
Program
Dasar-Dasar Kecerdasan Buatan
10 Hr
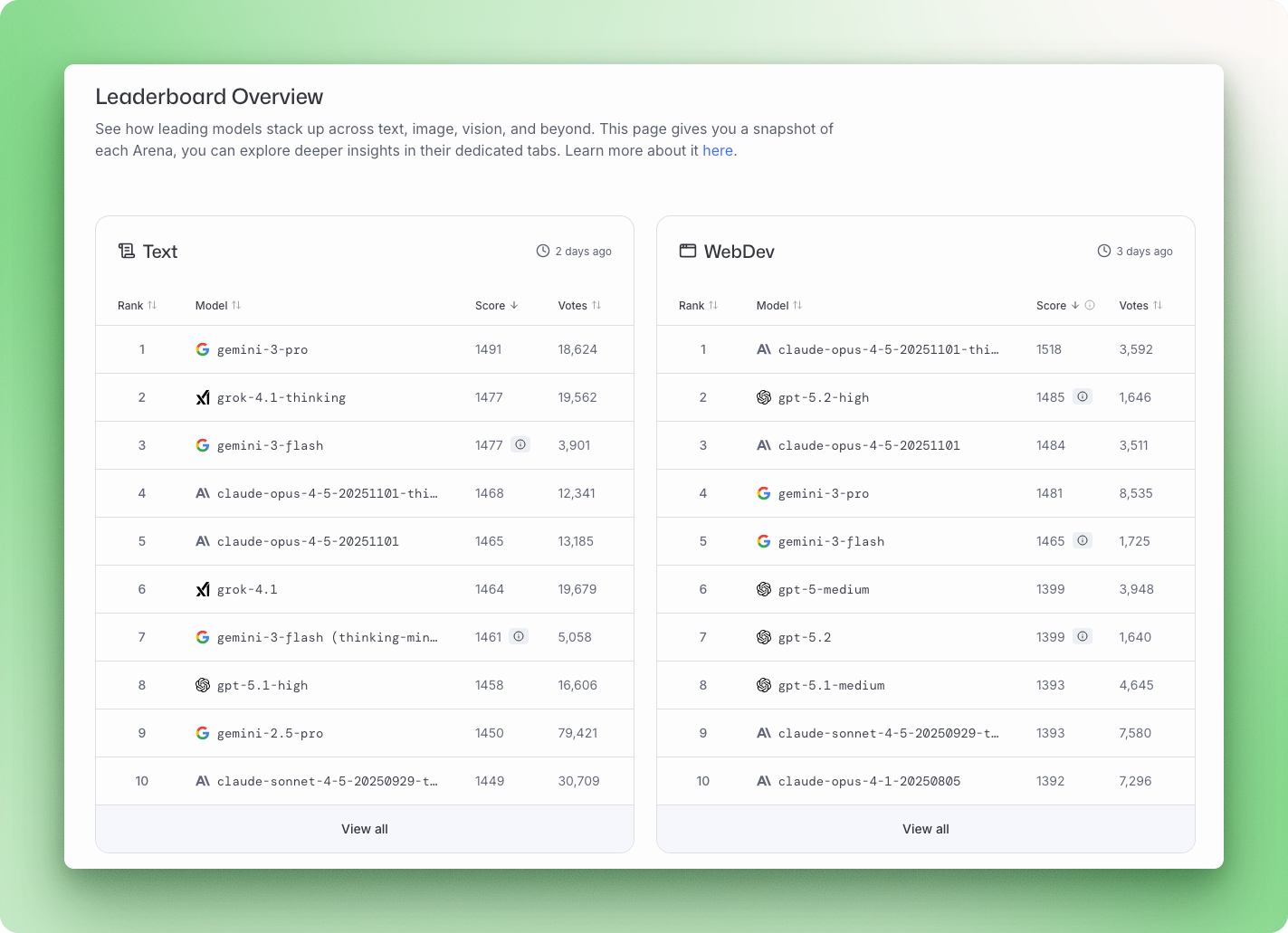
Model AI baru hadir hampir setiap minggu: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Setiap rilis hadir dengan skor benchmark dan klaim sebagai yang terbaik dalam sesuatu. Masalahnya: kebanyakan orang tidak tahu apa arti angka-angka ini atau bagaimana membandingkannya.
