Track
Основы данных на Python
28 ч
Связный список — это структура данных, которая играет ключевую роль в организации и управлении данными. Он содержит последовательность узлов, размещённых в произвольных местах памяти, что позволяет эффективно управлять памятью. Каждый узел связного списка включает два основных компонента: часть с данными и ссылку на следующий узел в последовательности.
Если на первый взгляд это кажется сложным — не переживайте!
Мы разберёмся с азами: что такое связные списки, зачем они нужны и какие уникальные преимущества дают.
Связные списки были созданы, чтобы преодолеть ряд недостатков хранения данных в обычных списках и массивах, перечисленных ниже:
В списках вставка или удаление элемента в любой позиции, кроме конца, требует сдвига всех последующих элементов. Эта операция имеет временную сложность O(n) и может заметно ухудшать производительность, особенно по мере роста списка. Если вы пока не знакомы с тем, как работают списки или как они реализованы, прочитайте наш туториал по спискам в Python.
Связные списки работают иначе. Они хранят элементы в разных, не смежных участках памяти и соединяют их указателями на последующие узлы. Такая структура позволяет добавлять или удалять элементы в любой позиции, просто меняя ссылки: включая новый элемент или обходя удалённый.
Как только у вас есть прямая ссылка на узел в точке вставки или удаления, сама операция выполняется за O(1). Однако поиск этой позиции по-прежнему требует прохода за O(n), поэтому преимущество O(1) действует только тогда, когда у вас уже есть указатель на нужный узел (например, когда вы работаете с головой списка).
Списки в Python — это динамические массивы, то есть они позволяют изменять размер.
Однако это сопровождается серией сложных операций, включая перераспределение массива в новый, более крупный блок памяти. Такое перераспределение неэффективно, поскольку элементы копируются в новый блок, и при этом может выделяться больше места, чем нужно прямо сейчас.
В отличие от этого, связные списки могут расти и уменьшаться динамически без перераспределения или изменения размера. Это делает их предпочтительным выбором для задач, где важна гибкость.
Списки выделяют память для всех элементов в одном непрерывном блоке. Если список должен вырасти сверх начального размера, ему нужно выделить новый, больший непрерывный блок памяти и скопировать туда все существующие элементы. Этот процесс затратен по времени и неэффективен, особенно для больших списков. С другой стороны, если начальный размер переоценён, неиспользуемая память простаивает.
Связные списки, напротив, выделяют память для каждого элемента отдельно. Такая организация улучшает использование памяти, поскольку память для новых элементов выделяется по мере их добавления.
Хотя связные списки предоставляют преимущества перед обычными списками и массивами — такие как динамический размер и эффективное использование памяти — у них есть и недостатки. Поскольку для каждого элемента нужно хранить указатель на следующий узел, расход памяти на элемент выше, чем у списков. Кроме того, эта структура не позволяет прямого доступа к данным: чтобы получить элемент, нужно последовательно пройти список с начала, что даёт временную сложность поиска O(n).
Выбор между связным списком и массивом зависит от конкретных нужд приложения. Связные списки особенно полезны, когда:
Существует три типа связных списков, каждый из которых даёт свои преимущества в разных сценариях. Это:
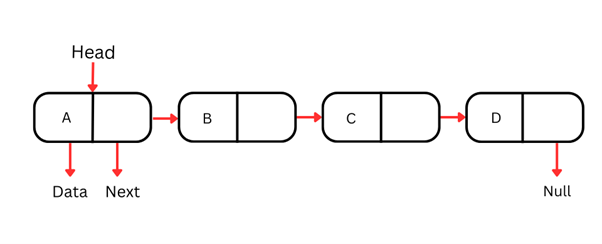
Односвязный список
Односвязный список — самый простой вид связного списка, где каждый узел содержит данные и ссылку на следующий узел в последовательности. По нему можно перемещаться только в одном направлении — от головы (первого узла) к хвосту (последнему узлу).
