diff --git a/.gitattributes b/.gitattributes
new file mode 100644
index 0000000..9ff5125
--- /dev/null
+++ b/.gitattributes
@@ -0,0 +1 @@
+*.md linguist-language=php
diff --git a/Cache/Redis.md b/Cache/Redis.md
index b43dba6..54cfc97 100644
--- a/Cache/Redis.md
+++ b/Cache/Redis.md
@@ -39,3 +39,10 @@ redis是一个开源的支持多种数据类型的key=>value的存储数据库
> hset、hget、hmget、hmset、hkeys、hlen、hsetnx、hvals
+### redis 各种类型的场景使用
+
+- string 就是存储简单的key=>value的字符串
+- list 使用场景。做先进先出的消费队列
+- set 进行集合过滤重复元素
+- zset 有序集合,排行榜 TOP N
+- hash 适合存储一组数据,比如用户的信息 以用户id为键,里面记录用户的昵称等信息。
\ No newline at end of file
diff --git "a/Linux/AWK\347\273\203\344\271\240.md" b/Linux/AWK.md
similarity index 96%
rename from "Linux/AWK\347\273\203\344\271\240.md"
rename to Linux/AWK.md
index 06aaa83..c920209 100644
--- "a/Linux/AWK\347\273\203\344\271\240.md"
+++ b/Linux/AWK.md
@@ -100,13 +100,13 @@ awk '/^UUID/{fs[$3]++}END{for(i in fs){print i,fs[i]}}' /etc/fstab
- 统计日志最多的10个IP
```shell
-awk '{arr[$1]++} END {for(i in arr) {print arr[i]}}' access.log | sort -k1 -nr | head -n10
+awk '{arr[$1]++} END {for(i in arr) {print i}}' access.log | sort -k1 -nr | head -n10
```
- 统计日志访问次数大于100次的IP
```shell
-awk '{arr[$1]++} END{for (i in arr) {if(arr[i] > 100){print $i}}}' access.log
+awk '{arr[$1]++} END{for (i in arr) {if(arr[i] > 100){print i}}}' access.log
```
- 统计2016年4月9日内访问最多的10个ip
diff --git "a/Linux/LinuxIO\346\250\241\345\236\213.md" "b/Linux/LinuxIO\346\250\241\345\236\213.md"
index 78ca37f..fd585c1 100644
--- "a/Linux/LinuxIO\346\250\241\345\236\213.md"
+++ "b/Linux/LinuxIO\346\250\241\345\236\213.md"
@@ -6,7 +6,7 @@
### 2. 进程切换
-为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的
+为了控制进程的执行,内核必须有能力挂起正在CPU上运行的进程,并恢复以前挂起的某个进程的执行。这种行为被称为进程切换。因此可以说,任何进程都是在操作系统内核的支持下运行的,是与内核紧密相关的
从一个进程的运行转到另一个进程上运行,这个过程中经过下面这些变化:
@@ -17,23 +17,23 @@
> 5. 更新内存管理的数据结构。
> 6. 恢复处理机上下文。
-
+
### 3. 进程的阻塞
-> 正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。`当进程进入阻塞状态,是不占用CPU资源的`。
+> 正在执行的进程,由于期待的某些事件未发生,如请求系统资源失败、等待某种操作的完成、新数据尚未到达或无新工作做等,则由系统自动执行阻塞原语(Block),使自己由运行状态变为阻塞状态。可见,进程的阻塞是进程自身的一种主动行为,也因此只有处于运行态的进程(获得CPU),才可能将其转为阻塞状态。`当进程进入阻塞状态,是不占用CPU资源的`。
### 4. 进程缓存区、内核缓冲区
缓冲区的出现是为了减少频繁的系统调用,由于系统调用需要保存之前的进程数据和状态等信息,而结束调用之后回来还需要回复之前的信息,为了减少这种耗时耗性能的调用于是出现了缓冲区。在linux系统中,每个进程有自己独立的缓冲区,叫做**进程缓冲区**,而系统内核也有个缓冲区叫做**内核缓冲区**。
- **操作系统使用read函数把数据从内核缓冲区复制到进程缓冲区,write把数据从进程缓冲区 复制到内核缓冲区中**
+ **操作系统使用read函数把数据从内核缓冲区复制到进程缓冲区,write把数据从进程缓冲区复制到内核缓冲区中**
### 5. 文件描述符fd
文件描述符(File descriptor)是计算机科学中的一个术语,`是一个用于表述指向文件的引用的抽象化概念`。 文件描述符在形式上是一个非负整数。实际上,`它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表`。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,一些涉及底层的程序编写往往会围绕着文件描述符展开
-## Linx/Unix 5种IO模型
+## Linx/Unix 5种IO模型
当一个io发生时候的,涉及到的步骤和对象
@@ -46,12 +46,12 @@
经历的步骤
-- 等待数据准备,比如accept(), recv()等待数据
-- 将数据从内核拷贝到进程中, 比如 accept()接受到请求,recv()接收连接发送的数据后需要复制到内核,再从内核复制到进程**用户空间**
+- 等待数据准备,比如accept(), recv()等待数据
+- 将数据从内核拷贝到进程中, 比如 accept()接受到请求,recv()接收连接发送的数据后需要复制到内核,再从内核复制到进程**用户空间**
### 阻塞IO
-
+
> 当用户进程调用了recvfrom这个系统调用,kernel就开始了IO的第一个阶段:准备数据(对于网络IO来说,很多时候数据在一开始还没有到达。比如,还没有收到一个完整的UDP包。这个时候kernel就要等待足够的数据到来)。这个过程需要等待,也就是说数据被拷贝到**操作系统内核的缓冲区**中是需要一个过程的。而在用户进程这边,整个进程会被阻塞(当然,是进程自己选择的阻塞)。当kernel一直等到数据准备好了,它就会**将数据从kernel中拷贝到用户内存**,然后kernel返回结果,用户进程才解除block的状态,重新运行起来。
@@ -59,7 +59,7 @@
### 非阻塞IO
-
+
当用户进程发出read操作时,如果kernel中的数据还没有准备好,**那么它并不会block用户进程,而是立刻返回一个error**。从用户进程角度讲 ,它发起一个read操作后,并不需要等待,而是马上就得到了一个结果。用户进程判断结果是一个error时,它就知道数据还没有准备好,于是它可以再次发送read操作。一旦kernel中的数据准备好了,并且又再次收到了用户进程的system call,那么它马上就将数据拷贝到了用户内存,然后返回
@@ -67,27 +67,27 @@
IO multiplexing就是我们说的select,poll,epoll,有些地方也称这种IO方式为event driven IO。select/epoll的好处就在于单个process就可以同时处理多个网络连接的IO。它的基本原理就是select,poll,epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
-
+
-在一个调用中阻塞`select`,等待数据报套接字可读。当`select` 返回套接字可读时,我们然后调用`recvfrom` 将数据报复制到我们的应用程序缓冲区中 .使用`select`需要两次系统调用而不是一次
+在一个调用中阻塞`select`,等待数据报套接字可读。当`select` 返回套接字可读时,我们然后调用`recvfrom` 将数据报复制到我们的应用程序缓冲区中 .使用`select`需要两次系统调用而不是一次
在IO multiplexing Model中,实际中,**对于每一个socket,一般都设置成为non-blocking,因为只有设置成non-blocking 才能使单个线程/进程不被阻塞(或者说锁住),可以继续处理其他socket。如上图所示,整个用户的process其实是一直被block的。只不过process是被select这个函数block,而不是被socket IO给block。**
### 异步 I/O
-
+
用户进程发起read操作之后,立刻就可以开始去做其它的事。而另一方面,从kernel的角度,当它受到一个asynchronous read之后,首先它会立刻返回,所以不会对用户进程产生任何block。然后,kernel会等待数据准备完成,然后将数据拷贝到用户内存,当这一切都完成之后,kernel会给用户进程发送一个signal,告诉它read操作完成了
### 异步、同步、阻塞、非阻塞
-同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列
+同步就是一个任务的完成需要依赖另外一个任务时,只有等待被依赖的任务完成后,依赖的任务才能算完成,这是一种可靠的任务序列
-异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了
+异步是不需要等待被依赖的任务完成,只是通知被依赖的任务要完成什么工作,依赖的任务也立即执行,只要自己完成了整个任务就算完成了
-阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务
+阻塞调用是指调用结果返回之前,当前线程会被挂起,一直处于等待消息通知,不能够执行其他业务
-非阻塞调用指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回
+非阻塞调用指在不能立刻得到结果之前,该函数不会阻塞当前线程,而会立刻返回
异步、同步是发生在用户空间内,当用户发起一个IO的调用的时候,同步的时候,如果这个操作比较耗时间,会阻塞后面的流程
@@ -109,7 +109,7 @@ aysnc_read("http://www.qq.com/",function($data){
这个aysnc_read 是一个异步读的操作,当读的时候,底下的操作不会阻塞住,会先输出end。当数据到达的时候,再echo $data;
-阻塞、非阻塞、发送在内核和用户空间之间。阻塞是指操作系统会挂起进程,直到数据准备好,非阻塞、操作系统不阻塞,当前进程可以继续执行。
+阻塞、非阻塞、发生在内核和用户空间之间。阻塞是指操作系统会挂起进程,直到数据准备好,非阻塞、操作系统不阻塞,当前进程可以继续执行。
举例说明
@@ -119,8 +119,8 @@ aysnc_read("http://www.qq.com/",function($data){
- 非阻塞IO
-还是张三去买书,老板去查询。这是时候,张三可以玩手机,然后隔段时间问,找到了没有,张三的进程没有被阻塞。但是这个任务是同步的,必须等待这个结果。就是老板没有告诉张三结果,张三是不能离开干其他的事。这个过程是同步非阻塞的。
+还是张三去买书,老板去查询。这是时候,张三可以玩手机,然后隔段时间问,张三问:"找到了没有",张三的进程没有被阻塞。但是这个任务是同步的,必须等待这个结果。就是老板没有告诉张三结果,张三是不能离开干其他的事。这个过程是同步非阻塞的。
- 异步IO
-张三去买书。然后去书店问老板有没有了。老板需要查询,张三告诉老板自己的手机号,找到了打电话给我,然后就去干其他的事了。这个过程是异步的。张三的进程没有被阻塞在这个买书的环节上。这就是异步非阻塞。
\ No newline at end of file
+张三去买书。然后去书店问老板有没有了。老板需要查询,张三告诉老板自己的手机号,找到了打电话给我,然后就去干其他的事了。这个过程是异步的。张三的进程没有被阻塞在这个买书的环节上。这就是异步非阻塞。
diff --git "a/Linux/Linux\345\221\275\344\273\244.md" "b/Linux/Linux\345\221\275\344\273\244.md"
index e26973b..7dfbd32 100644
--- "a/Linux/Linux\345\221\275\344\273\244.md"
+++ "b/Linux/Linux\345\221\275\344\273\244.md"
@@ -47,6 +47,7 @@ cat a.text| less
```shell
ls /proc && echo suss! || echo failed.
+cat access.log >> test.log
```
## 文本处理
@@ -134,7 +135,7 @@ sed '/^$/d' file #删除空白行
详细教程可以查看 http://awk.readthedocs.io/en/latest/chapter-one.html
```shell
-awk ' BEGIN{ statements } statements2 END{ statements } '
+awk ' BEGIN{ statements } statements2 END{ statements } '
```
工作流程
@@ -161,11 +162,11 @@ $2:第二个字段的文本内容;
awk '{print $2, $3}' file
# 日志格式:'$remote_addr - $remote_user [$time_local] "$request" $status $body_bytes_sent "$http_referer" "$http_user_agent" "$http_x_forwarded_for"'
#统计日志中访问最多的10个IP
-awk '{a[$1]++}END{for(i in a)print a[i],i|"sort -k1 -nr|head -n10"}' access.log
+awk '{a[$1]++}END{for(i in a)print a[i],i|"sort -k1 -nr|head -n10"}' access.log
```
-### 排序 port
+### 排序 sort
- -n 按数字进行排序 VS -d 按字典序进行排序
- -r 逆序排序
diff --git "a/Linux/Linux\345\221\275\344\273\2442.md" "b/Linux/Linux\345\221\275\344\273\2442.md"
index b9f99fd..0b05ed1 100644
--- "a/Linux/Linux\345\221\275\344\273\2442.md"
+++ "b/Linux/Linux\345\221\275\344\273\2442.md"
@@ -2,13 +2,13 @@
查看磁盘空间利用大小
-```
+```shell
df -h
```
查看当前目录所占空间大小
-```
+```shell
du -sh
```
@@ -59,21 +59,21 @@ netstat 命令用于显示各种网络相关信息,如网络连接,路由表
列出所有端口 (包括监听和未监听的):
-```
+```shell
netstat -a
```
列出所有 tcp 端口:
-```
+```shell
netstat -at
```
列出所有有监听的服务状态:
-```
+```shell
netstat -l
```
@@ -82,7 +82,7 @@ netstat -l
缺省时free的单位为KB
```shell
-$free
+$ free
total used free shared buffers cached
Mem: 8175320 6159248 2016072 0 310208 5243680
-/+ buffers/cache: 605360 7569960
diff --git a/Linux/Nginx.md b/Linux/Nginx.md
new file mode 100644
index 0000000..fac991c
--- /dev/null
+++ b/Linux/Nginx.md
@@ -0,0 +1,269 @@
+## nginx
+Nginx是一款轻量级的Web 服务器/反向代理服务器及电子邮件(IMAP/POP3)代理服务器,在BSD-like 协议下发行。其特点是占有内存少,并发能力强,已经渐渐取代老牌Apache 作为新的web服务器使用。
+### 安装
+
+依赖环境介绍
+
+- gcc gcc-c++
+
+> gcc为GNU Compiler Collection的缩写,可以编译C和C++源代码等,它是GNU开发的C和C++以及其他很多种语言 的编译器(最早的时候只能编译C,后来很快进化成一个编译多种语言的集合,如Fortran、Pascal、Objective-C、Java、Ada、 Go等。)
+gcc 在编译C++源代码的阶段,只能编译 C++ 源文件,而不能自动和 C++ 程序使用的库链接(编译过程分为编译、链接两个阶段,注意不要和可执行文件这个概念搞混,相对可执行文件来说有三个重要的概念:编译(compile)、链接(link)、加载(load)。源程序文件被编译成目标文件,多个目标文件连同库被链接成一个最终的可执行文件,可执行文件被加载到内存中运行)。因此,通常使用 g++ 命令来完成 C++ 程序的编译和连接,该程序会自动调用 gcc 实现编译。
+gcc-c++也能编译C源代码,只不过把会把它当成C++源代码,后缀为.c的,gcc把它当作是C程序,而g++当作是c++程序;后缀为.cpp的,两者都会认为是c++程序,注意,虽然c++是c的超集,但是两者对语法的要求是有区别的。
+- make automake
+
+> make是一个用来控制可执行文件和其他一些从源文件来的非源代码文件版本的软件。Make可以从一个名为makefile的文件中获得如何构建你所写程序的依赖关系,Makefile中列出了每个目标文件以及如何由其他文件来生成它。
+`automake`是一个从`Makefile.am`文件自动生成`Makefile.in`的工具。为了生成`Makefile.in`,automake还需用到perl,由于`automake`创建的发布完全遵循GNU标准,所以在创建中不需要`perl`。libtool是一款方便生成各种程序库的工具。
+
+- autoconf
+
+> autoconf是用来生成自动配置软件源代码脚本(configure)的工具
+
+- pcre pcre-devel
+
+> 在Nginx编译需要 PCRE(Perl Compatible Regular Expression),因为Nginx 的Rewrite模块和HTTP 核心模块会使用到PCRE正则表达式语法。
+
+- zlip zlib-devel
+
+> nginx启用压缩功能的时候,需要此模块的支持。
+- openssl openssl-devel
+
+> 开启SSL的时候需要此模块的支持。
+- libtool
+
+> libtool是一个通用库支持脚本,将使用动态库的复杂性隐藏在统一、可移植的接口中;使用libtool的标准方法,可以在不同平台上创建并调用动态库。
+libtool主要的一个作用是在编译大型软件的过程中解决了库的依赖问题;将繁重的库依赖关系的维护工作承担下来,从而释放了程序员的人力资源。libtool提供统一的接口,隐藏了不同平台间库的名称的差异等细节,生成一个抽象的后缀名为la高层库`libxx.la`(其实是个文本文件),并将该库对其它库的依赖关系,都写在该la的文件中。
+
+```shell
+
+$ sudo yum -y install gcc gcc-c++ make automake autoconf pcre pcre-devel zlib zlib-devel openssl openssl-devel libtool
+$ wget http://nginx.org/download/nginx-1.14.0.tar.gz
+$ tar zxvf nginx-1.14.0.tar.gz
+$ ./configure --prefix=/usr/local/nginx --sbin-path=/usr/local/nginx/sbin/nginx --conf-path=/usr/local/nginx/conf/nginx.conf --error-log-path=/var/log/nginx/error.log --http-log-path=/var/log/nginx/access.log --pid-path=/var/run/nginx/nginx.pid --lock-path=/var/lock/nginx.lock --user=nginx --group=nginx --with-http_ssl_module --with-http_stub_status_module --with-http_gzip_static_module --http-client-body-temp-path=/var/tmp/nginx/client/ --http-proxy-temp-path=/var/tmp/nginx/proxy/ --http-fastcgi-temp-path=/var/tmp/nginx/fcgi/ --http-uwsgi-temp-path=/var/tmp/nginx/uwsgi --http-scgi-temp-path=/var/tmp/nginx/scgi --with-pcre
+$ make && make install
+```
+
+### nginx 配置
+
+nginx的关于web服务器的配置,在http项中.每个server 对应一个主机
+
+```
+http {
+ server {}
+ server{}
+}
+```
+
+
+```
+user www-data;
+pid /run/nginx.pid;
+worker_processes auto;
+worker_rlimit_nofile 65535;
+
+events {
+ multi_accept on;
+ worker_connections 65535;
+}
+
+http {
+ charset utf-8;
+ sendfile on;
+ tcp_nopush on;
+ tcp_nodelay on;
+ server_tokens off;
+ log_not_found off;
+ types_hash_max_size 2048;
+ client_max_body_size 16M;
+
+ # MIME
+ include mime.types;
+ default_type application/octet-stream;
+
+ # logging
+ access_log /var/log/nginx/access.log;
+ error_log /var/log/nginx/error.log warn;
+
+ # SSL
+ ssl_session_timeout 1d;
+ ssl_session_cache shared:SSL:10m;
+ ssl_session_tickets off;
+
+ # Diffie-Hellman parameter for DHE ciphersuites
+ ssl_dhparam /etc/nginx/dhparam.pem;
+
+ # Mozilla Intermediate configuration
+ ssl_protocols TLSv1.2 TLSv1.3;
+ ssl_ciphers ECDHE-ECDSA-AES128-GCM-SHA256:ECDHE-RSA-AES128-GCM-SHA256:ECDHE-ECDSA-AES256-GCM-SHA384:ECDHE-RSA-AES256-GCM-SHA384:ECDHE-ECDSA-CHACHA20-POLY1305:ECDHE-RSA-CHACHA20-POLY1305:DHE-RSA-AES128-GCM-SHA256:DHE-RSA-AES256-GCM-SHA384;
+
+ # OCSP Stapling
+ ssl_stapling on;
+ ssl_stapling_verify on;
+ resolver 1.1.1.1 1.0.0.1 8.8.8.8 8.8.4.4 208.67.222.222 208.67.220.220 valid=60s;
+ resolver_timeout 2s;
+ #负载均衡
+ upstream backend{
+ server 127.0.0.1:8050 weight=1 max_fails=2 fail_timeout=10 ;
+ server 127.0.0.1:8060 weight=2 max_fails=2 fail_timeout=10 ;
+ }
+
+
+ # gzip
+ gzip on;
+ gzip_vary on;
+ gzip_proxied any;
+ gzip_comp_level 6;
+ gzip_types text/plain text/css text/xml application/json application/javascript application/rss+xml application/atom+xml image/svg+xml;
+ # HTTP 301 重定向
+ server {
+ listen 80;
+ listen [::]:80;
+ server_name .example.com;
+ location / {
+ return 301 https://www.example.com$request_uri;
+ }
+ }
+
+ server {
+ listen 80;#监听端口
+ server_name example.com;#绑定域名
+ root /var/www/example.com/public;#网站根目录
+ access_log /var/log/nginx/access.log;
+ error_log /var/log/nginx/error.log warn;
+
+ # index.html fallback
+ location / {
+ try_files $uri $uri/ /index.html;
+ }
+ # favicon.ico
+ location = /favicon.ico {
+ log_not_found off;
+ access_log off;
+ }
+
+ # robots.txt
+ location = /robots.txt {
+ log_not_found off;
+ access_log off;
+ }
+
+ # assets, media
+ location ~* \.(?:css(\.map)?|js(\.map)?|jpe?g|png|gif|ico|cur|heic|webp|tiff?|mp3|m4a|aac|ogg|midi?|wav|mp4|mov|webm|mpe?g|avi|ogv|flv|wmv)$ {
+ expires 7d;
+ access_log off;
+ }
+
+ # svg, fonts
+ location ~* \.(?:svgz?|ttf|ttc|otf|eot|woff2?)$ {
+ add_header Access-Control-Allow-Origin "*";
+ expires 7d;
+ access_log off;
+ }
+ # php配置
+ location ~ \.php$ {
+ include fastcgi_params;
+ # fastcgi settings
+ # fastcgi_pass 127.0.0.1:9000
+ fastcgi_pass unix:/var/run/php/php7.2-fpm.sock;
+ fastcgi_index index.php;
+ fastcgi_buffers 8 16k;
+ fastcgi_buffer_size 32k;
+ # fastcgi params
+ fastcgi_param DOCUMENT_ROOT $realpath_root;
+ fastcgi_param SCRIPT_FILENAME $realpath_root$fastcgi_script_name;
+ fastcgi_param PHP_ADMIN_VALUE "open_basedir=$base/:/usr/lib/php/:/tmp/";
+ }
+ #反向代理
+ location ^~/api/ {
+ proxy_pass http://127.0.0.1:3000;
+ proxy_http_version 1.1;
+ proxy_cache_bypass $http_upgrade;
+ proxy_set_header Upgrade $http_upgrade;
+ proxy_set_header Connection "upgrade";
+ proxy_set_header Host $host;
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
+ proxy_set_header X-Forwarded-Proto $scheme;
+ proxy_set_header X-Forwarded-Host $host;
+ proxy_set_header X-Forwarded-Port $server_port;
+ }
+ # 负载
+ location ^~/user/ {
+ proxy_set_header X-Real-IP $remote_addr;
+ proxy_pass http://backend
+ }
+ }
+
+}
+```
+
+### nginx 负载均衡的方式
+
+- 权重
+```
+upstream backend{
+ server 10.0.0.77 weight=5;
+ server 10.0.0.88 weight=10;
+}
+```
+- ip_hash
+
+根据客户端的ip的hash结果进行分配。这样每一个访客的固定访问的服务器都是一台机器
+```
+upstream backend{
+ server 10.0.0.77;
+ server 10.0.0.88;
+}
+```
+- fair 第三方
+
+按后端服务器的响应时间来分配请求。响应时间短的优先分配。
+
+```
+ upstream backend{
+ server 10.0.0.10:8080;
+ server 10.0.0.11:8080;
+ fair;
+}
+```
+- url_hash
+按訪问url的hash结果来分配请求,使每一个url定向到同一个后端服务器。后端服务器为缓存时比較有效。
+
+```
+ upstream backend{
+ server 10.0.0.10:7777;
+ server 10.0.0.11:8888;
+ hash $request_uri;
+ hash_method crc32;
+}
+
+upstream bakend{
+ #定义负载均衡设备的Ip及设备状态
+ ip_hash;
+ server 10.0.0.11:9090 down;
+ server 10.0.0.11:8080 weight=2;
+ server 10.0.0.11:6060;
+ server 10.0.0.11:7070 backup;
+}
+```
+
+upstream还能够为每一个设备设置状态值,这些状态值的含义分别例如以下:
+
+- down 表示单前的server临时不參与负载.
+
+- weight 默觉得1.weight越大,负载的权重就越大。
+
+- max_fails :同意请求失败的次数默觉得1.当超过最大次数时,返回proxy_next_upstream 模块定义的错误.
+
+- fail_timeout : max_fails次失败后。暂停的时间。
+
+- backup: 其他全部的非backup机器down或者忙的时候,请求backup机器。所以这台机器压力会最轻。
+
+### nginx启动 和停止停止
+```shell
+$ /usr/local/nginx/sbin/nginx
+
+#平滑启动
+$ /usr/local/nginx/sbin/nginx -s reload
+#停止
+$ /usr/local/nginx/sbin/nginx -s stop
+```
\ No newline at end of file
diff --git a/Linux/README.md b/Linux/README.md
index 9352660..b06ebf7 100644
--- a/Linux/README.md
+++ b/Linux/README.md
@@ -1,17 +1,3 @@
-## 目录
-
-- [操作系统概述](https://github.com/xianyunyh/PHP-Interview/tree/master/Linux#%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F%E6%A6%82%E8%BF%B0)
-- [Linux历史](https://github.com/xianyunyh/PHP-Interview/tree/master/Linux#gnu%E5%92%8Cgpl)
-- [Linux基本命令](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/Linux%E5%91%BD%E4%BB%A4.md)
-- [Linux(磁盘网络相关命令)](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/Linux%E5%91%BD%E4%BB%A42.md)
-- [Crontab计划任务](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/crontab.md)
-- [shell](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/shell.md)
-- [进程和线程](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/shell.md)
-- [AWK命令](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/AWK%E7%BB%83%E4%B9%A0.md)
-- [SED命令](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/Sed%E7%BB%83%E4%B9%A0.md)
-
-
-
## 操作系统概述
操作系统,英文名称Operating System,简称OS,是计算机系统中必不可少的基础系统软件,它是应用程序运行以及用户操作必备的基础环境支撑,是计算机系统的核心。
@@ -20,7 +6,36 @@

-## Linux和Unix
+### 内核态和用户态
+
+操作系统为了管理内存。将内存分为**内核空间**(内核态)和**用户空间**。内存空间和用户空间之间有隔离。程序需要访问系统资源必须向内核空间进行申请。由内核把数据读取到用户空间。
+
+Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程
+
+应用程序访问内核,一般有两种调用方式:系统调用和库函数调用
+
+**系统调用**:应用程序直接调用操作系统提供的接口 如write 函数
+
+**库函数调用**:应用程序通过一些库函数直接调用 如 fwrite
+
+系统调用(英语:system call),指运行在用户空间的应用程序向操作系统内核请求某些服务的调用过程。 系统调用提供了用户程序与操作系统之间的接口。一般来说,系统调用都在内核态执行。由于系统调用不考虑平台差异性,由内核直接提供,因而移植性较差(几乎无移植性)。
+
+库函数(library function),是由用户或组织自己开发的,具有一定功能的函数集合,一般具有较好平台移植性,通过库文件(静态库或动态库)向程序员提供功能性调用。程序员无需关心平台差异,由库来屏蔽平台差异性。
+
+| 函数库调用 | 系统调用 |
+| ----------------------------- | ----------------------- |
+| 平台移植性好 | 依赖于内核,不保证移植性 |
+| 调用函数库中的一段程序(或函数) | 调用系统内核的服务 |
+| 一个普通功能函数的调用 | 是操作系统的一个入口点 |
+| 在**用户空间**执行 | 在**内核空间**执行 |
+| 它的运行时间属于“用户时间” | 它的运行时间属于“系统”时间 |
+| 属于过程调用,调用开销较小 | 在用户空间和内核上下文环境间切换,开销较大 |
+| 库函数数量较多 | UNIX中大约有90个系统调用,较少 |
+| 典型的C函数库调用:printf scanf malloc | 典型的系统调用:fork open write |
+
+**用户空间即上层应用程序的活动空间**,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用
+
+## Linux和Unix
Unix系统于1969年在AT&T的贝尔实验室诞生,20世纪70年代,它逐步盛行,这期间,又产生了一个比较重要的分支,就是大约1977年诞生的BSD(Berkeley Software Distribution)系统。从BSD系统开始,各大厂商及商业公司开始了根据自身公司的硬件架构,并以BSD系统为基础进行Unix系统的研发,从而产生了各种版本的Unix系统.
