
Leerpad
AI-basisprincipes
10 Hr
Er verschijnen bijna wekelijks nieuwe AI-modellen: Gemini 3, Claude Opus 4.5, GPT-5.2, Mistral Large 3. Elke release komt met benchmarkcijfers en claims dat het ergens de beste in is. Het probleem: de meeste mensen hebben geen idee wat die cijfers betekenen of hoe je ze moet vergelijken.
Benchmarks voor Large Language Models (LLM's) zijn gestandaardiseerde tests die meten hoe goed modellen presteren op specifieke taken, van algemene kennistoetsen tot complexe codeeruitdagingen en meerstaps redeneerproblemen. Begrijpen wat elke benchmark meet helpt je door de marketing heen te prikken en het juiste model voor jouw echte behoeften te kiezen.
Deze gids zet de belangrijkste benchmarkcategorieën uiteen, legt uit waar je actuele ranglijsten vindt en laat zien hoe je je eigen evaluaties draait. Aan het einde kun je een leaderboard lezen en de AI kiezen die bij jouw usecase past.
Wil je dieper duiken in hoe LLM's onder de motorkap werken? Bekijk dan onze LLMs Concepts-cursus.
Een LLM-benchmark is een gestandaardiseerde test die meet hoe goed een taalmodel een specifiek type taak afhandelt. Dezelfde vragen en beoordelingscriteria worden op elk model toegepast dat de test doet.
De cijfers in modelaankondigingen komen uit een handvol populaire tests. Elke score vertelt een ander verhaal, en geen enkele benchmark vangt het volledige plaatje.
Benchmarks zijn om drie redenen belangrijk:
Modellen vergelijken: Als OpenAI GPT-5.2 uitbrengt en Anthropic in dezelfde maand Claude Opus 4.5 lanceert, geven benchmarks ons een gemeenschappelijke basis. Anders zitten we vast aan bedrijven die elk hun eigen overwinning claimen met zorgvuldig gekozen voorbeelden.
Voortgang volgen: Door dezelfde benchmark in de tijd te herhalen, zie je of modellen écht beter worden. MMLU-scores stegen van 70% in 2022 naar boven de 90% in 2025.
Gaten signaleren: Een model kan algemene kennisvragen afbluffen maar vastlopen op meerstaps wiskunde. Benchmarks maken dit soort zwaktes zichtbaar.
Benchmarkcijfers weerspiegelen meer dan rauwe intelligentie. Meerdere factoren bepalen de getallen die je op leaderboards ziet.
Modelgrootte is de voor de hand liggende. Parameters slaan alles op wat een model leert, en de meest geavanceerde modellen bevatten er honderden miljarden. Meer parameters betekenen dat het model complexer kan redeneren en meer nuance kan vasthouden, wat scores opkrikt.
De trade-off zie je tijdens de inferentie, wanneer het model daadwerkelijk antwoorden genereert: al die parameters moeten na elkaar vuren, dus grotere modellen zijn trager. Een model kan elke benchmark aanvoeren, maar toch enkele seconden nodig hebben om te antwoorden.

Trainingsduur is lastiger. Elke doorgang door de trainingsdata heet een epoch. Te weinig en het model heeft niet genoeg opgenomen om goed te scoren. Te veel en het begint voorbeelden te memoriseren in plaats van patronen te leren die overdragen naar nieuwe vragen. Dat is overfitting, en benchmarkontwerpers proberen dat juist te vangen door vragen op te nemen die het model niet tijdens training gezien kan hebben.