Каждый узел односвязного списка обычно состоит из двух частей:
Поскольку по таким структурам можно проходить только в одном направлении, доступ к конкретному элементу по значению или индексу требует начала с головы и последовательного перемещения по узлам до нужного. Эта операция имеет сложность O(n), что делает её менее эффективной для больших списков.
Вставка и удаление узла в начале односвязного списка крайне эффективны и выполняются за O(1). Однако вставка и удаление в середине или конце требуют прохода до нужного места, что приводит к сложности O(n).
Конструкция односвязных списков делает их удобными, когда операции выполняются в начале списка.
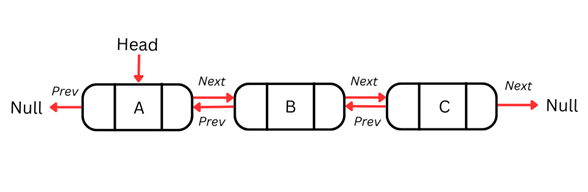
Двусвязный список
Один из недостатков односвязных списков — возможность перемещения только в одном направлении, без перехода к предыдущему узлу при необходимости. Это ограничивает операции, требующие двунаправленной навигации.
Двусвязные списки решают эту проблему, добавляя в каждый узел дополнительный указатель, благодаря чему по списку можно перемещаться в обе стороны. Каждый узел двусвязного списка содержит три элемента: данные, указатель на следующий узел и указатель на предыдущий узел.
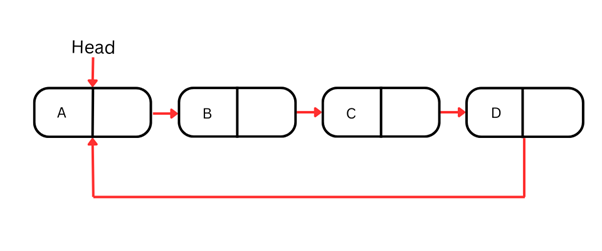
Кольцевой связный список
Кольцевые связные списки — это особый вид связного списка, в котором последний узел указывает обратно на первый, образуя кольцо. Это означает, что в отличие от рассмотренных выше одно- и двусвязных списков, кольцевой список не заканчивается, а зацикливается.
Зацикленная природа кольцевых списков делает их идеальными для сценариев, где нужно непрерывно проходить последовательность, например, в настольных играх, где ход возвращается от последнего игрока к первому, или в вычислительных алгоритмах вроде циклического распределения (round-robin) задач.
Полезно быстро сравнить связные списки со списками Python:
| Операция | Односвязный список | Массив/список Python |
|---|---|---|
| Доступ по индексу | O(n) | O(1) |
| Поиск по значению | O(n) | O(n) |
| Вставка в начало | O(1) | O(n) |
| Вставка в конец | O(n) | O(1) амортизированная |
| Вставка в середину | O(n) | O(n) |
| Удаление в начале | O(1) | O(n) |
| Удаление в конце | O(n) | O(1) амортизированная |
Главное: связные списки выигрывают при вставках и удалениях в голове (O(1)), но проигрывают во всём остальном. Если вы не добавляете и не удаляете элементы часто именно в начале структуры данных, обычный список Python, скорее всего, будет лучшим выбором.
Теперь, когда мы понимаем, что такое связные списки, зачем они нужны и какие бывают, перейдём к их реализации в Python. Ноутбук к этому руководству доступен также в этом рабочем блокноте DataLab; создав копию, вы сможете редактировать и запускать код. Это отличный вариант, если у вас возникнут сложности с запуском кода локально!
Как мы узнали ранее, узел — это элемент связного списка, который хранит данные и ссылку на следующий узел в последовательности. Вот как можно определить узел в Python:
class Node:
def __init__(self, data):
self.data = data
self.next = None
def __repr__(self):
return f"Node({self.data})"Приведённый код инициализирует узел, выполняя две основные операции: атрибут «data» узла получает значение, представляющее собственно информацию, которую должен содержать узел. Атрибут «next» представляет адрес следующего узла. Сейчас он установлен в None, что означает отсутствие ссылки на какой-либо другой узел списка. По мере добавления новых узлов в связный список этот атрибут будет обновляться и указывать на следующий узел.
