vec.to-patterns", locals())
+ if spacy_model.startswith("blank:"):
+ nlp = spacy.blank(spacy_model.replace("blank:", ""))
+ else:
+ nlp = spacy.load(spacy_model)
+ log(f"RECIPE: Loaded spaCy model '{spacy_model}'")
+ DB = connect()
+ if dataset not in DB:
+ msg.fail(f"Can't find dataset '{dataset}'", exits=1)
+ examples = DB.get_dataset(dataset)
+ terms = set([eg["word"] for eg in examples if eg["answer"] == "accept"])
+ if case_sensitive:
+ patterns = [[{"text": t.text} for t in nlp.make_doc(term)] for term in terms]
+ else:
+ terms = set([word.lower() for word in terms])
+ patterns = [[{"lower": t.lower_} for t in nlp.make_doc(term)] for term in terms]
+ patterns = [{"label": label, "pattern": pattern} for pattern in patterns]
+ log(f"RECIPE: Generated {len(patterns)} patterns")
+ if not dry:
+ srsly.write_jsonl(output_file, patterns)
+ return patterns
+
+
+@prodigy.recipe(
+ "sense2vec.eval",
+ dataset=("Dataset to save annotations to", "positional", None, str),
+ vectors_path=("Path to pretrained sense2vec vectors", "positional", None, str),
+ strategy=("Example selection strategy", "option", "st", str,),
+ senses=("The senses to use (all if not set)", "option", "s", split_string),
+ exclude_senses=("The senses to exclude", "option", "es", split_string),
+ n_freq=("Number of most frequent entries to limit to", "option", "f", int),
+ threshold=("Similarity threshold to consider examples", "option", "t", float),
+ batch_size=("The batch size to use", "option", "b", int),
+ eval_whole=("Evaluate whole dataset instead of session", "flag", "E", bool),
+ eval_only=("Don't annotate, only evaluate current set", "flag", "O", bool),
+ show_scores=("Show all scores for debugging", "flag", "S", bool),
+)
+def evaluate(
+ dataset,
+ vectors_path,
+ strategy="most_similar",
+ senses=None,
+ exclude_senses=EVAL_EXCLUDE_SENSES,
+ n_freq=100_000,
+ threshold=0.7,
+ batch_size=10,
+ eval_whole=False,
+ eval_only=False,
+ show_scores=False,
+):
+ """
+ Evaluate a sense2vec model by asking about phrase triples: is word A more
+ similar to word B, or to word C? If the human mostly agrees with the model,
+ the vectors model is good.
+ """
+ random.seed(0)
+ log("RECIPE: Starting recipe sense2vec.eval", locals())
+ strategies = eval_strategies.get_all()
+ if strategy not in strategies.keys():
+ err = f"Invalid strategy '{strategy}'. Expected: {list(strategies.keys())}"
+ msg.fail(err, exits=1)
+ s2v = Sense2Vec().from_disk(vectors_path)
+ log("RECIPE: Loaded sense2vec vectors", vectors_path)
+
+ def get_html(key, score=None, large=False):
+ word, sense = s2v.split_key(key)
+ html_word = f"{word}"
+ html_sense = f"{sense}"
+ html = f"{html_word} {html_sense}"
+ if show_scores and score is not None:
+ html += f" {score:.4}"
+ return html
+
+ def get_stream():
+ strategy_func = eval_strategies.get(strategy)
+ log(f"RECIPE: Using strategy {strategy}")
+ # Limit to most frequent entries
+ keys = [key for key, _ in s2v.frequencies[:n_freq]]
+ keys_by_sense = defaultdict(set)
+ for key in keys:
+ try:
+ sense = s2v.split_key(key)[1]
+ except ValueError:
+ continue
+ if (senses is None or sense in senses) and sense not in exclude_senses:
+ keys_by_sense[sense].add(key)
+ keys_by_sense = {s: keys for s, keys in keys_by_sense.items() if len(keys) >= 3}
+ all_senses = list(keys_by_sense.keys())
+ total_keys = sum(len(keys) for keys in keys_by_sense.values())
+ log(f"RECIPE: Using {total_keys} entries for {len(all_senses)} senses")
+ n_passes = 1
+ while True:
+ log(f"RECIPE: Iterating over the data ({n_passes})")
+ current_keys = copy.deepcopy(keys_by_sense)
+ while any(len(values) >= 3 for values in current_keys.values()):
+ sense = random.choice(all_senses)
+ all_keys = list(current_keys[sense])
+ key_a, key_b, key_c, sim_ab, sim_ac = strategy_func(s2v, all_keys)
+ if len(set([key_a.lower(), key_b.lower(), key_c.lower()])) != 3:
+ continue
+ if sim_ab < threshold or sim_ac < threshold:
+ continue
+ for key in (key_a, key_b, key_c):
+ current_keys[sense].remove(key)
+ confidence = 1.0 - (min(sim_ab, sim_ac) / max(sim_ab, sim_ac))
+ input_hash = murmurhash.hash(key_a)
+ task_hash = murmurhash.hash(" ".join([key_a] + sorted([key_b, key_c])))
+ task = {
+ "label": "Which one is more similar?",
+ "html": get_html(key_a, large=True),
+ "text": f"{key_a}: {key_b}, {key_c}",
+ "key": key_a,
+ "options": [
+ {
+ "id": key_b,
+ "html": get_html(key_b, sim_ab),
+ "score": sim_ab,
+ },
+ {
+ "id": key_c,
+ "html": get_html(key_c, sim_ac),
+ "score": sim_ac,
+ },
+ ],
+ "confidence": confidence,
+ TASK_HASH_ATTR: task_hash,
+ INPUT_HASH_ATTR: input_hash,
+ }
+ if show_scores:
+ task["meta"] = {
+ "confidence": f"{confidence:.4}",
+ "strategy": strategy,
+ }
+ yield task
+ n_passes += 1
+
+ def eval_dataset(set_id):
+ """Output summary about user agreement with the model."""
+ DB = connect()
+ data = DB.get_dataset(set_id)
+ accepted = [eg for eg in data if eg["answer"] == "accept" and eg.get("accept")]
+ rejected = [eg for eg in data if eg["answer"] == "reject"]
+ if not accepted and not rejected:
+ msg.warn("No annotations collected", exits=1)
+ high_conf = 0.8
+ agree_count = 0
+ disagree_high_conf = len([e for e in rejected if e["confidence"] > high_conf])
+ for eg in accepted:
+ choice = eg["accept"][0]
+ score_choice = [o["score"] for o in eg["options"] if o["id"] == choice][0]
+ score_other = [o["score"] for o in eg["options"] if o["id"] != choice][0]
+ if score_choice > score_other:
+ agree_count += 1
+ elif eg["confidence"] > high_conf:
+ disagree_high_conf += 1
+ pc = agree_count / (len(accepted) + len(rejected))
+ text = f"You agreed {agree_count} / {len(data)} times ({pc:.0%})"
+ msg.info(f"Evaluating data from '{set_id}'")
+ if pc > 0.5:
+ msg.good(text)
+ else:
+ msg.fail(text)
+ msg.text(f"You disagreed on {disagree_high_conf} high confidence scores")
+ msg.text(f"You rejected {len(rejected)} suggestions as not similar")
+
+ def on_exit(ctrl):
+ set_id = dataset if eval_whole else ctrl.session_id
+ eval_dataset(set_id)
+
+ if eval_only:
+ eval_dataset(dataset)
+ return None
+
+ return {
+ "view_id": "choice",
+ "dataset": dataset,
+ "stream": get_stream(),
+ "on_exit": on_exit,
+ "config": {
+ "batch_size": batch_size,
+ "choice_style": "single",
+ "choice_auto_accept": True,
+ },
+ }
+
+
+@eval_strategies.register("random")
+def eval_strategy_random(s2v, keys):
+ key_a, key_b, key_c = random.sample(keys, 3)
+ sim_ab = s2v.similarity(key_a, key_b)
+ sim_ac = s2v.similarity(key_a, key_c)
+ return key_a, key_b, key_c, sim_ab, sim_ac
+
+
+@eval_strategies.register("most_similar")
+def eval_strategy_most_similar(s2v, keys):
+ key_a = random.choice(keys)
+ most_similar = s2v.most_similar(key_a, n=min(2000, len(s2v)))
+ options = [(key, score) for key, score in most_similar if key in keys]
+ if len(options) < 2:
+ return eval_strategy_most_similar(s2v, keys)
+ key_b, sim_ab = options[len(options) // 2]
+ key_c, sim_ac = options[-1]
+ return key_a, key_b, key_c, sim_ab, sim_ac
+
+
+@eval_strategies.register("most_least_similar")
+def eval_strategy_most_least_similar(s2v, keys):
+ n_similar = 100
+ key_a = random.choice(keys)
+ most_similar_a = s2v.most_similar(key_a, n=n_similar)
+ options_a = [(key, score) for key, score in most_similar_a if key in keys]
+ if len(options_a) < 1:
+ return eval_strategy_most_least_similar(s2v, keys)
+ key_b, sim_ab = options_a[-1]
+ most_similar_b = s2v.most_similar(key_b, n=n_similar)
+ options_b = [(key, score) for key, score in most_similar_b if key in keys]
+ if len(options_b) < 1:
+ return eval_strategy_most_least_similar(s2v, keys)
+ key_c, sim_ac = options_b[-1]
+ return key_a, key_b, key_c, sim_ab, sim_ac
+
+
+@prodigy.recipe(
+ "sense2vec.eval-most-similar",
+ dataset=("Dataset to save annotations to", "positional", None, str),
+ vectors_path=("Path to pretrained sense2vec vectors", "positional", None, str),
+ senses=("The senses to use (all if not set)", "option", "s", split_string),
+ exclude_senses=("The senses to exclude", "option", "es", split_string),
+ n_freq=("Number of most frequent entries to limit to", "option", "f", int),
+ n_similar=("Number of similar items to check", "option", "n", int),
+ batch_size=("The batch size to use", "option", "b", int),
+ eval_whole=("Evaluate whole dataset instead of session", "flag", "E", bool),
+ eval_only=("Don't annotate, only evaluate current set", "flag", "O", bool),
+ show_scores=("Show all scores for debugging", "flag", "S", bool),
+)
+def eval_most_similar(
+ dataset,
+ vectors_path,
+ senses=None,
+ exclude_senses=EVAL_EXCLUDE_SENSES,
+ n_freq=100_000,
+ n_similar=10,
+ batch_size=5,
+ eval_whole=False,
+ eval_only=False,
+ show_scores=False,
+):
+ """
+ Evaluate a vectors model by looking at the most similar entries it returns
+ for a random phrase and unselecting the mistakes.
