


1 Introduction
The issue of income and wealth inequality has long been a focal point in economic literature, drawing contributions from numerous esteemed scholars. In the early stages of economic inquiry, when the discipline focused mainly on resource allocation and societal welfare, theoretical and methodological tools were comparatively rudimentary, and data availability was limited. As a result, classical economists concentrated on the “functional distribution” of income, analyzing its allocation among wages, profits, and rents. In contrast, contemporary economists place greater emphasis on the “personal distribution” of income, which looks at how income is distributed among individuals, irrespective of their role in production.
David Ricardo’s “Principles” extensively explored the underlying laws governing income distribution. With the emergence of the marginalist and neoclassical revolutions, economic focus shifted towards the general equilibrium theory (GET), a framework still relevant today under the guise of DSGE (dynamic stochastic general equilibrium) methodology. However, this approach, rooted in the “representative agent” paradigm, tends to overlook income distribution dynamics. While income distribution and inequality have never been entirely sidelined, they have often taken a backseat to the pursuit of proving market equilibrium’s existence, uniqueness, and stability under idealized assumptions.
Notably, applied mathematicians and statisticians, many hailing from Italy, have shown significant interest in the realm of income distribution and inequality. Figures such as Max Otto Lorenz, Vilfredo Pareto, Gaetano Pietra, Umberto Ricci, Corrado Gini, and Giampaolo Zanardi have made substantial contributions to this field, highlighting the interdisciplinary nature of the study of economic disparities. These scholars, among others, will be acknowledged in this Element.
Various definitions exist for income or wealth inequality, yet they converge on the idea that unequal distribution signifies uneven access to opportunities among individuals. The root causes of this disparity can vary widely, spanning global, local, and individual factors.
In many countries, there is a growing acknowledgment of widening gaps in income and wealth distribution, indicating a concerning trend towards heightened inequality. This consensus is underscored by various studies and reports, highlighting the significance of this issue within both academic circles and among policymakers.
The issue of inequality in the distribution of income and wealth has recently taken center stage in political debates, sparking renewed interest among scholars. Key contributions to this discussion include works by Atkinson (Reference Atkinson2015), Atkinson & Piketty (Reference Atkinson and Piketty2007), Piketty (Reference Piketty2014), and Stiglitz (Reference Stiglitz2012, Reference Stiglitz2015).
For policymakers in particular, it is imperative to develop theories and models rooted in robust empirical evidence. Thus, there is a need to utilize precise methodologies to determine the most accurate parametric distributions of income and wealth, as well as to identify the most reliable estimators for measuring inequality.
Inequality is a phenomenon that fluctuates across time and space, with a persistent presence throughout history and likely into the future. It stems from various factors, including the behaviors of individuals holding a transferable quantity like income or wealth, as well as broader environmental conditions such as political, cultural, and economic contexts. The uneven distribution of these resources underscores the disparity in opportunities among individuals.
Some contend that inequality is an inevitable outcome, while others see it as fulfilling a social function by incentivizing advancement and progress. However, the crux of the matter lies in the detrimental effects of inequality, as it perpetuates cycles of poverty and deprivation. While complete eradication may prove elusive, effective control through redistributive or protective policies is essential. These policies should prioritize crucial aspects such as ensuring access to quality healthcare and education, particularly for disadvantaged groups, as these are vital for unlocking better job prospects and opportunities.
The management of inequality is critical for its mitigation. Achieving this goal necessitates the development and application of robust theoretical and methodological frameworks to comprehend and gauge its extent accurately.
For example, while economic growth is typically seen as positive news, its benefits are not always evenly distributed among individuals. In some rapidly growing economies, we have observed an exacerbation of inequality, as only a select few reap substantial rewards, particularly when considering both the financial and real sectors of the economy. Therefore, true economic growth should extend its benefits to all members of society, ideally favoring those who are most disadvantaged. Sustainable growth is characterized by a balanced distribution of wealth, steering clear of extreme social stratification and ensuring a high quality of life for the majority, if not all, citizens. However, achieving this requires a thorough understanding of inequality, underpinned by robust theoretical frameworks and analytical tools that can accurately measure its extent within the mechanisms of economies.
Over the years, numerous theoretical models and inequality estimators have been proposed and explored, making it impractical to list or review them all here. Each proposal has its strengths and weaknesses, contributing to the ongoing discourse without yielding a definitive solution. In this context, this Element presents the most effective and up-to-date solutions available for inferring both the parametric distribution of income and wealth, as well as the appropriate measures of inequality. Specifically, it introduces the κ-generalized distribution and the Zanardi index of asymmetry as prominent tools in this endeavor. These approaches offer valuable insights into understanding and addressing the complexities of economic inequality in contemporary society.
A quantity is deemed “positive” if all its values are nonnegative. Furthermore, a positive quantity is considered “transferable” if a portion held by one observation unit can be transferred to another without altering the total available quantity through interaction. This transferable quantity is termed “diffused” when the ensemble of  units possesses nonuniform shares of the total amount. Conversely, if each unit holds an identical share of
units possesses nonuniform shares of the total amount. Conversely, if each unit holds an identical share of  , the quantity is deemed “equi-distributed” among individuals.
, the quantity is deemed “equi-distributed” among individuals.
When the distribution disproportionately favors certain individuals or groups, it is categorized as “concentrated.” Thus, while all transferable quantities are inherently diffused, the degree and shape of the distribution can vary widely, ranging from equi-distribution with minimal concentration to maximum concentration, where one unit possesses nearly the entire quantity while the remaining  units possess negligible amounts.
units possess negligible amounts.
We can unambiguously refer to equi-distribution when each individual holds an equal fraction, representing the scenario with minimal concentration. However, the opposite extreme, characterized by maximum concentration, lacks a specific term. In essence, between these theoretical extremes, lies a spectrum of situations with varying degrees of concentration. While the term equi-distribution implies equality, other distribution scenarios inherently involve some degree of inequality. Although this terminology is intuitive, it may not capture the nuanced variations effectively.
Equality can be conceptualized as a state of distribution devoid of any disparities. Conversely, when a transfer mechanism operates within a heterogeneous population, interacting through a complex network of relationships, inequality emerges.Footnote 1 This inequality can either intensify over time as distributive imbalances exacerbate or diminish as such imbalances ease. Unlike the idealized state of equality, which represents homogeneity, inequality is a persistent condition characterized by varying degrees of heterogeneity.
The κ-generalized distribution, initially proposed by Kaniadakis (Reference Kaniadakis2001) in the field of nonlinear particle physics kinetics and further refined over the following two decades, has recently found application in economics, thanks to studies by, among others, Clementi, Di Matteo, Gallegati, and Kaniadakis (Reference Clementi, Di Matteo, Gallegati and Kaniadakis2008), Clementi and Gallegati (Reference Clementi and Gallegati2016), and Clementi, Gallegati, and Kaniadakis (Reference Clementi, Gallegati and Kaniadakis2007, Reference Clementi, Gallegati and Kaniadakis2009, Reference Clementi, Gallegati and Kaniadakis2010, Reference Clementi, Gallegati and Kaniadakis2012a, Reference Clementi, Gallegati and Kaniadakis2012b). These works demonstrate that this distribution offers a superior fit compared to well-known functional forms such as the Singh–Maddala, Dagum type I, and GB2 models.
The asymmetry index of the Lorenz curve, introduced by Zanardi (Reference Zanardi1964, Reference Zanardi1965), employs a geometric decomposition method popularized by Tarsitano (Reference Tarsitano1987, Reference Tarsitano1988). Recent research by Clementi, Gallegati, Gianmoena, Landini, and Stiglitz (Reference Clementi, Gallegati, Gianmoena, Landini and Stiglitz2019) and Gallegati, Landini, and Stiglitz (Reference Gallegati, Landini and Stiglitz2016) has shown that this index outperforms the traditional Gini concentration index in measuring inequality.
Both the κ-generalized distribution and the Zanardi index serve as essential analytical and theoretical tools for understanding and quantifying income and wealth distribution inequality. They are invaluable for academic research as well as applied studies aimed at informing policy-making efforts.
This Element is structured as follows.
In Section 2, we provide a brief overview of existing methods for analyzing income distribution, focusing primarily on the Lorenz curve and traditional inequality measures. We then introduce novel insights into inequality measurement by addressing the asymmetry inherent in this curve. Specifically, we introduce the Zanardi index of asymmetry as a superior measure of inequality. Unlike other measures, this index considers both the intensity and direction of inequality within the distribution, facilitating comparisons even when Lorenz curves intersect. Empirical space-time estimates and comparisons with other indices, notably the Gini index, which only addresses concentration, support the superiority of the Zanardi index.
Section 3 presents the κ-generalized distribution, offering comprehensive mathematical details regarding its origin, limit cases, definitions, and fundamental properties. It explores the parametric specification of the Lorenz curve and various indices associated with this distribution. Additionally, the methodology for parameter estimation is elucidated, along with insights gleaned from applying this model to real income distribution data.
Section 4 provides many up-to-date applications of the κ-generalized distribution to real-world income data, showing fitting results and comparing them with those obtained from other parametric models.
Section 5 concludes this Element with essential reflections. While acknowledging that no result can be deemed definitively absolute, akin to physics, some findings can be deemed sufficiently robust until proven otherwise, especially if they offer superior explanations for known phenomena. This Element aspires to contribute to such advancements, and we invite readers to engage in further improving the results presented herein.
2 New Insights on the Measurement of Inequality
2.1 The Inequality Measures
The growing attention to economic inequality has revived debates on the most suitable metric or index for measuring income inequality. Since the introduction of the Lorenz curve in Reference Lorenz1905, which shows the share of income or wealth accruing to the bottom  percent of the population, numerous indices have been proposed to assess economic inequality.
percent of the population, numerous indices have been proposed to assess economic inequality.
The Gini (Reference Gini1914) coefficient stands as the predominant and extensively employed measure of income inequality. This metric measures inequality by calculating the area between the Lorenz curve, representing income distribution, and the line of perfect equality.
Based on the Lorenz curve, the literature on inequality has introduced alternative metrics, including the Pietra–Ricci index (Pietra, Reference Pietra1915; Ricci, Reference Ricci1916) and the Zanardi index (Zanardi, Reference Zanardi1964, Reference Zanardi1965), which provide new insights into income inequality. The Pietra–Ricci focuses on the redistribution needed to achieve equality, while the Zanardi index explores the asymmetry on the income distribution.Footnote 2
Other indices, like the Theil index, are grounded in information theory (Shorrocks, Reference Shorrocks1980; Theil, Reference Theil1967), while some, like the Atkinson (Reference Atkinson1970) index, are welfare-based measures of inequality and are more responsive to value judgments regarding inequality aversion. Though these indices offer valuable insights into the complex nature of inequality, each comes with its strengths and limitations. The choice of an index depends on the specific aspect of inequality under consideration and the societal values deemed most important.
In particular, indices that satisfy the three axiomatic conditions of (i) symmetry, (ii) scale invariance, and the (iii) transfer principle produce identical rankings for distinct income distributions only if the Lorenz curves do not intersect.Footnote 3 Likewise, rankings based on the Atkinson index remain consistent regardless of the level of risk aversion, only if the Lorenz curves do not intersect. If the Lorenz curves intersect, then different indices can yield different results depending on the type of inequality to which each index is most sensitive.
With the aim of discerning the nature of inequality, the Zanardi index distinguishes itself from the aforementioned indices by its capability to gauge the asymmetry of Lorenz curves. Unlike the previous measures, the Zanardi index delves into the shape of the distribution, aiding in the identification of whether inequality predominantly stems from the conditions of the poor or from the concentration of wealth among the richest.
2.2 Exploring the Lorenz Curve and the Gini Index Logic
It is well known that the most popular tool used to represent income distribution is the Lorenz curve  , whose upward and convex trend is strongly affected by how income is concentrated/distributed among individuals. The
, whose upward and convex trend is strongly affected by how income is concentrated/distributed among individuals. The  , whose formalization is discussed in Section 3.2.2, tells us which proportion of the total income is in the hands of a given percentage of population. If income is distributed homogeneously among individuals, the Lorenz curve coincides with the main diagonal of a unit square, showing an absence of income concentration.
, whose formalization is discussed in Section 3.2.2, tells us which proportion of the total income is in the hands of a given percentage of population. If income is distributed homogeneously among individuals, the Lorenz curve coincides with the main diagonal of a unit square, showing an absence of income concentration.
However, real-world income distribution is characterized by disparities between poor and rich people. This implies that less affluent individuals hold a share of total income below an equi-distributed allocation, while wealthier individuals hold more. Consequently, for typical income distributions, the Lorenz curve deviates from the diagonal, assuming the shape of a convex curve.
Closely tied to the representation of the Lorenz curve  , the Italian statistician Corrado Gini, in 1914, introduced a synthetic measure known as the Gini coefficient. This coefficient quantifies the ratio of the area between the Lorenz Curve and the equi-distribution line (hereinafter referred to as the concentration area) to the area of maximum concentration. It is crucial to emphasize that the Gini index specifically conveys information about the concentration of transferable quantities. However, it falls short in capturing other critical dimensions of inequality, such as the extent of heterogeneity, concentration, and asymmetry inherent in income distribution (Clementi et al., Reference Clementi, Gallegati, Gianmoena, Landini and Stiglitz2019; Gallegati et al., Reference Gallegati, Landini and Stiglitz2016).
, the Italian statistician Corrado Gini, in 1914, introduced a synthetic measure known as the Gini coefficient. This coefficient quantifies the ratio of the area between the Lorenz Curve and the equi-distribution line (hereinafter referred to as the concentration area) to the area of maximum concentration. It is crucial to emphasize that the Gini index specifically conveys information about the concentration of transferable quantities. However, it falls short in capturing other critical dimensions of inequality, such as the extent of heterogeneity, concentration, and asymmetry inherent in income distribution (Clementi et al., Reference Clementi, Gallegati, Gianmoena, Landini and Stiglitz2019; Gallegati et al., Reference Gallegati, Landini and Stiglitz2016).
The concept of heterogeneity underscores the presence of a nonuniform distribution of economic resources among different socioeconomic groups (poor and rich), with implications for understanding the dynamics of income inequality within a society; the concentration means considering different degrees of disparity between the classes, while the concept of asymmetry refers to the directional disparity in the distribution of endowments.
In particular, asymmetry implies that the distribution reveals a certain direction of the income imbalance which could be “right-wards” if the rich class of the distribution is more heterogeneous than the poor one, or “left-wards” in the opposite scenario.Footnote 4 These three concepts – concentration, heterogeneity, and asymmetry – are crucial for a thorough understanding of inequality. Consequently, it is necessary to consider alternative measures that can examine for the shape of Lorenz curves.
2.3 The Zanardi Asymmetry Index of the Lorenz Curve
In what follows, we provide a description and an interpretation of the Zanardi (Reference Zanardi1964, Reference Zanardi1965) index, which can be considered as a superior measure for examining income inequality, particularly in the presence of asymmetric income distributions. As highlighted by Clementi et al. (Reference Clementi, Gallegati, Gianmoena, Landini and Stiglitz2019), Gallegati et al. (Reference Gallegati, Landini and Stiglitz2016) and Park, Kim, and Ju (Reference Park, Kim and Ju2021) inequality is characterized not only by its “intensity” but also by its “direction.” In this framework, the “direction” of the inequality is discussed in terms of a positive and transferable quantity, such as income, which is unevenly distributed among recipients. This uneven distribution implies a form of “right-wing” or “left-wing” inequality concentration, highlighting the asymmetry of the Lorenz curve  .
.
Graphically, this situation is illustrated in Figure 2.1(a). Consider two intersecting Lorenz curves: one with a “bulge” in the lower-income segment (solid line) and the other with a “bulge” in the wealthier segment (dashed line); in this case, even though the areas enclosed by the two Lorenz curves and the diagonal of the unit square are the same, the income share ( th) of the poorest fraction (
th) of the poorest fraction ( th) of the population is lower in the first distribution than in the second, although the income concentration is exactly equal.
th) of the population is lower in the first distribution than in the second, although the income concentration is exactly equal.
