
Wat is deep learning?
Deep learning is een vorm van machine learning die computers leert om taken uit te voeren door van voorbeelden te leren, net zoals mensen dat doen. Stel je voor dat je een computer leert katten herkennen: in plaats van te vertellen dat hij moet letten op snorharen, oren en een staart, laat je duizenden foto’s van katten zien. De computer vindt zelf de gemeenschappelijke patronen en leert hoe hij een kat kan identificeren. Dat is in de kern deep learning.
In technische termen gebruikt deep learning zogenaamde "neurale netwerken", geïnspireerd op het menselijk brein. Deze netwerken bestaan uit lagen onderling verbonden knooppunten die informatie verwerken. Hoe meer lagen, hoe "dieper" het netwerk, waardoor het complexere kenmerken kan leren en geavanceerdere taken kan uitvoeren.
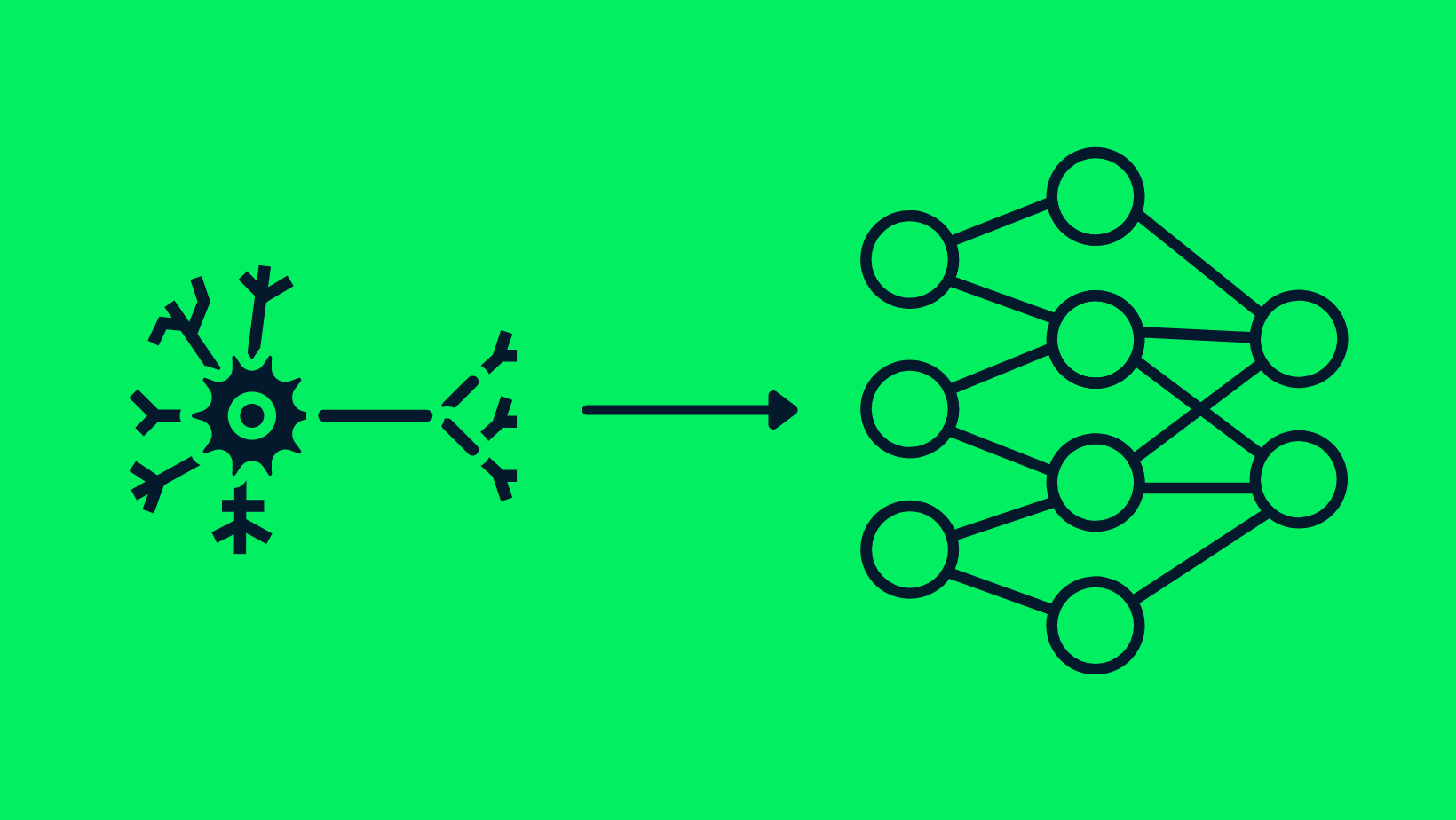
De gelijkenis tussen neuronen en neurale netwerken
De evolutie van machine learning naar deep learning
Wat is machine learning?
