course
Developing AI Systems with the OpenAI API
3 oră
20.8K
Articolul nostru de ansamblu despre GPT-Realtime-2 a acoperit lansarea, afirmațiile din benchmarkuri și de ce a împărțit OpenAI vocea în timp real într-o mică familie de modele. Acest tutorial pornește de unde s-a oprit acel articol: conectarea la API, trimiterea de audio și observarea modificărilor din cod.
Împărțirea contează în practică. Testul 1 folosește gpt-realtime-whisper pentru transcriere, Testul 2 folosește gpt-realtime-translate pentru traducere în timp real, iar Testul 3 folosește gpt-realtime-2 pentru un asistent vocal. Modelul principal funcționează și pentru sarcini mai simple, precum traducerea sau transcrierea, dar ați plăti pentru un nivel de raționare și moduri de răspuns care nu sunt necesare, deci ar fi prea mult.
Înainte de teste, ajută să separați transportul, autentificarea și formatul audio. Aceste detalii rămân în mare parte la fel în exemple. Punctele finale ale modelelor și numele evenimentelor sunt cele care se schimbă pe măsură ce articolul trece de la ieșire text la vorbire tradusă și apoi la un ciclu vocal complet.
Documentația OpenAI oferă o regulă simplă: folosiți WebRTC pentru clienți în browser și pe mobil și folosiți WebSockets pentru aplicații pe server. WebRTC gestionează bufferizarea jitterului și transportul audio. WebSocket-urile au sens când backendul primește deja audio brut de la un furnizor de telefonie sau dintr-un pipeline media.
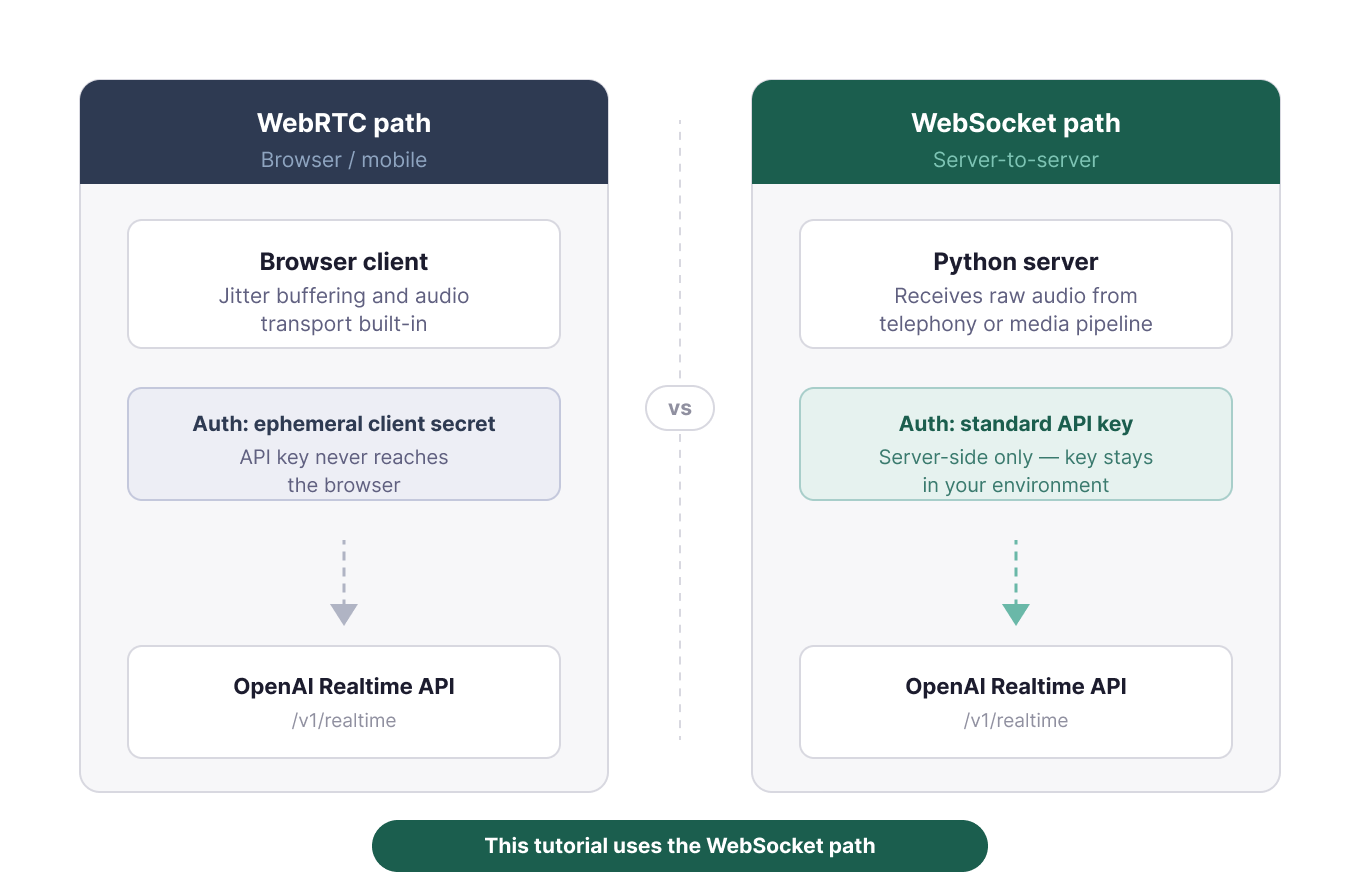
Două căi de transport pentru Realtime API. Imagine de autor.
