Courses
Rで学ぶ統計入門
4時間
130.2K
データが正規分布に従うなら、複数群の比較は簡単です。問題は、現実世界のデータの多くがそうではないことです。
ANOVA(分散分析)をデフォルトの検定にしてしまうと、データが正規分布に従うことを前提にしているため、誤った結論に至るおそれがあります。歪んだ分布や小標本など、その前提が満たされない場合は、別のアプローチが必要です。
Kruskal–Wallis検定は、その別のアプローチです。ANOVAのノンパラメトリックな代替であり、生の値ではなく順位に基づいてデータを扱うため、正規分布を仮定しません。
本記事では、その考え方や数式、PythonとRでの実行方法、結果の解釈について解説します。
Kruskal–Wallis検定は、3つ以上の独立した群を比較するためのノンパラメトリック手法です。すべての観測値を順位に変換し、生の値ではなく群間でその順位を比較します。
これは、Mann–WhitneyのU検定(別記事で解説)を拡張したものと考えることができます。
Mann–WhitneyのU検定は同じく順位に基づく比較ですが、対象は2群のみです。Kruskal–Wallis検定はそれを3群以上に拡張したもので、複数群があり、ANOVAが使えないときに用います。
順位を扱うため、特定の分布を仮定しません。現実のデータは特定の分布にぴったり当てはまらないことが多いため、そこが有用な点です。
Kruskal–Wallis検定は、次のような状況に適しています。
簡単な例を挙げます。
3つの異なるクラスの試験スコアを比較したいとします。スコアは歪んでおり、標本も小さいため、ANOVAは適切ではありません。Kruskal–Wallis検定は正規性を必要としないので使えます。少なくとも1つのクラスが他と異なるスコアだったかどうかを、データが満たせない仮定を置かずに判断できます。
どちらも群を比較しますが、方法が異なります。
ANOVAは群の平均を比較し、データが正規分布に従い、分散がおおむね等しいと仮定します。これらの仮定が成り立つなら、ANOVAの方が統計的検出力が高く、解釈もしやすいため、より良い選択です。
Kruskal–Wallis検定は群の分布を順位で比較します。正規性や等分散を気にしません。そのぶん柔軟ですが、統計的検出力はやや低下します。
比較表を簡単に示します。

ANOVAとKruskal–Wallis検定の比較
データが正規分布に従うならANOVAを。そうでない、または確認できないならKruskal–Wallisを使ってください。
Kruskal–Wallis検定は最終的に1つの検定統計量Hに集約されます。式は次のとおりです。
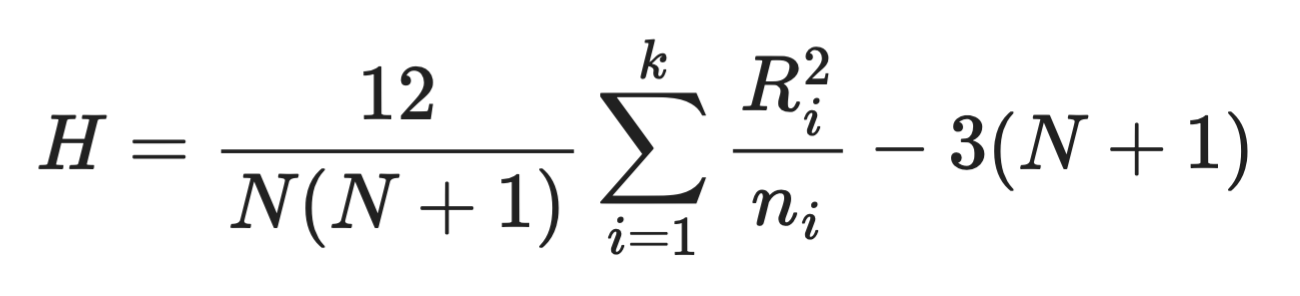
Kruskal–Wallisの式
各構成要素は次のとおりです。
N:全群の観測値の総数
k:群の数
n_i:群iの観測値の数
R_i:群iに割り当てられた順位の合計
この式は、すべての群が同一である場合に期待される値から、各群の順位和がどれだけ離れているかを測ります。Hが大きいほど群間に差があり、Hが小さいほど差は小さいことを意味します。
Hを求めたら、自由度k - 1のカイ二乗分布と比較してp値を得ます。
Kruskal–Wallis検定を行うには、次の4ステップです。
R_iですHの式に代入します。群が似ていれば順位和は近くなりHは小さく、ある群が一貫して高い(または低い)順位ならHは大きくなります以上です。
実際の値そのものではなく、全体の中での相対的な位置だけを見ていることがわかります。
PythonのscipyライブラリにはKruskal–Wallis検定の関数が用意されており、式を自分で実装する必要はありません。例を見ていきましょう。
3つのクラスの試験スコアを比較するケースを想定します。検定の実行は次のとおりです。
from scipy import stats
# Exam scores
class_a = [78, 85, 90, 72, 88]
class_b = [65, 70, 68, 74, 60]
class_c = [88, 92, 95, 85, 91]
# Run the test
statistic, p_value = stats.kruskal(class_a, class_b, class_c)
print(f"H statistic: {statistic:.4f}")
print(f"P-value: {p_value:.4f}")
Pythonの出力
p値は0.05未満で、少なくとも1つのクラスが他と異なるスコアだったことを示します。どのクラスかまでは教えてくれない点に注意してください—それを知るには事後検定が必要で、次のセクションで扱います。
Pythonと同様に、Rにも組み込み関数があります。同じ試験スコアの例を使います。
# Exam scores
class_a <- c(78, 85, 90, 72, 88)
class_b <- c(65, 70, 68, 74, 60)
class_c <- c(88, 92, 95, 85, 91)
# Combine
scores <- c(class_a, class_b, class_c)