Benchmark Large Language Model (LLM) adalah tes standar yang mengukur seberapa baik model menyelesaikan tugas tertentu, mulai dari kuis pengetahuan umum hingga tantangan pemrograman yang kompleks dan masalah penalaran multi-langkah. Memahami apa yang diukur tiap benchmark membantu Anda memilah marketing dan memilih model yang tepat untuk kebutuhan sebenarnya.
Panduan ini menguraikan kategori benchmark utama, menjelaskan di mana menemukan peringkat terkini, dan menunjukkan cara menjalankan evaluasi sendiri. Pada akhirnya, Anda akan tahu cara membaca leaderboard dan memilih AI yang sesuai dengan use case Anda.
Untuk penjelajahan lebih dalam tentang cara kerja LLM di balik layar, lihat kursus LLMs Concepts kami.
Benchmark LLM adalah tes standar yang mengukur seberapa baik model bahasa menangani jenis tugas tertentu. Pertanyaan dan rubrik penilaian yang sama diterapkan pada setiap model yang mengikuti tes.
Angka-angka dalam pengumuman model berasal dari segelintir tes populer. Setiap skor menceritakan hal yang berbeda, dan tidak ada satu benchmark pun yang menangkap gambaran utuh.
Benchmark penting karena tiga alasan:
Membandingkan model: Saat OpenAI merilis GPT-5.2 dan Anthropic merilis Claude Opus 4.5 di bulan yang sama, benchmark memberi kita pijakan yang sama. Jika tidak, kita hanya akan mendengar klaim kemenangan dari masing-masing perusahaan berdasarkan contoh yang dipilih-pilih.
Melacak kemajuan: Jalankan benchmark yang sama dari waktu ke waktu, dan Anda bisa melihat apakah model benar-benar makin baik. Skor MMLU melonjak dari 70% pada 2022 menjadi di atas 90% pada 2025.
Menemukan celah: Sebuah model bisa sangat unggul pada pertanyaan pengetahuan umum tetapi gagal pada matematika multi-langkah. Benchmark menampilkan kelemahan-kelemahan ini.
Skor benchmark mencerminkan lebih dari sekadar kecerdasan mentah. Banyak faktor membentuk angka yang Anda lihat di leaderboard.
Ukuran model adalah yang paling jelas. Parameter menyimpan semua yang dipelajari model, dan model frontier memuat ratusan miliar parameter. Lebih banyak parameter berarti model dapat menangani penalaran yang lebih kompleks dan memuat lebih banyak nuansa, yang mendorong skor meningkat.
Trade-off muncul saat inferensi, ketika model benar-benar menghasilkan respons: semua parameter itu harus aktif berurutan, sehingga model yang lebih besar lebih lambat. Sebuah model mungkin memuncaki setiap benchmark tetapi butuh beberapa detik untuk menjawab.

Durasi pelatihan lebih rumit. Setiap putaran melalui data pelatihan disebut epoch. Terlalu sedikit, model belum menyerap cukup untuk meraih skor baik. Terlalu banyak, ia mulai menghafal contoh alih-alih mempelajari pola yang bisa ditransfer ke pertanyaan baru. Itulah overfitting, dan perancang benchmark secara khusus mencoba menangkapnya dengan memasukkan pertanyaan yang mustahil dilihat model saat pelatihan.
Dengan puluhan benchmark yang digunakan saat ini, akan membantu jika mengelompokkannya berdasarkan apa yang sebenarnya diuji.
Benchmark mengelompok dalam hierarki kasar. Di dasar, uji pengetahuan memeriksa apa yang diketahui model. Di atasnya, benchmark penalaran menguji seberapa baik ia berpikir. Di puncak ada tes agentik dan multimodal yang mengukur apakah AI dapat bertindak di dunia nyata atau memproses informasi di luar teks.