diff --git "a/Linux/Sed\347\273\203\344\271\240.md" b/Linux/Sed.md
similarity index 100%
rename from "Linux/Sed\347\273\203\344\271\240.md"
rename to Linux/Sed.md
diff --git a/Linux/Vim.md b/Linux/Vim.md
new file mode 100644
index 0000000..066579a
--- /dev/null
+++ b/Linux/Vim.md
@@ -0,0 +1,96 @@
+## vim
+
+vim是一个类似vi编辑器的。有一个段子:程序员分为三类,一种是用`vim`的 一种是用`emacs` ,剩下的一种是用其他编辑器的。可见vim的流传度。vim的设计理解,是命令的组合。就是完全不用鼠标。通过命令就可以。比如我们在其他编辑器。如果跑到多少行,我们可能需要滚动鼠标。但是vim就在命令行模式下就完成了。先上一个图
+
+
+
+### VIM的模式
+
+vim的模式有三种:分别为命令模式,输入模式、尾行模式
+
+
+
+#### 1. 命令模式
+
+默认用vim打开一个文件的时候,就是进入了命令模式。在这个模式下。可以通过各种命令组合操作文本编辑器
+
+#### 2. 输入模式
+
+输入模式,就是和我们正常的编辑器一样。可以在这个模式下。编辑修改打开文件的内容
+
+在命令模式下。按`i`键。就是输入模式。按`ESC` 退出输入模式,进入到命令模式
+
+#### 3. 尾行模式
+
+在命令模式下`:` 进入尾行。尾行模式下命令也非常多。主要包括文件的查找,保存等
+
+### VIM命令模式下的快捷键
+
+介绍一些常用的快捷键。
+
+上下左右键可能跟我们之前的不一样。一般游戏爱好者的上下左右是wsad。但是在vim就是hjkl。
+
+| 移动光标的方法 | |
+| ------------------------------------------------------------ | ------------------------------------------------------------ |
+| h 或 向左箭头键(←) | 光标向左移动一个字符 |
+| j 或 向下箭头键(↓) | 光标向下移动一个字符 |
+| k 或 向上箭头键(↑) | 光标向上移动一个字符 |
+| l 或 向右箭头键(→) | 光标向右移动一个字符 |
+| 如果你将右手放在键盘上的话,你会发现 hjkl 是排列在一起的,因此可以使用这四个按钮来移动光标。 如果想要进行多次移动的话,例如向下移动 30 行,可以使用 "30j" 或 "30↓" 的组合按键, 亦即加上想要进行的次数(数字)后,按下动作即可! | |
+| [Ctrl] + [f] | 屏幕『向下』移动一页,相当于 [Page Down]按键 (常用) |
+| [Ctrl] + [b] | 屏幕『向上』移动一页,相当于 [Page Up] 按键 (常用) |
+| [Ctrl] + [d] | 屏幕『向下』移动半页 |
+| [Ctrl] + [u] | 屏幕『向上』移动半页 |
+| + | 光标移动到非空格符的下一行 |
+| - | 光标移动到非空格符的上一行 |
+| | |
+| 0 或功能键[Home] | 这是数字『 0 』:移动到这一行的最前面字符处 (常用) |
+| $ 或功能键[End] | 移动到这一行的最后面字符处(常用) |
+| H | 光标移动到这个屏幕的最上方那一行的第一个字符 |
+| M | 光标移动到这个屏幕的中央那一行的第一个字符 |
+| L | 光标移动到这个屏幕的最下方那一行的第一个字符 |
+| G | 移动到这个档案的最后一行(常用) |
+| nG | n 为数字。移动到这个档案的第 n 行。例如 20G 则会移动到这个档案的第 20 行(可配合 :set nu) |
+| gg | 移动到这个档案的第一行,相当于 1G 啊! (常用) |
+| x, X | 在一行字当中,x 为向后删除一个字符 (相当于 [del] 按键), X 为向前删除一个字符(相当于 [backspace] 亦即是退格键) (常用) |
+| -------- | ------------------------------------------------------------ |
+| nx | n 为数字,连续向后删除 n 个字符。举例来说,我要连续删除 10 个字符, 『10x』。 |
+| **dd** | 删除游标所在的那一整行(常用) |
+| **ndd** | n 为数字。删除光标所在的向下 n 行,例如 20dd 则是删除 20 行 (常用) |
+| d1G | 删除光标所在到第一行的所有数据 |
+| dG | 删除光标所在到最后一行的所有数据 |
+| d$ | 删除游标所在处,到该行的最后一个字符 |
+| d0 | 那个是数字的 0 ,删除游标所在处,到该行的最前面一个字符 |
+| **yy** | 复制游标所在的那一行(常用) |
+| **nyy** | n 为数字。复制光标所在的向下 n 行,例如 20yy 则是复制 20 行(常用) |
+| y1G | 复制游标所在行到第一行的所有数据 |
+| yG | 复制游标所在行到最后一行的所有数据 |
+| y0 | 复制光标所在的那个字符到该行行首的所有数据 |
+| y$ | 复制光标所在的那个字符到该行行尾的所有数据 |
+| **p, P** | p 为将已复制的数据在光标下一行贴上,P 则为贴在游标上一行! 举例来说,我目前光标在第 20 行,且已经复制了 10 行数据。则按下 p 后, 那 10 行数据会贴在原本的 20 行之后,亦即由 21 行开始贴。但如果是按下 P 呢? 那么原本的第 20 行会被推到变成 30 行。 (常用) |
+| J | 将光标所在行与下一行的数据结合成同一行 |
+| c | 重复删除多个数据,例如向下删除 10 行,[ 10cj ] |
+| u | 复原前一个动作。(常用) |
+| [Ctrl]+r | 重做上一个动作。(常用) |
+
+### 进入编辑模式的命令
+
+- `i` i 为『从目前光标所在处输入』 insert
+- `I` I 为『在目前所在行的第一个非空格符处开始输入』
+- `a` a 为『从目前光标所在的下一个字符处开始输入』 append
+- A 为『从光标所在行的最后一个字符处开始输入』。(常用)
+- `ESC` 退回到命令模式
+
+
+
+### 尾行模式下的命令
+
+- `:w` 将编辑的数据写入硬盘档案中
+- `:w!`若文件属性为『只读』时,强制写入该档案
+- `:q` 退出文件
+- `:q!` 不保存退出
+- `:wq ` 保存退出
+- `:wq!` 强制保存退出
+
+
+
diff --git a/Linux/crontab.md b/Linux/crontab.md
index b79a303..e0f7273 100644
--- a/Linux/crontab.md
+++ b/Linux/crontab.md
@@ -19,7 +19,7 @@
```shell
* * * * * echo "hello" #每1分钟执行hello
-3,15 * * * * myCommand #每小时第三分钟和第五分钟执行
+3,15 * * * * myCommand #每小时第三分钟和第十五分钟执行
3,15 8-11 * * * myCommand# 在上午8点到11点的第3和第15分钟执行
3,15 8-11 */2 * * myCommand #每隔两天的上午8点到11点的第3和第15分钟执行
30 21 * * * /etc/init.d/smb restart #每晚的21:30重启smb
@@ -34,4 +34,4 @@
```
$service cron restart
-```
\ No newline at end of file
+```
diff --git a/Linux/lanmp.md b/Linux/lanmp.md
index 0d3a928..e8e2528 100644
--- a/Linux/lanmp.md
+++ b/Linux/lanmp.md
@@ -119,13 +119,4 @@ AddType application/x-httpd-php .php
```SHELL
service httpd restart
-```
-
-
-
-### Lnmp安装
-
-
-
-
-
+```
\ No newline at end of file
diff --git a/Linux/shell.md b/Linux/shell.md
index 252ee07..e91873f 100644
--- a/Linux/shell.md
+++ b/Linux/shell.md
@@ -7,7 +7,7 @@
- 头声明
-shell脚本第一行必须以 #!开头,它表示该脚本使用后面的解释器解释执行。
+shell脚本第一行必须以 #!开头,它表示该脚本使用后面的解释器解释执行。
```shell
#!/bin/bash
diff --git a/MQ/images/vi-vim-cheat-sheet-sch1.gif b/MQ/images/vi-vim-cheat-sheet-sch1.gif
new file mode 100644
index 0000000..7caed81
Binary files /dev/null and b/MQ/images/vi-vim-cheat-sheet-sch1.gif differ
diff --git a/MQ/images/vim-vi-workmodel.png b/MQ/images/vim-vi-workmodel.png
new file mode 100644
index 0000000..3db4f5f
Binary files /dev/null and b/MQ/images/vim-vi-workmodel.png differ
diff --git a/MQ/question.md b/MQ/question.md
new file mode 100644
index 0000000..f9ed9ec
--- /dev/null
+++ b/MQ/question.md
@@ -0,0 +1,25 @@
+1. 消息队列的作用
+- 流量消峰
+ 并发量大的时间,所有的请求直接怼到数据库,造成数据库连接异常,将请求写进消息队列,后面的系统再从消息队列依次来取出。
+- 异步
+ 一些非必要的业务逻辑以同步的方式运行,太耗费时间。改成异步,可以提高系统的响应时间。
+- 解耦
+ 将消息写入消息队列,需要消息的系统自己从消息队列中订阅。从而使该系统不需要改代码。
+2. 如何保证消息队列高可用
+集群
+3. 如何保证消息不被重复消费
+那造成重复消费的原因?,就是因为网络传输等等故障,确认信息没有传送到消息队列,导致消息队列不知道自己已经消费过该消息了,再次将消息分发给其他的消费者。
+消费前做检测,比如写库成功的时候,写入到redis中,再次消费的时候如果redis已存在,则不进行消费
+4. 如何保证消费的可靠性传输?
+其实这个可靠性传输,每种MQ都要从三个角度来分析:
+
+ - 生产者弄丢数据
+
+ 从生产者弄丢数据这个角度来看,RabbitMQ提供transaction和confirm模式来确保生产者不丢消息
+ - 消息队列弄丢数据
+
+ 处理消息队列丢数据的情况,一般是开启持久化磁盘的配置。这个持久化配置可以和confirm机制配合使用
+ - 消费者弄丢数据
+
+ 消费者丢数据一般是因为采用了自动确认消息模式。这种模式下,消费者会自动确认收到信息。这时rabbitMQ会立即将消息删除,这种情况下,如果消费者出现异常而未能处理消息,就会丢失该消息。
+ 手动确认消息
diff --git a/MongoDb/MongoDB.md b/MongoDb/MongoDB.md
index 55bfa48..1526327 100644
--- a/MongoDb/MongoDB.md
+++ b/MongoDb/MongoDB.md
@@ -235,15 +235,15 @@ db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : 1}}}])
# select by_user, count(*) from mycol group by by_user
```
-| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
+| `$sum` | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| --------- | ---------------------------------------------- | ------------------------------------------------------------ |
-| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
-| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
+| `$avg` | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
+| `$min` | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
-| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
+| `$push` | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
-| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
+| `$last` | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
聚合框架中常用的几个操作:
@@ -264,6 +264,50 @@ db.articles.aggregate( [
#$match用于获取分数大于70小于或等于90记录,然后将符合条件的记录送到下一阶段$group管道操作符进行处理。
```
+**聚合后排序操作**
+
+```bash
+db.getCollection('position').aggregate({
+ "$group": {
+ "_id": "$create_time",
+ "count": {
+ "$sum": 1
+ }
+ }
+
+},{
+ "$sort": {
+ "_id": -1
+ }
+})
+```
+
+**起别名**
+
+```bash
+db.getCollection('position').aggregate({
+ "$group": {
+ "_id": "$create_time",
+ "count": {
+ "$sum": 1
+ }
+ }
+
+},{
+ "$sort": {
+ "_id": -1
+ }
+ },{
+ "$project": {
+ "date": "$_id",
+ "count": 1,
+ "_id": 0
+ }
+ })
+```
+
+
+
### 原子性和事务处理
diff --git "a/Mysql/MySQL\344\274\230\345\214\226.md" "b/Mysql/MySQL\344\274\230\345\214\226.md"
index bcc8aa4..4531e19 100644
--- "a/Mysql/MySQL\344\274\230\345\214\226.md"
+++ "b/Mysql/MySQL\344\274\230\345\214\226.md"
@@ -34,9 +34,8 @@ select * from user where name like '%a'
- 应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描
-- 很多时候用 exists 代替 in 是一个好的选择:
+- 很多时候用 exists 代替 in 是一个好的选择
--
## btree索引
diff --git "a/Mysql/MySQL\347\264\242\345\274\225\345\216\237\347\220\206\345\217\212\346\205\242\346\237\245\350\257\242\344\274\230\345\214\226.md" "b/Mysql/MySQL\347\264\242\345\274\225\345\216\237\347\220\206\345\217\212\346\205\242\346\237\245\350\257\242\344\274\230\345\214\226.md"
index 9cb8a86..2fcb85e 100644
--- "a/Mysql/MySQL\347\264\242\345\274\225\345\216\237\347\220\206\345\217\212\346\205\242\346\237\245\350\257\242\344\274\230\345\214\226.md"
+++ "b/Mysql/MySQL\347\264\242\345\274\225\345\216\237\347\220\206\345\217\212\346\205\242\346\237\245\350\257\242\344\274\230\345\214\226.md"
@@ -4,14 +4,14 @@ MySQL凭借着出色的性能、低廉的成本、丰富的资源,已经成为
```sql
select
- count(*)
+ count(*)
from
- task
+ task
where
- status=2
- and operator_id=20839
- and operate_time>1371169729
- and operate_time<1371174603
+ status=2
+ and operator_id=20839
+ and operate_time>1371169729
+ and operate_time<1371174603
and type=2;
```
@@ -42,8 +42,10 @@ various-system-software-hardware-latencies
### 详解b+树
+
+
b+树
-如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点只不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
+如上图,是一颗b+树,关于b+树的定义可以参见B+树,这里只说一些重点,浅蓝色的块我们称之为一个磁盘块,可以看到每个磁盘块包含几个数据项(深蓝色所示)和指针(黄色所示),如磁盘块1包含数据项17和35,包含指针P1、P2、P3,P1表示小于17的磁盘块,P2表示在17和35之间的磁盘块,P3表示大于35的磁盘块。真实的数据存在于叶子节点即3、5、9、10、13、15、28、29、36、60、75、79、90、99。非叶子节点不存储真实的数据,只存储指引搜索方向的数据项,如17、35并不真实存在于数据表中。
### b+树的查找过程
@@ -80,12 +82,12 @@ select count(*) from task where status = 0 ;
### 慢查询优化基本步骤
0. 先运行看看是否真的很慢,注意设置SQL_NO_CACHE
-1.where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的 where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
-1. explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
-2. order by limit 形式的sql语句让排序的表优先查
-3. 了解业务方使用场景
-4. 加索引时参照建索引的几大原则
-5. 观察结果,不符合预期继续从0分析
+1. where条件单表查,锁定最小返回记录表。这句话的意思是把查询语句的 where都应用到表中返回的记录数最小的表开始查起,单表每个字段分别查询,看哪个字段的区分度最高
+2. explain查看执行计划,是否与1预期一致(从锁定记录较少的表开始查询)
+3. order by limit 形式的sql语句让排序的表优先查
+4. 了解业务方使用场景
+5. 加索引时参照建索引的几大原则
+6. 观察结果,不符合预期继续从0分析
几个慢查询案例
下面几个例子详细解释了如何分析和优化慢查询
@@ -95,32 +97,32 @@ select count(*) from task where status = 0 ;
```sql
select
- distinct cert.emp_id
+ distinct cert.emp_id
from
- cm_log cl
+ cm_log cl
inner join
(
select
emp.id as emp_id,
- emp_cert.id as cert_id
+ emp_cert.id as cert_id
from
- employee emp
+ employee emp
left join
- emp_certificate emp_cert
- on emp.id = emp_cert.emp_id
+ emp_certificate emp_cert
+ on emp.id = emp_cert.emp_id
where
emp.is_deleted=0
- ) cert
+ ) cert
on (
- cl.ref_table='Employee'
+ cl.ref_table='Employee'
and cl.ref_oid= cert.emp_id
- )
+ )
or (
- cl.ref_table='EmpCertificate'
+ cl.ref_table='EmpCertificate'
and cl.ref_oid= cert.cert_id
- )
+ )
where
- cl.last_upd_date >='2013-11-07 15:03:00'
+ cl.last_upd_date >='2013-11-07 15:03:00'
and cl.last_upd_date<='2013-11-08 16:00:00';
```
@@ -129,8 +131,9 @@ where
先运行一下,53条记录 1.87秒,又没有用聚合语句,比较慢
53 rows in set (1.87 sec)
-1.explain
+1.explain
+```sql
+----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+
@@ -139,42 +142,43 @@ where
| 2 | DERIVED | emp | ALL | NULL | NULL | NULL | NULL | 13317 | Using where |
| 2 | DERIVED | emp_cert | ref | emp_certificate_empid | emp_certificate_empid | 4 | meituanorg.emp.id | 1 | Using index |
+----+-------------+------------+-------+---------------------------------+-----------------------+---------+-------------------+-------+--------------------------------+
+```
简述一下执行计划,首先mysql根据idx_last_upd_date索引扫描cm_log表获得379条记录;然后查表扫描了63727条记录,分为两部分,derived表示构造表,也就是不存在的表,可以简单理解成是一个语句形成的结果集,后面的数字表示语句的ID。derived2表示的是ID = 2的查询构造了虚拟表,并且返回了63727条记录。我们再来看看ID = 2的语句究竟做了写什么返回了这么大量的数据,首先全表扫描employee表13317条记录,然后根据索引emp_certificate_empid关联emp_certificate表,rows = 1表示,每个关联都只锁定了一条记录,效率比较高。获得后,再和cm_log的379条记录根据规则关联。从执行过程上可以看出返回了太多的数据,返回的数据绝大部分cm_log都用不到,因为cm_log只锁定了379条记录。
如何优化呢?可以看到我们在运行完后还是要和cm_log做join,那么我们能不能之前和cm_log做join呢?仔细分析语句不难发现,其基本思想是如果cm_log的ref_table是EmpCertificate就关联emp_certificate表,如果ref_table是Employee就关联employee表,我们完全可以拆成两部分,并用union连接起来,注意这里用union,而不用union all是因为原语句有“distinct”来得到唯一的记录,而union恰好具备了这种功能。如果原语句中没有distinct不需要去重,我们就可以直接使用union all了,因为使用union需要去重的动作,会影响SQL性能。
优化过的语句如下
```sql
select
- emp.id
+ emp.id
from
- cm_log cl
+ cm_log cl
inner join
- employee emp
- on cl.ref_table = 'Employee'
- and cl.ref_oid = emp.id
+ employee emp
+ on cl.ref_table = 'Employee'
+ and cl.ref_oid = emp.id
where
- cl.last_upd_date >='2013-11-07 15:03:00'
- and cl.last_upd_date<='2013-11-08 16:00:00'
- and emp.is_deleted = 0
+ cl.last_upd_date >='2013-11-07 15:03:00'
+ and cl.last_upd_date<='2013-11-08 16:00:00'
+ and emp.is_deleted = 0
union
select
- emp.id
+ emp.id
from
- cm_log cl
+ cm_log cl
inner join
- emp_certificate ec
- on cl.ref_table = 'EmpCertificate'
- and cl.ref_oid = ec.id
+ emp_certificate ec
+ on cl.ref_table = 'EmpCertificate'
+ and cl.ref_oid = ec.id
inner join
- employee emp
- on emp.id = ec.emp_id
+ employee emp
+ on emp.id = ec.emp_id
where
- cl.last_upd_date >='2013-11-07 15:03:00'
- and cl.last_upd_date<='2013-11-08 16:00:00'
+ cl.last_upd_date >='2013-11-07 15:03:00'
+ and cl.last_upd_date<='2013-11-08 16:00:00'
and emp.is_deleted = 0
```
-不需要了解业务场景,只需要改造的语句和改造之前的语句保持结果一致
+4.不需要了解业务场景,只需要改造的语句和改造之前的语句保持结果一致
5.现有索引可以满足,不需要建索引
@@ -186,12 +190,12 @@ where
```sql
select from
-stage_poi sp
+stage_poi sp
where
-sp.accurate_result=1
+sp.accurate_result=1
and (
- sp.sync_status=0
- or sp.sync_status=2
+ sp.sync_status=0
+ or sp.sync_status=2
or sp.sync_status=4
);
@@ -200,6 +204,7 @@ and (
0.先看看运行多长时间,951条数据6.22秒,真的很慢
951 rows in set (6.22 sec)
+
1.先explain,rows达到了361万,type = ALL表明是全表扫描
2.所有字段都应用查询返回记录数,因为是单表查询 0已经做过了951条
@@ -208,6 +213,7 @@ and (
看一下accurate_result = 1的记录数
+```sql
select count(*),accurate_result from stage_poi group by accurate_result;
+----------+-----------------+
| count(*) | accurate_result |
@@ -216,12 +222,14 @@ select count(*),accurate_result from stage_poi group by accurate_result;
| 2114655 | 0 |
| 972815 | 1 |
+----------+-----------------+
+```
我们看到accurate_result这个字段的区分度非常低,整个表只有-1,0,1三个值,加上索引也无法锁定特别少量的数据
再看一下sync_status字段的情况
+```sql
select count(*),sync_status from stage_poi group by sync_status;
+----------+-------------+
| count(*) | sync_status |
@@ -229,6 +237,7 @@ select count(*),sync_status from stage_poi group by sync_status;
| 3080 | 0 |
| 3085413 | 3 |
+----------+-------------+
+```
同样的区分度也很低,根据理论,也不适合建立索引
@@ -239,15 +248,17 @@ select count(*),sync_status from stage_poi group by sync_status;
5.根据建立索引规则,使用如下语句建立索引
-alter table stage_poi add index idx_acc_status(accurate_result,sync_status);
+```alter table stage_poi add index idx_acc_status(accurate_result,sync_status);```
6.观察预期结果,发现只需要200ms,快了30多倍。
952 rows in set (0.20 sec)
+
我们再来回顾一下分析问题的过程,单表查询相对来说比较好优化,大部分时候只需要把where条件里面的字段依照规则加上索引就好,如果只是这种“无脑”优化的话,显然一些区分度非常低的列,不应该加索引的列也会被加上索引,这样会对插入、更新性能造成严重的影响,同时也有可能影响其它的查询语句。所以我们第4步调差SQL的使用场景非常关键,我们只有知道这个业务场景,才能更好地辅助我们更好的分析和优化查询语句。
无法优化的语句
+```sql
select
c.id,
c.name,
@@ -264,37 +275,37 @@ select
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
- c.last_modified_user_id
+ c.last_modified_user_id
from
- contact c
+ contact c
inner join
- contact_branch cb
- on c.id = cb.contact_id
+ contact_branch cb
+ on c.id = cb.contact_id
inner join
- branch_user bu
- on cb.branch_id = bu.branch_id
+ branch_user bu
+ on cb.branch_id = bu.branch_id
and bu.status in (
1,
- 2)
+ 2)
inner join
- org_emp_info oei
- on oei.data_id = bu.user_id
- and oei.node_left >= 2875
- and oei.node_right <= 10802
- and oei.org_category = - 1
+ org_emp_info oei
+ on oei.data_id = bu.user_id
+ and oei.node_left >= 2875
+ and oei.node_right <= 10802
+ and oei.org_category = - 1
order by
c.created_time desc limit 0 ,
10;
-
+```
还是几个步骤
0.先看语句运行多长时间,10条记录用了13秒,已经不可忍受
10 rows in set (13.06 sec)
+
1.explain
```sql
-
+----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+--------+-------------------------------------+-------------------------+---------+--------------------------+------+----------------------------------------------+
@@ -312,22 +323,22 @@ rows返回的都非常少,看不到有什么异常情况。我们在看一下
select
count(*)
from
- contact c
+ contact c
inner join
- contact_branch cb
- on c.id = cb.contact_id
+ contact_branch cb
+ on c.id = cb.contact_id
inner join
- branch_user bu
- on cb.branch_id = bu.branch_id
+ branch_user bu
+ on cb.branch_id = bu.branch_id
and bu.status in (
1,
- 2)
+ 2)
inner join
- org_emp_info oei
- on oei.data_id = bu.user_id
- and oei.node_left >= 2875
- and oei.node_right <= 10802
- and oei.org_category = - 1
+ org_emp_info oei
+ on oei.data_id = bu.user_id
+ and oei.node_left >= 2875
+ and oei.node_right <= 10802
+ and oei.org_category = - 1
+----------+
| count(*) |
+----------+
@@ -388,6 +399,7 @@ c.created_time desc limit 0 ,
```
10 rows in set (0.00 sec)
+
本以为至此大工告成,但我们在前面的分析中漏了一个细节,先排序再join和先join再排序理论上开销是一样的,为何提升这么多是因为有一个limit!大致执行过程是:mysql先按索引排序得到前10条记录,然后再去join过滤,当发现不够10条的时候,再次去10条,再次join,这显然在内层join过滤的数据非常多的时候,将是灾难的,极端情况,内层一条数据都找不到,mysql还傻乎乎的每次取10条,几乎遍历了这个数据表!
用不同参数的SQL试验下
@@ -408,45 +420,49 @@ select
c.data_source,
from_unixtime(c.created_time) as created_time,
from_unixtime(c.last_modified) as last_modified,
- c.last_modified_user_id
+ c.last_modified_user_id
from
- contact c
+ contact c
where
exists (
select
- 1
+ 1
from
- contact_branch cb
+ contact_branch cb
inner join
- branch_user bu
- on cb.branch_id = bu.branch_id
+ branch_user bu
+ on cb.branch_id = bu.branch_id
and bu.status in (
1,
- 2)
+ 2)
inner join
- org_emp_info oei
- on oei.data_id = bu.user_id
- and oei.node_left >= 2875
- and oei.node_right <= 2875
- and oei.org_category = - 1
+ org_emp_info oei
+ on oei.data_id = bu.user_id
+ and oei.node_left >= 2875
+ and oei.node_right <= 2875
+ and oei.org_category = - 1
where
- c.id = cb.contact_id
- )
+ c.id = cb.contact_id
+ )
order by
c.created_time desc limit 0 ,
10;
Empty set (2 min 18.99 sec)
```
-2 min 18.99 sec!比之前的情况还糟糕很多。由于mysql的nested loop机制,遇到这种情况,基本是无法优化的。这条语句最终也只能交给应用系统去优化自己的逻辑了。
+2 min 18.99 sec!
+
+比之前的情况还糟糕很多。由于mysql的nested loop机制,遇到这种情况,基本是无法优化的。这条语句最终也只能交给应用系统去优化自己的逻辑了。
通过这个例子我们可以看到,并不是所有语句都能优化,而往往我们优化时,由于SQL用例回归时落掉一些极端情况,会造成比原来还严重的后果。所以,第一:不要指望所有语句都能通过SQL优化,第二:不要过于自信,只针对具体case来优化,而忽略了更复杂的情况。
慢查询的案例就分析到这儿,以上只是一些比较典型的案例。我们在优化过程中遇到过超过1000行,涉及到16个表join的“垃圾SQL”,也遇到过线上线下数据库差异导致应用直接被慢查询拖死,也遇到过varchar等值比较没有写单引号,还遇到过笛卡尔积查询直接把从库搞死。再多的案例其实也只是一些经验的积累,如果我们熟悉查询优化器、索引的内部原理,那么分析这些案例就变得特别简单了。
-写在后面的话
+##写在后面的话
+
本文以一个慢查询案例引入了MySQL索引原理、优化慢查询的一些方法论;并针对遇到的典型案例做了详细的分析。其实做了这么长时间的语句优化后才发现,任何数据库层面的优化都抵不上应用系统的优化,同样是MySQL,可以用来支撑Google/FaceBook/Taobao应用,但可能连你的个人网站都撑不住。套用最近比较流行的话:“查询容易,优化不易,且写且珍惜!”
-参考
-参考文献如下:
+##参考文献如下
+
1.《高性能MySQL》
+
2.《数据结构与算法分析》
diff --git "a/Mysql/\347\264\242\345\274\225.md" "b/Mysql/\347\264\242\345\274\225.md"
index 4eaa96a..b203f38 100644
--- "a/Mysql/\347\264\242\345\274\225.md"
+++ "b/Mysql/\347\264\242\345\274\225.md"
@@ -1,60 +1,163 @@
-**Mysql索引概念:**
+## 索引分类
-说说Mysql索引,看到一个很少比如:索引就好比一本书的目录,它会让你更快的找到内容,显然目录(索引)并不是越多越好,假如这本书1000页,有500也是目录,它当然效率低,目录是要占纸张的,而索引是要占磁盘空间的。
+**从物理存储角度**
-**Mysql索引主要有两种结构:B+tree和hash.**
+1. 聚集索引(clustered index)
-hash:hsah索引在mysql比较少用,他以把数据的索引以hash形式组织起来,因此当查找某一条记录的时候,速度非常快.当时因为是hash结构,每个键只对应一个值,而且是散列的方式分布.所以他并不支持范围查找和排序等功能.
+2. 非聚集索引(non-clustered index)、 二级索引
-B+树:b+tree是mysql使用最频繁的一个索引数据结构,数据结构以平衡树的形式来组织,因为是树型结构,所以更适合用来处理排序,范围查找等功能.相对hash索引,B+树在查找单条记录的速度虽然比不上hash索引,但是因为更适合排序等操作,所以他更受用户的欢迎.毕竟不可能只对数据库进行单条记录的操作.
