|
| 1 | +<!-- TOC --> |
| 2 | + |
| 3 | +- [一致性非锁定读和锁定读](#一致性非锁定读和锁定读) |
| 4 | + - [一致性非锁定读](#一致性非锁定读) |
| 5 | + - [锁定读](#锁定读) |
| 6 | +- [InnoDB对MVCC的实现](#InnoDB对MVCC的实现) |
| 7 | + - [隐藏字段](#隐藏字段]) |
| 8 | + - [ReadView](#ReadView) |
| 9 | + - [undo-log](#undo-log) |
| 10 | + - [数据可见性算法](#数据可见性算法) |
| 11 | +- [RC、RR隔离级别下MVCC的差异](#RC、RR隔离级别下MVCC的差异) |
| 12 | +- [MVCC解决不可重复读问题](#MVCC解决不可重复读问题) |
| 13 | + - [在RC下ReadView生成情况](#在RC下ReadView生成情况) |
| 14 | + - [在RR下ReadView生成情况](#在RR下ReadView生成情况) |
| 15 | +- [MVCC+Next-key-Lock防止幻读](#MVCC➕Next-key-Lock防止幻读) |
| 16 | + |
| 17 | +<!-- /TOC --> |
| 18 | + |
| 19 | + |
| 20 | + |
| 21 | +## 一致性非锁定读和锁定读 |
| 22 | + |
| 23 | +#### 一致性非锁定读 |
| 24 | + |
| 25 | +对于 [**一致性非锁定读(Consistent Nonlocking Reads)** ](https://dev.mysql.com/doc/refman/5.7/en/innodb-consistent-read.html)的实现,通常做法是加一个版本号或者时间戳字段,在更新数据的同时版本号 + 1或者更新时间戳。查询时,将当前可见的版本号与对应记录的版本号进行比对,如果记录的版本小于可见版本,则表示该记录可见 |
| 26 | + |
| 27 | +在 `InnoDB` 存储引擎中,[多版本控制 (multi versioning)](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html) 就是对非锁定读的实现。如果读取的行正在执行 `DELETE` 或 `UPDATE` 操作,这时读取操作不会去等待行上锁的释放。相反地,`InnoDB` 存储引擎会去读取行的一个快照数据,对于这种读取历史数据的方式,我们叫它快照读 (snapshot read) |
| 28 | + |
| 29 | +在 `Repeatable Read` 和 `Read Committed` 两个隔离级别下,如果是执行普通的 `select` 语句(不包括 `select ... lock in share mode` ,` select ... for update`)则会使用 `一致性非锁定读(MVCC)`。并且在 `Repeatable Read` 下 `MVCC` 实现了可重复读和防止部分幻读 |
| 30 | + |
| 31 | + |
| 32 | + |