Machine learning is zelf een subset van kunstmatige intelligentie (AI) die computers in staat stelt te leren van data en beslissingen te nemen zonder expliciete programmering. Het omvat verschillende technieken en algoritmen waarmee systemen patronen herkennen, voorspellingen doen en hun prestaties in de loop van de tijd verbeteren. Je kunt het verschil tussen machine learning en AI verkennen in een apart artikel.
Hoe deep learning verschilt van traditionele machine learning
Hoewel machine learning op zichzelf al een baanbrekende technologie is, gaat deep learning een stap verder door veel taken te automatiseren die normaal gesproken menselijke expertise vereisen.
Deep learning is in wezen een gespecialiseerde subset van machine learning, gekenmerkt door het gebruik van neurale netwerken met drie of meer lagen. Deze neurale netwerken proberen het gedrag van het menselijk brein te simuleren—zij het lang niet op hetzelfde niveau—om te "leren" van grote hoeveelheden data. Je kunt machine learning vs. deep learning uitgebreider verkennen in een aparte post.
Het belang van feature engineering
Feature engineering is het selecteren, transformeren of creëren van de meest relevante variabelen, de zogenaamde "features", uit ruwe data voor gebruik in machinelearningmodellen.
Als je bijvoorbeeld een model voor weersvoorspelling bouwt, kan de ruwe data temperatuur, luchtvochtigheid, windsnelheid en luchtdruk bevatten. Feature engineering houdt in dat je bepaalt welke van deze variabelen het belangrijkst zijn voor de voorspelling en ze eventueel transformeert (bijv. temperatuur van Fahrenheit naar Celsius omzetten) om ze bruikbaarder te maken voor het model.
In traditionele machine learning is feature engineering vaak een handmatig en tijdrovend proces dat domeinkennis vereist. Een van de voordelen van deep learning is echter dat het automatisch relevante features kan leren uit ruwe data, waardoor minder handmatige tussenkomst nodig is.
Waarom is deep learning belangrijk?
Waarom deep learning de industriestandaard is geworden:
- On gestructureerde data verwerken: Modellen die getraind zijn op gestructureerde data kunnen gemakkelijk leren van ongestructureerde data, wat tijd en middelen bespaart bij het standaardiseren van datasets.
- Grote hoeveelheden data verwerken: Dankzij de opkomst van graphics processing units (GPU’s) kunnen deep learning-modellen enorme hoeveelheden data razendsnel verwerken.
- Hoge nauwkeurigheid: Deep learning-modellen leveren de meest nauwkeurige resultaten in computer vision, natural language processing (NLP) en audioprocessing.
- Patroonherkenning: De meeste modellen vereisen tussenkomst van een machine learning engineer, maar deep learning-modellen kunnen allerlei patronen automatisch detecteren.
In deze tutorial duiken we in de wereld van deep learning en ontdekken we alle kernbegrippen die je nodig hebt om een carrière in kunstmatige intelligentie (AI) te starten. Wil je met praktische oefeningen aan de slag, bekijk dan onze cursus An Introduction to Deep Learning in Python.
Kernconcepten van deep learning
Voordat je je verdiept in de finesses van deep learning-algoritmen en hun toepassingen, is het essentieel om de basisconcepten te begrijpen die deze technologie zo revolutionair maken. In deze sectie maak je kennis met de bouwstenen van deep learning: neurale netwerken, diepe neurale netwerken en activatiefuncties.