+**从逻辑角度**
-**Mysql常见索引:**主键索引、唯一索引、普通索引、全文索引、组合索引
+1. 主键索引:主键索引是一种特殊的唯一索引,不允许有空值
-PRIMARY KEY(主键索引) ALTER TABLE \`table_name\` ADD PRIMARY KEY ( \`column\` )
+2. 普通索引或者单列索引
- UNIQUE(唯一索引) ALTER TABLE \`table_name\` ADD UNIQUE (\`column\`)
+3. 多列索引(联合索引):复合索引指多个字段上创建的索引,只有在查询条件中使用了创建索引时的第一个字段,索引才会被使用。使用复合索引时遵循最左前缀集合
-INDEX(普通索引) ALTER TABLE \`table\_name\` ADD INDEX index\_name ( \`column\` )
+4. 唯一索引或者非唯一索引
-FULLTEXT(全文索引) ALTER TABLE \`table_name\` ADD FULLTEXT ( \`column\` )
+5. 空间索引:空间索引是对空间数据类型的字段建立的索引,MYSQL中的空间数据类型有4种,分别是GEOMETRY、POINT、LINESTRING、POLYGON。
+ MYSQL使用SPATIAL关键字进行扩展,使得能够用于创建正规索引类型的语法创建空间索引。创建空间索引的列,必须将其声明为NOT NULL,空间索引只能在存储引擎为MYISAM的表中创建
-组合索引 ALTER TABLE \`table\_name\` ADD INDEX index\_name ( \`column1\`, \`column2\`, \`column3\` )
+**从数据结构角度**
-**Mysql各种索引区别:**
+1. B-Tree索引
-普通索引:最基本的索引,没有任何限制
-唯一索引:与"普通索引"类似,不同的就是:索引列的值必须唯一,但允许有空值。
+2. Hash索引:
+ a 仅仅能满足"=","IN"和"<=>"查询,不能使用范围查询
+ b 其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引
+ c 只有Memory存储引擎显示支持hash索引
-主键索引:它 是一种特殊的唯一索引,不允许有空值。
+3. FULLTEXT索引(现在MyISAM和InnoDB引擎都支持了)
-全文索引:仅可用于 MyISAM 表,针对较大的数据,生成全文索引很耗时好空间。
+4. R-Tree索引
-组合索引:为了更多的提高mysql效率可建立组合索引,遵循”最左前缀“原则。
-**B+Tree**
-
+## 聚簇索引(cluster index)
-1. 所有关键字都在叶子结点出现
+**聚簇索引、聚集索引 一个意思**。
-2. 所有叶子结点增加一个链指针
+指索引项的排序方式和表中数据记录排序方式一致的索引。一个表至少有一个聚集索引。
-## 聚集索引和辅助索引、覆盖索引
+1. 如果表设置了主键,则主键就是聚簇索引
-- 聚集索引(主键索引)
+2. 如果表没有主键,则会默认第一个NOT NULL,且唯一(UNIQUE)的列作为聚簇索引
-—innodb存储引擎是索引组织表,即表中的数据按照主键顺序存放。而聚集索引就是按照每张表的主键构造一颗B+树,同时叶子节点中存放的即为整张表的记录数据
+3. 以上都没有,则会默认创建一个隐藏的row_id作为聚簇索引
-—聚集索引的叶子节点称为数据页,数据页,数据页!重要的事说三遍。聚集索引的这个特性决定了索引组织表中的数据也是索引的一部分。
+InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。
-- 辅助索引(二级索引)
+由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
-—非主键索引
+> InnoDB的聚簇索引的叶子节点存储的是行记录(其实是页结构,一个页包含多行数据),InnoDB必须要有至少一个聚簇索引。
+>
+> 由此可见,使用聚簇索引查询会很快,因为可以直接定位到行记录。
-—叶子节点=键值+书签。Innodb存储引擎的书签就是相应行数据的主键索引值
+## 普通索引
-- 覆盖索引
+普通索引也叫**二级索引**,除聚簇索引外的索引,即非聚簇索引。
-如果查询的列恰好是索引的一部分,那么查询只需要在索引文件上进行,不需要进行到磁盘中找数据,若果查询得列不是索引的一部分则要到磁盘中找数据
+InnoDB的普通索引叶子节点存储的是主键(聚簇索引)的值,而MyISAM的普通索引存储的是记录指针。
-使用explain,可以通过输出的extra列来判断,对于一个索引覆盖查询,显示为**using index**,MySQL查询优化器在执行查询前会决定是否有索引覆盖查询
+```mysql
+mysql> create table user(
+ -> id int(10) auto_increment,
+ -> name varchar(30),
+ -> age tinyint(4),
+ -> primary key (id),
+ -> index idx_age (age)
+ -> )engine=innodb charset=utf8mb4;
+insert into user(name,age) values('张三',30);
+insert into user(name,age) values('李四',20);
+insert into user(name,age) values('王五',40);
+insert into user(name,age) values('刘八',10);
+```
+
+
+
+### 聚簇索引的结构
+
+> 叶子节点存储行信息
+
+
+
+### 非聚簇索引结构
+
+> 非聚簇索引,其叶子节点存储的是聚簇索引的的值
+
+
+
+```sql
+select * from user where id =1
+select * from user where age = 20
+```
+
+对于聚簇索引查询,需要扫描聚簇索引,一次即可扫描到记录,
+
+对于非聚簇索引,利用非非聚簇索引,扫到聚簇索引的值,然后会再次到聚簇索引中查找,
+
+### 回表查询
+
+先通过普通索引的值定位聚簇索引值,再通过聚簇索引的值定位行记录数据,需要扫描两次索引B+树,它的性能较扫一遍索引树更低。这个过程叫做回表
+
+### 索引覆盖
+
+查询的结果字段包含所有索引信息,不会回表,比如
+
+```sql
+select id,age from user where age = 10
+```
+
+当age索引一次扫描到聚簇索引的值的时候,正好得到了所有的结果,避免了回表操作。
+
+实现: 将被查询的字段,建立到联合索引里去。
+
+可以通过`explain` ,查看extra字段。如果是`use index` 则使用了索引,如果是`null` 则进行了回表
+
+- count 优化
+- 列查询优化
+- 分页查询优化
+
+
+
+## 索引下推
+
+索引下推(index condition pushdown) 指的是Mysql需要一个表中检索数据的时候,会使用索引过滤掉不符合条件的数据,然后再返回给客户端
+
+```sql
+"select * from user where username like '张%' and age > 10"
+```
+
+**没有ICP**
+
+根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后回表查询出相应的全行数据,然后再筛选出满足年龄小于等于10的用户数据
+
+1,获取下一行,首先读索引元组,然后使用索引去查找并读取所有的行
+
+2,根据WHERE条件部分,判断数据是否符合。根据判断结果接受或拒绝该行
+
+**使用ICP**
+
+这个过程则会变成这样:
+
+根据(username,age)联合索引查询所有满足名称以“张”开头的索引,然后直接再筛选出年龄小于等于10的索引,之后再回表查询全行数据
+
+
+
+1,获取下一行的索引元组(不是所有行)
+
+2,根据WHERE条件部分,判断是否可以只通过索引列满足条件。如果不满足,则获取下一行索引元组
+
+3,如果满足条件,则通过索引元组去查询并读取所有的行
+
+4,根据遗留的WHERE子句中的条件,在当前表中进行判断,根据判断结果接受或者拒绝改行
+
+
+
+ICP默认启动。可以通过optimizer_switch系统变量去控制它是否开启:
+
+```ini
+SET optimizer_switch = 'index_condition_pushdown=off';
+SET optimizer_switch = 'index_condition_pushdown=on';
+```
diff --git "a/Mysql/\351\224\201.md" "b/Mysql/\351\224\201.md"
new file mode 100644
index 0000000..2cfa199
--- /dev/null
+++ "b/Mysql/\351\224\201.md"
@@ -0,0 +1,64 @@
+## 乐观锁
+乐观锁是指操作数据库时(更新操作),想法很乐观,认为这次的操作不会导致冲突,在操作数据时,并不进行任何其他的特殊处理(也就是不加锁),而在进行更新后,再去判断是否有冲突了。通常的做法,是在表中加个版本字段,更新的时候和读取的时候做比对。如果一致则进行修改。
+```sql
+select v,name from table where id =1 ;// 假设v = 1
+
+update table set name ="test" and v = v+1 where id = 1 and v =1;// 如果v之前有过修改,则此次修改失败。
+```
+## 悲观锁
+与乐观锁相对应的就是悲观锁了。悲观锁就是在操作数据时,认为此操作会出现数据冲突,所以在进行每次操作时都要通过获取锁才能进行对相同数据的操作,所以悲观锁需要耗费较多的时间。另外与乐观锁相对应的,悲观锁是由数据库自己实现了的,要用的时候,我们直接调用数据库的相关语句就可以
+### 共享锁 [读锁]
+
+共享锁指的就是对于多个不同的事务,对同一个资源共享同一个锁。相当于对于同一把门,它拥有多个钥匙一样。就像这样,你家有一个大门,大门的钥匙有好几把,你有一把,你女朋友有一把,你们都可能通过这把钥匙进入你们家,这个就是所谓的共享锁。
+```sql
+begin
+select id from `table` where id = 1 lock in share mode;
+
+# 第二个客户端
+update `table` set name = "ddte" where id =1 ;//报错 第一个事务没提交
+```
+### 排它锁 [写锁]
+排它锁与共享锁相对应,就是指对于多个不同的事务,对同一个资源只能有一把锁。
+
+与共享锁类型,在需要执行的语句后面加上for update就可以了(对于Innodb引擎语句后面加上for update表示把此行数据锁定,MyISAM则是锁定整个表。)
+```sql
+select …… for update;
+```
+## MVCC
+
+mysql的innodb采用的是行锁,而且采用了多版本并发控制来提高读操作的性能。
+
+MVVC (Multi-Version Concurrency Control) (注:与MVCC相对的,是基于锁的并发控制,Lock-Based Concurrency Control)是一种基于多版本的并发控制协议,只有在InnoDB引擎下存在。MVCC是为了实现事务的隔离性,通过版本号,避免同一数据在不同事务间的竞争,你可以把它当成基于多版本号的一种乐观锁。当然,这种乐观锁只在事务级别未提交锁和已提交锁时才会生效。MVCC最大的好处,相信也是耳熟能详:读不加锁,读写不冲突。在读多写少的OLTP应用中,读写不冲突是非常重要的,极大的增加了系统的并发性能
+
+### 实现方式
+ InnoDB在每行数据都增加两个隐藏字段,一个记录创建的版本号,一个记录删除的版本号。
+版本链
+
+在InnoDB引擎表中,它的聚簇索引记录中有两个必要的隐藏列:
+
+- trx_id
+这个id用来存储的每次对某条聚簇索引记录进行修改的时候的事务id。
+- roll_pointer
+每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中。这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息。(注意插入操作的undo日志没有这个属性,因为它没有老版本)
+
+| id | name | trx_id | roll_pointer |
+| ---- | ---- | ------ | ------------ |
+| 1 | 1 | 50 | 49 |
+| | | | |
+
+在多版本并发控制中,为了保证数据操作在多线程过程中,保证事务隔离的机制,降低锁竞争的压力,保证较高的并发量。在每开启一个事务时,会生成一个事务的版本号,被操作的数据会生成一条新的数据行(临时),但是在提交前对其他事务是不可见的,对于数据的更新(包括增删改)操作成功,会将这个版本号更新到数据的行中,事务提交成功,将新的版本号更新到此数据行中,这样保证了每个事务操作的数据,都是互不影响的,也不存在锁的问题。
+### MVVC下的CRUD
+- SELECT:
+ 当隔离级别是REPEATABLE READ时select操作,InnoDB必须每行数据来保证它符合两个条件:
+ 1、InnoDB必须找到一个行的版本,它至少要和事务的版本一样老(也即它的版本号不大于事务的版本号)。这保证了不管是事务开始之前,或者事务创建时,或者修改了这行数据的时候,这行数据是存在的。
+ 2、这行数据的删除版本必须是未定义的或者比事务版本要大。这可以保证在事务开始之前这行数据没有被删除。
+符合这两个条件的行可能会被当作查询结果而返回。
+
+
+- INSERT:InnoDB为这个新行记录当前的系统版本号。
+
+- DELETE:InnoDB将当前的系统版本号设置为这一行的删除ID。
+- UPDATE:InnoDB会写一个这行数据的新拷贝,这个拷贝的版本为当前的系统版本号。它同时也会将这个版本号写到旧行的删除版本里。
+
+这种额外的记录所带来的结果就是对于大多数查询来说根本就不需要获得一个锁。他们只是简单地以最快的速度来读取数据,确保只选择符合条件的行。这个方案的缺点在于存储引擎必须为每一行存储更多的数据,做更多的检查工作,处理更多的善后操作。
+ MVCC只工作在REPEATABLE READ和READ COMMITED隔离级别下。READ UNCOMMITED不是MVCC兼容的,因为查询不能找到适合他们事务版本的行版本;它们每次都只能读到最新的版本。SERIABLABLE也不与MVCC兼容,因为读操作会锁定他们返回的每一行数据。
\ No newline at end of file
diff --git a/PHP/PHP8.1.md b/PHP/PHP8.1.md
new file mode 100644
index 0000000..6987891
--- /dev/null
+++ b/PHP/PHP8.1.md
@@ -0,0 +1,91 @@
+PHP8.1在2021年11月25日发布了。又带来了很多很特性和性能改进。
+
+## 枚举
+Enum 只支持整型和字符串两种类型
+```php
+enum Status: int {
+ case SUCCESS = 0
+ case ERROR = 1
+}
+
+function test (Status $status) {
+
+}
+test(Status::SUCCESS)
+```
+
+### 枚举属性和方法
+
+枚举有两个属性 `name` 、`value`
+```php
+ $status->name;
+ $status->value;
+```
+Enum 提供了 from () 方法来通过选项 value 的值来获取对应的选项
+
+```php
+dump(Status::from(0));
+
+```
+
+## 数组解包
+```php
+$array_1 = [
+ 'key1' => 'foo',
+ 'key2' => 'bar'
+];
+$array_2 = [
+ 'key3' => 'baz',
+ 'key4' => 'qux'
+];
+
+$array_unpacked = [...$array_1, ...$array_2];
+dd($array_unpacked);
+```
+新增`array_is_list ` 判断是否是从 0 开始递增的数字数组
+```php
+dump(array_is_list(['apple', 'orange']));
+```
+
+## 类相关
+
+### 只读属性readonly
+
+只读属性只允许初始化一次,修改 readonly 属性就会报错,只能在类的内部使用。
+
+```php
+class User {
+ public readonly int $uid;
+
+ public function __construct(int $uid) {
+ $this->uid = $uid;
+ }
+}
+$user = new User(12)
+$user->uid = 1;//error
+```
+### final 类常量
+
+```php
+class Foo {
+ final public const TEST = '1';
+}
+
+```
+
+## 函数相关
+
+1. First-class Callable
+
+```php
+$callable = strtoupper(...);
+echo $callable('hello, world') . PHP_EOL;
+```
+2. Never 返回类型
+
+```php
+function redirect(string $url): never {
+ header('Location: ' . $url);
+ exit();
+}
+```
diff --git a/PHP/PHP8.2.md b/PHP/PHP8.2.md
new file mode 100644
index 0000000..c0d6206
--- /dev/null
+++ b/PHP/PHP8.2.md
@@ -0,0 +1,72 @@
+## PHP8.2的变化
+- [PHP8.2](https://www.php.net/releases/8.2/zh.php)
+### 只读类
+使用`readonly` 修饰类名
+```php
+title = $title;
+ $this->status = $status;
+ }
+}
+```
+### 析取范式 (DNF)类型
+简单的理解,就是定义参数支持交集和并集,'组合并集和交集类型时,交集类型必须用括号进行分组'
+```php
+class Foo {
+ public function bar((A&B)|null $entity) {
+ return $entity;
+ }
+}
+```
+### 允许 null、false 和 true 作为独立类型
+```php
+
+function f(): false {
+ return false;
+}
+function f1(): true {
+ return true;
+}
+function f2(): null {
+ return null;
+}
+```
+### 新的“随机”扩展
+`\Random\Randomizer` 类提供了一个高级接口来使用引擎的随机性来生成随机整数、随机排列数组或字符串、选择随机数组键等。
+
+### Traits 中允许常量
+```php
+trait T
+{
+ public const CONSTANT = 1;
+}
+```
+### 弃用动态属性
+动态属性的创建已被弃用,以帮助避免错误和拼写错误,除非该类通过使用 `#[\AllowDynamicProperties]` 属性来选择。`stdClass` 允许动态属性。
+__get/__set 魔术方法的使用不受此更改的影响。
+```php
+class User
+{
+ public $name;
+}
+
+$user = new User();
+$user->last_name = 'Doe'; // Deprecated notice
+
+$user = new stdClass();
+$user->last_name = 'Doe'; // Still allowed
+```
+
+## 弃用和向后不兼容
+- 弃用 ${} 字符串插值。
+- 弃用 utf8_encode 和 utf8_decode 函数。
+- DateTime::createFromImmutable 和 DateTimeImmutable::createFromMutable 方法暂定返回类型为 static。
+- strtolower 和 strtoupper 函数不再对语言环境敏感。
diff --git a/PHP/PHP8.md b/PHP/PHP8.md
new file mode 100644
index 0000000..8644cc8
--- /dev/null
+++ b/PHP/PHP8.md
@@ -0,0 +1,78 @@
+## PHP8新特性
+
+#### 1. 命名参数
+
+命名参数实现了我们调用函数的时候,不用严格函数的定义顺序。
+
+```php
+function test($a,$b,$c) {
+ echo sprintf("a=%s,b=%s,c=%s \n",$a,$b,$c);
+}
+test("1",c:'2',b:"3");
+test(c: 'c',b: '2',a:"1");
+```
+
+### 2. 注解
+
+ PHP 原生语法来使用结构化的元数据
+
+```php
+#[Route("/api/posts/{id}")]
+function Attribute() {
+}
+$ref = new ReflectionFunction("Attribute");
+var_dump($ref->getAttributes("Route")[0]->getName()); //Route
+var_dump($ref->getAttributes("Route")[0]->getArguments());//
+```
+
+### 3. 联合类型
+
+联合类型 就是一个类型可以多个类型的其中一个
+
+```php
+class C
+{
+ private string|int $name;
+
+ public function setName($name){
+ $this->name = $name;
+ echo $this->name.PHP_EOL;
+ }
+}
+
+$c = new C();
+$c->setName(1);
+$c->setName("123");
+$c->setName([]);//error
+```
+
+### 4. Match表达式
+
+新的 match 类似于 switch,并具有以下功能:
+
+- Match 是一个表达式,它可以储存到变量中亦可以直接返回。
+- Match 分支仅支持单行,它不需要一个 break; 语句。
+- Match 使用严格比较
+
+```php
+echo match (8.0) {
+ '8.0' => "Oh no!",
+ 8.0 => "This is what I expected",
+};
+```
+
+### 5. **字符串与数字的比较逻辑**
+
+```php
+#php8
+0 == 'foobar' // false
+#php7
+0 == 'foobar' // true
+
+```
+
+### 6. JIT 即时编译
+
+### 7. 新的类、接口、函数
+
+- `str_contains` 字符串包含 、`str_starts_with` 以字符串开始、`str_ends_with`
diff --git "a/PHP/PHP\346\211\213\345\206\214\347\254\224\350\256\260/6.\351\235\242\345\220\221\345\257\271\350\261\241(OOP).md" "b/PHP/PHP\346\211\213\345\206\214\347\254\224\350\256\260/6.\351\235\242\345\220\221\345\257\271\350\261\241(OOP).md"
index eabfe2e..2f595e4 100644
--- "a/PHP/PHP\346\211\213\345\206\214\347\254\224\350\256\260/6.\351\235\242\345\220\221\345\257\271\350\261\241(OOP).md"
+++ "b/PHP/PHP\346\211\213\345\206\214\347\254\224\350\256\260/6.\351\235\242\345\220\221\345\257\271\350\261\241(OOP).md"
@@ -157,7 +157,7 @@ class B extends A{
public static $s = 's';
const PI = 111;
public function test(){
- echo parent::age;// 10
+ echo $this->age;// 10
}
diff --git "a/PHP/PHP\350\277\220\350\241\214\345\216\237\347\220\206.md" "b/PHP/PHP\350\277\220\350\241\214\345\216\237\347\220\206.md"
index f895fd0..c1515fb 100644
--- "a/PHP/PHP\350\277\220\350\241\214\345\216\237\347\220\206.md"
+++ "b/PHP/PHP\350\277\220\350\241\214\345\216\237\347\220\206.md"
@@ -4,13 +4,16 @@ PHP是一种适用于web开发的动态语言。具体点说,就是一个用C
了解PHP底层实现的目的是什么?动态语言要像用好首先得了解它,内存管理、框架模型值得我们借鉴,通过扩展开发实现更多更强大的功能,优化我们程序的性能。
-1. PHP的设计理念及特点
+### **PHP的设计理念及特点**
+
多进程模型:由于PHP是多进程模型,不同请求间互不干涉,这样保证了一个请求挂掉不会对全盘服务造成影响。当然,随着时代发展,PHP也早已支持多线程模型。
弱类型语言:和C/C++、Java、C#等语言不同,PHP是一门弱类型语言。一个变量的类型并不是一开始就确定不变,运行中才会确定并可能发生隐式或显式的类型转换,这种机制的灵活性在web开发中非常方便、高效,具体会在后面PHP变量中详述。
引擎(Zend)+组件(ext)的模式降低内部耦合。
中间层(sapi)隔绝web server和PHP。
语法简单灵活,没有太多规范。缺点导致风格混杂,但再差的程序员也不会写出太离谱危害全局的程序。
-2. PHP的四层体系
+
+### PHP的四层体系
+
PHP的核心架构如下图:
php-core
@@ -21,22 +24,40 @@ php-core
从图上可以看出,PHP从下到上是一个4层体系:
-Zend引擎:Zend整体用纯C实现,是PHP的内核部分,它将PHP代码翻译(词法、语法解析等一系列编译过程)为可执行opcode处理,并实现相应的处理方法,实现了基本的数据结构(如hashtable、oo)、内存分配及管理、提供了相应的api方法供外部调用,是一切的核心,所有的外围功能均围绕Zend实现。
-Extensions:围绕着Zend引擎,extensions通过组件式的方式提供各种基础服务,我们常见的各种内置函数(如array系列)、标准库等都是通过extension来实现,用户也可以根据需要实现自己的extension以达到功能扩展、性能优化等目的(如贴吧正在使用的PHP中间层、富文本解析就是extension的典型应用)。
-Sapi:Sapi全称是Server Application Programming Interface,也就是服务端应用编程接口,Sapi通过一系列钩子函数,使得PHP可以和外围交互数据,这是PHP非常优雅和成功的一个设计,通过sapi成功的将PHP本身和上层应用解耦隔离,PHP可以不再考虑如何针对不同应用进行兼容,而应用本身也可以针对自己的特点实现不同的处理方式。
-Application:这就是我们平时编写的PHP程序,通过不同的sapi方式得到各种各样的应用模式,如通过webserver实现web应用、在命令行下以脚本方式运行等等。
+1. Zend引擎:
+
+ Zend整体用纯C实现,是PHP的内核部分,它将PHP代码翻译(词法、语法解析等一系列编译过程)为可执行opcode处理,并实现相应的处理方法,实现了基本的数据结构(如hashtable、oo)、内存分配及管理、提供了相应的api方法供外部调用,是一切的核心,所有的外围功能均围绕Zend实现。
+
+2. Extensions:
+
+ 围绕着Zend引擎,extensions通过组件式的方式提供各种基础服务,我们常见的各种内置函数(如array系列)、标准库等都是通过extension来实现,用户也可以根据需要实现自己的extension以达到功能扩展、性能优化等目的(如贴吧正在使用的PHP中间层、富文本解析就是extension的典型应用)。
+
+3. Sapi:
+
+ Sapi全称是Server Application Programming Interface,也就是服务端应用编程接口,Sapi通过一系列钩子函数,使得PHP可以和外围交互数据,这是PHP非常优雅和成功的一个设计,通过sapi成功的将PHP本身和上层应用解耦隔离,PHP可以不再考虑如何针对不同应用进行兼容,而应用本身也可以针对自己的特点实现不同的处理方式。
+
+4. Application:
+
+ 这就是我们平时编写的PHP程序,通过不同的sapi方式得到各种各样的应用模式,如通过webserver实现web应用、在命令行下以脚本方式运行等等。
+
如果PHP是一辆车,那么车的框架就是PHP本身,Zend是车的引擎(发动机),Ext下面的各种组件就是车的轮子,Sapi可以看做是公路,车可以跑在不同类型的公路上,而一次PHP程序的执行就是汽车跑在公路上。因此,我们需要:性能优异的引擎+合适的车轮+正确的跑道。
-3. Sapi
-如前所述,Sapi通过通过一系列的接口,使得外部应用可以和PHP交换数据,并可以根据不同应用特点实现特定的处理方法,我们常见的一些sapi有:
+### SAPI
+
+如前所述,SAPI通过通过一系列的接口,使得外部应用可以和PHP交换数据,并可以根据不同应用特点实现特定的处理方法,我们常见的一些sapi有:
+
+**apache2handler**:这是以apache作为webserver,采用mod_PHP模式运行时候的处理方式。
+**cgi**:这是webserver和PHP直接的另一种交互方式,也就是大名鼎鼎的fastcgi协议,在最近今年fastcgi+PHP得到越来越多的应用,也是异步webserver所唯一支持的方式。
+**cli**:命令行调用的应用模式
+
-apache2handler:这是以apache作为webserver,采用mod_PHP模式运行时候的处理方式。
-cgi:这是webserver和PHP直接的另一种交互方式,也就是大名鼎鼎的fastcgi协议,在最近今年fastcgi+PHP得到越来越多的应用,也是异步webserver所唯一支持的方式。
-cli:命令行调用的应用模式
-4. PHP的执行流程&opcode
- 我们先来看看PHP代码的执行所经过的流程。
- 
+### PHP的执行流程&opcode
+
+
+我们先来看看PHP代码的执行所经过的流程。
+
+
从图上可以看到,PHP实现了一个典型的动态语言执行过程:拿到一段代码后,经过词法解析、语法解析等阶段后,源程序会被翻译成一个个指令(opcodes),然后ZEND虚拟机顺次执行这些指令完成操作。PHP本身是用C实现的,因此最终调用的也都是C的函数,实际上,我们可以把PHP看做是一个C开发的软件。
@@ -59,7 +80,10 @@ ZEND_IS_EQUAL_SPEC_CV_CONST:判断相等 $a==1
ZEND_IS_IDENTICAL_SPEC_CV_CONST:判断相等 $a===1
-5. HashTable — 核心数据结构
+
+
+### **HashTable — 核心数据结构**
+
HashTable是Zend的核心数据结构,在PHP里面几乎并用来实现所有常见功能,我们知道的PHP数组即是其典型应用,此外,在zend内部,如函数符号表、全局变量等也都是基于hash table来实现。
PHP的hash table具有如下特点:
@@ -78,18 +102,22 @@ Zend hash table实现了典型的hash表散列结构,同时通过附加一个
散列结构:Zend的散列结构是典型的hash表模型,通过链表的方式来解决冲突。需要注意的是zend的hash table是一个自增长的数据结构,当hash表数目满了之后,其本身会动态以2倍的方式扩容并重新元素位置。初始大小均为8。另外,在进行key->value快速查找时候,zend本身还做了一些优化,通过空间换时间的方式加快速度。比如在每个元素中都会用一个变量nKeyLength标识key的长度以作快速判定。
双向链表:Zend hash table通过一个链表结构,实现了元素的线性遍历。理论上,做遍历使用单向链表就够了,之所以使用双向链表,主要目的是为了快速删除,避免遍历。Zend hash table是一种复合型的结构,作为数组使用时,即支持常见的关联数组也能够作为顺序索引数字来使用,甚至允许2者的混合。
PHP关联数组:关联数组是典型的hash_table应用。一次查询过程经过如下几步(从代码可以看出,这是一个常见的hash查询过程,并增加一些快速判定加速查找。):
+```c
getKeyHashValue h;
index = n & nTableMask;
Bucket *p = arBucket[index];
while (p) {
if ((p->h == h) & (p->nKeyLength == nKeyLength)) {
- RETURN p->data;
+ return p->data;
}
p=p->next;
}
-RETURN FALTURE;
+return FALTURE;
+```
PHP索引数组:索引数组就是我们常见的数组,通过下标访问。例如 $arr[0],Zend HashTable内部进行了归一化处理,对于index类型key同样分配了hash值和nKeyLength(为0)。内部成员变量nNextFreeElement就是当前分配到的最大id,每次push后自动加一。正是这种归一化处理,PHP才能够实现关联和非关联的混合。由于push操作的特殊性,索引key在PHP数组中先后顺序并不是通过下标大小来决定,而是由push的先后决定。例如 $arr[1] = 2; $arr[2] = 3; 对于double类型的key,Zend HashTable会将他当做索引key处理
-6. PHP变量
+
+### PHP变量
+
PHP是一门弱类型语言,本身不严格区分变量的类型。PHP在变量申明的时候不需要指定类型。PHP在程序运行期间可能进行变量类型的隐示转换。和其他强类型语言一样,程序中也可以进行显示的类型转换。PHP变量可以分为简单类型(int、string、bool)、集合类型(array resource object)和常量(const)。以上所有的变量在底层都是同一种结构 zval。
Zval是zend中另一个非常重要的数据结构,用来标识并实现PHP变量,其数据结构如下:
@@ -118,7 +146,8 @@ PHP变量通过引用计数实现变量共享数据,那如果改变其中一
对于引用型变量,其要求和非引用型相反,引用赋值的变量间必须是捆绑的,修改一个变量就修改了所有捆绑变量。
-整数和浮点数
+### 整数和浮点数
+
整数、浮点数是PHP中的基础类型之一,也是一个简单型变量。对于整数和浮点数,在zvalue中直接存储对应的值。其类型分别是long和double。
从zvalue结构中可以看出,对于整数类型,和c等强类型语言不同,PHP是不区分int、unsigned int、long、long long等类型的,对它来说,整数只有一种类型也就是long。由此,可以看出,在PHP里面,整数的取值范围是由编译器位数来决定而不是固定不变的。
@@ -127,7 +156,8 @@ PHP变量通过引用计数实现变量共享数据,那如果改变其中一
在PHP中,如果整数范围越界了怎么办?这种情况下会自动转换为double类型,这个一定要小心,很多trick都是由此产生。
-字符和字符串
+### **字符和字符串**
+
和整数一样,字符变量也是PHP中的基础类型和简单型变量。通过zvalue结构可以看出,在PHP中,字符串是由由指向实际数据的指针和长度结构体组成,这点和c++中的string比较类似。由于通过一个实际变量表示长度,和c不同,它的字符串可以是2进制数据(包含\0),同时在PHP中,求字符串长度strlen是O(1)操作。
在新增、修改、追加字符串操作时,PHP都会重新分配内存生成新的字符串。最后,出于安全考虑,PHP在生成一个字符串时末尾仍然会添加\0。
@@ -136,20 +166,21 @@ PHP变量通过引用计数实现变量共享数据,那如果改变其中一
假设有如下4个变量:
-```php $strA = '123';
-
-```
-
+```php
+$strA = '123';
$strB = '456';
$intA = 123;
$intB = 456;
+```
现在对如下的几种字符串拼接方式做一个比较和说明:
// 下面两张情况,zend会重新malloc一块内存并进行相应处理,其速度一般
+```php
$res = $strA . $strB
$res = "$strA$strB"
-
+```
// 这种是速度最快的,zend会在当前strA基础上直接relloc,避免重复拷贝
+```php
$strA = $strA . $strB
// 这种速度较慢,因为需要做隐式的格式转换,实际编写程序中也应该注意尽量避免
@@ -159,12 +190,16 @@ $res = $intA . $intB
// 本身对于格式识别和处理就需要耗费比较多时间,另外本身机制也是malloc。
// 不过sprintf的方式最具可读性,实际中可以根据具体情况灵活选择。
$strA = sprintf ("%s%s", $strA . $strB);
-数组
+```
+
+### **数组**
+
PHP的数组通过Zend HashTable来天然实现。
foreach操作如何实现?对一个数组的foreach就是通过遍历hashtable中的双向链表完成。对于索引数组,通过foreach遍历效率比for高很多,省去了key->value的查找。count操作直接调用HashTable->NumOfElements,O(1)操作。对于 '123' 这样的字符串,zend会转换为其整数形式。$arr['123']和$arr[123]是等价的。
-资源
+### **资源**
+
资源类型变量是PHP中最复杂的一种变量,也是一种复合型结构。
PHP的zval可以表示广泛的数据类型,但是对于自定义的数据类型却很难充分描述。由于没有有效的方式描绘这些复合结构,因此也没有办法对它们使用传统的操作符。要解决这个问题,只需要通过一个本质上任意的标识符(label)引用指针,这种方式被称为资源。
@@ -178,7 +213,8 @@ PHP的zval可以表示广泛的数据类型,但是对于自定义的数据类
资源销毁:资源的数据类型是多种多样的。Zend本身没有办法销毁它。因此需要用户在注册资源的时候提供销毁函数。当unset资源时,zend调用相应的函数完成析构。同时从全局资源表中删除它。
资源可以长期驻留,不只是在所有引用它的变量超出作用域之后,甚至是在一个请求结束了并且新的请求产生之后。这些资源称为持久资源,因为它们贯通SAPI的整个生命周期持续存在,除非特意销毁。很多情况下,持久化资源可以在一定程度上提高性能。比如我们常见的mysql_pconnect ,持久化资源通过pemalloc分配内存,这样在请求结束的时候不会释放。 对zend来说,对两者本身并不区分。
-变量作用域
+### **变量作用域**
+
PHP中的局部变量和全局变量是如何实现的?对于一个请求,任意时刻PHP都可以看到两个符号表(symbol_table和active_symbol_table),其中前者用来维护全局变量。后者是一个指针,指向当前活动的变量符号表,当程序进入到某个函数中时,zend就会为它分配一个符号表x同时将active_symbol_table指向a。通过这样的方式实现全局、局部变量的区分。
获取变量值:PHP的符号表是通过hash_table实现的,对于每个变量都分配唯一标识,获取的时候根据标识从表中找到相应zval返回。
diff --git a/PHP/php7.md b/PHP/php7.md
index 0eebc9c..756cbd4 100644
--- a/PHP/php7.md
+++ b/PHP/php7.md
@@ -35,7 +35,7 @@ if(isset($_GET['a'])) {
$a = isset($_GET['a']) ? $_GET['a'] : 'none';
#PHP 7
-$a = isset($_GET['a']) ?? 'none';
+$a = $_GET['a'] ?? 'none';
```
@@ -50,7 +50,7 @@ function sumOfInts(int ...$ints)
{
return array_sum($ints);
}
-ar_dump(sumOfInts(2, '3', 4.1)); // int(9)
+var_dump(sumOfInts(2, '3', 4.1)); // int(9)
# 严格模式
declare(strict_types=1);
@@ -352,10 +352,8 @@ function handler(Throwable $e) { ... }
list 会按照原来的顺序进行赋值。不再是逆序了
```php
-list($a,$b,$c) = [1,2,3];
-var_dump($a);//1
-var_dump($b);//2
-var_dump($c);//3
+list($array[], $array[], $array[]) = [1, 2, 3];
+var_dump($array); // [1, 2, 3]
```
list不再支持解开字符串、
@@ -664,3 +662,111 @@ var_dump(
);
```
+## PHP 7.3
+
+#### 1. 灵活的heredoc 和nowdoc
+
+在php 7.3 之前我们定义一大段的字符串。需要用到heredoc
+
+```php
+'1','b'=>'2'];
+#php 7.3之前
+$firstKey = key(reset($array));
+# php 7.3
+$firstKey = array_key_first($array);//a
+$lastKey = array_key_last($array);//b
+```
+
+### 6.废除并移除大小写不敏感的常量
+
+你可以同时使用大小写敏感和大小写不敏感的常量。但大小写不敏感的常量会在使用中造成一点麻烦。所以,为了解决这个问题,PHP 7.3 废弃了大小写不敏感的常量。
+
+原先的情况是:
+
+- 类常量始终为「大小写敏感」。
+- 使用 `const` 关键字定义的全局常量始终为「大小写敏感」。注意此处仅仅是常量自身的名称,不包含命名空间名的部分,PHP 的命名空间始终为「大小写不敏感」。
+- 使用 `define()` 函数定义的常量默认为「大小写敏感」。
+- 使用 `define()` 函数并将第三个参数设为 `true` 定义的常量为「大小写不敏感」。
+
+如今 PHP 7.3 提议废弃并移除以下用法:
+
+- In PHP 7.3: 废弃使用 `true` 作为 `define()` 的第三个参数。
+- In PHP 7.3: 废弃使用与定义时的大小写不一致的名称,访问大小写不敏感的常量。`true`、`false` 以及 `null` 除外。
\ No newline at end of file
diff --git a/README.md b/README.md
index be3a4a0..35d7eaa 100644
--- a/README.md
+++ b/README.md
@@ -1,61 +1,59 @@
-## PHP面试准备的资料
+## PHP面试准备的资料
这个项目是自己准备面试整理的资料。可能包括PHP、MySQL等资料。方便自己以后查阅,会不定期更新,如果错误,请指出,谢谢。欢迎大家提交PR,谢谢大家的star
-有童鞋提议整理成gitbook的版本的。于是我又开了一个gitbook的分支。来完善这个。目前还没整理完成。
-
可以通过[https://xianyunyh.gitbooks.io/php-interview/](https://xianyunyh.gitbooks.io/php-interview/)预览。欢迎有精力的朋友完善一下。谢谢。
-[GITbooK分支](https://github.com/xianyunyh/PHP-Interview/tree/gitbook)
-- [Linux](https://github.com/xianyunyh/PHP-Interview/tree/master/Linux)
+### 目录
+- [Linux](Linux/REAMDE.md)
+ - [操作系统简述](操作系统/Readme.md)
+ - [进程和线程](Linux/进程和线程.md)
- [Linux基本命令](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/Linux%E5%91%BD%E4%BB%A4.md)
- - [Crontab](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/crontab.md)
- - [Shell](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/crontab.md)
- - [Linux-Inode介绍](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/inode.md)
- - [VIM编辑器]()
- - [Lnmp/Lamp](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/lanmp.md)
- - [LinuxIO模型.md](https://github.com/xianyunyh/PHP-Interview/blob/master/Linux/LinuxIO%E6%A8%A1%E5%9E%8B%E3%80%90%E9%98%BB%E5%A1%9E%E3%80%81%E9%9D%9E%E9%98%BB%E5%A1%9E%E3%80%81%E5%90%8C%E6%AD%A5%E3%80%81%E5%BC%82%E6%AD%A5%E3%80%91.md)
+ - [Crontab](Linux/crontab.md)
+ - [Shell](Linux/shell.md)
+ - [Linux-Inode介绍](Linux/inode.md)
+ - [VIM编辑器](Linux/Vim.md)
+ - [Lnmp/Lamp](Linux/lanmp.md)
+ - [LinuxIO模型.md](Linux/LinuxIO模型.md)
-- [数据库]()
+- [数据库](Mysql/README.md)
- - [MySQL](https://github.com/xianyunyh/PHP-Interview/tree/master/Mysql)
+ - [MySQL](Mysql/README.md)
- - [Mongodb](https://github.com/xianyunyh/PHP-Interview/blob/master/MongoDb/MongoDB.md)
+ - [Mongodb](MongoDb/MongoDB.md)
-- [计算机网络](https://github.com/xianyunyh/PHP-Interview/tree/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C)
+- [计算机网络](计算机网络/README.md)
- - [IP协议]()
+ - [IP协议](计算机网络/IP协议.md)
- - [TCP协议](https://github.com/xianyunyh/PHP-Interview/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/TCP%E5%8D%8F%E8%AE%AE.md)
- - [UDP协议](https://github.com/xianyunyh/PHP-Interview/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/UDP%E5%8D%8F%E8%AE%AE.md)
- - [HTTP协议](https://github.com/xianyunyh/PHP-Interview/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/HTTP%E5%8D%8F%E8%AE%AE.md)
- - [HTTPS/HTTP2/HTTP](https://github.com/xianyunyh/PHP-Interview/blob/master/%E8%AE%A1%E7%AE%97%E6%9C%BA%E7%BD%91%E7%BB%9C/HTTP2.md)
+ - [TCP协议](计算机网络/TCP协议.md)
+ - [UDP协议](计算机网络/UDP协议.md)
+ - [HTTP协议](计算机网络/HTTP协议)
+ - [HTTPS/HTTP2/HTTP](计算机网络/HTTP2.md)
-- [版本控制器](https://github.com/xianyunyh/PHP-Interview/tree/master/%E7%89%88%E6%9C%AC%E6%8E%A7%E5%88%B6%E5%99%A8)
+- [版本控制器](版本控制器/Git.md)
- - [Git](https://github.com/xianyunyh/PHP-Interview/blob/master/%E7%89%88%E6%9C%AC%E6%8E%A7%E5%88%B6%E5%99%A8/Git.md)
+ - [Git](版本控制器/Git.md)
- [SVN]()
-- [数据结构](https://github.com/xianyunyh/PHP-Interview/tree/master/%E6%95%B0%E6%8D%AE%E7%BB%93%E6%9E%84)
-
- - [数组]()
- - [链表]()
- - [单链表]()
- - [双链表]()
- - [队列]()
- - [栈]()
- - [堆]()
- - [集合]()
- - [树]()
+- [数据结构](数据结构/README.md)
+
+ - [数组](数据结构/数组.md)
+ - [链表](数据结构/链表.md)
+ - [队列](数据结构/队列.md)
+ - [栈](数据结构/栈.md)
+ - [堆](数据结构/堆.md)
+ - [集合](数据结构/集合.md)
+ - [树](数据结构/树.md)
- [二叉树 ]()
- [二叉查找树]()
- [红黑树]()
- [B-Tree、B+Tree]()
- [图]()
-- [算法](https://github.com/xianyunyh/PHP-Interview/tree/master/%E7%AE%97%E6%B3%95)
+- [算法](算法/README.md)
- [排序算法]()
- [冒泡排序](https://github.com/PuShaoWei/arithmetic-php/blob/master/package/Sort/BubbleSort.php)
@@ -79,42 +77,43 @@
- 深度优先、广度优先
- [编程之法:面试和算法心得](https://wizardforcel.gitbooks.io/the-art-of-programming-by-july/content/03.02.html)
-- [消息队列](https://github.com/xianyunyh/PHP-Interview/tree/master/MQ)
+- [消息队列](MQ/README.md)
- - [RabbitMQ](https://github.com/xianyunyh/PHP-Interview/blob/master/MQ/rabbitmq.md)
+ - [RabbitMQ](MQ/rabbitmq.md)
- [ActiveMq]()
- [Nsq]()
- [kafka]()
- [缓存系统]()
- - [Redis](https://github.com/xianyunyh/PHP-Interview/blob/master/Cache/Redis.md)
+ - [Redis](Cache/Redis.md)
- [Memcache]()
-- [PHP](https://github.com/xianyunyh/PHP-Interview/tree/master/PHP)
+- [PHP](PHP/README.md)
- - [PHP7](https://github.com/xianyunyh/PHP-Interview/blob/master/PHP/php7.md)
+ - [PHP7](PHP/php7.md)
- [面向对象OOP]()
- [Zval](https://github.com/xianyunyh/PHP-Interview/blob/master/PHP/PHP-Zval%E7%BB%93%E6%9E%84.md)
- [HashTable](https://github.com/xianyunyh/PHP-Interview/blob/master/PHP/PHP7-HashTable.md)
- [Swoole]()
-- [设计模式](https://github.com/xianyunyh/PHP-Interview/tree/master/%E8%AE%BE%E8%AE%A1%E6%A8%A1%E5%BC%8F)
+- [设计模式](设计模式/README.md)
- - [工厂模式]()
- - [单例模式]()
- - [观察者模式]()
- - [适配器模式]()
- - [门面模式]()
+- [面试](面试/README.md)
-- [面试](https://github.com/xianyunyh/PHP-Interview/tree/master/%E9%9D%A2%E8%AF%95)
-
+## 生成自己的Gitbook
-##推荐阅读资料
+```bash
+$ npm install gitbook-cli -g
+$ git clone https://github.com/xianyunyh/PHP-Interview
+$ cd PHP-Interview
+$ gitbook serve # 本地预览
+$ gitbook build # 生成静态的html
+```
+## 推荐阅读资料
- [PHP函数库](http://overapi.com/php)
-
- [PHP7内核剖析](https://github.com/pangudashu/php7-internal)
- [php7-internal](https://github.com/laruence/php7-internal)
- [PHP7-HashTable](http://nikic.github.io/2014/12/22/PHPs-new-hashtable-implementation.html)
@@ -126,3 +125,14 @@
- [程序员的内功-算法和数据结构](http://www.cnblogs.com/jingmoxukong/p/4329079.html)
- [数据结构和算法](http://www.cnblogs.com/skywang12345/p/3603935.html)
- [剑指offer-PHP实现](https://blog.csdn.net/column/details/15795.html)
+
+## 致谢
+
+- [OMGZui](https://github.com/OMGZui)
+- [fymmx](https://github.com/fymmx)
+
+
+
+如果这个系列的文章,对您有所帮助,您可以选择打赏一下作者。谢谢!