| 33 | +#### 锁定读 |
| 34 | + |
| 35 | +如果执行的是下列语句,就是 [**锁定读(Locking Reads)**](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking-reads.html) |
| 36 | + |
| 37 | +- select ... lock in share mode |
| 38 | +- select ... for update |
| 39 | +- insert、update、delete 操作 |
| 40 | + |
| 41 | + |
| 42 | + |
| 43 | +在锁定读下,读取的是数据的最新版本,这种读也被称为 `当前读(current read)`。锁定读会对读取到的记录加锁: |
| 44 | + |
| 45 | +- `select ... lock in share mode`:对记录加 `S` 锁,其它事务也可以加`S`锁,如果加 `x` 锁则会被阻塞 |
| 46 | + |
| 47 | +- `select ... for update`、`insert`、`update`、`delete `:对记录加 `X` 锁,且其它事务不能加任何锁 |
| 48 | + |
| 49 | + |
| 50 | + |
| 51 | +在一致性非锁定读下,即使读取的记录已被其它事务加上 `X` 锁,这时记录也是可以被读取的,即读取的快照数据。上面说了在 `Repeatable Read` 下 `MVCC` 防止了部分幻读,这边的 “部分” 是指在 `一致性非锁定读` 情况下,只能读取到第一次查询之前所插入的数据(根据Read View判断数据可见性,Read View在第一次查询时生成),但如果是`当前读` ,每次读取的都是最新数据,这时如果两次查询中间有其它事务插入数据,就会产生幻读。**所以 `InnoDB` 在实现`Repeatable Read` 时,如果执行的是当前读,则会对读取的记录使用 `Next-key Lock` ,来防止其它事务在间隙间插入数据** |
| 52 | + |
| 53 | + |
| 54 | + |
| 55 | +## InnoDB对MVCC的实现 |
| 56 | + |
| 57 | +`MVCC` 的实现依赖于:**隐藏字段、Read View、undo log**。在内部实现中,`InnoDB` 通过数据行的 `DB_TRX_ID` 和 `Read View` 来判断数据的可见性,如不可见,则通过数据行的 `DB_ROLL_PTR` 找到 `undo log` 中的历史版本。每个事务读到的数据版本可能是不一样的,在同一个事务中,用户只能看到该事务创建 `Read View` 之前已经提交的修改和该事务本身做的修改 |
| 58 | + |
| 59 | + |
| 60 | + |
| 61 | +#### 隐藏字段 |
| 62 | + |
| 63 | +在内部,`InnoDB` 存储引擎为每行数据添加了三个 [隐藏字段](https://dev.mysql.com/doc/refman/5.7/en/innodb-multi-versioning.html): |
| 64 | + |