Din acest motiv, toate cele trei teste Python folosesc WebSockets. Această cale arată direct numele evenimentelor, astfel încât diferențele dintre modele sunt vizibile în cod. Pentru un build de browser, folosiți secrete client efemere, astfel încât cheia API să nu ajungă niciodată în frontend.
Folosiți Python 3.9 sau mai nou. Codul complet pentru toate cele patru scripturi este disponibil la github.com/KhalidAbdelaty/gpt-realtime-api. Clonați-l mai întâi, apoi instalați dependențele:
git clone https://github.com/KhalidAbdelaty/gpt-realtime-api.git
cd gpt-realtime-api
pip install websocket-client sounddevice numpy python-dotenvwebsocket-client gestionează socketul. sounddevice capturează audio de la microfon, numpy convertește bufferul, iar python-dotenv încarcă cheia API. Pe macOS, este posibil să aveți nevoie de brew install portaudio înainte ca sounddevice să funcționeze. Pe Linux, instalați portaudio19-dev.
Creați un fișier .env la rădăcina proiectului:
OPENAI_API_KEY=sk-...Apoi încărcați-l în fiecare script:
import os
from dotenv import load_dotenv
load_dotenv()
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")Conexiunile pe server folosesc un header Authorization: Bearer la handshake-ul WebSocket. Adăugați OpenAI-Safety-Identifier dacă aplicația urmărește utilizatori individuali. Acestea sunt căile folosite ulterior în teste:
# Voice agent
wss://api.openai.com/v1/realtime?model=gpt-realtime-2
# Translation
wss://api.openai.com/v1/realtime/translations?model=gpt-realtime-translate
# Transcription
wss://api.openai.com/v1/realtime?intent=transcriptionAcea cale de traducere contează mai târziu, în Testul 2, deoarece este singurul endpoint care nu folosește direct /v1/realtime.
Transcrierea este un loc în care se exagerează ușor. Dacă ieșirea este doar text, modelul de transcriere este suficient.
gpt-realtime-whisper primește audio și emite delta-uri de transcript. Nu raționează, nu apelează instrumente și nu răspunde vocal. Această sarcină mai mică este motivul pentru care este tarifat în funcție de durata audio, nu cu același model de tokeni folosit de gpt-realtime-2. Secțiunea despre costuri revine la aceste tarife.
Câmpul cheie este session.type: "transcription". Acesta spune API-ului să sară peste răspunsurile asistentului și să emită doar evenimente de transcript. Scriptul complet gestionează și capturarea de la microfon și threading. Aceasta este partea care schimbă comportamentul sesiunii Realtime:
session_config = {
"type": "session.update",
"session": {
"type": "transcription",
"audio": {
"input": {
"format": {"type": "audio/pcm", "rate": 24000},
"transcription": {
"model": "gpt-realtime-whisper",
"language": "en"
},
"turn_detection": None
}
}
}
}
ws.send(json.dumps(session_config))
ws.send(json.dumps({
"type": "input_audio_buffer.append",
"audio": audio_b64
}))
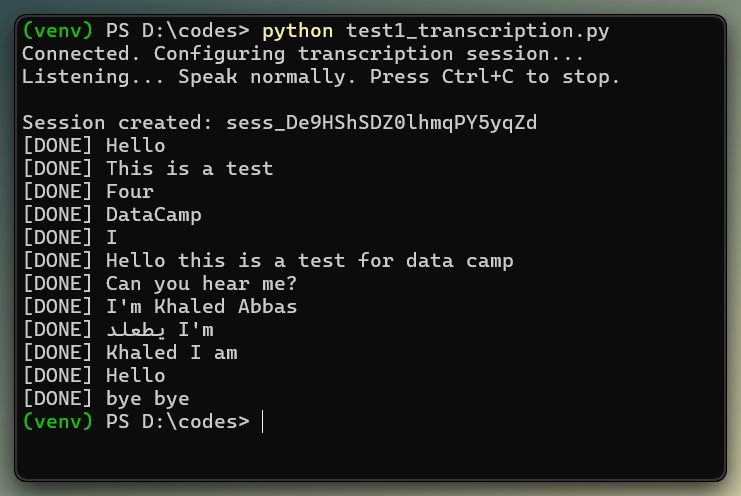
ws.send(json.dumps({"type": "input_audio_buffer.commit"}))Folosiți audio PCM16 mono la 24 kHz, codat base64. Spre deosebire de sesiunea asistentului vocal, scriptul finalizează manual bufferul de intrare la un interval de timp, în loc să folosească detecția de tăcere server_vad. Finalizările goale declanșează input_audio_buffer_commit_empty, motiv pentru care scriptul complet finalizează doar după ce a fost trimis audio real.