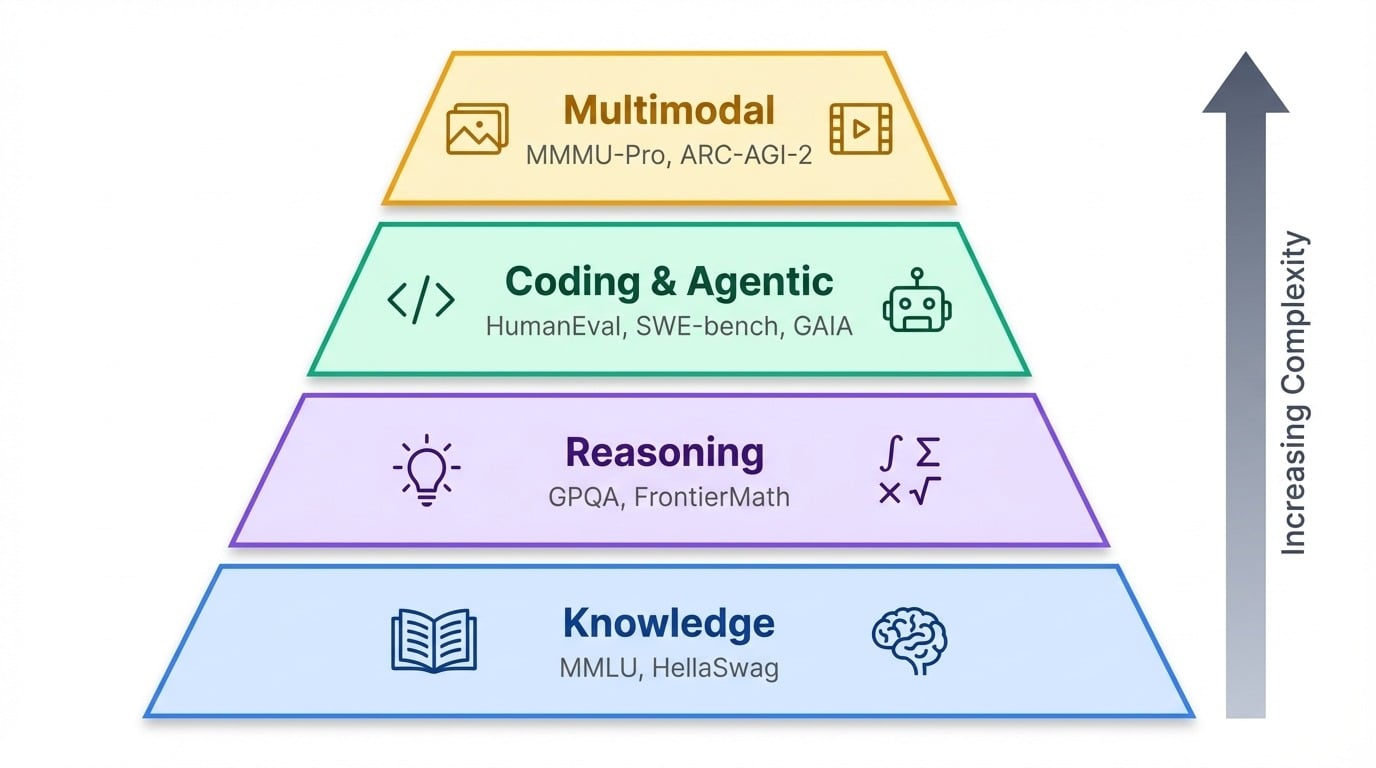
MMLU (Massive Multitask Language Understanding) mencakup 57 subjek akademik dari tingkat SMA hingga profesional, mencakup segala hal mulai dari aljabar abstrak hingga agama dunia. Selama bertahun-tahun, ini menjadi tes andalan untuk pengetahuan umum, tetapi model frontier kini berkumpul di atas 88%, menyisakan sedikit ruang untuk membedakan mereka.
Kejenuhan itu mendorong peneliti ke tes yang lebih sulit. GPQA (Graduate-level Google-Proof Q&A) mengajukan 448 pertanyaan dalam biologi, fisika, dan kimia yang dirancang pakar domain agar tidak dapat dicari.