Neurale netwerken
Het hart van deep learning wordt gevormd door neurale netwerken, computationele modellen die zijn geïnspireerd op het menselijk brein. Deze netwerken bestaan uit onderling verbonden knooppunten, of "neuronen", die samenwerken om informatie te verwerken en beslissingen te nemen. Net zoals ons brein verschillende gebieden heeft voor verschillende taken, heeft een neuraal netwerk lagen met specifieke functies.
We hebben een volledige gids, Wat zijn neurale netwerken, die de basis in meer detail behandelt.
Diepe neurale netwerken
Wat een neuraal netwerk "diep" maakt, is het aantal lagen tussen de input en de output. Een diep neuraal netwerk heeft meerdere lagen, waardoor het complexere kenmerken kan leren en nauwkeurigere voorspellingen kan doen. De "diepte" van deze netwerken geeft deep learning zijn naam en zijn kracht om ingewikkelde problemen op te lossen.
Onze tutorial introduction to deep neural networks behandelt het belang van DNN’s in deep learning en kunstmatige intelligentie.
Activatiefuncties
In een neuraal netwerk zijn activatiefuncties de besluitnemers. Ze bepalen welke informatie moet worden doorgegeven aan de volgende laag. Deze functies voegen complexiteit toe en stellen het netwerk in staat van data te leren en genuanceerde beslissingen te nemen.
Hoe deep learning werkt
Deep learning gebruikt feature-extractie om vergelijkbare kenmerken van hetzelfde label te herkennen en gebruikt vervolgens beslissingsgrenzen om te bepalen welke kenmerken elk label het best vertegenwoordigen. Bij de classificatie van katten en honden extraheert het model informatie zoals ogen, gezicht en lichaamsvorm van dieren en verdeelt die in twee klassen.
Het deep learning-model bestaat uit diepe neurale netwerken. Het eenvoudige neurale netwerk bestaat uit een inputlaag, een verborgen laag en een outputlaag. Deep learning-modellen bestaan uit meerdere verborgen lagen; met extra lagen neemt de nauwkeurigheid van het model toe.
 Eenvoudig neuraal netwerk
Eenvoudig neuraal netwerk
De inputlagen bevatten ruwe data en geven die door aan de knooppunten van de verborgen lagen. De knooppunten van de verborgen lagen classificeren de datapunten op basis van brede doelinformatie, en met elke volgende laag wordt de scope van de doelwaarde verder aangescherpt om nauwkeurige aannames te produceren. De outputlaag gebruikt de informatie uit de verborgen lagen om het meest waarschijnlijke label te kiezen. In ons geval: correct voorspellen dat het om een hondenafbeelding gaat in plaats van een kat.
Kunstmatige intelligentie vs. deep learning
Laten we een van de meest gestelde vragen op internet beantwoorden: "Is deep learning kunstmatige intelligentie?" Het korte antwoord is ja. Deep learning is een subset van machine learning, en machine learning is een subset van AI.
 AI vs. ML vs. DL
AI vs. ML vs. DL
Kunstmatige intelligentie is het idee dat intelligente machines gebouwd kunnen worden die menselijk gedrag nabootsen of menselijke intelligentie overtreffen. AI gebruikt machine learning- en deep learning-methoden om menselijke taken uit te voeren. Kort gezegd: AI omvat deep learning, omdat dat de meest geavanceerde algoritmen biedt die in staat zijn tot intelligente beslissingen.
Waar wordt deep learning voor gebruikt?
De technologiesector heeft recent een golf aan AI-toepassingen gezien, en die worden allemaal aangedreven door deep learning-modellen. De toepassingen variëren van filmaanbevelingen op Netflix tot beheersystemen in Amazon-magazijnen.
In deze sectie bekijken we enkele van de bekendste toepassingen die met deep learning zijn gebouwd. Zo krijg je een beeld van het volledige potentieel van diepe neurale netwerken.