| 65 | +- `DB_TRX_ID(6字节)`:表示最后一次插入或更新该行的事务id。此外,`delete` 操作在内部被视为更新,只不过会在记录头 `Record header` 中的 `deleted_flag` 字段将其标记为已删除 |
| 66 | +- `DB_ROLL_PTR(7字节)` 回滚指针,指向该行的 `undo log` 。如果该行未被更新,则为空 |
| 67 | +- `DB_ROW_ID(6字节)`:如果没有设置主键且该表没有唯一非空索引时,`InnoDB` 会使用该id来生成聚簇索引 |
| 68 | + |
| 69 | + |
| 70 | + |
| 71 | +#### ReadView |
| 72 | + |
| 73 | +[`Read View`](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L298) 主要是用来做可见性判断,里面保存了 “当前对本事务不可见的其他活跃事务” |
| 74 | + |
| 75 | +主要有以下字段: |
| 76 | + |
| 77 | +- `m_low_limit_id`:目前出现过的最大的事务ID+1,即下一个将被分配的事务ID。大于这个ID的数据版本均不可见 |
| 78 | +- `m_up_limit_id`:活跃事务列表 `m_ids` 中最小的事务ID,如果 `m_ids` 为空,则 `m_up_limit_id` 为 `m_low_limit_id`。小于这个ID的数据版本均可见 |
| 79 | +- `m_ids`:`Read View` 创建时其他未提交的活跃事务ID列表。创建 `Read View `时,将当前未提交事务ID记录下来,后续即使它们修改了记录行的值,对于当前事务也是不可见的。`m_ids` 不包括当前事务自己和已提交的事务(正在内存中) |
| 80 | +- `m_creator_trx_id`:创建该 `Read View` 的事务ID |
| 81 | + |
| 82 | + |
| 83 | + |
| 84 | +#### undo-log |
| 85 | + |
| 86 | +`undo log` 主要有两个作用: |
| 87 | + |
| 88 | +- 当事务回滚时用于将数据恢复到修改前的样子 |
| 89 | +- 另一个作用是 `MVCC` ,当读取记录时,若该记录被其他事务占用或当前版本对该事务不可见,则可以通过 `undo log` 读取之前的版本数据,以此实现非锁定读 |
| 90 | + |
| 91 | + |
| 92 | + |
| 93 | +**在 `InnoDB` 存储引擎中 `undo log` 分为两种: `insert undo log` 和 `update undo log`:** |
| 94 | + |
| 95 | + |
| 96 | + |
| 97 | +1. **`insert undo log`** :指在 `insert` 操作中产生的 `undo log`。因为 `insert` 操作的记录只对事务本身可见,对其他事务不可见,故该 `undo log` 可以在事务提交后直接删除。不需要进行 `purge` 操作 |
| 98 | + |
