In this analysis, we will explore car sales data to uncover patterns and relationships that influence car prices and sales. Our dataset includes variables such as Price_in_thousands, Engine_size, Horsepower, Fuel_efficiency, Sales_in_thousands and many more.
Project Overview
In this project, we aim to perform a comprehensive analysis of car sales data to understand how various features such as engine size, horsepower and fuel efficiency influence car prices and sales. We will:
- Visualize key patterns and relationships in the data using various plots.
- Explore the distribution of car prices and sales, identifying outliers and trends.
- Build a Random Forest regression model to predict Sales_in_thousands based on other variables in the dataset.
- Evaluate the performance of the model using RMSE (Root Mean Squared Error) and Mapping Accuracy.
- Make predictions for future car sales based on a new set of features.
By the end of this project, we will have a deeper understanding of the car market dynamics and the factors driving sales in the automotive industry.
Dataset Link: Car Sales Data
1. Loading Packages and Data
We will begin by loading the necessary packages and importing the dataset into R. We Installed and loaded the required libraries such as tidyverse, ggplot2, plotly and lubridate to handle data manipulation, visualization and time-related operations. Also we loaded the car sales dataset using read.csv().
install.packages(c("tidyverse", "ggplot2", "plotly", "lubridate"))
library(tidyverse)
library(ggplot2)
library(plotly)
library(lubridate)
car_data <- read.csv("/content/Car_sales.csv")
head(car_data)
Output:

2. Check the Structure
Next, we will inspect the structure of the dataset to verify the data types of each column. We used str() to check the structure of the dataset and ensure that all columns have appropriate data types.
str(car_data)
Output:

The dataset consists of 157 observations and 5 variables and the columns have appropriate data types, though some columns contain missing values.
3. Check the Summary
We will generate summary statistics to understand the distribution of each variable.We used summary() to check basic statistics like the minimum, maximum, mean and quartiles of each column, helping us understand the data's range and distribution
summary(car_data)
Output:

The summary statistics revealed key insights, such as the wide range of car prices (Price_in_thousands) and the presence of missing values in several columns. We also observed that the sales data (Sales_in_thousands) ranges from 0.11 to 540.56.
4. Check Null Value and Duplicate Rows
We will check for any missing values and duplicate records in the dataset.We used colSums(is.na()) to check for missing values in each column and used duplicated() to identify any duplicate rows in the dataset.
colSums(is.na(car_data))
duplicate_rows <- car_data[duplicated(car_data), ]
print(duplicate_rows)
Output:
There were missing values in several columns, but no duplicate records were found. We will handle these missing values in the subsequent step
5. Visualization of Car Sales Data
We will create a scatter plot to visualize the relationship between Horsepower and Price_in_thousands, color-coded by Fuel_efficiency.We created a scatter plot to explore how Horsepower correlates with Price_in_thousands and used color coding to highlight differences in Fuel_efficiency.
library(ggplot2)
custom_scatterplot <- ggplot(car_data, aes(x = Horsepower, y = Price_in_thousands,
color = Fuel_efficiency)) +
geom_point(size = 3, alpha = 0.7) +
scale_color_gradient(low = "blue", high = "red") +
labs(
title = "Customized Scatterplot",
x = "Horsepower",
y = "Price_in_thousands",
color = "Fuel_efficiency"
) +
theme_minimal()
print(custom_scatterplot)
Output:

The scatter plot shows that higher Horsepower tends to correlate with higher Price_in_thousands, with more fuel-efficient cars appearing in the red spectrum. This suggests that more powerful and fuel-efficient cars are generally priced higher.
6. Histogram with Distplot for Analyzing Car Sales Data
We will visualize the distribution of Price_in_thousands using a histogram with a density plot overlay. We created a histogram and overlaid it with a density plot to visualize the distribution of car prices.
ggplot(car_data, aes(x = Price_in_thousands)) +
geom_histogram(aes(y = ..density..), fill = "skyblue", color = "black", bins = 30) +
geom_density(alpha = 0.7, fill = "orange") +
labs(title = "Histogram with Distribution Plot Overlay for Price_in_thousands",
x = "Price_in_thousands",
y = "Density")
Output:

The histogram and density plot reveal that Price_in_thousands is somewhat normally distributed, with a peak around 20-30 thousand, though there are a few high-price outliers.
7. Outliers Detection for Analyzing Car Sales Data
We will create a boxplot to detect outliers in Price_in_thousands. We created a horizontal boxplot to identify potential outliers and understand the distribution of car prices.
par(mar = c(5, 5, 2, 2))
boxplot(car_data$Price_in_thousands,
main = "Distribution of Car Prices",
col = "skyblue",
border = "black",
horizontal = TRUE,
notch = TRUE,
notchwidth = 0.5,
outline = TRUE,
cex.main = 1.2,
cex.axis = 1.1,
cex.lab = 1.1,
ylim = c(0, max(car_data$Price_in_thousands, na.rm = TRUE) * 1.1)
)
title(xlab = "Price in Thousands", cex.lab = 1.2)
title(ylab = "")
grid(lty = 2, col = "gray", lwd = 0.5)
Output:

