Course
Developing AI Systems with the OpenAI API
3 ч
20.8K
Наш обзор GPT-Realtime-2 охватил запуск, заявленные бенчмарки и то, почему OpenAI разделила режим реального времени по голосу на небольшую линейку моделей. Этот учебник продолжает с того места, где остановилась статья: подключение к API, передача аудио и изменения в коде.
На практике разделение важно. Тест 1 использует gpt-realtime-whisper для транскрибации, Тест 2 — gpt-realtime-translate для синхронного перевода, а Тест 3 — gpt-realtime-2 для голосового ассистента. Основная модель тоже справится с более простыми задачами вроде перевода или транскрибации, но вы будете платить за уровень рассуждений и режимы ответа, которые не нужны, так что это будет избыточно.
Перед тестами полезно разделить транспорт, аутентификацию и аудиоформат. Эти детали в основном одинаковы во всех примерах. Меняются конечные точки моделей и имена событий по мере того, как мы переходим от текстового вывода к переведённой речи, а затем к полному голосовому циклу.
В документации OpenAI дана простая рекомендация: используйте WebRTC для браузера и мобильных клиентов, а WebSocket — для серверных приложений. WebRTC берёт на себя буферизацию джиттера и транспорт аудио. WebSocket уместен, когда бэкенд уже получает сырое аудио от телефонии или медиа-пайплайна.
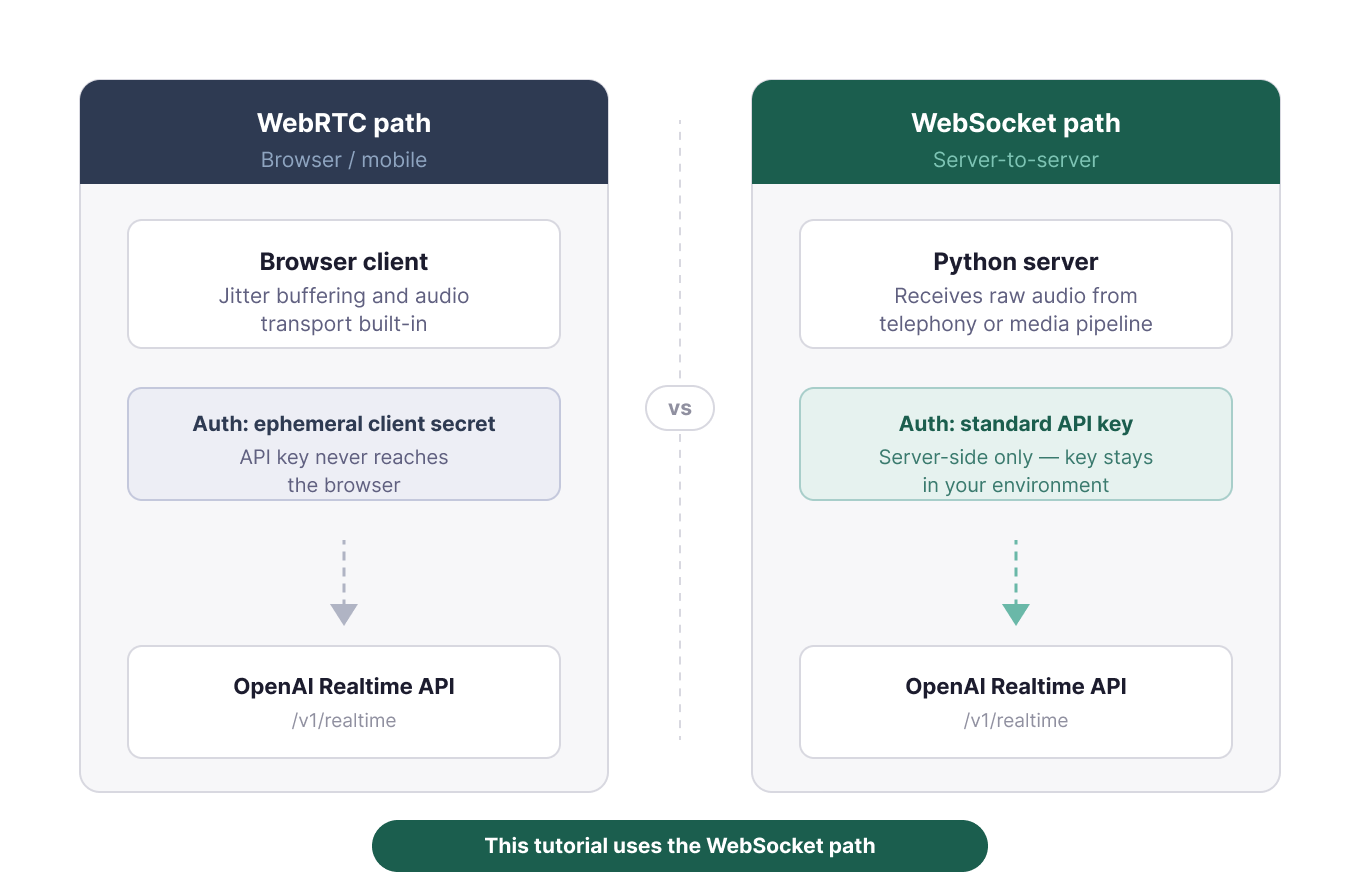
Два транспортных пути для Realtime API. Изображение автора.