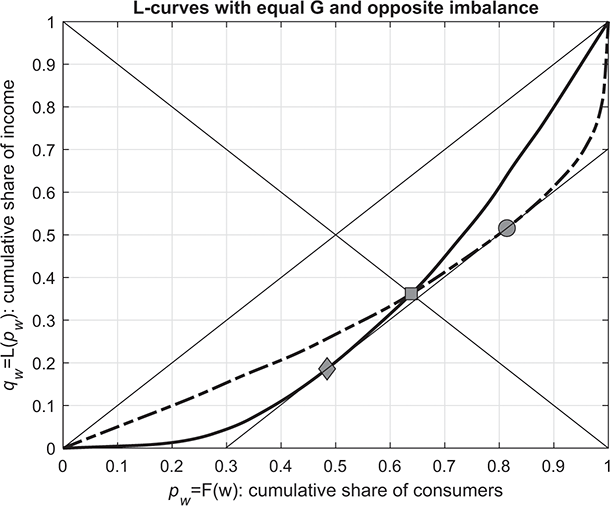
(a) Two Lorenz curves with the same Gini index and opposite asymmetry
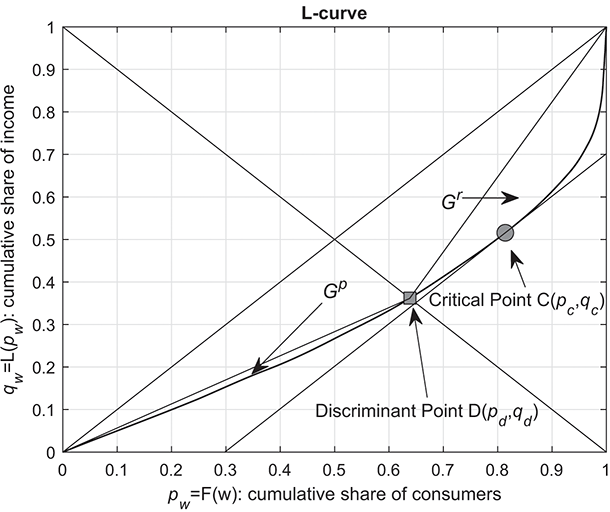
(b) the characteristic point, discriminant point, and critical point of the Lorenz curve
Figure 2.1 Note: See also Clementi et al. (Reference Clementi, Gallegati, Gianmoena, Landini and Stiglitz2019).
Figure 2.1(a) shows two contrasting scenarios: one where the rich are very rich and get a high share of the total income, represented by the dashed curve, and another where the poor are very poor and get a very small share of the income, depicted by the solid curve.
In this framework, the discussion of the asymmetry of the  will be in terms of the discriminant point
will be in terms of the discriminant point  , which separates the poor class from the rich one, given by the intersection of the Lorenz curve with the negative bisector
, which separates the poor class from the rich one, given by the intersection of the Lorenz curve with the negative bisector  , that is, the “axis of symmetry.” Thus, the share of poor income earners within the population is given by
, that is, the “axis of symmetry.” Thus, the share of poor income earners within the population is given by  and accumulates a share
and accumulates a share  of total income, which is larger than the income share
of total income, which is larger than the income share  accumulated by the
accumulated by the  rich. The discriminant point
rich. The discriminant point  plays a relevant role, since it separates the total area under the Lorenz curve in two sub-areas from which the Gini indexes for the poor and the rich (
plays a relevant role, since it separates the total area under the Lorenz curve in two sub-areas from which the Gini indexes for the poor and the rich ( and
and  , respectively) can be estimated (see Figure 2.1(b)).
, respectively) can be estimated (see Figure 2.1(b)).
Based on the discriminant point  , the Zanardi (Reference Zanardi1964, Reference Zanardi1965) index can be defined as
, the Zanardi (Reference Zanardi1964, Reference Zanardi1965) index can be defined as
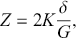 (2.1)
(2.1)
where  ,
,  denotes the disparity of concentration between the rich and poor, and
denotes the disparity of concentration between the rich and poor, and  is the overall Gini ratio. The index varies between −1 and 1, where
is the overall Gini ratio. The index varies between −1 and 1, where  means that the Lorenz curve is negatively asymmetric (or asymmetric to the left), while for
means that the Lorenz curve is negatively asymmetric (or asymmetric to the left), while for  the curve is positively asymmetric (or asymmetric to the right).
the curve is positively asymmetric (or asymmetric to the right).
Therefore, if  then
then  : the poor side is less concentrated than the rich one, or similarly the rich are more heterogeneous and concentrated than the poor, hence the distribution disadvantages the poor as they are more within-homogeneously poor than the rich side. In this case we face distributional imbalance toward the top (top-inequality), as described by the dashed curve in Figure 2.1(a). If
: the poor side is less concentrated than the rich one, or similarly the rich are more heterogeneous and concentrated than the poor, hence the distribution disadvantages the poor as they are more within-homogeneously poor than the rich side. In this case we face distributional imbalance toward the top (top-inequality), as described by the dashed curve in Figure 2.1(a). If  then
then  and the opposite interpretation holds: the poor exhibit greater heterogeneity and concentration compared to the rich, suggesting an imbalance distribution toward the bottom (bottom-inequality) – in other words, there are more ways of being poor than rich. This corresponds to the solid curve in Figure 2.1(a). Obviously,
and the opposite interpretation holds: the poor exhibit greater heterogeneity and concentration compared to the rich, suggesting an imbalance distribution toward the bottom (bottom-inequality) – in other words, there are more ways of being poor than rich. This corresponds to the solid curve in Figure 2.1(a). Obviously,  if the Lorenz curve is symmetric and no distributional imbalances are found, therefore inequality can be analyzed looking at the overall Gini index.
if the Lorenz curve is symmetric and no distributional imbalances are found, therefore inequality can be analyzed looking at the overall Gini index.
In this scenario, the Zanardi index may provide more insightful information than the Gini index, especially for distributions that exhibit the same  (i.e. the same level of concentration of
(i.e. the same level of concentration of  ) but differ in the sign of
) but differ in the sign of  (i.e.
(i.e.  , indicating “right-wing” skewness of
, indicating “right-wing” skewness of  , or
, or  , indicating “left-wing” skewness of
, indicating “left-wing” skewness of  ).
).
2.4 Empirical Insights on Inequality
This section briefly presents some empirical evidence on inequality measures estimated using the Luxembourg Income Study (LIS) Database. The LIS Database provides public access to granular household-level income data for 52 countries, including both developed and developing nations over a period spanning 1963 to 2022.Footnote 5 Using a harmonized and equivalized dataset,Footnote 6 we explore the dynamics of disposable household income across 822 distributions.Footnote 7
Figure 2.2 shows the relationship between the concentration index  and the entropy inequality indexes: mean logarithmic deviation (MLD), Theil, and Atkinson (with inequality aversion parameter equal to 1).Footnote 8 Although each index provides a distinct viewpoint on inequality, it is possible to observe that higher levels of concentration are associated with higher levels of distributive imbalances. For lower levels of concentration, all the indices are almost equivalent in classifying distributions, but for higher levels of concentration, the indices diverge while maintaining the same order. This pattern confirms a strong relationship between concentration and inequality, however, it does not offer insights into the specific nature or direction of the inequality.
and the entropy inequality indexes: mean logarithmic deviation (MLD), Theil, and Atkinson (with inequality aversion parameter equal to 1).Footnote 8 Although each index provides a distinct viewpoint on inequality, it is possible to observe that higher levels of concentration are associated with higher levels of distributive imbalances. For lower levels of concentration, all the indices are almost equivalent in classifying distributions, but for higher levels of concentration, the indices diverge while maintaining the same order. This pattern confirms a strong relationship between concentration and inequality, however, it does not offer insights into the specific nature or direction of the inequality.
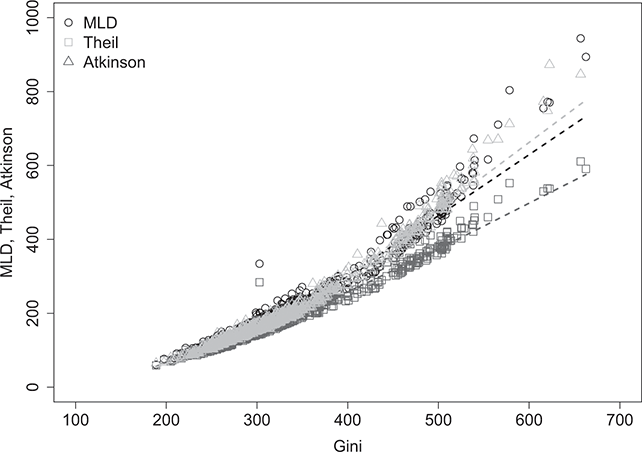
Figure 2.2 Relationship between concentration and entropy indexes of inequality ( )
)
Figure 2.3 illustrates the relationship between the general concentration index  and the concentration levels on the rich (
and the concentration levels on the rich ( ) and poor (
) and poor ( ) side. The graph unveils a distributional imbalance stemming from varying concentration levels between the two segments of the distribution – that is, the rich and poor segments – indicating a directional aspect of inequality not fully captured by the Gini index. Furthermore, it appears that the Gini index makes little distinction between sampling from the rich or the poor sides of the distribution. The estimates provided in Figure 2.3 show that a 1% increase in concentration on the rich side increases the overall concentration by approximately 0.64%, while a similar increase on the poor side results in an approximately 0.74% boost in overall concentration. This preliminary analysis underscores that inequity is slightly driven by a higher concentration on the poor side rather than the rich side. The presence of such asymmetry enables a deeper understanding of the inequality directionality, particularly in this scenario where it is driven by the disadvantaged group. Consequently, exploring the concentration gap between the rich and the poor through the Zanardi index could offer valuable insights.
) side. The graph unveils a distributional imbalance stemming from varying concentration levels between the two segments of the distribution – that is, the rich and poor segments – indicating a directional aspect of inequality not fully captured by the Gini index. Furthermore, it appears that the Gini index makes little distinction between sampling from the rich or the poor sides of the distribution. The estimates provided in Figure 2.3 show that a 1% increase in concentration on the rich side increases the overall concentration by approximately 0.64%, while a similar increase on the poor side results in an approximately 0.74% boost in overall concentration. This preliminary analysis underscores that inequity is slightly driven by a higher concentration on the poor side rather than the rich side. The presence of such asymmetry enables a deeper understanding of the inequality directionality, particularly in this scenario where it is driven by the disadvantaged group. Consequently, exploring the concentration gap between the rich and the poor through the Zanardi index could offer valuable insights.
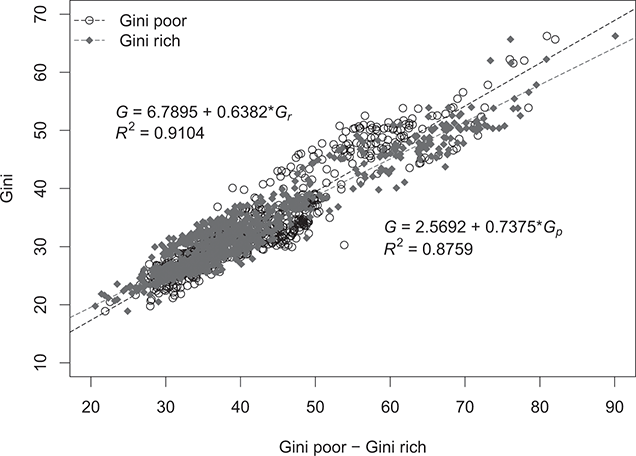
Figure 2.3 Overall Gini index,  , together with the concentration on the rich,
, together with the concentration on the rich,  , and the poor,
, and the poor,  , sides (
, sides ( )
)
For this purpose, Figure 2.4 shows the Gini concentration index (horizontal axis) and the Zanardi asymmetry index (vertical axis), both estimated on the Lorenz curves for all distributions. Gray-triangular values denote cases of equivalent Gini paired with opposite Zanardi, indicating distributions with similar concentration but opposite asymmetry. For such observations, an analysis based solely on the Gini index would be misleading because, behind the same concentration value, different forms of inequality may be hidden, that is, top-inequality cases (above the horizontal axis) and bottom-inequality cases (below the horizontal axis).
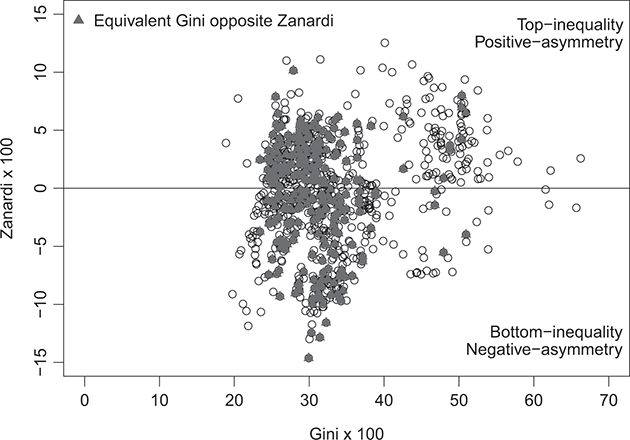
Figure 2.4 Overall Gini index,  , together with the Zanardi index,
, together with the Zanardi index, 
At this point in the analysis, we can draw some preliminary conclusions:
1. The income distributions for the entire sample turn out to be very heterogeneous in terms of income concentration (Gini values ranging from a maximum of 0.6626 to a minimum of 0.1887).
2. Such distributions exhibit significant inequality or asymmetry in both the rich and poor segments, as described by the Zanardi index (with values ranging from a maximum of 0.1253 to a minimum of −0.1932).
In order to eliminate these distributional gaps, wealth transfers should be implemented to nullify both concentration ( ) and inequality (
) and inequality ( ). The Pietra–Ricci index (
). The Pietra–Ricci index ( ) takes this aspect into account.
) takes this aspect into account.
With reference to Figure 2.1(b), the Pietra–Ricci index measures the maximum distance of the Lorenz curve  from the equi-concentration segment, that is, the vertical distance of the critical point from the line of perfect equality. Starting with an income distribution characterized by
from the equi-concentration segment, that is, the vertical distance of the critical point from the line of perfect equality. Starting with an income distribution characterized by  and
and  , it is possible to calculate the amount of income to transfer from a group (whether rich or poor) to achieve a distribution in which
, it is possible to calculate the amount of income to transfer from a group (whether rich or poor) to achieve a distribution in which  and
and  , indicating the absence of inequality. As shown in Figure 2.5(a), as concentration levels increase, it will be necessary to transfer larger amounts of income to eliminate inequality. Thus, with reference to Figure 2.5(b), for values of
, indicating the absence of inequality. As shown in Figure 2.5(a), as concentration levels increase, it will be necessary to transfer larger amounts of income to eliminate inequality. Thus, with reference to Figure 2.5(b), for values of  , it will be necessary to transfer a portion
, it will be necessary to transfer a portion  of the total income from the poor class to the rich class to completely eliminate concentration and inequality – akin to a “Matthew” effect. In the case of
of the total income from the poor class to the rich class to completely eliminate concentration and inequality – akin to a “Matthew” effect. In the case of  , on the other hand, the opposite will be necessary: transferring a portion of the total income from the rich class to the poor class – a kind of “Robin Hood” effect.
, on the other hand, the opposite will be necessary: transferring a portion of the total income from the rich class to the poor class – a kind of “Robin Hood” effect.
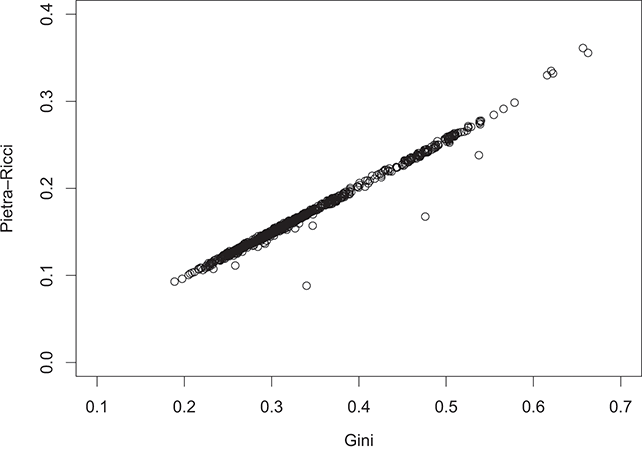
(a) Overall Gini index against the Pietra–Ricci index
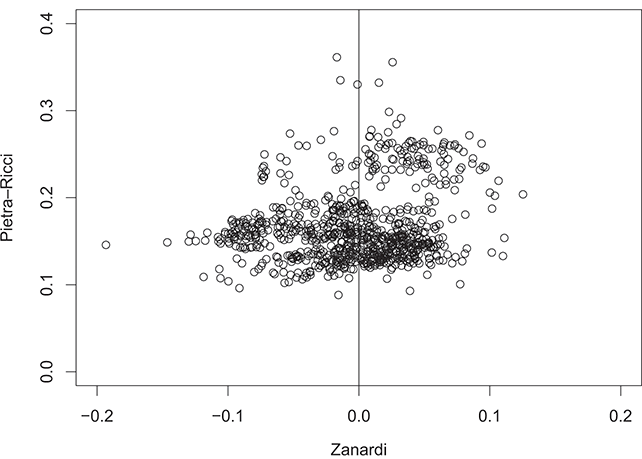
(b) the Zanardi index against the Pietra–Ricci
2.4.1 Examining the Inequality over Time
The analysis of inequality presented so far, while informative, is quite general and does not fully allow for an understanding of the time evolution of inequality. Furthermore, a misleading understanding of the concept of inequality becomes evident when solely focusing on the overall Gini index. A country-specific analysis provides a deeper understanding of the various forms of inequality within an economy, highlighting trends and potential divergences between the Gini and Zanardi indices.