| 99 | + |
| 100 | + |
| 101 | +**`insert` 时的数据初始状态:** |
| 102 | + |
| 103 | +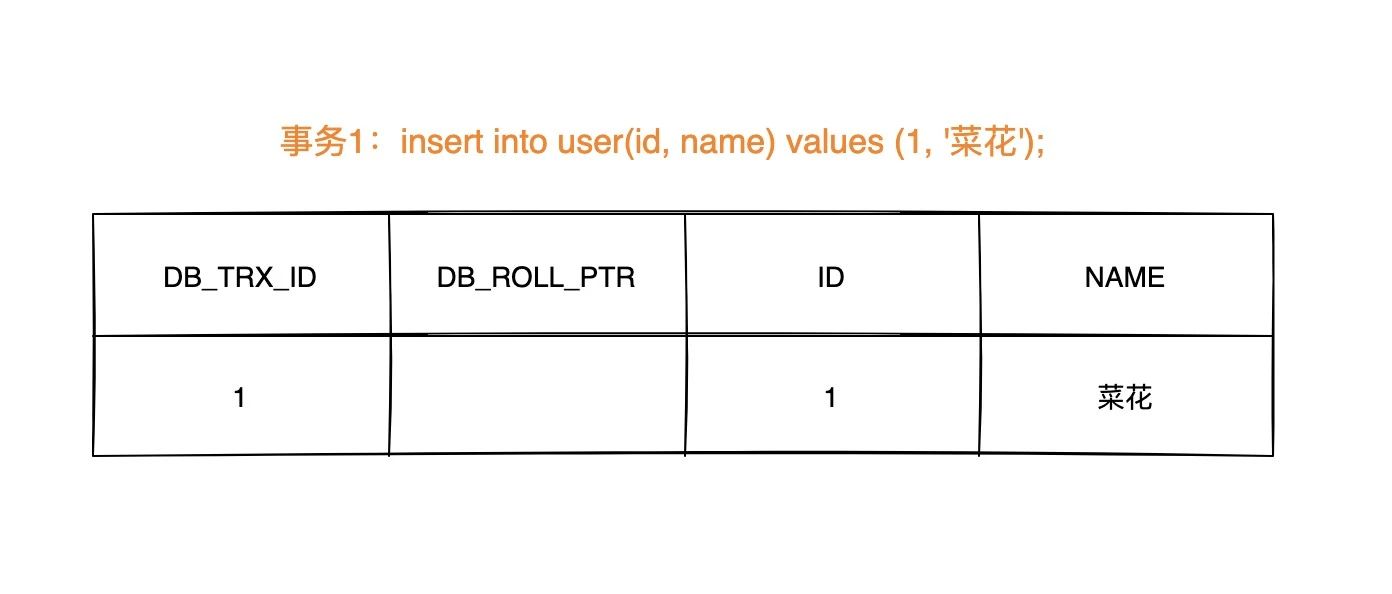 |
| 104 | + |
| 105 | +2. **`update undo log`** :`update` 或 `delete` 操作中产生的 `undo log`。该 `undo log`可能需要提供 `MVCC` 机制,因此不能在事务提交时就进行删除。提交时放入 `undo log` 链表,等待 `purge线程` 进行最后的删除 |
| 106 | + |
| 107 | + |
| 108 | + |
| 109 | +**数据第一次被修改时:** |
| 110 | + |
| 111 | + |
| 112 | + |
| 113 | +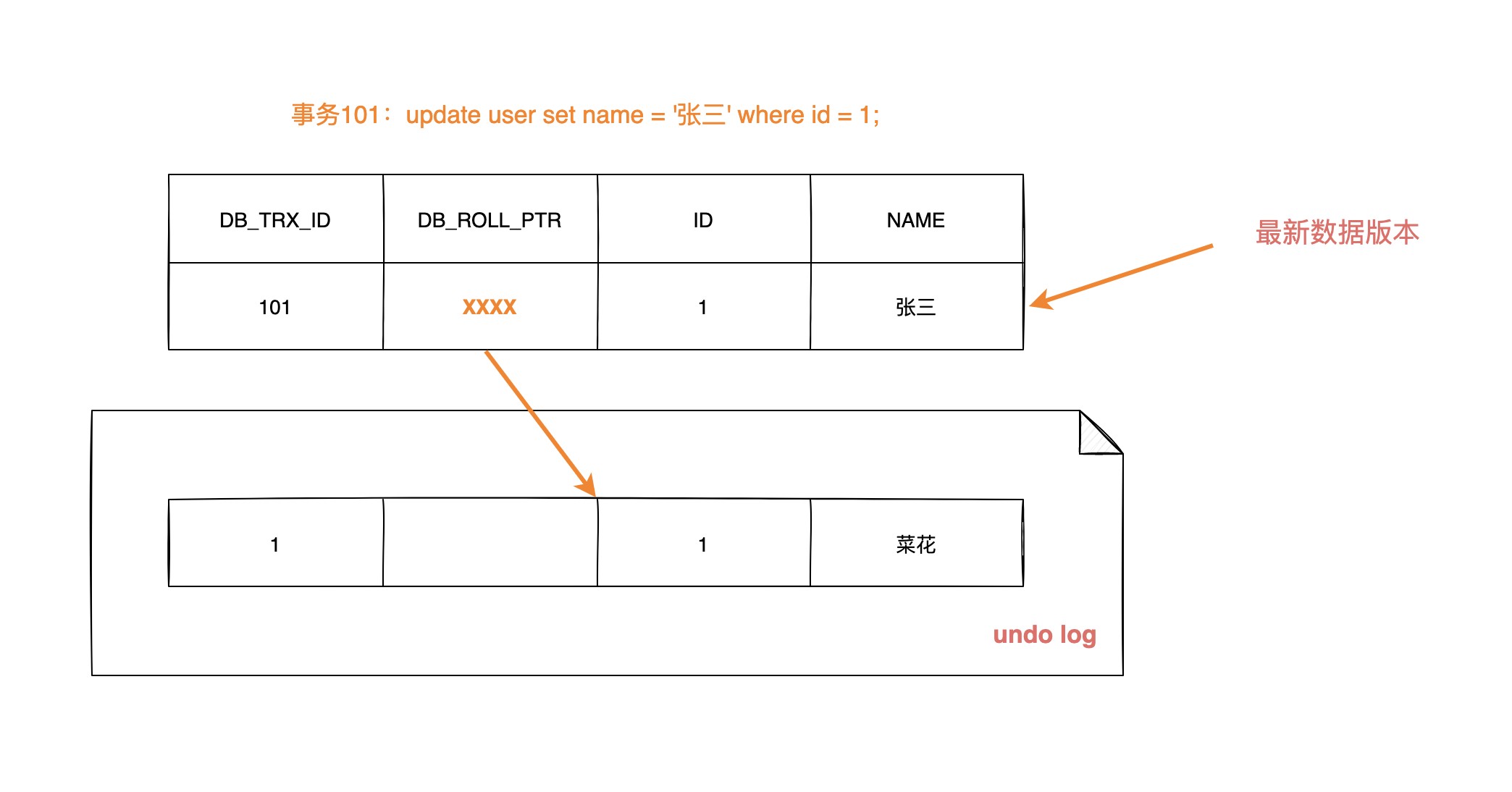 |
| 114 | + |
| 115 | +**数据第二次被修改时:** |
| 116 | + |
| 117 | + |
| 118 | + |
| 119 | +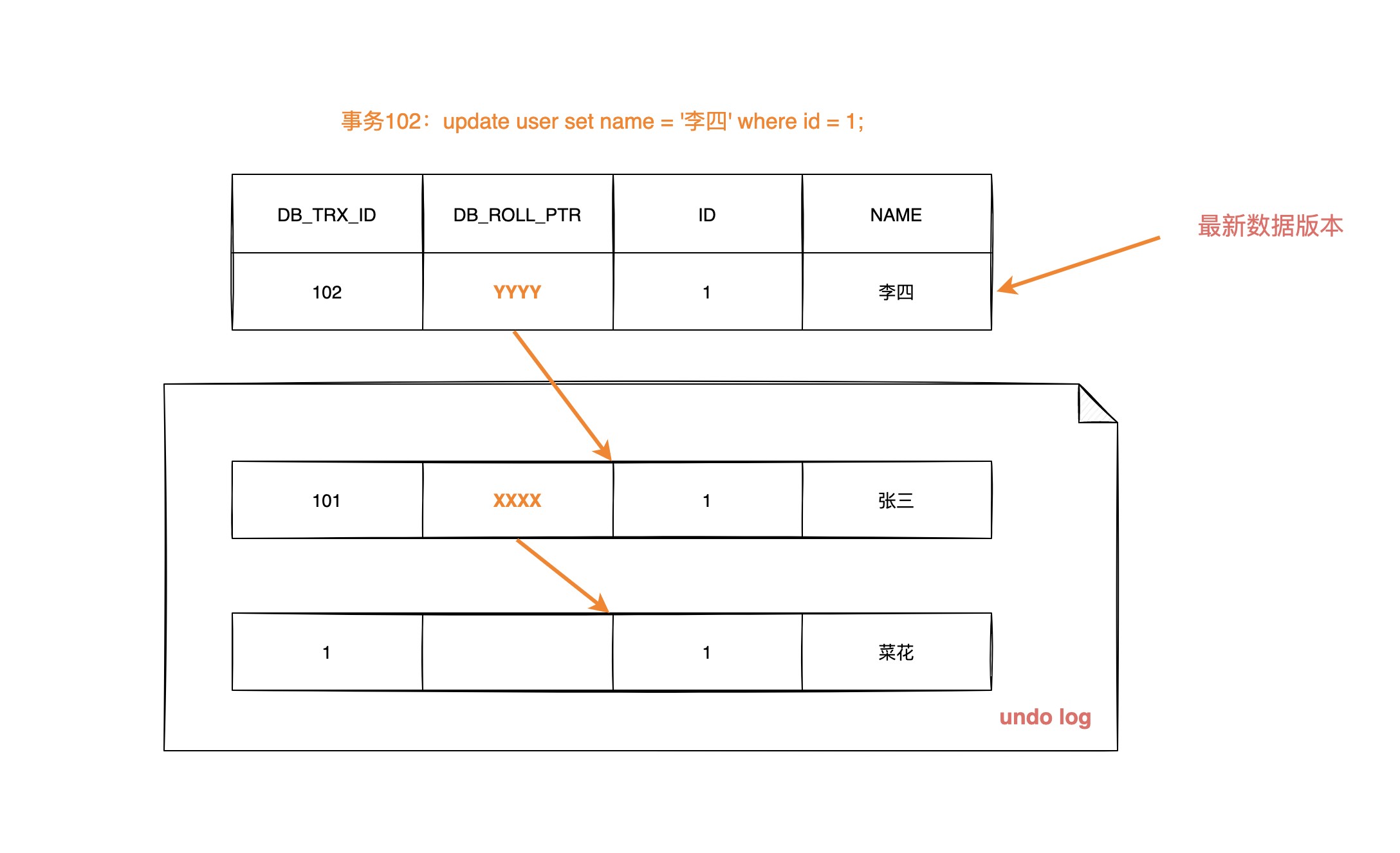 |
| 120 | + |
| 121 | +不同事务或者相同事务的对同一记录行的修改,会使该记录行的 `undo log` 成为一条链表,链首就是最新的记录,链尾就是最早的旧记录 |
| 122 | + |
| 123 | + |
| 124 | + |
| 125 | +#### 数据可见性算法 |
| 126 | + |
| 127 | +在 `InnoDB` 存储引擎中,创建一个新事务后,执行每个 `select` 语句前,都会创建一个快照(Read View),**快照中保存了当前数据库系统中正处于活跃(没有commit)的事务的ID号**。其实简单的说保存的是系统中当前不应该被本事务看到的其他事务ID列表(即m_ids)。当用户在这个事务中要读取某个记录行的时候,`InnoDB` 会将该记录行的 `DB_TRX_ID` 与 `Read View` 中的一些变量及当前事务ID进行比较,判断是否满足可见性条件 |
| 128 | + |
| 129 | +[具体的比较算法](https://github.com/facebook/mysql-8.0/blob/8.0/storage/innobase/include/read0types.h#L161)如下:[图源](https://leviathan.vip/2019/03/20/InnoDB%E7%9A%84%E4%BA%8B%E5%8A%A1%E5%88%86%E6%9E%90-MVCC/#MVCC-1) |
| 130 | + |
| 131 | + |
| 132 | + |
| 133 | +1. 如果记录 DB_TRX_ID < m_up_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之前就提交了,所以该记录行的值对当前事务是可见的 |
| 134 | + |