Computer Vision
Computer vision (CV) wordt in zelfrijdende auto’s gebruikt om objecten te detecteren en botsingen te vermijden. Het wordt ook ingezet voor gezichtsherkenning, pose-estimatie, beeldclassificatie en anomaliedetectie.
 Gezichtsherkenning
Gezichtsherkenning
Automatic Speech Recognition
Automatic speech recognition (ASR) wordt wereldwijd door miljarden mensen gebruikt. Het zit in onze telefoons en wordt vaak geactiveerd met "Hey, Google" of "Hi, Siri." Dergelijke audio-applicaties worden ook gebruikt voor tekst-naar-spraak, audioclassificatie en voice activity detection.
 Herkenning van spraakpatronen
Herkenning van spraakpatronen
Generative AI
Generatieve AI kent een enorme vraag, omdat CryptoPunk NFT zojuist voor $1 miljoen is verkocht. CryptoPunk is een collectie generatieve kunst die is gemaakt met deep learning-modellen. De introductie van het GPT-4-model door OpenAI heeft het domein van tekstgeneratie revolutionair veranderd met de krachtige ChatGPT-tool; je kunt modellen nu een hele roman laten schrijven of zelfs code laten schrijven voor je data science-projecten.
 Generatieve kunst
Generatieve kunst
Vertaling
Deep learning-vertaling is niet beperkt tot taalvertaling, want we kunnen nu foto’s naar tekst vertalen met OCR, of tekst naar afbeeldingen met NVIDIA’s GauGAN2 .
 Taalvertaling
Taalvertaling
Voorspellen met tijdreeksen
Voorspellen met tijdreeksen wordt gebruikt om beurscrashes, aandelenkoersen en weersveranderingen te voorspellen. De financiële sector drijft op speculatie en toekomstprojecties. Deep learning- en tijdreeksmodellen zijn beter dan mensen in het detecteren van patronen en zijn daarom cruciale tools in deze en vergelijkbare sectoren.
 Voorspelling met tijdreeksen
Voorspelling met tijdreeksen
Automatisering
Deep learning wordt gebruikt om taken te automatiseren, bijvoorbeeld het trainen van robots voor magazijnbeheer. De bekendste toepassing is het spelen van videogames en steeds beter worden in het oplossen van puzzels. Onlangs versloeg OpenAI’s Dota AI het profteam OG, wat de wereld verraste omdat niemand verwachtte dat alle vijf bots de wereldkampioenen zouden overtroeven.
 Robotarm aangestuurd door reinforcement learning
Robotarm aangestuurd door reinforcement learning
Klantfeedback
Deep learning wordt gebruikt voor het afhandelen van feedback en klachten van klanten. Het wordt in elke chatbot toegepast om naadloze klantenservice te bieden.
 Klantfeedback
Klantfeedback
Biomedisch
Deze sector heeft het meest geprofiteerd van de komst van deep learning. DL wordt in de biogeneeskunde gebruikt om kanker te detecteren, stabiele medicijnen te ontwikkelen, anomalieën op röntgenfoto’s van de borstkas op te sporen en medische apparatuur te ondersteunen.
 Analyseren van DNA-sequenties
Analyseren van DNA-sequenties
Deep learning-modellen
Laten we de verschillende soorten deep learning-modellen en hoe ze werken doornemen.
Supervised learning
Supervised learning gebruikt een gelabelde dataset om modellen te trainen om data te classificeren of waarden te voorspellen. De dataset bevat features en doel-labels, waarmee het algoritme kan leren door in de tijd het verlies tussen voorspelde en werkelijke labels te minimaliseren. Supervised learning is onder te verdelen in classificatie- en regressieproblemen.
Classificatie
Het classificatie-algoritme verdeelt de dataset in verschillende categorieën op basis van feature-extracties. Populaire deep learning-modellen zijn ResNet50 voor beeldclassificatie en BERT (taalmodel)) voor tekstclassificatie.