Delta-urile de transcript sosesc cuvânt cu cuvânt în timp real. Imagine de autor.
În testele locale, rezultatele transcrierii au apărut în fereastra de commit, la aproximativ 3–4 secunde după începerea vorbirii. Deoarece această configurare se bazează pe finalizări manuale, nu pe VAD, latența este legată de intervalul de commit.
De asemenea, atenție la ordonare: evenimentele de finalizare din ture suprapuse pot sosi în altă ordine, așa că reconciliați după item_id dacă construiți o interfață în jurul fluxului.
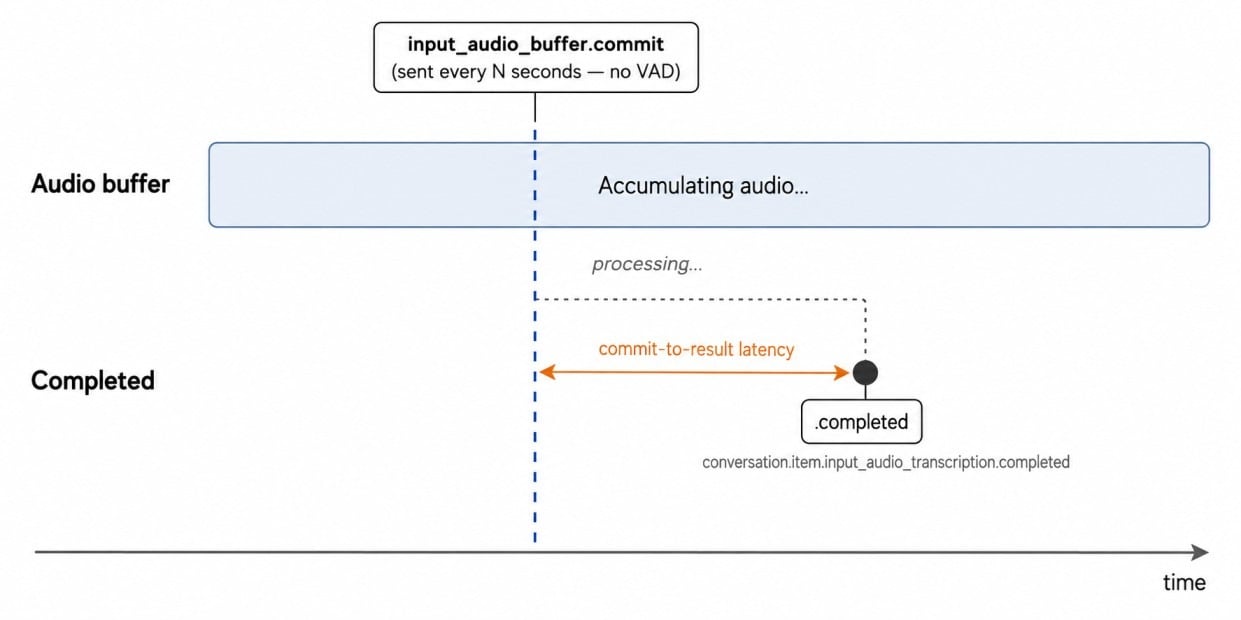
Transcrierea este declanșată de un commit manual periodic, nu de detecția tăcerii. Imagine de autor.
Verdict: Reușit. Pentru transcriere live pe server, gpt-realtime-whisper a făcut ce trebuia în acest test. Tot aș testa cu microfoane reale, accente și zgomot de cameră înainte de a stabili o țintă de latență.
