



目录
一. 为什么需要 Kubernetes
很多人会有疑问,有了 Docker 为什么还用 Kubernetes?
在业务开始进行容器化时,前期需要容器化的项目可能并不多,涉及的容器也并不多,此时基于Docker 容器直接部署至宿主机也能实现基本的需求。但是随着项目越来越多,管理的容器也会越来越多,此时使用“裸容器”部署的方式管理起来就显得很吃力,并且随着业务量的增加,会明显体会到“裸容器的不足。比如::
- 宿主机宕机造成该宿主机上的容器不可用,且无法自动恢复
- 容器明明在运行,接口就是不通(健康检查做得不到位)
- 应用程序部署、回滚、扩缩容困难
- 成百上千的容器和涉及的端口难以维护
上面的问题知识做一个简单的罗列,真正使用时还有很多其他的问题。大家也可能使用过Docker-compose、Docker-swarm 等编排工具,但是这些工具的功能和 Kubernetes 比起来还是相差很多的。所以注定 Kubernetes 编排工具将成为主流的容器编排工具
1. 对于开发人员
由于公司业务多,开发环境、测试环境、预生产环境和生产环境都是隔离的,而且除了生产环境,为了节省成本,其他环境可能没有进行日志收集。在没有用 Kubernetes 的时候,查看线下测试的日志,需要开发者或测试人员找到对应的机器,再找到对应的容器,才能査看对应的日志。在使用 Kubernetes 之后,开发人员和测试者直接在 Kubernetes 的 Dashboard 上找到对应的 namespace,即可定位到业务所在的容器,然后可以直接通过控制台查看到对应的日志,大大降低了操作时间
把应用部署到 Kubernetes 之后,代码的发布、回滚以及蓝绿发布、金丝雀发布等变得简单可控,不仅加快了业务代码的迭代速度,而且全程无须人工干预。生产环境可以使用 jenkins、git 等工具进行发版或回滚等。从开发环境到测试环境,完全遵守一次构建,多集群、多环境部署,通过不同的启动参数。不同的环境变量、不同的配置文件区分不同的环境
在使用服务网格后,开发人员在开发应用的过程中,无须去关心代码的网络部分,这些功能被服务网格实现,让开发人员可以只关心代码逻辑部分,即可轻松实现网络部分的功能,比如断流、分流、路由、负载均衡、限速和触发故障等功能
在测试过程中,可能同时存在多套环境,当然也会创建其他环境或临时环境,之前测试环境的创建需要找运维人员或者自行手工搭建。在迁移至 Kubernetes 集群后,开发人员如果需要新的环境,无须再找运维,只需要在 jenkins 上点点鼠标即可在 Kubernetes 集群上创建一套新的测试环境
2. 对于运维人员
对于运维人员,可能经常因为一些重复、烦琐的工作感到厌倦,比如一个项目需要一套新的测试环境。另一个项目需要迁移测试环境至其他平台。传统架构可能需要装系统、装依赖环境、部署域名、开通权限等,这一套下来,不仅耗时,而且可能会因为有某些遗漏而造成诸多问题。而如今,可以直接使用Kubernetes 包管理工具,一键式部署一套新的测试环境,甚至全程无须自己干预,开发人员通过 jenkins或者自动化运维平台即可一键式创建,大大降低了运维成本
在传统架构体系下,公司业务故障可能是因为基础环境不一致、依赖不一致、端口冲突等问题,而现在使用 docker 镜像部署,Kubernetes 进行编排,所有的依赖、基础都是一样的,并且环境的自动化扩容、健康检查、容灾、恢复都是自动的,大大减少了因为这类基础问题引发的故障。另外,也有可能公司业务由于服务器宕机、网络等问题造成服务不可用,此类情况均需要运维人员及时去修复,而在Kubernetes 中,可能在收到严重告警信息时,Kubernetes 已经自动恢复完成了
在没有使用 Kubernetes 时,业务应用的扩容和缩容需要人工去处理,从采购服务器、上架到部署依赖环境,不仅需要大量的人力物力,而且非常容易在中间过程出现问题,又要花大量的时间去查找问题。成功上架后,还需要在前端负载均衡添加该服务器,而如今,可以利用 Kubernetes 的弹性计算一键式扩容和缩容,不仅大大提高了运维效率,而且还节省了不少的服务器资源,提高了资源利用率
在反向代理配置方面,可能对nginx 的配置规则并不熟悉,一些高级的功能也很难实现,但是在Kubernetes 上,利用 Kubernetes 的 ingress 即可简单的实现那些复杂的逻辑,并且不会再遇到 nginx少加一个斜杠和多加一个斜杠的问题
在负载均衡方面,之前负载均衡可能是 nginx、LVS、Haproxy、F5 等,云上可能是云服务商提供的负载均衡机制。每次添加和删除节点时,都需要手动去配置前端负载均衡,手动去匹配后端节点。在使用Kubernetes 进行编排服务时,使用 Kubernetes 内部的 Service 即可实现自动管理节点,并且支持自动扩容、缩容
在高可用方面,Kubernetes 天生的高可用功能让运维人员彻底释放了双手,无需再去创建各类高可用工具,以及检测脚本。Kubernetes 支持进程、接口级别的健康检查,如果发现接口超时或者返回值不正确,会自动处理该问题
在中间件搭建方面,根据定义好的资源文件,可以实现秒级搭建各类中间件高可用集群,且支持一键式扩容、缩容,如 Redis、RabbitMQ、Zookeeper 等,并且大大减少了出错的概率
在应用端口方面,传统架构中,一台服务器可能跑了很多进程,每个进程都有一个端口,要认为的去配置端口,并且还需要考虑端口冲突的问题,如果有防火墙的话,还需要配置防火墙,在 Kubernetes 中,端口统一管理、统一配置,每个应用的端口都可以设置成一样的,之后通过 Service 进行负载均衡,大大降低了端口管理的复杂度和端口冲突
无论是对于开发人员、测试人员还是运维人员,Kubernetes 的诞生不仅减少了工作的复杂度,还减少了各种运维成本
二. Kubernetes 带来的挑战
Kubernetes 从诞生至今,一路突飞猛进,在容器编排的领域过关斩将,最终拿下了容器编排的冠军宝座,成为最无可替代、不可撼动的佼佼者,但是针对 Kubernetes 的学习和使用始终是一个很大的难题
首先,Kubernetes 本身的学习就很困难,因为Kubernetes 概念太多,涉及的知识面也非常广泛可能学习了一个月也无法入门,甚至连集群也搭建不出来,使人望而却步。并且Kubernetes 的技术能力要求也比较高,因为运维不仅仅均线于传统运维,有时候可能要修改业务代码、制定业务上线体系、给研发人员在开发应用中提供更好的建议等。需要掌握的知识也有很多,可能需要掌握公司内所有使用带的代码,比如代码如何进行编译、如何正确发布、如何修改代码配置文件等,这对于运维人员也是一种挑战。Kubernetes 的诞生把运维从传统的运维转变到了 Devps 方向,需要面临的问题更多,需要面临的新技术也很多,但是当真正掌握 Kubernetes 的核心和涉及理念,就会收益终身
三. Kubernetes 架构解析