Далее нужно создать класс связного списка. Он будет инкапсулировать все операции управления узлами, такие как вставка и удаление. Начнём с инициализации связного списка:
class LinkedList:
def __init__(self):
self.head = None # Initialize head as NoneУстанавливая self.head в None, мы указываем, что связный список изначально пуст и в нём нет узлов, на которые можно ссылаться. Теперь приступим к наполнению списка, вставляя новые узлы.
Внутри класса LinkedList добавим метод для создания нового узла и помещения его в начало списка:
def insertAtBeginning(self, new_data):
new_node = Node(new_data) # Create a new node
new_node.next = self.head # Next for new node becomes the current head
self.head = new_node # Head now points to the new nodeКаждый вызов этого метода создаёт новый узел с указанными вами данными. Указатель next этого узла устанавливается на текущую голову списка, что помещает новый узел перед остальными. Наконец, новый узел становится головой списка.
Сейчас мы заполним связный список последовательностью слов, чтобы лучше понять, как работает вставка. Для начала создадим метод для обхода и печати содержимого списка:
def printList(self):
temp = self.head # Start from the head of the list
while temp:
print(temp.data,end=' ') # Print the data in the current node
temp = temp.next # Move to the next node
print() # Ensures the output is followed by a new lineЭтот метод выведет содержимое нашего связного списка. Теперь воспользуемся созданными методами, чтобы заполнить список серией слов: «the quick brown fox».
if __name__ == '__main__':
# Create a new LinkedList instance
llist = LinkedList()
# Insert each letter at the beginning using the method we created
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Now 'the' is the head of the list, followed by 'quick', then 'brown' and 'fox'
# Print the list
llist.printList()Приведённые строки кода должны вывести следующий результат:
"the quick brown fox"
Теперь создадим метод insertAtEnd в классе LinkedList, чтобы добавлять новый узел в конец списка. Если список пуст, новый узел станет его головой. В противном случае он будет добавлен после текущего последнего узла. Посмотрим, как это работает на практике:
def insertAtEnd(self, new_data):
new_node = Node(new_data)
if self.head is None:
self.head = new_node
return
last = self.head
while last.next:
last = last.next
last.next = new_nodeМетод начинается с создания нового узла. Затем он проверяет, пуст ли список; если да — новый узел назначается головой. Иначе выполняется проход до последнего узла, после чего его указатель next перенаправляется на новый узел.
Теперь добавим этот метод в наш класс LinkedList и используем его, чтобы добавить слово в конец списка. Для этого измените основную функцию следующим образом:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list
llist.printList()Обратите внимание: мы просто вызвали метод insertAtEnd, чтобы добавить слово «jumps» в конец списка. Приведённый код должен вывести следующее:
"the quick brown fox jumps"
Удалить первый узел связного списка легко: достаточно перенаправить голову списка на второй узел. Таким образом, первый узел больше не будет частью списка. Для этого добавьте в класс LinkedList следующий метод:
def deleteFromBeginning(self):
if self.head is None:
return "The list is empty" # If the list is empty, return this string
self.head = self.head.next # Otherwise, remove the head by making the next node the new headЧтобы удалить последний узел связного списка, нужно пройти список, найти предпоследний узел и изменить его указатель next на None. Так последний узел больше не будет частью списка. Скопируйте и вставьте следующий метод в ваш класс LinkedList:
def deleteFromEnd(self):
if self.head is None:
return "The list is empty"
if self.head.next is None:
self.head = None # If there's only one node, remove the head by making it None
return
temp = self.head
while temp.next.next: # Otherwise, go to the second-last node
temp = temp.next
temp.next = None # Remove the last node by setting the next pointer of the second-last node to NoneСначала метод проверяет, пуст ли связный список, и, если да, возвращает сообщение пользователю. Иначе, если в списке один узел, он удаляется. Для списков с несколькими узлами метод находит предпоследний узел и обнуляет ссылку на следующий узел.