По этой причине все три Python‑теста используют WebSocket. Этот путь показывает имена событий напрямую, поэтому различия между моделями видны в коде. Для браузера используйте эфемерные клиентские секреты, чтобы ваш ключ API не попадал на фронтенд.
Используйте Python 3.9 или новее. Полный код всех четырёх скриптов доступен на github.com/KhalidAbdelaty/gpt-realtime-api. Склонируйте репозиторий, затем установите зависимости:
git clone https://github.com/KhalidAbdelaty/gpt-realtime-api.git
cd gpt-realtime-api
pip install websocket-client sounddevice numpy python-dotenvwebsocket-client управляет сокетом. sounddevice захватывает звук с микрофона, numpy конвертирует буфер, а python-dotenv загружает ключ API. На macOS может понадобиться brew install portaudio перед тем, как заработает sounddevice. В Linux установите portaudio19-dev.
Создайте файл .env в корне проекта:
OPENAI_API_KEY=sk-...Затем загрузите его в каждом скрипте:
import os
from dotenv import load_dotenv
load_dotenv()
OPENAI_API_KEY = os.environ.get("OPENAI_API_KEY")Серверные подключения используют заголовок Authorization: Bearer при рукопожатии WebSocket. Добавьте OpenAI-Safety-Identifier, если приложение отслеживает отдельных пользователей. Ниже пути, которые используются далее в тестах:
# Voice agent
wss://api.openai.com/v1/realtime?model=gpt-realtime-2
# Translation
wss://api.openai.com/v1/realtime/translations?model=gpt-realtime-translate
# Transcription
wss://api.openai.com/v1/realtime?intent=transcriptionЭтот путь для перевода важен в Тесте 2, потому что это единственная конечная точка, которая не использует /v1/realtime напрямую.
Транскрибацию часто излишне усложняют. Если на выходе нужен только текст, достаточно модели для транскрибации.
gpt-realtime-whisper принимает аудио и выдаёт дельты транскрипта. Она не рассуждает, не вызывает инструменты и не отвечает голосом. Благодаря меньшему объёму задач тарификация идёт по длительности аудио, а не по токенам, как у gpt-realtime-2. К вопросу стоимости вернёмся позже.
Ключевое поле — session.type: "transcription". Оно говорит API не формировать ответы ассистента и выдавать только события транскрипта. Полный скрипт также обрабатывает захват микрофона и потоки. Ниже часть, которая меняет поведение Realtime‑сессии:
session_config = {
"type": "session.update",
"session": {
"type": "transcription",
"audio": {
"input": {
"format": {"type": "audio/pcm", "rate": 24000},
"transcription": {
"model": "gpt-realtime-whisper",
"language": "en"
},
"turn_detection": None
}
}
}
}
ws.send(json.dumps(session_config))
ws.send(json.dumps({
"type": "input_audio_buffer.append",
"audio": audio_b64
}))
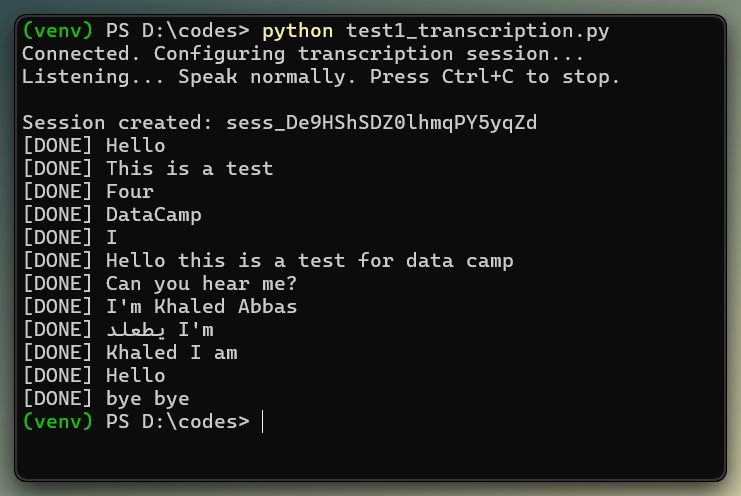
ws.send(json.dumps({"type": "input_audio_buffer.commit"}))Используйте моно-аудио PCM16 24 кГц, закодированное в base64. В отличие от сессии голосового агента, здесь входной буфер коммитится вручную по таймеру, а не через обнаружение очереди по server_vad. Пустые коммиты вызывают input_audio_buffer_commit_empty, поэтому полный скрипт коммитит только после отправки реального аудио.