+ """
+ log("RECIPE: Starting recipe sense2vec.eval-most-similar", locals())
+ random.seed(0)
+ s2v = Sense2Vec().from_disk(vectors_path)
+ log("RECIPE: Loaded sense2vec vectors", vectors_path)
+ seen = set()
+ DB = connect()
+ if dataset in DB:
+ examples = DB.get_dataset(dataset)
+ seen.update([eg["text"] for eg in examples if eg["answer"] == "accept"])
+ log(f"RECIPE: Skipping {len(seen)} terms already in dataset")
+
+ def get_html(key, score=None, large=False):
+ word, sense = s2v.split_key(key)
+ html_word = f"{word}"
+ html_sense = f"{sense}"
+ html = f"{html_word} {html_sense}"
+ if show_scores and score is not None:
+ html += f" {score:.4}"
+ return html
+
+ def get_stream():
+ keys = [key for key, _ in s2v.frequencies[:n_freq] if key not in seen]
+ while len(keys):
+ key = random.choice(keys)
+ keys.remove(key)
+ word, sense = s2v.split_key(key)
+ if sense in exclude_senses or (senses is not None and sense not in senses):
+ continue
+ most_similar = s2v.most_similar(key, n=n_similar)
+ options = [{"id": k, "html": get_html(k, s)} for k, s in most_similar]
+ task_hash = murmurhash.hash(key)
+ task = {
+ "html": get_html(key, large=True),
+ "text": key,
+ "options": options,
+ "accept": [key for key, _ in most_similar], # pre-select all
+ TASK_HASH_ATTR: task_hash,
+ INPUT_HASH_ATTR: task_hash,
+ }
+ yield task
+
+ def eval_dataset(set_id):
+ DB = connect()
+ data = DB.get_dataset(set_id)
+ accepted = [eg for eg in data if eg["answer"] == "accept" and eg.get("accept")]
+ rejected = [eg for eg in data if eg["answer"] == "reject"]
+ ignored = [eg for eg in data if eg["answer"] == "ignore"]
+ if not accepted and not rejected:
+ msg.warn("No annotations collected", exits=1)
+ total_count = 0
+ agree_count = 0
+ for eg in accepted:
+ total_count += len(eg.get("options", []))
+ agree_count += len(eg.get("accept", []))
+ msg.info(f"Evaluating data from '{set_id}'")
+ msg.text(f"You rejected {len(rejected)} and ignored {len(ignored)} pair(s)")
+ pc = agree_count / total_count
+ text = f"You agreed {agree_count} / {total_count} times ({pc:.0%})"
+ if pc > 0.5:
+ msg.good(text)
+ else:
+ msg.fail(text)
+
+ def on_exit(ctrl):
+ set_id = dataset if eval_whole else ctrl.session_id
+ eval_dataset(set_id)
+
+ if eval_only:
+ eval_dataset(dataset)
+ return None
+
+ return {
+ "view_id": "choice",
+ "dataset": dataset,
+ "stream": get_stream(),
+ "on_exit": on_exit,
+ "config": {"choice_style": "multiple", "batch_size": batch_size},
+ }
+
+
+@prodigy.recipe(
+ "sense2vec.eval-ab",
+ dataset=("Dataset to save annotations to", "positional", None, str),
+ vectors_path_a=("Path to pretrained sense2vec vectors", "positional", None, str),
+ vectors_path_b=("Path to pretrained sense2vec vectors", "positional", None, str),
+ senses=("The senses to use (all if not set)", "option", "s", split_string),
+ exclude_senses=("The senses to exclude", "option", "es", split_string),
+ n_freq=("Number of most frequent entries to limit to", "option", "f", int),
+ batch_size=("The batch size to use", "option", "b", int),
+ eval_whole=("Evaluate whole dataset instead of session", "flag", "E", bool),
+ eval_only=("Don't annotate, only evaluate current set", "flag", "O", bool),
+ show_mapping=("Show A/B mapping for debugging", "flag", "S", bool),
+)
+def eval_ab(
+ dataset,
+ vectors_path_a,
+ vectors_path_b,
+ senses=None,
+ exclude_senses=EVAL_EXCLUDE_SENSES,
+ n_freq=100_000,
+ n_similar=10,
+ batch_size=5,
+ eval_whole=False,
+ eval_only=False,
+ show_mapping=False,
+):
+ """
+ Perform an A/B evaluation of two pretrained sense2vec vector models by
+ comparing the most similar entries they return for a random phrase. The
+ UI shows two randomized options with the most similar entries of each model
+ and highlights the phrases that differ. At the end of the annotation
+ session the overall stats and preferred model are shown.
+ """
+ log("RECIPE: Starting recipe sense2vec.eval-ab", locals())
+ random.seed(0)
+ s2v_a = Sense2Vec().from_disk(vectors_path_a)
+ s2v_b = Sense2Vec().from_disk(vectors_path_b)
+ mapping = {"A": vectors_path_a, "B": vectors_path_b}
+ log("RECIPE: Loaded sense2vec vectors", (vectors_path_a, vectors_path_b))
+ seen = set()
+ DB = connect()
+ if dataset in DB:
+ examples = DB.get_dataset(dataset)
+ seen.update([eg["text"] for eg in examples if eg["answer"] == "accept"])
+ log(f"RECIPE: Skipping {len(seen)} terms already in dataset")
+
+ def get_term_html(key):
+ word, sense = s2v_a.split_key(key)
+ return (
+ f"{word} "
+ f"{sense}"
+ )
+
+ def get_option_html(most_similar, overlap):
+ html = []
+ for key in most_similar:
+ font_weight = "normal" if key in overlap else "bold"
+ border_color = "#f6f6f6" if key in overlap else "#ccc"
+ word, sense = s2v_a.split_key(key)
+ html.append(
+ f"{word} {sense}"
+ )
+ html = " ".join(html) if html else "No results"
+ return (
+ f"{html}
"
+ )
+
+ def get_stream():
+ keys_a = [key for key, _ in s2v_a.frequencies[:n_freq] if key not in seen]
+ keys_b = [key for key, _ in s2v_b.frequencies[:n_freq] if key not in seen]
+ while len(keys_a):
+ key = random.choice(keys_a)
+ keys_a.remove(key)
+ word, sense = s2v_a.split_key(key)
+ if sense in exclude_senses or (senses is not None and sense not in senses):
+ continue
+ if key not in keys_b:
+ continue
+ similar_a = set([k for k, _ in s2v_a.most_similar(key, n=n_similar)])
+ similar_b = set([k for k, _ in s2v_b.most_similar(key, n=n_similar)])
+ overlap = similar_a.intersection(similar_b)
+ options = [
+ {"id": "A", "html": get_option_html(similar_a, overlap)},
+ {"id": "B", "html": get_option_html(similar_b, overlap)},
+ ]
+ random.shuffle(options)
+ task_hash = murmurhash.hash(key)
+ task = {
+ "html": get_term_html(key),
+ "text": key,
+ "options": options,
+ TASK_HASH_ATTR: task_hash,
+ INPUT_HASH_ATTR: task_hash,
+ }
+ if show_mapping:
+ opt_map = [f"{opt['id']} ({mapping[opt['id']]})" for opt in options]
+ task["meta"] = {i + 1: opt for i, opt in enumerate(opt_map)}
+ yield task
+
+ def eval_dataset(set_id):
+ DB = connect()
+ data = DB.get_dataset(set_id)
+ accepted = [eg for eg in data if eg["answer"] == "accept" and eg.get("accept")]
+ rejected = [eg for eg in data if eg["answer"] == "reject"]
+ ignored = [eg for eg in data if eg["answer"] == "ignore"]
+ if not accepted and not rejected:
+ msg.warn("No annotations collected", exits=1)
+ counts = Counter()
+ for eg in accepted:
+ for model_id in eg["accept"]:
+ counts[model_id] += 1
+ preference, _ = counts.most_common(1)[0]
+ ratio = f"{counts[preference]} / {sum(counts.values()) - counts[preference]}"
+ msg.info(f"Evaluating data from '{set_id}'")
+ msg.text(f"You rejected {len(rejected)} and ignored {len(ignored)} pair(s)")
+ if counts["A"] == counts["B"]:
+ msg.warn(f"No preference ({ratio})")
+ else:
+ pc = counts[preference] / sum(counts.values())
+ msg.good(f"You preferred vectors {preference} with {ratio} ({pc:.0%})")
+ msg.text(mapping[preference])
+
+ def on_exit(ctrl):
+ set_id = dataset if eval_whole else ctrl.session_id
+ eval_dataset(set_id)
+
+ if eval_only:
+ eval_dataset(dataset)
+ return None
+
+ return {
+ "view_id": "choice",
+ "dataset": dataset,
+ "stream": get_stream(),
+ "on_exit": on_exit,
+ "config": {
+ "batch_size": batch_size,
+ "choice_style": "single",
+ "choice_auto_accept": True,
+ },
+ }
diff --git a/sense2vec/sense2vec.py b/sense2vec/sense2vec.py
new file mode 100644
index 0000000..1e1cf8f
--- /dev/null
+++ b/sense2vec/sense2vec.py
@@ -0,0 +1,366 @@
+from typing import Tuple, List, Union, Sequence, Dict, Callable, Any
+from pathlib import Path
+from spacy.vectors import Vectors
+from spacy.strings import StringStore
+from spacy.util import SimpleFrozenDict
+from thinc.api import NumpyOps
+import numpy
+import srsly
+
+from .util import registry, cosine_similarity
+
+
+class Sense2Vec(object):
+ def __init__(
+ self,
+ shape: tuple = (1000, 128),
+ strings: StringStore = None,
+ senses: List[str] = [],
+ vectors_name: str = "sense2vec",
+ overrides: Dict[str, str] = SimpleFrozenDict(),
+ ):
+ """Initialize the Sense2Vec object.
+
+ shape (tuple): The vector shape.
+ strings (StringStore): Optional string store. Will be created if it
+ doesn't exist.
+ senses (list): Optional list of all available senses. Used in methods
+ that generate the best sense or other senses.
+ vectors_name (unicode): Optional name to assign to the Vectors object.
+ overrides (dict): Optional custom functions to use, mapped to names
+ registered via the registry, e.g. {"make_key": "custom_make_key"}.
+ RETURNS (Sense2Vec): The newly constructed object.
+ """
+ self.vectors = Vectors(shape=shape, name=vectors_name)
+ self._row2key = None
+ self.strings = StringStore() if strings is None else strings
+ self.freqs: Dict[int, int] = {}
+ self.cache = None
+ self.cfg: Dict[str, Any] = {
+ "senses": senses,
+ "make_key": "default",
+ "split_key": "default",
+ }
+ self.cfg.update(overrides)
+
+ @property
+ def senses(self) -> Sequence[str]:
+ """RETURNS (list): The available senses."""
+ return self.cfg.get("senses", [])
+
+ @property
+ def frequencies(self) -> List[Tuple[str, int]]:
+ """RETURNS (list): The (key, freq) tuples by frequency, descending."""
+ freqs = [(self.strings[k], s) for k, s in self.freqs.items() if s is not None]
+ return sorted(freqs, key=lambda item: item[1], reverse=True)
+
+ def __len__(self) -> int:
+ """RETURNS (int): The number of rows in the vectors table."""
+ return len(self.vectors)
+
+ def __contains__(self, key: Union[str, int]) -> bool:
+ """Check if a key is in the vectors table.
+
+ key (unicode / int): The key to look up.
+ RETURNS (bool): Whether the key is in the table.
+ """
+ key = self.ensure_int_key(key)
+ return key in self.vectors
+
+ def __getitem__(self, key: Union[str, int]) -> Union[numpy.ndarray, None]:
+ """Retrieve a vector for a given key. Returns None if the key is not
+ in the table.
