AI engineers design, build and maintain AI powered systems that work reliably in real world applications. Their work involves integrating large language models with data pipelines, APIs and application interfaces.
The overall workflow of an AI engineer typically includes the following stages:
- Designing AI features: AI engineers first identify the problem to be solved using AI. This might involve building chatbots, assistants, search systems or automated decision tools.
- Prompt engineering: They design prompts that guide the AI model to produce accurate and useful responses.
- Building RAG pipelines: Retrieval Augmented Generation pipelines allow AI systems to retrieve relevant information from external data sources before generating answers.
- Tool integration: They integrate models with external tools such as databases, APIs, calculators or search systems to extend the model's capabilities.
- Evaluation and testing: They build evaluation systems to test model outputs and ensure the responses remain reliable over time.
- Deployment and monitoring: They deploy AI services into production environments and monitor performance, cost and reliability.
- Continuous improvement: AI systems are constantly improved by refining prompts, adjusting retrieval methods and optimizing infrastructure.
Skills Required
1. Python Programming
Python is the primary programming language used in AI development. To build a strong foundation in Python, the following topics are important:
- Introduction
- Variables
- Data Types
- Conditional Statements
- Loops
- Functions
- NumPy for Numerical Computing
- Pandas for Data Manipulation
2. Backend Development
AI systems often run as backend services that communicate with applications. Backend development allows applications to send requests to AI systems and receive responses.
- Introduction and Installation of FastAPI
- Django vs Flask vs FastAPI
- Creating REST APIs
- Handling File Uploads
- Pydantic
- Request Body
- Response Model
- Database Integration in FastAPI using MongoDB
- SQLite Integration
3. Understanding LLM APIs
Modern AI applications use LLM APIs from platforms like OpenAI to send prompts to language models and receive generated responses. AI engineers need to understand concepts such as:
- Function Calling: This allows the model to interact with external tools or services such as databases, calculators or APIs. Instead of only generating text, the model can trigger specific functions to perform tasks.
- Model Parameters: These are settings that control how the model generates responses. For example, temperature controls creativity.
- Prompt Management: This involves designing, organizing and refining prompts to ensure the LLMs produces accurate, consistent and useful responses without hallucination.
- Structured Outputs: LLMs can return responses in structured formats such as JSON which makes it easier for applications to process and use the output programmatically.
RAG Fundamentals
Retrieval Augmented Generation (RAG) is a technique used to improve the accuracy of AI systems by allowing language models to access external knowledge sources. Instead of relying only on the model’s training data, RAG systems retrieve relevant information from documents or databases before generating a response.
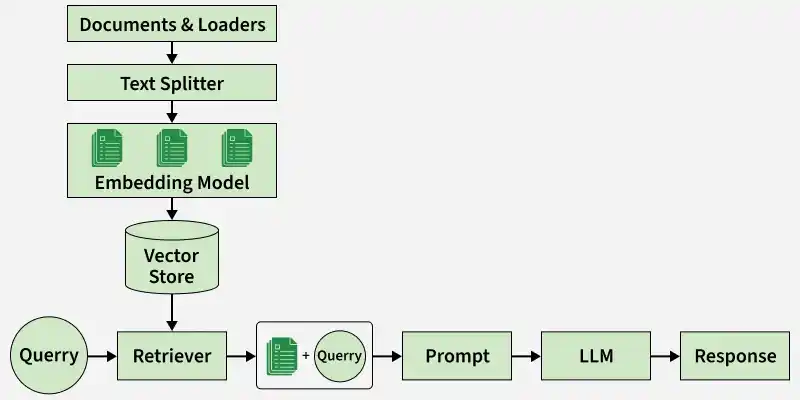
The main components of a RAG system include:
- Chunking: It is used to divide large documents into smaller sections called chunks. This makes it easier for the system to search and retrieve relevant information efficiently.
- Retrieval: When a user asks a question, the system searches the stored document chunks to find the pieces of information that are most relevant to the query using retrieval.
- Reranking: After retrieval, several candidate chunks may be returned. Reranking is the process of re-evaluating these results and ordering them based on their relevance to the query.
- Context Injection: The selected chunks are then added to the prompt that is sent to the language model. This additional context helps the model generate more accurate and informative responses.
Context Engineering
Context engineering focuses on improving how information is selected and presented to language models. Since LLMs have limited context windows, it is important to provide only the most relevant and useful information so the model can generate accurate responses.