+
+
diff --git a/_config.yml b/_config.yml
new file mode 100644
index 0000000..259a24e
--- /dev/null
+++ b/_config.yml
@@ -0,0 +1 @@
+theme: jekyll-theme-tactile
\ No newline at end of file
diff --git a/mm_reward_qrcode.jpg b/mm_reward_qrcode.jpg
new file mode 100644
index 0000000..6a848e4
Binary files /dev/null and b/mm_reward_qrcode.jpg differ
diff --git "a/\346\223\215\344\275\234\347\263\273\347\273\237/Readme.md" "b/\346\223\215\344\275\234\347\263\273\347\273\237/Readme.md"
new file mode 100644
index 0000000..60290d5
--- /dev/null
+++ "b/\346\223\215\344\275\234\347\263\273\347\273\237/Readme.md"
@@ -0,0 +1,73 @@
+
+# 操作系统概论
+
+操作系统是一种计算机软件。在硬件之上,应用程序之下。主要功能就是管理底下的计算机硬件,并为上层的应用程序提供统一的接口。
+
+
+
+**系统调用**:应用程序直接调用操作系统提供的接口 如write 函数
+
+**库函数调用**:应用程序通过一些库函数直接调用 如 fwrite
+
+## 内核态和用户态
+
+操作系统为了管理内存。将内存分为**内核空间**(内核态)和**用户空间**。内存空间和用户空间之间有隔离。
+
+**用户空间即上层应用程序的活动空间**,应用程序的执行必须依托于内核提供的资源,包括CPU资源、存储资源、I/O资源等。为了使上层应用能够访问到这些资源,内核必须为上层应用提供访问的接口:即系统调用
+
+
+
+
+
+
+
+内核从本质上看是一种软件——控制计算机的硬件资源,并提供上层应用程序运行的环境。
+
+shell就是外壳。类似一种胶水的功能。可以通过shell访问内核。
+
+内核态与用户态是指CPU的运行状态(即特权级别),每个进程的每种CPU状态都有其运行上下文,运行上下文就包括了当前状态所使用的空间,CPU访问的逻辑地址(即空间)通过地址映射表映射到相应的物理地址(即物理内存)。在Linux系统中,进程的用户空间是独立的,而内核空间是公用的,进程切换时,用户空间切换,内核空间不变。
+
+对于多数CPU而言,处于内核态时,可以访问所有地址空间,而处于用户态时,就只能访问用户空间了。
+
+
+
+## 用户态和内核态切换
+
+操作系统的资源是有限的,如果访问资源的操作过多,必然会消耗过多的资源,而且如果不对这些操作加以区分,很可能造成资源访问的冲突。
+
+为了减少有限资源的访问和使用冲突,Unix/Linux的设计哲学之一就是:对不同的操作赋予不同的执行等级,就是所谓特权的概念
+
+Linux操作系统中主要采用了0和3两个特权级,分别对应的就是内核态和用户态。运行于用户态的进程可以执行的操作和访问的资源都会受到极大的限制,而运行在内核态的进程则可以执行任何操作并且在资源的使用上没有限制。很多程序开始时运行于用户态,但在执行的过程中,一些操作需要在内核权限下才能执行,这就涉及到一个从用户态切换到内核态的过程
+
+
+
+
+
+## 库函数调用和系统调用的区别
+
+
+
+系统调用(英语:system call),指运行在用户空间的应用程序向操作系统内核请求某些服务的调用过程。 系统调用提供了用户程序与操作系统之间的接口。一般来说,系统调用都在内核态执行。由于系统调用不考虑平台差异性,由内核直接提供,因而移植性较差(几乎无移植性)。
+
+库函数(library function),是由用户或组织自己开发的,具有一定功能的函数集合,一般具有较好平台移植性,通过库文件(静态库或动态库)向程序员提供功能性调用。程序员无需关心平台差异,由库来屏蔽平台差异性。
+
+| 函数库调用 | 系统调用 |
+| ----------------------------- | ----------------------- |
+| 平台移植性好 | 依赖于内核,不保证移植性 |
+| 调用函数库中的一段程序(或函数) | 调用系统内核的服务 |
+| 一个普通功能函数的调用 | 是操作系统的一个入口点 |
+| 在**用户空间**执行 | 在**内核空间**执行 |
+| 它的运行时间属于“用户时间” | 它的运行时间属于“系统”时间 |
+| 属于过程调用,调用开销较小 | 在用户空间和内核上下文环境间切换,开销较大 |
+| 库函数数量较多 | UNIX中大约有90个系统调用,较少 |
+| 典型的C函数库调用:printf scanf malloc | 典型的系统调用:fork open write |
+
+
+
+读写IO通常是大量的数据(这种大量是相对于底层驱动的系统调用所实现的数据操作单位而言),使用库函数调用可以大大减少系统调用的次数。这是因为缓冲区技术。在用户空间和内核空间,对文件操作都使用了缓冲区,当内核缓冲区写满之后或写结束之后才将内核缓冲区内容写到文件对应的硬件媒介中。
+
+**不带缓冲指的是每个read和write这些文件I/O操作都调用的是系统调用,属于内核态的操作**
+
+诸如fread和fwrite这些标准I/O操作属于用户态操作,具体是库函数的实现,需要借助用户缓冲区来实现
+
+更多内容可以参考 [操作系统](https://github.com/xianyunyh/studynotes/tree/master/%E6%93%8D%E4%BD%9C%E7%B3%BB%E7%BB%9F)
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/Leetcode\347\273\217\345\205\270\344\272\214\345\217\211\346\240\221\351\242\230\347\233\256\351\233\206\345\220\210.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/Leetcode\347\273\217\345\205\270\344\272\214\345\217\211\346\240\221\351\242\230\347\233\256\351\233\206\345\220\210.md"
new file mode 100644
index 0000000..e31bb76
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/Leetcode\347\273\217\345\205\270\344\272\214\345\217\211\346\240\221\351\242\230\347\233\256\351\233\206\345\220\210.md"
@@ -0,0 +1,625 @@
+## :pencil2:Leetcode经典二叉树题目集合
+
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+****
+### :pencil2:1.二叉树的前序遍历(leetcode144)
+
+
+  +
+
+**前序遍历,先访问根结点,然后在访问左子树,最后访问右子树。可以利用栈的特点,这里我结合了队列和栈的特点来实现。先压入树,取出根节点。先把根节点值push到队列中,然后把右子树压入栈中,最后压入左子树。返回队列。当然你可以调整成你想要的实现方式。(只要前中后序顺序理解正确即可)**
+
+```php
+
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * public $val = null;
+ * public $left = null;
+ * public $right = null;
+ * function __construct($value) { $this->val = $value; }
+ * }
+ */
+
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function preorderTraversal($root) {
+ $res=[];
+ $list=[];
+ array_unshift($res,$root);
+ while(!empty($res)){
+ $current=array_shift($res);
+ if($current==null) continue;
+ array_push($list,$current->val);
+ array_unshift($res,$current->right);
+ array_unshift($res,$current->left);
+ }
+ return $list;
+ }
+}
+
+```
+
+****
+
+### :pencil2:2.二叉树的中序遍历(leetcode94)
+
+
+
+
+
+**前序遍历,先访问根结点,然后在访问左子树,最后访问右子树。可以利用栈的特点,这里我结合了队列和栈的特点来实现。先压入树,取出根节点。先把根节点值push到队列中,然后把右子树压入栈中,最后压入左子树。返回队列。当然你可以调整成你想要的实现方式。(只要前中后序顺序理解正确即可)**
+
+```php
+
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * public $val = null;
+ * public $left = null;
+ * public $right = null;
+ * function __construct($value) { $this->val = $value; }
+ * }
+ */
+
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function preorderTraversal($root) {
+ $res=[];
+ $list=[];
+ array_unshift($res,$root);
+ while(!empty($res)){
+ $current=array_shift($res);
+ if($current==null) continue;
+ array_push($list,$current->val);
+ array_unshift($res,$current->right);
+ array_unshift($res,$current->left);
+ }
+ return $list;
+ }
+}
+
+```
+
+****
+
+### :pencil2:2.二叉树的中序遍历(leetcode94)
+
+
+  +
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function inorderTraversal($root) {
+ $res=[];
+ $this->helper($root,$res);
+ return $res;
+ }
+ function helper($root,&$res){
+ if($root !=null){
+ if($root->left !=null) $this->helper($root->left,$res);
+ array_push($res,$root->val);
+ if($root->right !=null) $this->helper($root->right,$res);
+ }
+
+ }
+```
+
+**或者不用递归**
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function inorderTraversal($root) {
+ $res=[];
+ $list=[];
+ while(!empty($list) || $root !=null){
+ while($root != null){
+ array_unshift($list,$root);
+ $root=$root->left;
+ }
+ $root=array_shift($list);
+ array_push($res,$root->val);
+ $root=$root->right;
+ }
+ return $res;
+ }
+```
+****
+
+
+### :pencil2:3.二叉树的后序遍历(leetcode145)
+
+
+
+
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function inorderTraversal($root) {
+ $res=[];
+ $this->helper($root,$res);
+ return $res;
+ }
+ function helper($root,&$res){
+ if($root !=null){
+ if($root->left !=null) $this->helper($root->left,$res);
+ array_push($res,$root->val);
+ if($root->right !=null) $this->helper($root->right,$res);
+ }
+
+ }
+```
+
+**或者不用递归**
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function inorderTraversal($root) {
+ $res=[];
+ $list=[];
+ while(!empty($list) || $root !=null){
+ while($root != null){
+ array_unshift($list,$root);
+ $root=$root->left;
+ }
+ $root=array_shift($list);
+ array_push($res,$root->val);
+ $root=$root->right;
+ }
+ return $res;
+ }
+```
+****
+
+
+### :pencil2:3.二叉树的后序遍历(leetcode145)
+
+
+  +
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function postorderTraversal($root) {
+ $list=[];
+ $res=[];
+ array_push($list,$root);
+ while(!empty($list)){
+ $node=array_shift($list);
+ if(!$node) continue;
+ array_unshift($res,$node->val);
+ array_unshift($list,$node->left);
+ array_unshift($list,$node->right);
+ }
+ return $res;
+ }
+ }
+```
+****
+
+### :pencil2:4.二叉树的层次遍历(leetcode102)
+
+
+
+
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer[]
+ */
+ function postorderTraversal($root) {
+ $list=[];
+ $res=[];
+ array_push($list,$root);
+ while(!empty($list)){
+ $node=array_shift($list);
+ if(!$node) continue;
+ array_unshift($res,$node->val);
+ array_unshift($list,$node->left);
+ array_unshift($list,$node->right);
+ }
+ return $res;
+ }
+ }
+```
+****
+
+### :pencil2:4.二叉树的层次遍历(leetcode102)
+
+
+  +
+
+**DFS和BFS都可以解,竟然已经要我们按照层打印了,那么先使用BFS,思路就是先判断树是否是空,不是空加入一个队列的结构中,如果队列不为空,取出头元素,那么当前元素表示的就是当前这一层了,所以只需要遍历这一层里的所有的元素即可,然后下一层....**
+
+```php
+ class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Integer[][]
+ */
+ function levelOrder($root) {
+ if(empty($root)) return [];
+ $result = [];
+ $queue = [];
+ array_push($queue,$root);
+ while(!empty($queue)){
+ $count = count($queue);
+ $leveQueue = [];
+ for($i = 0;$i<$count;$i++){
+ $node = array_shift($queue);
+ array_push($leveQueue,$node->val);
+ if($node->left) array_push($queue,$node->left);
+ if($node->right) array_push($queue,$node->right);
+ }
+ array_push($result,$leveQueue);
+ }
+ return $result;
+ }
+ }
+```
+
+**如果使用DFS的话,就是一条路走到黑,然后再重新一路路的退回来再找下一路,所以这样的话,每一次我们需要记录一下当前他所在的这个点属于哪一层即可,代码用递归实现。**
+```php
+
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Integer[][]
+ */
+ function levelOrder($root) {
+ if(empty($root)) return [];
+ $result=[];
+ $this->helper($result,$root,0);
+ return $result;
+ }
+
+ function helper(&$result,$node,$level){
+ if(empty($node)) return ;
+ if(count($result)<$level+1){
+ array_push($result,[]); //说明当前行没有结果
+ }
+ array_push($result[$level],$node->val);
+ $this->helper($result,$node->left,$level+1);
+ $this->helper($result,$node->right,$level+1);
+ }
+}
+
+```
+****
+
+### :pencil2:5.二叉树的最大深度(leetcode104)
+
+
+
+
+
+**DFS和BFS都可以解,竟然已经要我们按照层打印了,那么先使用BFS,思路就是先判断树是否是空,不是空加入一个队列的结构中,如果队列不为空,取出头元素,那么当前元素表示的就是当前这一层了,所以只需要遍历这一层里的所有的元素即可,然后下一层....**
+
+```php
+ class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Integer[][]
+ */
+ function levelOrder($root) {
+ if(empty($root)) return [];
+ $result = [];
+ $queue = [];
+ array_push($queue,$root);
+ while(!empty($queue)){
+ $count = count($queue);
+ $leveQueue = [];
+ for($i = 0;$i<$count;$i++){
+ $node = array_shift($queue);
+ array_push($leveQueue,$node->val);
+ if($node->left) array_push($queue,$node->left);
+ if($node->right) array_push($queue,$node->right);
+ }
+ array_push($result,$leveQueue);
+ }
+ return $result;
+ }
+ }
+```
+
+**如果使用DFS的话,就是一条路走到黑,然后再重新一路路的退回来再找下一路,所以这样的话,每一次我们需要记录一下当前他所在的这个点属于哪一层即可,代码用递归实现。**
+```php
+
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Integer[][]
+ */
+ function levelOrder($root) {
+ if(empty($root)) return [];
+ $result=[];
+ $this->helper($result,$root,0);
+ return $result;
+ }
+
+ function helper(&$result,$node,$level){
+ if(empty($node)) return ;
+ if(count($result)<$level+1){
+ array_push($result,[]); //说明当前行没有结果
+ }
+ array_push($result[$level],$node->val);
+ $this->helper($result,$node->left,$level+1);
+ $this->helper($result,$node->right,$level+1);
+ }
+}
+
+```
+****
+
+### :pencil2:5.二叉树的最大深度(leetcode104)
+
+
+  +
+
+**DFS和BFS都可以解,竟然已经要我们按照层打印了,那么先使用BFS,思路就是先判断树是否是空,不是空加入一个队列的结构中,如果队列不为空,取出头元素,那么当前元素表示的就是当前这一层了,所以只需要遍历这一层里的所有的元素即可,然后下一层....**
+
+```php
+
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function maxDepth($root) {
+ if(empty($root)) return 0;
+ $left = $this->maxDepth($root->left);
+ $right = $this->maxDepth($root->right);
+ return $left<$right? $right+1:$left+1;
+ return max($left,$right)+1;
+ }
+```
+****
+
+### :pencil2:6.二叉树的最小深度(leetcode111)
+
+
+
+
+
+**DFS和BFS都可以解,竟然已经要我们按照层打印了,那么先使用BFS,思路就是先判断树是否是空,不是空加入一个队列的结构中,如果队列不为空,取出头元素,那么当前元素表示的就是当前这一层了,所以只需要遍历这一层里的所有的元素即可,然后下一层....**
+
+```php
+
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function maxDepth($root) {
+ if(empty($root)) return 0;
+ $left = $this->maxDepth($root->left);
+ $right = $this->maxDepth($root->right);
+ return $left<$right? $right+1:$left+1;
+ return max($left,$right)+1;
+ }
+```
+****
+
+### :pencil2:6.二叉树的最小深度(leetcode111)
+
+
+  +
+
+**DFS和BFS都可以求解**
+
+```php
+
+ //BFS
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function minDepth($root) {
+ if(empty($root)) return 0;
+ if(!$root->right) return $this->minDepth($root->left)+1;
+ if(!$root->left) return $this->minDepth($root->right)+1;
+ $left=$this->minDepth($root->left);
+ $right=$this->minDepth($root->right);
+ return min($left,$right)+1;
+
+ }
+```
+
+```php
+
+//DFS
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function minDepth($root) {
+ if(empty($root)) return 0;
+ $left=$this->minDepth($root->left);
+ $right=$this->minDepth($root->right);
+ if($left==0 || $right==0) return $left+$right+1;
+ return min($left,$right)+1;
+ }
+```
+****
+
+
+### :pencil2:7.判断是否是平衡二叉树(leetcode110)
+
+
+
+
+
+**DFS和BFS都可以求解**
+
+```php
+
+ //BFS
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function minDepth($root) {
+ if(empty($root)) return 0;
+ if(!$root->right) return $this->minDepth($root->left)+1;
+ if(!$root->left) return $this->minDepth($root->right)+1;
+ $left=$this->minDepth($root->left);
+ $right=$this->minDepth($root->right);
+ return min($left,$right)+1;
+
+ }
+```
+
+```php
+
+//DFS
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function minDepth($root) {
+ if(empty($root)) return 0;
+ $left=$this->minDepth($root->left);
+ $right=$this->minDepth($root->right);
+ if($left==0 || $right==0) return $left+$right+1;
+ return min($left,$right)+1;
+ }
+```
+****
+
+
+### :pencil2:7.判断是否是平衡二叉树(leetcode110)
+
+
+  +
+
+**每一节点的两个子树的深度相差不能超过1。如果是空树,直接true。**
+
+```php
+
+
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Boolean
+ */
+ private $result=true;
+ function isBalanced($root) {
+ if(empty($root)) return true;
+ $this->helper($root);
+ return $this->result;
+ }
+ function helper($root)
+{
+ if(!$root) return ;
+ $left=$this->helper($root->left);
+ $right=$this->helper($root->right);
+ if(abs($left-$right)>1) $this->result=false;
+ return max($left,$right)+1;
+ }
+}
+```
+****
+
+
+### :pencil2:8.判断是否是对称二叉树(leetcode101)
+
+
+
+
+
+**每一节点的两个子树的深度相差不能超过1。如果是空树,直接true。**
+
+```php
+
+
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Boolean
+ */
+ private $result=true;
+ function isBalanced($root) {
+ if(empty($root)) return true;
+ $this->helper($root);
+ return $this->result;
+ }
+ function helper($root)
+{
+ if(!$root) return ;
+ $left=$this->helper($root->left);
+ $right=$this->helper($root->right);
+ if(abs($left-$right)>1) $this->result=false;
+ return max($left,$right)+1;
+ }
+}
+```
+****
+
+
+### :pencil2:8.判断是否是对称二叉树(leetcode101)
+
+
+  +
+
+**1.两个子节点都是空,那说明他们是对称的返回true**
+
+**2.一个子节点为空,另一个子节点不为空,false**
+
+**3.两个子节点都不为空,但是他们不相等,false**
+
+**4.两个子节点不为空且相等,继续判断他们的左子树和右子树,把左子树的左子节点和右子树的右子节点进行比较,把左子树的右子节点和右子树的左子节点进行比较**
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Boolean
+ */
+ function isSymmetric($root) {
+ if(empty($root)) return true;
+ return $this->helper($root->left,$root->right);
+ }
+ function helper($l,$r){
+ if(!$l && !$r) return true;
+ if(!$l || !$r || $l->val != $r->val) return false;
+ return $this->helper($l->left ,$r->right) && $this->helper($l->right,$r->left);
+ }
+```
+****
+
+### :pencil2:9.反转二叉树(leetcode226)
+
+
+
+
+
+**1.两个子节点都是空,那说明他们是对称的返回true**
+
+**2.一个子节点为空,另一个子节点不为空,false**
+
+**3.两个子节点都不为空,但是他们不相等,false**
+
+**4.两个子节点不为空且相等,继续判断他们的左子树和右子树,把左子树的左子节点和右子树的右子节点进行比较,把左子树的右子节点和右子树的左子节点进行比较**
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Boolean
+ */
+ function isSymmetric($root) {
+ if(empty($root)) return true;
+ return $this->helper($root->left,$root->right);
+ }
+ function helper($l,$r){
+ if(!$l && !$r) return true;
+ if(!$l || !$r || $l->val != $r->val) return false;
+ return $this->helper($l->left ,$r->right) && $this->helper($l->right,$r->left);
+ }
+```
+****
+
+### :pencil2:9.反转二叉树(leetcode226)
+
+
+  +
+
+```php
+
+ /**
+ * @param TreeNode $root
+ * @return TreeNode
+ */
+ function invertTree($root) {
+ if(!$root) return null;
+ $list=[];
+ array_push($list,$root);
+ while(!empty($list)){
+ $node=array_shift($list);
+ $temp=$node->left;
+ $node->left=$node->right;
+ $node->right=$temp;
+ if($node->left) array_push($list,$node->left);
+ if($node->right) array_push($list,$node->right);
+ }
+ return $root;
+ }
+```
+**递归解**
+```php
+ /**
+ * @param TreeNode $root
+ * @return TreeNode
+ */
+ function invertTree($root) {
+ if(empty($root)){
+ return null;
+ }
+ $right=$this->invertTree($root->right);
+ $left=$this->invertTree($root->left);
+ $root->left=$right;
+ $root->right=$left;
+ return $root;
+ }
+```
+****
+
+
+### :pencil2:10.给定单链表(值有序)转化成平衡二叉查找树(leetcode109)
+
+
+
+
+
+```php
+
+ /**
+ * @param TreeNode $root
+ * @return TreeNode
+ */
+ function invertTree($root) {
+ if(!$root) return null;
+ $list=[];
+ array_push($list,$root);
+ while(!empty($list)){
+ $node=array_shift($list);
+ $temp=$node->left;
+ $node->left=$node->right;
+ $node->right=$temp;
+ if($node->left) array_push($list,$node->left);
+ if($node->right) array_push($list,$node->right);
+ }
+ return $root;
+ }
+```
+**递归解**
+```php
+ /**
+ * @param TreeNode $root
+ * @return TreeNode
+ */
+ function invertTree($root) {
+ if(empty($root)){
+ return null;
+ }
+ $right=$this->invertTree($root->right);
+ $left=$this->invertTree($root->left);
+ $root->left=$right;
+ $root->right=$left;
+ return $root;
+ }
+```
+****
+
+
+### :pencil2:10.给定单链表(值有序)转化成平衡二叉查找树(leetcode109)
+
+
+  +
+
+**先将链表数据转换成有序数组,然后利用二分查找的特性,构建左右子树。**
+
+```php
+
+/**
+ * Definition for a singly-linked list.