Traducerea vorbirii live arată la început similar cu transcrierea, dar ciclul sesiunii este diferit. Endpointul de traducere elimină bucla de răspuns a asistentului, ceea ce face exemplul mai scurt.
Sesiunile de traducere nu au buclă de ture ale asistentului și nu au response.create. Modelul funcționează ca un interpret live, nu ca un agent conversațional. Pentru întrebări-răspunsuri, unelte sau stare conversațională, articolul trece la gpt-realtime-2 în Testul 3.
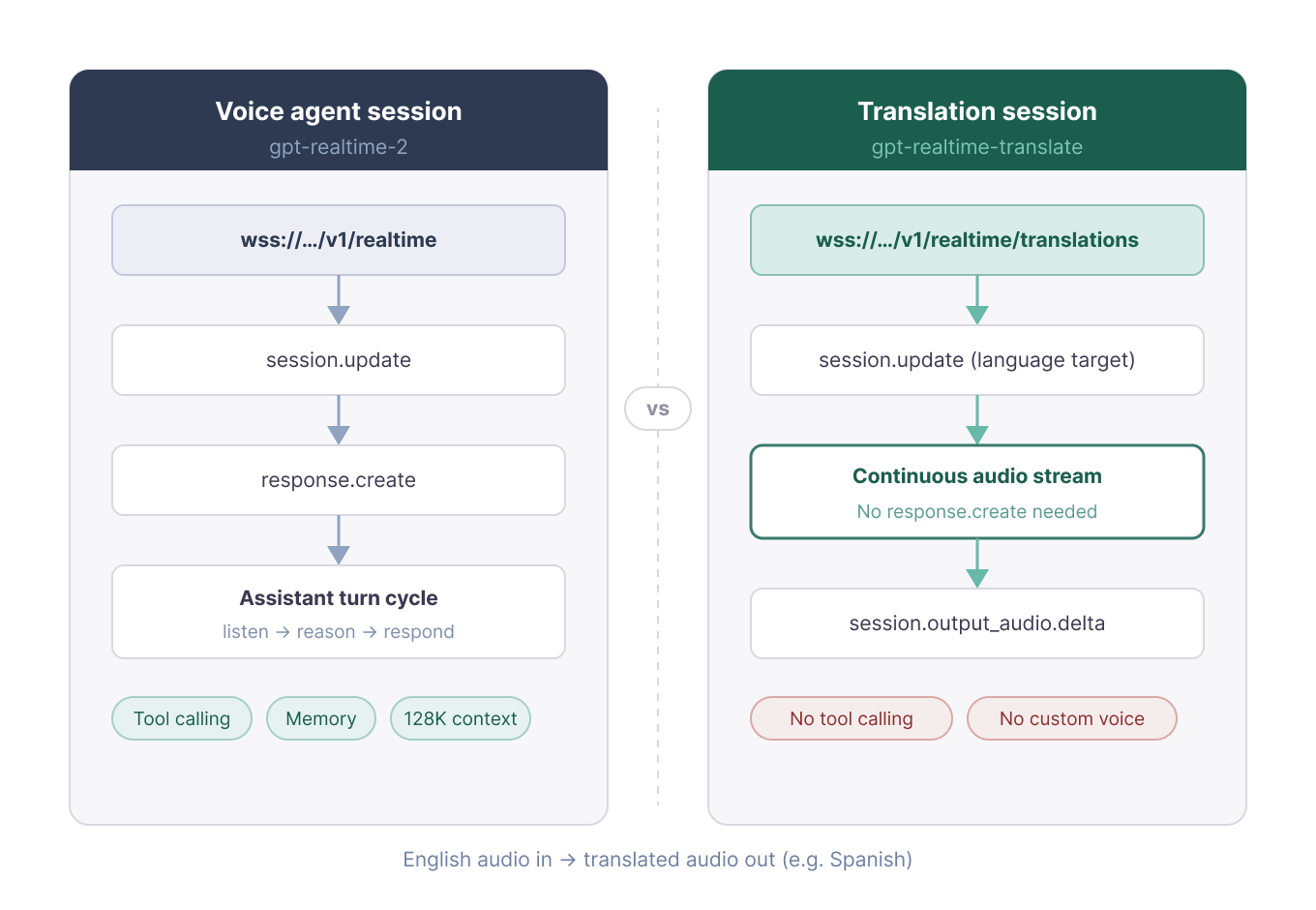
Sesiunile de traducere folosesc un endpoint dedicat, separat. Imagine de autor.