With this purpose, Figures 2.6–2.9 show the time series of the Gini and Zanardi indices for a subset of countries with the highest number of consecutive years of data within the time period from 1990 to 2021. For the sake of exposition, we classify these economies into four groups: Anglo-Saxon countries (Canada, the United Kingdom, and the United States); Western European countries (France and Germany); Southern European countries (Italy and Spain); and Northern European countries (Denmark, Norway, and Sweden).
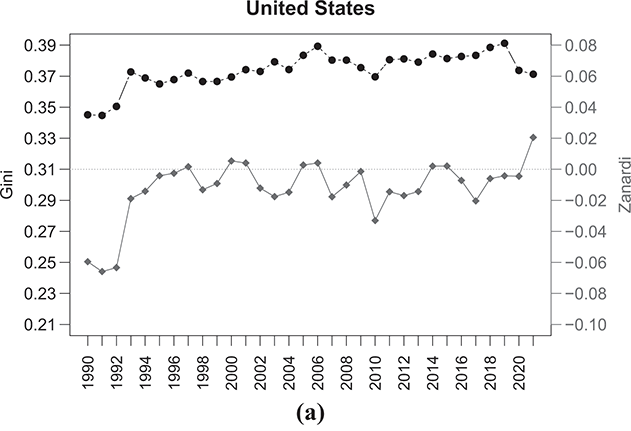
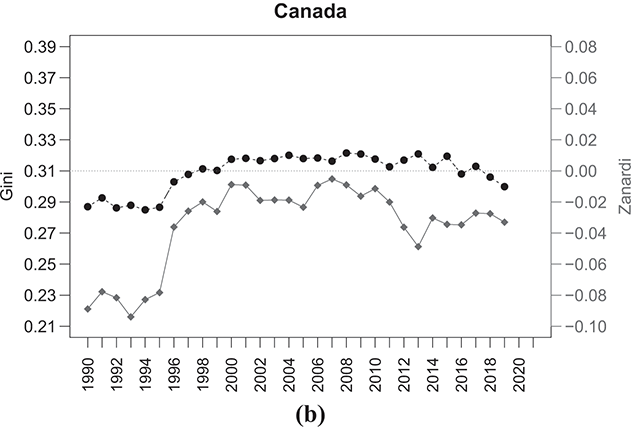
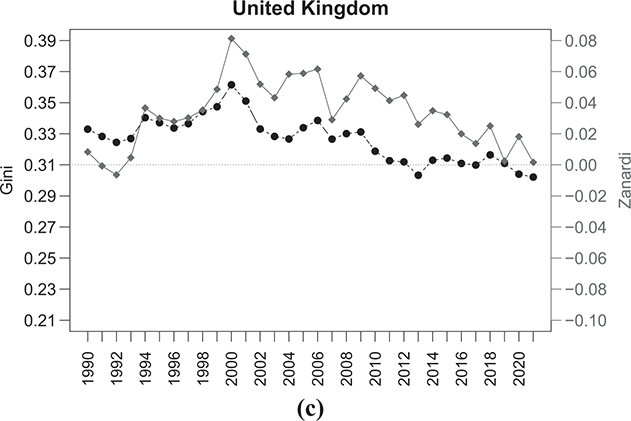
Figure 2.6 Temporal evolution of the Gini (bullets, left scale) and Zanardi (squares, right scale), Anglo-Saxon countries
Note: The horizontal line represents the zero reference line for the Zanardi index.
The United States (Figure 2.6(a)) shows an almost constant increase in the  concentration index throughout the period considered, with the exception of the last few years, where there is a marked decrease in the
concentration index throughout the period considered, with the exception of the last few years, where there is a marked decrease in the  index from values close to 0.39 to values close to 0.37. However, concerning the type of the inequality, there is a cyclical fluctuation between negative values of the
index from values close to 0.39 to values close to 0.37. However, concerning the type of the inequality, there is a cyclical fluctuation between negative values of the  index and values close to zero for almost the entire period. This increased inequality on the poor side, as indicated by negative
index and values close to zero for almost the entire period. This increased inequality on the poor side, as indicated by negative  values, is attributed to greater heterogeneity within the lower-income group, where individuals experience higher levels of poverty. These disparities on the side of the poor are mitigated in three time periods: 2000–2001, 2005–2006, and 2014–2015, during which the Zanardi index approaches zero, indicating a reduction in income distribution asymmetry, albeit with persistently high-income concentration values as indicated by the Gini index. In 2020–2021, however, the distribution undergoes a shift, as indicated by the positive
values, is attributed to greater heterogeneity within the lower-income group, where individuals experience higher levels of poverty. These disparities on the side of the poor are mitigated in three time periods: 2000–2001, 2005–2006, and 2014–2015, during which the Zanardi index approaches zero, indicating a reduction in income distribution asymmetry, albeit with persistently high-income concentration values as indicated by the Gini index. In 2020–2021, however, the distribution undergoes a shift, as indicated by the positive  values associated with an increase of inequality, this time in favor of the rich-side. The income distribution shows an increase in heterogeneity within the richer class, with the emergence of a segment of wealthy individuals holding significant shares of income within the richer class (i.e. the super-rich).
values associated with an increase of inequality, this time in favor of the rich-side. The income distribution shows an increase in heterogeneity within the richer class, with the emergence of a segment of wealthy individuals holding significant shares of income within the richer class (i.e. the super-rich).
A similar trend, albeit with lower values, is observed for Canada (Figure 2.6(b)). The concentration levels of  increase throughout the first decade, stabilizing at values around 0.32 in the following ten years, and then fluctuating with a tendency to decrease in the last period. Although the Gini index shows an almost constant trend, the
increase throughout the first decade, stabilizing at values around 0.32 in the following ten years, and then fluctuating with a tendency to decrease in the last period. Although the Gini index shows an almost constant trend, the  index values move further away from the symmetry line, especially in the last ten years, with a significant increase in concentration (hence heterogeneity) among the poor (bottom-inequality).
index values move further away from the symmetry line, especially in the last ten years, with a significant increase in concentration (hence heterogeneity) among the poor (bottom-inequality).
The case of the United Kingdom in Figure 2.6(c) differs and is, in some respects, the opposite of the United States and Canada, showing a downward trend in both the  and
and  indices. The Zanardi index shows how, in the United Kingdom, the distributive imbalance has always favored the richer, with a tendency towards values close to zero only in recent years. We are therefore seeing a general reduction in concentration and inequality, particularly within the wealthy class, indicating a shift from a top-inequality profile to a bottom-inequality one.
indices. The Zanardi index shows how, in the United Kingdom, the distributive imbalance has always favored the richer, with a tendency towards values close to zero only in recent years. We are therefore seeing a general reduction in concentration and inequality, particularly within the wealthy class, indicating a shift from a top-inequality profile to a bottom-inequality one.
Countries in Western Europe, like France and Germany, generally have lower levels of income concentration (Figure 2.7). France’s Gini index shows a relatively stable trend over time, while Germany’s Gini index depicts a rising trend. Both countries exhibit positive imbalances in income distribution, as reflected by consistently positive values of  . Consequently, a significant portion of total income in these economies is unequally distributed, with a larger proportion going to the rich while a smaller proportion is shared among the poor.
. Consequently, a significant portion of total income in these economies is unequally distributed, with a larger proportion going to the rich while a smaller proportion is shared among the poor.
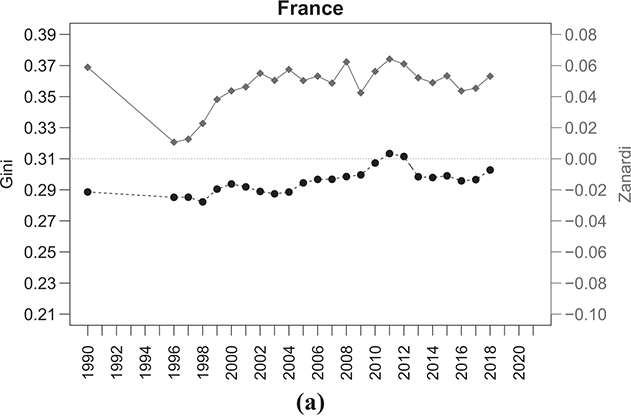
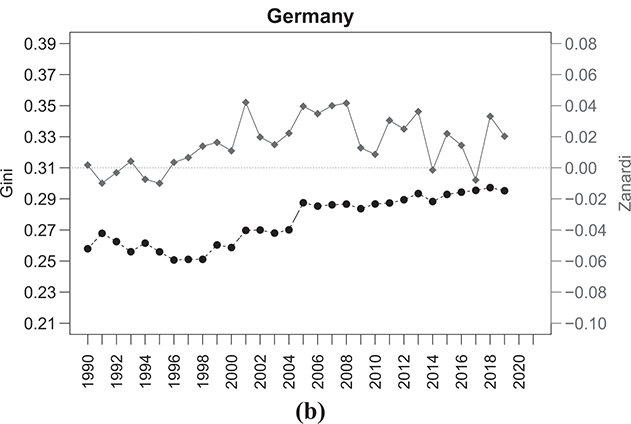
Figure 2.7 Temporal evolution of the Gini (bullets, left scale) and Zanardi (squares, right scale), Western European countries
Note: The horizontal line represents the zero reference line for the Zanardi index.
The situation in Southern European countries, specifically Italy and Spain, presents another interesting pattern (Figure 2.8). The Gini index shows relatively stable values over the years, around 0.33–0.35 for both countries. Conversely, the Zanardi index consistently falls below the symmetry line for both economies, indicating strongly negative  values. The two countries have seen a notable rise in bottom-inequality, leading to increased poverty among individuals. While the trend in Spain does not seem to be improving, Italy has experienced a significant decline in bottom-inequality, reflected in progressively less negative
values. The two countries have seen a notable rise in bottom-inequality, leading to increased poverty among individuals. While the trend in Spain does not seem to be improving, Italy has experienced a significant decline in bottom-inequality, reflected in progressively less negative  values, at least until the first half of the 2000s, before reverting to worsening. Once more, this particular case highlights the limit of the Gini index in accurately capturing inequality. The similar and constant concentration values might erroneously imply a similarity between the two economies, which is not what real data tell us.
values, at least until the first half of the 2000s, before reverting to worsening. Once more, this particular case highlights the limit of the Gini index in accurately capturing inequality. The similar and constant concentration values might erroneously imply a similarity between the two economies, which is not what real data tell us.
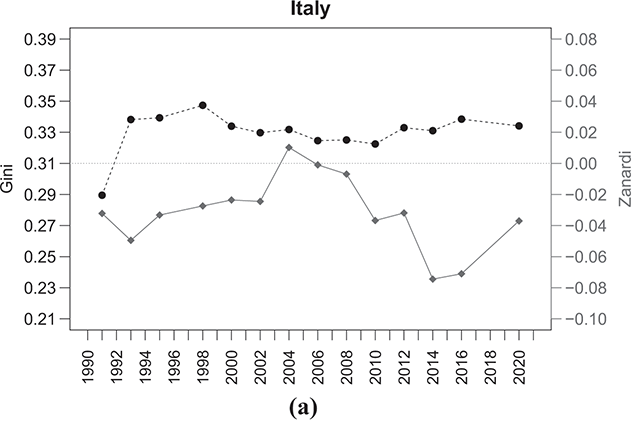
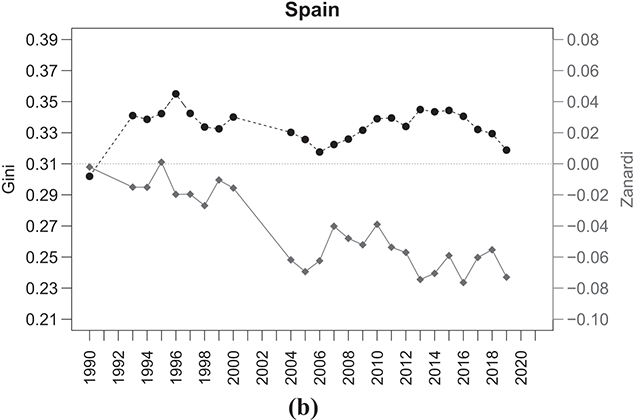
Figure 2.8 Temporal evolution of the Gini (bullets, left scale) and Zanardi (squares, right scale), Southern European countries
Note: The horizontal line represents the zero reference line for the Zanardi index.
The same conclusion applies to the Northern European countries referred to in Figure 2.9, where despite initially displaying relatively low levels of  , there has been a significant shift in inequality dynamics between the rich and the poor over time. For instance, in countries like Denmark, there has been a transition from highly negative Zanardi index values to values approaching the symmetry line. On the other hand, Norway and Sweden have observed increased bottom-inequality since 2006, with Norway experiencing a notable shift in trend in the last year.
, there has been a significant shift in inequality dynamics between the rich and the poor over time. For instance, in countries like Denmark, there has been a transition from highly negative Zanardi index values to values approaching the symmetry line. On the other hand, Norway and Sweden have observed increased bottom-inequality since 2006, with Norway experiencing a notable shift in trend in the last year.
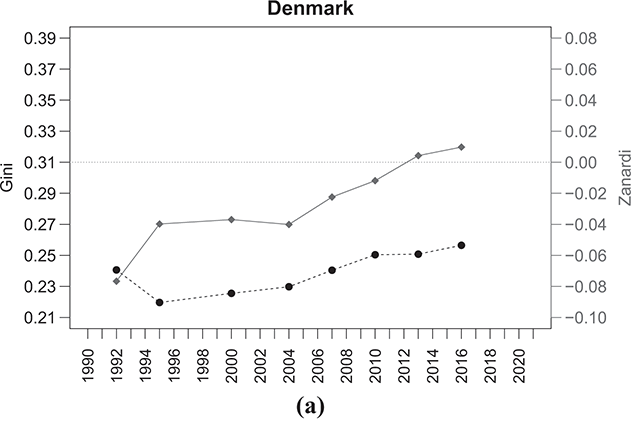
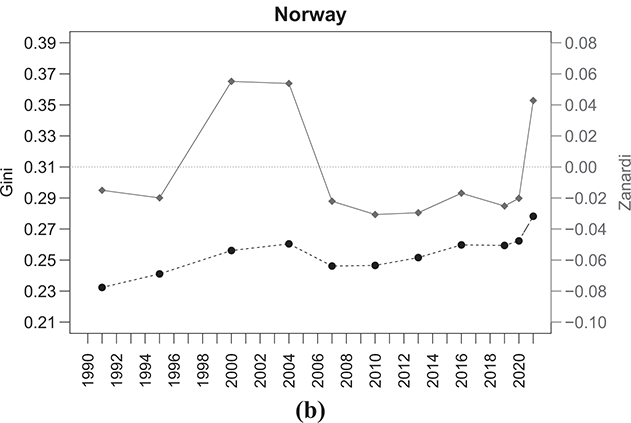
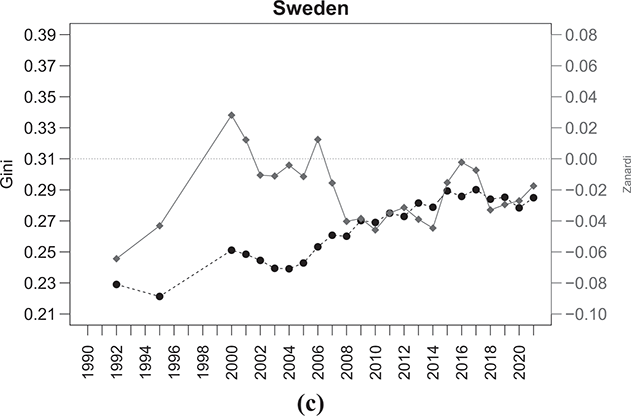
Figure 2.9 Temporal evolution of the Gini (bullets, left scale) and Zanardi (squares, right scale), Northern European countries
Note: The horizontal line represents the zero reference line for the Zanardi index.