Дельты транскрипта приходят слово за словом в реальном времени. Изображение автора.
В моих локальных тестах результаты транскрипции появлялись в пределах окна коммита — примерно через 3–4 секунды после начала речи. Поскольку тут используются ручные коммиты, а не VAD, задержка зависит от интервала коммита.
Следите за порядком: события завершения из перекрывающихся очередей могут приходить не по порядку, поэтому, если вы строите UI вокруг потока, сводите их по item_id.
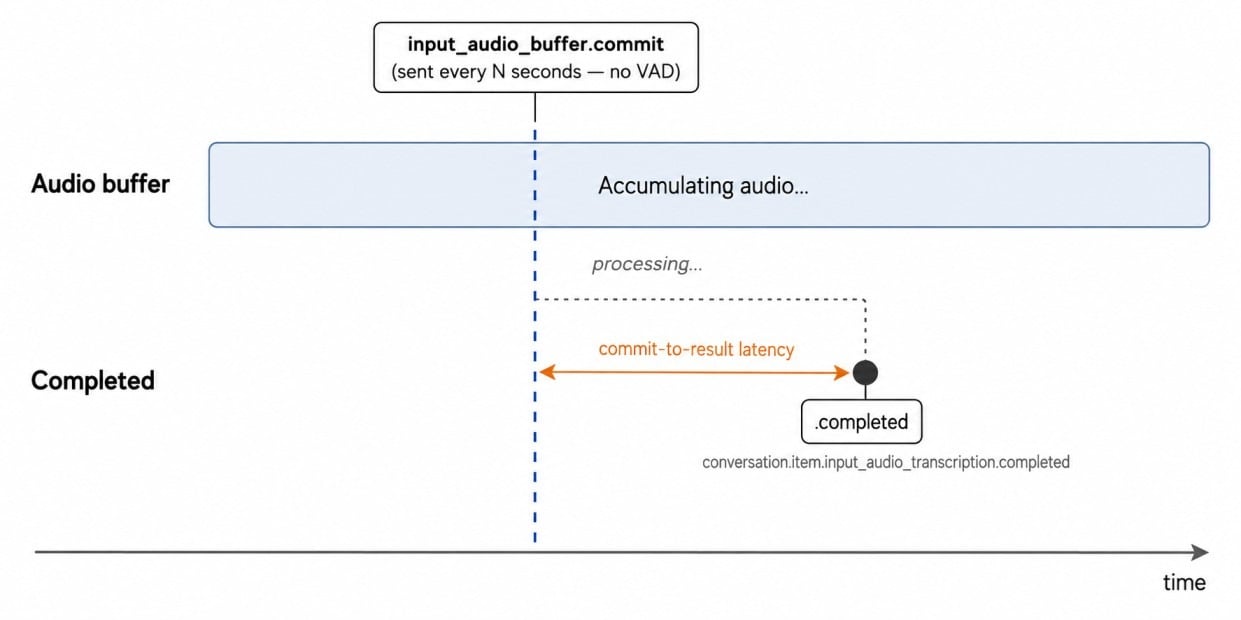
Транскрибация запускается периодическим ручным коммитом, а не детекцией пауз. Изображение автора.
Вердикт: зачёт. Для серверной транскрибации в реальном времени gpt-realtime-whisper сделал всё, что требовалось. Я бы всё же протестировал реальные микрофоны, акценты и шумы помещений перед установкой целевой задержки.
На первый взгляд перевод живой речи похож на транскрибацию, но жизненный цикл сессии другой. Конечная точка перевода убирает цикл ответов ассистента, поэтому пример короче.
В сессиях перевода нет очередей ассистента и нет response.create. Модель работает как синхронный переводчик, а не как разговорный агент. Для вопросов-ответов, инструментов или состояния беседы в Тесте 3 статья переходит на gpt-realtime-2.