Benchmark ini memiliki tiga tingkat kesulitan, dengan Diamond berisi pertanyaan paling sulit. Bahkan dengan akses web tanpa batas, non-ahli hanya meraih 34%—hanya 9% di atas hasil yang diharapkan dari tebakan acak dengan empat opsi jawaban. Per Desember 2025, Gemini 3 Pro memimpin GPQA Diamond dengan 92,6%.
Benchmark GDPval (Gross Domestic Product-valued) dari OpenAI mengukur hal yang berbeda: keluaran kerja dunia nyata. Ini mencakup 44 pekerjaan di berbagai sektor senilai US$3 triliun aktivitas ekonomi tahunan, meminta model menghasilkan deliverable seperti legal brief, slide deck, dan spesifikasi rekayasa alih-alih menjawab pilihan ganda. GPT-5.2 yang baru dirilis adalah pemimpin dalam hal ini.
HellaSwag menguji penalaran akal sehat dengan menyajikan skenario sehari-hari dan meminta model memilih kalimat berikutnya yang paling masuk akal. Seseorang yang memasak makan malam meraih wajan. Apa yang terjadi selanjutnya?
Jawaban yang salah ditulis khusus untuk mengelabui AI: menggunakan kata-kata yang secara statistik cocok dengan konteks tetapi menggambarkan hasil yang mustahil (wajan melayang, kompor berubah menjadi kucing). Manusia meraih 95,6% karena kita tahu cara kerja dapur. Model tertipu karena mereka memprediksi kata yang mungkin, bukan kejadian yang mungkin.
Benchmark terbaru mendorong kesulitan lebih jauh:
FrontierMath menampilkan soal yang belum pernah dipublikasikan dari peneliti matematika, di mana bahkan model terbaik meraih kurang dari 20%.
Humanity's Last Exam mengumpulkan 2.500 pertanyaan tingkat ahli yang dirancang untuk sulit ditebak.
MathArena mengambil soal dari kompetisi matematika 2025 untuk menjamin nol tumpang tindih dengan data pelatihan.
HumanEval adalah tes coding klasik: berisi 164 masalah Python di mana model menulis fungsi dari docstring dan dinilai berdasarkan apakah kodenya lulus unit test. Sebagian besar model frontier saat ini meraih lebih dari 85%, sehingga peneliti membuat varian yang lebih sulit seperti HumanEval+ dengan kasus uji yang lebih ketat.
SWE-bench (Software Engineering Benchmark) melampaui fungsi-fungsi terisolasi. Ini menempatkan model ke dalam repositori GitHub nyata dan meminta mereka memperbaiki bug sebenarnya. Model harus menavigasi basis kode, memahami masalah, dan menghasilkan patch yang berfungsi.
SWE-bench Verified adalah subset lebih kecil yang sangat terkurasi dari SWE-bench asli, yang menyaring tugas berkualitas tinggi yang ditelaah insinyur manusia. Per Desember 2025, Claude Opus 4.5 menjadi model pertama yang menembus 80% di SWE-bench Verified (80,9%).