groups <- factor(rep(c("A", "B", "C"), each = 5))
# Run the test
kruskal.test(scores ~ groups)
Rの出力
出力はPythonと同じで、H統計量もp値も一致します。p < 0.05であれば、帰無仮説を棄却し、少なくとも1つの群が異なると結論づけます。
Kruskal–Wallis検定の帰無仮説は、「すべての群が同じ分布を持つ」です。p値に基づいて棄却するかを判断します。解釈は次のとおりです。
0.05というしきい値は慣例です。分野や分析の重要性によっては、0.01のように厳しくしたり、0.10のように緩くしたりします。
この検定だけでは、どの群が異なるかはわかりません。有意ということは「すべて同じではない」という意味です。何かが起きていることはわかっても、どこかは不明です。どの組み合わせが差の要因かを知るには、事後検定が必要です。
この検定は「少なくとも1つが違う」ことまでは示しますが、「どの群か」は示しません。3群でp < 0.05なら、A対B、A対C、B対C、またはその組み合わせが考えられます。対比較を得るには事後検定が必要です。
Dunn検定が最も一般的です。全群間の対比較を行い、多重比較に伴うp値の補正を行います。補正なしでは偽陽性の確率が膨らみます。比較の数が増えるほど、偶然の「有意」を見つけてしまうリスクが高まるためです。
このためにはscikit_posthocsライブラリが必要です。未インストールならpip install scikit-posthocsで導入してください。
あとは計算は簡単です。
import scikit_posthocs as sp
import pandas as pd
# Same exam scores as before
class_a = [78, 85, 90, 72, 88]
class_b = [65, 70, 68, 74, 60]
class_c = [88, 92, 95, 85, 91]
# Combine
scores = class_a + class_b + class_c
groups = ["A"] * 5 + ["B"] * 5 + ["C"] * 5
df = pd.DataFrame({"score": scores, "group": groups})
# Run the test
result = sp.posthoc_dunn(df, val_col="score", group_col="group", p_adjust="bonferroni")
print(result)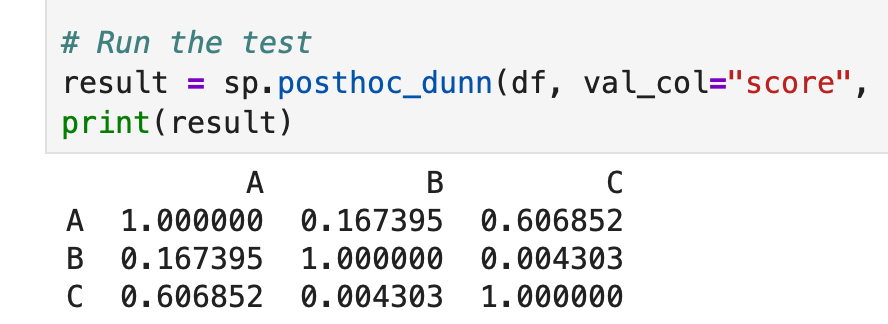
PythonでのDunn検定
各セルはそのペアの補正後p値を示します。ここではB対C(p = 0.004)のみが0.05を下回り、この2群に差があります。A対B(p = 0.167)とA対C(p = 0.607)は有意でなく、クラスAは他の2クラスのいずれとも統計的に有意な差はありません。
まず必要であればinstall.packages("dunn.test")でライブラリをインストールします。
library(dunn.test)
# Same exam scores as before
class_a <- c(78, 85, 90, 72, 88)
class_b <- c(65, 70, 68, 74, 60)
class_c <- c(88, 92, 95, 85, 91)
scores <- c(class_a, class_b, class_c)
groups <- factor(rep(c("A", "B", "C"), each = 5))
# Run the test
dunn.test(scores, groups, method = "bonferroni")
RでのDunn検定
結果は期待どおりPythonと一致します。有意なのはB対Cのみで、A対BとA対Cは有意ではありません。Kruskal–Wallis検定で検出された差の要因はクラスBとクラスCです。
Kruskal–Wallis検定はANOVAより柔軟ですが、実行前に確認すべき前提が3つあります。
最初の2つの前提に反すると、検定結果は妥当ではありません。3つ目の前提はやや緩やかで、実行可否ではなく解釈の仕方に影響します。
次の3つのケースでは、別の検定のほうが適しています。
Kruskal–Wallis検定は、ANOVAのような検定が要求する正規性が満たされないときに、3群以上の独立した群を比較するための手法です。生の値ではなく順位を用いることで可能になっています。
とはいえ、これはANOVAの代替ではありません。データが正規的ならANOVAのほうが統計的に有利です。一方、対応のあるデータにはFriedman検定を使います。常に、適切な検定はデータ次第です。
条件が整っていれば、Kruskal–Wallis検定は信頼できてシンプルな選択です。検定を実行してp値を確認し、どの群間が差の要因か知る必要があればDunn検定で追跡してください。
統計の知識が少し錆びついていませんか?Introduction to Statisticsコースで、午後のひとときで感覚を取り戻しましょう。