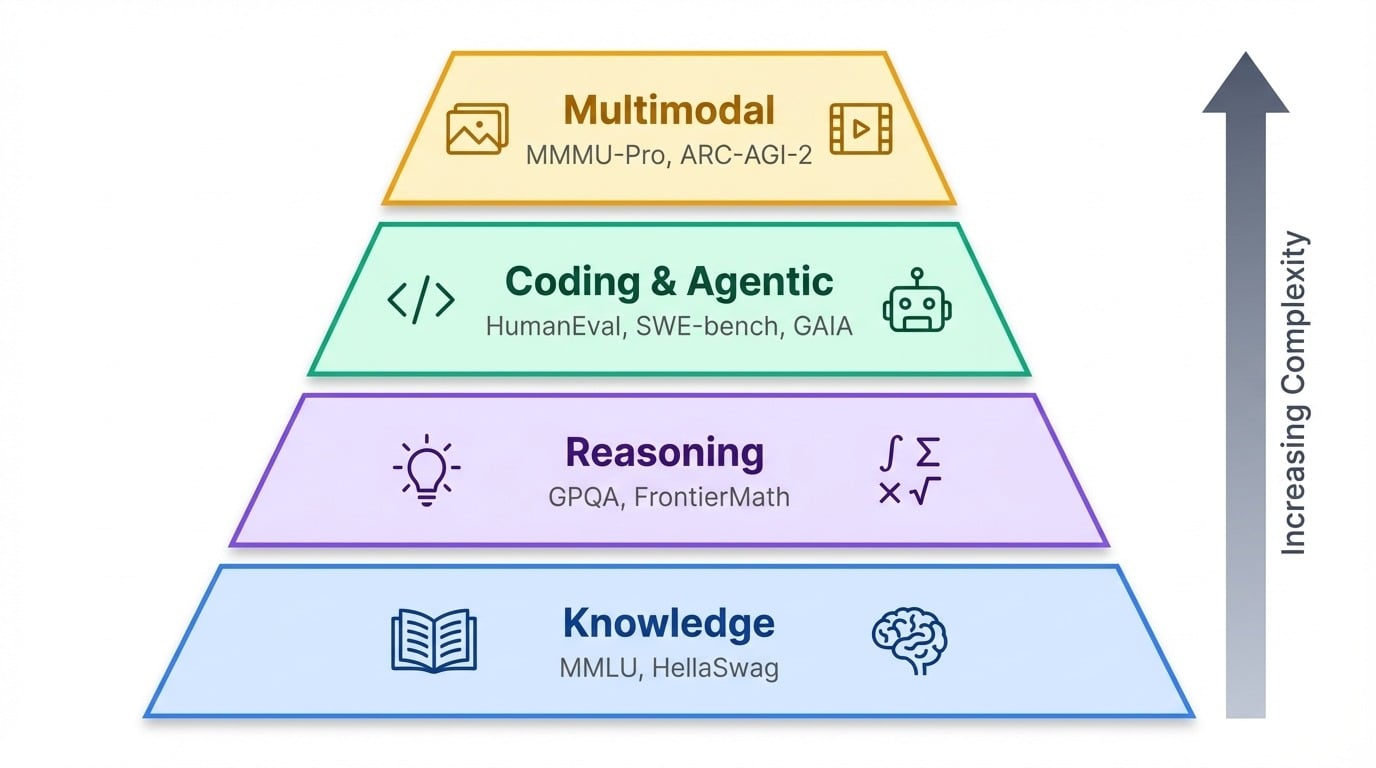
Met tientallen benchmarks die vandaag in gebruik zijn, helpt het om ze te groeperen naar wat ze daadwerkelijk testen.
Benchmarks clusteren in een ruwe hiërarchie. Aan de basis testen kennistoetsen wat een model weet. Daarboven peilen redeneerbenchmarks hoe goed het denkt. Bovenaan staan agentische en multimodale tests die meten of AI in de echte wereld kan handelen of informatie buiten tekst kan verwerken.
MMLU (Massive Multitask Language Understanding) bestrijkt 57 academische vakken van middelbare school tot professioneel niveau, van abstracte algebra tot wereldreligies. Jarenlang was het de standaardtest voor algemene kennis, maar de meest geavanceerde modellen zitten nu boven de 88%, waardoor er weinig ruimte overblijft om ze te onderscheiden.
Die verzadiging duwde onderzoekers naar moeilijkere tests. GPQA (Graduate-level Google-Proof Q&A) stelt 448 vragen in biologie, natuurkunde en scheikunde die door domeinexperts zo zijn ontworpen dat ze niet te googelen zijn.
