Course
Linear Classifiers in Python
4 ч
66.2K
Пытались ли вы когда‑нибудь извлечь полезные закономерности из набора данных с тысячами признаков?
Вы понимаете, что в огромном датасете наверняка скрыта полезная структура. Проблема в том, что «сырые» данные содержат много шума, избыточности, пропущенных значений и гораздо больше измерений, чем действительно нужно. Большинство алгоритмов машинного обучения не смогут корректно работать с такими данными или, в лучшем случае, сильно замедлят обучение.
Сингулярное разложение (SVD) разбивает любую матрицу (в данном случае — датасет) на три более простые матрицы, которые показывают её ключевую структуру. Это математика, стоящая за рекомендательными системами, сжатием изображений и методами снижения размерности, такими как PCA, — и, разобравшись в ней, вы начнёте встречать её почти в любой рабочей задаче.
В этой статье я объясню, что такое SVD, как оно работает, где применяется в data science и когда лучше выбрать альтернативный подход.
Сложно даются такие понятия, как векторы и определители? Прежде чем продолжить, прочитайте нашу публикацию «Проще о математике для глубокого обучения».
SVD — это метод, который разбивает любую матрицу на три более простые матрицы.
Представьте так. У вас есть матрица A — это может быть датасет или изображение. SVD разбивает A на три части:
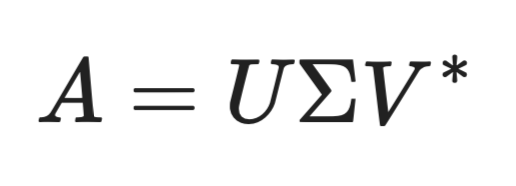
Формула SVD
U — ортогональная матрица размера m x m. Её столбцы называются левыми сингулярными векторами и описывают взаимосвязи между строками A
\Sigma — диагональная матрица размера m x n. Значения на диагонали — это сингулярные значения — они всегда неотрицательны и отсортированы по убыванию
V* — сопряжённо‑транспонированная матрица к ортогональной матрице размера n x n. Её строки называются правыми сингулярными векторами и описывают взаимосвязи между столбцами A
Каждая часть показывает что‑то своё об исходных данных. U содержит паттерны на уровне строк (как строки связаны друг с другом), \Sigma — веса значимости (насколько важен каждый паттерн), а V* — паттерны на уровне столбцов (как столбцы связаны между собой).
Аналогия: представьте, что вы объясняете рецепт. Его можно разложить на три части: ингредиенты (что нужно), пропорции (сколько чего) и шаги (как всё соединяется). По отдельности они не воссоздают блюдо, но вместе дают полную картину. SVD делает то же с матрицами — разделяет «что», «сколько» и «как» на самостоятельные компоненты, с которыми можно работать независимо.
Особенность SVD в линейной алгебре в том, что он работает для любой матрицы. Ей не обязательно быть квадратной или обладать особыми свойствами. Любую матрицу m x n можно так разложить — поэтому SVD так часто встречается в data science.
Давайте внимательно разберёмся, начиная с основ.
Пусть у вас есть матрица 3×2 A:
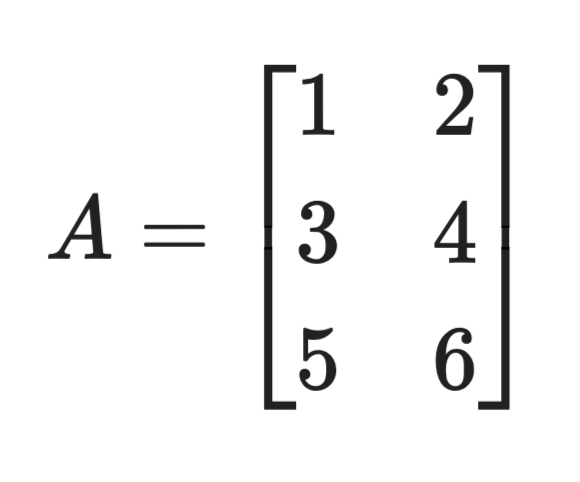
Декомпозиция матрицы
SVD раскладывает её на U (3×3), \Sigma (3×2) и V* (2×2). Столбцы U получаются из собственных векторов A x A^T, а столбцы V — из собственных векторов A^T x A. Сингулярные значения в \Sigma — это квадратные корни из собственных значений любого из этих произведений.