This simple empirical analysis offers a clear demonstration of the importance of incorporating asymmetry into the analysis of inequality. It offers essential insights for a discussion on the accurate interpretation of inequality. In conclusion, these results call for a more detailed approach to understanding income inequality, moving beyond the conventional analysis focused solely on Lorenz curve concentration or entropy indices, in favor of a more detailed analysis that can also emphasize asymmetries in income distributions.
3 The  -Generalized Distribution
-Generalized Distribution

3.1 Introduction
Mathematical statistics is dominated by two large families of distributions. The first is the exponential family, whose main characteristic is that it contains distributions that decay exponentially. Three important members of the exponential family are mentioned below. The first distribution is the generalized gamma distribution, with the probability density function (PDF)  given by
given by  , where
, where  is the normalization constant and
is the normalization constant and  , with
, with  ,
,  ,
,  . A second distribution from the family of exponential distributions is the generalized logistic distribution, which is defined starting from its survival function
. A second distribution from the family of exponential distributions is the generalized logistic distribution, which is defined starting from its survival function  , where
, where  , which is connected to
, which is connected to  by
by  . The standard logistic distribution corresponds to
. The standard logistic distribution corresponds to  and
and  . A third distribution is the Weibull distribution, which corresponds to the case
. A third distribution is the Weibull distribution, which corresponds to the case  of the second distribution, and its survival function is given by
of the second distribution, and its survival function is given by  .
.
Besides the exponential family, a second family is that of distributions whose tails are described by the Pareto law  , with
, with  . This family of distributions contains three commonly used distributions defined by the survival function as follows: the first is the log-logistic distribution, with
. This family of distributions contains three commonly used distributions defined by the survival function as follows: the first is the log-logistic distribution, with  ; the second is the Burr Type XII or Sing-Maddala distribution, with
; the second is the Burr Type XII or Sing-Maddala distribution, with  and
and  ; finally, the third distribution is that of Dagum, with
; finally, the third distribution is that of Dagum, with  .
.
In the distributions of the second family, the monomial function  is the same as the one that occurs in the first family. Apart from this common point, there is no other correlation between the two families of distributions. It can also be noted that the three distributions of the second family are the simplest to construct, but there are a variety of other distributions that have asymptotically Pareto tails.
is the same as the one that occurs in the first family. Apart from this common point, there is no other correlation between the two families of distributions. It can also be noted that the three distributions of the second family are the simplest to construct, but there are a variety of other distributions that have asymptotically Pareto tails.
This dichotomy between these two families of statistical distributions leads to some problems on a theoretical level if we keep in mind that there are a large number of systems that are well described by exponential models for low values of the variable  while these models gradually turn into power-law tail models for increasing values of
while these models gradually turn into power-law tail models for increasing values of  .
.
The problem thus arises as to whether the second family of models must be proposed independently of the first family, as has been done in the past, or whether the models of the second family must be replaced by another family which is a deformation of the models of the first family. In the last two decades, this idea has been developed and it has shown that is possible to propose a unique family of models, different from the two above-discussed families. The new family of models, for  reduces to the first exponential family, while for
reduces to the first exponential family, while for  behaves differently to the second family but it also presents Pareto power-law tails. This was possible thanks to the physical mechanism emerging in special relativity which deforms the ordinary exponential function and replaces it with a new function, the so-called κ-exponential function defined as
behaves differently to the second family but it also presents Pareto power-law tails. This was possible thanks to the physical mechanism emerging in special relativity which deforms the ordinary exponential function and replaces it with a new function, the so-called κ-exponential function defined as
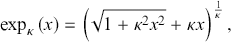 (3.1)
(3.1)
with  (Kaniadakis, Reference Kaniadakis2001, Reference Kaniadakis2002, Reference Kaniadakis2005). For
(Kaniadakis, Reference Kaniadakis2001, Reference Kaniadakis2002, Reference Kaniadakis2005). For  or equivalently for
or equivalently for  , the κ-exponential reduces to the Euler ordinary exponential, that is,
, the κ-exponential reduces to the Euler ordinary exponential, that is,  , whereas for
, whereas for  the κ-exponential reduces to Pareto law, that is,
the κ-exponential reduces to Pareto law, that is,  .Footnote 9
.Footnote 9
The κ-deformed version of the three distributions of the exponential family can be introduced easily as follows (Kaniadakis, Reference Kaniadakis2021):
(i) κ-deformed generalized gamma distribution; it is defined through its PDF as
with(3.2)
. In the limit, the density function reduces to the ordinary Generalized Gamma density . Asymptotically for , the density function behaves according to .(ii) κ-deformed generalized logistic distribution; the survival function of the distribution is given by
with(3.3)
. In the limit, the function (3.3) reduces to ordinary generalized logistic survival function , while for it behaves according to .(iii) κ-deformed Weibull distribution; the special case corresponding to
of the previous distribution is the κ-deformed Weibull distribution with survival or reliability function given by
(3.4)














The κ-deformed Weibull distribution is the κ-deformed distribution that undoubtedly has found extensive applications, particularly in economics (Clementi, Reference Clementi2023; Clementi et al., Reference Clementi, Di Matteo, Gallegati and Kaniadakis2008; Clementi & Gallegati, Reference Clementi, Gallegati, Kaniadakis and Landini2016, Reference Clementi and Gallegati2017; Clementi et al., Reference Clementi, Gallegati and Kaniadakis2007, Reference Clementi, Gallegati and Kaniadakis2009, Reference Clementi, Gallegati and Kaniadakis2010, Reference Clementi, Gallegati and Kaniadakis2012a, Reference Clementi, Gallegati and Kaniadakis2012b; Clementi et al., Reference Clementi, Gallegati, Kaniadakis and Landini2016; Clementi & Gianmoena, Reference Clementi and Gallegati2017) and in seismology (Hristopulos & Baxevani, Reference Hristopulos and Baxevani2022; Hristopulos, Petrakis, & Kaniadakis, Reference Hristopulos, Petrakis and Kaniadakis2014, Reference Hristopulos, Petrakis and Kaniadakis2015). Its cumulative distribution function  writes as
writes as
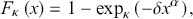 (3.5)
(3.5)
while the related PDF  becomes
becomes
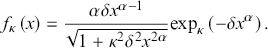 (3.6)
(3.6)
After noticing that
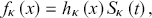 (3.7)
(3.7)
with
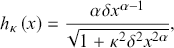 (3.8)
(3.8)
we deduce that  represents the hazard function of the model.
represents the hazard function of the model.
The derivation with respect  of the survival function permits to obtain easily its rate equation in the form
of the survival function permits to obtain easily its rate equation in the form
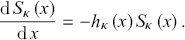 (3.9)
(3.9)
The integration of this first-order linear ordinary differential equation with the initial condition  permits to write the survival function in the form
permits to write the survival function in the form
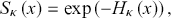 (3.10)
(3.10)
where  is the cumulative hazard function, defined by means of the integral
is the cumulative hazard function, defined by means of the integral
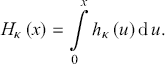 (3.11)
(3.11)
After performing the latter integral, the explicit form of the cumulative hazard function is obtained as
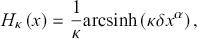 (3.12)
(3.12)
which in the  limit reduces to the standard Weibull cumulative hazard function
limit reduces to the standard Weibull cumulative hazard function  .
.
A direct comparison between Equations (3.4) and (3.10), incorporating the expression of the cumulative hazard function as provided in Equation (3.12), yields the already established second representation of the κ-exponential function, namely
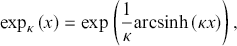 (3.13)
(3.13)
so that the κ-Weibull survival function assumes the form
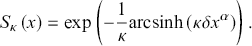 (3.14)
(3.14)
The remainder of the section is devoted to elucidating the main statistical properties of the κ-deformed Weibull distribution, also known in econophysics literature as the κ-generalized distribution after Clementi et al. (Reference Clementi, Gallegati and Kaniadakis2007). This distribution, employing a marginally distinct parameterization from the κ-deformed Weibull, where  , offers a cohesive framework for describing real-world data, encompassing the power-law tails observed in empirical distributions of income and wealth.Footnote 10
, offers a cohesive framework for describing real-world data, encompassing the power-law tails observed in empirical distributions of income and wealth.Footnote 10
The κ-generalized distribution has showcased remarkable efficacy and is frequently viewed as a superior alternative to other commonly utilized parametric models. Initially introduced in 2007 and subsequently refined in subsequent years, this model traces its roots back to the realm of κ-generalized statistical mechanics (Kaniadakis, Reference Kaniadakis2001, Reference Kaniadakis2002, Reference Kaniadakis2005, Reference Kaniadakis2009a, Reference Kaniadakis2009b, Reference Kaniadakis2013). It possesses a bulk closely resembling that of the Weibull distribution, with an upper tail that follows a Pareto power law for high levels of income and wealth. This characteristic enables it to offer an intermediate perspective between the two previously mentioned descriptions.
3.2 The κ-Generalized Model for Income Distribution
3.2.1 Definitions and Fundamental Properties
A variable  following a κ-generalized distribution, denoted
following a κ-generalized distribution, denoted  , is characterized by a PDF given byFootnote 11
, is characterized by a PDF given byFootnote 11
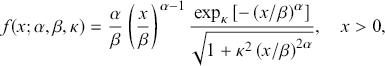 (3.15)
(3.15)
where  and
and  . The cumulative distribution function (CDF) of this distribution is formulated as
. The cumulative distribution function (CDF) of this distribution is formulated as
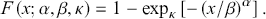 (3.16)
(3.16)
Figure 3.1 visually depicts the properties of the κ-generalized PDF and the complementary CDF (a.k.a. the survival function), referred to as  , under various parameter configurations. In each pair of plots, two parameters remain constant while the third is adjusted to demonstrate its effect on the distribution.
, under various parameter configurations. In each pair of plots, two parameters remain constant while the third is adjusted to demonstrate its effect on the distribution.
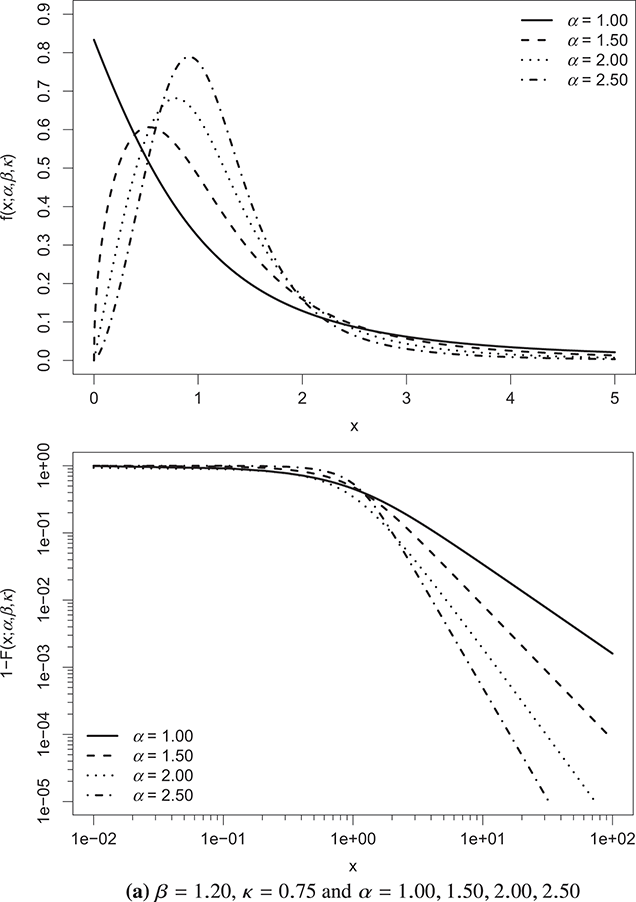
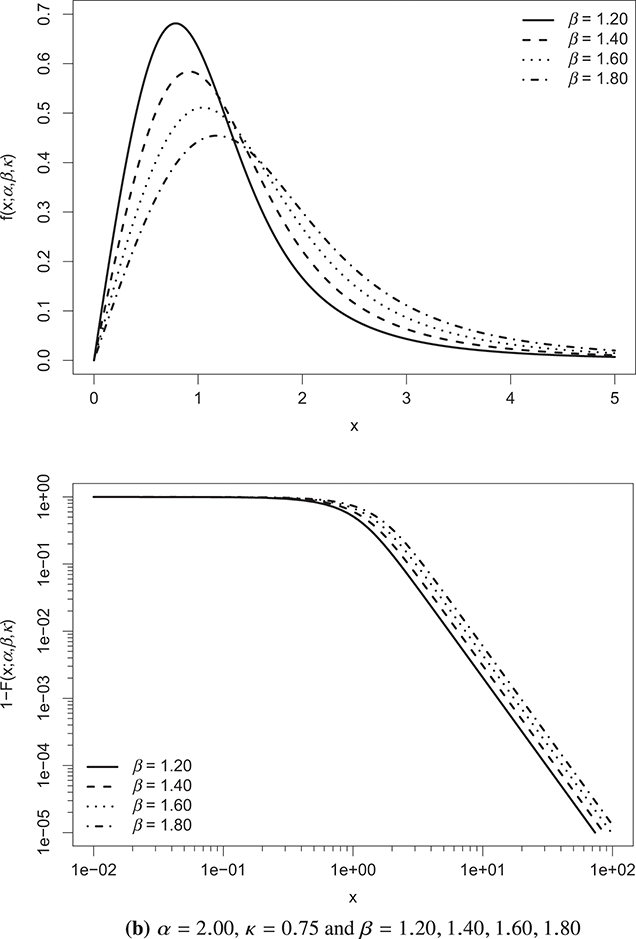
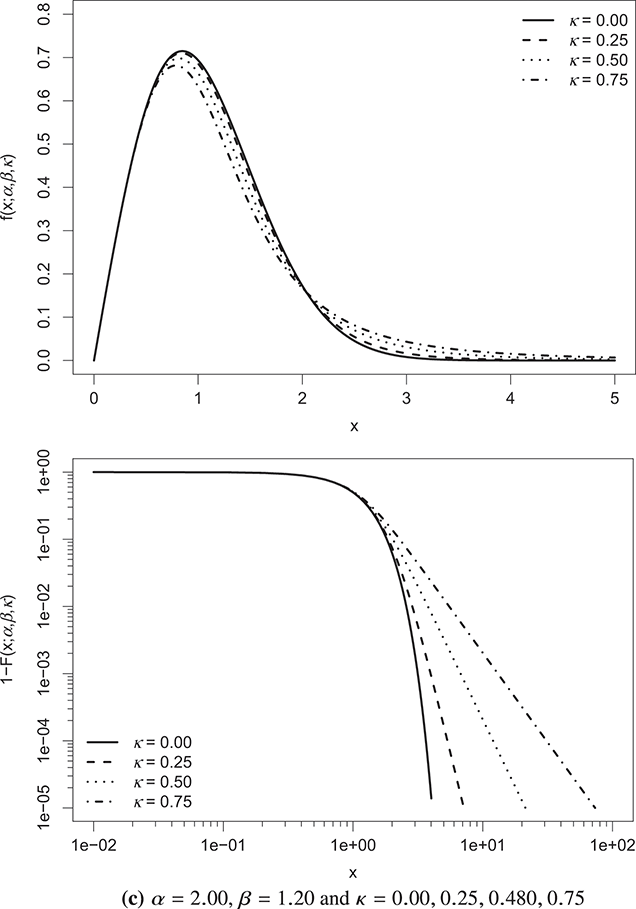
Figure 3.1 κ-generalized PDF (top) and complementary CDF (bottom) across different parameter values
Note: The complementary CDF is plotted on double-log axes to accentuate the right-tail behavior of the distribution.
The constant  acts as a scale factor, representing the income dimension. Thus, it incorporates the monetary unit, facilitating adjustments for inflation and allowing for cross-country comparisons of income distributions expressed in different currencies. Increases in
acts as a scale factor, representing the income dimension. Thus, it incorporates the monetary unit, facilitating adjustments for inflation and allowing for cross-country comparisons of income distributions expressed in different currencies. Increases in  correspond to global rises in individual income and average income levels.
correspond to global rises in individual income and average income levels.