De benchmark kent drie moeilijkheidsniveaus, waarbij Diamond de lastigste vragen bevat. Zelfs met onbeperkte webtoegang scoren niet-experts slechts 34%—slechts 9% boven het resultaat dat je van willekeurig gokken met vier opties zou verwachten. Per december 2025 leidt Gemini 3 Pro GPQA Diamond met 92,6%.
OpenAI's GDPval (Gross Domestic Product-valued) benchmark meet iets anders: werkoutput in de echte wereld. Het bestrijkt 44 beroepen in sectoren ter waarde van 3 biljoen dollar aan jaarlijkse economische activiteit, en vraagt modellen om deliverables als juridische memo's, slidedecks en engineeringspecificaties te produceren in plaats van meerkeuzevragen te beantwoorden. De onlangs uitgebrachte GPT-5.2 is hierin de koploper.
HellaSwag test gezond verstand door alledaagse scenario's te schetsen en modellen te laten kiezen wat de meest plausibele volgende zin is. Iemand die aan het koken is pakt een pan. Wat gebeurt er daarna?
De foute antwoorden zijn speciaal geschreven om AI te misleiden: ze gebruiken woorden die statistisch in de context passen maar onmogelijke uitkomsten beschrijven (de pan zweeft weg, het fornuis verandert in een kat). Mensen scoren 95,6% omdat we weten hoe keukens werken. Modellen trappen erin omdat ze waarschijnlijke woorden voorspellen, niet waarschijnlijke gebeurtenissen.
De nieuwste benchmarks voeren de moeilijkheid verder op:
FrontierMath bevat nooit eerder gepubliceerde problemen van onderzoekswiskundigen, waarop zelfs de beste modellen onder de 20% scoren.
Humanity's Last Exam bundelt 2.500 vragen op expertniveau die ontworpen zijn om gokken te weerstaan.
MathArena haalt opgaven uit wiskundewedstrijden van 2025 om nul overlap met trainingsdata te garanderen.
HumanEval is de klassieke codeertest: het bevat 164 Pythonproblemen waarbij modellen functies schrijven op basis van docstrings en worden beoordeeld op het slagen voor unittests. De meeste huidige toonaangevende modellen scoren boven 85%, dus onderzoekers maakten moeilijkere varianten zoals HumanEval+ met strengere testcases.
SWE-bench (Software Engineering Benchmark) gaat verder dan losse functies. Het dropt modellen in echte GitHub-repo's en vraagt ze om échte bugs te fixen. Het model moet door de codebase navigeren, het probleem begrijpen en een werkende patch opleveren.
SWE-bench Verified is een kleinere, sterk gecureerde subset van de oorspronkelijke SWE-bench, die filtert op hoogwaardige taken beoordeeld door menselijke engineers. Per december 2025 is Claude Opus 4.5 het eerste model dat 80% doorbreekt in SWE-bench Verified (80,9%).
