|
6 | 6 | 2. 消息队列相关:削峰和解耦; |
7 | 7 | 3. Redis 相关:缓存穿透问题的解决; |
8 | 8 | 4. 一些基础问题: |
9 | | - - 网络相关:1.浏览器输入URL发生了什么? 2.TCP和UDP区别? 3.TCP如何保证传输可靠性? |
10 | | - - Java 基础: |
| 9 | + - 网络相关:1.浏览器输入 URL 发生了什么? 2.TCP 和 UDP 区别? 3.TCP 如何保证传输可靠性? |
| 10 | + - Java 基础:1. 既然有了字节流,为什么还要有字符流? 2.深拷贝 和 浅拷贝有啥区别呢? |
11 | 11 |
|
12 | 12 | 下面是正文! |
13 | 13 |
|
|
76 | 76 |
|
77 | 77 | > 我觉得可以从下面几个方面来说: |
78 | 78 | > |
79 | | -> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入MQ之前,你不用考虑消息丢失或者说MQ挂掉等等的情况,但是,引入MQ之后你就需要去考虑了! |
80 | | -> 2. **系统复杂性提高:** 加入MQ之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题! |
| 79 | +> 1. **系统可用性降低:** 系统可用性在某种程度上降低,为什么这样说呢?在加入 MQ 之前,你不用考虑消息丢失或者说 MQ 挂掉等等的情况,但是,引入 MQ 之后你就需要去考虑了! |
| 80 | +> 2. **系统复杂性提高:** 加入 MQ 之后,你需要保证消息没有被重复消费、处理消息丢失的情况、保证消息传递的顺序性等等问题! |
81 | 81 | > 3. **一致性问题:** 我上面讲了消息队列可以实现异步,消息队列带来的异步确实可以提高系统响应速度。但是,万一消息的真正消费者并没有正确消费消息怎么办?这样就会导致数据不一致的情况了! |
82 | 82 |
|
83 | 83 | **面试官**:做项目的过程中遇到了什么问题吗?解决了吗?如果解决的话是如何解决的呢? |
|
112 | 112 | > |
113 | 113 | > 另外,这里多说一嘴,一般情况下我们是这样设计 key 的: `表名:列名:主键名:主键值`。 |
114 | 114 | > |
115 | | -> **2)布隆过滤器:**布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在与海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。 |
| 115 | +> **2)布隆过滤器:** 布隆过滤器是一个非常神奇的数据结构,通过它我们可以非常方便地判断一个给定数据是否存在于海量数据中。我们需要的就是判断 key 是否合法,有没有感觉布隆过滤器就是我们想要找的那个“人”。 |
116 | 116 |
|
117 | 117 | **面试官:** 不错不错!你还知道布隆过滤器啊!来给我谈一谈。 |
118 | 118 |
|
119 | | -**我:** 内心os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。” |
| 119 | +**我:** 内心 os:“如果你准备过海量数据处理的面试题,你一定对:“如何确定一个数字是否在于包含大量数字的数字集中(数字集很大,5 亿以上!)?”这个题目很了解了!解决这道题目就要用到布隆过滤器。” |
120 | 120 |
|
121 | | -> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。** |
| 121 | +> 布隆过滤器在针对海量数据去重或者验证数据合法性的时候非常有用。**布隆过滤器的本质实际上是 “位(bit)数组”,也就是说每一个存入布隆过滤器的数据都只占一位。相比于我们平时常用的的 List、Map 、Set 等数据结构,它占用空间更少并且效率更高,但是缺点是其返回的结果是概率性的,而不是非常准确的。** |