| 135 | +2. 如果 DB_TRX_ID >= m_low_limit_id,那么表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照之后才修改该行,所以该记录行的值对当前事务不可见。跳到步骤5 |
| 136 | + |
| 137 | +3. m_ids 为空,则表明在当前事务创建快照之前,修改该行的事务就已经提交了,所以该记录行的值对当前事务是可见的 |
| 138 | + |
| 139 | +4. 如果 m_up_limit_id <= DB_TRX_ID < m_up_limit_id,表明最新修改该行的事务(DB_TRX_ID)在当前事务创建快照的时候可能处于“活动状态”或者“已提交状态”;所以就要对活跃事务列表 m_ids 进行查找(源码中是用的二分查找,因为是有序的) |
| 140 | + |
| 141 | + - 如果在活跃事务列表 m_ids 中能找到 DB_TRX_ID,表明:①在当前事务创建快照前,该记录行的值被事务ID为 DB_TRX_ID 的事务修改了,但没有提交;或者 ②在当前事务创建快照后,该记录行的值被事务ID为 DB_TRX_ID 的事务修改了。这些情况下,这个记录行的值对当前事务都是不可见的。跳到步骤5 |
| 142 | + |
| 143 | + - 在活跃事务列表中找不到,则表明“id为trx_id的事务”在修改“该记录行的值”后,在“当前事务”创建快照前就已经提交了,所以记录行对当前事务可见 |
| 144 | + |
| 145 | +5. 在该记录行的 DB_ROLL_PTR 指针所指向的 `undo log` 取出快照记录,用快照记录的 DB_TRX_ID 跳到步骤1重新开始判断,直到找到满足的快照版本或返回空 |
| 146 | + |
| 147 | + |
| 148 | + |
| 149 | +## RC和RR隔离级别下MVCC的差异 |
| 150 | + |
| 151 | +在事务隔离级别 `RC` 和 `RR` (InnoDB存储引擎的默认事务隔离级别)下,` InnoDB` 存储引擎使用 `MVCC`(非锁定一致性读),但它们生成 `Read View` 的时机却不同 |
| 152 | + |
| 153 | +- 在 RC 隔离级别下的 **`每次select`** 查询前都生成一个`Read View` (m_ids列表) |
| 154 | +- 在 RR 隔离级别下只在事务开始后 **`第一次select`** 数据前生成一个`Read View`(m_ids列表) |
| 155 | + |
| 156 | + |
| 157 | + |
| 158 | +## MVCC解决不可重复读问题 |
| 159 | + |
| 160 | +虽然 RC 和 RR 都通过 `MVCC` 来读取快照数据,但由于 **生成 Read View 时机不同**,从而在 RR 级别下实现可重复读 |
| 161 | + |
| 162 | +举个例子: |
| 163 | + |
| 164 | + |
| 165 | + |
| 166 | + |
| 167 | +#### **在RC下ReadView生成情况** |
| 168 | + |
| 169 | +1. **`假设时间线来到 T4 ,那么此时数据行 id = 1 的版本链为`:** |