+ * class ListNode {
+ * public $val = 0;
+ * public $next = null;
+ * function __construct($val) { $this->val = $val; }
+ * }
+ */
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * public $val = null;
+ * public $left = null;
+ * public $right = null;
+ * function __construct($value) { $this->val = $value; }
+ * }
+ */
+class Solution {
+
+ /**
+ * @param ListNode $head
+ * @return TreeNode
+ */
+ function sortedListToBST($head) {
+ $data=[];
+ while($head){
+ array_push($data,$head->val);
+ $head=$head->next;
+ }
+ return $this->helper($data);
+ }
+
+ function helper($data)
+{
+ if(!$data) return ;
+ $middle=floor(count($data)/2);
+ $node=new TreeNode($data[$middle]);
+ $node->left=$this->helper(array_slice($data,0,$middle));
+ $node->right=$this->helper(array_slice($data,$middle+1));
+ return $node;
+ }
+}
+```
+****
+
+
+### :pencil2:11.强盗打劫版本3(leetcode337)
+
+
+
+
+
+**先将链表数据转换成有序数组,然后利用二分查找的特性,构建左右子树。**
+
+```php
+
+/**
+ * Definition for a singly-linked list.
+ * class ListNode {
+ * public $val = 0;
+ * public $next = null;
+ * function __construct($val) { $this->val = $val; }
+ * }
+ */
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * public $val = null;
+ * public $left = null;
+ * public $right = null;
+ * function __construct($value) { $this->val = $value; }
+ * }
+ */
+class Solution {
+
+ /**
+ * @param ListNode $head
+ * @return TreeNode
+ */
+ function sortedListToBST($head) {
+ $data=[];
+ while($head){
+ array_push($data,$head->val);
+ $head=$head->next;
+ }
+ return $this->helper($data);
+ }
+
+ function helper($data)
+{
+ if(!$data) return ;
+ $middle=floor(count($data)/2);
+ $node=new TreeNode($data[$middle]);
+ $node->left=$this->helper(array_slice($data,0,$middle));
+ $node->right=$this->helper(array_slice($data,$middle+1));
+ return $node;
+ }
+}
+```
+****
+
+
+### :pencil2:11.强盗打劫版本3(leetcode337)
+
+
+  +
+
+**最后的目的算出最多能抢金额数而不触发报警器。除了根节点,每一个结点只有一个父节点,能直接相连的两个节点不能同时抢,比如图1,抢了根节点,直接相连的左右子结点就不能抢。所以要么抢根节点的左右子结点,要么根结点+根结点->left->right+根结点->right->right。**
+
+
+```php
+
+//递归
+/**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function rob($root) {
+ if($root==null){
+ return 0;
+ }
+ $res1=$root->val;
+ if($root->left !=null) {
+ $res1 +=$this->rob($root->left->left)+$this->rob($root->left->right);
+ }
+ if($root->right !=null){
+ $res1 +=$this->rob($root->right->left)+$this->rob($root->right->right);
+ }
+
+ $res2=$this->rob($root->left)+$this->rob($root->right);
+ return max($res1,$res2);
+
+ }
+```
+
+**上面那种大量的重复计算,改进一下。**
+
+ **如果结点不存在直接返回0,对左右结点分别递归,设置了4个变量,ll和lr分别表示左子结点的左右子结点的最大金额数,rl和rr分别表示右子结点的左右子结点的最大金额数。所以我们最后比较的还是两种情况,第一种就是当前结点+左右子结点的左右子结点的值(即这里定义的ll,lr,rl,rr).第二种是当前结点的左右子结点的值(也就是说我只抢当前结点的子结点,不抢当前结点和孙子结点),再通俗的说就是如果树的层数是3层,要么抢中间一层,要么抢上下两层,谁钱多抢谁。**
+
+ ```php
+/**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function rob($root) {
+ $l=0;$r=0;
+ return $this->countMax($root,$l,$r);
+ }
+ function countMax($root,&$l,&$r){
+ if($root==null) return 0;
+ $ll=0;$lr=0;$rl=0;$rr=0;
+ $l=$this->countMax($root->left,$ll,$lr);
+ $r=$this->countMax($root->right,$rl,$rr);
+ return max($root->val+$ll+$lr+$rl+$rr,$l+$r);
+ }
+```
+****
+
+### :pencil2:12.判断二叉树路径和是否存在(leetcode112)
+
+
+
+
+
+**最后的目的算出最多能抢金额数而不触发报警器。除了根节点,每一个结点只有一个父节点,能直接相连的两个节点不能同时抢,比如图1,抢了根节点,直接相连的左右子结点就不能抢。所以要么抢根节点的左右子结点,要么根结点+根结点->left->right+根结点->right->right。**
+
+
+```php
+
+//递归
+/**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function rob($root) {
+ if($root==null){
+ return 0;
+ }
+ $res1=$root->val;
+ if($root->left !=null) {
+ $res1 +=$this->rob($root->left->left)+$this->rob($root->left->right);
+ }
+ if($root->right !=null){
+ $res1 +=$this->rob($root->right->left)+$this->rob($root->right->right);
+ }
+
+ $res2=$this->rob($root->left)+$this->rob($root->right);
+ return max($res1,$res2);
+
+ }
+```
+
+**上面那种大量的重复计算,改进一下。**
+
+ **如果结点不存在直接返回0,对左右结点分别递归,设置了4个变量,ll和lr分别表示左子结点的左右子结点的最大金额数,rl和rr分别表示右子结点的左右子结点的最大金额数。所以我们最后比较的还是两种情况,第一种就是当前结点+左右子结点的左右子结点的值(即这里定义的ll,lr,rl,rr).第二种是当前结点的左右子结点的值(也就是说我只抢当前结点的子结点,不抢当前结点和孙子结点),再通俗的说就是如果树的层数是3层,要么抢中间一层,要么抢上下两层,谁钱多抢谁。**
+
+ ```php
+/**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function rob($root) {
+ $l=0;$r=0;
+ return $this->countMax($root,$l,$r);
+ }
+ function countMax($root,&$l,&$r){
+ if($root==null) return 0;
+ $ll=0;$lr=0;$rl=0;$rr=0;
+ $l=$this->countMax($root->left,$ll,$lr);
+ $r=$this->countMax($root->right,$rl,$rr);
+ return max($root->val+$ll+$lr+$rl+$rr,$l+$r);
+ }
+```
+****
+
+### :pencil2:12.判断二叉树路径和是否存在(leetcode112)
+
+
+  +
+
+**只要使用深度优先算法思想遍历每一条完整的路径,如果是个空树直接false,如果结点没有左右子树(说明此时已然是叶子结点,判断值是否是给定值,这个条件正好是递归终止的条件),相等直接返回true,根据这个推导出递归公式。**
+
+```php
+/**
+ * @param TreeNode $root
+ * @param Integer $sum
+ * @return Boolean
+ */
+ function hasPathSum($root, $sum) {
+ if($root==null){
+ return false;
+ }
+ if($root->left ==null && $root->right==null && $root->val==$sum) return true;
+ return $this->hasPathSum($root->left,$sum-$root->val) || $this->hasPathSum($root->right,$sum-$root->val);
+ }
+```
+
+**改成迭代**
+
+```php
+
+/**
+ * @param TreeNode $root
+ * @param Integer $sum
+ * @return Boolean
+ */
+ function hasPathSum($root, $sum) {
+ if($root==null){
+ return false;
+ }
+ $res=[];
+ array_push($res,$root);
+ while(!empty($res)){
+ $node=array_shift($res);
+ if(!$node->left && !$node->right ){
+ if($node->val==$sum) return true;
+ }
+ if($node->left){
+ $node->left->val +=$node->val;
+ array_push($res,$node->left);
+ }
+ if($node->right){
+ $node->right->val +=$node->val;
+ array_push($res,$node->right);
+ }
+ }
+ return false;
+ }
+```
+****
+
+
+### :pencil2:13.判断是否是二叉查找树(leetcode98)
+
+
+
+
+
+**只要使用深度优先算法思想遍历每一条完整的路径,如果是个空树直接false,如果结点没有左右子树(说明此时已然是叶子结点,判断值是否是给定值,这个条件正好是递归终止的条件),相等直接返回true,根据这个推导出递归公式。**
+
+```php
+/**
+ * @param TreeNode $root
+ * @param Integer $sum
+ * @return Boolean
+ */
+ function hasPathSum($root, $sum) {
+ if($root==null){
+ return false;
+ }
+ if($root->left ==null && $root->right==null && $root->val==$sum) return true;
+ return $this->hasPathSum($root->left,$sum-$root->val) || $this->hasPathSum($root->right,$sum-$root->val);
+ }
+```
+
+**改成迭代**
+
+```php
+
+/**
+ * @param TreeNode $root
+ * @param Integer $sum
+ * @return Boolean
+ */
+ function hasPathSum($root, $sum) {
+ if($root==null){
+ return false;
+ }
+ $res=[];
+ array_push($res,$root);
+ while(!empty($res)){
+ $node=array_shift($res);
+ if(!$node->left && !$node->right ){
+ if($node->val==$sum) return true;
+ }
+ if($node->left){
+ $node->left->val +=$node->val;
+ array_push($res,$node->left);
+ }
+ if($node->right){
+ $node->right->val +=$node->val;
+ array_push($res,$node->right);
+ }
+ }
+ return false;
+ }
+```
+****
+
+
+### :pencil2:13.判断是否是二叉查找树(leetcode98)
+
+
+  +
+
+**思路有两种,二叉查找树的特点就是左子树上的结点都小于根结点,右子树上的结点都大于根节点。所以有两个方向,可以分别递归的判断左子树,右子树。或者拿左子树上的最大值,右子树上的最小值分别对应根结点进行判断。**
+
+```php
+
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * public $val = null;
+ * public $left = null;
+ * public $right = null;
+ * function __construct($value) { $this->val = $value; }
+ * }
+ */
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Boolean
+ */
+ function isValidBST($root) {
+ return $this->helper($root,null,null);
+ }
+ function helper($root,$lower,$upper){
+ if($root==null) return true;
+ $res=$root->val;
+ if($lower !==null && $res<=$lower) return false;
+ if($upper !==null && $res>=$upper) return false;
+ if(!$this->helper($root->left,$lower,$res)) return false;
+ if(!$this->helper($root->right,$res,$upper)) return false;
+ return true;
+ }
+}
+```
+****
+
+
+### :pencil2:14.找出二叉树最后一层最左边的值(leetcode513)
+
+
+
+
+
+**思路有两种,二叉查找树的特点就是左子树上的结点都小于根结点,右子树上的结点都大于根节点。所以有两个方向,可以分别递归的判断左子树,右子树。或者拿左子树上的最大值,右子树上的最小值分别对应根结点进行判断。**
+
+```php
+
+/**
+ * Definition for a binary tree node.
+ * class TreeNode {
+ * public $val = null;
+ * public $left = null;
+ * public $right = null;
+ * function __construct($value) { $this->val = $value; }
+ * }
+ */
+class Solution {
+
+ /**
+ * @param TreeNode $root
+ * @return Boolean
+ */
+ function isValidBST($root) {
+ return $this->helper($root,null,null);
+ }
+ function helper($root,$lower,$upper){
+ if($root==null) return true;
+ $res=$root->val;
+ if($lower !==null && $res<=$lower) return false;
+ if($upper !==null && $res>=$upper) return false;
+ if(!$this->helper($root->left,$lower,$res)) return false;
+ if(!$this->helper($root->right,$res,$upper)) return false;
+ return true;
+ }
+}
+```
+****
+
+
+### :pencil2:14.找出二叉树最后一层最左边的值(leetcode513)
+
+
+  +
+
+**思路有两种,二叉查找树的特点就是左子树上的结点都小于根结点,右子树上的结点都大于根节点。所以有两个方向,可以分别递归的判断左子树,右子树。或者拿左子树上的最大值,右子树上的最小值分别对应根结点进行判断。**
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function findBottomLeftValue($root) {
+ $data=[];
+ array_push($data,$root);
+ while(!empty($data)){
+ $node = array_shift($data);
+ if($node->right) array_push($data,$node->right);
+ if($node->left) array_push($data,$node->left);
+ }
+ return $node->val;
+ }
+```
+****
+
+### 联系
+
+
+
+
+
+**思路有两种,二叉查找树的特点就是左子树上的结点都小于根结点,右子树上的结点都大于根节点。所以有两个方向,可以分别递归的判断左子树,右子树。或者拿左子树上的最大值,右子树上的最小值分别对应根结点进行判断。**
+
+```php
+ /**
+ * @param TreeNode $root
+ * @return Integer
+ */
+ function findBottomLeftValue($root) {
+ $data=[];
+ array_push($data,$root);
+ while(!empty($data)){
+ $node = array_shift($data);
+ if($node->right) array_push($data,$node->right);
+ if($node->left) array_push($data,$node->left);
+ }
+ return $node->val;
+ }
+```
+****
+
+### 联系
+
+
+  +
+
+
+
+
+
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\344\272\214\345\217\211\346\240\221\345\237\272\346\234\254\346\223\215\344\275\234.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\344\272\214\345\217\211\346\240\221\345\237\272\346\234\254\346\223\215\344\275\234.md"
new file mode 100644
index 0000000..766ea8e
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\344\272\214\345\217\211\346\240\221\345\237\272\346\234\254\346\223\215\344\275\234.md"
@@ -0,0 +1,228 @@
+## :数据结构线性表之二叉树1
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+
+
+
+
+
+
+
+
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\344\272\214\345\217\211\346\240\221\345\237\272\346\234\254\346\223\215\344\275\234.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\344\272\214\345\217\211\346\240\221\345\237\272\346\234\254\346\223\215\344\275\234.md"
new file mode 100644
index 0000000..766ea8e
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\344\272\214\345\217\211\346\240\221\345\237\272\346\234\254\346\223\215\344\275\234.md"
@@ -0,0 +1,228 @@
+## :数据结构线性表之二叉树1
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+
+  +
+
+### :pencil2:一.二叉树的定义
+**既然都叫二叉树了,那么二叉树的特点是每个至多只有两棵子树。换句话来说,每个结点的度不超过两个,并且二叉树的子树还存在左右之分,它的次序不能任意颠倒。**
+### :pencil2:二叉树的表现形态
+
+
+
+
+
+### :pencil2:一.二叉树的定义
+**既然都叫二叉树了,那么二叉树的特点是每个至多只有两棵子树。换句话来说,每个结点的度不超过两个,并且二叉树的子树还存在左右之分,它的次序不能任意颠倒。**
+### :pencil2:二叉树的表现形态
+
+
+  +
+
+**1.满二叉树:棵深度为k有且有2^k-1结点的树称之为满二叉树,比如图中的a(深度为4,拥有15个结点)。这里我们就可以得到二叉树的一个特性:在二叉树的第i层中至多有2^i-1个结点(i>=1)。当然了他不止这一个特性。。。**
+
+**2.完全二叉树:深度为k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n一一对应时,才是完全二叉树。这里图c不是完全二叉树,假设根节点A是1,那么图c在n等于12这个点上就没有对应。所以不是完全二叉树。所以完全二叉树的特点:(1)叶子结点只可能在层次最大的两层上出现。(2)对任意一个结点,若其右子树的最大层次是l,那么其左子树的最大层数必须是l或者l+1。**
+
+**三·二叉树的存储树这种结构的存储不像线性结构那样简单,并不能直接用前后关系来描述。一个树有有很多的子树,一个结点不止一个后继。下面用图来说明用数组存储和链表存储。**
+
+### :pencil2:三.二叉树的存储
+
+
+
+
+
+**1.满二叉树:棵深度为k有且有2^k-1结点的树称之为满二叉树,比如图中的a(深度为4,拥有15个结点)。这里我们就可以得到二叉树的一个特性:在二叉树的第i层中至多有2^i-1个结点(i>=1)。当然了他不止这一个特性。。。**
+
+**2.完全二叉树:深度为k,有n个结点的二叉树,当且仅当其每一个结点都与深度为k的满二叉树中编号从1至n一一对应时,才是完全二叉树。这里图c不是完全二叉树,假设根节点A是1,那么图c在n等于12这个点上就没有对应。所以不是完全二叉树。所以完全二叉树的特点:(1)叶子结点只可能在层次最大的两层上出现。(2)对任意一个结点,若其右子树的最大层次是l,那么其左子树的最大层数必须是l或者l+1。**
+
+**三·二叉树的存储树这种结构的存储不像线性结构那样简单,并不能直接用前后关系来描述。一个树有有很多的子树,一个结点不止一个后继。下面用图来说明用数组存储和链表存储。**
+
+### :pencil2:三.二叉树的存储
+
+
+  +
+
+**按照顺序存储的结构。用一组连续的存储单元至上而下,至左到右存储,图中的0表示不存在该结点,每一个不存在的点我们都需要浪费一个空间。所以在最坏的情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)却需要长度为2^k-1的一维数组。所以这种顺序存储适合完全二叉树。**
+
+
+
+
+
+**按照顺序存储的结构。用一组连续的存储单元至上而下,至左到右存储,图中的0表示不存在该结点,每一个不存在的点我们都需要浪费一个空间。所以在最坏的情况下,一个深度为k且只有k个结点的单支树(树中不存在度为2的结点)却需要长度为2^k-1的一维数组。所以这种顺序存储适合完全二叉树。**
+
+
+  +
+
+**链式存储的结构是由一个数据元素和分别指向其左右子树的两个分支构成。包含了三个域:数据域,左右指针域。链表的头指向树的根节点。**
+
+### :pencil2:四·二叉树的前中后序遍历
+```php
+
+//二叉树
+class Tree{
+ public $res='';
+ public $left=null;
+ public $right=null;
+ public function __construct($res)
+{
+ $this->res=$res;
+ }
+
+}
+//前序遍历
+ function front($tree){
+ if($tree==null){
+ return ;
+ }
+ echo $tree->res.'
+
+
+**链式存储的结构是由一个数据元素和分别指向其左右子树的两个分支构成。包含了三个域:数据域,左右指针域。链表的头指向树的根节点。**
+
+### :pencil2:四·二叉树的前中后序遍历
+```php
+
+//二叉树
+class Tree{
+ public $res='';
+ public $left=null;
+ public $right=null;
+ public function __construct($res)
+{
+ $this->res=$res;
+ }
+
+}
+//前序遍历
+ function front($tree){
+ if($tree==null){
+ return ;
+ }
+ echo $tree->res.'
';
+ front($tree->left);
+ front($tree->right);
+}
+
+//中序遍历
+ function middle($tree)
+{
+ if($tree==null){
+ return ;
+ }
+ middle($tree->left);
+ echo $tree->res.'
';
+ middle($tree->right);
+ }
+
+//后序遍历
+ function backend($tree)
+{
+ if($tree==null){
+ return ;
+ }
+ backend($tree->right);
+ backend($tree->left);
+ echo $tree->res.'
';
+}
+
+$treeA=new Tree('a');
+$treeB=new Tree('b');
+$treeC=new Tree('c');
+$treeA->left=$treeB;
+$treeA->right=$treeC;
+//
+//front($treeA);
+//echo "-------------------".'
';
+//middle($treeA);
+//echo "-------------------".'
';
+//backend($treeA);
+```
+
+### :pencil2:五.二叉排序树的插入,查找,删除.
+**我主要说明一下删除操作,删除操作主要分三种情况:(1)如果待删除结点中,只有一个左子结点,那么只要把待删除结点的父结点的left指向待删除结点的左子结点。(2)如果待删除结点只有一个右子结点,那么只要把带删除结点的父结点的right指向带删除结点的右子结点。(3)如果待删除结点有左右结点,那么需要找到这个结点右子树中最小的结点,把他替换到待删除的结点上面。**
+
+
+  +
+
+```php
+
+class Tree{
+ public $res='';
+ public $left=null;
+ public $right=null;
+ public function __construct($res)
+{
+ $this->res=$res;
+ }
+
+}
+
+class BinarySortTree
+{
+ public $tree;
+
+ public function getTree()
+{
+ return $this->tree;
+ }
+
+ //插入
+ public function insertTree($data)
+ {
+ if(!$this->tree){
+ $this->tree=new Tree($data);
+ return ;
+ }
+ $p=$this->tree;
+ while($p){
+ if($data<$p->res){ //如果插入结点当前结点
+ if(!$p->left){ //并且不存在左子结点
+ $p->left=new Tree($data);
+ return ;
+ }
+ $p=$p->left;
+ }elseif ($data>$p->res){
+ if(!$p->right){
+ $p->right=new Tree($data);
+ return ;
+ }
+ $p=$p->right;
+ }else{
+ return ;
+ }
+ }
+ }
+
+
+
+ //删除
+ public function deleteTree($data)
+{
+ if (!$this->tree) {
+ return;
+ }
+ $p = $this->tree;
+ $fatherP = null;
+ while ($p && $p->res !== $data) {
+ $fatherP=$p; //结点的父结点
+ if ($data > $p->res) {
+ $p = $p->right;
+ }else{
+ $p=$p->left;
+ }
+ }
+
+ //如果二叉树不存在
+ if($p==null){
+ var_dump('当前树中没有此结点');return;
+ }
+
+ //待删除待有两个子结点
+ if($p->left && $p->right){
+ $minR=$p->right;
+ $minRR=$p;// 最小结点的父结点
+ //查找右子树的最小结点
+ while($minR->left){
+ $minRR=$minR;
+ $minR=$minR->left;
+ }
+ $p->res=$minR->res;//把右子树上最小结点的值赋值给待删除结点
+ $p=$minR;
+ $fatherP=$minRR;
+
+ }
+ $child=null;
+ if($p->left){
+ $child=$p->left;
+ }elseif($p->right){
+ $child=$p->right;
+ }else{
+ $child=null;
+ }
+
+ if(!$fatherP){ //待删除结点是根结点
+ $this->tree=$child;
+ }elseif ($fatherP->left==$p){ //待删除结点只有一个左结点,把待删除结点的父结点的left指向待删除结点的子节点
+ $fatherP->left=$child;
+ }else{ //待删除结点只有一个右结点,把待删除结点的父结点的right指向待删除结点的子节点
+ $fatherP->right=$child;
+ }
+
+ }
+}
+
+$sortTree=new BinarySortTree();
+$sortTree->insertTree(9);
+$sortTree->insertTree(8);
+$sortTree->insertTree(10);
+$sortTree->insertTree(5);
+$sortTree->insertTree(6);
+$sortTree->insertTree(4);
+//$sortTree->search(1);
+//$sortTree->deleteTree(8);
+//var_dump($sortTree->getTree());
+```
+
+### 联系
+
+
+
+
+
+
+
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\345\240\206\346\240\210.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\240\206\346\240\210.md"
new file mode 100644
index 0000000..42ed110
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\240\206\346\240\210.md"
@@ -0,0 +1,115 @@
+## :数据结构线性表之堆栈
+
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+
+
+
+
+```php
+
+class Tree{
+ public $res='';
+ public $left=null;
+ public $right=null;
+ public function __construct($res)
+{
+ $this->res=$res;
+ }
+
+}
+
+class BinarySortTree
+{
+ public $tree;
+
+ public function getTree()
+{
+ return $this->tree;
+ }
+
+ //插入
+ public function insertTree($data)
+ {
+ if(!$this->tree){
+ $this->tree=new Tree($data);
+ return ;
+ }
+ $p=$this->tree;
+ while($p){
+ if($data<$p->res){ //如果插入结点当前结点
+ if(!$p->left){ //并且不存在左子结点
+ $p->left=new Tree($data);
+ return ;
+ }
+ $p=$p->left;
+ }elseif ($data>$p->res){
+ if(!$p->right){
+ $p->right=new Tree($data);
+ return ;
+ }
+ $p=$p->right;
+ }else{
+ return ;
+ }
+ }
+ }
+
+
+
+ //删除
+ public function deleteTree($data)
+{
+ if (!$this->tree) {
+ return;
+ }
+ $p = $this->tree;
+ $fatherP = null;
+ while ($p && $p->res !== $data) {
+ $fatherP=$p; //结点的父结点
+ if ($data > $p->res) {
+ $p = $p->right;
+ }else{
+ $p=$p->left;
+ }
+ }
+
+ //如果二叉树不存在
+ if($p==null){
+ var_dump('当前树中没有此结点');return;
+ }
+
+ //待删除待有两个子结点
+ if($p->left && $p->right){
+ $minR=$p->right;
+ $minRR=$p;// 最小结点的父结点
+ //查找右子树的最小结点
+ while($minR->left){
+ $minRR=$minR;
+ $minR=$minR->left;
+ }
+ $p->res=$minR->res;//把右子树上最小结点的值赋值给待删除结点
+ $p=$minR;
+ $fatherP=$minRR;
+
+ }
+ $child=null;
+ if($p->left){
+ $child=$p->left;
+ }elseif($p->right){
+ $child=$p->right;
+ }else{
+ $child=null;
+ }
+
+ if(!$fatherP){ //待删除结点是根结点
+ $this->tree=$child;
+ }elseif ($fatherP->left==$p){ //待删除结点只有一个左结点,把待删除结点的父结点的left指向待删除结点的子节点
+ $fatherP->left=$child;
+ }else{ //待删除结点只有一个右结点,把待删除结点的父结点的right指向待删除结点的子节点
+ $fatherP->right=$child;
+ }
+
+ }
+}
+
+$sortTree=new BinarySortTree();
+$sortTree->insertTree(9);
+$sortTree->insertTree(8);
+$sortTree->insertTree(10);
+$sortTree->insertTree(5);
+$sortTree->insertTree(6);
+$sortTree->insertTree(4);
+//$sortTree->search(1);
+//$sortTree->deleteTree(8);
+//var_dump($sortTree->getTree());
+```
+
+### 联系
+
+
+
+
+
+
+
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\345\240\206\346\240\210.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\240\206\346\240\210.md"
new file mode 100644
index 0000000..42ed110
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\240\206\346\240\210.md"
@@ -0,0 +1,115 @@
+## :数据结构线性表之堆栈
+
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+
+  +
+
+### :pencil2:一.栈的特点
+**栈是仅限在栈顶进行插入和删除的线性表.对栈来说,表尾端称之为栈顶,表头端称之为栈底.假设栈S=(a1,a2,a3,a4,a5....an),那么a1为栈的栈底,an为栈顶元素.对栈的操作是按照后进先出的原则,因此栈又称之为(LIFO)数据结构.**
+
+### :pencil2:二.栈的表示和实现
+**和线性表类似,栈也有两种存储的方式.顺序栈,即栈的存储是利用一组连续的存储单元依次存放自栈底到栈顶的元素.同时还要定义指针top指向栈顶元素在顺序栈中的位置.通常的做法是top=0表示空栈.一般在使用栈的过程中难以预料所需要的空间大小.所以预先分配大小的容量,当栈的使用空间不够时,再进行动态的扩容.top作为栈顶的指针,初始的时候指向栈底,当有元素入栈时,top自增,当从栈中删除一个元素时,top--,然后删除元素,所以top始终指向栈顶的下一个空位置.**
+ ```php
+LOC(ai+1)=LOC(ai)+L //申明 这里的i,i+1是下标
+```
+**线性结构的顺序表示以元素在计算机中的物理位置相邻来表示逻辑位置相邻,相邻两个元素之间的位置以物理位置的角度分析就是相差一位,只要确定了存储线性表的起始位,那么我们就能任意存储线性表中元素,下图具体表示**
+
+
+
+
+
+### :pencil2:一.栈的特点
+**栈是仅限在栈顶进行插入和删除的线性表.对栈来说,表尾端称之为栈顶,表头端称之为栈底.假设栈S=(a1,a2,a3,a4,a5....an),那么a1为栈的栈底,an为栈顶元素.对栈的操作是按照后进先出的原则,因此栈又称之为(LIFO)数据结构.**
+
+### :pencil2:二.栈的表示和实现
+**和线性表类似,栈也有两种存储的方式.顺序栈,即栈的存储是利用一组连续的存储单元依次存放自栈底到栈顶的元素.同时还要定义指针top指向栈顶元素在顺序栈中的位置.通常的做法是top=0表示空栈.一般在使用栈的过程中难以预料所需要的空间大小.所以预先分配大小的容量,当栈的使用空间不够时,再进行动态的扩容.top作为栈顶的指针,初始的时候指向栈底,当有元素入栈时,top自增,当从栈中删除一个元素时,top--,然后删除元素,所以top始终指向栈顶的下一个空位置.**
+ ```php
+LOC(ai+1)=LOC(ai)+L //申明 这里的i,i+1是下标
+```
+**线性结构的顺序表示以元素在计算机中的物理位置相邻来表示逻辑位置相邻,相邻两个元素之间的位置以物理位置的角度分析就是相差一位,只要确定了存储线性表的起始位,那么我们就能任意存储线性表中元素,下图具体表示**
+
+
+  +
+
+### :pencil2:三.栈的使用场景
+**栈的使用场景很多,例如idea的撤销回退功能,浏览器前进和后退功能.数制的转换,表达式求值,八皇后.......**
+### :pencil2:四.用栈实现代码
+```php
+
+/**
+ * 使用栈实现十进制转8精制,其他转换类似
+ */
+function tenChageEight($num)
+{
+ $data=[];
+ while($num) {
+ $val = $num % 8;
+ $num = intval(floor($num / 8));
+ array_unshift($data, $val);
+ }
+ $data2=[];
+ while(!empty($data)){
+ array_push($data2,array_shift($data));