+
+ key (unicode / int): The key to look up.
+ RETURNS (numpy.ndarray): The vector.
+ """
+ key = self.ensure_int_key(key)
+ if key in self.vectors:
+ return self.vectors[key]
+ return None
+
+ def __setitem__(self, key: Union[str, int], vector: numpy.ndarray):
+ """Set a vector for a given key. Will raise an error if the key
+ doesn't exist.
+
+ key (unicode / int): The key.
+ vector (numpy.ndarray): The vector to set.
+ """
+ key = self.ensure_int_key(key)
+ if key not in self.vectors:
+ raise ValueError(f"Can't find key {key} in table")
+ self.vectors[key] = vector
+ self._row2key = None
+
+ def __iter__(self):
+ """YIELDS (tuple): String key and vector pairs in the table."""
+ yield from self.items()
+
+ def items(self):
+ """YIELDS (tuple): String key and vector pairs in the table."""
+ for key, value in self.vectors.items():
+ yield self.strings[key], value
+
+ def keys(self):
+ """YIELDS (unicode): The string keys in the table."""
+ for key in self.vectors.keys():
+ yield self.strings[key]
+
+ def values(self):
+ """YIELDS (numpy.ndarray): The vectors in the table."""
+ yield from self.vectors.values()
+
+ @property
+ def row2key(self):
+ if not self._row2key:
+ self._row2key = {row: key for key, row in self.vectors.key2row.items()}
+ return self._row2key
+
+ @property
+ def make_key(self) -> Callable:
+ """Get the function to make keys."""
+ return registry.make_key.get(self.cfg["make_key"])
+
+ @property
+ def split_key(self) -> Callable:
+ """Get the function to split keys."""
+ return registry.split_key.get(self.cfg["split_key"])
+
+ def add(self, key: Union[str, int], vector: numpy.ndarray, freq: int = None):
+ """Add a new vector to the table.
+
+ key (unicode / int): The key to add.
+ vector (numpy.ndarray): The vector to add.
+ freq (int): Optional frequency count.
+ """
+ if not isinstance(key, int):
+ key = self.strings.add(key)
+ self.vectors.add(key, vector=vector)
+ if freq is not None:
+ self.set_freq(key, freq)
+ self._row2key = None
+
+ def get_freq(self, key: Union[str, int], default=None) -> Union[int, None]:
+ """Get the frequency count for a given key.
+
+ key (unicode / int): They key to look up.
+ default: Default value to return if no frequency is found.
+ RETURNS (int): The frequency count.
+ """
+ key = self.ensure_int_key(key)
+ return self.freqs.get(key, default)
+
+ def set_freq(self, key: Union[str, int], freq: int):
+ """Set a frequency count for a given key.
+
+ key (unicode / int): The key to set the count for.
+ freq (int): The frequency count.
+ """
+ if not isinstance(freq, int):
+ raise ValueError(f"Invalid frequency count: {repr(freq)} for '{key}'")
+ key = self.ensure_int_key(key)
+ self.freqs[key] = freq
+
+ def ensure_int_key(self, key: Union[str, int]) -> int:
+ """Ensure that a key is an int by looking it up in the string store.
+
+ key (unicode / int): The key.
+ RETURNS (int): The integer key.
+ """
+ return key if isinstance(key, int) else self.strings.add(key)
+
+ def similarity(
+ self,
+ keys_a: Union[Sequence[Union[str, int]], str, int],
+ keys_b: Union[Sequence[Union[str, int]], str, int],
+ ) -> float:
+ """Make a semantic similarity estimate of two keys or two sets of keys.
+ The default estimate is cosine similarity using an average of vectors.
+
+ keys_a (unicode / int / iterable): The string or integer key(s).
+ keys_b (unicode / int / iterable): The other string or integer key(s).
+ RETURNS (float): The similarity score.
+ """
+ if isinstance(keys_a, (str, int)):
+ keys_a = [keys_a]
+ if isinstance(keys_b, (str, int)):
+ keys_b = [keys_b]
+ average_a = numpy.vstack([self[key] for key in keys_a]).mean(axis=0)
+ average_b = numpy.vstack([self[key] for key in keys_b]).mean(axis=0)
+ return cosine_similarity(average_a, average_b)
+
+ def most_similar(
+ self,
+ keys: Union[Sequence[Union[str, int]], str, int],
+ n: int = 10,
+ batch_size: int = 16,
+ ) -> List[Tuple[str, float]]:
+ """Get the most similar entries in the table. If more than one key is
+ provided, the average of the vectors is used.
+
+ keys (unicode / int / iterable): The string or integer key(s) to compare to.
+ n (int): The number of similar keys to return.
+ batch_size (int): The batch size to use.
+ RETURNS (list): The (key, score) tuples of the most similar vectors.
+ """
+ if isinstance(keys, (str, int)):
+ keys = [keys]
+ for key in keys:
+ if key not in self:
+ raise ValueError(f"Can't find key {key} in table")
+ if self.cache and self.cache["indices"].shape[1] >= n:
+ n = min(len(self.vectors), n)
+ key = self.ensure_int_key(key)
+ key_row = self.vectors.find(key=key)
+ if key_row < self.cache["indices"].shape[0]:
+ rows = self.cache["indices"][key_row, :n]
+ scores = self.cache["scores"][key_row, :n]
+ entries = zip(rows, scores)
+ entries = [
+ (self.strings[self.row2key[r]], score)
+ for r, score in entries
+ if r in self.row2key
+ ]
+ return entries
+ # Always ask for more because we'll always get the keys themselves
+ n = min(len(self.vectors), n + len(keys))
+ rows = numpy.asarray(self.vectors.find(keys=keys))
+ vecs = self.vectors.data[rows]
+ average = vecs.mean(axis=0, keepdims=True)
+ result_keys, _, scores = self.vectors.most_similar(
+ average, n=n, batch_size=batch_size
+ )
+ result = list(zip(result_keys.flatten(), scores.flatten()))
+ result = [(self.strings[key], score) for key, score in result if key]
+ result = [(key, score) for key, score in result if key not in keys]
+ return result
+
+ def get_other_senses(
+ self, key: Union[str, int], ignore_case: bool = True
+ ) -> List[str]:
+ """Find other entries for the same word with a different sense, e.g.
+ "duck|VERB" for "duck|NOUN".
+
+ key (unicode / int): The key to check.
+ ignore_case (bool): Check for uppercase, lowercase and titlecase.
+ RETURNS (list): The string keys of other entries with different senses.
+ """
+ result = []
+ key = key if isinstance(key, str) else self.strings[key]
+ word, orig_sense = self.split_key(key)
+ versions = (
+ set([word, word.lower(), word.upper(), word.title()])
+ if ignore_case
+ else [word]
+ )
+ for text in versions:
+ for sense in self.senses:
+ new_key = self.make_key(text, sense)
+ if sense != orig_sense and new_key in self:
+ result.append(new_key)
+ return result
+
+ def get_best_sense(
+ self, word: str, senses: Sequence[str] = tuple(), ignore_case: bool = True
+ ) -> Union[str, None]:
+ """Find the best-matching sense for a given word based on the available
+ senses and frequency counts. Returns None if no match is found.
+
+ word (unicode): The word to check.
+ senses (list): Optional list of senses to limit the search to. If not
+ set / empty, all senses in the vectors are used.
+ ignore_case (bool): Check for uppercase, lowercase and titlecase.
+ RETURNS (unicode): The best-matching key or None.
+ """
+ sense_options = senses or self.senses
+ if not sense_options:
+ return None
+ versions = (
+ set([word, word.lower(), word.upper(), word.title()])
+ if ignore_case
+ else [word]
+ )
+ freqs = []
+ for text in versions:
+ for sense in sense_options:
+ key = self.make_key(text, sense)
+ if key in self:
+ freq = self.get_freq(key, -1)
+ freqs.append((freq, key))
+ return max(freqs)[1] if freqs else None
+
+ def to_bytes(self, exclude: Sequence[str] = tuple()) -> bytes:
+ """Serialize a Sense2Vec object to a bytestring.
+
+ exclude (list): Names of serialization fields to exclude.
+ RETURNS (bytes): The serialized Sense2Vec object.
+ """
+ vectors_bytes = self.vectors.to_bytes()
+ freqs = list(self.freqs.items())
+ data = {"vectors": vectors_bytes, "cfg": self.cfg, "freqs": freqs}
+ if "strings" not in exclude:
+ data["strings"] = self.strings.to_bytes()
+ if "cache" not in exclude:
+ data["cache"] = self.cache
+ return srsly.msgpack_dumps(data)
+
+ def from_bytes(self, bytes_data: bytes, exclude: Sequence[str] = tuple()):
+ """Load a Sense2Vec object from a bytestring.
+
+ bytes_data (bytes): The data to load.
+ exclude (list): Names of serialization fields to exclude.
+ RETURNS (Sense2Vec): The loaded object.
+ """
+ data = srsly.msgpack_loads(bytes_data)
+ self.vectors = Vectors().from_bytes(data["vectors"])
+ # Pin vectors to the CPU so that we don't end up comparing
+ # numpy and cupy arrays.
+ self.vectors.to_ops(NumpyOps())
+ self.freqs = dict(data.get("freqs", []))
+ self.cfg.update(data.get("cfg", {}))
+ if "strings" not in exclude and "strings" in data:
+ self.strings = StringStore().from_bytes(data["strings"])
+ if "cache" not in exclude and "cache" in data:
+ self.cache = data.get("cache", {})
+ self._row2key = None
+ return self
+
+ def to_disk(self, path: Union[Path, str], exclude: Sequence[str] = tuple()):
+ """Serialize a Sense2Vec object to a directory.
+
+ path (unicode / Path): The path.
+ exclude (list): Names of serialization fields to exclude.
+ """
+ path = Path(path)
+ self.vectors.to_disk(path)
+ srsly.write_json(path / "cfg", self.cfg)
+ srsly.write_json(path / "freqs.json", list(self.freqs.items()))
+ if "strings" not in exclude:
+ self.strings.to_disk(path / "strings.json")
+ if "cache" not in exclude and self.cache:
+ srsly.write_msgpack(path / "cache", self.cache)
+
+ def from_disk(self, path: Union[Path, str], exclude: Sequence[str] = tuple()):
+ """Load a Sense2Vec object from a directory.
+
+ path (unicode / Path): The path to load from.
+ exclude (list): Names of serialization fields to exclude.
+ RETURNS (Sense2Vec): The loaded object.
+ """
+ path = Path(path)
+ strings_path = path / "strings.json"
+ freqs_path = path / "freqs.json"
+ cache_path = path / "cache"
+ self.vectors = Vectors().from_disk(path)
+ # Pin vectors to the CPU so that we don't end up comparing
+ # numpy and cupy arrays.