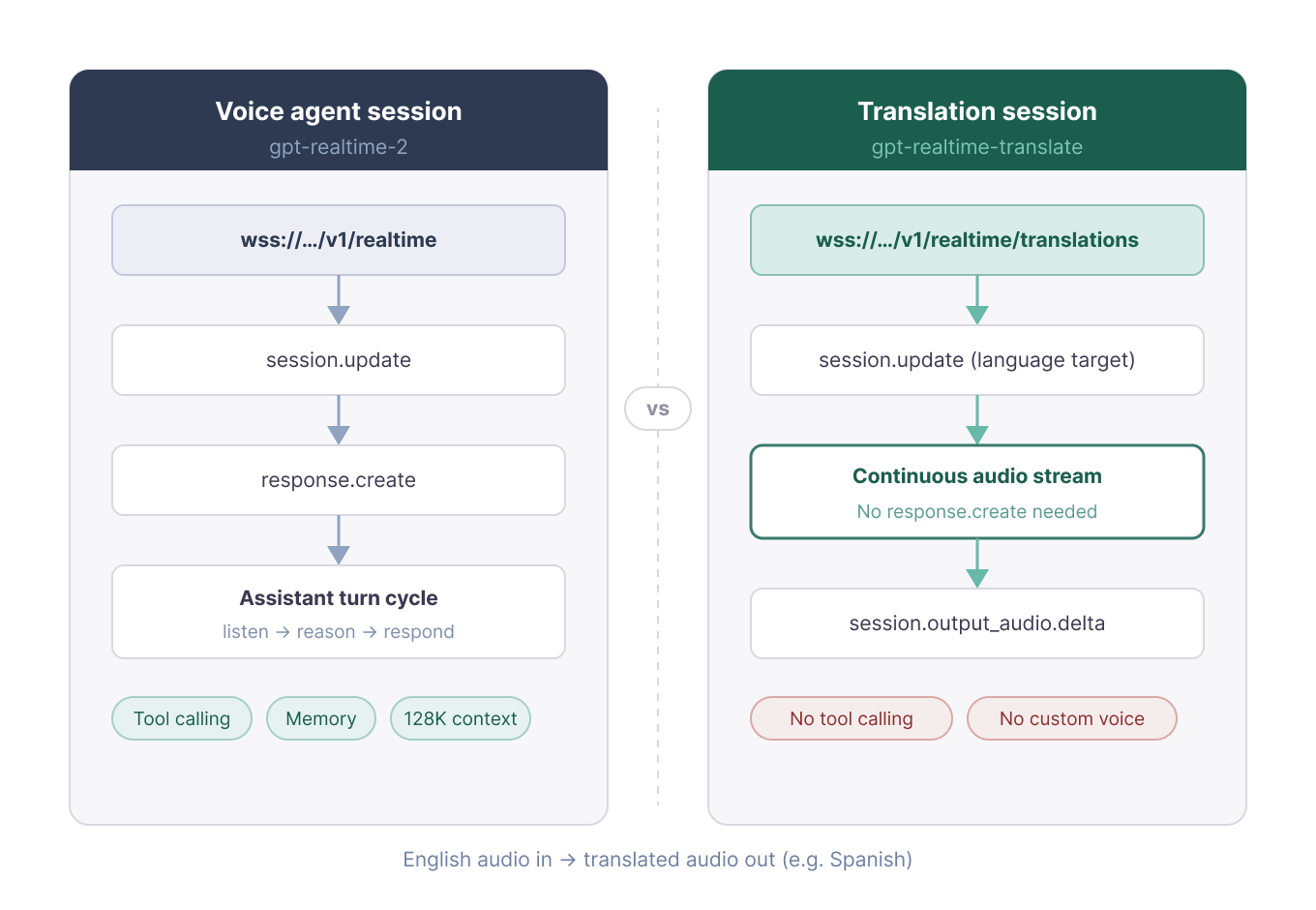
Сессии перевода используют отдельную специализированную конечную точку. Изображение автора.
Модель поддерживает более 70 языков на входе и 13 языков на выходе. Целевой язык задаётся в session.audio.output.language; определение исходного выполняется автоматически. Ограничения простые: нет кастомных промптов, выбора голоса и предметных глоссариев.
Как отмечалось, перевод использует URL WebSocket с /translations. Меняются ещё две детали: поле цели session.audio.output.language и имя события session.input_audio_buffer.append. Обратите внимание на префикс session.. В сессиях перевода он используется здесь.
url = "wss://api.openai.com/v1/realtime/translations?model=gpt-realtime-translate"
session_config = {
"type": "session.update",
"session": {
"audio": {
"output": {"language": "es"},
"input": {
"transcription": {"model": "gpt-realtime-whisper"},
"noise_reduction": {"type": "near_field"}
}
}
}
}
ws.send(json.dumps(session_config))
ws.send(json.dumps({
"type": "session.input_audio_buffer.append",
"audio": audio_b64
}))Переведённое аудио приходит в событии session.output_audio.delta, и байты находятся в event["delta"], а не в event["audio"]. Исходный и переведённый транскрипты приходят раздельно:
if event_type == "session.output_audio.delta":
audio_out_queue.put(base64.b64decode(event["delta"]))
elif event_type == "session.input_transcript.delta":
print("[EN]", event.get("delta", ""), end="")
elif event_type == "session.output_transcript.delta":
print("[ES]", event.get("delta", ""), end="")Один крайний случай: если исходное аудио уже на целевом языке, модель может выдать тишину вместо пропуска без изменений.
Для коротких английско‑испанских фраз переведённое аудио начиналось ещё до завершения исходной реплики. В терминале шли вперемешку строки [EN] и [ES] по мере поступления дельт. Для более дальних языковых пар ожидание контекста может быть дольше. Следить за переведённым голосом было несложно, но выбор кастомного голоса недоступен.