+ }
+ return implode($data2);
+}
+var_dump(tenChageEight(1348));
+```
+****
+```php
+
+class Stack
+{
+ private $stack=[];
+ private $size=0;
+ public function __construct($size)
+{
+ $this->size=$size;
+ }
+
+ /**
+ *推入栈顶
+ */
+ public function push($value)
+{
+ if(count($this->stack)>=$this->size){
+ return false;
+ }
+ array_unshift($this->stack,$value);
+
+ }
+ /**
+ *出栈
+ */
+ public function pop()
+{
+ if($this->size==0){
+ return false;
+ }
+ array_shift($this->stack);
+ }
+ /**
+ *获取栈顶元素
+ */
+ public function top()
+{
+ if($this->size==0){
+ return false;
+ }
+ return current($this->stack);
+ }
+
+ public function data()
+{
+ return $this->stack;
+ }
+
+}
+
+$stack=new Stack(10);
+$stack->push(2);
+$stack->push(10);
+$stack->push(8);
+$stack->pop();
+var_dump($stack->top());
+var_dump($stack->data());
+```
+### 联系
+
+
+
+
+
+
+
+
+
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\345\255\227\347\254\246\344\270\262.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\255\227\347\254\246\344\270\262.md"
new file mode 100644
index 0000000..6040c2d
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\255\227\347\254\246\344\270\262.md"
@@ -0,0 +1,65 @@
+##旋转字符串
+给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符'a'和'b'移动到字符串的尾部,使得原字符串变成字符串“cdefab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
+###解法一:暴力移位法
+```php
+function move(&$str , $n){
+ for ($i = 0; $i<$n; $i++){
+ LeftShiftOne($str);
+ }
+}
+
+function LeftShiftOne(&$str){
+ $len = strlen($str);
+ $last = $str[$len - 1];
+ for ($i = 0; $i<$len-1; $i++){
+ $str[$i - 1] =$str[$i];
+ }
+ $str[$len-2] = $last;
+}
+$str = "abcd";
+move($str, 4);
+
+```
+时间复杂度为O(m n),空间复杂度为O(1),空间复杂度符合题目要求,但时间复杂度不符合,所以,我们得需要寻找其他更好的办法来降低时间复杂度。
+###解法二:三步反转法
+对于这个问题,换一个角度思考一下。
+将一个字符串分成X和Y两个部分,在每部分字符串上定义反转操作,如X^T,即把X的所有字符反转(如,X="abc",那么X^T="cba"),那么就得到下面的结论:(X^TY^T)^T=YX,显然就解决了字符串的反转问题。
+例如,字符串 abcdef ,若要让def翻转到abc的前头,只要按照下述3个步骤操作即可:
+- 首先将原字符串分为两个部分,即X:abc,Y:def;
+- 将X反转,X->X^T,即得:abc->cba;将Y反转,Y->Y^T,即得:def->fed。
+- 反转上述步骤得到的结果字符串X^TY^T,即反转字符串cbafed的两部分(cba和fed)给予反转,cbafed得到defabc,形式化表示为(X^TY^T)^T=YX,这就实现了整个反转。
+```php
+
+/**
+ * 旋转字符串
+ * @param $str
+ * @param $start
+ * @param $end
+ */
+function ReverseString(&$str, $start, $end){
+ while($start < $end){
+ $t = $str[$start];
+ $str[$start++] = $str[$end];
+ $str[$end--] = $t;
+ }
+}
+
+
+/**
+ * @param $str
+ * @param $n 字符串长度
+ * @param $m 移动位数
+ */
+function LeftRotateString(&$str, $n, $m){
+ $m %= $n;
+ ReverseString($str, 0, $m-1);
+ ReverseString($str, $m, $n-1);
+ ReverseString($str, 0, $n-1);
+
+}
+
+$str = "abcd";
+LeftRotateString($str, strlen($str), 1);
+```
+
+这就是把字符串分为两个部分,先各自反转再整体反转的方法,时间复杂度为O(n),空间复杂度为O(1),达到了题目的要求。
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\243\345\210\227\350\241\250.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\243\345\210\227\350\241\250.md"
new file mode 100644
index 0000000..5174d2b
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\243\345\210\227\350\241\250.md"
@@ -0,0 +1,114 @@
+## 数据结构之散列表
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+
+
+
+### :pencil2:三.栈的使用场景
+**栈的使用场景很多,例如idea的撤销回退功能,浏览器前进和后退功能.数制的转换,表达式求值,八皇后.......**
+### :pencil2:四.用栈实现代码
+```php
+
+/**
+ * 使用栈实现十进制转8精制,其他转换类似
+ */
+function tenChageEight($num)
+{
+ $data=[];
+ while($num) {
+ $val = $num % 8;
+ $num = intval(floor($num / 8));
+ array_unshift($data, $val);
+ }
+ $data2=[];
+ while(!empty($data)){
+ array_push($data2,array_shift($data));
+ }
+ return implode($data2);
+}
+var_dump(tenChageEight(1348));
+```
+****
+```php
+
+class Stack
+{
+ private $stack=[];
+ private $size=0;
+ public function __construct($size)
+{
+ $this->size=$size;
+ }
+
+ /**
+ *推入栈顶
+ */
+ public function push($value)
+{
+ if(count($this->stack)>=$this->size){
+ return false;
+ }
+ array_unshift($this->stack,$value);
+
+ }
+ /**
+ *出栈
+ */
+ public function pop()
+{
+ if($this->size==0){
+ return false;
+ }
+ array_shift($this->stack);
+ }
+ /**
+ *获取栈顶元素
+ */
+ public function top()
+{
+ if($this->size==0){
+ return false;
+ }
+ return current($this->stack);
+ }
+
+ public function data()
+{
+ return $this->stack;
+ }
+
+}
+
+$stack=new Stack(10);
+$stack->push(2);
+$stack->push(10);
+$stack->push(8);
+$stack->pop();
+var_dump($stack->top());
+var_dump($stack->data());
+```
+### 联系
+
+
+
+
+
+
+
+
+
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\345\255\227\347\254\246\344\270\262.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\255\227\347\254\246\344\270\262.md"
new file mode 100644
index 0000000..6040c2d
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\345\255\227\347\254\246\344\270\262.md"
@@ -0,0 +1,65 @@
+##旋转字符串
+给定一个字符串,要求把字符串前面的若干个字符移动到字符串的尾部,如把字符串“abcdef”前面的2个字符'a'和'b'移动到字符串的尾部,使得原字符串变成字符串“cdefab”。请写一个函数完成此功能,要求对长度为n的字符串操作的时间复杂度为 O(n),空间复杂度为 O(1)。
+###解法一:暴力移位法
+```php
+function move(&$str , $n){
+ for ($i = 0; $i<$n; $i++){
+ LeftShiftOne($str);
+ }
+}
+
+function LeftShiftOne(&$str){
+ $len = strlen($str);
+ $last = $str[$len - 1];
+ for ($i = 0; $i<$len-1; $i++){
+ $str[$i - 1] =$str[$i];
+ }
+ $str[$len-2] = $last;
+}
+$str = "abcd";
+move($str, 4);
+
+```
+时间复杂度为O(m n),空间复杂度为O(1),空间复杂度符合题目要求,但时间复杂度不符合,所以,我们得需要寻找其他更好的办法来降低时间复杂度。
+###解法二:三步反转法
+对于这个问题,换一个角度思考一下。
+将一个字符串分成X和Y两个部分,在每部分字符串上定义反转操作,如X^T,即把X的所有字符反转(如,X="abc",那么X^T="cba"),那么就得到下面的结论:(X^TY^T)^T=YX,显然就解决了字符串的反转问题。
+例如,字符串 abcdef ,若要让def翻转到abc的前头,只要按照下述3个步骤操作即可:
+- 首先将原字符串分为两个部分,即X:abc,Y:def;
+- 将X反转,X->X^T,即得:abc->cba;将Y反转,Y->Y^T,即得:def->fed。
+- 反转上述步骤得到的结果字符串X^TY^T,即反转字符串cbafed的两部分(cba和fed)给予反转,cbafed得到defabc,形式化表示为(X^TY^T)^T=YX,这就实现了整个反转。
+```php
+
+/**
+ * 旋转字符串
+ * @param $str
+ * @param $start
+ * @param $end
+ */
+function ReverseString(&$str, $start, $end){
+ while($start < $end){
+ $t = $str[$start];
+ $str[$start++] = $str[$end];
+ $str[$end--] = $t;
+ }
+}
+
+
+/**
+ * @param $str
+ * @param $n 字符串长度
+ * @param $m 移动位数
+ */
+function LeftRotateString(&$str, $n, $m){
+ $m %= $n;
+ ReverseString($str, 0, $m-1);
+ ReverseString($str, $m, $n-1);
+ ReverseString($str, 0, $n-1);
+
+}
+
+$str = "abcd";
+LeftRotateString($str, strlen($str), 1);
+```
+
+这就是把字符串分为两个部分,先各自反转再整体反转的方法,时间复杂度为O(n),空间复杂度为O(1),达到了题目的要求。
\ No newline at end of file
diff --git "a/\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\243\345\210\227\350\241\250.md" "b/\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\243\345\210\227\350\241\250.md"
new file mode 100644
index 0000000..5174d2b
--- /dev/null
+++ "b/\346\225\260\346\215\256\347\273\223\346\236\204/\346\225\243\345\210\227\350\241\250.md"
@@ -0,0 +1,114 @@
+## 数据结构之散列表
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+  +
+
+### :pencil2:一.散列表的介绍
+**散列表也叫哈希表,在前面的各种数据结构中(数组,链表,树等),记录在结构中的相对位置是随机的,和记录的关键字不存在确定的关系。在顺序结构中,顺序查找,比较的结果是'='或者'!=',在二分查找,二叉排序树比较的关系是'>','=‘,’<‘,查找的效率依赖于查找过程中比较的次数。**
+**什么样的方法能使得理想情况下不需要进行任何比较,通过一次存储就能得到所查的记录。答案就是记录存储位置和关键字之间的对应关系。**
+
+
+
+
+
+### :pencil2:一.散列表的介绍
+**散列表也叫哈希表,在前面的各种数据结构中(数组,链表,树等),记录在结构中的相对位置是随机的,和记录的关键字不存在确定的关系。在顺序结构中,顺序查找,比较的结果是'='或者'!=',在二分查找,二叉排序树比较的关系是'>','=‘,’<‘,查找的效率依赖于查找过程中比较的次数。**
+**什么样的方法能使得理想情况下不需要进行任何比较,通过一次存储就能得到所查的记录。答案就是记录存储位置和关键字之间的对应关系。**
+
+
+  +
+
+**我们记录了存储位置和关键字的对应关系h,因此在查找的过程中,只要根据对应关系h找到给定值k的像h(k),如果结构中存在关建字和k相等的记录,那么肯定是存储在h(k)的位置上,就像上图k1..k5的一样,我们称这个对应关系h为散列函数或者是哈希函数。**
+****
+**从上面的例子可以看出:**
+
+**1.散列函数是一个映像,因此设定散列函数可以非常灵活。**
+
+**2.从图中可以看出,k2 != k5 ,但是h(k2)===h(k5),这就是散列冲突。**
+
+### :pencil2:二.散列冲突
+
+
+
+
+
+**我们记录了存储位置和关键字的对应关系h,因此在查找的过程中,只要根据对应关系h找到给定值k的像h(k),如果结构中存在关建字和k相等的记录,那么肯定是存储在h(k)的位置上,就像上图k1..k5的一样,我们称这个对应关系h为散列函数或者是哈希函数。**
+****
+**从上面的例子可以看出:**
+
+**1.散列函数是一个映像,因此设定散列函数可以非常灵活。**
+
+**2.从图中可以看出,k2 != k5 ,但是h(k2)===h(k5),这就是散列冲突。**
+
+### :pencil2:二.散列冲突
+
+
+  +
+
+**我们看当前例子,关键字 John Smith !=Sandra Dee,但是通过散列函数之后h(John Smith)===h(Sandra Dee),他们的位置都在散列表01这个位置,但是这个位置只能存储一个记录,那多出来的记录存放在哪里?**
+
+**正因为散列函数是一个映像,我们在构造散列函数的时候,只能去分析关键字的特性,选择一个恰当的散列函数来避免冲突的发生。一般情况下,冲突只能尽可能的减少,而不能完全避免。**
+
+### :pencil2:三.散列函数的构造
+**先来看看什么是好的散列函数。如果对于关键字集合中任意一个,经过散列函数映射到地址集合中任何一个位置的概率都是相等的,就可以称为均匀散列函数。**
+
+**1.直接定址法**
+
+**取关键字或者关键字的某个线性函数值为哈希地址。**
+
+**h(key)=key或者h(key)=a*key+b a,b为常量。比如说做一个地区年龄段的人数统计,我们就可以把年龄1-100作为关键字,现在你要查38岁的人口数时只需要h(38)=???。**
+****
+
+**2.数字分析法**
+
+**要通过具体的数字分析,找出关键字集合的特点和关系,通过这组关系构造一个散列函数。**
+****
+**3.平方取中法**
+
+**取关键字平方后的中间几位为哈希地址,因为一般情况下,选定哈希函数时并不一定知道关键字的全部情况,取哪几位也不一定合适,而一个平方后的中间几位数和数的每一位都有关,由此使随机分布的关键字得到的哈希地址也是随机的。**
+****
+**4.折叠法**
+
+**将关键字分割成位数相同的几部分,然后取这几部分的叠加和,也就是舍去它的进位,作为他的哈希地址。**
+****
+**5.除留余数法**
+**取关键字被某个不大于散列表表长m的数(暂且称之为p)除后所得余数为哈希地址。**
+```php
+h(key)=key MOD p, p<=m
+```
+**以上都偏于理论,具体的使用需要视情况而定,通常,考虑的因素有以下几点**
+
+**1.计算散列函数所需的时间**
+
+**2.关键字的长度**
+
+**3.哈希表的大小**
+
+**4.关键字的分布情况**
+
+ **5.记录查找的频率**
+
+ ### :pencil2:四.处理冲突
+ **之前说过,散列函数可以减少冲突,但是不能避免,这时候我们就需要处理冲突。**
+
+ **1.开放寻址法**
+
+ **简单的来说,下图中当前哈希表的长度是8,现在已填入关键字1,9,3,4,5的记录,假如当前我们需要再填入关键字10这条记录。通过散列函数得出h(3)===h(10),但是此时哈希地址2已被3占领。现在我们咋么处理?**
+
+ **线性探测再散列得到下一个地址3,发现3也被占领,再求下一个地址4,还被占领,直到5这个位置时,处理冲突过程结束,把当前h(10)记录在地址为5的位置即可。也可以使用二次探测再散列或者伪随机再散列都是属于开放寻址法。**
+
+
+
+
+
+**我们看当前例子,关键字 John Smith !=Sandra Dee,但是通过散列函数之后h(John Smith)===h(Sandra Dee),他们的位置都在散列表01这个位置,但是这个位置只能存储一个记录,那多出来的记录存放在哪里?**
+
+**正因为散列函数是一个映像,我们在构造散列函数的时候,只能去分析关键字的特性,选择一个恰当的散列函数来避免冲突的发生。一般情况下,冲突只能尽可能的减少,而不能完全避免。**
+
+### :pencil2:三.散列函数的构造
+**先来看看什么是好的散列函数。如果对于关键字集合中任意一个,经过散列函数映射到地址集合中任何一个位置的概率都是相等的,就可以称为均匀散列函数。**
+
+**1.直接定址法**
+
+**取关键字或者关键字的某个线性函数值为哈希地址。**
+
+**h(key)=key或者h(key)=a*key+b a,b为常量。比如说做一个地区年龄段的人数统计,我们就可以把年龄1-100作为关键字,现在你要查38岁的人口数时只需要h(38)=???。**
+****
+
+**2.数字分析法**
+
+**要通过具体的数字分析,找出关键字集合的特点和关系,通过这组关系构造一个散列函数。**
+****
+**3.平方取中法**
+
+**取关键字平方后的中间几位为哈希地址,因为一般情况下,选定哈希函数时并不一定知道关键字的全部情况,取哪几位也不一定合适,而一个平方后的中间几位数和数的每一位都有关,由此使随机分布的关键字得到的哈希地址也是随机的。**
+****
+**4.折叠法**
+
+**将关键字分割成位数相同的几部分,然后取这几部分的叠加和,也就是舍去它的进位,作为他的哈希地址。**
+****
+**5.除留余数法**
+**取关键字被某个不大于散列表表长m的数(暂且称之为p)除后所得余数为哈希地址。**
+```php
+h(key)=key MOD p, p<=m
+```
+**以上都偏于理论,具体的使用需要视情况而定,通常,考虑的因素有以下几点**
+
+**1.计算散列函数所需的时间**
+
+**2.关键字的长度**
+
+**3.哈希表的大小**
+
+**4.关键字的分布情况**
+
+ **5.记录查找的频率**
+
+ ### :pencil2:四.处理冲突
+ **之前说过,散列函数可以减少冲突,但是不能避免,这时候我们就需要处理冲突。**
+
+ **1.开放寻址法**
+
+ **简单的来说,下图中当前哈希表的长度是8,现在已填入关键字1,9,3,4,5的记录,假如当前我们需要再填入关键字10这条记录。通过散列函数得出h(3)===h(10),但是此时哈希地址2已被3占领。现在我们咋么处理?**
+
+ **线性探测再散列得到下一个地址3,发现3也被占领,再求下一个地址4,还被占领,直到5这个位置时,处理冲突过程结束,把当前h(10)记录在地址为5的位置即可。也可以使用二次探测再散列或者伪随机再散列都是属于开放寻址法。**
+
+
+  +
+
+****
+
+**2.再散列法**
+
+**即在同义词产生地址冲突时计算另一个散列函数的地址,直到冲突不再发生,这种方法毋庸置疑,增加了计算的时间。**
+****
+**3.链地址法**
+
+**将所有关键字为同义词的记录存储在同一个线性链表中。初始状态是一个空指针。凡是通过关键字计算出地址一样的记录都插入到当前位置的链表中,在链表中插入的位置可以是表头,表尾,或者表中,以保持同义词在同一个线性表中按关键字有序。**
+
+
+
+
+
+****
+
+**2.再散列法**
+
+**即在同义词产生地址冲突时计算另一个散列函数的地址,直到冲突不再发生,这种方法毋庸置疑,增加了计算的时间。**
+****
+**3.链地址法**
+
+**将所有关键字为同义词的记录存储在同一个线性链表中。初始状态是一个空指针。凡是通过关键字计算出地址一样的记录都插入到当前位置的链表中,在链表中插入的位置可以是表头,表尾,或者表中,以保持同义词在同一个线性表中按关键字有序。**
+
+
+  +
+
+ ****
+
+ **4.建立一个公共溢出区**
+
+ **假设散列函数的值域为[0,m-1],则设置向量HashTable[0,m-1]为基本表,每一个分量存储一个记录,另外设置向量OverTable[0,v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表中。**
+****
+ ### 联系
+
+
+
+
+
+
+
+
+
diff --git "a/\346\236\266\346\236\204\345\222\214\347\263\273\347\273\237\350\256\276\350\256\241/API\350\256\276\350\256\241.md" "b/\346\236\266\346\236\204\345\222\214\347\263\273\347\273\237\350\256\276\350\256\241/API\350\256\276\350\256\241.md"
new file mode 100644
index 0000000..e99b89e
--- /dev/null
+++ "b/\346\236\266\346\236\204\345\222\214\347\263\273\347\273\237\350\256\276\350\256\241/API\350\256\276\350\256\241.md"
@@ -0,0 +1,89 @@
+## REST API
+
+REST(Representational State Transfer)表述性状态转换,**REST指的是一组架构约束条件和原则** 。
+
+使用URL定位资源,用HTTP动词(GET,POST,PUT,DELETE)描述操作。
+
+### 基本概念
+
+- 资源
+
+ > 资源就是网络上的一个实体,一段文本,一张图片或者一首歌曲。资源总是要通过一种载体来反应它的内容。文本可以用TXT,也可以用HTML或者XML、图片可以用JPG格式或者PNG格式,JSON是现在最常用的资源表现形式。
+
+- 统一资源接口
+
+ > 统一接口。RESTful风格的数据元操CRUD(create,read,update,delete)分别对应HTTP方法:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源,这样就统一了数据操作的接口。
+
+ - GET 获取资源
+ - PUT更新资源
+ - POST 新增资源
+ - DELETE 删除
+
+- URI
+
+ > URI。可以用一个URI(统一资源定位符)指向资源,即每个URI都对应一个特定的资源。要获取这个资源访问它的URI就可以,因此URI就成了每一个资源的地址或识别符。一般的,每个资源至少有一个URI与之对应,最典型的URI就是URL。
+
+- 无状态
+
+ > 所谓无状态即所有的资源都可以URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而变化。有状态和无状态的区别,举个例子说明一下,例如要查询员工工资的步骤为第一步:登录系统。第二步:进入查询工资的页面。第三步:搜索该员工。第四步:点击姓名查看工资。这样的操作流程就是有状态的,查询工资的每一个步骤都依赖于前一个步骤,只要前置操作不成功,后续操作就无法执行。如果输入一个URL就可以得到指定员工的工资,则这种情况就是无状态的,因为获取工资不依赖于其他资源或状态,且这种情况下,员工工资是一个资源,由一个URL与之对应可以通过HTTP中的GET方法得到资源,这就是典型的RESTful风格。
+
+
+
+### 设计风格
+
+- 协议
+
+ API接口通讯,一般是通过HTTP[s]协议。
+
+- 域名
+
+ 域名应单独部署到对应的域名。
+
+ ```php
+ api.github.com
+ ```
+
+- 版本控制
+
+ ```
+ api.github.com/v1/
+ ```
+
+- 路径规则
+
+ 路径中,不要出现动词。比如getUsers。复数表示获取集合数组
+
+ ```
+ /v1/user/10 获取id为10的用户
+ /v1/users 获取所有用户
+ ```
+
+- HTTP请求方式表示动作
+
+ - GET 表示获取资源
+ - PUT 更新资源
+ - POST新增资源
+ - DELETE 删除资源
+
+ ```
+ GET /users
+ PUT /user/10
+ POST /user/10
+ DELETE /user/10
+ ```
+
+- 过滤信息
+
+ 如果记录过多,可以使用分页过滤信息
+
+ - ?limit=10 指定返回记录的数量
+ - ?offset=10:指定返回记录的开始位置。
+ - ?page=2&per_page=100:指定第几页,以及每页的记录数。
+ - ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
+ - ?producy_type=1:指定筛选条件
+
+- 异常响应
+
+ 当 RESTful API 接口出现非 2xx 的 HTTP 错误码响应时,采用全局的异常结构响应信息。
+
+
\ No newline at end of file
diff --git "a/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/Git_removeCommits.md" "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/Git_removeCommits.md"
new file mode 100644
index 0000000..a4abb5e
--- /dev/null
+++ "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/Git_removeCommits.md"
@@ -0,0 +1,100 @@
+在 Git 开发中通常会控制主干分支的质量,但有时还是会把错误的代码合入到远程主干。 虽然可以 直接回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 但有时新的代码也已经合入,直接回滚后最近的提交都要重新操作。 那么有没有只移除某些 Commit 的方式呢?可以一次 [revert](https://git-scm.com/docs/git-revert) 操作来完成。
+
+# 一个例子
+
+考虑这个例子,我们提交了 6 个版本,其中 3-4 包含了错误的代码需要被回滚掉。 同时希望不影响到后续的 5-6。
+
+```
+* 982d4f6 (HEAD -> master) version 6
+* 54cc9dc version 5
+* 551c408 version 4, harttle screwed it up again
+* 7e345c9 version 3, harttle screwed it up
+* f7742cd version 2
+* 6c4db3f version 1
+```
+
+这种情况在团队协作的开发中会很常见:可能是流程或认为原因不小心合入了错误的代码, 也可能是合入一段时间后才发现存在问题。 总之已经存在后续提交,使得直接回滚不太现实。
+
+下面的部分就开始介绍具体操作了,同时我们假设远程分支是受保护的(不允许 Force Push)。 思路是从产生一个新的 Commit 撤销之前的错误提交。
+
+# git revert
+
+使用 `git revert ` 可以撤销指定的提交, 要撤销一串提交可以用 `..` 语法。 注意这是一个前开后闭区间,即不包括 commit1,但包括 commit2。
+
+```
+git revert --no-commit f7742cd..551c408
+git commit -a -m 'This reverts commit 7e345c9 and 551c408'
+```
+
+其中 `f7742cd` 是 version 2,`551c408` 是 version 4,这样被移除的是 version 3 和 version 4。 注意 revert 命令会对每个撤销的 commit 进行一次提交,`--no-commit` 后可以最后一起手动提交。
+
+此时 Git 记录是这样的:
+
+```
+* 8fef80a (HEAD -> master) This reverts commit 7e345c9 and 551c408
+* 982d4f6 version 6
+* 54cc9dc version 5
+* 551c408 version 4, harttle screwed it up again
+* 7e345c9 version 3, harttle screwed it up
+* f7742cd version 2
+* 6c4db3f version 1
+```
+
+现在的 HEAD(`8fef80a`)就是我们想要的版本,把它 Push 到远程即可。
+
+# 确认 diff
+
+如果你像不确定是否符合预期,毕竟批量干掉了别人一堆 Commit,可以做一下 diff 来确认。 首先产生 version 4(`551c408`)与 version 6(`982d4f6`)的 diff,这些是我们想要保留的:
+
+```
+git diff 551c408..982d4f6
+```
+
+然后再产生 version 2(`f7742cd`)与当前状态(HEAD)的 diff:
+
+```
+git diff f7742cd..HEAD
+```
+
+如果 version 3, version 4 都被 version 6 撤销的话,上述两个 diff 为空。 可以人工确认一下,或者 grep 掉 description 之后做一次 diff。 下面介绍的另一种方法可以容易地确认 diff。
+
+# 另外一种方式
+
+类似 [安全回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 我们先回到 version 2,让它合并 version 4 同时代码不变, 再合并 version 5, version 6。
+
+```
+# 从 version 2 切分支出来
+git checkout -b fixing f7742cd
+# 合并 version 4,保持代码不变
+git merge -s ours 551c408
+# 合并 version 5, version 6
+git merge master
+```
+
+上述分支操作可以从 [分支管理](https://harttle.land/2016/09/02/git-workflow-branch.html) 一文了解。 至此,`fixing` 分支已经移除了 version 3 和 version 4 的代码,图示如下:
+
+```
+* 3cb9f8a (HEAD -> v2) Merge branch 'master' into v2
+|\
+| * 982d4f6 (master) version 6
+| * 54cc9dc version 5
+* | c669557 Merge commit '551c408' into v2
+|\ \
+| |/
+| * 551c408 version 4, harttle screwed it up again
+| * 7e345c9 version 3, harttle screwed it up
+|/
+* f7742cd version 2
+* 6c4db3f version 1
+```
+
+可以简单 diff 一下来确认效果:
+
+```
+# 第一次 merge 结果与 version 2 的 diff,应为空
+git diff f7742cd..c669557
+# 第二次 merge 的内容,应包含 version 5 和 version 6 的改动
+git diff c669557..3cb9f8a
+```
+
+现在的 `HEAD`(即 `fixing` 分支)就是我们想要的版本,可以把它 Push 到远程了。 注意由于现在处于 `fixing` 分支, 需要 [Push 时指定远程分支](https://harttle.land/2016/09/05/git-workflow-remote.html) 为 `master`。
diff --git "a/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/gitcheat.jpg" "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/gitcheat.jpg"
new file mode 100644
index 0000000..5dd105a
Binary files /dev/null and "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/gitcheat.jpg" differ
diff --git "a/\347\256\227\346\263\225/Readme.md" "b/\347\256\227\346\263\225/Readme.md"
index 18952d5..73cdf7e 100644
--- "a/\347\256\227\346\263\225/Readme.md"
+++ "b/\347\256\227\346\263\225/Readme.md"
@@ -131,25 +131,33 @@ function SelectSort(array $container)
- [快速排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/QuickSort.php)
+> 快速排序(Quicksort)是对冒泡排序的一种改进。他的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,整个排序过程可以递归进行,以达到整个序列有序的目的。
+
```php
-function QuickSort(array $container)
+function QuickSort(&$arr,$low,$high)
{
- $count = count($container);
- if ($count <= 1) { // 基线条件为空或者只包含一个元素,只需要原样返回数组
- return $container;
+ if ($low < $high) {
+ $middle = getMiddle($arr,$low,$high);
+ QuickSort($arr,$low,$middle-1);
+ QuickSort($arr,$middle+1,$high);
}
- $pivot = $container[0]; // 基准值 pivot
- $left = $right = [];
- for ($i = 1; $i < $count; $i++) {
- if ($container[$i] < $pivot) {
- $left[] = $container[$i];
- } else {
- $right[] = $container[$i];
+}
+
+function getMiddle (&$arr,$low,$high)
+{
+ $temp = $arr[$low];
+ while ($low < $high) {
+ while($low < $high && $temp <= $arr[$high]) {
+ $high --;
+ }
+ $arr[$low] = $arr[$high];
+ while ($low < $high && $temp >= $arr[$low]) {
+ $low ++;
}
+ $arr[$high] = $arr[$low];
}
- $left = QuickSort($left);
- $right = QuickSort($right);
- return array_merge($left, [$container[0]], $right);
+ $arr[$low] = $temp;
+ return $low;
}
```
diff --git "a/\347\256\227\346\263\225/\344\272\214\345\210\206\346\237\245\346\211\276.md" "b/\347\256\227\346\263\225/\344\272\214\345\210\206\346\237\245\346\211\276.md"
new file mode 100644
index 0000000..251be5d
--- /dev/null
+++ "b/\347\256\227\346\263\225/\344\272\214\345\210\206\346\237\245\346\211\276.md"
@@ -0,0 +1,156 @@
+## :算法之排序二分查找
+### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+### :pencil2:二分查找
+
+
+
+
+
+ ****
+
+ **4.建立一个公共溢出区**
+
+ **假设散列函数的值域为[0,m-1],则设置向量HashTable[0,m-1]为基本表,每一个分量存储一个记录,另外设置向量OverTable[0,v]为溢出表。所有关键字和基本表中关键字为同义词的记录,不管它们由哈希函数得到的哈希地址是什么,一旦发生冲突,都填入溢出表中。**
+****
+ ### 联系
+
+
+
+
+
+
+
+
+
diff --git "a/\346\236\266\346\236\204\345\222\214\347\263\273\347\273\237\350\256\276\350\256\241/API\350\256\276\350\256\241.md" "b/\346\236\266\346\236\204\345\222\214\347\263\273\347\273\237\350\256\276\350\256\241/API\350\256\276\350\256\241.md"
new file mode 100644
index 0000000..e99b89e
--- /dev/null
+++ "b/\346\236\266\346\236\204\345\222\214\347\263\273\347\273\237\350\256\276\350\256\241/API\350\256\276\350\256\241.md"
@@ -0,0 +1,89 @@
+## REST API
+
+REST(Representational State Transfer)表述性状态转换,**REST指的是一组架构约束条件和原则** 。
+
+使用URL定位资源,用HTTP动词(GET,POST,PUT,DELETE)描述操作。
+
+### 基本概念
+
+- 资源
+
+ > 资源就是网络上的一个实体,一段文本,一张图片或者一首歌曲。资源总是要通过一种载体来反应它的内容。文本可以用TXT,也可以用HTML或者XML、图片可以用JPG格式或者PNG格式,JSON是现在最常用的资源表现形式。
+
+- 统一资源接口
+
+ > 统一接口。RESTful风格的数据元操CRUD(create,read,update,delete)分别对应HTTP方法:GET用来获取资源,POST用来新建资源(也可以用于更新资源),PUT用来更新资源,DELETE用来删除资源,这样就统一了数据操作的接口。
+
+ - GET 获取资源
+ - PUT更新资源
+ - POST 新增资源
+ - DELETE 删除
+
+- URI
+
+ > URI。可以用一个URI(统一资源定位符)指向资源,即每个URI都对应一个特定的资源。要获取这个资源访问它的URI就可以,因此URI就成了每一个资源的地址或识别符。一般的,每个资源至少有一个URI与之对应,最典型的URI就是URL。
+
+- 无状态
+