+ self.vectors.to_ops(NumpyOps())
+ self.cfg.update(srsly.read_json(path / "cfg"))
+ if freqs_path.exists():
+ self.freqs = dict(srsly.read_json(freqs_path))
+ if "strings" not in exclude and strings_path.exists():
+ self.strings = StringStore().from_disk(strings_path)
+ if "cache" not in exclude and cache_path.exists():
+ self.cache = srsly.read_msgpack(cache_path)
+ self._row2key = None
+ return self
diff --git a/sense2vec/tests/conftest.py b/sense2vec/tests/conftest.py
deleted file mode 100644
index 0670340..0000000
--- a/sense2vec/tests/conftest.py
+++ /dev/null
@@ -1,12 +0,0 @@
-import pytest
-
-
-def pytest_addoption(parser):
- parser.addoption("--models", action="http://github.com/store_true",
- help="include tests that require full models")
-
-
-def pytest_runtest_setup(item):
- for opt in ['models']:
- if opt in item.keywords and not item.config.getoption("--%s" % opt):
- pytest.skip("need --%s option to run" % opt)
diff --git a/sense2vec/tests/data/cache b/sense2vec/tests/data/cache
new file mode 100644
index 0000000..658d704
Binary files /dev/null and b/sense2vec/tests/data/cache differ
diff --git a/sense2vec/tests/data/cfg b/sense2vec/tests/data/cfg
new file mode 100644
index 0000000..35aa2e9
--- /dev/null
+++ b/sense2vec/tests/data/cfg
@@ -0,0 +1,6 @@
+{
+ "senses":[
+ "NOUN",
+ "VERB"
+ ]
+}
\ No newline at end of file
diff --git a/sense2vec/tests/data/freqs.json b/sense2vec/tests/data/freqs.json
new file mode 100644
index 0000000..cb6c225
--- /dev/null
+++ b/sense2vec/tests/data/freqs.json
@@ -0,0 +1,22 @@
+[
+ [
+ 1729617160722737612,
+ 498
+ ],
+ [
+ 5277779877049457024,
+ 6718
+ ],
+ [
+ 8106363108491243548,
+ 495
+ ],
+ [
+ 2803970341986411846,
+ 87
+ ],
+ [
+ 7493120824676996139,
+ 33985
+ ]
+]
\ No newline at end of file
diff --git a/sense2vec/tests/data/key2row b/sense2vec/tests/data/key2row
new file mode 100644
index 0000000..9d868d1
Binary files /dev/null and b/sense2vec/tests/data/key2row differ
diff --git a/sense2vec/tests/data/strings.json b/sense2vec/tests/data/strings.json
new file mode 100644
index 0000000..19b4ce3
--- /dev/null
+++ b/sense2vec/tests/data/strings.json
@@ -0,0 +1,7 @@
+[
+ "beekeepers|NOUN",
+ "duck|VERB",
+ "honey_bees|NOUN",
+ "Beekeepers|NOUN",
+ "duck|NOUN"
+]
\ No newline at end of file
diff --git a/sense2vec/tests/data/vectors b/sense2vec/tests/data/vectors
new file mode 100644
index 0000000..5c50142
Binary files /dev/null and b/sense2vec/tests/data/vectors differ
diff --git a/sense2vec/tests/test_component.py b/sense2vec/tests/test_component.py
new file mode 100644
index 0000000..9d62836
--- /dev/null
+++ b/sense2vec/tests/test_component.py
@@ -0,0 +1,137 @@
+import pytest
+import numpy
+import spacy
+from spacy.vocab import Vocab
+from spacy.tokens import Doc, Span
+from sense2vec import Sense2VecComponent
+from pathlib import Path
+
+
+@pytest.fixture
+def doc():
+ vocab = Vocab()
+ doc = Doc(vocab, words=["hello", "world"])
+ doc[0].pos_ = "INTJ"
+ doc[1].pos_ = "NOUN"
+ return doc
+
+
+def test_component_attributes(doc):
+ s2v = Sense2VecComponent(doc.vocab, shape=(10, 4))
+ vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.s2v.add("world|NOUN", vector, 123)
+ doc = s2v(doc)
+ assert doc[0]._.s2v_key == "hello|INTJ"
+ assert doc[1]._.s2v_key == "world|NOUN"
+ assert doc[0]._.in_s2v is False
+ assert doc[1]._.in_s2v is True
+ assert doc[0]._.s2v_freq is None
+ assert doc[1]._.s2v_freq == 123
+ assert numpy.array_equal(doc[1]._.s2v_vec, vector)
+
+
+def test_component_attributes_ents(doc):
+ s2v = Sense2VecComponent(doc.vocab, shape=(10, 4))
+ s2v.first_run = False
+ vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.s2v.add("world|NOUN", vector)
+ s2v.s2v.add("world|GPE", vector)
+ doc = s2v(doc)
+ assert len(doc._.s2v_phrases) == 0
+ doc.ents = [Span(doc, 1, 2, label="GPE")]
+ assert len(doc._.s2v_phrases) == 1
+ phrase = doc._.s2v_phrases[0]
+ assert phrase._.s2v_key == "world|GPE"
+ assert phrase[0]._.s2v_key == "world|NOUN"
+ assert phrase._.in_s2v is True
+ assert phrase[0]._.in_s2v is True
+
+
+def test_component_similarity(doc):
+ s2v = Sense2VecComponent(doc.vocab, shape=(4, 4))
+ s2v.first_run = False
+ vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.s2v.add("hello|INTJ", vector)
+ s2v.s2v.add("world|NOUN", vector)
+ doc = s2v(doc)
+ assert doc[0]._.s2v_similarity(doc[1]) == 1.0
+ assert doc[1:3]._.s2v_similarity(doc[1:3]) == 1.0
+
+
+def test_component_lemmatize(doc):
+ def lemmatize(doc, lookups):
+ for token in doc:
+ token.lemma_ = lookups.get(token.text, token.text)
+ return doc
+
+ s2v = Sense2VecComponent(doc.vocab, shape=(4, 4), lemmatize=True)
+ s2v.first_run = False
+ vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.s2v.add("hello|INTJ", vector)
+ s2v.s2v.add("world|NOUN", vector)
+ s2v.s2v.add("wrld|NOUN", vector)
+ doc = lemmatize(doc, {"world": "wrld"})
+ doc = s2v(doc)
+ assert doc[0]._.s2v_key == "hello|INTJ"
+ assert doc[1].lemma_ == "wrld"
+ assert doc[1]._.s2v_key == "wrld|NOUN"
+ doc = lemmatize(doc, {"hello": "hll"})
+ assert doc[0].lemma_ == "hll"
+ assert doc[0]._.s2v_key == "hello|INTJ"
+ s2v.s2v.add("hll|INTJ", vector)
+ assert doc[0]._.s2v_key == "hll|INTJ"
+ new_s2v = Sense2VecComponent().from_bytes(s2v.to_bytes())
+ assert new_s2v.s2v.cfg["lemmatize"] is True
+
+
+def test_component_to_from_bytes(doc):
+ s2v = Sense2VecComponent(doc.vocab, shape=(1, 4))
+ s2v.first_run = False
+ vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.s2v.add("world|NOUN", vector)
+ assert "world|NOUN" in s2v.s2v
+ assert "world|GPE" not in s2v.s2v
+ doc = s2v(doc)
+ assert doc[0]._.in_s2v is False
+ assert doc[1]._.in_s2v is True
+ s2v_bytes = s2v.to_bytes()
+ new_s2v = Sense2VecComponent(doc.vocab).from_bytes(s2v_bytes)
+ new_s2v.first_run = False
+ assert "world|NOUN" in new_s2v.s2v
+ assert numpy.array_equal(new_s2v.s2v["world|NOUN"], vector)
+ assert "world|GPE" not in new_s2v.s2v
+ new_s2v.s2v.vectors.resize((2, 4))
+ new_s2v.s2v.add("hello|INTJ", vector)
+ assert doc[0]._.in_s2v is False
+ new_doc = new_s2v(doc)
+ assert new_doc[0]._.in_s2v is True
+
+
+def test_component_initialize():
+ data_path = Path(__file__).parent / "data"
+ # With from_disk
+ nlp = spacy.blank("en")
+ s2v = nlp.add_pipe("sense2vec")
+ if Doc.has_extension("s2v_phrases"):
+ s2v.first_run = False # don't set up extensions again
+ s2v.from_disk(data_path)
+ doc = Doc(nlp.vocab, words=["beekeepers"], pos=["NOUN"])
+ s2v(doc)
+ assert doc[0]._.s2v_key == "beekeepers|NOUN"
+ most_similar = [item for item, score in doc[0]._.s2v_most_similar(2)]
+ assert most_similar[0] == ("honey bees", "NOUN")
+ assert most_similar[1] == ("Beekeepers", "NOUN")
+
+ # With initialize
+ nlp = spacy.blank("en")
+ s2v = nlp.add_pipe("sense2vec")
+ s2v.first_run = False # don't set up extensions again
+ init_cfg = {"sense2vec": {"data_path": str(data_path)}}
+ nlp.config["initialize"]["components"] = init_cfg
+ nlp.initialize()
+ doc = Doc(nlp.vocab, words=["beekeepers"], pos=["NOUN"])
+ s2v(doc)
+ assert doc[0]._.s2v_key == "beekeepers|NOUN"
+ most_similar = [item for item, score in doc[0]._.s2v_most_similar(2)]
+ assert most_similar[0] == ("honey bees", "NOUN")
+ assert most_similar[1] == ("Beekeepers", "NOUN")
diff --git a/sense2vec/tests/test_issue155.py b/sense2vec/tests/test_issue155.py
new file mode 100644
index 0000000..546734d
--- /dev/null
+++ b/sense2vec/tests/test_issue155.py
@@ -0,0 +1,13 @@
+from pathlib import Path
+import pytest
+from sense2vec.sense2vec import Sense2Vec
+from thinc.api import use_ops
+from thinc.util import has_cupy_gpu
+
+
+@pytest.mark.skipif(not has_cupy_gpu, reason="requires Cupy/GPU")
+def test_issue155():
+ data_path = Path(__file__).parent / "data"
+ with use_ops("cupy"):
+ s2v = Sense2Vec().from_disk(data_path)
+ s2v.most_similar("beekeepers|NOUN")
diff --git a/sense2vec/tests/test_model.py b/sense2vec/tests/test_model.py
new file mode 100644
index 0000000..45e29ea
--- /dev/null
+++ b/sense2vec/tests/test_model.py
@@ -0,0 +1,53 @@
+import pytest
+from pathlib import Path
+from sense2vec import Sense2Vec
+import numpy
+
+
+@pytest.fixture
+def s2v():
+ data_path = Path(__file__).parent / "data"
+ return Sense2Vec().from_disk(data_path)
+
+
+def test_model_most_similar(s2v):
+ s2v.cache = None
+ assert "beekeepers|NOUN" in s2v
+ ((key1, _), (key2, _)) = s2v.most_similar(["beekeepers|NOUN"], n=2)
+ assert key1 == "honey_bees|NOUN"
+ assert key2 == "Beekeepers|NOUN"
+
+