On the other hand, the parameters  and κ are dimensionless and shape the distribution.
and κ are dimensionless and shape the distribution.  primarily affects the region near the distribution’s origin, while both
primarily affects the region near the distribution’s origin, while both  and κ influence the distribution’s upper tail. A higher κ leads to a thicker upper tail, while increasing
and κ influence the distribution’s upper tail. A higher κ leads to a thicker upper tail, while increasing  narrows both tails and concentrates probability mass around the distribution’s peak.
narrows both tails and concentrates probability mass around the distribution’s peak.
As κ approaches 0, the κ-generalized distribution tends towards the Weibull distribution.Footnote 12 This convergence is evident from
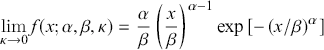 (3.17)
(3.17)
and
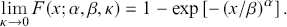 (3.18)
(3.18)
As  approaches 0 from the positive side, the distribution behaves like the Weibull model. Conversely, for large
approaches 0 from the positive side, the distribution behaves like the Weibull model. Conversely, for large  , it tends towards a Pareto distribution of the first kind, characterized by a scale parameter
, it tends towards a Pareto distribution of the first kind, characterized by a scale parameter  and a shape parameter
and a shape parameter  , expressed as
, expressed as
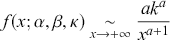 (3.19)
(3.19)
and
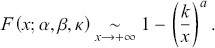 (3.20)
(3.20)
Thus, it adheres to the weak Pareto law, as defined by Mandelbrot (Reference Mandelbrot1960).Footnote 13
The closed-form expression for the quantile function, derived from Equation (3.16), is
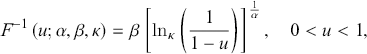 (3.21)
(3.21)
where  represents the deformed logarithmic function, defined as the inverse function of (3.1), namely
represents the deformed logarithmic function, defined as the inverse function of (3.1), namely  . It is expressed as
. It is expressed as
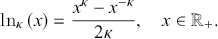 (3.22)
(3.22)
Thus, random numbers from a κ-generalized distribution can be easily generated using the inversion method.
The median of the distribution is
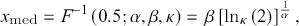 (3.23)
(3.23)
and the mode occurs at
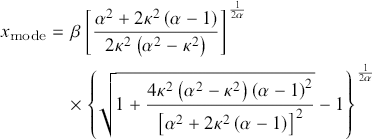 (3.24)
(3.24)
if  ; otherwise, the distribution is zero-modal with a pole at the origin.
; otherwise, the distribution is zero-modal with a pole at the origin.
The  th raw moment of the κ-generalized distribution is given by
th raw moment of the κ-generalized distribution is given by
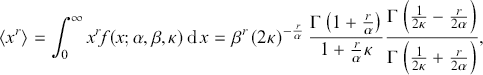 (3.25)
(3.25)
where  denotes the gamma function, and it exists for
denotes the gamma function, and it exists for  . Particularly,
. Particularly,
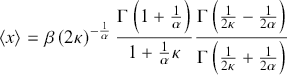 (3.26)
(3.26)
represents the mean of the distribution, and
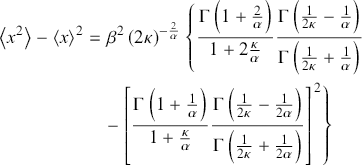 (3.27)
(3.27)
denotes the variance.
3.2.2 Assessing Income Inequality through the κ-Generalized Distribution
In economics, the notion of inequality traces its roots to Pareto’s early investigations (Pareto, Reference Pareto1895, Reference Pareto and Busino1896, Reference Pareto1897a, Reference Pareto1897b), which revealed that roughly 80 percent of total income/wealth was held by the top 20 percent. Subsequently, Lorenz (Reference Lorenz1905) introduced the Lorenz curve, a widely employed method for gauging income/wealth inequality. This curve compares the actual income or wealth distribution with an equal distribution. Under perfect equality, the Lorenz curve aligns with the diagonal of a unit square. Any deviation from this diagonal signifies a more unequal distribution.
The Lorenz curve for a positive and transferable random variable  with a CDF
with a CDF  and a finite mean
and a finite mean  is defined as presented by Gastwirth (Reference Gastwirth1971)
is defined as presented by Gastwirth (Reference Gastwirth1971)
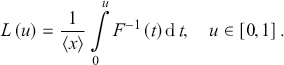 (3.28)
(3.28)
By employing the closed-form expression of the quantile function  of the κ-generalized distribution, the Lorenz curve can be represented as indicated by Okamoto (Reference Okamoto2013)
of the κ-generalized distribution, the Lorenz curve can be represented as indicated by Okamoto (Reference Okamoto2013)
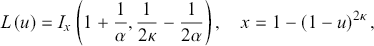 (3.29)
(3.29)
where  denotes the regularized incomplete beta function, defined in terms of the incomplete beta function and the complete beta function, as
denotes the regularized incomplete beta function, defined in terms of the incomplete beta function and the complete beta function, as  . The curve exists if and only if
. The curve exists if and only if  . Specifically, if
. Specifically, if  for
for  , the conditions for the Lorenz curves of
, the conditions for the Lorenz curves of  and
and  not to intersect are elaborated in Clementi et al. (Reference Clementi, Gallegati and Kaniadakis2010) as
not to intersect are elaborated in Clementi et al. (Reference Clementi, Gallegati and Kaniadakis2010) as
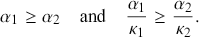 (3.30)
(3.30)
The Lorenz curves of two κ-generalized distributions  and
and  with parameters chosen according to (3.30) are illustrated in Figure 3.2. The depicted curves indicate that
with parameters chosen according to (3.30) are illustrated in Figure 3.2. The depicted curves indicate that  exhibits less inequality than
exhibits less inequality than  , as the Lorenz curve of
, as the Lorenz curve of  neither intersects nor falls below that of
neither intersects nor falls below that of  .
.
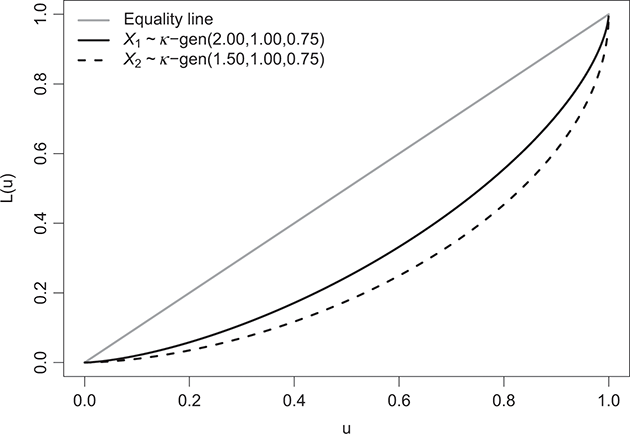
Figure 3.2 Lorenz curves for two κ-generalized distributions
Economists have employed different statistical metrics to measure income and wealth inequality. Among these, the coefficient introduced by Gini (Reference Gini1914) is prominent. Starting from the general definition provided by Arnold and Laguna (Reference Arnold and Laguna1977), the Gini coefficient associated with the κ-generalized distribution is derived as
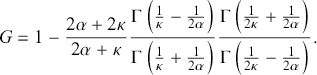 (3.31)
(3.31)
Employing the Stirling approximation for the gamma function and taking the limit as  in Equation (3.31), and after simplification, we obtain
in Equation (3.31), and after simplification, we obtain  , representing the explicit form of the Gini coefficient for the Weibull distribution. Additionally, for
, representing the explicit form of the Gini coefficient for the Weibull distribution. Additionally, for  and
and  , the exponential distribution emerges as a special limiting case of the κ-generalized distribution with a Gini coefficient of one half (Drăgulescu & Yakovenko, Reference Drăgulescu and Yakovenko2001).
, the exponential distribution emerges as a special limiting case of the κ-generalized distribution with a Gini coefficient of one half (Drăgulescu & Yakovenko, Reference Drăgulescu and Yakovenko2001).
Although the Gini coefficient is widely used, it assumes specific patterns of income disparities across different distribution segments. It is most sensitive to transfers around the middle of the distribution and less responsive to changes among the extremely wealthy or impoverished (Allison, Reference Allison1978). In contrast, the generalized entropy class of inequality measures (Cowell, Reference Cowell1980a, Reference Cowell1980b; Cowell & Kuga, Reference Cowell and Kuga1981a, Reference Cowell and Kuga1981b; Shorrocks, Reference Shorrocks1980) offers a range of indices sensitive to inequality across various distribution segments. The formula for this class of inequality indices in terms of the κ-generalized parameters is provided by (Clementi et al., Reference Clementi, Gallegati and Kaniadakis2009)
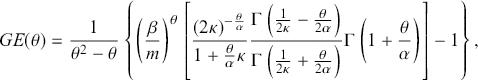 (3.32)
(3.32)
where  and
and  denotes the mean of the distribution. This class allows different forms of inequality measures depending on the value assigned to
denotes the mean of the distribution. This class allows different forms of inequality measures depending on the value assigned to  , indicating the index’s sensitivity to income differences across various distribution segments – a more positive or negative
, indicating the index’s sensitivity to income differences across various distribution segments – a more positive or negative  corresponds to greater sensitivity of
corresponds to greater sensitivity of  to income differences at the top or bottom of the distribution. Notable limiting cases, derived when
to income differences at the top or bottom of the distribution. Notable limiting cases, derived when  is set to 0 and 1, are the MLD index
is set to 0 and 1, are the MLD index
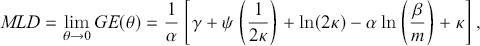 (3.33)
(3.33)
where  is the Euler-Mascheroni constant and
is the Euler-Mascheroni constant and  is the digamma function, and the Theil (Reference Theil1967) index:
is the digamma function, and the Theil (Reference Theil1967) index:
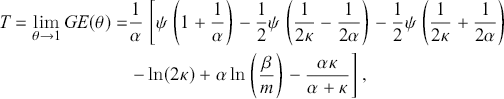 (3.34)
(3.34)
where the former is more sensitive to changes in the middle of the distribution, while the latter is more responsive to variations in the upper tail (Jenkins, Reference Jenkins2009; Sarabia, Jordá, & Remuzgo, Reference Sarabia, Jordá and Remuzgo2017).Footnote 14
Lastly, the inequality measures family introduced by Atkinson (Reference Atkinson1970) can be derived from (3.32) using the relationship (Cowell, Reference Cowell2011; Jenkins, Reference Jenkins2009)
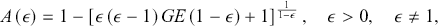 (3.35)
(3.35)
where  represents the inequality aversion parameter. As
represents the inequality aversion parameter. As  increases,
increases,  becomes more sensitive to changes in lower incomes and less responsive to alterations in top incomes (Allison, Reference Allison1978). The limiting expression of (3.35) is
becomes more sensitive to changes in lower incomes and less responsive to alterations in top incomes (Allison, Reference Allison1978). The limiting expression of (3.35) is  .Footnote 15
.Footnote 15
3.2.3 Estimation
The estimation of parameters in the κ-generalized distribution can be achieved through maximum likelihood estimation, providing estimators known for their advantageous statistical properties (Ghosh, Reference Ghosh1994; Rao, Reference Rao1973). For a set of independent sample observations  , the likelihood function is expressed as
, the likelihood function is expressed as
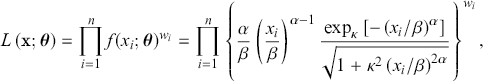 (3.36)
(3.36)
where  represents the PDF,
represents the PDF,  denotes the vector of unknown parameters,
denotes the vector of unknown parameters,  is the weight assigned to the
is the weight assigned to the  th observation, and
th observation, and  is the sample size. This formulation leads to determining the partial derivatives with respect to
is the sample size. This formulation leads to determining the partial derivatives with respect to  ,
,  , and κ for the log-likelihood function
, and κ for the log-likelihood function
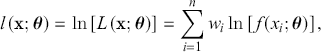 (3.37)
(3.37)
which translates into solving the following system of equations
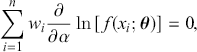 (3.38)
(3.38)
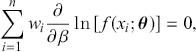 (3.39)
(3.39)
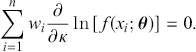 (3.40)
(3.40)
However, obtaining explicit expressions for the maximum likelihood estimators of the three κ-generalized parameters poses a challenge due to the absence of feasible analytical solutions. Therefore, resorting to numerical optimization algorithms becomes imperative to tackle the maximum likelihood estimation problem.
3.2.4 Utilizations of κ-Generalized Models in Analyzing Income and Wealth Data
Over the past two decades, the κ-generalized model has found extensive application in analyzing income and wealth data across various real-world contexts.
The initial investigation, led by Clementi et al. (Reference Clementi, Gallegati and Kaniadakis2007), scrutinized household incomes in Germany, Italy, and the United Kingdom during 2001–2002. Their study revealed a notable agreement between the model and empirical distributions across all income tiers, particularly within the intermediate range where deviations were noted when using the Weibull model and pure Pareto law for interpolation.
Subsequent studies extended the application of the κ-generalized distribution to Australian household incomes in 2002–2003 (Clementi et al., Reference Clementi, Di Matteo, Gallegati and Kaniadakis2008) and US family incomes in 2003 (Clementi et al., Reference Clementi, Di Matteo, Gallegati and Kaniadakis2008, Reference Clementi, Gallegati and Kaniadakis2009). In both instances, the model provided a comprehensive depiction of the income spectrum and yielded accurate estimations of inequality measures, such as the Lorenz curve and Gini coefficient.
Comparative analyses, pivotal for assessing relative performance, were also undertaken. For example, Clementi et al. (Reference Clementi, Gallegati and Kaniadakis2010) examined household income distributions in Italy spanning from 1989 to 2006. Their results showcased the superior performance of the κ-generalized model over three-parameter competitors, such as the Singh–Maddala and Dagum type I distributions, except for the GB2 distribution, which features an additional parameter. Similar evaluations were conducted for household income datasets from Greece, Germany, the United Kingdom, and the United States, demonstrating the superiority of the κ-generalized model, particularly in modeling the right tail of the data (Clementi, Reference Clementi2023; Clementi et al., Reference Clementi, Gallegati and Kaniadakis2012a). Additionally, Clementi and Gallegati (Reference Clementi and Gallegati2016) concluded that the κ-generalized distribution offered a superior fit to the data and more precise estimates of income inequality compared to alternatives, leveraging household income data from 45 countries extracted from the LIS Database.
The application of the κ-generalized distribution extends to examining peculiarities within survey data on net wealth, defined as gross wealth minus total debt (Clementi & Gallegati, Reference Clementi and Gallegati2016; Clementi et al., Reference Clementi, Gallegati and Kaniadakis2012b). These datasets often feature significant occurrences of households or individuals with either null or negative wealth. The model for wealth distribution, based on the κ-generalized distribution, comprises a mixture of an atomic and two continuous distributions. The atomic distribution caters to economic units with zero net worth, while negative net worth data are described by a Weibull function. Conversely, positive net worth values are characterized by the κ-generalized model outlined in Equation (3.15). Analyzing US net worth data from 1984 to 2011 (Clementi et al., Reference Clementi, Gallegati and Kaniadakis2012b), the κ-generalized mixture model for wealth distribution demonstrated remarkable accuracy, surpassing finite mixture models based on the Singh–Maddala and Dagum type I distributions for positive net worth values. A similar examination carried out by Clementi and Gallegati (Reference Clementi and Gallegati2016) explored net wealth data from nine distinct countries.
4 Modeling Income Data Using the -Generalized Distribution

In the following, we explore the ability of the κ-generalized model in describing real-world income distributions. Initially, we present the outcomes of fitting the κ-generalized distribution to LIS income data, demonstrating its accuracy in representing real-world data. Subsequently, we assess the performance of the κ-generalized distribution against alternative parametric models proposed in the literature for income distribution. These models are applied to all available national datasets within the income micro-database currently utilized. As previously noted in Section 2.4 of this Element, the statistical analyses presented here are based on LIS microdata updated in March 2024, incorporating additional datasets into the database and thereby broadening the scope of distributions that can be analyzed.
4.1 Results of Fitting to Empirical Distributions
Figures 4.1–4.4 illustrate the outcomes of fitting the κ-generalized model to empirical income data, reflecting the household income distribution in key countries categorized into the four groups discussed in Section 2.4.1: the United States, emblematic of the Anglo-Saxon countries group; Germany, representing the Western European countries group; Italy, representing the Southern European countries group; and Sweden, representing the Northern European countries group. These four cases correspond to the latest available data years for the respective countries within the LIS Database, specifically 2022 for the United States, 2020 for Germany and Italy, and 2021 for Sweden.
