File tree Expand file tree Collapse file tree 8 files changed +308
-366
lines changed
dataStructures-algorithms/data-structure
system-design/framework/spring Expand file tree Collapse file tree 8 files changed +308
-366
lines changed Original file line number Diff line number Diff line change 7878
7979### 2.4. 数组 vs 链表
8080
81- - 数据支持随机访问 ,而链表不支持。
81+ - 数组支持随机访问 ,而链表不支持。
8282- 数组使用的是连续内存空间对 CPU 的缓存机制友好,链表则相反。
83- - 数据的大小固定 ,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
83+ - 数组的大小固定 ,而链表则天然支持动态扩容。如果声明的数组过小,需要另外申请一个更大的内存空间存放数组元素,然后将原数组拷贝进去,这个操作是比较耗时的!
8484
8585## 3. 栈
8686
Original file line number Diff line number Diff line change @@ -510,7 +510,7 @@ ForkJoinPool.commonPool-worker-9>>2
510510>
511511> 正例:使用 JDK8 的 Optional 类来防止 NPE 问题。
512512
513- 他建议使用 `Optional ` 解决 NPE (`java.lang. NumberFormatException `)问题,它就是为 NPE 而生的,其中可以包含空值或非空值。下面我们通过源码逐步揭开 `Optional ` 的红盖头。
513+ 他建议使用 `Optional ` 解决 NPE (`java.lang. NullPointerException `)问题,它就是为 NPE 而生的,其中可以包含空值或非空值。下面我们通过源码逐步揭开 `Optional ` 的红盖头。
514514
515515假设有一个 `Zoo ` 类,里面有个属性 `Dog `,需求要获取 `Dog ` 的 `age`。
516516
@@ -537,7 +537,7 @@ if(zoo != null){
537537}
538538```
539539
540- 层层判断对象分空 ,有人说这种方式很丑陋不优雅,我并不这么认为。反而觉得很整洁,易读,易懂。你们觉得呢?
540+ 层层判断对象非空 ,有人说这种方式很丑陋不优雅,我并不这么认为。反而觉得很整洁,易读,易懂。你们觉得呢?
541541
542542`Optional ` 是这样的实现的:
543543
Load Diff Large diffs are not rendered by default.
Original file line number Diff line number Diff line change 5151
5252简单来说“Shell编程就是对一堆Linux命令的逻辑化处理”。
5353
54-
5554W3Cschool 上的一篇文章是这样介绍 Shell的,如下图所示。
5655![ 什么是 Shell?] ( https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/18-11-26/19456505.jpg )
5756
@@ -91,7 +90,7 @@ shell中 # 符号表示注释。**shell 的第一行比较特殊,一般都会
9190** Shell编程中一般分为三种变量:**
9291
93921 . ** 我们自己定义的变量(自定义变量):** 仅在当前 Shell 实例中有效,其他 Shell 启动的程序不能访问局部变量。
94- 2 . ** Linux已定义的环境变量** (环境变量, 例如:$ PATH, $ HOME 等..., 这类变量我们可以直接使用),使用 ` env ` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
93+ 2 . ** Linux已定义的环境变量** (环境变量, 例如:` PATH ` , ` HOME ` 等..., 这类变量我们可以直接使用),使用 ` env ` 命令可以查看所有的环境变量,而set命令既可以查看环境变量也可以查看自定义变量。
95943 . ** Shell变量** :Shell变量是由 Shell 程序设置的特殊变量。Shell 变量中有一部分是环境变量,有一部分是局部变量,这些变量保证了 Shell 的正常运行
9695
9796** 常用的环境变量:**
@@ -347,7 +346,6 @@ echo $a;
347346简单示例:
348347
349348``` shell
350-
351349#! /bin/bash
352350a=" abc" ;
353351b=" efg" ;
@@ -530,8 +528,6 @@ echo "输入的两个数字之和为 $?"
530528
531529### 带参数的函数
532530
533-
534-
535531``` shell
536532#! /bin/bash
537533funWithParam (){
@@ -544,7 +540,6 @@ funWithParam(){
544540 echo " 作为一个字符串输出所有参数 $* !"
545541}
546542funWithParam 1 2 3 4 5 6 7 8 9 34 73
547-
548543```
549544
550545输出结果:
@@ -557,5 +552,4 @@ funWithParam 1 2 3 4 5 6 7 8 9 34 73
557552第十一个参数为 73 !
558553参数总数有 11 个!
559554作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !
560-
561555```
Original file line number Diff line number Diff line change 88
99开始本文的内容之前,我们先聊聊为什么要学习操作系统。
1010
11- - **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存可以看作外存的高速缓存 ,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
11+ - **从对个人能力方面提升来说** :操作系统中的很多思想、很多经典的算法,你都可以在我们日常开发使用的各种工具或者框架中找到它们的影子。比如说我们开发的系统使用的缓存(比如 Redis)和操作系统的高速缓存就很像。CPU 中的高速缓存有很多种,不过大部分都是为了解决 CPU 处理速度和内存处理速度不对等的问题。我们还可以把内存看作外存的高速缓存 ,程序运行的时候我们把外存的数据复制到内存,由于内存的处理速度远远高于外存,这样提高了处理速度。同样地,我们使用的 Redis 缓存就是为了解决程序处理速度和访问常规关系型数据库速度不对等的问题。高速缓存一般会按照局部性原理(2-8 原则)根据相应的淘汰算法保证缓存中的数据是经常会被访问的。我们平常使用的 Redis 缓存很多时候也会按照 2-8 原则去做,很多淘汰算法都和操作系统中的类似。既说了 2-8 原则,那就不得不提命中率了,这是所有缓存概念都通用的。简单来说也就是你要访问的数据有多少能直接在缓存中直接找到。命中率高的话,一般表明你的缓存设计比较合理,系统处理速度也相对较快。
1212- ** 从面试角度来说** :尤其是校招,对于操作系统方面知识的考察是非常非常多的。
1313
1414** 简单来说,学习操作系统能够提高自己思考的深度以及对技术的理解力,并且,操作系统方面的知识也是面试必备。**
Original file line number Diff line number Diff line change @@ -163,7 +163,7 @@ _玩玩电脑游戏还是必须要有 Windows 的,所以我现在是一台 Win
163163
164164- ** 类 Unix 系统** : Linux 是一种自由、开放源码的类似 Unix 的操作系统
165165- ** Linux 本质是指 Linux 内核** : 严格来讲,Linux 这个词本身只表示 Linux 内核,单独的 Linux 内核并不能成为一个可以正常工作的操作系统。所以,就有了各种 Linux 发行版。
166- - ** Linux 之父** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 ** Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
166+ - ** Linux 之父(林纳斯·本纳第克特·托瓦兹 Linus Benedict Torvalds) ** : 一个编程领域的传奇式人物,真大佬!我辈崇拜敬仰之楷模。他是 ** Linux 内核** 的最早作者,随后发起了这个开源项目,担任 Linux 内核的首要架构师。他还发起了 Git 这个开源项目,并为主要的开发者。
167167
168168![ Linux] ( images/Linux之父.png )
169169
@@ -303,7 +303,7 @@ Linux 中的打包文件一般是以.tar 结尾的,压缩的命令一般是以
303303
304304** 2)解压压缩包:**
305305
306- 命令:`tar [ -xvf] 压缩文件``
306+ 命令:` tar [-xvf] 压缩文件 `
307307
308308其中:x:代表解压
309309
Original file line number Diff line number Diff line change @@ -409,6 +409,8 @@ class WebSite {
409409
410410SpringBoot 项目的 spring-boot-starter-web 依赖中已经有 hibernate-validator 包,不需要引用相关依赖。如下图所示(通过 idea 插件—Maven Helper 生成):
411411