Вердикт: зачёт, с оговоркой. gpt-realtime-translate сработал для прямого синхронного перевода. Менее полезен там, где важны контроль терминологии или брендовый голос.
Это тест gpt-realtime-2: голосовой агент, который слушает, говорит, держит контекст и может вызывать инструменты. Здесь также клиентский код начинает играть большую роль, потому что воспроизведение и состояние очередей могут рассинхронизироваться.
gpt-realtime-2 — модель «речь‑в‑речь» с рассуждениями. Она избегает отдельного конвейера STT→LLM→TTS, а окно контекста 128K даёт больше пространства для длинных сессий. Рассуждения управляются через reasoning.effort; начинайте с low, если задаче не нужно больше рассуждений, потому что более высокие значения добавляют задержку.
Ниже используется semantic_vad, который ориентируется на речевые признаки, а не только на тишину. eagerness управляет тем, как быстро модель решает, что пользователь закончил. Обратите внимание на имя модели, параметры аудиовыхода, ручной response.create и имя события с аудио ассистента:
session_config = {
"type": "session.update",
"session": {
"type": "realtime",
"model": "gpt-realtime-2",
"output_modalities": ["audio"],
"audio": {
"input": {
"format": {"type": "audio/pcm", "rate": 24000},
"transcription": {"model": "gpt-realtime-whisper", "language": "en"},
"turn_detection": {
"type": "semantic_vad",
"eagerness": "medium",
"create_response": False,
"interrupt_response": True
}
},
"output": {
"format": {"type": "audio/pcm", "rate": 24000},
"voice": "marin"
}
},
"instructions": "You are a helpful voice assistant. Keep answers short.",
"reasoning": {"effort": "low"}
}
}Когда транскрипт пользователя завершён, клиент создаёт ответ ассистента. Аудио ассистента приходит как response.output_audio.delta, а не response.audio.delta.
if event_type == "conversation.item.input_audio_transcription.completed":
ws.send(json.dumps({"type": "response.create"}))
elif event_type == "response.output_audio.delta":
audio_out_queue.put(base64.b64decode(event["delta"]))Последовательность прерывания легко сделать неправильно. Когда пользователь говорит поверх ассистента, сервер шлёт input_audio_buffer.speech_started. Клиент останавливает воспроизведение, фиксирует, сколько аудио было проиграно, и отправляет conversation.item.truncate с audio_end_ms, чтобы зафиксировать точку обрезки. Иначе сервер продолжит транскрибировать текст, который пользователь не слышал, и следующий ход может «поехать».