 Classificatie
Classificatie
Regressie
In plaats van de dataset in categorieën te verdelen, leert het regressiemodel de relatie tussen input- en outputvariabelen om de uitkomst te voorspellen. Regressiemodellen worden vaak gebruikt voor voorspellende analyses, weersvoorspelling en het voorspellen van beursresultaten. LSTM en RNN zijn populaire deep learning-regressiemodellen.
 Lineaire regressie
Lineaire regressie
Unsupervised learning
Unsupervised learning-algoritmen leren patronen binnen een ongelabelde dataset en maken clusters. Deep learning-modellen kunnen verborgen patronen leren zonder menselijke tussenkomst en worden vaak ingezet in aanbevelingssystemen.
Unsupervised learning wordt gebruikt voor het groeperen van soorten, medische beeldvorming en marktonderzoek. Het meest gebruikte deep learning-model voor clusteren is het deep embedded clustering-algoritme.
 Clustering van data
Clustering van data
Reinforcement learning
Reinforcement learning (RL) is een machinelearningmethode waarbij agents verschillende gedragingen leren vanuit de omgeving. Deze agent neemt willekeurige acties en krijgt beloningen. De agent leert doelen te bereiken via trial-and-error in een complexe omgeving zonder menselijke tussenkomst.
Net zoals een baby met aanmoediging van zijn ouders leert lopen, leert de AI bepaalde taken uitvoeren door beloningen te maximaliseren, waarbij de ontwerper het beloningsbeleid bepaalt. RL kent recent veel vraag in automatisering door vooruitgang in robotica, zelfrijdende auto’s, het verslaan van profspelers in games en het terug op aarde laten landen van raketten.
 Reinforcement learning-framework
Reinforcement learning-framework
Laten we de videogame Mario als voorbeeld nemen:
- Aan het begin ontvangt de agent (Mario-personage) toestand nul van de omgeving.
- Op basis van de toestand neemt de agent een actie; in ons geval bewoog Mario naar rechts.
- Nu is de toestand veranderd en staat het personage in een nieuw frame.
- De agent ontvangt een beloning, omdat het personage door naar rechts te gaan niet dood is. Ons hoofddoel is het maximaliseren van beloningen.
De agent blijft de lus van actie ondernemen en beloningen maximaliseren herhalen totdat hij het einde van het level bereikt of sterft. Leer meer in An Introduction to Reinforcement Learning.
Generative Adversarial Networks
Generative adversarial networks (GAN’s) gebruiken twee neurale netwerken en genereren samen synthetische voorbeelden van originele data. GAN’s hebben de afgelopen jaren veel populariteit gewonnen omdat ze grote kunstenaars kunnen nabootsen en meesterwerken produceren. Ze worden veel gebruikt voor het genereren van synthetische kunst, video, muziek en teksten. Leer meer over toepassingen in de echte wereld in de Generative Adversarial Networks Tutorial.
 Framework voor generative adversarial network
Framework voor generative adversarial network
Hoe GAN’s werken bij het genereren van synthetische afbeeldingen:
- Eerst nemen de generator-netwerken willekeurige ruis als input en genereren nepart afbeeldingen.
- De gegenereerde en de echte afbeeldingen worden aan de discriminator gevoerd.
- De discriminator beslist of de gegenereerde afbeelding echt is of niet. Hij geeft waarschijnlijkheden terug van nul tot één, waarbij nul een nepafbeelding is en één een authentieke afbeelding. De architectuur van GAN’s bevat twee feedbacklussen. De discriminator staat in een feedbacklus met echte afbeeldingen, terwijl de generator in een feedbacklus met de discriminator staat. Ze werken synchroon om echtere beelden te produceren.
Graph Neural Network
Een graaf is een datastructuur die bestaat uit randen en hoekpunten. De randen kunnen gericht zijn als er directionele afhankelijkheden tussen hoekpunten (nodes) bestaan, ook wel gerichte grafen genoemd. De groene cirkels in het diagram hieronder zijn knooppunten en de pijlen stellen de randen voor.