由图可知,Kubernetes 架构可以简单分为主(master)节点,从(worker/node)节点和数据库 ETCD其中主节点为集群的控制单元,一般不会运行业务应用程序,主要包含的组件 Kube-APIServer.Kube-ControllerManager、Kube-Scheduler。从节点为工作节点,也就是部署应用程序容器的节点,主要包含的组件有 Kubelet、Kube-Proxy,当然如果 master 节点也要部署容器,也会包含这两个组件
同时,可以看出一个集群中可以有多个node 节点,用于保证集群容器的分布式部署,以保证业务的高可用性,也可以有很多的 master 节点,之后通过一个负载均衡保证集群控制节点的高可用。负载均衡可以使用软件负载均衡 Nginx、LVs、Haproxy+Keepalived 或者硬件负载均衡 F5 等,通过负载均衡对Kube-APIServer 提供的 VIP 即可实现 master 节点的高可用,其他组件通过该 VIP 连接至Kube-APIServer。ETCD 集群可以和 master 节点部署在同一个宿主机,也可以单独部署,生产环境建议部署大于3的奇数台 ETCD 节点用于实现 ETCD 集群的高可用。etcd 的 Leader 选举和数据写入都需要半数以上的成员投票通过确认,因此,集群最好由奇数个成员组成,以确保集群内部一定能够产生多数投票通过的场景。这也就是为什么 etcd 集群至少需要 3 个以上的成员
1. master 节点的组件
master 节点是 Kubernetes 集群的控制节点,在生产环境中不建议部署集群核心组件外的任何容器(在 kubeadm 安装方式下,系统组件以容器方式运行在 master 节点的宿主机上;二进制安装方式下,系统组件以守护进程的方式运行,master 节点可以不运行任何容器),公司业务程序的容器是不建议部署在 master 节点上,以免升级或者维护时对业务在成影响
(1)API server
API server 提供了集群网关,是整个集群的控制中枢,提供集群中各个模块之间的数据交换,并将集群信息存储到 ETCD 集群中。同时,它也是集群管理、资源配额、提供完备的集群安全机制的入口,为集群各类资源对象提供增删改査。API server 在客户端对集群进行访问, 客户端需要通过认证, 并使用 API server 作为访问节点和 pod (以及服务)的堡垒和代理/通道
- API 服务器公开 Kubernetes API
- REST/kubectl 的入口点–它是 Kubernetes 控制平面的前端
- 它跟踪所有集群组件的状态并管理它们之间的交互
- 它旨在水平扩展
- 它使用 YAML/JSON manifest 文件
- 它验证和处理通过 API 发出的请求
(2)scheduler
Scheduler 主要功能是资源调度,将 pod 调度到对应的主机上。依据请求资源的可用性、服务请求的质量等约束条件,K8s 也支持用户自己提供的调度器
- 它将 pod 调度到工作节点
- 它监视 api-server 以査找没有分配节点的新创建的 Pod,并选择一个健康的节点让它们运行
- 如果没有合适的节点,则Pod 将处于挂起状态,直到出现这样一个健康的节点。
- 它监视 API Server 的新工作任务
(3)Controller Manager
Controller Manager 负责维护集群的状态,比如故障检测、内存垃圾回收、滚动更新等,也执行API 业务逻辑;K8s 默认提供 replication controller、replicaset controller、daemonsetcontroller 等控制器
- 它监视它管理的对象的期望状态并通过 API 服务器监视它们的当前状态
- 采取纠正措施以确保当前状态与所需状态相同
- 它是控制器的控制器
- 它运行控制器进程。从逻辑上讲,每个控制器都是一个单独的进程,但为了降低复杂性,它们都被编译成一个二进制文件并在单个进程中运行
(4)etcd
etcd 用于可靠的存储集群的配置数据,是一种持久性、轻量型、分布式的键值数据存储组件。可以理解为一种分布式的非关系型数据库。etcd 是集群的状态, K8s 默认使用分布式的 etcd 集群整体存储用来实现发现服务和共享配置集群的所有状态都存储在 etcd 实例中,并具有监控的能力,因此当 etcd中的信息发生变化时,能够快速地通知集群中相关的组件