Modelul acceptă peste 70 de limbi de intrare și 13 limbi de ieșire. Setați ținta cu session.audio.output.language; detectarea limbii sursă este automată. Limitările sunt clare: fără prompting personalizat, fără selecție de voce și fără glosare de domeniu.
După cum s-a menționat, traducerea folosește URL-ul WebSocket /translations. Alte două detalii se schimbă: câmpul țintă session.audio.output.language și numele evenimentului session.input_audio_buffer.append. Observați prefixul session.. Sesiunile de traducere îl folosesc aici.
url = "wss://api.openai.com/v1/realtime/translations?model=gpt-realtime-translate"
session_config = {
"type": "session.update",
"session": {
"audio": {
"output": {"language": "es"},
"input": {
"transcription": {"model": "gpt-realtime-whisper"},
"noise_reduction": {"type": "near_field"}
}
}
}
}
ws.send(json.dumps(session_config))
ws.send(json.dumps({
"type": "session.input_audio_buffer.append",
"audio": audio_b64
}))Audio tradus sosește pe session.output_audio.delta, iar octeții audio se află în event["delta"], nu în event["audio"]. Transcriptul sursă și cel tradus sosesc separat:
if event_type == "session.output_audio.delta":
audio_out_queue.put(base64.b64decode(event["delta"]))
elif event_type == "session.input_transcript.delta":
print("[EN]", event.get("delta", ""), end="")
elif event_type == "session.output_transcript.delta":
print("[ES]", event.get("delta", ""), end="")Un caz de margine: dacă audio-ul sursă este deja în limba țintă, modelul poate produce tăcere în loc să îl lase să treacă.
Pentru expresii scurte din engleză în spaniolă, audio-ul tradus a început înainte ca enunțul sursă să se termine. Terminalul a afișat linii [EN] și [ES] intercalate pe măsură ce veneau delta-urile. Perechile de limbi mai îndepărtate pot aștepta mai mult pentru context. Am putut urmări vocea tradusă fără probleme, dar selecția de voce personalizată nu este disponibilă.
Verdict: Reușit, cu o rezervă. gpt-realtime-translate a funcționat pentru traducere live directă. Este mai puțin util când contează controlul terminologiei sau identitatea vocală.
Acesta este testul gpt-realtime-2: un agent vocal care ascultă, vorbește, păstrează context și poate apela unelte. Este și punctul în care codul clientului începe să conteze mai mult, deoarece redarea și starea turelor pot ieși din sincron.
gpt-realtime-2 este un model de raționare vorbire-la-vorbire. Evită un pipeline separat STT-LLM-TTS, iar fereastra de context de 128K oferă mai mult spațiu sesiunilor lungi. Raționarea este controlată cu reasoning.effort; începeți la low dacă sarcina nu are nevoie de mai multă raționare, deoarece setările mai ridicate adaugă latență.
Configurația de mai jos folosește semantic_vad, care se uită la indicii de vorbire, nu doar la tăcere. eagerness controlează cât de repede modelul decide că utilizatorul a terminat. Părțile de observat sunt numele modelului, setările de ieșire audio, response.create manual și numele evenimentului de audio al asistentului:
session_config = {
"type": "session.update",
"session": {
"type": "realtime",
"model": "gpt-realtime-2",
"output_modalities": ["audio"],
"audio": {
"input": {
"format": {"type": "audio/pcm", "rate": 24000},
"transcription": {"model": "gpt-realtime-whisper", "language": "en"},
"turn_detection": {
"type": "semantic_vad",
"eagerness": "medium",
"create_response": False,
"interrupt_response": True
}
},
"output": {
"format": {"type": "audio/pcm", "rate": 24000},
"voice": "marin"
}
},
"instructions": "You are a helpful voice assistant. Keep answers short.",
"reasoning": {"effort": "low"}
}
}Când transcriptul utilizatorului se încheie, clientul creează răspunsul asistentului. Audio-ul asistentului sosește apoi ca response.output_audio.delta, nu response.audio.delta.
if event_type == "conversation.item.input_audio_transcription.completed":
ws.send(json.dumps({"type": "response.create"}))
elif event_type == "response.output_audio.delta":
audio_out_queue.put(base64.b64decode(event["delta"]))Secvența de întrerupere este ușor de greșit. Când utilizatorul vorbește peste asistent, serverul trimite input_audio_buffer.speech_started. Clientul oprește redarea, înregistrează cât audio a redat și trimite conversation.item.truncate cu audio_end_ms pentru a ține evidența unde a fost tăiat. Altfel, serverul continuă să transcrie text pe care utilizatorul nu l-a auzit, iar următoarea tură poate părea deplasată.
if current_response_item_id and playback_position_ms > 0:
ws.send(json.dumps({
"type": "conversation.item.truncate",
"item_id": current_response_item_id,
"content_index": 0,
"audio_end_ms": playback_position_ms
}))O problemă practică cu difuzoarele laptopului: microfonul poate prelua ieșirea audio a asistentului și o poate trimite înapoi modelului. Scriptul de exemplu folosește MUTE_MIC_DURING_ASSISTANT = True pentru a reduce la tăcere fluxul de intrare cât timp vorbește asistentul și pentru o scurtă perioadă după. Setați pe False doar dacă folosiți căști și doriți suport pentru întrerupere.