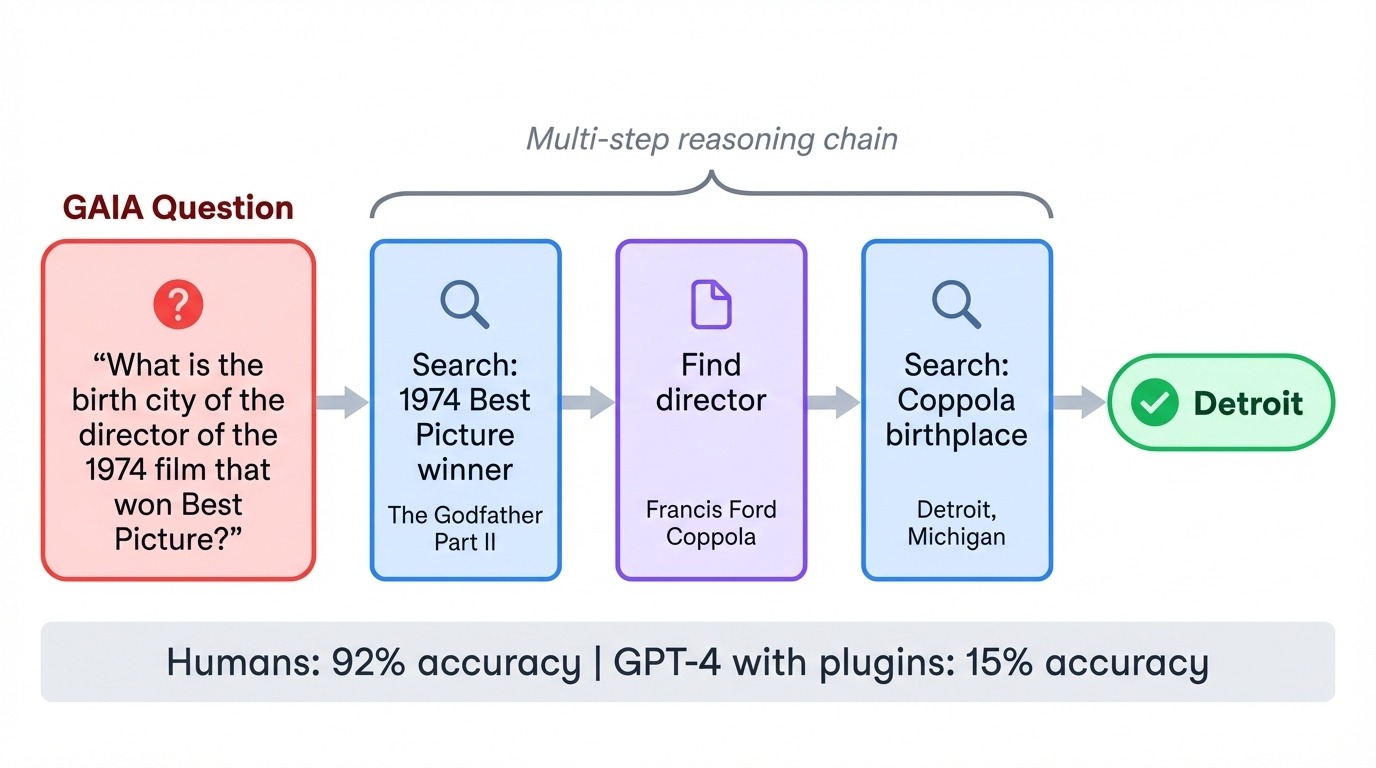
GAIA (General AI Assistants) membalik hubungan kesulitan yang biasa. 466 tugasnya sepele bagi manusia (akurasi 92%) tetapi berat bagi AI. Saat GPT-4 pertama kali mencoba GAIA dengan plugin, skornya hanya 15%. Setiap tugas mensyaratkan merangkai beberapa langkah: menelusuri web, membaca dokumen, melakukan perhitungan, dan menyintesis jawaban.
Pertanyaan khas mungkin menanyakan kota kelahiran sutradara dari film tertentu tahun 1970-an, yang mengharuskan model mengidentifikasi film, menemukan sutradara, lalu mencari detail biografi. Benchmark ini menguji apakah model dapat mengoordinasikan alat dan mengeksekusi rencana multi-langkah tanpa kehilangan jejak.
Terakhir, WebArena menempatkan model di lingkungan web self-hosted di mana mereka harus menyelesaikan tugas seperti memesan penerbangan, mengelola sistem konten, dan menavigasi situs e-niaga dengan berinteraksi dengan antarmuka browser sebenarnya.
Benchmark berbasis teks saja melewatkan frontier yang berkembang. Benchmark MMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) menguji penalaran visual di 30 subjek dengan menyematkan pertanyaan langsung ke dalam gambar, memaksa model membaca dan menafsirkan informasi visual secara bersamaan.
Benchmark ini menyaring pertanyaan yang bisa dijawab model berbasis teks saja, memastikan bahwa visi benar-benar penting. Gemini 3 Pro memimpin di sini dengan 81%.
Beberapa benchmark membawa penalaran visual ke tingkat berikutnya.