- Query Rewriting: Modifying or expanding the user’s query to make it clearer and easier for the retrieval system to find relevant information.
- Multi stage Retrieval: Retrieving documents in multiple steps, where an initial search finds candidate documents and later stages refine the results.
- Context Filtering: Removing irrelevant or low quality information from retrieved results so that only useful content is passed to the model.
- Document Ranking: Ordering retrieved documents based on their relevance to the query to ensure the most important information is included in the final context.
- Hybrid Search: It combines keyword search, vector search and semantic ranking to retrieve both exact matches and contextually relevant results. Example: (BM25), vector search and semantic ranking.
Agent Systems
Agent systems allow AI models to perform complex tasks by planning and executing multiple steps. Instead of generating a single response, these systems can break down a task, use tools and complete workflows automatically.

These systems include components such as:
- Planners: It involves planning task steps and selecting appropriate tools like APIs, databases, or search systems to complete the task.
- Memory Systems: Store previous interactions or important information so the system can maintain context across tasks.
- Guardrails: Apply safety rules to prevent harmful outputs or unsafe actions.
Cost and Latency Optimization
Cost and latency optimization focuses on making AI systems faster while reducing operational costs. AI engineers use different techniques to reuse computations and improve system efficiency.
1. Caching: Storing previously generated results to avoid repeated computation.
- Response caching: Saves generated responses for repeated queries.
- Embedding caching: Reuses embeddings that were already computed.
- Retrieval caching: Stores retrieved results to avoid repeated searches.
2. Batching Requests: Multiple requests are processed together instead of individually, which improves efficiency and reduces computation overhead.
3. Streaming Responses: The system sends partial outputs as they are generated, allowing users to see responses faster instead of waiting for the full output.
4. Model Routing: Selecting different models based on task complexity so that simpler tasks use cheaper models while complex tasks use more powerful ones.
Evaluation Systems
Evaluation systems are important for measuring how well an AI model performs in real world applications. AI engineers use evaluation frameworks to test model outputs and identify errors:
- Creating Test Datasets: Preparing a set of example inputs and expected outputs to test how accurately the model responds to different scenarios.
- Building Grading Systems: Designing methods to automatically evaluate model responses based on criteria such as correctness, relevance or quality.
- Running Regression Testing: Re-testing the system after updates to ensure that changes do not reduce performance or introduce new errors.
AI Safety
AI safety focuses on ensuring that AI systems behave responsibly and securely. AI engineers implement safety measures to prevent misuse, protect data and reduce harmful outputs. Important safety practices include:
- Preventing Prompt Injection Attacks: Protecting the system from malicious inputs that try to override instructions or manipulate the model’s behaviour.
- Protecting Sensitive Data: Ensuring the AI system does not expose private or confidential information by applying secure data handling and access controls.
- Content Moderation: Detecting and filtering harmful, unsafe or inappropriate outputs generated by the model.
- Red Teaming: It involves testing the system by simulating attacks or misuse to identify weaknesses and improve safety mechanisms.
Deployment
AI engineers must understand how to deploy AI systems so they can run reliably in real world applications. Deployment involves packaging applications, automating updates and monitoring system performance.
- Containers: Tools like Docker are used to package applications and their dependencies so they run consistently across different environments.
- CI/CD Pipelines: Continuous Integration and Continuous Deployment automate testing, building and deployment, allowing updates to be released quickly and safely.
- Cloud Platforms: AI applications are commonly deployed on cloud services like AWS, Google Cloud Platform (GCP) and Microsoft Azure which provide scalable infrastructure.
- Monitoring Systems: Monitoring tools such as Prometheus and Grafana track system performance, including latency, error rates and infrastructure health, to ensure the AI service runs smoothly.
Fields in AI Engineering
AI engineering is used across many industries to build intelligent systems that automate tasks, improve productivity and support better decision making.
- AI Assistants: Systems that help users with tasks such as writing, research, scheduling and information retrieval.
- Customer Support Automation: AI chatbots that handle customer queries, provide instant responses and reduce support workload.
- Knowledge Retrieval Systems: AI tools that search internal documents or databases and provide accurate answers.
- Content Generation: AI applications that assist in writing, summarizing and generating reports or marketing content.
- Developer Productivity Tools: AI powered coding assistants that help developers write, debug and understand code more efficiently.