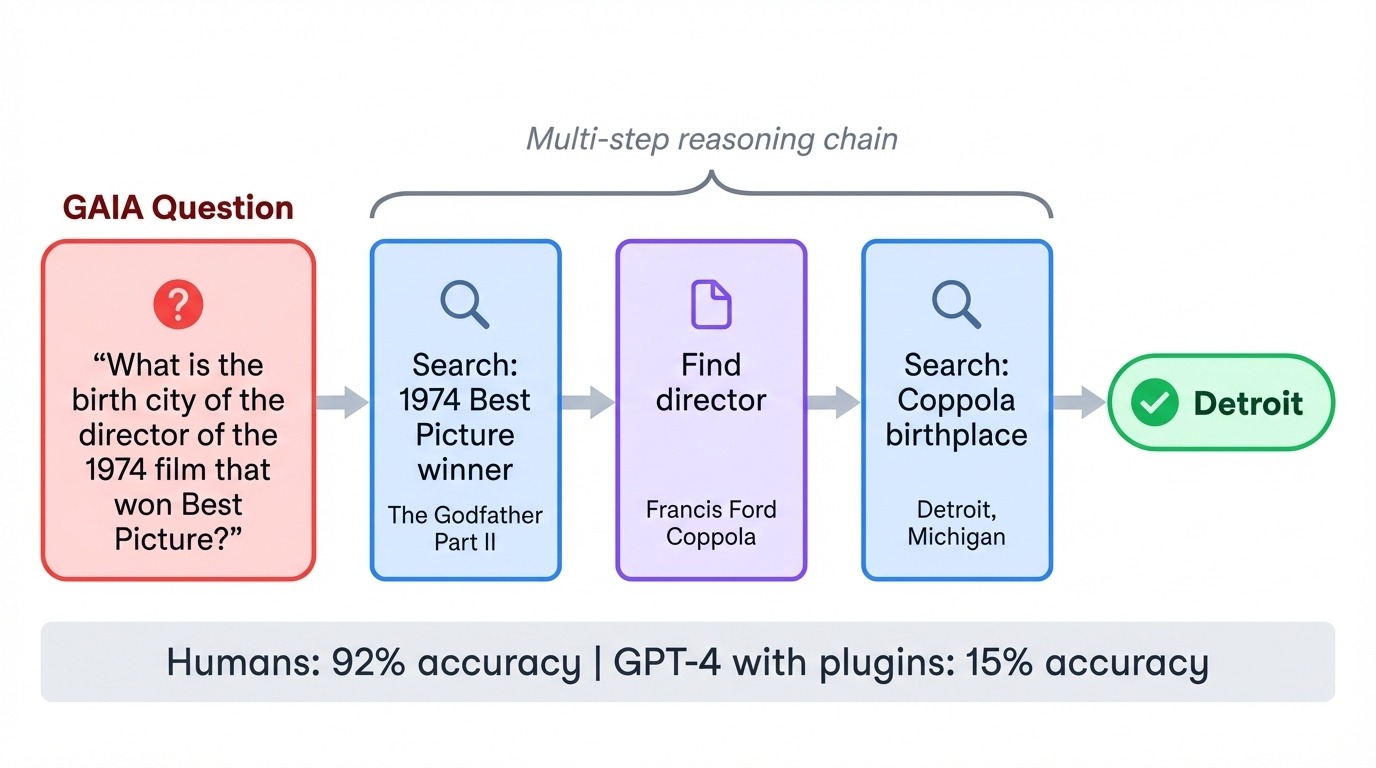
GAIA (General AI Assistants) keert de gebruikelijke moeilijkheidsrelatie om. De 466 taken zijn triviaal voor mensen (92% nauwkeurigheid) maar meedogenloos voor AI. Toen GPT-4 GAIA voor het eerst met plugins probeerde, scoorde het slechts 15%. Elke taak vereist het aaneenrijgen van meerdere stappen: zoeken op het web, documenten lezen, berekeningen doen en antwoorden synthetiseren.
Een typische vraag kan de geboorteplaats vragen van de regisseur van een specifieke film uit de jaren 70, waarbij het model de film moet identificeren, de regisseur moet vinden en vervolgens biografische details moet opzoeken. De benchmark test of modellen tools kunnen coördineren en meerstapsplannen kunnen uitvoeren zonder de draad kwijt te raken.
Tot slot zet WebArena modellen in in zelfgehoste webomgevingen waar ze taken moeten voltooien zoals vluchten boeken, content-systemen beheren en e-commercesites navigeren door met echte browserinterfaces te interageren.
Tekst-only benchmarks missen een groeiende frontier. De MMMU-Pro (Massive Multi-discipline Multimodal Understanding and Reasoning) benchmark test visueel redeneren over 30 vakken door vragen direct in afbeeldingen te embedden, waardoor modellen visuele informatie tegelijk moeten lezen en interpreteren.
De benchmark filtert vragen weg die tekst-only modellen zouden kunnen beantwoorden, zodat visie echt uitmaakt. Gemini 3 Pro leidt hier met 81%.