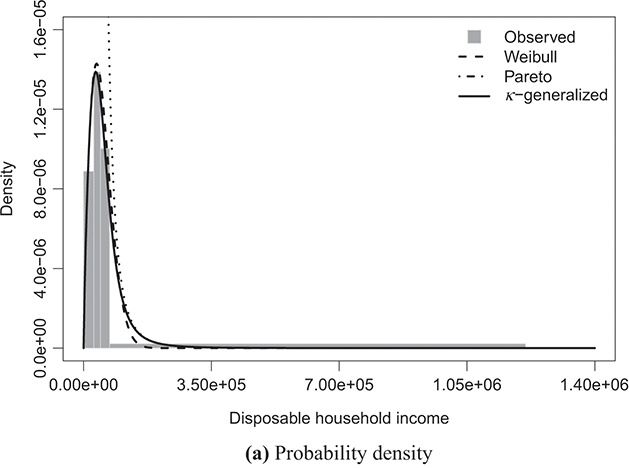
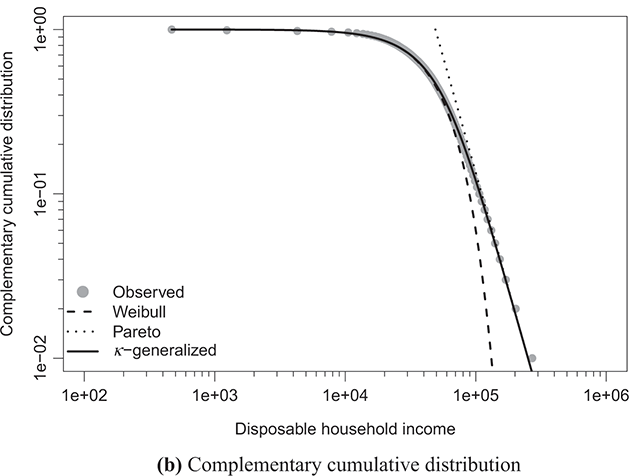
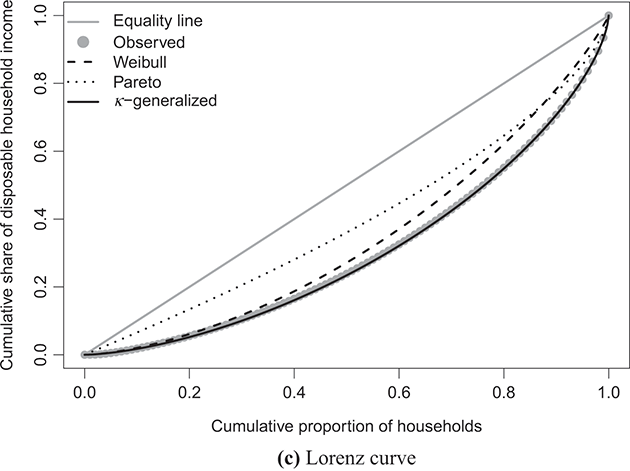
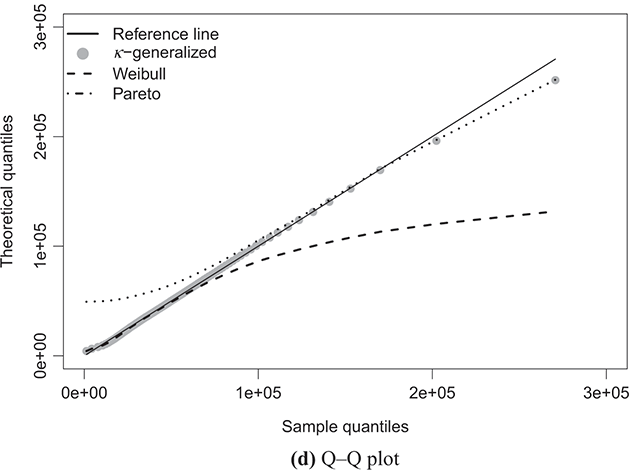
Figure 4.1 The κ-generalized distribution fitted to household income data for the United States in 2022
Note: The solid line depicts the κ-generalized model, which fits the data across the entire income spectrum, from low to high incomes, including the middle-income range. This model is contrasted with the Weibull (dashed line) and Pareto power-law (dotted line) distributions. The complementary cumulative distribution is plotted on a double-log scale, emphasizing the distribution’s behavior in the right tail. The Lorenz curve plot compares the empirical and theoretical curves, where the solid gray line represents the Lorenz curve of a society with equal income distribution. The Q–Q plot of sample percentiles versus theoretical percentiles of the fitted κ-generalized model shows an excellent fit, with corresponding percentiles closely aligned along the 45-degree line from the origin.
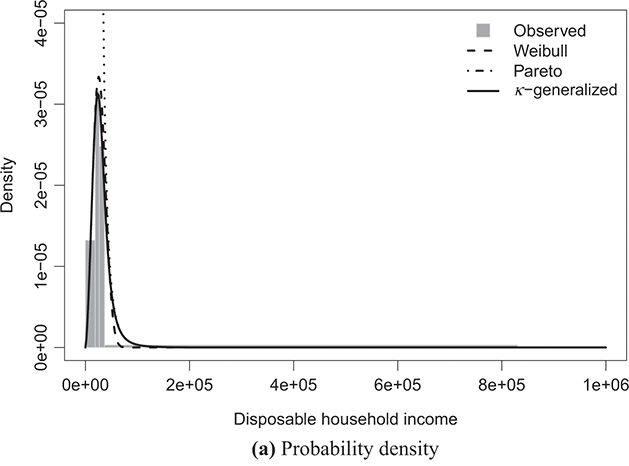
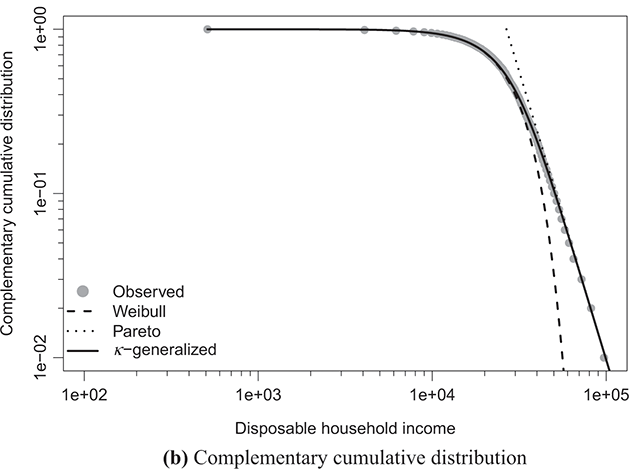
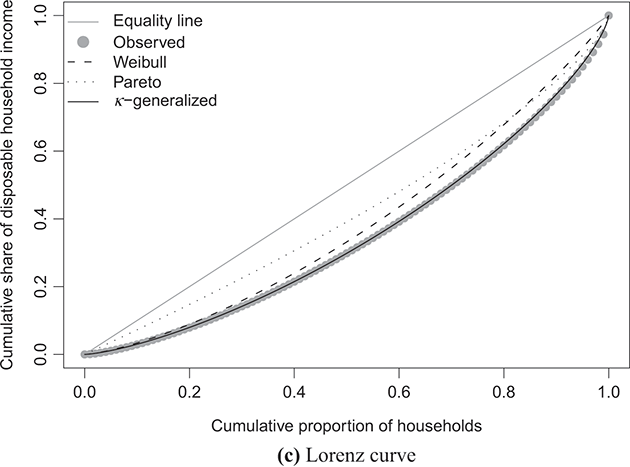
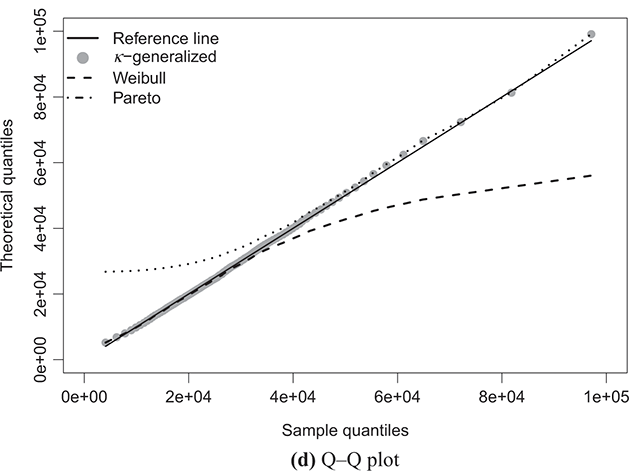
Figure 4.2 The κ-generalized distribution fitted to household income data for Germany in 2020
Note: See note to Figure 4.1.
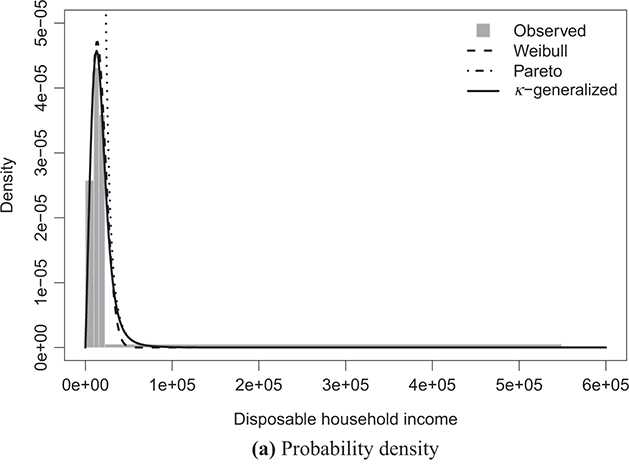
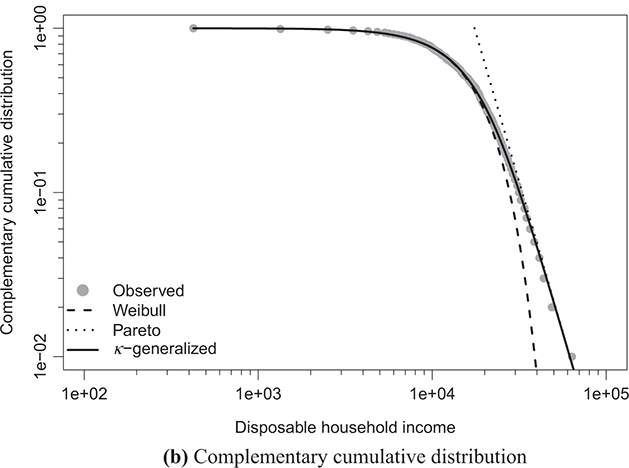
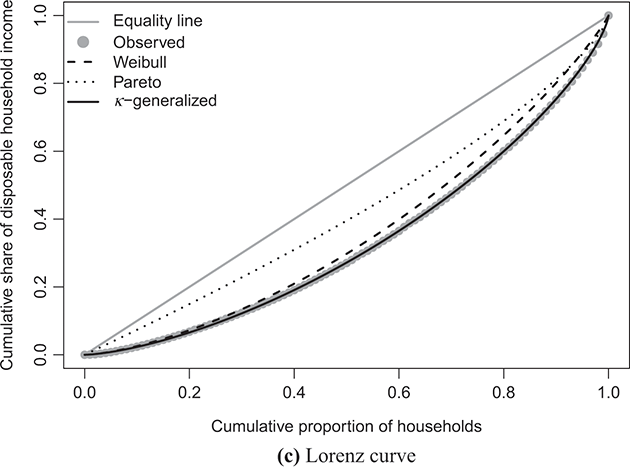
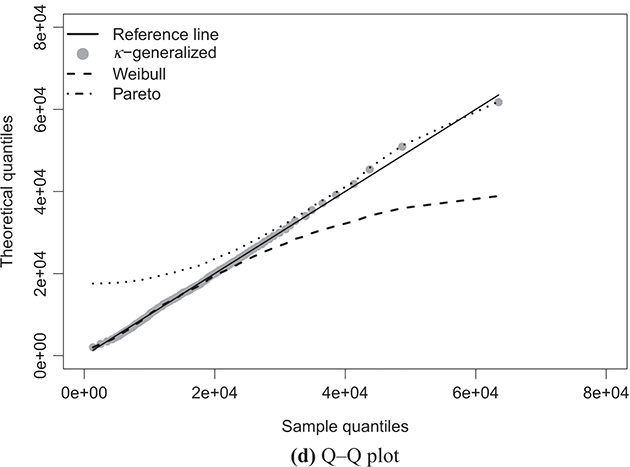
Figure 4.3 The κ-generalized distribution fitted to household income data for Italy in 2020
Note: See note to Figure 4.1.
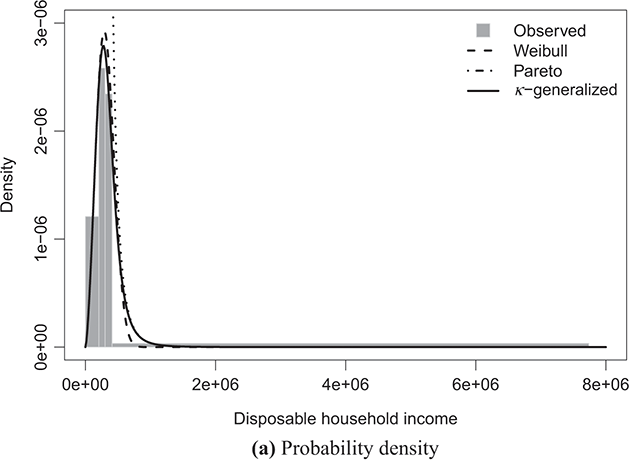
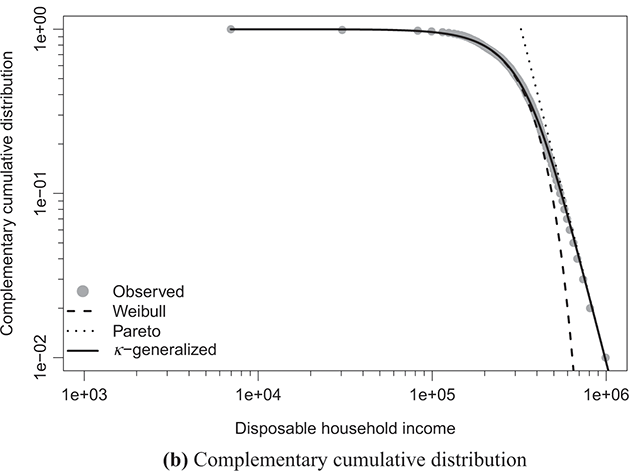
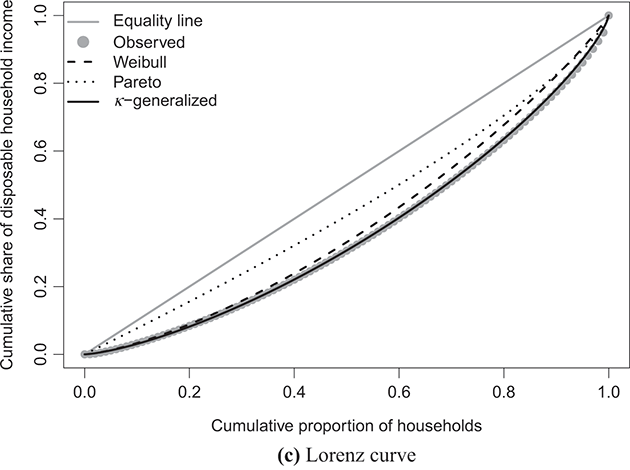
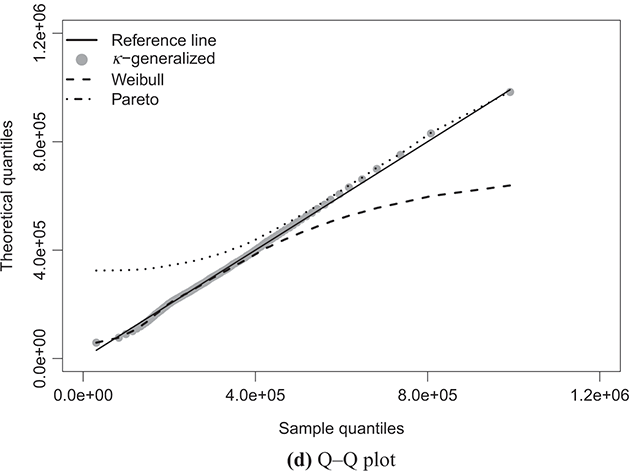
Figure 4.4 The κ-generalized distribution fitted to household income data for Sweden in 2021
Note: See note to Figure 4.1.