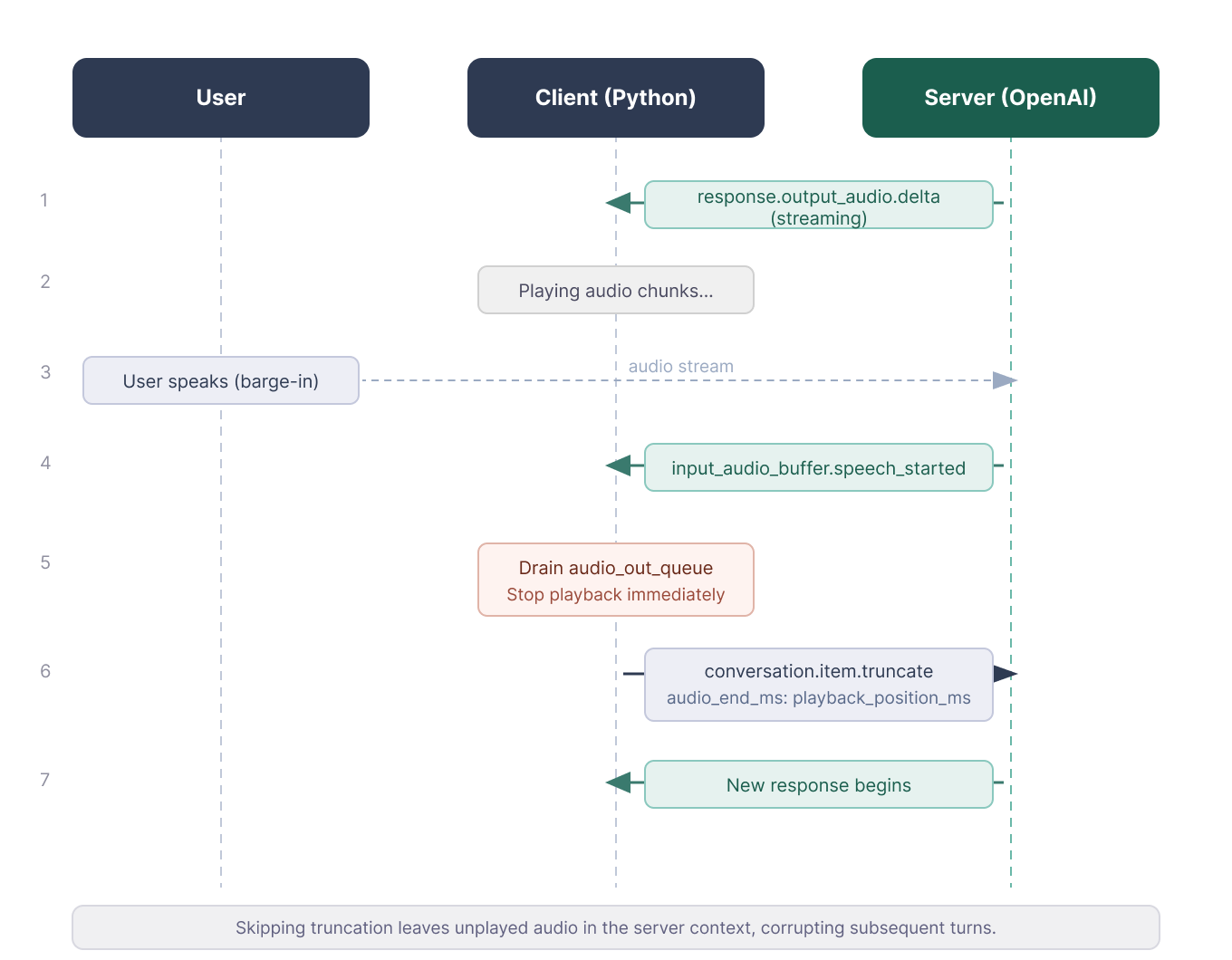
Trunchierea menține serverul și clientul sincronizate. Imagine de autor.