- 它是一个一致的、分布式的、高度可用的键值存储
- 它是有状态的持久存储,用于存储所有 Kubernetes 集群数据(集群状态和配置)
- 它是集群的真相来源
- 它可以是控制平面的一部分,也可以在外部进行配置
etcd 集群最少3个节点,容错点才会有1个。3个节点和4个节点的容错能力是一样的,所以有时候保持奇数节点更好,从这里可以判断出我们在部署k8s 的时候,至少有3个节点,才保证 etcd 有1个节点容错性
另外,etcd 的 Leader 选举和数据写入都需要半数以上的成员投票通过确认,因此,集群最好由奇数个成员组成,以确保集群内部一定能够产生多数投票通过的场景。所以 etcd 集群至少需要 3 个以上的奇数个成员
如果使用偶数个节点,可能出现以下问题:
- 偶数个节点集群不可用风险更高,表现在选主(Leader 选举)过程中,有较大概率的等额选票从而触发下一轮选举
- 偶数个节点集群在某些网络分割的场景下无法正常工作。当网络分割发生后,将集群节点对半分割开,形成脑裂
2. Node 节点包含的组件
Node 节点也被成为 worker 节点,是主要负责部署容器的主机,集群中的每个节点都必须具备容器的Runtime(运行时),比如docker
kubelet 作为守护进程运行在 Node 节点上,负责监听该节点上所有的 pod,同时负责上报该节点上所有 pod 的运行状态,确保节点上的所有容器都能正常运行。当 Node 节点宕机或故障时,该节点上运行的 pod 会被自动转移到其他节点上
(1)容器运行时
docker 引擎是本地的容器运行时环境,负责镜像管理以及 pod 和容器的真正运行。K8s 本身并不提供容器运行时环境,但提供了接口,可以插入所选择的容器运行时环境,目前支持 Docker 和 rkt。容器运行时是负责运行容器(在 Pod 中)的软件,为了运行容器,每个工作节点都有一个容器运行时引警,它从容器镜像注册表(container image registry)中提取镜像并启动和停止容器
Kubernetes 支持多种容器运行时:
- Docker
- containerd
- CRI-0
- Kubernetes CRI(Container Runtime Interface,容器运行时接口)的任何实现
(2)kubelet
kubelet 是 node 节点上最主要的工作代理,用于汇报节点状态并负责维护 pod 的生命周期,也负责volume(CVI)和网络(CNI)的管理。kubelet是 pod 和节点 API 的主要实现者,负责驱动容器执行层作为基本的执行单元,pod 可以拥有多个容器和存储卷,能够方便地在每个容器中打包一个单一的应用,从而解耦了应用构建时和部署时所关心的事项,方便在物理机或虚拟机之间进行迁移
- 它是在集群中的每个节点上运行的代理
- 它充当 API 服务器和节点之间的管道
- 它确保容器在 Pod 中运行并且它们是健康的
- 它实例化并执行 Pod
- 它监视 API Server 的工作任务
- 它从主节点那里得到指令并报告给主节点
(3)kube-proxy 代理
kube-proxy 代理对抽象的应用地址的访问,服务提供了一种访问一群 pod 的途径, kube-proxy 负责为服务提供集群内部的服务发现和应用的负载均衡(通常利用 iptables 规则),实现服务到 pod 的路由和转发。此方式通过创建一个虚拟的 IP 来实现,客户端能够访问此 IP,并能够将服务透明地代理至 pod
- 它是网络组件,在网络中起着至关重要的作用
- 它管理 IP 转换和路由
- 它是运行在集群中每个节点上的网络代理
- 它维护节点上的网络规则。这些网络规则允许从集群内部或外部与Pod进行网络通信
- 它确保每个 Pod 获得唯一的 IP 地址
- 这使得 pod 中的所有容器共享一个 IP 成为可能
- 它促进了 Kubernetes 网络服务和服务中所有 pod 的负载平衡
- 它处理单个主机子网并确保服务可供外部各方使用
3. kubernetes 网络组件
CNI(容器网络接口)是一个云原生计算基金会项目,它包含了一些规范和库,用于编写在 Linux容器中配置网络接口的一系列插件。CNI 只关注容器的网络连接,并在容器被删除时移除所分配的资源
Kubernetes 使用 CNI 作为网络提供商和 Kubernetes Pod 网络之间的接口