The best-fitting parameter values were determined using maximum likelihood estimation, as discussed in Section 3.2.3. This yielded the parameter estimates shown in Table 4.1. The very small errors indicate precise parameter estimation. By comparing the observed and fitted probabilities in panels (a) and (b) of the figures, it becomes apparent that the κ-generalized distribution holds great potential for accurately describing the data across their entire range, from the low-to-medium income region to the high-income Pareto power-law regime, encompassing the intermediate region where a clear deviation is evident when using two different curves.
Table 4.1 Estimated κ-generalized parameters for selected LIS country datasets
| Country | Year |  |  |  |
|---|---|---|---|---|
| Germany | 2020 | 2.579 | 30,999.950 | 0.735 |
| (0.028) | (161.972) | (0.020) | ||
| Italy | 2020 | 2.076 | 18,634.850 | 0.569 |
| (0.030) | (159.347) | (0.026) | ||
| Sweden | 2021 | 2.564 | 351,933.240 | 0.619 |
| (0.031) | (2,104.757) | (0.022) | ||
| United States | 2022 | 1.790 | 56,138.910 | 0.636 |
| (0.009) | (189.766) | (0.009) |
Note: Estimated standard errors in parentheses.
Panel (c) of the same figures displays the empirical data points for the Lorenz curve, overlaid with the theoretical curve derived from Equation (3.29) using the parameter estimates in place of  and κ. This curve is represented by the solid line in the plots and exhibits an exceptional fit to the data. Additionally, the plots juxtapose the empirical Lorenz curve with the theoretical curves associated with the Weibull and Pareto distributions, respectively defined as
and κ. This curve is represented by the solid line in the plots and exhibits an exceptional fit to the data. Additionally, the plots juxtapose the empirical Lorenz curve with the theoretical curves associated with the Weibull and Pareto distributions, respectively defined as
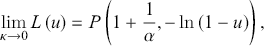 (4.1)
(4.1)
where  denotes the lower regularized incomplete gamma function, and
denotes the lower regularized incomplete gamma function, and
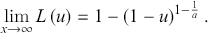 (4.2)
(4.2)
As evident, these curves capture only a fraction of the overall narrative.
The linear development observed in the quantile–quantile (Q–Q) plot of sample percentiles against the fitted κ-generalized distribution, along with its limiting cases, depicted in panels (d) of Figures 4.1 through 4.4, confirms the validity of the model. It also highlights that the Weibull and Pareto distributions offer only partial and incomplete descriptions of the data.
To indirectly evaluate the precision of parameter estimation, we computed predicted values for mean and median disposable household income, along with two inequality measures: the Gini coefficient and the Atkinson coefficient, where the latter’s inequality aversion parameter was set to 0.5 and 1. These computations entailed substituting the estimated parameters into the relevant expressions detailed in Sections 3.2.1 and 3.2.2. The results of these calculations are shown alongside their respective empirical counterparts in Figure 4.5 (for mean and median values) and Figure 4.6 (for inequality measures).Footnote 16 The empirical data were obtained from statistics provided by LIS staff under the LIS Inequality and Poverty Key Figures for the countries and years considered.Footnote 17
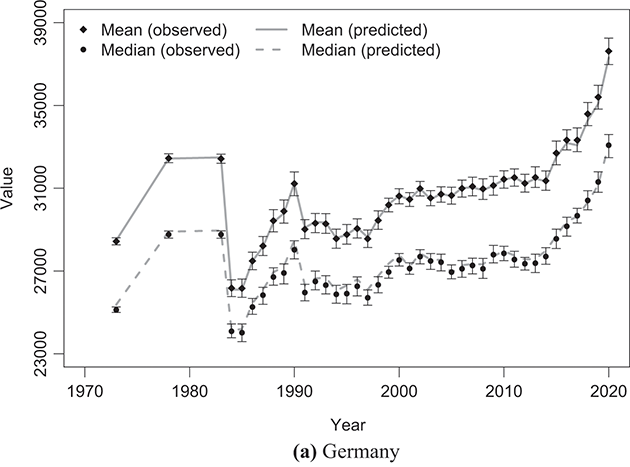
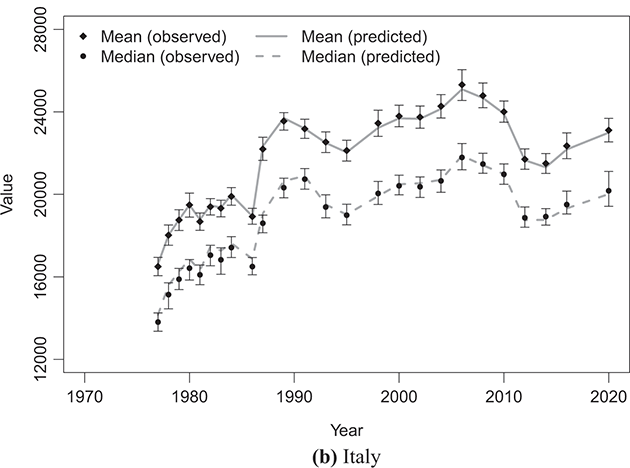
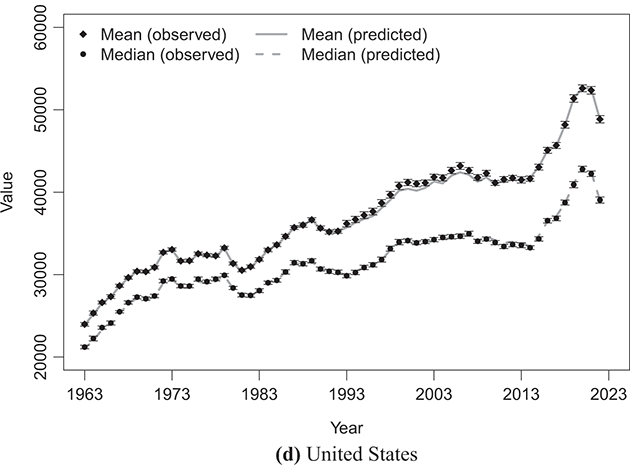
Figure 4.5 Observed mean and median values of disposable household income compared with the predicted values based on the κ-generalized model
Note: To directly compare absolute monetary values across different LIS datasets, mean and median monetary values have been converted into 2017 USD PPPs by dividing them by the corresponding year’s LIS PPP, which combines CPI (Consumer Price Index) and PPP (Purchasing Power Parity) deflators to compare real amounts across countries and over time.
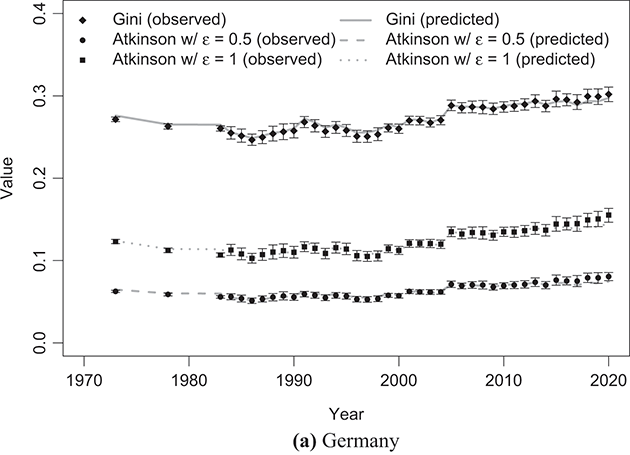
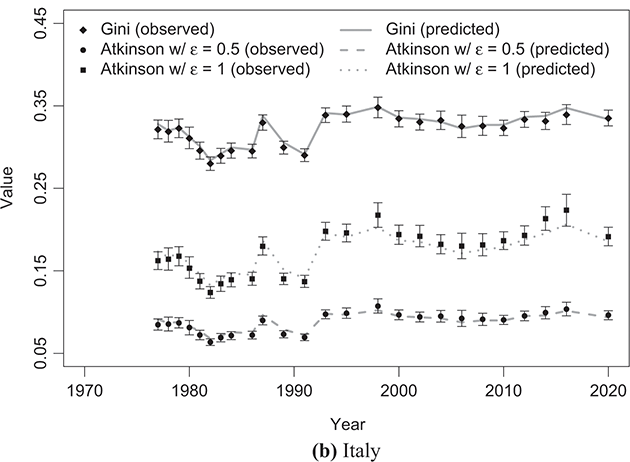
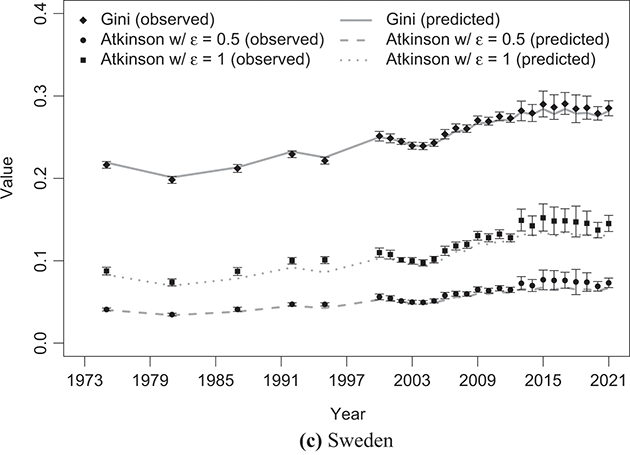
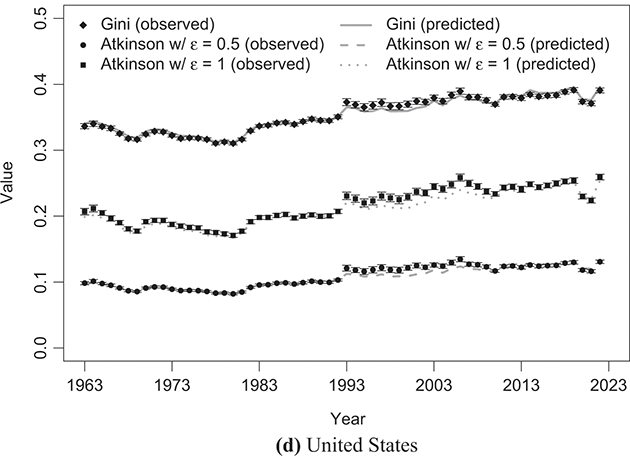
Figure 4.6 Observed Gini and Atkinson indices of disposable household income compared with the predicted values based on the κ-generalized model
As can be observed, the predictions derived from the κ-generalized distribution are largely encompassed by the confidence intervals constructed around the empirical values in the vast majority of cases.Footnote 18 This confirms the remarkable agreement between the model and the sample observations. Furthermore, the agreement between the estimates derived from the κ-generalized distribution and the sample values of the considered statistics remains excellent even when considering their temporal trend. Indeed, as shown in Table 4.2, the correlation coefficients between the time series of the considered statistics calculated from the data and those obtained from the estimation of the κ-generalized model are close to unity and all highly significant (the corresponding  -value is less than 0.001 in all cases).
-value is less than 0.001 in all cases).
Table 4.2 Correlation between selected distributional statistics computed from the data and the corresponding estimates implied by the fitted κ-generalized model
| Country | Time span | Statistic | ||||
|---|---|---|---|---|---|---|
| Mean | Median | G | A(0.5) | A(1) | ||
| Germany | 1973–2020 | 0.999 | 0.997 | 0.992 | 0.969 | 0.974 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | ||
| Italy | 1977–2020 | 0.999 | 0.997 | 0.988 | 0.973 | 0.982 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | ||
| Sweden | 1975–2021 | 1.000 | 1.000 | 0.998 | 0.990 | 0.988 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | ||
| United | 1963–2022 | 0.999 | 0.999 | 0.985 | 0.962 | 0.980 |
| (0.000) | (0.000) | (0.000) | (0.000) | (0.000) | ||
Note: Values in parentheses denote  -values for testing whether the correlation coefficient is statistically significant.
-values for testing whether the correlation coefficient is statistically significant.
The good performance of the κ-generalized distribution can also be appreciated by considering its ability to replicate the temporal trend of the Zanardi asymmetry index. As shown in Figure 4.7, the temporal pattern of the predicted Zanardi index values closely mirrors that of the corresponding empirical estimates calculated from the sample data and discussed in Section 2.4.1 of this Element.Footnote 19 The correlation coefficient values between the empirical Zanardi index and the corresponding estimates from the κ-generalized model, as presented in Table 4.3, corroborate the findings from the visual examination of the figure: all correlation coefficients indeed indicate a strong association between these series, being highly significant with  -value lesser than 0.001 in all cases.
-value lesser than 0.001 in all cases.
Table 4.3 Correlation between the implied and sample estimates of the Zanardi asymmetry index
| Country | Time span | Correlation | p-value |
|---|---|---|---|
| Canada | 1990–2019 | 0.991 | 0.000 |
| Denmark | 1992–2016 | 0.967 | 0.000 |
| France | 1990–2018 | 0.641 | 0.001 |
| Germany | 1990–2019 | 0.895 | 0.000 |
| Italy | 1991–2020 | 0.975 | 0.000 |
| Norway | 1991–2021 | 0.976 | 0.000 |
| Spain | 1990–2019 | 0.980 | 0.000 |
| Sweden | 1992–2021 | 0.927 | 0.000 |
| United Kingdom | 1990–2021 | 0.927 | 0.000 |
| United States | 1990–2021 | 0.853 | 0.000 |
Note: The  -value is for testing whether a correlation coefficient is significantly different from zero.
-value is for testing whether a correlation coefficient is significantly different from zero.
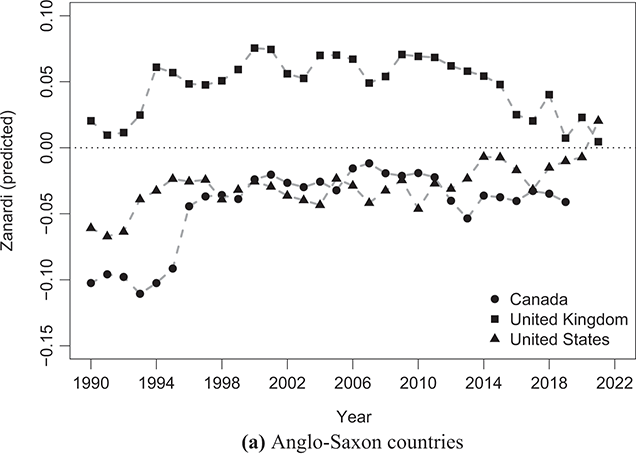
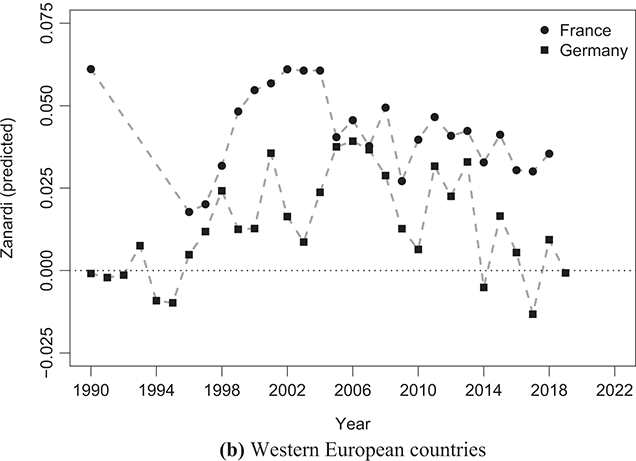
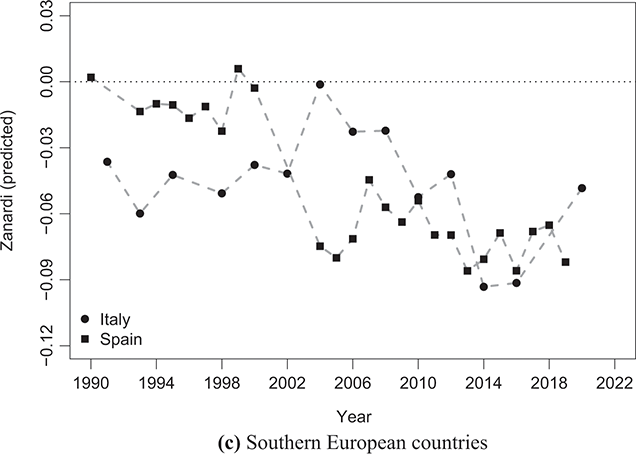
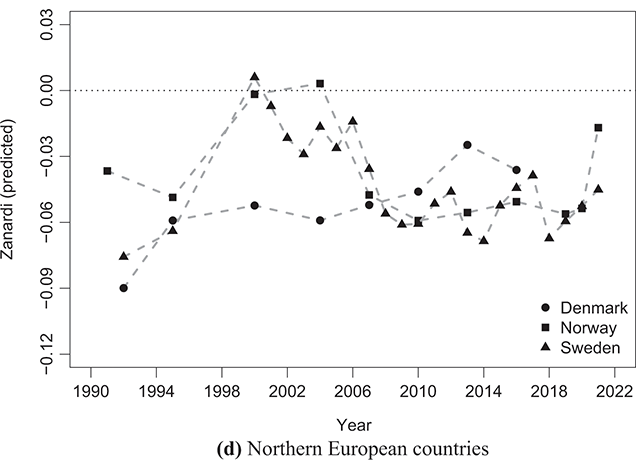
Figure 4.7 The Zanardi asymmetry index based on the κ-generalized model
Note: The horizontal line represents the zero reference line for the Zanardi index.