+ > 所谓无状态即所有的资源都可以URI定位,而且这个定位与其他资源无关,也不会因为其他资源的变化而变化。有状态和无状态的区别,举个例子说明一下,例如要查询员工工资的步骤为第一步:登录系统。第二步:进入查询工资的页面。第三步:搜索该员工。第四步:点击姓名查看工资。这样的操作流程就是有状态的,查询工资的每一个步骤都依赖于前一个步骤,只要前置操作不成功,后续操作就无法执行。如果输入一个URL就可以得到指定员工的工资,则这种情况就是无状态的,因为获取工资不依赖于其他资源或状态,且这种情况下,员工工资是一个资源,由一个URL与之对应可以通过HTTP中的GET方法得到资源,这就是典型的RESTful风格。
+
+
+
+### 设计风格
+
+- 协议
+
+ API接口通讯,一般是通过HTTP[s]协议。
+
+- 域名
+
+ 域名应单独部署到对应的域名。
+
+ ```php
+ api.github.com
+ ```
+
+- 版本控制
+
+ ```
+ api.github.com/v1/
+ ```
+
+- 路径规则
+
+ 路径中,不要出现动词。比如getUsers。复数表示获取集合数组
+
+ ```
+ /v1/user/10 获取id为10的用户
+ /v1/users 获取所有用户
+ ```
+
+- HTTP请求方式表示动作
+
+ - GET 表示获取资源
+ - PUT 更新资源
+ - POST新增资源
+ - DELETE 删除资源
+
+ ```
+ GET /users
+ PUT /user/10
+ POST /user/10
+ DELETE /user/10
+ ```
+
+- 过滤信息
+
+ 如果记录过多,可以使用分页过滤信息
+
+ - ?limit=10 指定返回记录的数量
+ - ?offset=10:指定返回记录的开始位置。
+ - ?page=2&per_page=100:指定第几页,以及每页的记录数。
+ - ?sortby=name&order=asc:指定返回结果按照哪个属性排序,以及排序顺序
+ - ?producy_type=1:指定筛选条件
+
+- 异常响应
+
+ 当 RESTful API 接口出现非 2xx 的 HTTP 错误码响应时,采用全局的异常结构响应信息。
+
+
\ No newline at end of file
diff --git "a/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/Git_removeCommits.md" "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/Git_removeCommits.md"
new file mode 100644
index 0000000..a4abb5e
--- /dev/null
+++ "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/Git_removeCommits.md"
@@ -0,0 +1,100 @@
+在 Git 开发中通常会控制主干分支的质量,但有时还是会把错误的代码合入到远程主干。 虽然可以 直接回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 但有时新的代码也已经合入,直接回滚后最近的提交都要重新操作。 那么有没有只移除某些 Commit 的方式呢?可以一次 [revert](https://git-scm.com/docs/git-revert) 操作来完成。
+
+# 一个例子
+
+考虑这个例子,我们提交了 6 个版本,其中 3-4 包含了错误的代码需要被回滚掉。 同时希望不影响到后续的 5-6。
+
+```
+* 982d4f6 (HEAD -> master) version 6
+* 54cc9dc version 5
+* 551c408 version 4, harttle screwed it up again
+* 7e345c9 version 3, harttle screwed it up
+* f7742cd version 2
+* 6c4db3f version 1
+```
+
+这种情况在团队协作的开发中会很常见:可能是流程或认为原因不小心合入了错误的代码, 也可能是合入一段时间后才发现存在问题。 总之已经存在后续提交,使得直接回滚不太现实。
+
+下面的部分就开始介绍具体操作了,同时我们假设远程分支是受保护的(不允许 Force Push)。 思路是从产生一个新的 Commit 撤销之前的错误提交。
+
+# git revert
+
+使用 `git revert ` 可以撤销指定的提交, 要撤销一串提交可以用 `..` 语法。 注意这是一个前开后闭区间,即不包括 commit1,但包括 commit2。
+
+```
+git revert --no-commit f7742cd..551c408
+git commit -a -m 'This reverts commit 7e345c9 and 551c408'
+```
+
+其中 `f7742cd` 是 version 2,`551c408` 是 version 4,这样被移除的是 version 3 和 version 4。 注意 revert 命令会对每个撤销的 commit 进行一次提交,`--no-commit` 后可以最后一起手动提交。
+
+此时 Git 记录是这样的:
+
+```
+* 8fef80a (HEAD -> master) This reverts commit 7e345c9 and 551c408
+* 982d4f6 version 6
+* 54cc9dc version 5
+* 551c408 version 4, harttle screwed it up again
+* 7e345c9 version 3, harttle screwed it up
+* f7742cd version 2
+* 6c4db3f version 1
+```
+
+现在的 HEAD(`8fef80a`)就是我们想要的版本,把它 Push 到远程即可。
+
+# 确认 diff
+
+如果你像不确定是否符合预期,毕竟批量干掉了别人一堆 Commit,可以做一下 diff 来确认。 首先产生 version 4(`551c408`)与 version 6(`982d4f6`)的 diff,这些是我们想要保留的:
+
+```
+git diff 551c408..982d4f6
+```
+
+然后再产生 version 2(`f7742cd`)与当前状态(HEAD)的 diff:
+
+```
+git diff f7742cd..HEAD
+```
+
+如果 version 3, version 4 都被 version 6 撤销的话,上述两个 diff 为空。 可以人工确认一下,或者 grep 掉 description 之后做一次 diff。 下面介绍的另一种方法可以容易地确认 diff。
+
+# 另外一种方式
+
+类似 [安全回滚远程分支](https://harttle.land/2018/03/12/reset-origin-without-force-push.html), 我们先回到 version 2,让它合并 version 4 同时代码不变, 再合并 version 5, version 6。
+
+```
+# 从 version 2 切分支出来
+git checkout -b fixing f7742cd
+# 合并 version 4,保持代码不变
+git merge -s ours 551c408
+# 合并 version 5, version 6
+git merge master
+```
+
+上述分支操作可以从 [分支管理](https://harttle.land/2016/09/02/git-workflow-branch.html) 一文了解。 至此,`fixing` 分支已经移除了 version 3 和 version 4 的代码,图示如下:
+
+```
+* 3cb9f8a (HEAD -> v2) Merge branch 'master' into v2
+|\
+| * 982d4f6 (master) version 6
+| * 54cc9dc version 5
+* | c669557 Merge commit '551c408' into v2
+|\ \
+| |/
+| * 551c408 version 4, harttle screwed it up again
+| * 7e345c9 version 3, harttle screwed it up
+|/
+* f7742cd version 2
+* 6c4db3f version 1
+```
+
+可以简单 diff 一下来确认效果:
+
+```
+# 第一次 merge 结果与 version 2 的 diff,应为空
+git diff f7742cd..c669557
+# 第二次 merge 的内容,应包含 version 5 和 version 6 的改动
+git diff c669557..3cb9f8a
+```
+
+现在的 `HEAD`(即 `fixing` 分支)就是我们想要的版本,可以把它 Push 到远程了。 注意由于现在处于 `fixing` 分支, 需要 [Push 时指定远程分支](https://harttle.land/2016/09/05/git-workflow-remote.html) 为 `master`。
diff --git "a/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/gitcheat.jpg" "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/gitcheat.jpg"
new file mode 100644
index 0000000..5dd105a
Binary files /dev/null and "b/\347\211\210\346\234\254\346\216\247\345\210\266\345\231\250/gitcheat.jpg" differ
diff --git "a/\347\256\227\346\263\225/Readme.md" "b/\347\256\227\346\263\225/Readme.md"
index 18952d5..73cdf7e 100644
--- "a/\347\256\227\346\263\225/Readme.md"
+++ "b/\347\256\227\346\263\225/Readme.md"
@@ -131,25 +131,33 @@ function SelectSort(array $container)
- [快速排序](https://github.com/xianyunyh/arithmetic-php/blob/master/package/Sort/QuickSort.php)
+> 快速排序(Quicksort)是对冒泡排序的一种改进。他的基本思想是:通过一趟排序将待排记录分割成独立的两部分,其中一部分的关键字均比另一部分记录的关键字小,则可分别对这两部分记录继续进行快速排序,整个排序过程可以递归进行,以达到整个序列有序的目的。
+
```php
-function QuickSort(array $container)
+function QuickSort(&$arr,$low,$high)
{
- $count = count($container);
- if ($count <= 1) { // 基线条件为空或者只包含一个元素,只需要原样返回数组
- return $container;
+ if ($low < $high) {
+ $middle = getMiddle($arr,$low,$high);
+ QuickSort($arr,$low,$middle-1);
+ QuickSort($arr,$middle+1,$high);
}
- $pivot = $container[0]; // 基准值 pivot
- $left = $right = [];
- for ($i = 1; $i < $count; $i++) {
- if ($container[$i] < $pivot) {
- $left[] = $container[$i];
- } else {
- $right[] = $container[$i];
+}
+
+function getMiddle (&$arr,$low,$high)
+{
+ $temp = $arr[$low];
+ while ($low < $high) {
+ while($low < $high && $temp <= $arr[$high]) {
+ $high --;
+ }
+ $arr[$low] = $arr[$high];
+ while ($low < $high && $temp >= $arr[$low]) {
+ $low ++;
}
+ $arr[$high] = $arr[$low];
}
- $left = QuickSort($left);
- $right = QuickSort($right);
- return array_merge($left, [$container[0]], $right);
+ $arr[$low] = $temp;
+ return $low;
}
```
diff --git "a/\347\256\227\346\263\225/\344\272\214\345\210\206\346\237\245\346\211\276.md" "b/\347\256\227\346\263\225/\344\272\214\345\210\206\346\237\245\346\211\276.md"
new file mode 100644
index 0000000..251be5d
--- /dev/null
+++ "b/\347\256\227\346\263\225/\344\272\214\345\210\206\346\237\245\346\211\276.md"
@@ -0,0 +1,156 @@
+## :算法之排序二分查找
+### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+### :pencil2:二分查找
+
+
+  +
+
+
+**二分查找是一种常见的查找方式。在生活中有一个猜大小的例子。比如给定一个0-100的范围,让你猜出事先我所设置的数字,每次把数字的范围缩小到一半。第一次猜50,大了还是小了,继续缩小数字的范围。但是有一个前提,我们得保证我们查找的是一个有序的范围。**
+
+****
+
+### :pencil2:查找思想
+
+**二分查找针对的是一个有序的集合。它的查找算法有点类型分治的思想,就像上面所说的。每次我通过中间的数和指定的数进行比较,判断大小,缩小猜测的区间,最多到区间等于0的时候,结果也就是最终指定的答案。二分查找是一种高效的查找算法,它的时间复杂度是O(logn).**
+
+****
+
+### :pencil2:php实现二分查找
+
+**1.我们先实现一个最基础的,在一个有序数组中(数组没有重复的值)查找给定值。(迭代)**
+
+```php
+function binarySerach($data,$res)
+{
+ $l=0;
+ $r=count($data)-1;
+ while($l<=$r){
+ // $middle=floor(($l+$r)/2);
+ // $middle=$l+floor(($r-$l)/2);
+ $middle=$l+(($r-$l)>>1); //使用位运算查找更高效
+ if($data[$middle]==$res) return $middle;
+ elseif ($data[$middle]>$res) $r=$middle-1;
+ else $l=$middle+1;
+ }
+ return -1;
+}
+$data=[2,5,6,7,12,34];
+$res=12;
+var_dump(binarySerach($data,$res));
+```
+****
+
+**使用递归实现刚才的操作。**
+
+```php
+function binarySerach($data,$res){
+ return recursion($data,0,count($data)-1,$res);
+}
+
+function recursion($data,$l,$r,$res)
+{
+ if($l>$r){
+ return -1;
+ }
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]==$res) return $middle;
+ elseif ($data[$middle]>$res) return recursion($data,$l,$middle-1,$res);
+ else return recursion($data,$middle+1,$r,$res);
+}
+$data=[2,5,6,7,12,34];
+$res=12;
+var_dump(binarySerach($data,$res));
+```
+****
+
+
+### :pencil2:二分查找的变形问题
+
+**上面的那个注释是在数字没有重复的情况下,现在我们来实现数组中有重复值的情况下,如何查找出第一个等于给定值的元素。其实就是在做等于判断的时候如果索引是0那么是第一个等于给定值的数,或者当前等于给定值的上一个索引值不等于给定值。**
+
+```php
+
+function binarySerach($data,$res){
+ $l=0;
+ $r=count($data);
+ while($l<=$r){
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]>$res) $r=$middle-1;
+ elseif($data[$middle]<$res) $l=$middle+1;
+ else{
+ if($middle==0 || $data[$middle-1] !==$res) return $middle;
+ else $r=$middle-1;
+ }
+ }
+}
+$data=[2,5,6,7,8,8,10];
+$res=8;
+var_dump(binarySerach($data,$res));
+```
+****
+**查找第一个大于等于给定值的元素。**
+```php
+
+//查找第一个大于等于给定值的数
+function binarySerach($data,$res)
+{
+ $l=0;
+ $r=count($data)-1;
+ while($l<=$r){
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]<$res) $l=$middle+1;
+ else{
+ if($middle==0 || $data[$middle-1]<$res ) return $middle;
+ else $r=$middle-1;
+ }
+ }
+
+}
+$data=[2,5,6,7,8,8,10];
+$res=9;
+var_dump(binarySerach($data,$res));
+```
+****
+
+**针对数组是一个循环有序的数组Leetcode35题**
+```php
+
+function binarySerach($data,$res)
+{
+ $l=0;
+ $r=count($data)-1;
+ while($l<=$r){
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]==$res) return $middle;
+ elseif ($data[$middle]>$data[$r]){
+ if($data[$l]<=$res && $data[$middle]>$res) $r=$middle-1;
+ else $l=$middle+1;
+ }else{
+ if($data[$middle]<=$res && $data[$r] >$res) $r=$middle-1;
+ else $l=$middle+1;
+ }
+ }
+}
+$data=[5,6,7,8,1,2,3,4];
+$res=7;
+var_dump(binarySerach($data,$res));
+```
+
+**当然二分查找还有很多的应用场景,我就总结到这了。**
+
+
+
+
+### 联系
+
+
+
+
+
+
+
+
+
diff --git "a/\347\256\227\346\263\225/\345\212\250\346\200\201\350\247\204\345\210\222.md" "b/\347\256\227\346\263\225/\345\212\250\346\200\201\350\247\204\345\210\222.md"
new file mode 100644
index 0000000..4443d82
--- /dev/null
+++ "b/\347\256\227\346\263\225/\345\212\250\346\200\201\350\247\204\345\210\222.md"
@@ -0,0 +1,263 @@
+## :算法算法之动态规划
+
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+***动态规划需要花很长时间去练习巩固的。其实在理解动态规划之前正确的顺序应该是先写递归,因为很多动态规划的转移方程都是通过递归加记忆法从而推导出公式,但是我随性,所以就不按套路出牌了。接下来就是简单介绍一下动态规划以及应用场景,最后把之前刷过的动态规划的题目全放出来,方便一次性查看。***
+****
+
+### :pencil2:动态规划的介绍
+
+***动态规划背后的思想简单概括就是,若要解一个指定的问题,我们需要解它的不同部分问题(子问题),再合并子问题求出最终想要的解。***
+
+***在现实生活中,有一类活动的过程,由于它的特殊性,可将过程分成若干个互相联系的阶段,在它的每一阶段都需要作出决策,从而使整个过程达到最好的活动效果。因此各个阶段决策的选取不能任意确定,它依赖于当前面临的状态,又影响以后的发展。当各个阶段决策确定后,就组成一个决策序列,因而也就确定了整个过程的一条活动路线。这种把一个问题看做是一个前后关联具有链状结构的多阶段过程就称为多阶段决策过程,这种问题称为多阶段决策最优化问题。每个阶段中,都求出本阶段的各个初始状态到过程终点的最短路径和最短距离,当逆序倒推到过程起点时,便得到了全过程的最短路径及最短距离,同时附带得到了一组最优结果。***
+
+
+****
+
+### :pencil2:动态规划的步骤
+
+ ***1.递归+记忆化 ->反向推出递推公式***
+
+ ***2.状态的定义 opt[n],dp[n].***
+
+ ***3.状态转移的方程dp[n]=dp[n-1]+dp[n-2]***
+
+ ***4.最优子结构***
+******
+**最经典的爬楼梯问题,给定一个数字代表着楼梯的层数,每次你可以走一步或者两步,求最终你可以有几种方式到达顶峰。递归是自上而下,一层层调用,到了递归的出口,又一层层的回来。而动态规划是从下而上的去思考,比如还是这个爬楼梯问题,如果是动态规划的思想就是**
+```php
+
+f[n]=f[n-1]+f[n+2];
+//一个斐波那契数列
+```
+
+***动态规划需要大量的实战练习,一般你只要记住两步,定义好状态,有些时候单单定义一个一维数组的状态是不够的,二通过状态的定义推出递推公式。具体看场景使用。(下面是leetcode70,72,120,121,122,123,152,300动态规划的题目)***
+
+
+
+
+
+
+**二分查找是一种常见的查找方式。在生活中有一个猜大小的例子。比如给定一个0-100的范围,让你猜出事先我所设置的数字,每次把数字的范围缩小到一半。第一次猜50,大了还是小了,继续缩小数字的范围。但是有一个前提,我们得保证我们查找的是一个有序的范围。**
+
+****
+
+### :pencil2:查找思想
+
+**二分查找针对的是一个有序的集合。它的查找算法有点类型分治的思想,就像上面所说的。每次我通过中间的数和指定的数进行比较,判断大小,缩小猜测的区间,最多到区间等于0的时候,结果也就是最终指定的答案。二分查找是一种高效的查找算法,它的时间复杂度是O(logn).**
+
+****
+
+### :pencil2:php实现二分查找
+
+**1.我们先实现一个最基础的,在一个有序数组中(数组没有重复的值)查找给定值。(迭代)**
+
+```php
+function binarySerach($data,$res)
+{
+ $l=0;
+ $r=count($data)-1;
+ while($l<=$r){
+ // $middle=floor(($l+$r)/2);
+ // $middle=$l+floor(($r-$l)/2);
+ $middle=$l+(($r-$l)>>1); //使用位运算查找更高效
+ if($data[$middle]==$res) return $middle;
+ elseif ($data[$middle]>$res) $r=$middle-1;
+ else $l=$middle+1;
+ }
+ return -1;
+}
+$data=[2,5,6,7,12,34];
+$res=12;
+var_dump(binarySerach($data,$res));
+```
+****
+
+**使用递归实现刚才的操作。**
+
+```php
+function binarySerach($data,$res){
+ return recursion($data,0,count($data)-1,$res);
+}
+
+function recursion($data,$l,$r,$res)
+{
+ if($l>$r){
+ return -1;
+ }
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]==$res) return $middle;
+ elseif ($data[$middle]>$res) return recursion($data,$l,$middle-1,$res);
+ else return recursion($data,$middle+1,$r,$res);
+}
+$data=[2,5,6,7,12,34];
+$res=12;
+var_dump(binarySerach($data,$res));
+```
+****
+
+
+### :pencil2:二分查找的变形问题
+
+**上面的那个注释是在数字没有重复的情况下,现在我们来实现数组中有重复值的情况下,如何查找出第一个等于给定值的元素。其实就是在做等于判断的时候如果索引是0那么是第一个等于给定值的数,或者当前等于给定值的上一个索引值不等于给定值。**
+
+```php
+
+function binarySerach($data,$res){
+ $l=0;
+ $r=count($data);
+ while($l<=$r){
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]>$res) $r=$middle-1;
+ elseif($data[$middle]<$res) $l=$middle+1;
+ else{
+ if($middle==0 || $data[$middle-1] !==$res) return $middle;
+ else $r=$middle-1;
+ }
+ }
+}
+$data=[2,5,6,7,8,8,10];
+$res=8;
+var_dump(binarySerach($data,$res));
+```
+****
+**查找第一个大于等于给定值的元素。**
+```php
+
+//查找第一个大于等于给定值的数
+function binarySerach($data,$res)
+{
+ $l=0;
+ $r=count($data)-1;
+ while($l<=$r){
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]<$res) $l=$middle+1;
+ else{
+ if($middle==0 || $data[$middle-1]<$res ) return $middle;
+ else $r=$middle-1;
+ }
+ }
+
+}
+$data=[2,5,6,7,8,8,10];
+$res=9;
+var_dump(binarySerach($data,$res));
+```
+****
+
+**针对数组是一个循环有序的数组Leetcode35题**
+```php
+
+function binarySerach($data,$res)
+{
+ $l=0;
+ $r=count($data)-1;
+ while($l<=$r){
+ $middle=$l+(($r-$l)>>1);
+ if($data[$middle]==$res) return $middle;
+ elseif ($data[$middle]>$data[$r]){
+ if($data[$l]<=$res && $data[$middle]>$res) $r=$middle-1;
+ else $l=$middle+1;
+ }else{
+ if($data[$middle]<=$res && $data[$r] >$res) $r=$middle-1;
+ else $l=$middle+1;
+ }
+ }
+}
+$data=[5,6,7,8,1,2,3,4];
+$res=7;
+var_dump(binarySerach($data,$res));
+```
+
+**当然二分查找还有很多的应用场景,我就总结到这了。**
+
+
+
+
+### 联系
+
+
+
+
+
+
+
+
+
diff --git "a/\347\256\227\346\263\225/\345\212\250\346\200\201\350\247\204\345\210\222.md" "b/\347\256\227\346\263\225/\345\212\250\346\200\201\350\247\204\345\210\222.md"
new file mode 100644
index 0000000..4443d82
--- /dev/null
+++ "b/\347\256\227\346\263\225/\345\212\250\346\200\201\350\247\204\345\210\222.md"
@@ -0,0 +1,263 @@
+## :算法算法之动态规划
+
+#### php-leetcode之路 [Leetcode-php](https://github.com/wuqinqiang/leetcode-php)
+
+***动态规划需要花很长时间去练习巩固的。其实在理解动态规划之前正确的顺序应该是先写递归,因为很多动态规划的转移方程都是通过递归加记忆法从而推导出公式,但是我随性,所以就不按套路出牌了。接下来就是简单介绍一下动态规划以及应用场景,最后把之前刷过的动态规划的题目全放出来,方便一次性查看。***
+****
+
+### :pencil2:动态规划的介绍
+
+***动态规划背后的思想简单概括就是,若要解一个指定的问题,我们需要解它的不同部分问题(子问题),再合并子问题求出最终想要的解。***
+
+***在现实生活中,有一类活动的过程,由于它的特殊性,可将过程分成若干个互相联系的阶段,在它的每一阶段都需要作出决策,从而使整个过程达到最好的活动效果。因此各个阶段决策的选取不能任意确定,它依赖于当前面临的状态,又影响以后的发展。当各个阶段决策确定后,就组成一个决策序列,因而也就确定了整个过程的一条活动路线。这种把一个问题看做是一个前后关联具有链状结构的多阶段过程就称为多阶段决策过程,这种问题称为多阶段决策最优化问题。每个阶段中,都求出本阶段的各个初始状态到过程终点的最短路径和最短距离,当逆序倒推到过程起点时,便得到了全过程的最短路径及最短距离,同时附带得到了一组最优结果。***
+
+
+****
+
+### :pencil2:动态规划的步骤
+
+ ***1.递归+记忆化 ->反向推出递推公式***
+
+ ***2.状态的定义 opt[n],dp[n].***
+
+ ***3.状态转移的方程dp[n]=dp[n-1]+dp[n-2]***
+
+ ***4.最优子结构***
+******
+**最经典的爬楼梯问题,给定一个数字代表着楼梯的层数,每次你可以走一步或者两步,求最终你可以有几种方式到达顶峰。递归是自上而下,一层层调用,到了递归的出口,又一层层的回来。而动态规划是从下而上的去思考,比如还是这个爬楼梯问题,如果是动态规划的思想就是**
+```php
+
+f[n]=f[n-1]+f[n+2];
+//一个斐波那契数列
+```
+
+***动态规划需要大量的实战练习,一般你只要记住两步,定义好状态,有些时候单单定义一个一维数组的状态是不够的,二通过状态的定义推出递推公式。具体看场景使用。(下面是leetcode70,72,120,121,122,123,152,300动态规划的题目)***
+
+
+  +
+
+```php
+ /**
+ * @param Integer $n
+ * @return Integer
+ */
+ function climbStairs($n) {
+ if($n<=1){
+ return 1;
+ }
+ $res[0]=1;
+ $res[1]=1;
+ for($i=2;$i<=$n;$i++){
+ $res[$i]=$res[$i-1]+$res[$i-2];
+ }
+ return $res[$n];
+
+ }
+```
+******
+
+
+
+
+
+
+```php
+ /**
+ * @param Integer $n
+ * @return Integer
+ */
+ function climbStairs($n) {
+ if($n<=1){
+ return 1;
+ }
+ $res[0]=1;
+ $res[1]=1;
+ for($i=2;$i<=$n;$i++){
+ $res[$i]=$res[$i-1]+$res[$i-2];
+ }
+ return $res[$n];
+
+ }
+```
+******
+
+
+
+  +
+
+```php
+ /**
+ * @param String $word1
+ * @param String $word2
+ * @return Integer
+ */
+ function minDistance($word1, $word2) {
+
+ for($i=0;$i<=strlen($word1);$i++) $dp[$i][0]=$i;
+ for($i=0;$i<=strlen($word2);$i++) $dp[0][$i]=$i;
+
+ for($i=1;$i<=strlen($word1);$i++){
+ for($j=1;$j<=strlen($word2);$j++){
+ if(substr($word1,$i-1,1)==substr($word2,$j-1,1)){
+ $dp[$i][$j]=$dp[$i-1][$j-1];
+ }else{
+ $dp[$i][$j]=min($dp[$i-1][$j],$dp[$i][$j-1],$dp[$i-1][$j-1])+1;
+ }
+ }
+ }
+ return $dp[strlen($word1)][strlen($word2)];
+ }
+```
+******
+
+
+
+
+
+
+```php
+ /**
+ * @param String $word1
+ * @param String $word2
+ * @return Integer
+ */
+ function minDistance($word1, $word2) {
+
+ for($i=0;$i<=strlen($word1);$i++) $dp[$i][0]=$i;
+ for($i=0;$i<=strlen($word2);$i++) $dp[0][$i]=$i;
+
+ for($i=1;$i<=strlen($word1);$i++){
+ for($j=1;$j<=strlen($word2);$j++){
+ if(substr($word1,$i-1,1)==substr($word2,$j-1,1)){
+ $dp[$i][$j]=$dp[$i-1][$j-1];
+ }else{
+ $dp[$i][$j]=min($dp[$i-1][$j],$dp[$i][$j-1],$dp[$i-1][$j-1])+1;
+ }
+ }
+ }
+ return $dp[strlen($word1)][strlen($word2)];
+ }
+```
+******
+
+
+
+  +
+
+```php
+ /**
+ * @param Integer[][] $triangle
+ * @return Integer
+ */
+ function minimumTotal($triangle) {
+ if(empty(count($triangle))){
+ return 0;
+ }
+ for($i=count($triangle)-1;$i>=0;$i--){
+ for($j=0;$j
+
+
+
+```php
+ /**
+ * @param Integer[][] $triangle
+ * @return Integer
+ */
+ function minimumTotal($triangle) {
+ if(empty(count($triangle))){
+ return 0;
+ }
+ for($i=count($triangle)-1;$i>=0;$i--){
+ for($j=0;$j
+  +
+
+```php
+ /**
+ * @param Integer[] $prices
+ * @return Integer
+ */
+ function maxProfit($prices) {
+
+ //二维数组的0,1,2表示的状态分别是没买股票,买了股票, 卖了股票
+ $res=0;
+ $pro[0][0]=$pro[0][2]=0;
+ $pro[0][1]=-$prices[0];
+ for($i=1;$i
+
+
+
+```php
+ /**
+ * @param Integer[] $prices
+ * @return Integer
+ */
+ function maxProfit($prices) {
+
+ //二维数组的0,1,2表示的状态分别是没买股票,买了股票, 卖了股票
+ $res=0;
+ $pro[0][0]=$pro[0][2]=0;
+ $pro[0][1]=-$prices[0];
+ for($i=1;$i
+  +
+
+```php
+ /**
+ * @param Integer[] $prices
+ * @return Integer
+ */
+ function maxProfit($prices) {
+ $dp[0][0]=0;
+ $dp[0][1]= -$prices[0];
+ $res=0;
+ for($i=1;$i
+
+
+
+```php
+ /**
+ * @param Integer[] $prices
+ * @return Integer
+ */
+ function maxProfit($prices) {
+ $dp[0][0]=0;
+ $dp[0][1]= -$prices[0];
+ $res=0;
+ for($i=1;$i
+  +
+
+```php
+ /**
+ * @param Integer[] $prices
+ * @return Integer
+ */
+ function maxProfit($prices) {
+ $res=0;
+ $dp[0][0][0]=0;
+ $dp[0][0][1]= -$prices[0];
+ $dp[0][1][0]= -$prices[0];
+ $dp[0][1][1]= -$prices[0];
+ $dp[0][2][0]=0;
+
+ for($i=1;$i
+
+
+
+```php
+ /**
+ * @param Integer[] $prices
+ * @return Integer
+ */
+ function maxProfit($prices) {
+ $res=0;
+ $dp[0][0][0]=0;
+ $dp[0][0][1]= -$prices[0];
+ $dp[0][1][0]= -$prices[0];
+ $dp[0][1][1]= -$prices[0];
+ $dp[0][2][0]=0;
+
+ for($i=1;$i
+  +
+
+```php
+ /**
+ * @param Integer[] $nums
+ * @return Integer
+ */
+ function maxProduct($nums) {
+ $max=$min=$res=$nums[0];
+ for($i=1;$i
+
+
+
+```php
+ /**
+ * @param Integer[] $nums
+ * @return Integer
+ */
+ function maxProduct($nums) {
+ $max=$min=$res=$nums[0];
+ for($i=1;$i
+  +
+
+```php
+
+/**
+ * @param Integer[] $nums
+ * @return Integer
+ */
+ function lengthOfLIS($nums) {
+ if(empty($nums)){
+ return 0;
+ }
+ $res=1;
+ for($i=0;$i
+
+
+
+
+
+
+
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md"
index e8ae82a..2f329c8 100644
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md"
+++ "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md"
@@ -39,7 +39,7 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
3. HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4. HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
-
+
## 使用SPDY加快你的网站速度
@@ -64,5 +64,23 @@ SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTT
- **header压缩,**如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- **服务端推送**(server push),同SPDY一样,HTTP2.0也具有server push功能。目前,有大多数网站已经启用HTTP2.0,例如[YouTuBe](https://www.youtube.com/),[淘宝网](http://www.taobao.com/)等网站,利用chrome控制台可以查看是否启用H2
-
+
+```conf
+server {
+ listen 443 ssl http2;
+ server_name example.com;
+ root /var/www/example.com/public;
+
+ # SSL
+ ssl_certificate /etc/live/example.com/fullchain.pem;
+ ssl_certificate_key /etc/live/example.com/privkey.pem;
+ ssl_trusted_certificate /etc/live/example.com/chain.pem;