| 170 | + |
| 171 | + 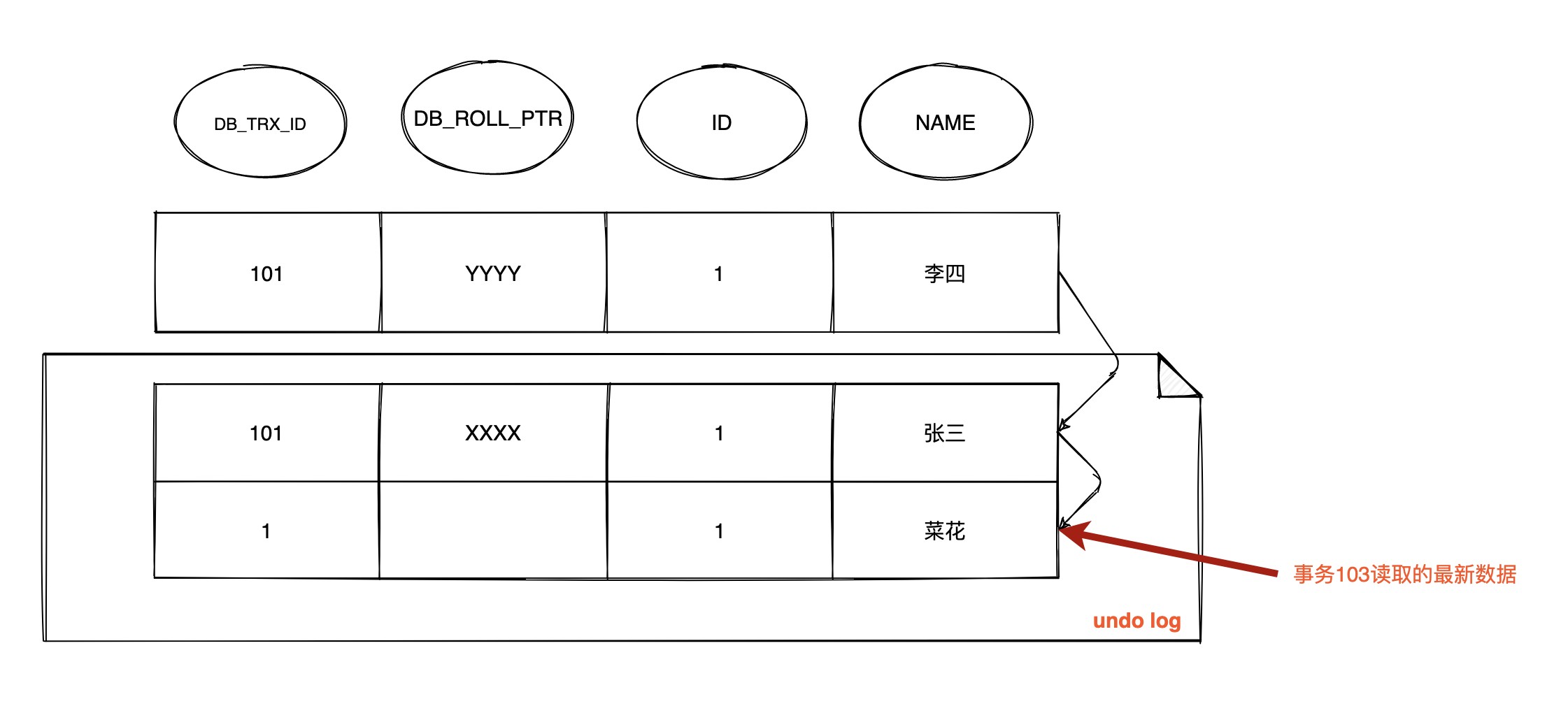 |
| 172 | + |
| 173 | +由于 RC 级别下每次查询都会生成` Read View` ,并且事务101、102 并未提交,此时 `103` 事务生成的 `Read View` 中活跃的事务 **`m_ids` 为:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103 |
| 174 | + |
| 175 | +- 此时最新记录的 `DB_TRX_ID` 为101,m_up_limit_id <= 101 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见 |
| 176 | +- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是101,不可见 |
| 177 | +- 继续找上一条 `DB_TRX_ID`为1,满足 1 < m_up_limit_id,可见,所以事务103查询到数据为 `name = 菜花` |
| 178 | + |
| 179 | + |
| 180 | + |
| 181 | +2. **`时间线来到 T6 ,数据的版本链为`:** |
| 182 | + |
| 183 | + 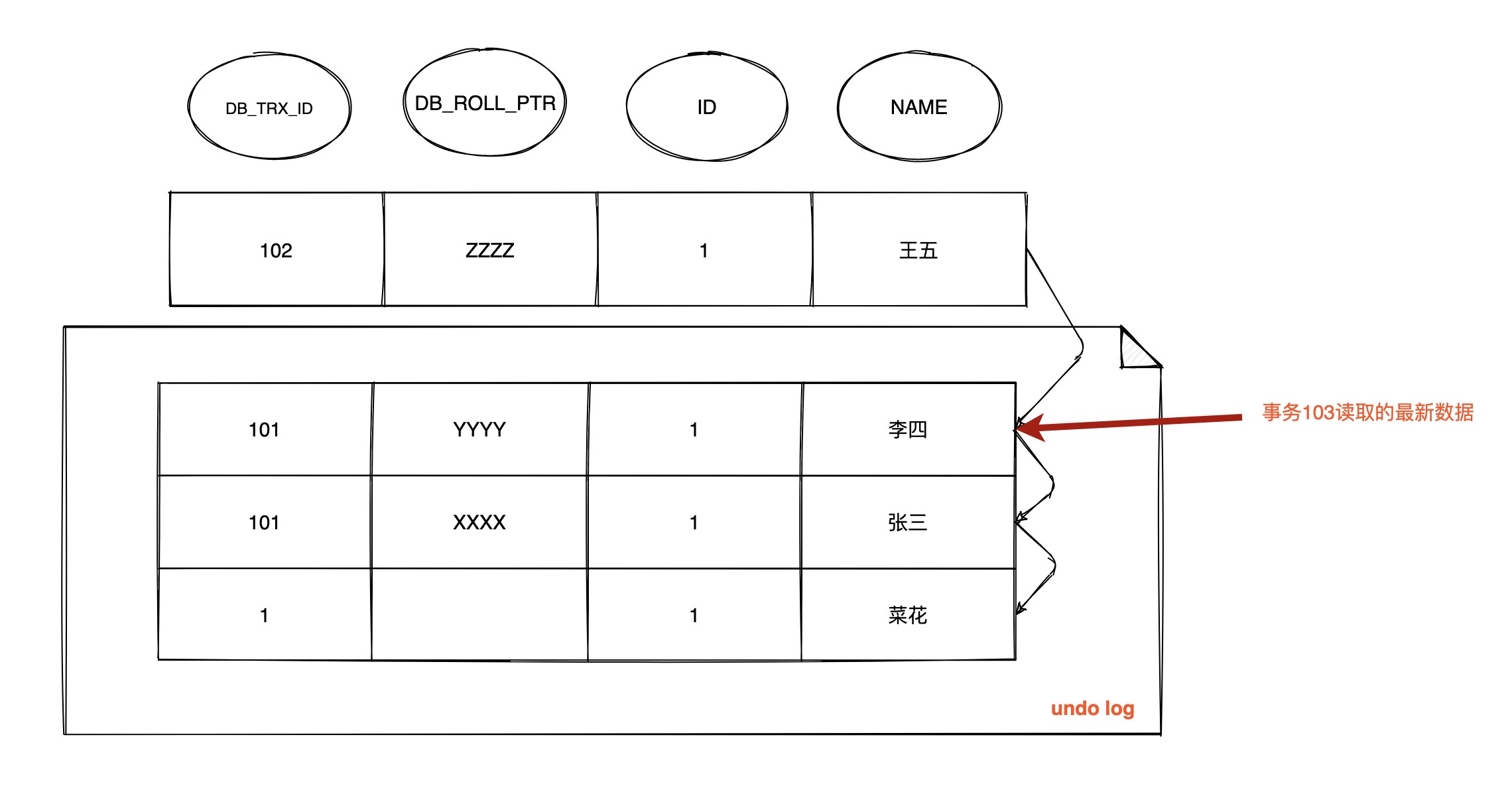 |
| 184 | + |
| 185 | +因为在 RC 级别下,重新生成 `Read View`,这时事务101已经提交,102并未提交,所以此时 `Read View` 中活跃的事务 **`m_ids`:[102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:102,`m_creator_trx_id`为:103 |
| 186 | + |
| 187 | +- 此时最新记录的 `DB_TRX_ID` 为102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见 |
| 188 | + |
| 189 | +- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 为101,满足 102 < m_up_limit_id,记录可见,所以在 `T6` 时间点查询到数据为 `name = 李四`,与时间 T4 查询到的结果不一致,不可重复读! |
| 190 | + |
| 191 | + |
| 192 | + |
| 193 | +3. **`时间线来到 T9 ,数据的版本链为`:** |
| 194 | + |
| 195 | + |
| 196 | + |
| 197 | +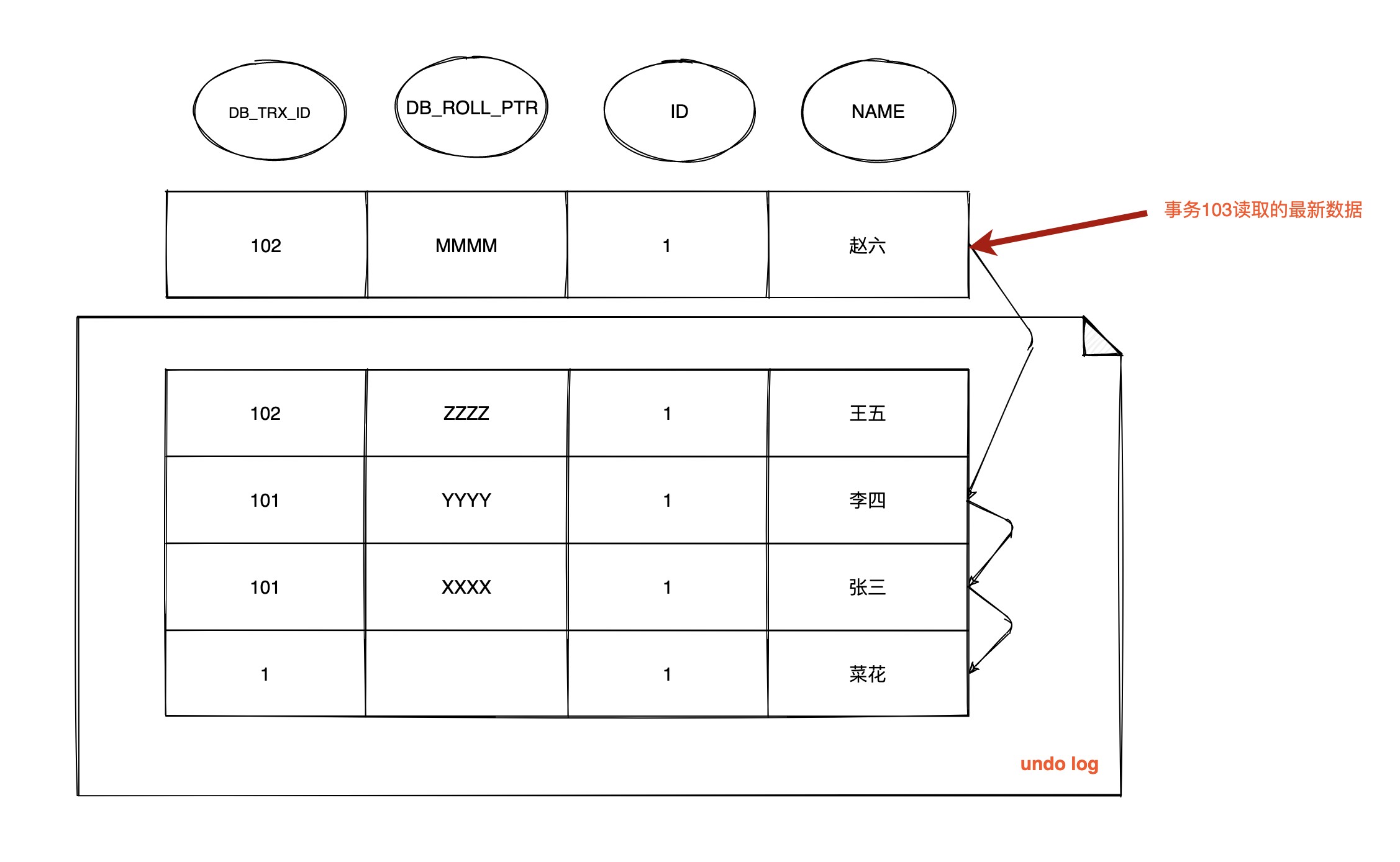 |
| 198 | + |
| 199 | +重新生成 `Read View`, 这时事务 101 和 102 都已经提交,所以 **m_ids** 为空,则 m_up_limit_id = m_low_limit_id = 104,最新版本事务ID为102,满足 102 < m_low_limit_id,可见,查询结果为 `name = 赵六` |