(1)Flannel 网络
由 Coreosk 开发的一个项目,很多部署工具或者 k8s 的发行版都是默认安装,flanne1 是可以用集群现有的 etcd,利用 api 方式存储自身状态信息,不需要专门的数据存储,是配置第三层的 ipv4 0verlay网络,在此网络内,每个节点一个子网,用于分配 ip 地址,配置 pod 时候,节点上的网桥接口会为每个新容器分配一个地址,同一主机中的 pod 可以使用网桥通信,不同主机的 pod 流量封装在 udp 数据包中,路由到目的地
Flannel 通过每个节点上启动一个 flnnel 的进程,负责给每一个节点上的子网划分、将子网网段等信息保存至 etcd,具体的报文转发是后端实现,在启动时可以通过配置文件指定不同的后端进行通信,目前有 UDP、VXLAN、host-gateway 三种,VXLAN 是官方推荐,因为性能良好,不需人工干预。UDP、VXLAN是基于三层网络即可实现,host-gateway 模式需要集群所有机器都在同一个广播域、就是需要在二层网络在同一个交换机下才能实现,host-gateway 用于对网络性能要求较高的常见,需要基础网络架构支持,UDP 用于测试或者不支持 VXLAN 的 linux 内核。反正一般小规模集群是完全够用的,直到很多功能无法提供时在考虑其他插件