122 | 122 | > |
123 | 123 | > **当一个元素加入布隆过滤器中的时候,会进行如下操作:** |
124 | 124 | > |
|
132 | 132 | > |
133 | 133 | > 举个简单的例子: |
134 | 134 | > |
135 | | -> |
136 | | -> |
137 | 135 | > 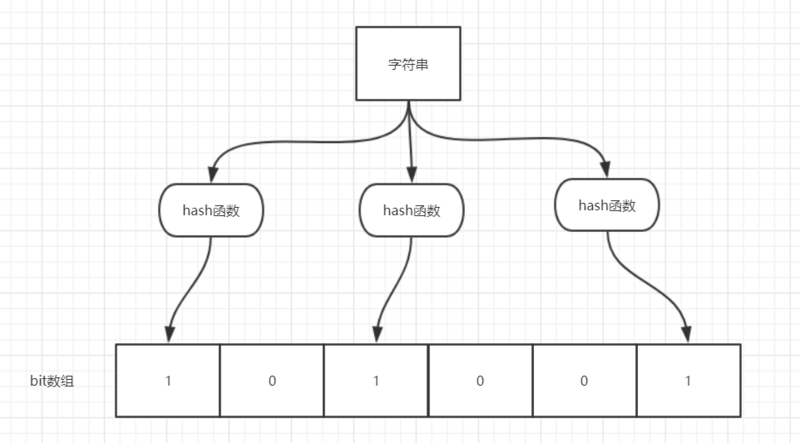 |
138 | 136 | > |
139 | | -> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为0)。当第二次存储相同字符串时,因为先前的对应位置已设置为1,所以很容易知道此值已经存在(去重非常方便)。 |
| 137 | +> 如图所示,当字符串存储要加入到布隆过滤器中时,该字符串首先由多个哈希函数生成不同的哈希值,然后在对应的位数组的下表的元素设置为 1(当位数组初始化时 ,所有位置均为 0)。当第二次存储相同字符串时,因为先前的对应位置已设置为 1,所以很容易知道此值已经存在(去重非常方便)。 |
140 | 138 | > |
141 | 139 | > 如果我们需要判断某个字符串是否在布隆过滤器中时,只需要对给定字符串再次进行相同的哈希计算,得到值之后判断位数组中的每个元素是否都为 1,如果值都为 1,那么说明这个值在布隆过滤器中,如果存在一个值不为 1,说明该元素不在布隆过滤器中。 |
142 | 140 | > |
|
150 | 148 |
|
151 | 149 | <img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/布隆过滤器-缓存穿透-redis.png" style="zoom:50%;" /> |
152 | 150 |
|
153 | | -更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md) ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。 |
| 151 | +更多关于布隆过滤器的内容可以看我的这篇原创:[《不了解布隆过滤器?一文给你整的明明白白!》](https://github.com/Snailclimb/JavaGuide/blob/master/docs/dataStructures-algorithms/data-structure/bloom-filter.md "《不了解布隆过滤器?一文给你整的明明白白!》") ,强烈推荐,个人感觉网上应该找不到总结的这么明明白白的文章了。 |
154 | 152 |
|
155 | | -**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心os: 难不成这家伙满口高并发,连最基础的东西都不会吧! |
| 153 | +**面试官:** 好了好了。项目就暂时问到这里吧!下面有一些比较基础的问题我简单地问一下你。内心 os: 难不成这家伙满口高并发,连最基础的东西都不会吧! |
156 | 154 |
|
157 | 155 | **我:** 好的好的!没问题! |
158 | 156 |
|
159 | | -**面试官:** 浏览器输入URL发生了什么? |
| 157 | +**面试官:** 浏览器输入 URL 发生了什么? |
160 | 158 |
|
161 | | -**我:**内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。 |
| 159 | +**我:** 内心 os:“很常问的一个问题,建议拿小本本记好了!另外,百度好像最喜欢问这个问题,去百度面试可要提前备好这道题的功课哦!相似问题:打开一个网页,整个过程会使用哪些协议?”。 |
162 | 160 |
|
163 | | -> 图解(图片来源:《图解HTTP》): |