4.2 Comparison of Alternative Income Parametric Models
In this section, we present comparisons of the performance between the κ-generalized distribution and other parametric models introduced in existing literature. Specifically, we evaluate the κ-generalized model’s ability to approximate empirical income distributions against the three-parameter Singh–Maddala (Singh & Maddala, Reference Singh and Maddala1976) and Dagum type I (Dagum, Reference Dagum1977) functional forms. These models are characterized, respectively, by the following probability densities
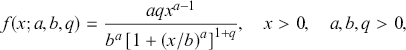 (4.3)
(4.3)
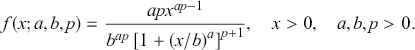 (4.4)
(4.4)
Kleiber and Kotz (Reference Kleiber and Kotz2003) offer analytical expressions for distribution functions, moments, and tools for inequality measurement, such as the Lorenz curve and the Gini coefficient. Additionally, Chotikapanich, Griffiths, Hajargasht, Karunarathne, and Rao (Reference Chotikapanich, Griffiths, Hajargasht, Karunarathne and Rao2018) and Jenkins (Reference Jenkins2009) provide formulas for generalized entropy measures of the GB2 distribution, from which the Singh–Maddala and Dagum versions can be readily derived.Footnote 20
Our comparisons involve all country datasets included in the LIS Database after the March 2024 update, except for those that are excluded from the calculation of LIS Inequality and Poverty Key Figures. The total number of income distributions considered amounts to 858. For space reasons, maximum likelihood estimates for the parameters of the three models under consideration are not presented here but are available upon request.
Given that a “good” model of income distribution should not only accurately capture the shape of empirical distributions but also closely align with them in a manner consistent with economic welfare considerations, we assess the performance of the three scrutinized models by analyzing the accuracy of selected distributional statistics implied by parameter estimates. These statistics include: the mean; the Gini index,  ; the mean logarithmic deviation,
; the mean logarithmic deviation,  ; the Theil index,
; the Theil index,  ; the Atkinson index with the inequality aversion parameter set to 1,
; the Atkinson index with the inequality aversion parameter set to 1,  . For each examined model, the accuracy of predictions regarding these statistics is determined by computing the absolute percentage error using the formula
. For each examined model, the accuracy of predictions regarding these statistics is determined by computing the absolute percentage error using the formula
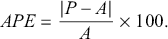 (4.5)
(4.5)
Here,  represents the predicted values and
represents the predicted values and  represents the actual sample estimates.
represents the actual sample estimates.
The results are summarized in Figure 4.8, which illustrates the percentage of cases where each model achieves the lowest  for the distributional statistics under consideration. The κ-generalized distribution consistently exhibits a closer match between implied and sample estimates of the mean compared to the Singh–Maddala and Dagum type I models. Conversely, the Gini coefficient estimates are often more accurate for the latter models than for the competing κ-generalized distribution. Therefore, while the estimation procedure of the κ-generalized parameters appears to have generally preserved the mean characteristic across most analyzed country datasets, it has often poorly modeled intra- and/or inter-group variation. However, when examining income disparities across different parts of the income distribution, the κ-generalized model yields relatively more accurate estimates than its competitors for the mean logarithmic deviation, the Theil index, and the Atkinson inequality measure
for the distributional statistics under consideration. The κ-generalized distribution consistently exhibits a closer match between implied and sample estimates of the mean compared to the Singh–Maddala and Dagum type I models. Conversely, the Gini coefficient estimates are often more accurate for the latter models than for the competing κ-generalized distribution. Therefore, while the estimation procedure of the κ-generalized parameters appears to have generally preserved the mean characteristic across most analyzed country datasets, it has often poorly modeled intra- and/or inter-group variation. However, when examining income disparities across different parts of the income distribution, the κ-generalized model yields relatively more accurate estimates than its competitors for the mean logarithmic deviation, the Theil index, and the Atkinson inequality measure  . Given that the
. Given that the  index is sensitive to differences in middle incomes, while the
index is sensitive to differences in middle incomes, while the  and
and  indices are more attuned to variations at the upper and lower ends of the income distribution respectively, these findings consistently support the κ-generalized model’s closest approximation to the income distribution shape in a significant number of cases.
indices are more attuned to variations at the upper and lower ends of the income distribution respectively, these findings consistently support the κ-generalized model’s closest approximation to the income distribution shape in a significant number of cases.
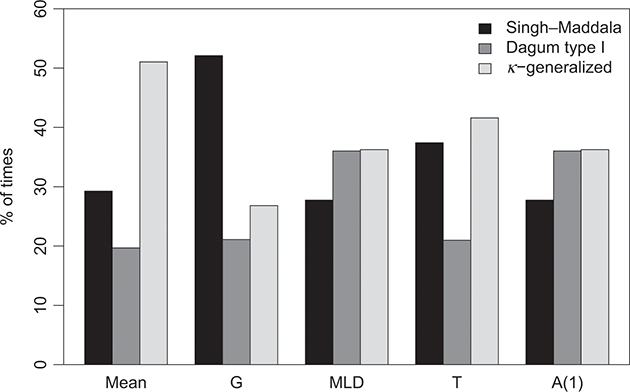
Figure 4.8 Percentage of occurrences in which the Singh–Maddala, Dagum type I and κ-generalized models achieve the lowest absolute percentage error between predicted values for key distributional summary measures and their sample counterparts
5 Conclusion
The κ-generalized distribution model was originally proposed by Kaniadakis (Reference Kaniadakis2001) within the context of developing a relativistic interpretation of statistical mechanics for kinetic particles. Since then, it has garnered significant attention in the field of economics, particularly through the works of Clementi et al. (Reference Clementi, Gallegati and Kaniadakis2007, Reference Clementi, Di Matteo, Gallegati and Kaniadakis2008, Reference Clementi, Gallegati and Kaniadakis2009, Reference Clementi, Gallegati and Kaniadakis2010, Reference Clementi, Gallegati and Kaniadakis2012a, Reference Clementi, Gallegati and Kaniadakis2012b). Notably, in the realm of income and wealth distribution analysis, Clementi and Gallegati (Reference Clementi and Gallegati2016) provide a comprehensive reference on this topic.
This probabilistic model defines a new family of distributions characterized by some real parameters  , indicated by
, indicated by  . It includes either the exponential family
. It includes either the exponential family  and the power-law family
and the power-law family  . It grasps either concentration phenomena about the expected value and inequality induced by the tails. This is due to the fact that, beyond numerical transformations of data, this model is based on functional deformations of the limited and finite support
. It grasps either concentration phenomena about the expected value and inequality induced by the tails. This is due to the fact that, beyond numerical transformations of data, this model is based on functional deformations of the limited and finite support  of a positive and transferable quantity for which the probability field is not isotropic. Differently said, for a given positive-transferable quantity
of a positive and transferable quantity for which the probability field is not isotropic. Differently said, for a given positive-transferable quantity  and a finite sample
and a finite sample  of
of  observation units, this model well describes the distribution of masses
observation units, this model well describes the distribution of masses  as if their order of magnitude were able to deform the shape of the probability field
as if their order of magnitude were able to deform the shape of the probability field  mainly on the right tail, where few observations far from the expected value weigh more than the majority on the left side fairly below the mean. The κ-generalized manages such quantities that behave strangely:Footnote 21 that is, cases where below a given threshold
mainly on the right tail, where few observations far from the expected value weigh more than the majority on the left side fairly below the mean. The κ-generalized manages such quantities that behave strangely:Footnote 21 that is, cases where below a given threshold  the quantity follows the probabilistic principles of the exponential family, i.e., when
the quantity follows the probabilistic principles of the exponential family, i.e., when  , while beyond it the quantity follows the probabilistic principles of the power-law family, that is, when
, while beyond it the quantity follows the probabilistic principles of the power-law family, that is, when  .
.
The superior capability of the κ-generalized model in describing positive-transferable quantities, which arise from countless repeated interactions among diverse individuals, such as exchanging portions of a given endowment like income or wealth, stems precisely from its relativistic nature. This characteristic underscores that the probabilistic principles governing such quantities vary across their spectrum of values. This differentiation, akin to a weak analogy with Einstein’s special relativity, underpins the κ-generalized model’s ability to shape the probability landscape significantly, particularly impacting concentration and inequality measures.
Conceptually, this can be illustrated as follows: within the observation units  , those where
, those where  exhibit bosonic behavior, akin to particles not subject to an exclusion principle. Here, many different individuals may possess similar levels of wealth within the range
exhibit bosonic behavior, akin to particles not subject to an exclusion principle. Here, many different individuals may possess similar levels of wealth within the range  , implying
, implying  . Conversely, observations where
. Conversely, observations where  display fermionic behavior, adhering to an exclusion principle. In this regime, only a few individuals may attain similar levels of wealth within the interval
display fermionic behavior, adhering to an exclusion principle. In this regime, only a few individuals may attain similar levels of wealth within the interval  . Although bosonic-like incomes are prevalent while fermionic-like ones are rare, the latter typically accumulate the majority of wealth compared to the former.
. Although bosonic-like incomes are prevalent while fermionic-like ones are rare, the latter typically accumulate the majority of wealth compared to the former.
While it is commonly assumed that the scenario described above is typical, exceptions do exist. Indeed, it is a matter of record that a fermion-like recipient such as Elon Musk may possess more wealth than a boson-like individual, like many of us, and that there are generally more bosons than fermions. However, there are instances, be it in certain countries or at different times within the same country, where the rich-fermions exhibit greater heterogeneity than the poor-bosons, or vice versa.
When the fermions demonstrate greater heterogeneity in wealth compared to the poor-bosons, concentration on the affluent side of the distribution surpasses that on the impoverished side, denoted as  . This situation arises when there are more pathways to wealth than to poverty, characterizing the top-inequality scenario identifiable through the Zanardi index of inequality. Specifically, in cases where the asymmetry index of the Lorenz curve is positive,
. This situation arises when there are more pathways to wealth than to poverty, characterizing the top-inequality scenario identifiable through the Zanardi index of inequality. Specifically, in cases where the asymmetry index of the Lorenz curve is positive,  .
.
Conversely, in scenarios where the bosons are more heterogeneously impoverished than the rich-fermions are wealthy, concentration on the impoverished side of the distribution outweighs that on the affluent side, denoted as  . This circumstance occurs when there are more avenues to poverty than to wealth, delineating the bottom-inequality case discernible through the Zanardi index, which reveals a negative asymmetry,
. This circumstance occurs when there are more avenues to poverty than to wealth, delineating the bottom-inequality case discernible through the Zanardi index, which reveals a negative asymmetry,  , of the associated Lorenz curve.
, of the associated Lorenz curve.
Considering this perspective, the Zanardi asymmetry index of the Lorenz curve emerges as a fitting measure of inequality for several reasons. Firstly, the  index aligns with the econophysics interpretation of the κ-generalized probabilistic model, which capitalizes on the differentiated concentrations of bosons and fermions to effectively model distributions of positive-transferable quantities such as income and wealth. This alignment underscores its superiority over alternative models in capturing the nuances of wealth distribution.
index aligns with the econophysics interpretation of the κ-generalized probabilistic model, which capitalizes on the differentiated concentrations of bosons and fermions to effectively model distributions of positive-transferable quantities such as income and wealth. This alignment underscores its superiority over alternative models in capturing the nuances of wealth distribution.
Secondly, the  index possesses the capability to identify distributional imbalances across both space and time, a feature unmatched by any other index, including the renowned Gini index, which is confined solely to assessing the overall concentration of the distribution.
index possesses the capability to identify distributional imbalances across both space and time, a feature unmatched by any other index, including the renowned Gini index, which is confined solely to assessing the overall concentration of the distribution.
Thirdly, the  index remains robust for space-time comparisons, even in scenarios involving intersecting Lorenz curves. In contrast, traditional measures like the Gini index may yield inaccurate results in such cases, as they disregard the directional aspects of inequality stemming from imbalances in concentration between rich fermions and poor bosons.
index remains robust for space-time comparisons, even in scenarios involving intersecting Lorenz curves. In contrast, traditional measures like the Gini index may yield inaccurate results in such cases, as they disregard the directional aspects of inequality stemming from imbalances in concentration between rich fermions and poor bosons.
In conclusion, this Element presents two significant analytical findings within the framework of econophysics theory, bolstered by empirical estimates drawn from a comprehensive and up-to-date database encompassing countries worldwide across various time periods.
Firstly, this Element establishes compelling evidence supporting the suitability of the κ-generalized model for fitting distributions of strange quantities. These quantities, representing positive-transferable assets, arise from the intricate interactions among heterogeneous agents within a complex economic system, exchanging portions of their endowments. Through empirical analysis, it becomes evident that the κ-generalized effectively captures the dynamics of such distributions, offering a robust framework for understanding the underlying mechanisms.
Secondly, this Element provides clear insights into the Zanardi asymmetry index of the Lorenz curve, demonstrating its efficacy as the most appropriate measure of inequality for strange quantities such as income and wealth. By offering a comprehensive interpretation, it underscores the importance of this index in accurately quantifying and assessing the disparities within these economic quantities.
In summary, these findings not only contribute to advancing our understanding of economic systems from a physics-inspired perspective but also offer practical insights into effectively modeling and measuring the distribution and inequality of vital economic resources.
Acknowledgments
The authors gratefully acknowledge Joe Stiglitz for fruitful discussions, comments, and critiques over the last five years of cooperation or so. Opinions and comments do not involve the responsibility of IRES Piemonte.
Series Editors
Rosario Nunzio Mantegna
University of Palermo
Rosario Nunzio Mantegna is Professor of Applied Physics at the University of Palermo and an external faculty member of the Complexity Science Hub in Vienna. He is one of the pioneers of econophysics and economic networks, and he co-authored the first book on the topic (‘Introduction to Econophysics’, Cambridge, 1999).
Bikas K. Chakrabarti
Saha Institute of Nuclear Physics
Bikas K. Chakrabarti is Emeritus Professor at Saha Institute of Nuclear Physics and visiting Professor of Economics in the Indian Statistical Institute, Kolkata. He has co-authored more than two hundred papers and ten books (including ‘Econophysics of Income & Wealth Distributions’, Cambridge, 2013). In 1995, he organized a conference in Kolkata, where the term "econophysics" was first coined.
Mauro Gallegati
Polytechnic University of Marche, Ancona
Mauro Gallegati is Professor of Economics at Polytechnic University of Marche, Ancona, Ancona. He has previously held visiting scholarships at Cambridge, Stanford, MIT, Columbia, the Santa Fe Institute, the Brookings Institution, and ETH Zurich. His research includes business fluctuations, nonlinear dynamics, models of financial fragility, and heterogeneous interacting agents.
Irena Vodenska
Boston University
Irena Vodenska is Professor and Director of Finance Programs at Boston University Metropolitan College. Her research is focused on network theory and complexity science in macroeconomics, particularly the modeling of early warning indicators and systemic risk propagation throughout interconnected financial and economic networks. She is a co-editor of the book ‘Econophysics and Sociophysics: Recent Progress and Future Directions’ (Springer, 2017)
About the Series
Econophysics is a dynamic research field at the interface of physics and economics, in which analytical and computational techniques from physics are employed to study the properties of complex economic, financial, and social systems. Elements in Econophysics explores recent developments within this multidisciplinary research area and covers key topics including: big data in econophysics, financial networks, income and wealth distributions, market microstructure, stylized agent-based models, and sociophysics.




























































