+def test_model_most_similar_cache(s2v):
+ query = "beekeepers|NOUN"
+ assert s2v.cache
+ assert query in s2v
+ indices = s2v.cache["indices"]
+ # Modify cache to test that the cache is used and values aren't computed
+ query_row = s2v.vectors.find(key=s2v.ensure_int_key(query))
+ scores = numpy.array(s2v.cache["scores"], copy=True) # otherwise not writable
+ honey_bees_row = s2v.vectors.find(key="honey_bees|NOUN")
+ beekeepers_row = s2v.vectors.find(key="Beekeepers|NOUN")
+ for i in range(indices.shape[0]):
+ for j in range(indices.shape[1]):
+ if indices[i, j] == honey_bees_row:
+ scores[i, j] = 2.0
+ elif indices[i, j] == beekeepers_row:
+ scores[i, j] = 3.0
+ s2v.cache["scores"] = scores
+ ((key1, score1), (key2, score2)) = s2v.most_similar([query], n=2)
+ assert key1 == "honey_bees|NOUN"
+ assert score1 == 2.0
+ assert key2 == "Beekeepers|NOUN"
+ assert score2 == 3.0
+
+
+def test_model_other_senses(s2v):
+ others = s2v.get_other_senses("duck|NOUN")
+ assert len(others) == 1
+ assert others[0] == "duck|VERB"
+
+
+def test_model_best_sense(s2v):
+ assert s2v.get_best_sense("duck") == "duck|NOUN"
+ assert s2v.get_best_sense("honey bees") == "honey_bees|NOUN"
diff --git a/sense2vec/tests/test_sense2vec.py b/sense2vec/tests/test_sense2vec.py
index 0268e1a..298d32c 100644
--- a/sense2vec/tests/test_sense2vec.py
+++ b/sense2vec/tests/test_sense2vec.py
@@ -1,12 +1,161 @@
import pytest
+import numpy
+from sense2vec import Sense2Vec, registry
-import sense2vec
+def test_sense2vec_object():
+ s2v = Sense2Vec(shape=(10, 4))
+ assert s2v.vectors.shape == (10, 4)
+ assert len(s2v) == 10
+ test_vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.add("test", test_vector)
+ assert "test" in s2v
+ assert isinstance(s2v.strings["test"], int)
+ assert s2v.strings["test"] in s2v
+ assert "foo" not in s2v
+ assert numpy.array_equal(s2v["test"], test_vector)
+ assert numpy.array_equal(s2v[s2v.strings["test"]], test_vector)
+ assert list(s2v.keys()) == ["test"]
+ s2v.add("test2", test_vector)
+ assert "test2" in s2v
+ assert sorted(list(s2v.keys())) == ["test", "test2"]
+ with pytest.raises(ValueError):
+ s2v["test3"] = test_vector
+ s2v["test2"] = test_vector
-@pytest.mark.models
-def test_sample():
- s2v = sense2vec.load('reddit_vectors')
- freq, query_vector = s2v[u"beekeepers|NOUN"]
- assert freq is not None
- assert s2v.most_similar(query_vector, 3)[0] == \
- [u'beekeepers|NOUN', u'honey_bees|NOUN', u'Beekeepers|NOUN']
+
+def test_sense2vec_freqs():
+ s2v = Sense2Vec(shape=(10, 4))
+ vector = numpy.asarray([4, 2, 2, 2], dtype=numpy.float32)
+ s2v.add("test1", vector, 123)
+ s2v.add("test2", vector, 456)
+ assert len(s2v.freqs) == 2
+ assert s2v.get_freq("test1") == 123
+ assert s2v.get_freq("test2") == 456
+ assert s2v.get_freq("test3") is None
+ assert s2v.get_freq("test3", 100) == 100
+ s2v.set_freq("test3", 200)
+ assert s2v.get_freq("test3") == 200
+
+
+def test_sense2vec_other_senses():
+ s2v = Sense2Vec(shape=(6, 4))
+ s2v.cfg["senses"] = ["A", "B", "C", "D"]
+ for key in ["a|A", "a|B", "a|C", "b|A", "b|C", "c|A"]:
+ s2v.add(key, numpy.asarray([4, 2, 2, 2], dtype=numpy.float32))
+ others = s2v.get_other_senses("a|A")
+ assert sorted(others) == ["a|B", "a|C"]
+ others = s2v.get_other_senses("b|C")
+ assert others == ["b|A"]
+ others = s2v.get_other_senses("B|C")
+ assert others == ["b|A"]
+ others = s2v.get_other_senses("c|A")
+ assert others == []
+
+
+def test_sense2vec_best_sense():
+ s2v = Sense2Vec(shape=(5, 4))
+ s2v.cfg["senses"] = ["A", "B", "C"]
+ for key, freq in [("a|A", 100), ("a|B", 50), ("a|C", 10), ("b|A", 1), ("B|C", 2)]:
+ s2v.add(key, numpy.asarray([4, 2, 2, 2], dtype=numpy.float32), freq)
+ assert s2v.get_best_sense("a") == "a|A"
+ assert s2v.get_best_sense("A") == "a|A"
+ assert s2v.get_best_sense("b") == "B|C"
+ assert s2v.get_best_sense("b", ignore_case=False) == "b|A"
+ assert s2v.get_best_sense("c") is None
+ s2v.cfg["senses"] = []
+ assert s2v.get_best_sense("a") is None
+ assert s2v.get_best_sense("b", ["A"]) == "b|A"
+ assert s2v.get_best_sense("b", ["A", "C"]) == "B|C"
+
+
+def test_sense2vec_similarity():
+ s2v = Sense2Vec(shape=(5, 4))
+ s2v.add("a", numpy.asarray([4, 4, 2, 2], dtype=numpy.float32))
+ s2v.add("b", numpy.asarray([4, 4, 2, 2], dtype=numpy.float32))
+ s2v.add("c", numpy.asarray([4, 4, 4, 2], dtype=numpy.float32))
+ s2v.add("d", numpy.asarray([0.1, 0.2, 0.3, 0.4], dtype=numpy.float32))
+ s2v.add("e", numpy.asarray([0, 0, 0, 0], dtype=numpy.float32))
+ assert s2v.similarity("a", "b") == 1.0
+ assert 1.0 > s2v.similarity("b", "c") > 0.9
+ assert 1.0 > s2v.similarity(["a", "b"], "c") > 0.9
+ assert s2v.similarity("b", "c") == s2v.similarity(["a", "b"], "c")
+ assert s2v.similarity("a", "d") < 0.8
+ assert s2v.similarity("a", "e") == 0.0
+
+
+def test_sense2vec_most_similar():
+ s2v = Sense2Vec(shape=(6, 4))
+ s2v.add("a", numpy.asarray([4, 2, 2, 2], dtype=numpy.float32))
+ s2v.add("b", numpy.asarray([4, 4, 2, 2], dtype=numpy.float32))
+ s2v.add("c", numpy.asarray([4, 4, 4, 2], dtype=numpy.float32))
+ s2v.add("d", numpy.asarray([4, 4, 4, 4], dtype=numpy.float32))
+ s2v.add("x", numpy.asarray([4, 2, 2, 2], dtype=numpy.float32))
+ s2v.add("y", numpy.asarray([0.1, 1, 1, 1], dtype=numpy.float32))
+ result1 = s2v.most_similar(["x"], n=2)
+ assert len(result1) == 2
+ assert result1[0][0] == "a"
+ assert result1[0][1] == 1.0
+ assert result1[0][1] == pytest.approx(1.0)
+ assert result1[1][0] == "b"
+ result2 = s2v.most_similar(["a", "x"], n=2)
+ assert len(result2) == 2
+ assert sorted([key for key, _ in result2]) == ["b", "d"]
+ result3 = s2v.most_similar(["a", "b"], n=3)
+ assert len(result3) == 3
+ assert "y" not in [key for key, _ in result3]
+ assert len(s2v.most_similar(["a", "b"], n=10)) == 4
+ with pytest.raises(ValueError):
+ s2v.most_similar(["z"], n=1) # key not in table
+
+
+def test_sense2vec_to_from_bytes():
+ s2v = Sense2Vec(shape=(2, 4))
+ test_vector1 = numpy.asarray([1, 2, 3, 4], dtype=numpy.float32)
+ test_vector2 = numpy.asarray([5, 6, 7, 8], dtype=numpy.float32)
+ s2v.add("test1", test_vector1, 123)
+ s2v.add("test2", test_vector2, 456)
+ s2v_bytes = s2v.to_bytes()
+ new_s2v = Sense2Vec().from_bytes(s2v_bytes)
+ assert len(new_s2v) == 2
+ assert new_s2v.vectors.shape == (2, 4)
+ assert "test1" in new_s2v
+ assert "test2" in new_s2v
+ assert new_s2v.get_freq("test1") == 123
+ assert new_s2v.get_freq("test2") == 456
+ assert numpy.array_equal(new_s2v["test1"], test_vector1)
+ assert numpy.array_equal(new_s2v["test2"], test_vector2)
+ assert s2v_bytes == new_s2v.to_bytes()
+ s2v_bytes2 = s2v.to_bytes(exclude=["strings"])
+ new_s2v2 = Sense2Vec().from_bytes(s2v_bytes2)
+ assert len(new_s2v2.strings) == 0
+ assert "test1" in new_s2v2
+ assert s2v.strings["test1"] in new_s2v2
+ with pytest.raises(KeyError): # can't resolve hash
+ new_s2v2.strings[s2v.strings["test2"]]
+
+
+def test_registry():
+ """Test that custom functions are used internally if they're registered."""
+
+ @registry.make_key.register("custom_make_key")
+ def custom_make_key(word, sense):
+ return f"{word}###{sense}"
+
+ @registry.split_key.register("custom_split_key")
+ def custom_split_key(key):
+ return tuple(key.split("###"))
+
+ overrides = {"make_key": "custom_make_key", "split_key": "custom_split_key"}
+ test_vector = numpy.asarray([1, 2, 3, 4], dtype=numpy.float32)
+ data = [("clear", "NOUN", 100), ("clear", "VERB", 200), ("clear", "ADJ", 300)]
+ s2v = Sense2Vec(shape=(len(data), 4), overrides=overrides)
+ for word, sense, freq in data:
+ s2v.add(custom_make_key(word, sense), test_vector, freq)
+ s2v.cfg["senses"].append(sense)
+ assert "clear###NOUN" in s2v
+ other_senses = s2v.get_other_senses("clear###NOUN")
+ assert len(other_senses) == 2
+ assert "clear###VERB" in other_senses
+ assert "clear###ADJ" in other_senses
+ assert s2v.get_best_sense("clear") == "clear###ADJ"
diff --git a/sense2vec/tests/test_util.py b/sense2vec/tests/test_util.py
new file mode 100644
index 0000000..80ad994
--- /dev/null
+++ b/sense2vec/tests/test_util.py
@@ -0,0 +1,59 @@
+import pytest
+from spacy.tokens import Doc, Span
+from spacy.vocab import Vocab
+from sense2vec.util import get_true_cased_text, make_key, split_key
+
+
+def get_doc(vocab, words, spaces, pos):
+ doc = Doc(vocab, words=words, spaces=spaces)
+ for i, pos_tag in enumerate(pos):
+ doc[i].pos_ = pos_tag
+ return doc
+
+
+def test_get_true_cased_text():
+ vocab = Vocab()
+ words1 = ["Cool", ",", "thanks", "!"]