(2)calico 网络
虽然 falnnel 很好,但是 calico 因为其性能、灵活性都好而备受欢迎,calico 的功能更加全面,不但具有提供主机和 pod 间网络通信的功能,还有网络安全和管理的功能,而且在 CNI 框架之内封装了calico 的功能,calico 还能与服务网络技术 Istio 集成,不但能够更加清楚的看到网络架构也能进行灵活的网络策略的配置,calico 不使用 overlay 网络,配置在第三层网络,**使用 BGP 路由协议**在主机之间路由数据包,意味着不需要包装额外的封装层。主要点在网络策略配置这一点,可以提高安全性和网络环境的控制
如果集群规模较大,选择 calico 没错,当然 calico 提供长期支持,对于一次配置长期使用的目的来说,是个很好的选择

四. 部署 Kubernetes
1. 基础配置
关闭防火墙和安全机制(三台主机都要执行)
[root@localhost ~]# systemctl stop firewalld
[root@localhost ~]# systemctl disable firewalld
[root@localhost ~]# setenforce 0
[root@localhost ~]# vim /etc/sysconfig/selinux
SELINUX=disabled
192.168.10.101
[root@localhost ~]# hostnamectl set-hostname k8s-master
[root@localhost ~]# bash
[root@k8s-master ~]# vim /etc/hosts
192.168.10.101 k8s-master
192.168.10.102 k8s-node01
192.168.10.103 k8s-node02
192.168.10.102
[root@localhost ~]# hostnamectl set-hostname k8s-node01
[root@localhost ~]# bash
[root@k8s-node01 ~]# vim /etc/hosts
192.168.10.101 k8s-master
192.168.10.102 k8s-node01
192.168.10.103 k8s-node02
192.168.10.103
[root@localhost ~]# hostnamectl set-hostname k8s-node02
[root@localhost ~]# bash
[root@k8s-node02 ~]# vim /etc/hosts
192.168.10.101 k8s-master
192.168.10.102 k8s-node01
192.168.10.103 k8s-node02
2. 关闭交换分区
操作节点:k8s-master,k8s-node01,k8s-node02
[root@k8s-master ~]# swapoff -a
[root@k8s-master ~]# vim /etc/fstab
#/dev/mapper/openeuler-swap none swap defaults 0 0


3. 配置 Kubernetes 的 YUM 源
操作节点:k8s-master,k8s-node01,k8s-node02
[root@k8s-master ~]# cat <<EOF > /etc/yum.repos.d/kubernetes.repo
> [kubernetes]
> name=Kubernetes
> baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
> enabled=1
> gpgcheck=1
> repo_gpgcheck=1
> gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
> EOF

4. 关闭校验
操作节点:k8s-master,k8s-node01,k8s-node02
[root@k8s-master yum.repos.d]# vim kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg

5. 所有节点安装 kubelet、kubeadm、kubectl
操作节点:k8s-master,k8s-node01,k8s-node02
[root@k8s-master ~]# dnf -y install kubelet-1.23.0 kubeadm-1.23.0 kubectl-1.23.0
[root@k8s-master ~]# systemctl start kubelet
[root@k8s-master ~]# systemctl enable kubelet
Created symlink /etc/systemd/system/multi-user.target.wants/kubelet.service → /usr/lib/systemd/system/kubelet.service.

6. 生成初始化配置文件并修改
操作节点:k8s-master
[root@k8s-master ~]# kubeadm config print init-defaults > init-config.yaml
[root@k8s-master ~]# vim init-config.yaml
apiVersion: kubeadm.k8s.io/v1beta3
bootstrapTokens:
- groups:
- system:bootstrappers:kubeadm:default-node-token
token: abcdef.0123456789abcdef
ttl: 24h0m0s
usages:
- signing
- authentication
kind: InitConfiguration
localAPIEndpoint:
advertiseAddress: 192.168.10.101
bindPort: 6443
nodeRegistration:
criSocket: /var/run/dockershim.sock
imagePullPolicy: IfNotPresent
name: k8s-master
taints: null
---
apiServer:
timeoutForControlPlane: 4m0s
apiVersion: kubeadm.k8s.io/v1beta3
certificatesDir: /etc/kubernetes/pki
clusterName: kubernetes
controllerManager: {}
dns: {}
etcd:
local:
dataDir: /var/lib/etcd
imageRepository: registry.aliyuncs.com/google_containers
kind: ClusterConfiguration
kubernetesVersion: 1.23.0
networking:
dnsDomain: cluster.local
serviceSubnet: 10.96.0.0/12
podSubnet: 10.244.0.0/16
scheduler: {}