Sommige benchmarks tillen visueel redeneren naar het volgende niveau.
MathVista combineert bijvoorbeeld visuele perceptie met wiskundig redeneren. Problemen omvatten het interpreteren van functieplotten, het lezen van wetenschappelijke grafieken en het oplossen van meetkunde aan de hand van diagrammen. Video-MMMU breidt dit uit naar temporeel begrip en test of modellen over causaliteit en sequenties kunnen redeneren over videoframes in plaats van losse beelden.
ARC-AGI-2 blijft de benchmark die AI nog niet heeft gekraakt. Elke taak presenteert een paar input-outputrastervoorbeelden en vraagt het model de transformatiestructuur te achterhalen en die vervolgens op een nieuwe input toe te passen.

Mensen lossen deze puzzels in minder dan twee pogingen op. Pure taalmodellen scoren 0%. De beste hybride systemen halen 54%, en dat tegen een kostprijs van 30 dollar per taak. ARC-AGI-2 test vloeibare intelligentie: redeneren vanuit eerste principes in plaats van patronen te matchen die tijdens training zijn gezien.
Benchmarks leveren scores op, maar leaderboards bepalen hoe die worden gepresenteerd. Verschillende platforms geven prioriteit aan verschillende factoren: menselijke voorkeur, open-source transparantie of multidimensionale evaluatie. Welke leaderboard je raadpleegt hangt af van wat je wilt meten.
De LMArena (LMSYS Chatbot Arena) pakt het anders aan dan geautomatiseerde benchmarks. In plaats van antwoorden tegen een rubric te scoren, laat het mensen de betere respons kiezen. Gebruikers dienen een prompt in, krijgen uitkomsten van twee anonieme modellen en stemmen op degene die ze prefereren. De modellen blijven verborgen tot na de stemming, zodat merkvoorkeur de keuze niet beïnvloedt.
Het platform gebruikt een Bradley-Terry-statistisch model om meer dan 5 miljoen paarsgewijze stemmen om te zetten in ranglijsten. Per december 2025 voert Gemini 3 Pro de algehele Arena aan met een score van 1501, gevolgd door Grok 4.1 met 1483, daarna Claude Opus 4.5 en GPT-5.2.
De LMArena vangt iets wat benchmarks missen: of een antwoord daadwerkelijk behulpzaam aanvoelt. Het nadeel is dat breedsprakige, zelfverzekerd klinkende antwoorden stemmen kunnen winnen, zelfs als er een korter, accurater antwoord bestaat.
Het Open LLM Leaderboard van Hugging Face richt zich op open-sourcemodellen en jaagt ze door gestandaardiseerde tests met de EleutherAI Evaluation Harness. Versie 2 lanceerde in juni 2024 met moeilijkere benchmarks, nadat de oorspronkelijke testsuite door de topmodellen was verzadigd.
De huidige batterij omvat GPQA, MATH Level 5 en MMLU-PRO, met genormaliseerde scores waarbij 0 willekeurige performance betekent en 100 perfect. Top open modellen zijn onder andere Qwen3, Llama 3.3 70B en DeepSeek V3.1, die allemaal binnen slagafstand van closed-source koplopers concurreren.
Stanford HELM (Holistic Evaluation of Language Models) meet meer dan alleen of de resultaten van modellen kloppen. Elk model wordt per scenario op zeven dimensies geëvalueerd: nauwkeurigheid, calibratie, robuustheid, eerlijkheid, bias, toxiciteit en efficiëntie.
Het framework bestrijkt 42 scenario's en houdt expliciet bij waar modellen falen, niet alleen waar ze slagen. HELM draait ook een apart veiligheidsleaderboard dat risico's als geweld, fraude en intimidatie beoordeelt. Per december 2025 staat Claude 3.5 Sonnet het hoogst op de samengestelde veiligheidsscores.
Geen enkel bedrijf wint overal. Maar zodra je een paar leaderboards kruist, ontstaan er patronen.