if current_response_item_id and playback_position_ms > 0:
ws.send(json.dumps({
"type": "conversation.item.truncate",
"item_id": current_response_item_id,
"content_index": 0,
"audio_end_ms": playback_position_ms
}))Практическая проблема с динамиками ноутбука: микрофон может подхватить звук ассистента и отправить его обратно в модель. В примерном скрипте используется MUTE_MIC_DURING_ASSISTANT = True, чтобы заглушать входной поток, пока говорит ассистент, и ещё короткое время после. Ставьте False только если вы в наушниках и хотите поддерживать прерывания.
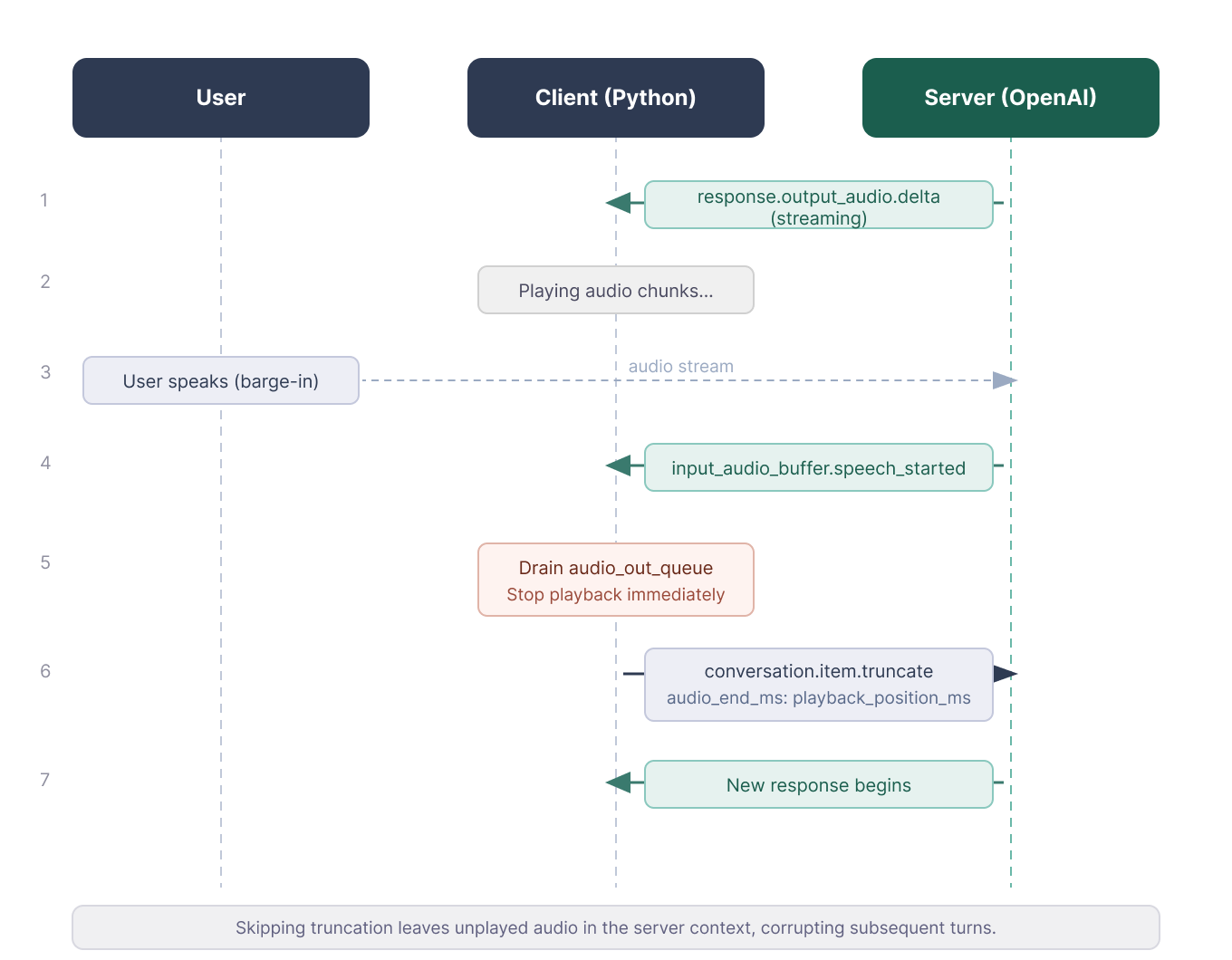
Обрезка держит сервер и клиент в синхронизации. Изображение автора.
WebRTC и SIP берут на себя больше буферизации. В пути WebSocket, который используется в этом учебнике, за это отвечает клиент. Счётчик в примере достаточен для демо; в продакшене следует отслеживать временные метки из аудиовыходного потока.
Когда reasoning.effort выше low, паузы становятся заметны. Можно добавить короткие устные преамбулы в системный промпт:
# Preambles
Use a short spoken update before longer tasks.
Keep preambles under five seconds.
Skip preambles for short factual questions.Такое поведение задокументировано для gpt-realtime-2.
Очередность работала при настройках по умолчанию в тихой комнате. С динамиками ноутбука понадобилось заглушение микрофона; без него модель слышала свой же вывод и начиналась эхо‑петля.
В более шумных помещениях важнее становятся параметры VAD и расположение микрофона. Память беседы оставалась согласованной в десятиминутном тесте, но я бы не выпускал более длинное приложение без плана переподключения.
Вердикт: зачёт для базового голосового цикла. gpt-realtime-2 справился с ассистентом с низкой нагрузкой на рассуждения в моём тесте. Дополнительная работа — на клиенте: воспроизведение, обработка прерываний, переподключения и вызовы инструментов, если они нужны.
Приложение Streamlit прячет тесты за переключателем вкладок. Оно позволяет записать аудио, выбрать целевой язык и сравнить пути моделей без правки скриптов. Я оставил это как демо, а не основную учебную тропу, поскольку терминальные скрипты нагляднее показывают события.