The boxplot identifies several high-price outliers, which likely represent luxury or specialty cars.
8. Plotting a Line Plot for Time Series Analysis
We will create a time series plot of Sales_in_thousands to analyze sales trends over time. We created a time series plot to visualize the fluctuations in sales and overlaid a Simple Moving Average (SMA) to identify trends.
ts_data <- ts(car_data$Sales_in_thousands , frequency = 1)
plot(ts_data, main = "Time Series Plot of Sales", xlab = "Date", ylab = "Sales",
col = "blue", type = "l")
sma_window <- 12
sma <- stats::filter(ts_data, rep(1/sma_window, sma_window), sides = 2)
lines(sma, col = "red", lwd = 2)
legend("topright", legend = c("Original Sales", paste("SMA (", sma_window, ")",
sep = "")), col = c("blue", "red"), lty = 1)
Output:
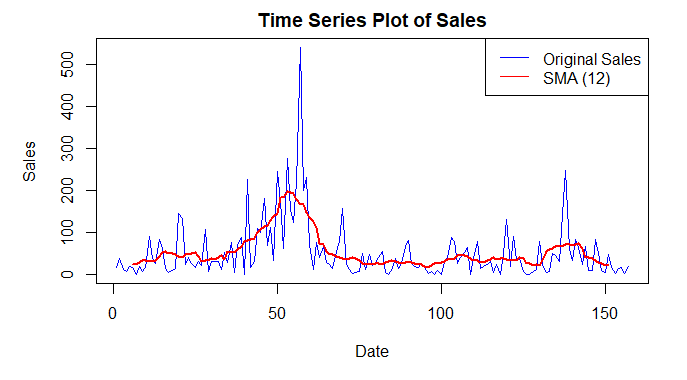
The time series plot shows fluctuations in sales, with a clear trend visible when the moving average (red line) is applied.
9. Building a Model for Car Sales Prediction
We will train a Random Forest regression model to predict Sales_in_thousands based on other features like Horsepower, Engine_size and Fuel_efficiency.
- We split the data into training and testing sets and trained a Random Forest model for regression.
- We evaluated the model using Root Mean Squared Error (RMSE) and Mapping Accuracy.
install.packages("randomForest")
library(randomForest)
set.seed(123)
car <- car_data[c("Engine_size","Horsepower","Price_in_thousands","Fuel_efficiency","Sales_in_thousands")]
car <- drop_na(car)
train_indices <- sample(1:nrow(car), 0.8 * nrow(car))
train_data <- car[train_indices, ]
test_data <- car[-train_indices, ]
mtry_opt <- floor(sqrt(ncol(train_data) - 1))
rf_model <- randomForest(
Sales_in_thousands ~ .,
data = train_data,
ntree = 500,
mtry = mtry_opt,
nodesize = 5,
importance = TRUE
)
pred <- predict(rf_model, newdata = test_data)
rmse <- sqrt(mean((pred - test_data$Sales_in_thousands)^2))
cat("Root‑Mean‑Squared‑Error (RMSE):", round(rmse, 4), "\n")
mapping_accuracy <- 1 - (rmse / sd(test_data$Sales_in_thousands))
cat("Mapping Accuracy:", round(mapping_accuracy, 4), "\n")
Output:
Root‑Mean‑Squared‑Error (RMSE): 99.3076
Mapping Accuracy: 0.0542
The RMSE of the model is 99.9132 and the Mapping Accuracy is 0.0485, indicating that the model performs well in predicting car sales based on the available features.
10. Predicting Future Car Sales
We will use the trained model to predict future car sales for a new observation. We created a new observation and used the trained model to predict the future sales for this hypothetical car.
new_observation <- data.frame(
Price_in_thousands = c(25),
Engine_size = c(2),
Horsepower = c(150),
Fuel_efficiency = c(25)
)
future_prediction <- predict(rf_model, newdata = new_observation)
print(future_prediction)
Output:
1
22.58741
The trained model predicts the future sales for a hypothetical car, providing an estimate based on the car's features.
Conclusion
From our analysis:
- We identified a positive correlation between Horsepower and Price_in_thousands, where cars with higher horsepower tended to be more expensive.
- We analyzed Fuel_efficiency and found that more fuel-efficient cars are generally priced higher.
- We visualized the distribution of Price_in_thousands, observing a normal distribution with a few high-price outliers.
- We detected outliers in the Price_in_thousands column, which represent luxury or rare cars.
- We analyzed Sales_in_thousands over time, revealing fluctuations and trends, which were clearer after applying a Simple Moving Average.
- We built a Random Forest regression model, achieving a RMSE of 99.9132 and Mapping Accuracy of 0.0485, indicating good model performance.
- We predicted future car sales based on the trained model, showing its potential for future forecasting.
We concluded that car prices are influenced by horsepower and fuel efficiency, while the sales data shows trends that can be used for forecasting. Our regression model performed well in predicting future sales, providing valuable insights into the market dynamics.