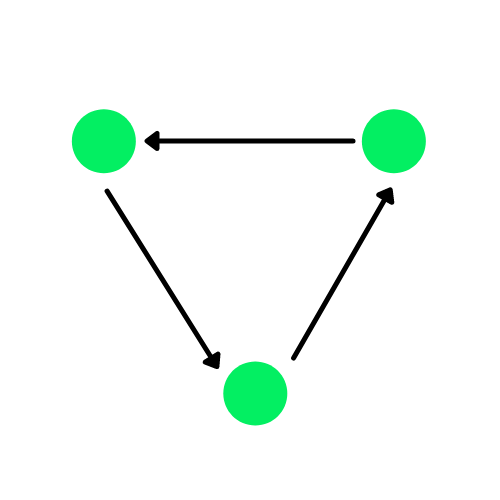
Een gerichte graaf
Een graph neural network (GNN) is een type deep learning-architectuur die direct op graafstructuren opereert. GNN’s worden toegepast in de analyse van grote datasets, aanbevelingssystemen en computer vision.
 Een graafnetwerk
Een graafnetwerk
Ze worden ook gebruikt voor nodeclassificatie, linkvoorspelling en clusteren. In sommige gevallen hebben graph neural networks beter gepresteerd dan convolutionele neurale netwerken, bijvoorbeeld bij objectherkenning en het voorspellen van semantische relaties.
Natural Language Processing
Natural language processing (NLP) gebruikt deep learning-technologie om computers te helpen een natuurlijke menselijke taal te leren. NLP gebruikt deep learning om menselijke taal te lezen, ontcijferen en begrijpen. Het wordt veel toegepast voor het verwerken van spraak, tekst en beelden. De introductie van transfer learning heeft NLP naar een hoger niveau getild, omdat we het model met enkele voorbeelden kunnen fine-tunen en state-of-the-art prestaties kunnen behalen.
 Subcategorieën van NLP
Subcategorieën van NLP
NLP is op te delen in meerdere gebieden:
- Vertaling: talen, moleculaire structuren en wiskundige vergelijkingen vertalen
- Samenvatten: grote lappen tekst in een paar regels samenvatten, met behoud van de kerninformatie.
- Classificatie: tekst in verschillende categorieën indelen.
- Generatie: tekst-naar-tekstgeneratie; kan complete essays genereren met één regel tekst.
- Conversational: virtuele assistenten, eerdere gesprekskennis behouden en menselijke gesprekken nabootsen.
- Vragen beantwoorden: AI beantwoordt vragen met Q&A-data.
- Feature-extractie: patronen in tekst detecteren of informatie extraheren, zoals "named entity recognition" en "woordsoort".
- Zinsgelijkenis: overeenkomsten tussen verschillende teksten evalueren.
- Tekst-naar-spraak: tekst omzetten naar hoorbare spraak.
- Automatic speech recognition: verschillende geluiden begrijpen en omzetten naar tekst.
- Optical character recognition: tekstdata uit afbeeldingen extraheren.
Wil je alle verschillende NLP-toepassingen testen, probeer dan Hugging Face Spaces. Spaces host allerlei webapplicaties waar je mee kunt spelen om inspiratie op te doen voor je NLP-project.
Een diepere kijk op deep learning-concepten
Activatiefuncties
In neurale netwerken levert de activatiefunctie output-beslissingsgrenzen op en wordt ze gebruikt om de prestaties van het model te verbeteren. De activatiefunctie is een wiskundige uitdrukking die beslist of de input door een neuron moet worden doorgegeven, op basis van de relevantie. Ze introduceert ook non-lineariteit in netwerken. Zonder activatiefunctie wordt het neuraal netwerk een eenvoudig lineair regressiemodel.
Er zijn verschillende soorten activatiefuncties:
- Tanh
- ReLU
- Sigmoid
- Lineair
- Softmax
- Swish
 Activatiefunctie
Activatiefunctie
Deze functies produceren verschillende outputgrenzen, zoals in de afbeelding hierboven. Met meerdere lagen en activatiefuncties kun je elk complex probleem oplossen. Leer meer over wat activatiefuncties in deep learning zijn.