MathVista, misalnya, menggabungkan persepsi visual dengan penalaran matematika. Soal mencakup menafsirkan plot fungsi, membaca grafik ilmiah, dan menyelesaikan geometri dari diagram. Video-MMMU memperluas ini ke pemahaman temporal, menguji apakah model dapat bernalar tentang kausalitas dan urutan antar frame video, bukan gambar tunggal.
ARC-AGI-2 tetap menjadi benchmark yang belum berhasil dipecahkan AI. Setiap tugas menyajikan beberapa contoh grid input-output dan meminta model menyimpulkan aturan transformasi, lalu menerapkannya pada input baru.

Manusia menyelesaikan teka-teki ini dalam kurang dari dua percobaan. Model bahasa murni meraih 0%. Sistem hibrida terbaik mencapai 54%, itu pun dengan biaya US$30 per tugas. ARC-AGI-2 menguji kecerdasan cair: bernalar dari prinsip pertama alih-alih mencocokkan pola yang dilihat saat pelatihan.
Benchmark menghasilkan skor, tetapi leaderboard memutuskan cara menyajikannya. Platform berbeda memprioritaskan faktor berbeda: preferensi manusia, transparansi open-source, atau evaluasi multi-dimensi. Mengetahui leaderboard mana yang dirujuk bergantung pada apa yang ingin Anda ukur.
LMArena (LMSYS Chatbot Arena) mengambil pendekatan berbeda dari benchmark otomatis. Alih-alih menilai jawaban berdasarkan rubrik, ini meminta manusia memilih respons yang lebih baik. Pengguna mengirimkan prompt, menerima keluaran dari dua model anonim, dan memilih yang mereka sukai. Model tetap tersembunyi hingga setelah pemungutan suara, mencegah bias merek memengaruhi pilihan.
Platform menggunakan model statistik Bradley-Terry untuk mengonversi lebih dari 5 juta suara berpasangan menjadi peringkat. Per Desember 2025, Gemini 3 Pro memimpin Arena keseluruhan dengan skor 1501, diikuti Grok 4.1 pada 1483, lalu Claude Opus 4.5 dan GPT-5.2.
LMArena menangkap hal yang luput dari benchmark: apakah respons terasa benar-benar membantu. Trade-off-nya, jawaban yang panjang dan terdengar percaya diri dapat memenangkan suara meski ada jawaban yang lebih singkat dan lebih akurat.
Open LLM Leaderboard dari Hugging Face berfokus pada model open-source dan menjalankannya melalui tes standar menggunakan EleutherAI Evaluation Harness. Versi 2 diluncurkan pada Juni 2024 dengan benchmark yang lebih sulit, setelah model frontier menjenuhkan suite tes asli.
Paket saat ini mencakup GPQA, MATH Level 5, dan MMLU-PRO, dengan penilaian ternormalisasi di mana 0 berarti kinerja acak dan 100 berarti sempurna. Model open-source teratas termasuk Qwen3, Llama 3.3 70B, dan DeepSeek V3.1, semuanya bersaing mendekati pemimpin closed-source.
Stanford HELM (Holistic Evaluation of Language Models) mengukur lebih dari sekadar akurat tidaknya hasil model. Setiap model dievaluasi di tujuh dimensi per skenario: akurasi, kalibrasi, ketahanan, keadilan, bias, toksisitas, dan efisiensi.
Kerangka ini mencakup 42 skenario dan secara eksplisit melacak di mana model gagal, bukan hanya di mana mereka berhasil. HELM juga menjalankan leaderboard keamanan terpisah yang menilai risiko seperti kekerasan, penipuan, dan pelecehan. Per Desember 2025, Claude 3.5 Sonnet menempati peringkat tertinggi pada skor keamanan agregat.
Tidak ada satu perusahaan pun yang menang di semua tempat. Namun, begitu Anda menyilang-rujuk beberapa leaderboard, pola mulai terlihat.