注意:1.24.0 的版本中 apiVersion: kubeadm.k8s.io/v1beta2 被弃用
servicesubnet:指定使用 ipvs 网络进行通信,ipvs 称之为 IP 虛拟服务器(IP Virtual Server,简写为IPVS)。是运行在 LVS 下的提供负载平衡功能的一种技术。含义 IPVS 基本上是一种高效的 Layer-4交换机
podsubnet 10.244.0.0/16 参数需要和后文中 kube-flannel.yml 中的保持一致,否则,可能会使得 Node 间 Cluster Ip 不通
默认情况下,每个节点会从 Podsubnet 中注册一个掩码长度为 24 的子网,然后该节点的所有 podip 地址都会从该子网中分配
Kubeadm 配置在 Kubernetes 集群中存于 ConfigMap,可写入配置文件,通过 kubeadm config 命令操作配置文件

7. 导入镜像
操作节点:k8s-master,k8s-node01,k8s-node02


8. 初始化 k8s-master
操作节点:k8s-master
[root@k8s-master ~]# kubeadm init --config=init-config.yaml


9. node 节点加入集群
[root@k8s-node01 ~]# kubeadm join 192.168.10.101:6443 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:61d11d85ac3a63dd142ff5ecbe547e1ab02f02a470ac9b39c3920af788f5f9b5
> [root@k8s-node02 ~]# kubeadm join 192.168.10.101:6443 --token abcdef.0123456789abcdef \
> --discovery-token-ca-cert-hash sha256:61d11d85ac3a63dd142ff5ecbe547e1ab02f02a470ac9b39c3920af788f5f9b5


10. 设置变量
[root@k8s-master ~]# mkdir -p $HOME/.kube
[root@k8s-master ~]# sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
[root@k8s-master ~]# sudo chown $(id -u):$(id -g) $HOME/.kube/config
[root@k8s-master ~]# vim .bashrc
# .bashrc
# User specific aliases and functions
alias rm='rm -i'
alias cp='cp -i'
alias mv='mv -i'
alias ku='kubectl'
# Source global definitions
if [ -f /etc/bashrc ]; then
. /etc/bashrc
fi
[root@k8s-master ~]# vim .bash_profile
export KUBECONFIG=/etc/kubernetes/admin.conf
[root@k8s-master ~]# source .bashrc
[root@k8s-master ~]# source .bash_profile
[root@k8s-master ~]# ku get nodes
[root@k8s-master ~]# ku get pod -A





11. 安装网络插件
[root@k8s-master ~]# ku create -f calico.yaml

12. 查看各节点
[root@k8s-master ~]# ku get nodes
[root@k8s-master ~]# ku get pod --all-namespaces