+ spaces1 = [False, True, False, False]
+ pos1 = ["ADJ", "PUNCT", "NOUN", "PUNCT"]
+ doc1 = get_doc(vocab, words1, spaces1, pos1)
+ assert get_true_cased_text(doc1[0:4]) == "cool, thanks!"
+ assert get_true_cased_text(doc1[0]) == "cool"
+ assert get_true_cased_text(doc1[2:4]) == "thanks!"
+ words2 = ["I", "can", "understand", "."]
+ spaces2 = [True, True, False, False]
+ pos2 = ["PRON", "VERB", "VERB", "PUNCT"]
+ doc2 = get_doc(vocab, words2, spaces2, pos2)
+ assert get_true_cased_text(doc2[0:4]) == "I can understand."
+ assert get_true_cased_text(doc2[0]) == "I"
+ assert get_true_cased_text(doc2[2:4]) == "understand."
+ words3 = ["You", "think", "Obama", "was", "pretty", "good", "..."]
+ spaces3 = [True, True, True, True, True, False, False]
+ pos3 = ["PRON", "VERB", "PROPN", "VERB", "ADV", "ADJ", "PUNCT"]
+ doc3 = get_doc(vocab, words3, spaces3, pos3)
+ doc3.ents = [Span(doc3, 2, 3, label="PERSON")]
+ assert get_true_cased_text(doc3[0:7]) == "You think Obama was pretty good..."
+ assert get_true_cased_text(doc3[0]) == "you"
+ assert get_true_cased_text(doc3[2]) == "Obama"
+ assert get_true_cased_text(doc3[4:6]) == "pretty good"
+ words4 = ["Ok", ",", "Barack", "Obama", "was", "pretty", "good", "..."]
+ spaces4 = [False, True, True, True, True, True, False, False]
+ pos4 = ["INTJ", "PUNCT", "PROPN", "PROPN", "VERB", "ADV", "ADJ", "PUNCT"]
+ doc4 = get_doc(vocab, words4, spaces4, pos4)
+ doc4.ents = [Span(doc4, 2, 4, label="PERSON")]
+ assert get_true_cased_text(doc4[0:8]) == "Ok, Barack Obama was pretty good..."
+ assert get_true_cased_text(doc4[2:4]) == "Barack Obama"
+ assert get_true_cased_text(doc4[3]) == "Obama"
+
+
+@pytest.mark.parametrize(
+ "word,sense,expected",
+ [
+ ("foo", "bar", "foo|bar"),
+ ("hello world", "TEST", "hello_world|TEST"),
+ ("hello world |test!", "TEST", "hello_world_|test!|TEST"),
+ ],
+)
+def test_make_split_key(word, sense, expected):
+ assert make_key(word, sense) == expected
+ assert split_key(expected) == (word, sense)
diff --git a/sense2vec/tests/test_vectors.py b/sense2vec/tests/test_vectors.py
deleted file mode 100644
index 9d5d755..0000000
--- a/sense2vec/tests/test_vectors.py
+++ /dev/null
@@ -1,47 +0,0 @@
-import pytest
-import numpy
-
-from sense2vec.vectors import VectorStore
-
-
-def test_init():
- vec = VectorStore(128)
- assert vec.mem is not None
- with pytest.raises(AttributeError) as excinfo:
- vec.mem = None
-
-
-def test_add():
- vecs = VectorStore(128)
- good = numpy.ndarray(shape=(vecs.nr_dim,), dtype='float32')
- vecs.add(good)
- bad = numpy.ndarray(shape=(vecs.nr_dim+1,), dtype='float32')
- with pytest.raises(AssertionError) as excinfo:
- vecs.add(bad)
-
-
-@pytest.mark.xfail
-def test_borrow():
- vecs = VectorStore(128)
- good = numpy.ndarray(shape=(vecs.nr_dim,), dtype='float32')
- vecs.borrow(good)
- bad = numpy.ndarray(shape=(vecs.nr_dim+1,), dtype='float32')
- with pytest.raises(AssertionError) as excinfo:
- vecs.borrow(bad)
-
-
-@pytest.mark.xfail
-def test_most_similar():
- vecs = VectorStore(4)
- vecs.add(numpy.asarray([4,2,2,2], dtype='float32'))
- vecs.add(numpy.asarray([4,4,2,2], dtype='float32'))
- vecs.add(numpy.asarray([4,4,4,2], dtype='float32'))
- vecs.add(numpy.asarray([4,4,4,4], dtype='float32'))
-
- indices, scores = vecs.most_similar(
- numpy.asarray([4,2,2,2], dtype='float32'), 4)
- print(list(scores))
- assert list(indices) == [0,1]
- indices, scores = vecs.most_similar(
- numpy.asarray([0.1,1,1,1], dtype='float32'), 4)
- assert list(indices) == [4,3]
diff --git a/sense2vec/util.py b/sense2vec/util.py
index de356e9..e5862fe 100644
--- a/sense2vec/util.py
+++ b/sense2vec/util.py
@@ -1,26 +1,180 @@
-import sputnik
-from sputnik.dir_package import DirPackage
-from sputnik.package_list import (PackageNotFoundException,
- CompatiblePackageNotFoundException)
-
-from . import about
-
-
-def get_package(data_dir):
- if not isinstance(data_dir, six.string_types):
- raise RuntimeError('data_dir must be a string')
- return DirPackage(data_dir)
-
-
-def get_package_by_name(name=None, via=None):
- try:
- return sputnik.package(about.title, about.version,
- name or about.default_model, data_path=via)
- except PackageNotFoundException as e:
- raise RuntimeError("Model not installed. Please run 'python -m "
- "sense2vec.download' to install latest compatible "
- "model.")
- except CompatiblePackageNotFoundException as e:
- raise RuntimeError("Installed model is not compatible with sense2vec "
- "version. Please run 'python -m sense2vec.download "
- "--force' to install latest compatible model.")
+from typing import Union, List, Tuple, Set
+import re
+from spacy.tokens import Doc, Token, Span
+from spacy.util import filter_spans
+from thinc.api import get_array_module
+import catalogue
+
+try:
+ import importlib.metadata as importlib_metadata # Python 3.8
+except ImportError:
+ import importlib_metadata # noqa: F401
+
+
+class registry(object):
+ make_key = catalogue.create("sense2vec", "make_key")
+ split_key = catalogue.create("sense2vec", "split_key")
+ make_spacy_key = catalogue.create("sense2vec", "make_spacy_key")
+ get_phrases = catalogue.create("sense2vec", "get_phrases")
+ merge_phrases = catalogue.create("sense2vec", "merge_phrases")
+
+
+@registry.make_key.register("default")
+def make_key(word: str, sense: str) -> str:
+ """Create a key from a word and sense, e.g. "usage_example|NOUN".
+
+ word (unicode): The word.
+ sense (unicode): The sense.
+ RETURNS (unicode): The key.
+ """
+ text = re.sub(r"\s", "_", word)
+ return text + "|" + sense
+
+
+@registry.split_key.register("default")
+def split_key(key: str) -> Tuple[str, str]:
+ """Split a key into word and sense, e.g. ("usage example", "NOUN").
+
+ key (unicode): The key to split.
+ RETURNS (tuple): The split (word, sense) tuple.
+ """
+ if not isinstance(key, str) or "|" not in key:
+ raise ValueError(f"Invalid key: {key}")
+ word, sense = key.replace("_", " ").rsplit("|", 1)
+ return word, sense
+
+
+@registry.make_spacy_key.register("default")
+def make_spacy_key(
+ obj: Union[Token, Span], prefer_ents: bool = False, lemmatize: bool = False
+) -> Tuple[str, str]:
+ """Create a key from a spaCy object, i.e. a Token or Span. If the object
+ is a token, the part-of-speech tag (Token.pos_) is used for the sense
+ and a special string is created for URLs. If the object is a Span and
+ has a label (i.e. is an entity span), the label is used. Otherwise, the
+ span's root part-of-speech tag becomes the sense.
+
+ obj (Token / Span): The spaCy object to create the key for.
+ prefer_ents (bool): Prefer entity types for single tokens (i.e.
+ token.ent_type instead of tokens.pos_). Should be enabled if phrases
+ are merged into single tokens, because otherwise the entity sense would
+ never be used.
+ lemmatize (bool): Use the object's lemma instead of its text.
+ RETURNS (unicode): The key.
+ """
+ default_sense = "?"
+ text = get_true_cased_text(obj, lemmatize=lemmatize)
+ if isinstance(obj, Token):
+ if obj.like_url:
+ text = "%%URL"
+ sense = "X"
+ elif obj.ent_type_ and prefer_ents:
+ sense = obj.ent_type_
+ else:
+ sense = obj.pos_
+ elif isinstance(obj, Span):
+ sense = obj.label_ or obj.root.pos_
+ return (text, sense or default_sense)
+
+
+def get_true_cased_text(obj: Union[Token, Span], lemmatize: bool = False):
+ """Correct casing so that sentence-initial words are not title-cased. Named
+ entities and other special cases (such as the word "I") should still be
+ title-cased.
+
+ obj (Token / Span): The spaCy object to conver to text.
+ lemmatize (bool): Use the object's lemma instead of its text.
+ RETURNS (unicode): The converted text.
+ """
+ if lemmatize:
+ return obj.lemma_
+ if isinstance(obj, Token) and (not obj.is_sent_start or obj.ent_type_):
+ return obj.text
+ elif isinstance(obj, Span) and (not obj[0].is_sent_start or obj[0].ent_type):
+ return obj.text
+ elif ( # Okay, we have a non-entity, starting a sentence
+ not obj.text[0].isupper() # Is its first letter upper-case?
+ or any(c.isupper() for c in obj.text[1:]) # ..Only its first letter?
+ or obj.text[0] == "I" # Is it "I"?
+ ):
+ return obj.text
+ else: # Fix the casing
+ return obj.text.lower()
+
+
+def get_noun_phrases(doc: Doc) -> List[Span]:
+ """Compile a list of noun phrases in sense2vec's format (without
+ determiners). Separated out to make it easier to customize, e.g. for
+ languages that don't implement a noun_chunks iterator out-of-the-box, or
+ use different label schemes.
+
+ doc (Doc): The Doc to get noun phrases from.
+ RETURNS (list): The noun phrases as a list of Span objects.
+ """
+ trim_labels = ("advmod", "amod", "compound")
+ spans = []
+ if doc.has_annotation("DEP"):
+ for np in doc.noun_chunks:
+ while len(np) > 1 and np[0].dep_ not in trim_labels:
+ np = np[1:]
+ spans.append(np)
+ return spans
+
+
+@registry.get_phrases.register("default")
+def get_phrases(doc: Doc) -> List[Span]:
+ """Compile a list of sense2vec phrases based on a processed Doc: named
+ entities and noun chunks without determiners.
+
+ doc (Doc): The Doc to get phrases from.
+ RETURNS (list): The phrases as a list of Span objects.
+ """
+ spans = list(doc.ents)
+ ent_words: Set[str] = set()
+ for span in spans:
+ ent_words.update(token.i for token in span)
+ for np in get_noun_phrases(doc):
+ # Prefer entities over noun chunks if there's overlap
+ if not any(w.i in ent_words for w in np):
+ spans.append(np)
+ return spans
+
+
+def is_particle(
+ token: Token, pos: Tuple[str] = ("PART",), deps: Tuple[str] = ("prt",)
+) -> bool:
+ """Determine whether a word is a particle, for phrasal verb detection.