412+ **注**:更新版本的 spring-boot-starter-web 依赖中不再有 hibernate-validator 包(如2.3.11.RELEASE),需要自己引入 `spring-boot-starter-validation` 依赖。
413+
412414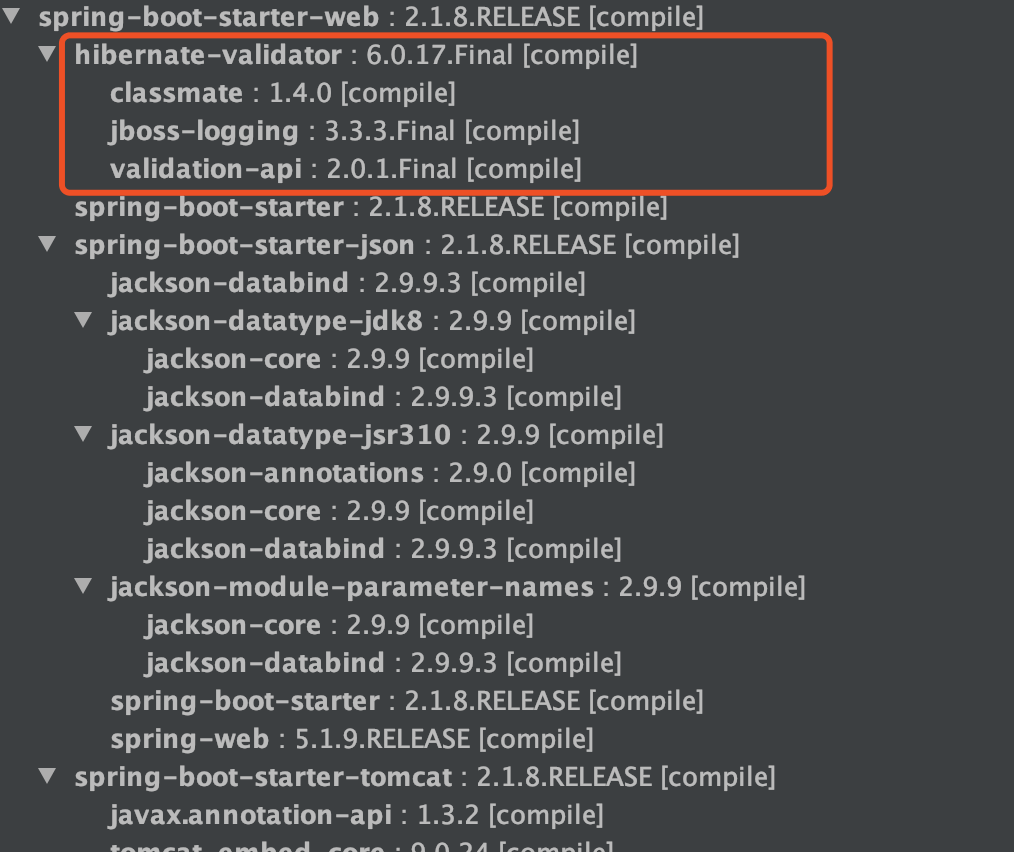
413415
414416非 SpringBoot 项目需要自行引入相关依赖包,这里不多做讲解,具体可以查看我的这篇文章:《[如何在 Spring/Spring Boot 中做参数校验?你需要了解的都在这里!](https://mp.weixin.qq.com/s?__biz=Mzg2OTA0Njk0OA==&mid=2247485783&idx=1&sn=a407f3b75efa17c643407daa7fb2acd6&chksm=cea2469cf9d5cf8afbcd0a8a1c9cc4294d6805b8e01bee6f76bb2884c5bc15478e91459def49&token=292197051&lang=zh_CN#rd)》。
Original file line number Diff line number Diff line change @@ -83,11 +83,11 @@ IoC源码阅读
8383
8484AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无关,** 却为业务模块所共同调用的逻辑或责任(例如事务处理、日志管理、权限控制等)封装起来** ,便于** 减少系统的重复代码** ,** 降低模块间的耦合度** ,并** 有利于未来的可拓展性和可维护性** 。
8585
86- ** Spring AOP就是基于动态代理的** ,如果要代理的对象,实现了某个接口,那么Spring AOP会使用** JDK Proxy** ,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用** Cglib** ,这时候Spring AOP会使用 ** Cglib ** 生成一个被代理对象的子类来作为代理,如下图所示:
86+ ** Spring AOP就是基于动态代理的** ,如果要代理的对象,实现了某个接口,那么Spring AOP会使用** JDK Proxy** ,去创建代理对象,而对于没有实现接口的对象,就无法使用 JDK Proxy 去进行代理了,这时候Spring AOP会使用** Cglib** 生成一个被代理对象的子类来作为代理,如下图所示:
8787
8888![ SpringAOPProcess] ( https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-6/SpringAOPProcess.jpg )
8989
90- 当然你也可以使用 AspectJ , Spring AOP 已经集成了AspectJ ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
90+ 当然你也可以使用 AspectJ, Spring AOP 已经集成了AspectJ,AspectJ 应该算的上是 Java 生态系统中最完整的 AOP 框架了。
9191
9292使用 AOP 之后我们可以把一些通用功能抽象出来,在需要用到的地方直接使用即可,这样大大简化了代码量。我们需要增加新功能时也方便,这样也提高了系统扩展性。日志功能、事务管理等等场景都用到了 AOP 。
9393
@@ -117,7 +117,7 @@ AOP(Aspect-Oriented Programming:面向切面编程)能够将那些与业务无
117117
118118常见的有 2 种解决办法:
119119
120- 2 . 在类中定义一个 ` ThreadLocal ` 成员变量,将需要的可变成员变量保存在 ` ThreadLocal ` 中(推荐的一种方式)。
120+ 1 . 在类中定义一个 ` ThreadLocal ` 成员变量,将需要的可变成员变量保存在 ` ThreadLocal ` 中(推荐的一种方式)。
1211212 . 改变 Bean 的作用域为 “prototype”:每次请求都会创建一个新的 bean 实例,自然不会存在线程安全问题。
122122
123123
You can’t perform that action at this time.
0 commit comments