Теперь обновим основную функцию, чтобы удалить элементы из начала и конца связного списка:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from the beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()Этот код выведет список до и после удаления, наглядно показывая работу операций вставки и удаления в связных списках. После запуска вы должны увидеть следующий вывод:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown foxПоследняя операция в этой главе — поиск конкретного значения в связном списке. Для этого метод должен начать с головы и последовательно проходить узлы, проверяя, совпадают ли данные узла с искомым значением. Вот практическая реализация этой операции:
def search(self, value):
current = self.head # Start with the head of the list
position = 0 # Counter to keep track of the position
while current: # Traverse the list
if current.data == value: # Compare the list's data to the search value
return f"Value '{value}' found at position {position}" # Print the value if a match is found
current = current.next
position += 1
return f"Value '{value}' not found in the list" Чтобы найти конкретные значения в созданном нами списке, обновите основную функцию, добавив метод поиска:
if __name__ == '__main__':
llist = LinkedList()
# Insert words at the beginning
llist.insertAtBeginning('fox')
llist.insertAtBeginning('brown')
llist.insertAtBeginning('quick')
llist.insertAtBeginning('the')
# Insert a word at the end
llist.insertAtEnd('jumps')
# Print the list before deletion
print("List before deletion:")
llist.printList()
# Deleting nodes from beginning and end
llist.deleteFromBeginning()
llist.deleteFromEnd()
# Print the list after deletion
print("List after deletion:")
llist.printList()
# Search for 'quick' and 'lazy' in the list
print(llist.search('quick')) # Expected to find
print(llist.search('lazy')) # Expected not to findЭтот код выведет следующий результат:
List before deletion:
the quick brown fox jumps
List after deletion:
quick brown fox
Value 'quick' found at position 0
Value 'lazy' not found in the listСлово «quick» успешно найдено в связном списке, так как находится на первой позиции. Однако слова «lazy» в списке нет, поэтому оно не было найдено.
Если вы дочитали до этого места — поздравляем! Теперь у вас есть прочное понимание основ связных списков: их структуры, типов, способов добавления и удаления элементов, а также обхода.
Но на этом путь не заканчивается. Связные списки — лишь начало мира структур данных и алгоритмов. Вот несколько возможных следующих шагов, чтобы углубить знания по теме:
Погрузитесь в практику, внедрив связные списки в проект по программированию или data science. Связные списки используют при разработке файловых систем, построении хеш-таблиц, а также при создании GPS-навигации и настольных игр. Чтобы начать собственные проекты, посмотрите наши бесплатные проекты по data science с пошаговыми инструкциями, которые научат вас решать реальные задачи на Python, R и SQL.
Освоение других структур данных — таких как деревья, стеки и очереди — это логичное продолжение после связных списков. Эти структуры опираются на принципы связных списков и помогают эффективно решать более широкий круг вычислительных задач. Например, деревья и двоичные деревья поиска развивают идею связных списков в иерархическую форму, позволяя каждому узлу соединяться с несколькими элементами структуры.
Если эти понятия звучат для вас непривычно — не переживайте! У Datacamp есть целый курс по структурам данных и алгоритмам в Python, где эти темы разобраны подробнее. Сначала вы познакомитесь со структурами данных, такими как стеки, деревья, хеш-таблицы, очереди и графы. По мере продвижения вы освоите алгоритмы поиска и сортировки, что поможет вам стать более эффективным программистом и решателем задач.
В этом руководстве мы реализовали односвязные списки, рассмотрев операции вставки, удаления и обхода.
Вы можете продвинуться дальше, изучив реализацию двусвязных и кольцевых списков. Skip list — ещё одно развитие связных списков, позволяющее ускорить поиск за счёт более быстрого доступа к элементам.
Знакомство с этими продвинутыми структурами данных выведет ваши технические навыки на новый уровень и значительно улучшит ваши способности в программировании, подготовив к более сложным задачам в областях вроде data science, разработки ПО и инженерии машинного обучения.
Если вам нужна более дружелюбная к новичкам вводная в программирование перед изучением продвинутых тем, посмотрите карьерный трек Python Programmer. Это серия курсов, которая научит вас основам языка.
Продолжайте изучать Python!
Track
Track
Course