五. Metrics Server 部署
Metrics Server 是一种可扩展、高效的容器资源指标来源,适用于 Kubernetes 内置的自动缩放管道。Metrics Server以 Kubelets 收集资源指标,并通过 Metics AP!将它们暴霞在 Kubernetes apiserver 中,供 Horizontal Pod Autoscaler 和Vertical Pod Autoscaler 使用。指标 AP|也可以通过访问 kubect top,从而更容易调试自动缩放管道
Metrics Server 对集群和网络配置有特定的要求,这些要求并不是所有集群分布的默认要求。在使用 Metics Server之前,请确保您的集群分布支持这些要求:
-
kube-apiserver 必须启用聚合层
-
节点必须启用 Webhook 身份验证和授权
-
Kubelet 证书需要由集群证书颁发机构签名(或通过传递 --kubelet -insecure-ts 给 Metrics Server 来禁用证书验少注意这里是重点,如果本地没有签名需要传递 args:“–kubelet-insecure-tls”给 Metrics Server
-
容器运行时必须实现容器指标 RPC(或具有 cAdvisor 支持)网络应支持以下通信:
控制平面到指标服务器。控制平面节点需要到达 Metrics Server 的 pod IP 和端口 10250(或节点IP 和自定义端口如果 hostNetwork 已启用)
1. 下载Metrics-server 的yaml 文件
https://github.com/kubernetes-sigs/metrics-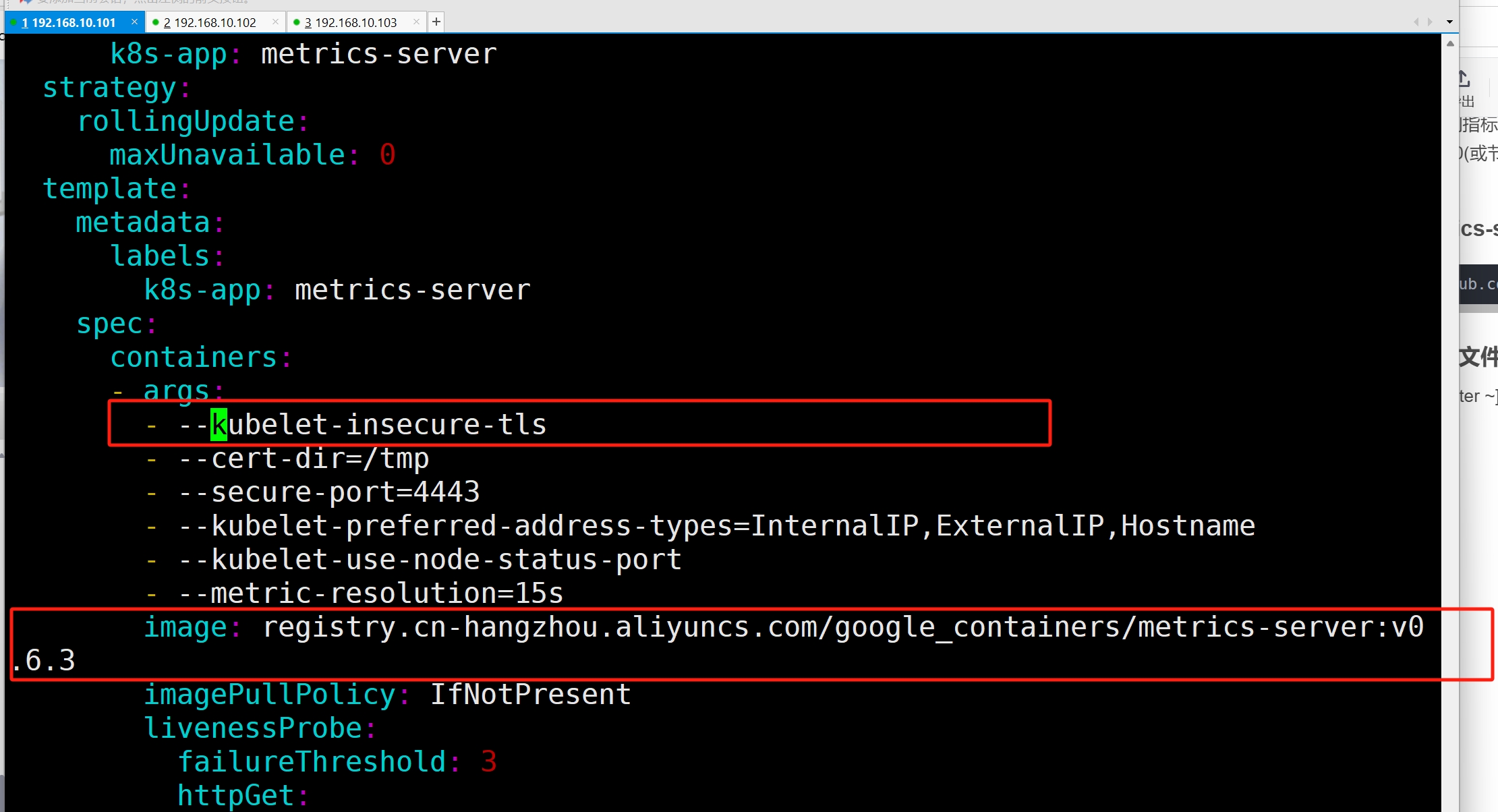
server/releases/download/v0.6.3/components.yaml
2. 修改yaml文件并安装
[root@k8s-master ~]# vim components.yaml
[root@k8s-master ~]# ku create -f components.yaml


3. 测试
[root@k8s-master ~]# ku top node

六. 部署helm客户端
1. 安装helm客户端
[root@k8s-master ~]# tar zxf helm-v3.9.4-linux-amd64.tar.gz
[root@k8s-master ~]# mv linux-amd64/helm /usr/local/bin/

2. 查看安装版本
[root@k8s-master ~]# helm version


















 2775
2775

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