+
+ token (Token): The token to check.
+ pos (tuple): The universal POS tags to check (Token.pos_).
+ deps (tuple): The dependency labels to check (Token.dep_).
+ """
+ return token.pos_ in pos or token.dep_ in deps
+
+
+@registry.merge_phrases.register("default")
+def merge_phrases(doc: Doc) -> Doc:
+ """Transform a spaCy Doc to match the sense2vec format: merge entities
+ into one token and merge noun chunks without determiners.
+
+ doc (Doc): The document to merge phrases in.
+ RETURNS (Doc): The Doc with merged tokens.
+ """
+ spans = get_phrases(doc)
+ spans = filter_spans(spans)
+ with doc.retokenize() as retokenizer:
+ for span in spans:
+ retokenizer.merge(span)
+ return doc
+
+
+def cosine_similarity(vec1, vec2) -> float:
+ """Compute the cosine similarity of two vectors."""
+ if vec1.all() == 0 or vec2.all() == 0:
+ return 0.0
+ xp = get_array_module(vec1)
+ norm1 = xp.linalg.norm(vec1)
+ norm2 = xp.linalg.norm(vec2)
+ if norm1 == norm2:
+ return 1.0
+ return xp.dot(vec1, vec2) / (norm1 * norm2)
diff --git a/sense2vec/vectors.pxd b/sense2vec/vectors.pxd
deleted file mode 100644
index ea7dfab..0000000
--- a/sense2vec/vectors.pxd
+++ /dev/null
@@ -1,29 +0,0 @@
-from libcpp.vector cimport vector
-from preshed.maps cimport PreshMap
-from spacy.strings cimport StringStore, hash_string
-from murmurhash.mrmr cimport hash64
-
-from cymem.cymem cimport Pool
-
-
-cdef class VectorMap:
- cdef readonly Pool mem
- cdef readonly VectorStore data
- cdef readonly StringStore strings
- cdef readonly PreshMap freqs
-
-
-cdef class VectorStore:
- cdef readonly Pool mem
- cdef readonly PreshMap cache
- cdef vector[float*] vectors
- cdef vector[float] norms
- cdef vector[float] _similarities
- cdef readonly int nr_dim
-
-
-cdef float get_l2_norm(const float* vec, int n) nogil
-
-
-cdef float cosine_similarity(const float* v1, const float* v2,
- float norm1, float norm2, int n) nogil
diff --git a/sense2vec/vectors.pyx b/sense2vec/vectors.pyx
deleted file mode 100644
index 50ce668..0000000
--- a/sense2vec/vectors.pyx
+++ /dev/null
@@ -1,364 +0,0 @@
-# cython: profile=True
-# cython: cdivision=True
-# cython: infer_types=True
-cimport cython.parallel
-cimport cpython.array
-
-from libc.stdint cimport int32_t
-from libc.stdint cimport uint64_t
-from libc.string cimport memcpy
-from libc.math cimport sqrt
-
-from libcpp.pair cimport pair
-from libcpp.queue cimport priority_queue
-from libcpp.vector cimport vector
-from spacy.cfile cimport CFile
-from preshed.maps cimport PreshMap
-from spacy.strings cimport StringStore, hash_string
-from murmurhash.mrmr cimport hash64
-
-from cymem.cymem cimport Pool
-cimport numpy as np
-import numpy
-from os import path
-try:
- import ujson as json
-except ImportError:
- import json
-
-
-ctypedef pair[float, int] Entry
-ctypedef priority_queue[Entry] Queue
-ctypedef float (*do_similarity_t)(const float* v1, const float* v2,
- float nrm1, float nrm2, int nr_dim) nogil
-
-
-cdef struct _CachedResult:
- int* indices
- float* scores
- int n
-
-
-cdef class VectorMap:
- '''Provide key-based access into the VectorStore. Keys are unicode strings.
- Also manage freqs.'''
- def __init__(self, nr_dim):
- self.data = VectorStore(nr_dim)
- self.strings = StringStore()
- self.freqs = PreshMap()
-
- @property
- def nr_dim(self):
- return self.data.nr_dim
-
- def __len__(self):
- '''Number of entries in the map.
-
- Returns: length int >= 0
- '''
- return self.data.vectors.size()
-
- def __contains__(self, unicode string):
- '''Check whether the VectorMap has a given key.
-
- Returns: has_key bool
- '''
- cdef uint64_t hashed = hash_string(string)
- return bool(self.freqs[hashed])
-
- def __getitem__(self, unicode key):
- '''Retrieve a (frequency, vector) tuple from the vector map, or
- raise KeyError if the key is not found.
-
- Arguments:
- key unicode
-
- Returns:
- tuple[int, float32[:self.nr_dim]]
- '''
- cdef uint64_t hashed = hash_string(key)
- freq = self.freqs[hashed]
- if not freq:
- raise KeyError(key)
- else:
- i = self.strings[key]
- return freq, self.data[i]
-
- def __setitem__(self, unicode key, value):
- '''Assign a (frequency, vector) tuple to the vector map.
-
- Arguments:
- key unicode
- value tuple[int, float32[:self.nr_dim]]
- Returns:
- None
- '''
- # TODO: Handle case where we're over-writing an existing entry.
- cdef int freq
- cdef float[:] vector
- freq, vector = value
- idx = self.strings[key]
- cdef uint64_t hashed = hash_string(key)
- self.freqs[hashed] = freq
- assert self.data.vectors.size() == idx
- self.data.add(vector)
-
- def __iter__(self):
- '''Iterate over the keys in the map, in order of insertion.
-
- Generates:
- key unicode
- '''
- yield from self.strings
-
- def keys(self):
- '''Iterate over the keys in the map, in order of insertion.
-
- Generates:
- key unicode
- '''
- yield from self.strings
-
- def values(self):
- '''Iterate over the values in the map, in order of insertion.
-
- Generates:
- (freq,vector) tuple[int, float32[:self.nr_dim]]
- '''
- for key, value in self.items():
- yield value
-
- def items(self):
- '''Iterate over the items in the map, in order of insertion.
-
- Generates:
- (key, (freq,vector)): tuple[int, float32[:self.nr_dim]]
- '''
- cdef uint64_t hashed
- for i, string in enumerate(self.strings):
- hashed = hash_string(string)
- freq = self.freqs[hashed]
- yield string, (freq, self.data[i])
-
-
- def most_similar(self, float[:] vector, int n=10):
- '''Find the keys of the N most similar entries, given a vector.
-
- Arguments:
- vector float[:]
- n int default=10
-
- Returns:
- list[unicode] length<=n
- '''
- indices, scores = self.data.most_similar(vector, n)
- return [self.strings[idx] for idx in indices], scores
-
- def add(self, unicode string, int freq, float[:] vector):
- '''Insert a vector into the map by value. Makes a copy of the vector.
- '''
- idx = self.strings[string]
- cdef uint64_t hashed = hash_string(string)
- self.freqs[hashed] = freq
- assert self.data.vectors.size() == idx
- self.data.add(vector)
-
- def borrow(self, unicode string, int freq, float[:] vector):
- '''Insert a vector into the map by reference. Does not copy the data, and
- changes to the vector will be reflected in the VectorMap.
-
- The user is responsible for ensuring that another reference to the vector
- is maintained --- otherwise, the Python interpreter will free the memory,
- potentially resulting in an invalid read.
- '''
- idx = self.strings[string]
- cdef uint64_t hashed = hash_string(string)
- self.freqs[hashed] = freq
- assert self.data.vectors.size() == idx
- self.data.borrow(vector)
-
- def save(self, data_dir):
- '''Serialize to a directory.
-
- * data_dir/strings.json --- The keys, in insertion order.
- * data_dir/freqs.json --- The frequencies.
- * data_dir/vectors.bin --- The vectors.
- '''
- with open(path.join(data_dir, 'strings.json'), 'w') as file_:
- self.strings.dump(file_)
- self.data.save(path.join(data_dir, 'vectors.bin'))
- freqs = []
- cdef uint64_t hashed
- for string in self.strings:
- hashed = hash_string(string)
- freq = self.freqs[hashed]
- if not freq:
- continue
- freqs.append([string, freq])
- with open(path.join(data_dir, 'freqs.json'), 'w') as file_:
- json.dump(freqs, file_)
-
- def load(self, data_dir):
- '''Load from a directory:
-
- * data_dir/strings.json --- The keys, in insertion order.
- * data_dir/freqs.json --- The frequencies.
- * data_dir/vectors.bin --- The vectors.
- '''
- self.data.load(path.join(data_dir, 'vectors.bin'))
- with open(path.join(data_dir, 'strings.json')) as file_:
- self.strings.load(file_)
- with open(path.join(data_dir, 'freqs.json')) as file_:
- freqs = json.load(file_)
- cdef uint64_t hashed
- for string, freq in freqs:
- hashed = hash_string(string)
- self.freqs[hashed] = freq
-
-
-cdef class VectorStore:
- '''Maintain an array of float* pointers for word vectors, which the
- table may or may not own. Keys and frequencies sold separately ---
- we're just a dumb vector of data, that knows how to run linear-scan
- similarity queries.'''
- def __init__(self, int nr_dim):
- self.mem = Pool()
- self.nr_dim = nr_dim
- zeros = self.mem.alloc(self.nr_dim, sizeof(float))
- self.vectors.push_back(zeros)
- self.norms.push_back(0)
- self.cache = PreshMap(100000)
-
- def __getitem__(self, int i):
- cdef float* ptr = self.vectors.at(i)
- cv = ptr
- return numpy.asarray(cv)
-
- def add(self, float[:] vec):
- assert len(vec) == self.nr_dim
- ptr = self.mem.alloc(self.nr_dim, sizeof(float))
- memcpy(ptr,
- &vec[0], sizeof(ptr[0]) * self.nr_dim)
- self.norms.push_back(get_l2_norm(&ptr[0], self.nr_dim))
- self.vectors.push_back(ptr)
-
- def borrow(self, float[:] vec):
- self.norms.push_back(get_l2_norm(&vec[0], self.nr_dim))
- # Danger! User must ensure this is memory contiguous!
- self.vectors.push_back(&vec[0])
-
- def similarity(self, float[:] v1, float[:] v2):
- '''Measure the similarity between two vectors, using cosine.