| 200 | + |
| 201 | + |
| 202 | + |
| 203 | +> **总结:** **在RC隔离级别下,事务在每次查询开始时都会生成并设置新的 Read View,所以导致不可重复读** |
| 204 | +
|
| 205 | + |
| 206 | +#### **在RR下ReadView生成情况** |
| 207 | + |
| 208 | +**在可重复读级别下,只会在事务开始后第一次读取数据时生成一个Read View(m_ids列表)** |
| 209 | + |
| 210 | +1. **`在 T4 情况下的版本链为`:** |
| 211 | + |
| 212 | + |
| 213 | +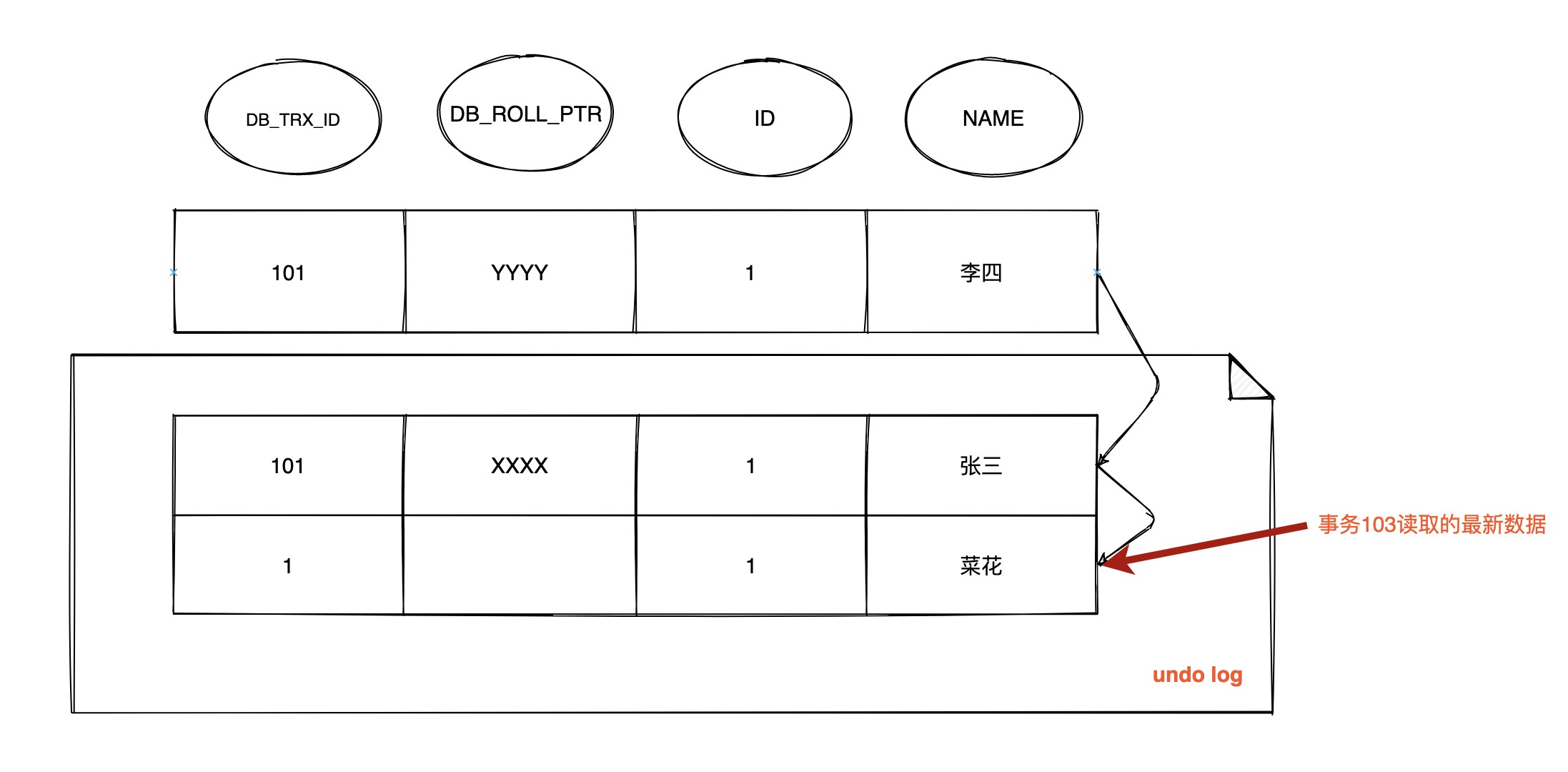 |
| 214 | + |
| 215 | +在当前执行 `select` 语句时生成一个 `Read View`,此时 **`m_ids`:[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103 |
| 216 | + |
| 217 | +此时和 RC 级别下一样: |
| 218 | + |
| 219 | +- 最新记录的 `DB_TRX_ID` 为101,m_up_limit_id <= 101 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见 |
| 220 | +- 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是101,不可见 |
| 221 | +- 继续找上一条 `DB_TRX_ID`为1,满足 1 < m_up_limit_id,可见,所以事务103查询到数据为 `name = 菜花` |
| 222 | + |
| 223 | + |
| 224 | +2. **`时间点 T6 情况下`:** |
| 225 | + |
| 226 | + 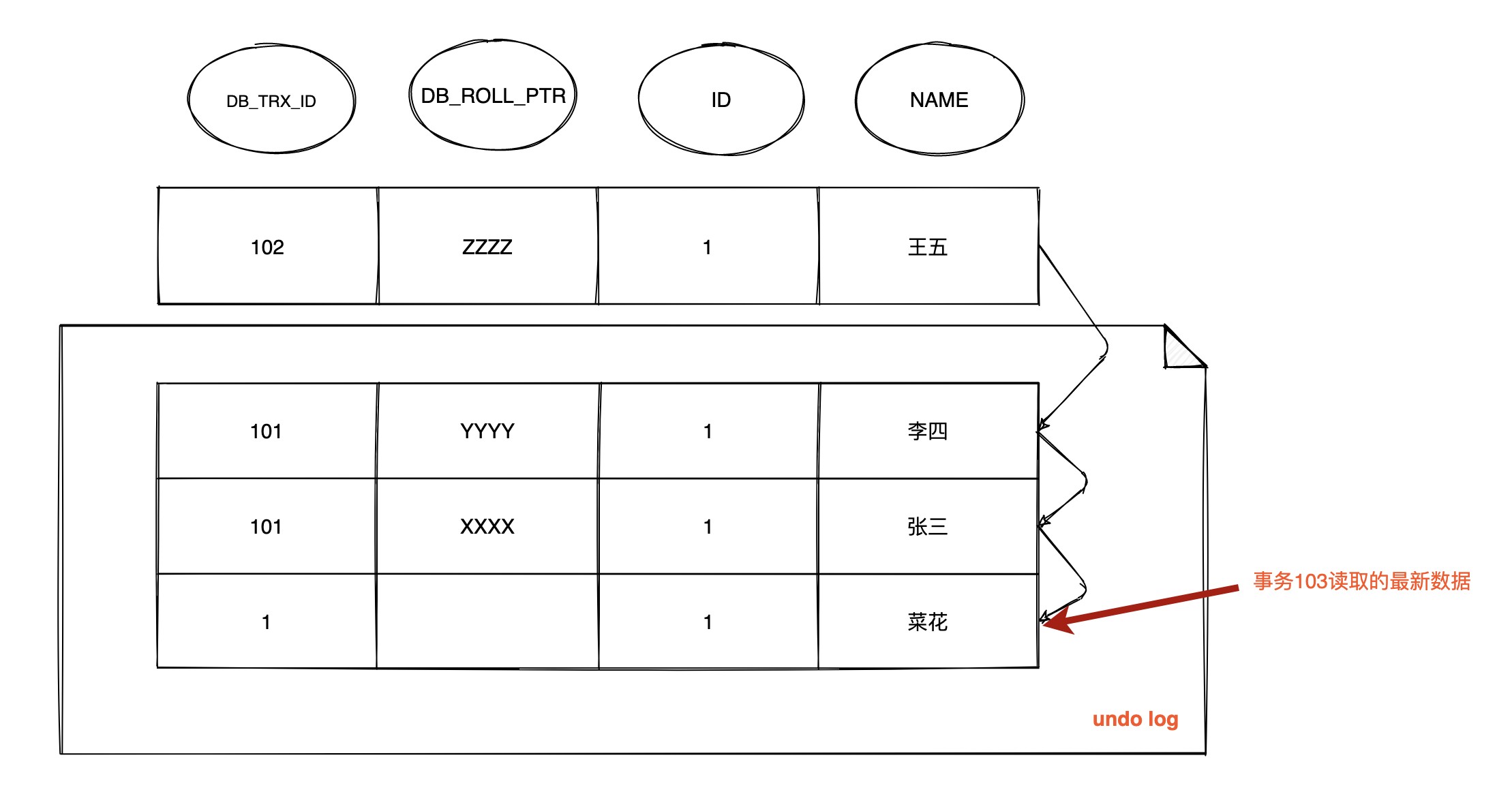 |
| 227 | + |
| 228 | + 在 RR 级别下只会生成一次`Read View`,所以此时依然沿用 **`m_ids` :[101,102]** ,`m_low_limit_id`为:104,`m_up_limit_id`为:101,`m_creator_trx_id` 为:103 |
| 229 | + |
| 230 | + |
| 231 | + - 最新记录的 `DB_TRX_ID` 为102,m_up_limit_id <= 102 < m_low_limit_id,所以要在 `m_ids` 列表中查找,发现 `DB_TRX_ID` 存在列表中,那么这个记录不可见 |
| 232 | + |
| 233 | + - 根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 为101,不可见 |
| 234 | + |
| 235 | + - 继续根据 `DB_ROLL_PTR` 找到 `undo log` 中的上一版本记录,上一条记录的 `DB_TRX_ID` 还是101,不可见 |