Model Gemini dari Google mendominasi benchmark multimodal dan penalaran ilmiah. Gemini 3 Pro memimpin GPQA Diamond pada 91,9% dan menempati puncak Arena secara keseluruhan. Lini Claude dari Anthropic unggul dalam coding dan keamanan. Claude Opus 4.5 memegang rekor SWE-bench Verified pada 80,9%, dan Claude 3.5 Sonnet memimpin HELM Safety.
Model GPT dari OpenAI tetap menjadi generalis yang kuat, kompetitif di sebagian besar benchmark tanpa kelemahan mencolok. Seri Llama dari Meta membuktikan open-source dapat menandingi model tertutup pada banyak tugas, dengan Llama 3.3 70B menyaingi keluaran dari sistem proprietari yang jauh lebih besar.

Pola yang paling penting: cocokkan leaderboard dengan use case Anda. Peringkat Arena mencerminkan kualitas percakapan. Skor HELM menunjukkan keandalan dan keamanan. Hugging Face melacak apa yang bisa Anda jalankan sendiri. Model yang memuncaki satu daftar bisa berada di tengah pada daftar lain, dan itu bukan cacat pada peringkat. Itu adalah tes berbeda yang mengukur hal berbeda.
Leaderboard memberi tahu Anda bagaimana model dibandingkan pada tes standar, tetapi terkadang Anda memerlukan jawaban spesifik untuk situasi Anda.
Anda mungkin sedang memilih antara model open-source untuk hardware Anda, atau memverifikasi bahwa model yang di-fine-tune tidak kehilangan kemampuan penalaran umum. Dalam kasus lain, benchmark standar tidak mencakup domain Anda.
Dalam semua kasus tersebut, Anda mungkin ingin mempertimbangkan melakukan benchmark LLM sendiri. Saya akan menunjukkan cara melakukannya dan hal-hal yang perlu Anda ingat.
EleutherAI LM Evaluation Harness adalah standar industri untuk menjalankan evaluasi ini secara lokal. Ini mendukung Hugging Face Open LLM Leaderboard dan lebih dari 60 benchmark.
Cara kerjanya berbeda dari kebanyakan orang berinteraksi dengan chatbot. Ia tidak sekadar "mengobrol" dengan model; ia melakukan analisis matematis yang lebih deterministik.
Untuk pertanyaan pilihan ganda, yang umum dalam benchmark seperti MMLU atau ARC, harness tidak meminta model mengeluarkan "A," "B," "C," atau "D." Sebagai gantinya, ia membangun prompt terpisah untuk setiap opsi dan meminta model menilai seberapa mungkin masing-masing opsi. Opsi dengan log-likelihood tertinggi kemudian diambil sebagai pilihan model.
Benchmark lain memerlukan pendekatan generatif, di mana model menghasilkan respons teks penuh alih-alih memilih probabilitas. Setelah generasi selesai, harness mengurai keluaran menggunakan regular expression (regex), mengekstrak nilai spesifik yang diperlukan untuk memverifikasinya terhadap kunci jawaban.
Mari lihat cara menjalankan evaluasi LLM pertama Anda.
Anda dapat memasang evaluation harness menggunakan pip:
pip install lm-evalSebelum menjalankan evaluasi penuh, uji pipeline dengan sampel kecil. Flag --limit membatasi benchmark ke jumlah contoh tertentu. Contoh ini menguji Qwen2.5-1.5B-Instruct, model kecil yang berjalan di sebagian besar hardware tanpa memerlukan GPU kelas atas, menggunakan benchmark HellaSwag:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Tugas |
Versi |
Filter |
n-shot |
Metrik |
|
Nilai |
|
Stderr |
|
hellaswag |
1 |
none |
0 |
acc |
↑ |
0.3 |
± |
0.1528 |
|
none |
0 |
acc_norm |
↑ |
0.4 |
± |
0.1633 |
Keluaran menampilkan dua metrik akurasi: acc adalah akurasi mentah, sementara acc_norm menyesuaikan bias model terhadap penyelesaian yang lebih pendek atau lebih panjang. Selain itu, standard error dilaporkan, yang menyusut seiring bertambahnya ukuran sampel. Pada uji pertama kita yang hanya menggunakan 10 sampel, Stderr yang tinggi (0,15) berarti skor ini adalah perkiraan kasar.