| 161 | +> 图解(图片来源:《图解 HTTP》): |
164 | 162 | > |
165 | 163 | > <img src="https://my-blog-to-use.oss-cn-beijing.aliyuncs.com/2019-11/url输入到展示出来的过程.jpg" style="zoom:50%;" /> |
166 | 164 | > |
167 | 165 | > 总体来说分为以下几个过程: |
168 | 166 | > |
169 | | -> 1. DNS解析 |
170 | | -> 2. TCP连接 |
171 | | -> 3. 发送HTTP请求 |
172 | | -> 4. 服务器处理请求并返回HTTP报文 |
| 167 | +> 1. DNS 解析 |
| 168 | +> 2. TCP 连接 |
| 169 | +> 3. 发送 HTTP 请求 |
| 170 | +> 4. 服务器处理请求并返回 HTTP 报文 |
173 | 171 | > 5. 浏览器解析渲染页面 |
174 | 172 | > 6. 连接结束 |
175 | 173 | > |
176 | 174 | > 具体可以参考下面这篇文章: |
177 | 175 | > |
178 | | -> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700) |
| 176 | +> - [https://segmentfault.com/a/1190000006879700](https://segmentfault.com/a/1190000006879700 "https://segmentfault.com/a/1190000006879700") |
179 | 177 |
|
180 | | -**面试官:** TCP和UDP区别? |
| 178 | +**面试官:** TCP 和 UDP 区别? |
181 | 179 |
|
182 | 180 | **我:** |
183 | 181 |
|
184 | 182 | > 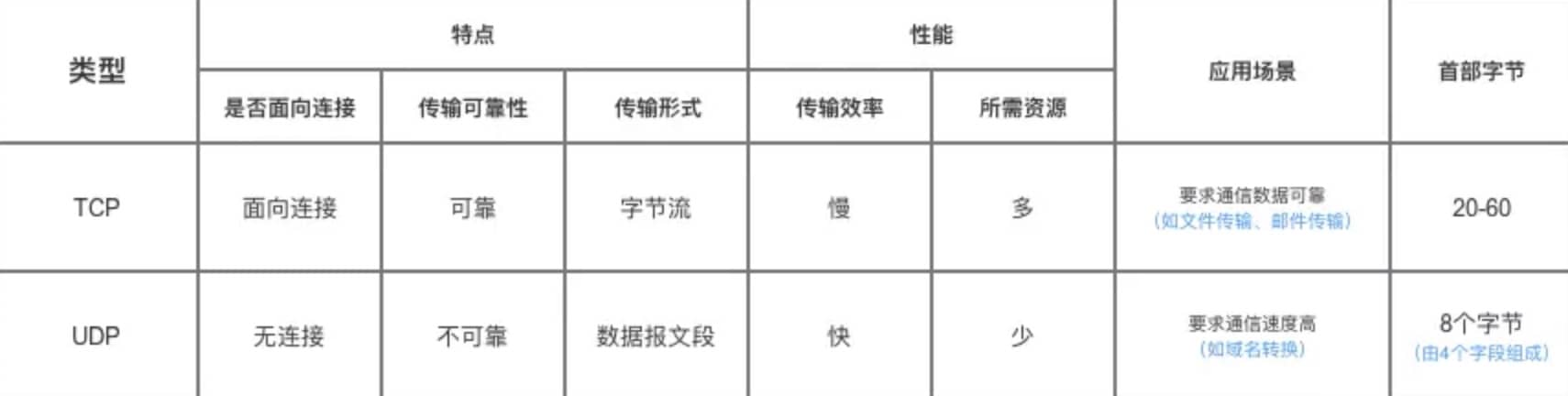 |
185 | 183 | > |
186 | 184 | > UDP 在传送数据之前不需要先建立连接,远地主机在收到 UDP 报文后,不需要给出任何确认。虽然 UDP 不提供可靠交付,但在某些情况下 UDP 确是一种最有效的工作方式(一般用于即时通信),比如: QQ 语音、 QQ 视频 、直播等等 |
187 | 185 | > |
188 | | -> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP的可靠体现在TCP在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。 |
| 186 | +> TCP 提供面向连接的服务。在传送数据之前必须先建立连接,数据传送结束后要释放连接。 TCP 不提供广播或多播服务。由于 TCP 要提供可靠的,面向连接的传输服务(TCP 的可靠体现在 TCP 在传递数据之前,会有三次握手来建立连接,而且在数据传递时,有确认、窗口、重传、拥塞控制机制,在数据传完后,还会断开连接用来节约系统资源),这一难以避免增加了许多开销,如确认,流量控制,计时器以及连接管理等。这不仅使协议数据单元的首部增大很多,还要占用许多处理机资源。TCP 一般用于文件传输、发送和接收邮件、远程登录等场景。 |
189 | 187 |
|
190 | | -**面试官:** TCP如何保证传输可靠性? |
| 188 | +**面试官:** TCP 如何保证传输可靠性? |
191 | 189 |
|
192 | 190 | **我:** |
193 | 191 |
|
194 | | -> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。 |
195 | | -> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。 |