| 236 | + |
| 237 | + - 继续找上一条 `DB_TRX_ID`为1,满足 1 < m_up_limit_id,可见,所以事务103查询到数据为 `name = 菜花` |
| 238 | + |
| 239 | + |
| 240 | + |
| 241 | +3. **时间点 T9 情况下:** |
| 242 | + |
| 243 | +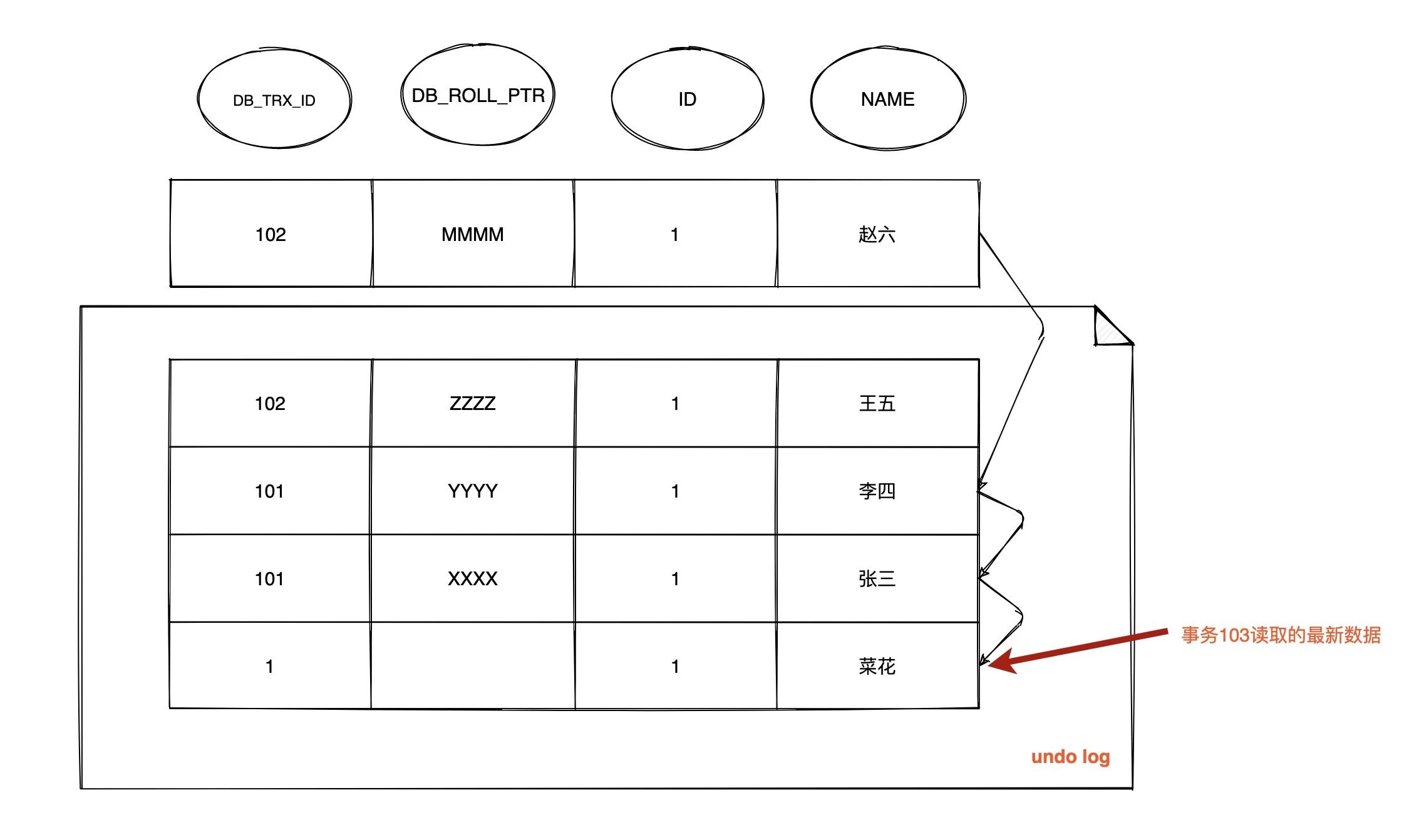 |
| 244 | + |
| 245 | + |
| 246 | + |
| 247 | +此时情况跟 T6 完全一样,由于已经生成了 `Read View`,此时依然沿用 **`m_ids` :[101,102]** ,所以查询结果依然是 `name = 菜花` |
| 248 | + |
| 249 | + |
| 250 | + |
| 251 | +## MVCC➕Next-key-Lock防止幻读 |
| 252 | + |
| 253 | +`InnoDB`存储引擎在 RR 级别下通过 `MVCC`和 `Next-key Lock` 来解决幻读问题: |
| 254 | + |
| 255 | +1. **执行普通 `select`,此时会以 `MVCC` 快照读的方式读取数据** |
| 256 | + |
| 257 | +在快照读的情况下,RR 隔离级别只会在事务开启后的第一次查询生成 `Read View` ,并使用至事务提交。所以在生成 `Read View` 之后其它事务所做的更新、插入记录版本对当前事务并不可见,实现了可重复读和防止快照读下的 “幻读” |
| 258 | + |
| 259 | +2. **执行select...for update/lock in share mode、insert、update、delete等当前读** |
| 260 | + |
| 261 | +在当前读下,读取的都是最新的数据,如果其它事务有插入新的记录,并且刚好在当前事务查询范围内,就会产生幻读!`InnoDB` 使用 [Next-key Lock](https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-next-key-locks) 来防止这种情况。当执行当前读时,会锁定读取到的记录的同时,锁定它们的间隙,防止其它事务在查询范围内插入数据。只要我不让你插入,就不会发生幻读 |
| 262 | + |
| 263 | + |
| 264 | + |
| 265 | +## 参考 |
| 266 | + |
| 267 | +- **《MySQL技术内幕InnoDB存储引擎第2版》** |
| 268 | + |
| 269 | +- [Innodb中的事务隔离级别和锁的关系](https://tech.meituan.com/2014/08/20/innodb-lock.html) |
| 270 | +- [MySQL事务与MVCC如何实现的隔离级别](https://blog.csdn.net/qq_35190492/article/details/109044141) |
0 commit comments