De Gemini-modellen van Google domineren multimodale benchmarks en wetenschappelijk redeneren. Gemini 3 Pro leidt GPQA Diamond met 91,9% en staat bovenaan de Arena. De Claude-lijn van Anthropic blinkt uit in coderen en veiligheid. Claude Opus 4.5 heeft het SWE-bench Verified-record met 80,9%, en Claude 3.5 Sonnet voert HELM Safety aan.
OpenAI's GPT-modellen blijven sterke generalisten, competitief op de meeste benchmarks zonder een enkele opvallende zwakte. Meta's Llama-serie bewijst dat open source op veel taken kan tippen aan gesloten modellen, met Llama 3.3 70B dat output levert die kan wedijveren met veel grotere proprietary systemen.

Het belangrijkste patroon: koppel het leaderboard aan jouw usecase. Arena-ranglijsten weerspiegelen conversatiekwaliteit. HELM-scores laten betrouwbaarheid en veiligheid zien. Hugging Face volgt wat je zelf kunt draaien. Een model dat één lijst aanvoert, kan middenmoot scoren op een andere—en dat is geen fout in de ranglijsten. Het zijn verschillende tests die verschillende dingen meten.
Leaderboards vertellen hoe modellen zich verhouden op standaardtests, maar soms heb je antwoorden nodig die specifiek zijn voor jouw situatie.
Misschien kies je tussen open-sourcemodellen voor jouw hardware, of verifieer je dat een fijn-afgesteld model zijn algemene redeneervermogen niet is kwijtgeraakt. In andere gevallen dekken de standaardbenchmarks jouw domein simpelweg niet.
In al die gevallen is het de moeite waard om LLM's zelf te benchmarken. Ik laat je zien hoe je dat doet en waar je op moet letten.
De EleutherAI LM Evaluation Harness is de industriestandaard om deze evaluaties lokaal te draaien. Het voedt het Hugging Face Open LLM Leaderboard en ondersteunt meer dan 60 benchmarks.
Het werkt anders dan hoe de meeste mensen met chatbots omgaan. Het gaat niet gewoon met het model "chatten"; het voert een meer deterministische wiskundige analyse uit.
Voor meerkeuzevragen, een veelgebruikte methode in benchmarks als MMLU of ARC, vraagt de harness het model niet om "A", "B", "C" of "D" uit te spuwen. In plaats daarvan construeert het voor elke optie een aparte prompt en vraagt het model hoe waarschijnlijk elk ervan is. De optie met de hoogste log-likelihood wordt dan genomen als de keuze van het model.
Andere benchmarks vereisen een generatieve aanpak, waarbij het model een volledig tekstantwoord produceert in plaats van een waarschijnlijkheid te kiezen. Zodra de generatie klaar is, parseert de harness de output met reguliere expressies (regex) om de specifieke waarde te extraheren die nodig is om te verifiëren tegen de antwoordsleutel.
Laten we kijken hoe je je eerste LLM-evaluatie draait.
Je kunt de evaluation harness installeren met pip:
pip install lm-evalTest de pijplijn met een kleine steekproef voordat je een volledige evaluatie draait. De --limit-vlag beperkt de benchmark tot een opgegeven aantal voorbeelden. Dit voorbeeld test Qwen2.5-1.5B-Instruct, een klein model dat op de meeste hardware draait zonder high-end GPU, met de HellaSwag-benchmark:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag \
--device mps \
--batch_size 4 \
--limit 10|
Taken |
Versie |
Filter |
n-shot |
Metric |
|
Waarde |
|
Stderr |
|
hellaswag |
1 |
none |
0 |
acc |
↑ |
0.3 |
± |
0.1528 |
|
none |
0 |
acc_norm |
↑ |
0.4 |
± |
0.1633 |
De output toont twee nauwkeurigheidsmaten: acc is ruwe nauwkeurigheid, terwijl acc_norm corrigeert voor de bias van het model richting kortere of langere completions. Daarnaast wordt de standaardfout gerapporteerd, die kleiner wordt naarmate de steekproef groter is. In onze eerste test met slechts 10 samples betekent de hoge Stderr (0,15) dat deze scores grove schattingen zijn.