+
+ # index.html fallback
+ location / {
+ try_files $uri $uri/ /index.html;
+ }
+}
+
+```
\ No newline at end of file
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md"
index 6b3cb1a..8d6b12a 100644
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md"
+++ "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md"
@@ -191,3 +191,16 @@
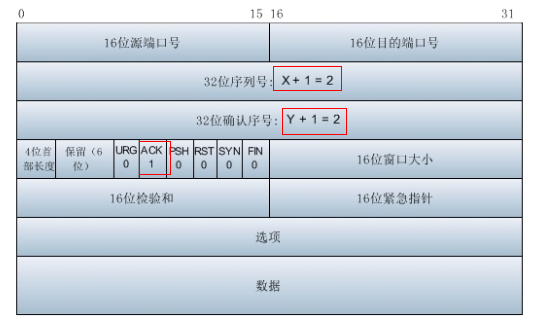
+## TCP粘包
+
+> 世界上本没有“粘包”,只不过是少数人没有正确处理TCP数据边界问题,成熟的应用层协议(http、ssh)都不会存在这个问题。但是如果你使用纯TCP自定义协议,那就需要自己处理好了。
+TCP是面向字节流的传输,一个数据包可能会被拆成多个小的数据包进行发送,这样就会和其他的数据包连在一起,形成粘包。
+举个例子,比如发送两个"hello world" 但是可能服务端收到的是"hello" 和 "worldhello world"。第一次的数据包和第二次的数据连在一起了。
+
+"粘包"的原因
+ - 当连续发送数据时,由于tcp协议的nagle算法,会将较小的内容拼接成大的内容,一次性发送到服务器端,因此造成粘包
+ - 当发送内容较大时,由于服务器端的recv(buffer_size)方法中的buffer_size较小,不能一次性完全接收全部内容,因此在下一次请求到达时,接收的内容依然是上一次没有完全接收完的内容,因此造成粘包现象
+解决粘包的方案
+- 使用特殊的字符或字符串作为消息的边界,例如 HTTP 协议的 headers 以“\r\n”为字段的分隔符,但是如果消息中不能含有定界符,否则会导致消息混乱
+- 消息长度固定,消息长度不足,空白填充 提前确定包长度,读取的时候也安固定长度读取,适合定长消息包。
+- 自定义协议,将消息分为消息头和消息体,消息头中包含表示消息总长度。
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md"
index 08b8f20..37e0ab4 100644
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md"
+++ "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md"
@@ -2,7 +2,7 @@
> Websocket是html5提出的一个协议规范,参考rfc6455。
>
-> websocket约定了一个通信的规范,通过一个握手的机制,客户端(浏览器)和服务器(webserver)之间能建立一个类似tcp的连接,从而方便c-s之间的通信。在websocket出现之前,web交互一般是基于http协议的短连接或者长连接。
+> websocket约定了一个通信的规范,通过一个握手的机制,客户端(浏览器)和服务器(webserver)之间能建立一个类似tcp的连接,从而方便C-S之间的通信。在websocket出现之前,web交互一般是基于http协议的短连接或者长连接。
>
> WebSocket是为解决客户端与服务端实时通信而产生的技术。websocket协议本质上是一个基于tcp的协议,是先通过HTTP/HTTPS协议发起一条特殊的http请求进行握手后创建一个用于交换数据的TCP连接,此后服务端与客户端通过此TCP连接进行实时通信。
@@ -10,7 +10,7 @@
### Websocket和HTTP协议的关系
-同样作为应用层的协议,WebSocket在现代的软件开发中被越来越多的实践,和HTTP有很多相似的地方,这里将它们简单的做一个纯个人、非权威的比较:
+同样作为应用层的协议,WebSocket在现代的软件开发中被越来越多的实践,和HTTP有很多相似的地方,这里将它们简单比较:
#### 相同点
@@ -58,12 +58,10 @@ Sec-WebSocket-Version: 13
```http
HTTP/1.1 101 Switching Protocols
-Content-Length: 0
Upgrade: websocket
Sec-Websocket-Accept: ZEs+c+VBk8Aj01+wJGN7Y15796g=
-Server: TornadoServer/4.5.1
Connection: Upgrade
-Date: Wed, 21 Jun 2017 03:29:14 GMT
+Sec-WebSocket-Protocol: chat, superchat
```
Sec-Websocket-Accept 是一个校验。用客户端发来的sec_key 服务器通过sha1计算拼接商GUID【258EAFA5-E914-47DA-95CA-C5AB0DC85B11 】 。然后再base64encode
@@ -96,10 +94,95 @@ Sec-Websocket-Accept 是一个校验。用客户端发来的sec_key 服务器通
- Payload data:任意长度数据。包含有扩展定义数据和应用数据,如果没有定义扩展则没有此项,仅含有应用数据。
+### 服务端简单实现
+```php
+// 封装ws 协议的数据包
+function build($msg) {
+ $frame = [];
+ $frame[0] = '81'; // 81 就是 10000001 第一位1表示最后一个数据段,最后一位1表示这是文本数据
+ $len = strlen($msg);
+ if ($len < 126) {
+ //7位长度 第一个是掩码 默认是0
+ //小于126的时候 也是 01111110 数据包第二个字节表示长度
+ $frame[1] = $len < 16 ? '0' . dechex($len) : dechex($len);
+ } else if ($len < 65025) {
+ //7位 + 16位 01111110 00000000 00000000
+ $s = dechex($len);
+ $frame[1] = '7e' . str_repeat('0', 4 - strlen($s)) . $s;
+ } else {
+ //7位 + 64位 01111111 00000000 00000000
+ $s = dechex($len);
+ $frame[1] = '7f' . str_repeat('0', 16 - strlen($s)) . $s;
+ }
+ $data = '';
+ $l = strlen($msg);
+ for ($i = 0; $i < $l; $i++) {
+ $data .= dechex(ord($msg{$i}));
+ }
+ //最后是数据内容
+ $frame[2] = $data;
+ $data = implode('', $frame);
+ return pack("H*", $data);
+}
+//拆包
+function parse($buffer) {
+ $decoded = '';
+ $len = ord($buffer[1]) & 127;
+ if ($len === 126) {
+ $masks = substr($buffer, 4, 4);
+ $data = substr($buffer, 8);
+ } else if ($len === 127) {
+ $masks = substr($buffer, 10, 4);
+ $data = substr($buffer, 14);
+ } else {
+ $masks = substr($buffer, 2, 4);
+ $data = substr($buffer, 6);
+ }
+ for ($index = 0; $index < strlen($data); $index++) {
+ $decoded .= $data[$index] ^ $masks[$index % 4];
+ }
+ return $decoded;
+ }
+$socket = stream_socket_server("tcp://0.0.0.0:8888", $errno, $errstr);
+if (!$socket) {
+ echo "$errstr ($errno)
+
+
+```php
+
+/**
+ * @param Integer[] $nums
+ * @return Integer
+ */
+ function lengthOfLIS($nums) {
+ if(empty($nums)){
+ return 0;
+ }
+ $res=1;
+ for($i=0;$i
+
+
+
+
+
+
+
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md"
index e8ae82a..2f329c8 100644
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md"
+++ "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/HTTP2.md"
@@ -39,7 +39,7 @@ HTTP1.0最早在网页中使用是在1996年,那个时候只是使用一些较
3. HTTP和HTTPS使用的是完全不同的连接方式,用的端口也不一样,前者是80,后者是443。
4. HTTPS可以有效的防止运营商劫持,解决了防劫持的一个大问题。
-
+
## 使用SPDY加快你的网站速度
@@ -64,5 +64,23 @@ SPDY位于HTTP之下,TCP和SSL之上,这样可以轻松兼容老版本的HTT
- **header压缩,**如上文中所言,对前面提到过HTTP1.x的header带有大量信息,而且每次都要重复发送,HTTP2.0使用encoder来减少需要传输的header大小,通讯双方各自cache一份header fields表,既避免了重复header的传输,又减小了需要传输的大小。
- **服务端推送**(server push),同SPDY一样,HTTP2.0也具有server push功能。目前,有大多数网站已经启用HTTP2.0,例如[YouTuBe](https://www.youtube.com/),[淘宝网](http://www.taobao.com/)等网站,利用chrome控制台可以查看是否启用H2
-
+
+```conf
+server {
+ listen 443 ssl http2;
+ server_name example.com;
+ root /var/www/example.com/public;
+
+ # SSL
+ ssl_certificate /etc/live/example.com/fullchain.pem;
+ ssl_certificate_key /etc/live/example.com/privkey.pem;
+ ssl_trusted_certificate /etc/live/example.com/chain.pem;
+
+ # index.html fallback
+ location / {
+ try_files $uri $uri/ /index.html;
+ }
+}
+
+```
\ No newline at end of file
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md"
index 6b3cb1a..8d6b12a 100644
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md"
+++ "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/TCP\345\215\217\350\256\256.md"
@@ -191,3 +191,16 @@

+## TCP粘包
+
+> 世界上本没有“粘包”,只不过是少数人没有正确处理TCP数据边界问题,成熟的应用层协议(http、ssh)都不会存在这个问题。但是如果你使用纯TCP自定义协议,那就需要自己处理好了。
+TCP是面向字节流的传输,一个数据包可能会被拆成多个小的数据包进行发送,这样就会和其他的数据包连在一起,形成粘包。
+举个例子,比如发送两个"hello world" 但是可能服务端收到的是"hello" 和 "worldhello world"。第一次的数据包和第二次的数据连在一起了。
+
+"粘包"的原因
+ - 当连续发送数据时,由于tcp协议的nagle算法,会将较小的内容拼接成大的内容,一次性发送到服务器端,因此造成粘包
+ - 当发送内容较大时,由于服务器端的recv(buffer_size)方法中的buffer_size较小,不能一次性完全接收全部内容,因此在下一次请求到达时,接收的内容依然是上一次没有完全接收完的内容,因此造成粘包现象
+解决粘包的方案
+- 使用特殊的字符或字符串作为消息的边界,例如 HTTP 协议的 headers 以“\r\n”为字段的分隔符,但是如果消息中不能含有定界符,否则会导致消息混乱
+- 消息长度固定,消息长度不足,空白填充 提前确定包长度,读取的时候也安固定长度读取,适合定长消息包。
+- 自定义协议,将消息分为消息头和消息体,消息头中包含表示消息总长度。
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md"
index 08b8f20..37e0ab4 100644
--- "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md"
+++ "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/Webscokt.md"
@@ -2,7 +2,7 @@
> Websocket是html5提出的一个协议规范,参考rfc6455。
>
-> websocket约定了一个通信的规范,通过一个握手的机制,客户端(浏览器)和服务器(webserver)之间能建立一个类似tcp的连接,从而方便c-s之间的通信。在websocket出现之前,web交互一般是基于http协议的短连接或者长连接。
+> websocket约定了一个通信的规范,通过一个握手的机制,客户端(浏览器)和服务器(webserver)之间能建立一个类似tcp的连接,从而方便C-S之间的通信。在websocket出现之前,web交互一般是基于http协议的短连接或者长连接。
>
> WebSocket是为解决客户端与服务端实时通信而产生的技术。websocket协议本质上是一个基于tcp的协议,是先通过HTTP/HTTPS协议发起一条特殊的http请求进行握手后创建一个用于交换数据的TCP连接,此后服务端与客户端通过此TCP连接进行实时通信。
@@ -10,7 +10,7 @@
### Websocket和HTTP协议的关系
-同样作为应用层的协议,WebSocket在现代的软件开发中被越来越多的实践,和HTTP有很多相似的地方,这里将它们简单的做一个纯个人、非权威的比较:
+同样作为应用层的协议,WebSocket在现代的软件开发中被越来越多的实践,和HTTP有很多相似的地方,这里将它们简单比较:
#### 相同点
@@ -58,12 +58,10 @@ Sec-WebSocket-Version: 13
```http
HTTP/1.1 101 Switching Protocols
-Content-Length: 0
Upgrade: websocket
Sec-Websocket-Accept: ZEs+c+VBk8Aj01+wJGN7Y15796g=
-Server: TornadoServer/4.5.1
Connection: Upgrade
-Date: Wed, 21 Jun 2017 03:29:14 GMT
+Sec-WebSocket-Protocol: chat, superchat
```
Sec-Websocket-Accept 是一个校验。用客户端发来的sec_key 服务器通过sha1计算拼接商GUID【258EAFA5-E914-47DA-95CA-C5AB0DC85B11 】 。然后再base64encode
@@ -96,10 +94,95 @@ Sec-Websocket-Accept 是一个校验。用客户端发来的sec_key 服务器通
- Payload data:任意长度数据。包含有扩展定义数据和应用数据,如果没有定义扩展则没有此项,仅含有应用数据。
+### 服务端简单实现
+```php
+// 封装ws 协议的数据包
+function build($msg) {
+ $frame = [];
+ $frame[0] = '81'; // 81 就是 10000001 第一位1表示最后一个数据段,最后一位1表示这是文本数据
+ $len = strlen($msg);
+ if ($len < 126) {
+ //7位长度 第一个是掩码 默认是0
+ //小于126的时候 也是 01111110 数据包第二个字节表示长度
+ $frame[1] = $len < 16 ? '0' . dechex($len) : dechex($len);
+ } else if ($len < 65025) {
+ //7位 + 16位 01111110 00000000 00000000
+ $s = dechex($len);
+ $frame[1] = '7e' . str_repeat('0', 4 - strlen($s)) . $s;
+ } else {
+ //7位 + 64位 01111111 00000000 00000000
+ $s = dechex($len);
+ $frame[1] = '7f' . str_repeat('0', 16 - strlen($s)) . $s;
+ }
+ $data = '';
+ $l = strlen($msg);
+ for ($i = 0; $i < $l; $i++) {
+ $data .= dechex(ord($msg{$i}));
+ }
+ //最后是数据内容
+ $frame[2] = $data;
+ $data = implode('', $frame);
+ return pack("H*", $data);
+}
+//拆包
+function parse($buffer) {
+ $decoded = '';
+ $len = ord($buffer[1]) & 127;
+ if ($len === 126) {
+ $masks = substr($buffer, 4, 4);
+ $data = substr($buffer, 8);
+ } else if ($len === 127) {
+ $masks = substr($buffer, 10, 4);
+ $data = substr($buffer, 14);
+ } else {
+ $masks = substr($buffer, 2, 4);
+ $data = substr($buffer, 6);
+ }
+ for ($index = 0; $index < strlen($data); $index++) {
+ $decoded .= $data[$index] ^ $masks[$index % 4];
+ }
+ return $decoded;
+ }
+$socket = stream_socket_server("tcp://0.0.0.0:8888", $errno, $errstr);
+if (!$socket) {
+ echo "$errstr ($errno)
\n";
+ die;
+}
+while (1) {
+ $conn = stream_socket_accept($socket);
+ $data = stream_get_contents($conn,500);
+ $data = explode("\r\n",$data);
+ $secKey = "";
+ foreach ($data as $key=>$val) {
+ if (strpos($val,"WebSocket-Key:") >= 1 ) {
+ $key = explode(":",$val );
+ $secKey = $key[1];
+ }
+ }
+ //固定key 算法 base64(sha1(key+258EAFA5-E914-47DA-95CA-C5AB0DC85B11))
+ $hashkey = base64_encode(sha1(trim($secKey)."258EAFA5-E914-47DA-95CA-C5AB0DC85B11",true));
+ $ws = "HTTP/1.1 101 Switching Protocols\r\n";
+ $ws .= "Upgrade: websocket\r\n";
+ $ws .= "Connection: Upgrade\r\n";
+ $ws .= "Sec-WebSocket-Version:13\r\n";
+ $ws .= "Sec-WebSocket-Accept: $hashkey\r\n";
+ $ws .= "Sec-WebSocket-Protocol: chat\r\n";
+ $ws .= "\r\n";
+ if (!$conn) {
+ continue;
+ }
+ fwrite($conn, $ws);
+ fwrite($conn,build("hello"));
+ fclose($conn);
+ break;
+}
+fclose($socket);
+```
+
### 客户端
```js
-var websocket = new WebSocket("ws://127.0.0.1")
+var websocket = new WebSocket("ws://127.0.0.1:8888","chat")
websocket.onopen = function(){
}
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/images/http2.png" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/images/http2.png"
new file mode 100644
index 0000000..9cf1a93
Binary files /dev/null and "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/images/http2.png" differ
diff --git "a/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/images/https.png" "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/images/https.png"
new file mode 100644
index 0000000..c998d85
Binary files /dev/null and "b/\350\256\241\347\256\227\346\234\272\347\275\221\347\273\234/images/https.png" differ
diff --git "a/\351\235\242\350\257\225/05\350\260\210\350\226\252\350\265\204.md" "b/\351\235\242\350\257\225/05\350\260\210\350\226\252\350\265\204.md"
new file mode 100644
index 0000000..e6964a4
--- /dev/null
+++ "b/\351\235\242\350\257\225/05\350\260\210\350\226\252\350\265\204.md"
@@ -0,0 +1,27 @@
+谈薪资的时候,基本上是我们到了面试的最后的步骤了,这个时候,你的报价决定你以后的工作的工资的多少。也是很关键的一步,我之前面试的就是由于缺乏经验,导致自己报价低了。然后入职之后再往上加,就很难了。
+
+
+
+在我们面试的时候,我们**尽量不要先出牌**,比如我们在填表格的时候,期望薪资, 可以写上面谈,或者写一个范围区间。不要写一个具体的数字,因为很多hr人员都会压低你的工资。比如你写的是20k,可能hr会给你18k。
+
+- 你期望的薪资是多少?
+
+**了解该公司所在地区、所属行业、公司规模等信息**,你的薪水要求应该在该公司所在地 区、行业、公司规模相应的薪水范围之内。**尽可能提供一个你期望的薪水范围,而不是具体的薪金数。** 了解具体的福利情况。好的福利可以让你的薪资加上不少。比如有的公司是15薪,然后公司稍低点,有的工资高,但是福利少。你可以权衡一下。
+
+
+
+- 你的上一份的薪资是多少?
+
+ 问你这个问题的时候,是想知道和你当前薪资对比,比如你上一份是10k ,这次你报价20k,别人应该只会给你15k。所以上一份的薪资,应该和本次的报价,不是特别差别大。但是也不能一样。不然你跳槽就没不涨薪,上一份的薪资,你就应该把你的福利也加上。比如你有绩效奖金,薪资调整都加上,得到一个范围值,不要告诉具体的数值。比如你薪资15k,你加上乱七八糟的,你可以说15-18k之间。
+
+- 你认为每年的加薪幅度是多少?
+
+ 提示:通常, 比较可靠的回答是: 你希望收入的增长和生活水平的提高保持一致。你还应该提到,
+
+ 你的业绩将是加薪的主要因素
+
+ **求职者** : 总体来说,取决于我个人的业绩和公司的业绩(盈利状况)。但一般而言,至少和生活水平的提高保持一致。
+
+
+
+在面试过程中,我们做的准备与实际遇到的问题总会有一些出入。记得大致的原则,巧妙的随机应变。懂得自己在市场中的定位,将对薪资的确定更为有利。
diff --git "a/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\230.md" "b/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\230.md"
index a2a792a..ac44e8a 100644
--- "a/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\230.md"
+++ "b/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\230.md"
@@ -217,7 +217,7 @@ function getPoint(Node $a,Node $b) {
17、**isset(null) isset(false) empty(null) empty(false)输出**
- false,false,true,true
+ false,true,true,true,[参考](http://php.net/manual/zh/types.comparisons.php)
18、**优化MYSQL的方法**
@@ -391,15 +391,76 @@ type 记录变量的类型。然后根据不同的类型,找到不同的value

-38、有两个文件文件,大小都超过了1G,一行一条数据,每行数据不超过500字节,两文件中有一部分内容是完全相同的,请写代码找到相同的行,并写到新文件中。PHP最大允许内内为255M。
+38、有两个文本文件,大小都超过了1G,一行一条数据,每行数据不超过500字节,两文件中有一部分内容是完全相同的,请写代码找到相同的行,并写到新文件中。PHP最大允许内内为255M。
+
+```php
+// 思路:使用协程yield
+function readFieldFile($fileName)
+{
+ $fp = fopen($fileName, "rb");
+ while (!feof($fp)) {
+ yield fgets($fp);
+ }
+ fclose($fp);
+}
+
+$file1 = readFieldFile('big1.txt');
+$file2 = readFieldFile('big2.txt');
+
+$file1->rewind();
+$file2->rewind();
+while ($file1->valid() && $file2->valid()) {
+ if ($file1->current() == $file2->current()) {
+ file_put_contents('big.txt', $file1->current(), FILE_APPEND);
+ }
+ $file1->next();
+ $file2->next();
+}
+```
39、请写出自少两个支持回调处理的PHP函数,并自己实现一个支持回调的PHP函数
-preg_matacth_callback. call_user_func
+preg_match_callback. call_user_func
+
+```php
+function myCallBack(Closure $closure, $a, $b)
+{
+ return $closure($a, $b);
+}
+
+myCallBack(function ($a, $b) {
+ return $a + $b;
+}, 1, 2);
+
+```
-40、请写出自少两个获取指定文件夹下所有文件的方法(代码或思路)。
+40、请写出至少两个获取指定文件夹下所有文件的方法(代码或思路)。
+
+```php
+// 递归获取,排除.和..,除了文件夹就是文件
+function myScanDir($dir)
+{
+ $files = array();
+ if (is_dir($dir)) {
+ if ($handle = opendir($dir)) {
+ while (($file = readdir($handle)) !== false) {
+ if ($file != "." && $file != "..") {
+ if (is_dir($dir . "/" . $file)) {
+ $files[$file] = myScanDir($dir . "/" . $file);
+ } else {
+ $files[] = $dir . "/" . $file;
+ }
+ }
+ }
+ closedir($handle);
+ return $files;
+ }
+ }
+}
+
+```
-41、请写出自少三种截取文件名后缀的方法或函数(PHP原生函数和自己实现函数均可)
+41、请写出至少三种截取文件名后缀的方法或函数(PHP原生函数和自己实现函数均可)
basename expload() strpos
diff --git "a/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2302.md" "b/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2302.md"
index f4b37f3..629334b 100644
--- "a/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2302.md"
+++ "b/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2302.md"
@@ -4,7 +4,7 @@
1. TCP报头格式
- 
+ 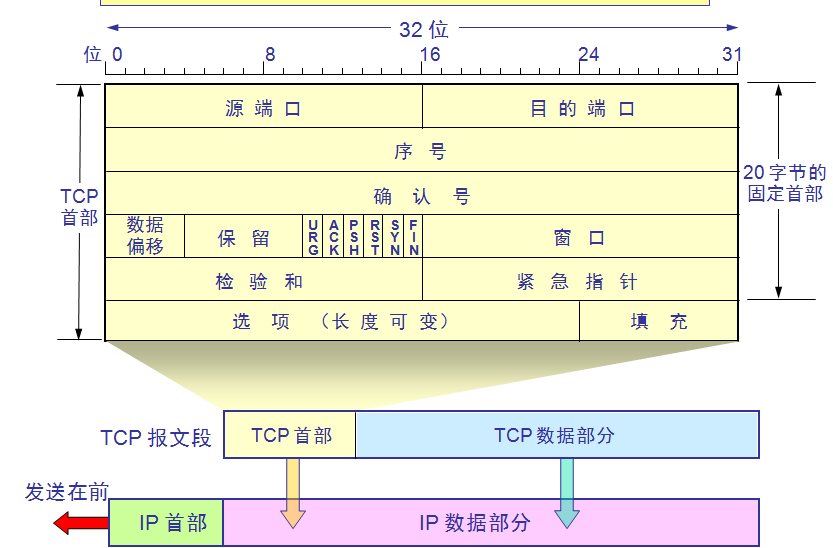
端口号用来标识不同的应用程序。
@@ -41,13 +41,13 @@
- 5、首部长度:首部中32bit字的数目,可表示15*32bit=60字节的首部。一般首部长度为20字节。
- 6、数据
-1. TCP/UDP区别(不仅是宏观上的,最好能根据各自的机制讲解清楚)
+3. TCP/UDP区别(不仅是宏观上的,最好能根据各自的机制讲解清楚)
TCP存在三次握手。能进行流量控制,保证数据的完整。
UDP不存在握手。会导致丢包。传输比较快。
-2. HTTP状态码(最好结合使用场景,比如在缓存命中时使用哪个)
+4. HTTP状态码(最好结合使用场景,比如在缓存命中时使用哪个)
2xx 标识正常
@@ -57,13 +57,13 @@
5xx 服务器内部错误
-3. HTTP协议(一些报头字段的作用,如cace-control、keep-alive)
+5. HTTP协议(一些报头字段的作用,如cace-control、keep-alive)
-4. OSI协议、TCP/IP协议以及每层对应的协议。
+6. OSI协议、TCP/IP协议以及每层对应的协议。
-5. SESSION机制、cookie机制
+7. SESSION机制、cookie机制
-6. TCP三次握手、四次挥手(这个问题真的要回答吐了,不过真的是面试官最喜欢问的,建议每天手撸一遍,而且不只是每次请求的过程,各种FIN_WAIT、TIME_WAIT状态也要掌握)。
+8. TCP三次握手、四次挥手(这个问题真的要回答吐了,不过真的是面试官最喜欢问的,建议每天手撸一遍,而且不只是每次请求的过程,各种FIN_WAIT、TIME_WAIT状态也要掌握)。
[TCP详解](https://github.com/xianyunyh/tcp-ip-protocal)
@@ -80,11 +80,15 @@
- 服务器再发送FIN,序号为N的数据包 进入LAST_ACK
- 客户端收到后,进入TIME_WAIT,再发送ACK=1.ack=N+1的数据包 服务端进入 CLOSED
-1. 打开网页到页面显示之间的过(涵盖了各个方面,DNS解析过程,Nginx请求转发、连接建立和保持过程、浏览器内容渲染过程,考虑的越详细越好)。
-2. http和https区别,https在请求时额外的过程,https是如何保证数据安全的
-3. IP地址子网划分
-4. POST和GET区别
-5. DNS解析过程
+9. 打开网页到页面显示之间的过(涵盖了各个方面,DNS解析过程,Nginx请求转发、连接建立和保持过程、浏览器内容渲染过程,考虑的越详细越好)。
+
+10. http和https区别,https在请求时额外的过程,https是如何保证数据安全的
+
+11. IP地址子网划分
+
+12. POST和GET区别
+
+13. DNS解析过程
**深入部分**
diff --git "a/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2304.md" "b/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2304.md"
index c945417..b2237af 100644
--- "a/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2304.md"
+++ "b/\351\235\242\350\257\225/\347\254\224\350\257\225\351\242\2304.md"
@@ -10,7 +10,7 @@
3. `$a = 3; echo "$a",'$a',"\\\$a","$a"."$a","$a"+"$a"`
- 33$a\$a336
+ 3$a\$a336
4. require include区别
@@ -65,4 +65,4 @@
19. 项目中遇到了什么问题,
20. 之前的项目有没有其他的优化方案?
21. 平时怎么学习的?
-22. 未来的职业的职业方向?
\ No newline at end of file
+22. 未来的职业的职业方向?
diff --git "a/\351\235\242\350\257\225/\351\235\242\350\257\225\346\200\273\347\273\223.md" "b/\351\235\242\350\257\225/\351\235\242\350\257\225\346\200\273\347\273\223.md"
new file mode 100644
index 0000000..306bcae
--- /dev/null
+++ "b/\351\235\242\350\257\225/\351\235\242\350\257\225\346\200\273\347\273\223.md"
@@ -0,0 +1,45 @@
+参加了一次的面试,和面试官聊的还可以,最后让面试官对我简单评价下和给我一点建议,对方说我技术栈比较全面,但是可能缺少大型项目的锻炼,说的很对。大型项目可是自己的短板,理论的东西没有实战,只是理论。下面就记录下面试的问题。
+
+
+
+1. 你们之前的项目的pv、uv是多少?
+
+这个我当时实话实说了,pv并不高,高并发不存在。架构简单,因为不想瞎扯,吹那么多
+
+2. 之前项目有没有做过集群
+
+这个确实做过,无论是采用的阿里云的负载均衡还是自己nginx搭建的反向代理和自己用lvs+keeplived做的实验,都说了
+
+3. 做了集群,后端的机器如何拿到前面访问的真实IP
+
+这个通过添加header头的方式
+
+4. 协成了解过吗?和线程的区别
+
+用户态线程,由程序控制,开销小,线程CPU直接调度,CPU时钟切换,耗费资源
+
+5. 分库分表做过没?采取什么样的方式
+
+通过区间范围、hash
+
+6. mysql分区表了解过没
+
+了解过,但是这种一般不推荐用
+
+7. sso单点登陆有哪些方案
+
+这个我当时想的是统一中心认证,使用jsonp拉取登陆信息。
+
+8. 主流的框架,都看过源码没?
+
+看过thinkphp laravel的
+
+9. swoole了解过没?使用过没?
+
+这个了解过,真实项目未使用。
+
+10. golang的协程、python的协程,的区别
+
+golang的协程goruntine
+
+11. 对加班怎么看?
\ No newline at end of file
diff --git "a/\351\235\242\350\257\225/\351\235\242\350\257\225\351\242\2305.md" "b/\351\235\242\350\257\225/\351\235\242\350\257\225\351\242\2305.md"
new file mode 100644
index 0000000..a8a82c6
--- /dev/null
+++ "b/\351\235\242\350\257\225/\351\235\242\350\257\225\351\242\2305.md"
@@ -0,0 +1,74 @@
+今天去参加了一个面试,然后总共就4个题目,记录下,给大家一点启发。
+
+### 1. 查询订单表(order)中,累计支付金额大于200的用户
+
+| uid | amount|
+| :------------ | :------------ |
+| 1 | 10 |
+| 2| 10 |
+
+```sql
+select sum(amount) as ct,uid from orders group by uid having ct > 200
+```
+### 2. 查询一个表中的重叠数据。
+
+| id | uid | start | end |
+| ------------ | ------------ | ------------ | ------------ |
+| 1| 1 | 2020-02-01 | 2020-03-01 |
+| 2 | 1 | 2020-02-04 |2020-04-03 |
+| 3 | 2 | 2020-01-01 | 2020-02-01 |
+| 4 | 2 | 2020-02-02 | 2020-05-01 |
+
+解释: 在上述表中,`uid=1`的记录 在时间段上有重叠, id=1的记录和`2020-02-01` - `2020-03-01` 和 id = 2的记录 `2020-02-04` - `2020-04-03`。
+写一个sql实现,找出找个重叠的两条数据。
+
+- 利用自联结
+- 出现重叠数据一条记录的开始时间落在的另外一条记录的start和end之间
+
+```sql
+SELECT
+ a.uid,
+ a.`start` AS a_start,
+ b.`start` AS b_start,
+ a.`end` AS a_end,
+ b.`end` AS b_end
+FROM
+ log AS a
+LEFT JOIN log AS b ON a.uid = b.uid
+WHERE
+ a.id <> b.id
+AND (
+ (a.`start` > b.`start` && a.`start` < b.`end`) or (b.`start` > a.`start` && b.`start` < a.end )
+)
+ORDER BY
+ a.id ASC
+```
+
+### 3. 实现一个函数,判断给定的字符串是不是合法?
+ ```php
+ function isEmail(array $string): bool {
+
+ }
+ ```
+1. 假设给定的字符串是一个字符数组 `['a','b'....]`
+2. 不允许使用正则表达式
+3. 你只能使用以下三个函数 `empty`、`foreach`、`array_shift`
+4. 假定给定的字符中只有**小写字母[a-z]**、**\@**、**\.** 这三种字符
+正确的邮箱:`test@test.com`
+不是邮箱的字符:`@.`、`.@`、`@@`、`a@test.cc.c`、`aac@..a`
+
+### 4. 防止超卖
+商品表(goods)
+- good_id 商品id
+- num 库存
+| good_id | num |
+| ------------ | ------------ |
+| 1 | 1 |
+
+ ```php
+ $dbh->beginTransaction();
+ //加锁
+ $dbh->execute("update goods set num = num -1 where goods_id =1")
+ $dbh->commit();
+ ```
+上面的代码有啥问题?,如何解决?
diff --git "a/\351\235\242\350\257\225/\351\235\242\350\257\225\351\242\2306.md" "b/\351\235\242\350\257\225/\351\235\242\350\257\225\351\242\2306.md"
new file mode 100644
index 0000000..6f19a7a
--- /dev/null
+++ "b/\351\235\242\350\257\225/\351\235\242\350\257\225\351\242\2306.md"
@@ -0,0 +1,22 @@
+## 实现version_compare函数。
+
+1. 假设给你的两个版本号里面,都不为空
+2. 字符串中只包含数字和小数点.
+3. 如果a >b 返回 1 b > a 返回-1,其他情况返回0
+```php
+ function version_compare(string $v1,string $v2): int{
+ $v1Arr = explode('.',$v1);
+ $v2Arr = explode('.',$v2);
+ $len = count($v1Arr) > count($v2Arr) ? count($v1Arr) : count($v2Arr);
+ for ($i = 0; $i < $len;$i++) {
+ $n = (int)($v1Arr[$i] ?? 0);
+ $m = (int) ($v2Arr[$i] ?? 0);
+ if ($n > $m) {
+ return 1;
+ } else if ($n < $m) {
+ return -1;
+ }
+ }
+ return 0;
+ }
+```