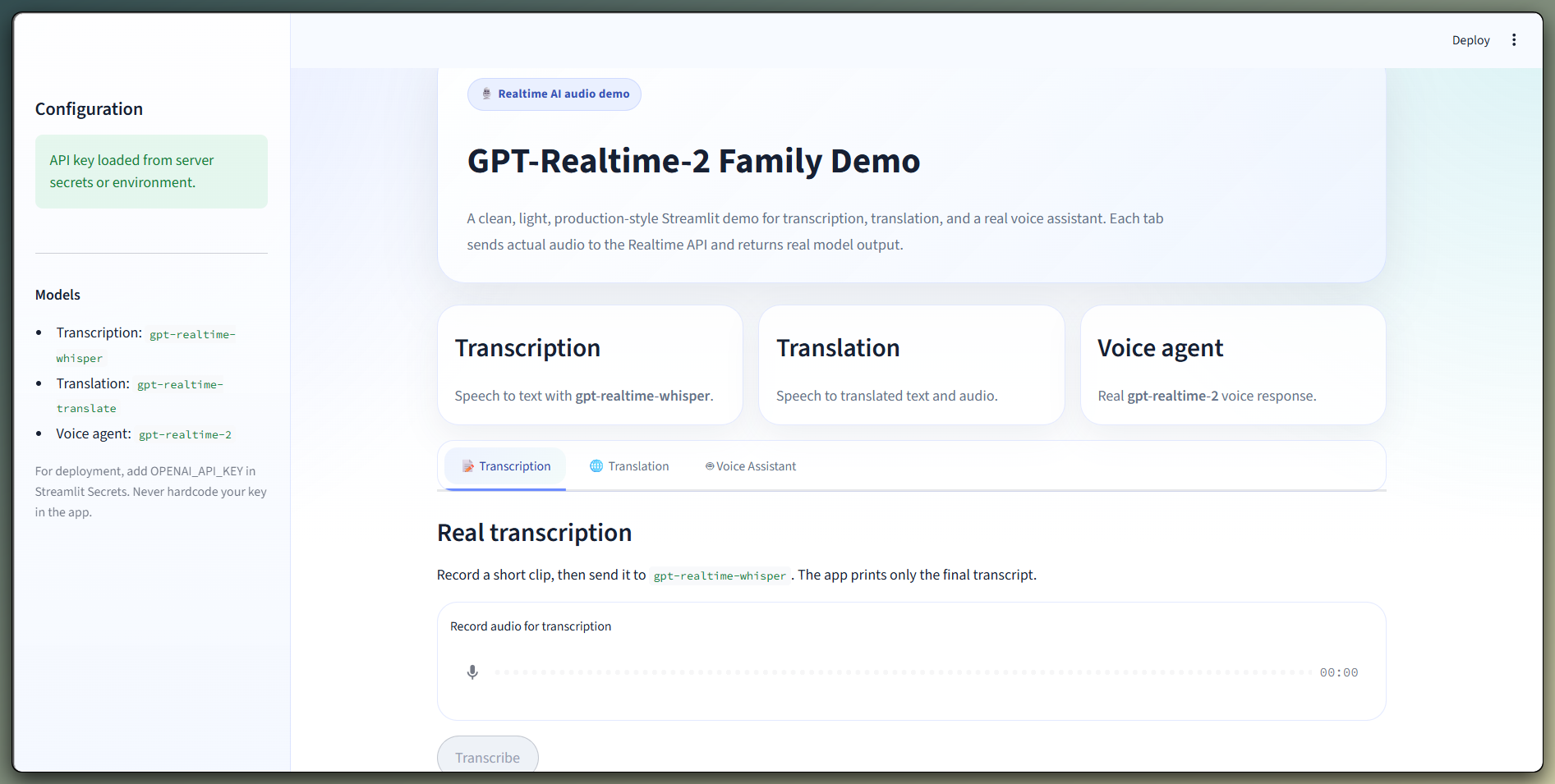
Три модели в одном интерфейсе с вкладками. Изображение автора.
Демонстрационное видео ниже показывает вкладки с живым ключом API. Каждая вкладка использует реальные вызовы Realtime WebSocket.
Запустите приложение из той же папки, что и скрипты:
streamlit run demo_app.pyВаш ключ API указывается в боковой панели и нигде не сохраняется. Для публичного приложения поместите его в Streamlit Secrets.
Как отмечалось в Тесте 1, цены делятся на две группы: gpt-realtime-2 тарифицируется по токенам, а перевод и транскрибация — поминутно.
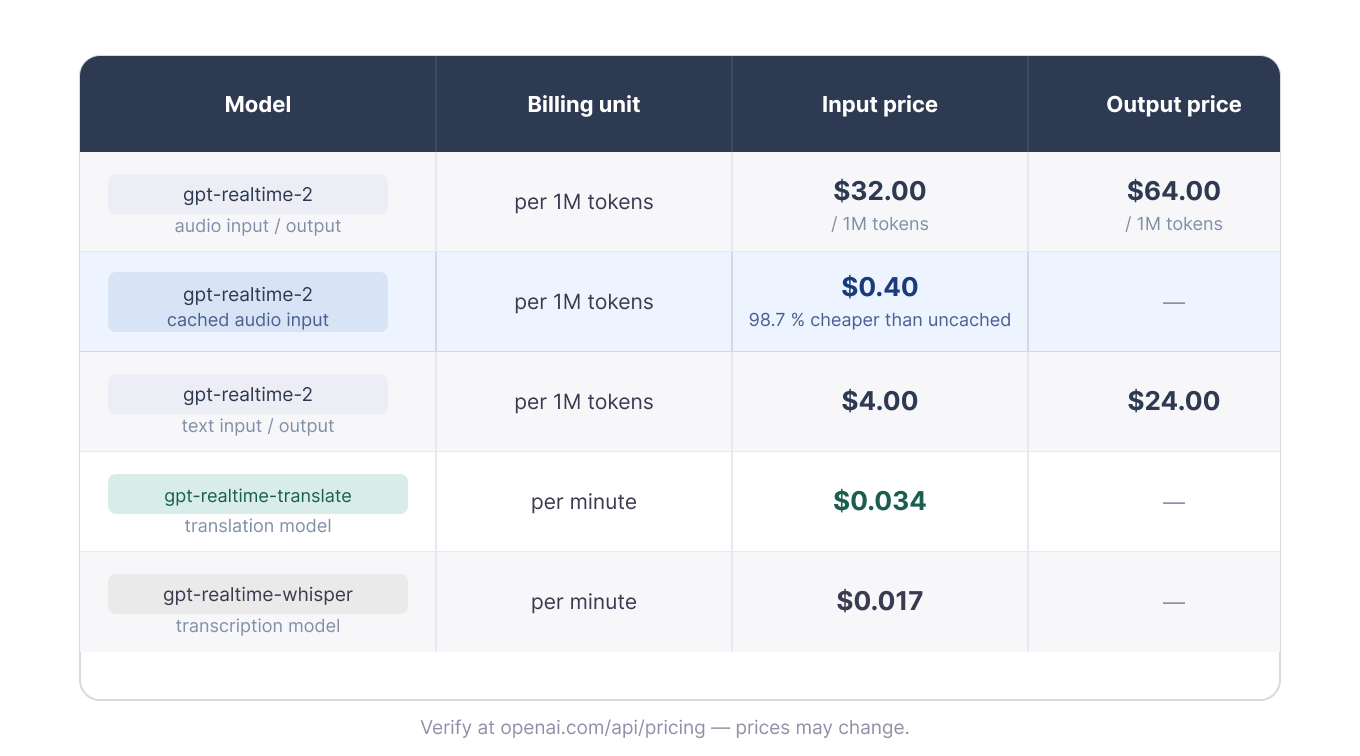
Тарификация по токенам и минутам в зависимости от модели. Изображение автора.
Для транскрибации и перевода стоимость масштабируется с длительностью. На момент написания тридцать минут стоят около $0.51 на gpt-realtime-whisper и около $1.02 на gpt-realtime-translate.
Оценивать голосовых агентов сложнее, потому что аудиотокены накапливаются с обеих сторон разговора. Важны длина сессии, доля говорящего времени, усилие рассуждений и размер контекста. Кэширование промптов может снизить расходы, если ранние ходы беседы остаются стабильными.
REST-вызов транскрибации плюс TTS — это другая плоскость сравнения, если не требуется взаимодействие в реальном времени. Для файлов whisper-1 дешевле, но это уже другой тип API.
Вот ограничения, которые повлияли на мои первые прогоны. Большинство сбоев были из‑за ошибок аудиоформата или жизненного цикла сессии, а не из‑за самой модели.
Как отмечалось в первом тесте, аудио по WebSocket должно быть PCM16 24 кГц, моно, в кодировке base64. Каждый input_audio_buffer.append ограничен 15 МБ, так что 50‑миллисекундные чанки остаются далеко ниже лимита. Для телефонии поддерживается и G.711.