Verliesfunctie
De verliesfunctie is het verschil tussen werkelijke en voorspelde waarden. Hiermee kunnen neurale netwerken de algehele prestatie van het model volgen. Afhankelijk van het specifieke probleem kiezen we een bepaald type functie, bijvoorbeeld de mean squared error.
Loss = Som (Voorspeld - Werkelijk)²
De meest gebruikte verliesfuncties in deep learning zijn:
- Binaire kruis-entropie
- Categorische hinge
- Mean squared error
- Huber
- Sparse categorical cross-entropy
Backpropagation
Bij forward propagation initialiseren we ons neuraal netwerk met willekeurige inputs om een eveneens willekeurige output te produceren. Om ons model beter te laten presteren, passen we gewichten willekeurig aan via backpropagation. Om de prestaties van het model te volgen, hebben we een verliesfunctie nodig die het globale minimum vindt om de nauwkeurigheid te maximaliseren.
Stochastic gradient descent
Gradient descent wordt gebruikt om de verliesfunctie te optimaliseren door gewichten op een gecontroleerde manier te wijzigen om minimaal verlies te bereiken. We hebben nu een doel, maar we hebben richting nodig: moeten we de gewichten vergroten of verkleinen voor betere prestaties? De afgeleide van de verliesfunctie geeft ons richting, en die kunnen we gebruiken om de gewichten van het netwerk te updaten.
 Gradient descent
Gradient descent
De onderstaande vergelijking laat zien hoe gewichten met gradient descent worden bijgewerkt.
w = w -Jw
Bij stochastic gradient descent worden samples in batches verdeeld in plaats van de volledige dataset te gebruiken om gradient descent te optimaliseren. Dit is handig als je sneller een minimaal verlies wilt bereiken en rekenkracht wilt optimaliseren.
Hyperparameter
Hyperparameters zijn afstembare parameters die worden aangepast vóór de training. Deze parameters hebben directe invloed op de modelprestatie en helpen je sneller een globaal minimum te bereiken.
Lijst met meest gebruikte hyperparameters:
- Learning rate: stapgrootte per iteratie en kan worden ingesteld van 0,1 tot 0,0001. Kortom: bepaalt de snelheid waarmee het model leert.
- Batchgrootte: aantal samples dat tegelijk door een neuraal netwerk gaat.
- Aantal epochs: het aantal keren dat het model gewichten verandert. Te veel epochs kan overfitting veroorzaken en te weinig kan underfitting veroorzaken, dus we kiezen een middenweg.
Leer meer over hoe deze componenten samenwerken in de Keras Tutorial: Deep Learning in Python.
Populaire algoritmen
Convolutional neural networks
Het convolutional neural network (CNN) is een feedforward neuraal netwerk dat een gestructureerde array aan data kan verwerken. Het wordt veel gebruikt voor computer vision-toepassingen zoals beeldclassificatie.
 Architectuur van convolutioneel neuraal netwerk
Architectuur van convolutioneel neuraal netwerk
CNN’s zijn goed in het herkennen van patronen, lijnen en vormen. Het CNN bestaat uit een convolutionele laag, een pooling-laag en een outputlaag (volledig verbonden lagen). Modellen voor beeldclassificatie bevatten doorgaans meerdere convolutionele lagen, gevolgd door pooling-lagen, omdat extra lagen de nauwkeurigheid verhogen. Leer meer over convolutionele lagen hier: Convolutional Neural Networks in Python.
Recurrent neural networks
Recurrent neural networks (RNN) verschillen van feedforward-netwerken doordat de output van de laag wordt teruggevoerd naar de input om de output van de laag te voorspellen. Dit helpt bij sequentiële data, omdat het informatie van vorige samples kan opslaan om toekomstige samples te voorspellen. Leer meer in de Recurrent Neural Network (RNN) Tutorial: Types & Examples.
 Architectuur van recurrent neuraal netwerk
Architectuur van recurrent neuraal netwerk
In traditionele neurale netwerken wordt de output van de lagen berekend op basis van de huidige inputwaarden, maar in RNN’s wordt de output ook op basis van voorgaande inputs berekend. Daardoor zijn ze goed in het voorspellen van het volgende woord, het voorspellen van aandelenkoersen, in AI-chatbots en bij anomaliedetectie.