WebRTC și SIP gestionează mai mult din această bufferizare. Cu calea WebSocket folosită în acest tutorial, responsabilitatea este la client. Contorul din scriptul de exemplu este suficient pentru un demo; codul de producție ar trebui să urmărească timestampuri din fluxul de ieșire audio.
Când reasoning.effort este peste low, tăcerea devine sesizabilă. Pot fi adăugate preambuluri vorbite scurte în promptul de sistem:
# Preambles
Use a short spoken update before longer tasks.
Keep preambles under five seconds.
Skip preambles for short factual questions.Acest comportament este documentat pentru gpt-realtime-2.
Luarea pe rând a funcționat la setările implicite într-o cameră liniștită. Cu difuzoare de laptop, a fost nevoie să reduc volumul microfonului; fără aceasta, modelul își auzea propria ieșire și pornea o buclă de ecou.
În încăperi mai zgomotoase, setările VAD și amplasarea microfonului au contat mai mult. Memoria conversației a rămas consecventă pe parcursul unui test de zece minute, dar nu aș livra o aplicație mai lungă fără un plan de reconectare.
Verdict: Reușit pentru bucla vocală de bază. gpt-realtime-2 a gestionat un asistent cu efort redus de raționare în testul meu. Munca suplimentară este la client: redare, gestionarea întreruperilor, reconectări și apeluri de unelte dacă aplicația are nevoie.
Aplicația Streamlit pune testele în spatele unui selector de file. Vă permite să înregistrați audio, să alegeți o limbă țintă și să comparați căile modelelor fără a edita scripturi. Am păstrat aceasta ca aplicație demo, nu ca principala cale didactică, deoarece scripturile din terminal arată mai direct evenimentele.
Trei modele într-o interfață cu file. Imagine de autor.
Videoclipul demo de mai jos arată filele cu o cheie API live. Fiecare filă folosește apeluri Realtime WebSocket reale.
Rulați aplicația din același folder ca scripturile:
streamlit run demo_app.pyCheia dumneavoastră API se introduce în bara laterală și nu este stocată nicăieri. Pentru o aplicație publică, puneți-o în Streamlit Secrets.
După cum s-a menționat în Testul 1, prețurile se împart în două grupe: gpt-realtime-2 este tarifat pe token, în timp ce traducerea și transcrierea sunt tarifate pe minut.
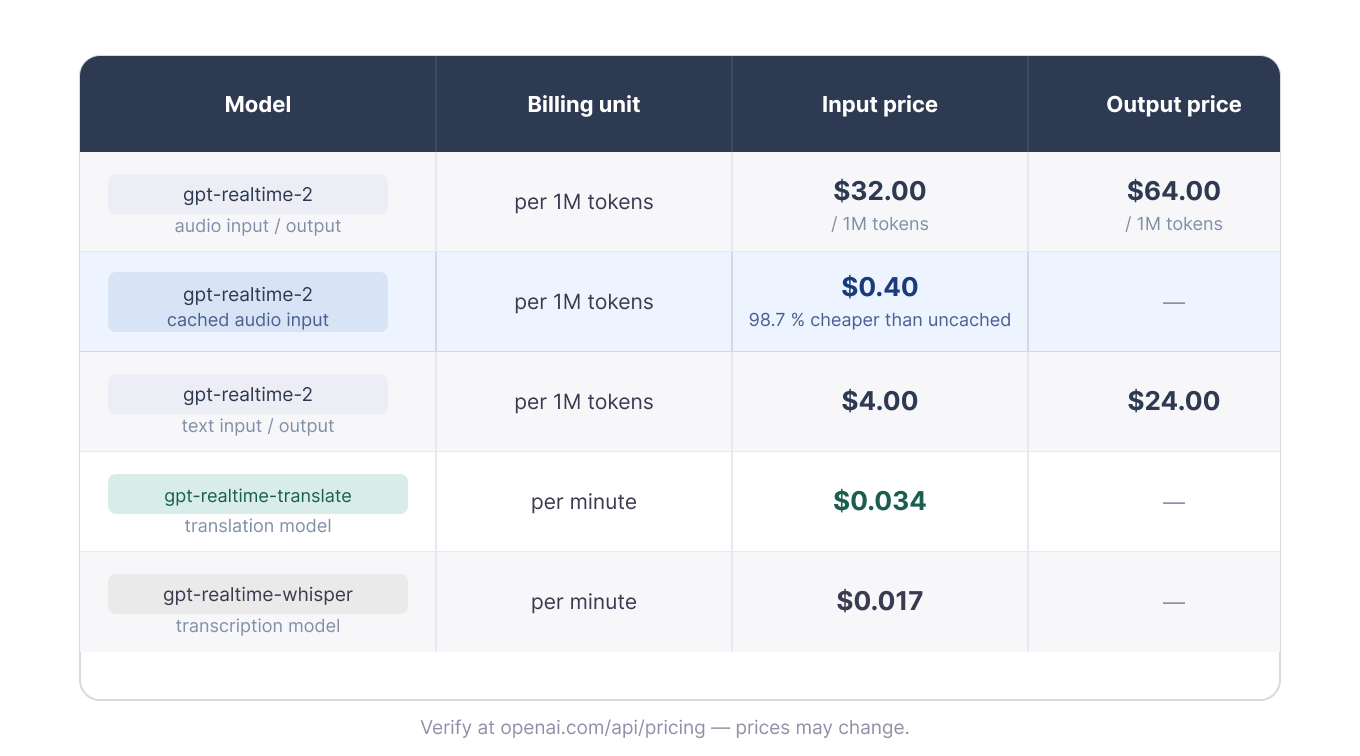
Taxare pe token și pe minut în funcție de model. Imagine de autor.