196 | | -> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。 |
197 | | -> 4. TCP 的接收端会丢弃重复的数据。 |
198 | | -> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制) |
| 192 | +> 1. 应用数据被分割成 TCP 认为最适合发送的数据块。 |
| 193 | +> 2. TCP 给发送的每一个包进行编号,接收方对数据包进行排序,把有序数据传送给应用层。 |
| 194 | +> 3. **校验和:** TCP 将保持它首部和数据的检验和。这是一个端到端的检验和,目的是检测数据在传输过程中的任何变化。如果收到段的检验和有差错,TCP 将丢弃这个报文段和不确认收到此报文段。 |
| 195 | +> 4. TCP 的接收端会丢弃重复的数据。 |
| 196 | +> 5. **流量控制:** TCP 连接的每一方都有固定大小的缓冲空间,TCP 的接收端只允许发送端发送接收端缓冲区能接纳的数据。当接收方来不及处理发送方的数据,能提示发送方降低发送的速率,防止包丢失。TCP 使用的流量控制协议是可变大小的滑动窗口协议。 (TCP 利用滑动窗口实现流量控制) |
199 | 197 | > 6. **拥塞控制:** 当网络拥塞时,减少数据的发送。 |
200 | | -> 7. **ARQ协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。 |
201 | | -> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。 |
| 198 | +> 7. **ARQ 协议:** 也是为了实现可靠传输的,它的基本原理就是每发完一个分组就停止发送,等待对方确认。在收到确认后再发下一个分组。 |
| 199 | +> 8. **超时重传:** 当 TCP 发出一个段后,它启动一个定时器,等待目的端确认收到这个报文段。如果不能及时收到一个确认,将重发这个报文段。 |
| 200 | +
|
| 201 | +**面试官:** 我再来问你一些 Java 基础的问题吧!小伙子。 |
| 202 | + |
| 203 | +**我:** 好的。(内心 os:“你尽管来!”) |
| 204 | + |
| 205 | +**面试官:** 既然有了字节流,为什么还要有字符流? |
| 206 | + |
| 207 | +我:内心 os :“问题本质想问:**不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?**” |
| 208 | + |
| 209 | +> 字符流是由 Java 虚拟机将字节转换得到的,问题就出在这个过程还算是非常耗时,并且,如果我们不知道编码类型就很容易出现乱码问题。所以, I/O 流就干脆提供了一个直接操作字符的接口,方便我们平时对字符进行流操作。如果音频文件、图片等媒体文件用字节流比较好,如果涉及到字符的话使用字符流比较好。 |
| 210 | +
|
| 211 | +**面试官**:深拷贝 和 浅拷贝有啥区别呢? |
| 212 | + |
| 213 | +**我:** |
| 214 | + |
| 215 | +> 1. **浅拷贝**:对基本数据类型进行值传递,对引用数据类型进行引用传递般的拷贝,此为浅拷贝。 |
| 216 | +> 2. **深拷贝**:对基本数据类型进行值传递,对引用数据类型,创建一个新的对象,并复制其内容,此为深拷贝。 |
| 217 | +> |
| 218 | +> 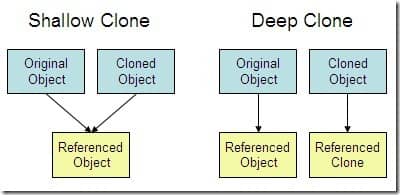 |
| 219 | +
|
| 220 | +**面试官:** 好的!面试结束。小伙子可以的!回家等通知吧! |
202 | 221 |
|
| 222 | +**我:** 好的好的!辛苦您了! |
0 commit comments