Long short-term memory-netwerken
Long short-term memory-netwerken (LSTM) zijn geavanceerde varianten van recurrente neurale netwerken die meer informatie over eerdere waarden kunnen vasthouden. Ze lossen de verdwijnende-gradiëntproblemen op die in eenvoudige RNN’s voorkomen.
 LSTM-architectuur
LSTM-architectuur
De typische RNN bestaat uit herhalende neurale netwerken met één tanh-laag, terwijl LSTM uit vier interactieve lagen bestaat die samenwerken om grote sequenties data te verwerken.
Je kunt praktijkervaring opdoen met de volgende Tutorial: LSTM voor aandelenvoorspellingen of de cursus advanced deep learning with Keras als je meer wilt leren over deep learning-modellen.
Deep learning-frameworks
Er zijn meerdere deep learning-frameworks, zoals MxNet, CNTK en Caffe2, maar we behandelen de populairste frameworks.
Tensorflow
Tensorflow (TF) is een open-sourcelibrary voor het creëren van deep learning-toepassingen. Het bevat alle benodigde tools om te experimenteren en commerciële AI-producten te ontwikkelen. Het ondersteunt zowel CPU, GPU als TPU voor het trainen van complexe modellen. TF is oorspronkelijk ontwikkeld door het Google AI-team voor intern gebruik en is nu publiek beschikbaar.
De Tensorflow-API is beschikbaar voor browsergebaseerde applicaties en mobiele apparaten, en TensorFlow Extended is ideaal voor productie. TF is inmiddels de industriestandaard geworden en wordt gebruikt voor zowel academisch onderzoek als het uitrollen van deep learning-modellen in productie.
TF wordt ook geleverd met Tensorboard, een dashboard dat je machinelearning-experimenten kan analyseren. Onlangs hebben Tensorflow-ontwikkelaars Keras geïntegreerd in het framework, populair voor het ontwikkelen van diepe neurale netwerken. Leer meer in de Introduction to TensorFlow in Python Course.
Keras
Keras is een neurale-netwerkenframework geschreven in Python en kan draaien op meerdere frameworks, zoals Tensorflow en Theano. Keras is een open-sourcelibrary ontwikkeld om snel te kunnen experimenteren met deep learning, zodat je concepten eenvoudig kunt omzetten in werkende AI-applicaties.
De documentatie is goed te begrijpen en de API lijkt op Numpy, waardoor je het makkelijk met elk data science-project kunt integreren. Net als TF kan Keras draaien op CPU, GPU en TPU, afhankelijk van de beschikbare hardware. Leer meer in Introduction to Deep Learning with Keras.
PyTorch
PyTorch is het populairste en eenvoudigste deep learning-framework. Het gebruikt tensors in plaats van Numpy-arrays om snelle numerieke berekeningen uit te voeren met GPU-ondersteuning. PyTorch wordt vooral gebruikt voor deep learning en het ontwikkelen van complexe machinelearningmodellen.
Academische onderzoekers geven de voorkeur aan PyTorch vanwege de flexibiliteit en het gebruiksgemak. Het is geschreven in C++ en Python en biedt ook versnelling met GPU’s en TPU’s. Het is uitgegroeid tot een one-stopoplossing voor alle deep learning-problemen. Wil je meer leren over PyTorch, volg dan de cursus Introduction to Deep Learning with PyTorch.
Conclusie
In deze tutorial hebben we behandeld wat deep learning is, enkele basisprincipes, hoe het werkt en de toepassingen ervan. We hebben ook geleerd hoe diepe neurale netwerken werken en welke verschillende soorten deep learning-modellen er zijn. Tot slot heb je kennisgemaakt met enkele populaire deep learning-frameworks.
Deze tutorial gaf je alle kerninformatie die je nodig hebt om te beginnen met deep learning. Wil je verder leren, dan bereidt de Deep Learning in Python Track je voor op projecten uit de praktijk. Je kunt ook deep learning met Keras in R bekijken als je vertrouwd bent met de programmeertaal R.