Verwijder --limit om de volledige benchmark te draaien. Voor meerdere benchmarks in één run, geef ze met komma's op:
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-1.5B-Instruct \
--tasks hellaswag,mmlu,arc_easy \
--device mps \
--batch_size 8 \
--output_path ./resultsStel --device in op basis van je hardware: mps voor Apple Silicon, cuda:0 voor NVIDIA GPU's, of cpu als fallback. Volledige MMLU duurt 1-2 uur op een moderne GPU; kleinere benchmarks zoals HellaSwag zijn in minuten klaar.
Voor latency- en throughputtests draait Ollama modellen lokaal en rapporteert tokens per seconde over verschillende quantisatieniveaus. Een 7B-model kan 100+ tokens per seconde genereren op een V100, terwijl een 70B-model terugvalt naar enkele tokens per seconde.
Er zijn een paar best practices om in gedachten te houden bij het benchmarken van een LLM.
Allereerst en het belangrijkst: zorg dat het model de evaluatievragen niet tijdens training heeft gezien. Zo ja, dan meet je slechts overfitting in plaats van het redeneervermogen van het model, zoals in het begin besproken. In dat geval worden benchmarkcijfers betekenisloos.
Om reproduceerbare resultaten te krijgen, moet de variabiliteit in de antwoorden van het model zo laag mogelijk zijn. Dit bereik je door de temperatuur op nul te zetten om accuratesse boven creativiteit te verkiezen.
De harness bevat gestandaardiseerde few-shot prompts voor elke benchmark. Gebruik die in plaats van eigen prompts te schrijven, want kleine woordkeuzes beïnvloeden scores meer dan je verwacht. Voor domeinspecifiek werk moet je echter altijd een kleine testset bouwen met echte voorbeelden uit jouw veld voordat je een model in productie neemt.
Standaardbenchmarks zijn uitstekend in feiten checken, maar worstelen met nuance. Voor open taken zoals samenvatten of creatief schrijven beoordeelt LLM-as-a-judge de uitkomsten van een ander model op behulpzaamheid en accuratesse met een sterker model als scheidsrechter.
De judge krijgt doorgaans een rubric en wordt gevraagd om ofwel een numerieke score toe te kennen (bijv. 1-10) of een paarsgewijze vergelijking te doen om te bepalen welk van twee antwoorden beter is. Hoewel niet perfect, komen deze oordelen in 80-85% van de gevallen overeen met menselijke voorkeuren. LLM-as-a-judge biedt dus een schaalbaar alternatief voor dure menselijke beoordeling.
AI-evaluatie verandert net zo snel als de modellen zelf. Nu benchmarks zoals MMLU verzadigd raken, bouwen onderzoekers moeilijkere tests die diepte van redeneren peilen in plaats van gememoriseerde kennis. FrontierMath en Humanity's Last Exam vertegenwoordigen deze nieuwe moeilijkheidsgrens, waar zelfs de beste modellen moeite mee hebben.
De bredere signalen wijzen één kant op: meer trainingcompute, slimmere algoritmes en benchmarksuites die gelijke tred houden met de vooruitgang. Multimodale tests verbreden wat we modellen laten doen, van grafieken lezen tot videoscènes begrijpen.
Maar de kern blijft simpel. Geen enkele score vertelt het hele verhaal. Een model dat de Arena aanvoert, kan achterblijven op SWE-bench. Het beste codemodel kan middendoor scoren op veiligheid. Koppel de benchmark aan wat je echt nodig hebt: redeneren, codegeneratie, visueel begrip of pure snelheid. Dat is de enige vergelijking die telt.
Wil je verder gaan dan benchmarken? Leer LLM's bouwen en fine-tunen met onze Developing Large Language Models skill track.
LLM-cursussen
Leerpad
Leerpad
Cursus
blog
Adel Nehme
15 min