-
- Arguments:
- v1 float[:]
- v2 float[:]
-
- Returns:
- similarity_score -1self.cache.get(cache_key)
- if cached_result is not NULL and cached_result.n == n:
- memcpy(&indices[0], cached_result.indices, sizeof(indices[0]) * n)
- memcpy(&scores[0], cached_result.scores, sizeof(scores[0]) * n)
- else:
- # This shouldn't happen. But handle it if it does
- if cached_result is not NULL:
- if cached_result.indices is not NULL:
- self.mem.free(cached_result.indices)
- if cached_result.scores is not NULL:
- self.mem.free(cached_result.scores)
- self.mem.free(cached_result)
- self._similarities.resize(self.vectors.size())
- linear_similarity(&indices[0], &scores[0], &self._similarities[0],
- n, &query[0], self.nr_dim,
- &self.vectors[0], &self.norms[0], self.vectors.size(),
- cosine_similarity)
- cached_result = <_CachedResult*>self.mem.alloc(sizeof(_CachedResult), 1)
- cached_result.n = n
- cached_result.indices = self.mem.alloc(
- sizeof(cached_result.indices[0]), n)
- cached_result.scores = self.mem.alloc(
- sizeof(cached_result.scores[0]), n)
- self.cache.set(cache_key, cached_result)
- memcpy(cached_result.indices, &indices[0], sizeof(indices[0]) * n)
- memcpy(cached_result.scores, &scores[0], sizeof(scores[0]) * n)
- return indices, scores
-
- def save(self, loc):
- cdef CFile cfile = CFile(loc, 'wb')
- cdef float* vec
- cdef int32_t nr_vector = self.vectors.size()
- cfile.write_from(&nr_vector, 1, sizeof(nr_vector))
- cfile.write_from(&self.nr_dim, 1, sizeof(self.nr_dim))
- for vec in self.vectors:
- cfile.write_from(vec, self.nr_dim, sizeof(vec[0]))
- cfile.close()
-
- def load(self, loc):
- cdef CFile cfile = CFile(loc, 'rb')
- cdef int32_t nr_vector
- cfile.read_into(&nr_vector, 1, sizeof(nr_vector))
- cfile.read_into(&self.nr_dim, 1, sizeof(self.nr_dim))
- cdef vector[float] tmp
- tmp.resize(self.nr_dim)
- cdef float[:] cv
- for i in range(nr_vector):
- cfile.read_into(&tmp[0], self.nr_dim, sizeof(tmp[0]))
- ptr = &tmp[0]
- cv = ptr
- if i >= 1:
- self.add(cv)
- cfile.close()
-
-
-cdef void linear_similarity(int* indices, float* scores, float* tmp,
- int nr_out, const float* query, int nr_dim,
- const float* const* vectors, const float* norms, int nr_vector,
- do_similarity_t get_similarity) nogil:
- query_norm = get_l2_norm(query, nr_dim)
- # Initialize the partially sorted heap
- cdef int i
- cdef float score
- for i in cython.parallel.prange(nr_vector, nogil=True):
- tmp[i] = get_similarity(query, vectors[i], query_norm, norms[i], nr_dim)
- cdef priority_queue[pair[float, int]] queue
- cdef float cutoff = 0
- for i in range(nr_vector):
- score = tmp[i]
- if score > cutoff:
- queue.push(pair[float, int](-score, i))
- cutoff = -queue.top().first
- if queue.size() > nr_out:
- queue.pop()
- # Fill the outputs
- i = 0
- while i < nr_out and not queue.empty():
- entry = queue.top()
- scores[nr_out-(i+1)] = -entry.first
- indices[nr_out-(i+1)] = entry.second
- queue.pop()
- i += 1
-
-
-cdef float get_l2_norm(const float* vec, int n) nogil:
- norm = 0.0
- for i in range(n):
- norm += vec[i] ** 2
- return sqrt(norm)
-
-
-cdef float cosine_similarity(const float* v1, const float* v2,
- float norm1, float norm2, int n) nogil:
- dot = 0.0
- for i in range(n):
- dot += v1[i] * v2[i]
- return dot / (norm1 * norm2)
diff --git a/setup.cfg b/setup.cfg
new file mode 100644
index 0000000..44a4c07
--- /dev/null
+++ b/setup.cfg
@@ -0,0 +1,66 @@
+[metadata]
+version = 2.0.2
+description = Contextually-keyed word vectors
+url = https://github.com/explosion/sense2vec
+author = Explosion
+author_email = contact@explosion.ai
+license = MIT
+long_description = file: README.md
+long_description_content_type = text/markdown
+classifiers =
+ Development Status :: 5 - Production/Stable
+ Environment :: Console
+ Intended Audience :: Developers
+ Intended Audience :: Science/Research
+ License :: OSI Approved :: MIT License
+ Operating System :: POSIX :: Linux
+ Operating System :: MacOS :: MacOS X
+ Operating System :: Microsoft :: Windows
+ Programming Language :: Python :: 3
+ Programming Language :: Python :: 3.6
+ Programming Language :: Python :: 3.7
+ Programming Language :: Python :: 3.8
+ Programming Language :: Python :: 3.9
+ Programming Language :: Python :: 3.10
+ Programming Language :: Python :: 3.11
+ Topic :: Scientific/Engineering
+
+[options]
+zip_safe = true
+include_package_data = true
+python_requires = >=3.6
+install_requires =
+ spacy>=3.0.0,<4.0.0
+ wasabi>=0.8.1,<1.2.0
+ srsly>=2.4.0,<3.0.0
+ catalogue>=2.0.1,<2.1.0
+ numpy>=1.15.0
+ importlib_metadata>=0.20; python_version < "3.8"
+
+[options.entry_points]
+spacy_factories =
+ sense2vec = sense2vec:component.make_sense2vec
+prodigy_recipes =
+ sense2vec.teach = sense2vec:prodigy_recipes.teach
+ sens2vec.to-patterns = sense2vec:prodigy_recipes.to_patterns
+ sense2vec.eval = sense2vec:prodigy_recipes.evaluate
+ sense2vec.eval-most-similar = sense2vec:prodigy_recipes.eval_most_similar
+ sense2vec.eval-ab = sense2vec:prodigy_recipes.eval_ab
+
+[bdist_wheel]
+universal = true
+
+[sdist]
+formats = gztar
+
+[flake8]
+ignore = E203, E266, E501, E731, W503
+max-line-length = 80
+select = B,C,E,F,W,T4,B9
+exclude =
+ .env,
+ .git,
+ __pycache__,
+
+[mypy]
+ignore_missing_imports = True
diff --git a/setup.py b/setup.py
index 91e4f34..0468093 100644
--- a/setup.py
+++ b/setup.py
@@ -1,165 +1,6 @@
#!/usr/bin/env python
-from __future__ import print_function
-import os
-import shutil
-import subprocess
-import sys
-import contextlib
-from distutils.command.build_ext import build_ext
-from distutils.sysconfig import get_python_inc
-from distutils import ccompiler, msvccompiler
-try:
- from setuptools import Extension, setup
-except ImportError:
- from distutils.core import Extension, setup
+if __name__ == "__main__":
+ from setuptools import setup, find_packages
-
-PACKAGES = [
- 'sense2vec',
- 'sense2vec.tests'
-]
-
-MOD_NAMES = [
- 'sense2vec.vectors'
-]
-
-
-# By subclassing build_extensions we have the actual compiler that will be used which is really known only after finalize_options
-# http://stackoverflow.com/questions/724664/python-distutils-how-to-get-a-compiler-that-is-going-to-be-used
-compile_options = {'msvc' : ['/Ox', '/EHsc'],
- 'other' : ['-O3', '-Wno-unused-function',
- '-fno-stack-protector']}
-link_options = {'msvc' : [],
- 'other' : ['-fno-stack-protector']}
-
-
-if os.environ.get('USE_BLAS') == '1':
- compile_options['other'].extend([
- '-DUSE_BLAS=1',
- '-fopenmp'])
-#else:
-# link_options['other'].extend([
-# '-fopenmp'])
-#
-
-class build_ext_subclass(build_ext):
- def build_extensions(self):
- for e in self.extensions:
- e.extra_compile_args = compile_options.get(
- self.compiler.compiler_type, compile_options['other'])
- for e in self.extensions:
- e.extra_link_args = link_options.get(
- self.compiler.compiler_type, link_options['other'])
- build_ext.build_extensions(self)
-
-
-def generate_cython(root, source):
- print('Cythonizing sources')
- p = subprocess.call([sys.executable,
- os.path.join(root, 'bin', 'cythonize.py'),
- source])
- if p != 0:
- raise RuntimeError('Running cythonize failed')
-
-
-def is_source_release(path):
- return os.path.exists(os.path.join(path, 'PKG-INFO'))
-
-
-def clean(path):
- for name in MOD_NAMES:
- name = name.replace('.', '/')
- for ext in ['.so', '.html', '.cpp', '.c']:
- file_path = os.path.join(path, name + ext)
- if os.path.exists(file_path):
- os.unlink(file_path)
-
-
-@contextlib.contextmanager
-def chdir(new_dir):
- old_dir = os.getcwd()
- try:
- os.chdir(new_dir)
- sys.path.insert(0, new_dir)
- yield
- finally:
- del sys.path[0]
- os.chdir(old_dir)
-
-
-def setup_package():
- root = os.path.abspath(os.path.dirname(__file__))
- src_path = 'sense2vec'
-
- if len(sys.argv) > 1 and sys.argv[1] == 'clean':
- return clean(root)
-
- with chdir(root):
- with open(os.path.join(root, src_path, 'about.py')) as f:
- about = {}
- exec(f.read(), about)
-
- with open(os.path.join(root, 'README.rst')) as f:
- readme = f.read()
-
- include_dirs = [
- get_python_inc(plat_specific=True),
- os.path.join(root, 'include')]
-
- if (ccompiler.new_compiler().compiler_type == 'msvc'
- and msvccompiler.get_build_version() == 9):
- include_dirs.append(os.path.join(root, 'include', 'msvc9'))
-
- ext_modules = []
- for mod_name in MOD_NAMES:
- mod_path = mod_name.replace('.', '/') + '.cpp'
- ext_modules.append(
- Extension(mod_name, [mod_path],
- language='c++', include_dirs=include_dirs))
-
- if not is_source_release(root):
- generate_cython(root, src_path)
-
- setup(
- name=about['title'],
- zip_safe=False,
- packages=PACKAGES,
- package_data={'': ['*.pyx', '*.pxd', '*.h']},
- description=about['summary'],
- author=about['author'],
- author_email=about['email'],
- version=about['version'],
- url=about['uri'],
- license=about['license'],
- ext_modules=ext_modules,
- install_requires=[
- 'numpy>=1.7',
- 'spacy>=0.100,<0.102',
- 'preshed>=0.46,<0.47',
- 'murmurhash>=0.26,<0.27',
- 'cymem>=1.30,<1.32',
- 'sputnik>=0.9.0,<0.10.0'],
- classifiers=[
- 'Development Status :: 4 - Beta',
- 'Environment :: Console',
- 'Intended Audience :: Developers',
- 'Intended Audience :: Science/Research',
- 'License :: OSI Approved :: MIT License',
- 'Operating System :: POSIX :: Linux',
- 'Operating System :: MacOS :: MacOS X',
- 'Operating System :: Microsoft :: Windows',
- 'Programming Language :: Cython',
- 'Programming Language :: Python :: 2.6',
- 'Programming Language :: Python :: 2.7',
- 'Programming Language :: Python :: 3.3',
- 'Programming Language :: Python :: 3.4',
- 'Programming Language :: Python :: 3.5',
- 'Topic :: Scientific/Engineering'],
- cmdclass = {
- 'build_ext': build_ext_subclass},
- )
-
-
-if __name__ == '__main__':
- setup_package()
+ setup(name="sense2vec", packages=find_packages())