Hapus --limit untuk menjalankan benchmark lengkap. Untuk beberapa benchmark dalam sekali jalan, daftarkan dengan koma:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsAtur --device berdasarkan hardware Anda: mps untuk Apple Silicon, cuda:0 untuk GPU NVIDIA, atau cpu sebagai cadangan. MMLU penuh memakan waktu 1–2 jam pada GPU modern; benchmark yang lebih kecil seperti HellaSwag selesai dalam hitungan menit.
Untuk pengujian latensi dan throughput, Ollama menjalankan model secara lokal dan melaporkan token per detik di berbagai tingkat kuantisasi. Model 7B dapat menghasilkan 100+ token per detik pada V100, sementara model 70B turun ke satu digit.
Ada beberapa praktik terbaik yang perlu diingat saat melakukan benchmarking LLM.
Pertama dan terpenting, Anda harus memastikan bahwa model belum pernah melihat pertanyaan evaluasi saat pelatihan. Jika iya, Anda hanya mengukur overfitting, bukan kemampuan penalaran model, seperti dibahas di awal. Dalam kasus ini, skor benchmark menjadi tidak bermakna.
Untuk memperoleh hasil yang dapat direproduksi, variabilitas dalam jawaban model harus dibuat serendah mungkin. Ini dapat dicapai dengan menyetel temperature ke nol untuk memprioritaskan akurasi daripada kreativitas.
Harness menyertakan prompt few-shot standar untuk tiap benchmark. Gunakan itu alih-alih menulis prompt sendiri, karena perubahan kata-kata kecil memengaruhi skor lebih dari yang diperkirakan. Namun, untuk pekerjaan spesifik domain, Anda sebaiknya selalu membangun set uji kecil dari contoh nyata di bidang Anda sebelum memilih model untuk produksi.
Benchmark standar unggul dalam memeriksa fakta, tetapi kesulitan mengukur nuansa. Untuk tugas terbuka seperti merangkum atau menulis kreatif, LLM-as-a-judge menggunakan model yang lebih kuat untuk menilai keluaran berdasarkan kebermanfaatan dan akurasi.
Biasanya, judge diberi rubrik dan diminta untuk memberi skor numerik (misalnya 1–10) atau melakukan perbandingan berpasangan untuk memutuskan mana dari dua jawaban yang lebih baik. Meskipun tidak sempurna, penilaian ini selaras dengan preferensi manusia sekitar 80–85% dari waktu. Karenanya, LLM-as-a-judge menawarkan alternatif yang dapat diskalakan untuk tinjauan manusia yang mahal.
Evaluasi AI berubah secepat modelnya. Saat benchmark seperti MMLU jenuh, peneliti membangun tes yang lebih sulit yang menguji kedalaman penalaran alih-alih pengetahuan yang dihafal. FrontierMath dan Humanity's Last Exam merepresentasikan frontier kesulitan baru ini, di mana bahkan model terbaik pun kesulitan.
Sinyal yang lebih luas mengarah ke satu arah: komputasi pelatihan yang lebih besar, algoritme yang lebih cerdas, dan suite benchmark yang mengikuti laju kemajuan. Tes multimodal memperluas apa yang kita minta model lakukan, dari membaca grafik hingga memahami urutan video.
Namun intinya tetap sederhana. Tidak ada satu skor pun yang menceritakan keseluruhan cerita. Model yang memimpin Arena bisa tertinggal di SWE-bench. Model coding teratas bisa berada di tengah pada keamanan. Cocokkan benchmark dengan apa yang benar-benar Anda butuhkan: penalaran, generasi kode, pemahaman visual, atau kecepatan mentah. Hanya perbandingan itu yang penting.
Untuk meningkatkan kemampuan Anda melampaui benchmarking, pelajari cara membangun dan melakukan fine-tuning LLM sendiri dengan skill track Developing Large Language Models kami.
Kursus LLM
Program
Program
Kursus
blogs
Dario Radečić
15 mnt
blogs
Javier Canales Luna
14 mnt
blogs
David Woods
13 mnt
blogs
Hugo Bowne-Anderson
13 mnt