Сессии Realtime завершаются через 60 минут в OpenAI и 30 минут в Azure OpenAI. Более длинным приложениям нужен план переподключения и способ восстановить состояние. Голос также нужно выбрать до первого аудиовывода; поменять его посреди сессии нельзя.
Лимиты зависят от уровня и проекта. В Tier 1 сейчас указано 200 запросов в минуту и 40 000 токенов в минуту для gpt-realtime-2. Бесплатный уровень не поддерживается.
Чаще всего у меня возникали ошибки пустых коммитов буфера и неверного аудиоформата. Для голосовых агентов следите также за петлями обратной связи, когда микрофон слышит звук динамиков ассистента. Используйте наушники, эхоподавление или заглушение микрофона.
Для длинных сессий переподключайтесь примерно на 55‑й минуте, не дожидаясь истечения. Одна нестыковка в доках: на странице модели gpt-realtime-2 есть общая строка «Streaming: Not supported», тогда как в руководствах по Realtime описано использование /v1/realtime. Эта строка относится к стримингу в Chat Completions, а не к поведению Realtime API.
Одна и та же закономерность прослеживается во всех трёх тестах: у каждой задачи — своя модель и конечная точка. Это влияет на возможности модели, тарификацию и объём клиентского кода, который вам придётся вести.
Как показано выше, gpt-realtime-whisper покрывает вывод в текст, gpt-realtime-translate — прямой перевод речи, а gpt-realtime-2 — поведение ассистента с речью, рассуждениями и контекстом.
Код не показывает, что одна модель заменяет другие. Он показывает, что голосовые приложения в реальном времени зависят от дизайна сессии. Я бы начинал с наименьшей модели, соответствующей задаче, а оставшееся время разработки тратил на качество аудио, очередность, переподключения и состояние клиента.
Для дополнительной справки наши учебники охватывают смежные темы аудио и Realtime API:
Изучайте ИИ с DataCamp!
Course
Course
Course