Pentru transcriere și traducere, costul scalează cu durata. La momentul scrierii, treizeci de minute costă aproximativ 0,51 $ pe gpt-realtime-whisper și aproximativ 1,02 $ pe gpt-realtime-translate.
Agenții vocali sunt mai greu de estimat deoarece tokenii audio se acumulează de ambele părți ale conversației. Lungimea sesiunii, raportul de vorbire, efortul de raționare și dimensiunea contextului contează toate. Cache-ul de prompt poate reduce costul când turele anterioare ale conversației rămân stabile.
Un apel REST de transcriere plus TTS este o comparație diferită, cu excepția cazului în care este necesară interacțiunea live. whisper-1 este mai ieftin pentru fișiere, dar nu este același tip de API.
Acestea sunt limitele care au afectat primele mele rulări de test. Majoritatea eșecurilor au venit din greșeli de formatare audio sau de ciclu de viață al sesiunii, nu din modelul în sine.
După cum s-a menționat în primul test, audio-ul pe WebSocket ar trebui să fie PCM16 la 24 kHz, mono și codat base64. Fiecare eveniment input_audio_buffer.append este limitat la 15 MB, astfel încât fragmentele de 50 de milisecunde rămân mult sub limită. G.711 este de asemenea acceptat pentru telefonie.
Sesiunile Realtime se încheie după 60 de minute pe OpenAI și 30 de minute pe Azure OpenAI. Aplicațiile mai lungi au nevoie de un plan de reconectare și o modalitate de a reconstrui starea. Vocea trebuie, de asemenea, aleasă înainte de prima ieșire audio; nu poate fi schimbată în timpul sesiunii.
Limitele de rată sunt pe nivel și specifice proiectului. Nivelul 1 listează în prezent 200 de cereri pe minut și 40.000 de tokeni pe minut pentru gpt-realtime-2. Nivelul Gratuit nu este acceptat.
Erorile pe care le-am întâlnit cel mai des au fost commituri de buffer goale și formatare audio greșită. Pentru agenții vocali, urmăriți și buclele de feedback în care microfonul aude ieșirea difuzorului asistentului. Folosiți căști, anulare ecou sau dezactivarea microfonului.
Pentru sesiuni lungi, reconectați-vă în jur de 55 de minute în loc să așteptați expirarea. O particularitate din documentație: pagina modelului gpt-realtime-2 are un rând generic „Streaming: Not supported”, în timp ce ghidurile Realtime documentează utilizarea /v1/realtime. Acel rând se referă la streamingul din Chat Completions, nu la comportamentul Realtime API.
Același tipar apare în cele trei teste: fiecare sarcină are propriul model și propriul endpoint. Această împărțire afectează ce poate face modelul, cum este tarifat și cât cod pe client trebuie să gestionați.
După cum s-a arătat, gpt-realtime-whisper acoperă textul live, gpt-realtime-translate acoperă traducerea directă a vorbirii, iar gpt-realtime-2 acoperă comportamentul de asistent cu vorbire, raționare și context.
Codul nu arată un model înlocuindu-le pe celelalte. Arată că aplicațiile de voce în timp real depind de designul sesiunii. Punctul meu de plecare ar fi cel mai mic model care se potrivește sarcinii, cu timpul de inginerie rămas petrecut pe calitatea audio, luarea pe rând, reconectări și starea clientului.
Pentru mai mult context, tutorialele noastre acoperă subiecte conexe despre audio și API-ul în timp real:
Învățați AI cu DataCamp!
course
course
course