Хорошая новость: вам не нужно считать это вручную. В Python достаточно одной строки кода:
import numpy as np
A = np.array([[1, 2], [3, 4], [5, 6]])
U, sigma, Vt = np.linalg.svd(A, full_matrices=True)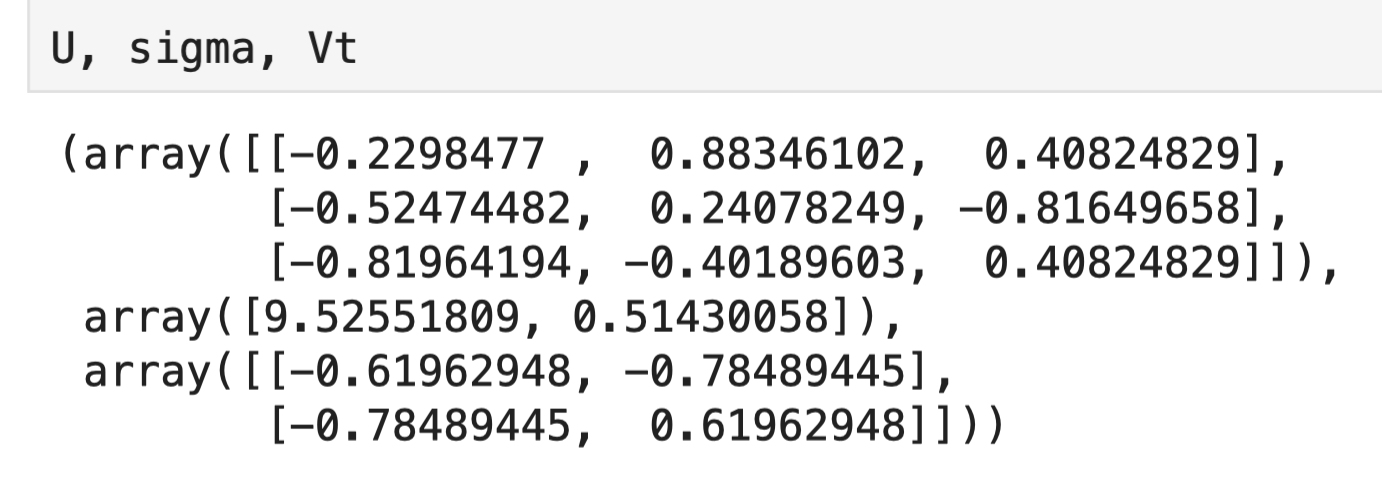
Вывод Numpy
Три матрицы взаимодействуют через умножение. U поворачивает данные в пространстве строк, \Sigma масштабирует их по каждой оси, а V* поворачивает в пространстве столбцов. В результате получается исходная матрица A.
Диагональные значения в \Sigma показывают вклад каждой компоненты в общую матрицу.
Первое сингулярное значение всегда наибольшее — оно захватывает самый доминирующий паттерн в данных. Каждое последующее — меньше. Если первые несколько значений велики, а остальные близки к нулю, значит, большая часть информации сосредоточена лишь в нескольких компонентах.
Именно это и делает возможным сжатие данных.
Можно отбросить малые сингулярные значения (и соответствующие им столбцы в U и строки в V*), почти не потеряв информации. В итоге вы получите приближение исходной матрицы меньшего ранга, с которой проще и быстрее работать.
Число ненулевых сингулярных значений также определяет ранг матрицы — количество линейно независимых строк или столбцов. Если у матрицы 100×50 только 10 ненулевых сингулярных значений, это означает, что данные имеют лишь 10 независимых измерений. Остальные 40 избыточны.
Исходную матрицу можно восстановить умножением трёх компонентов:
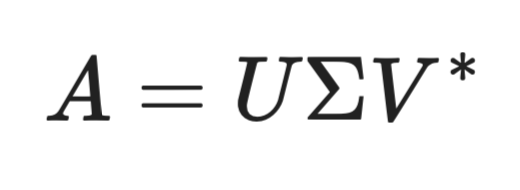
Реконструкция матрицы
Но на практике чаще нужна частичная реконструкция. Вместо использования всех сингулярных значений вы оставляете только первые k значений и соответствующие им векторы. Это даёт ранг‑k приближение матрицы A:
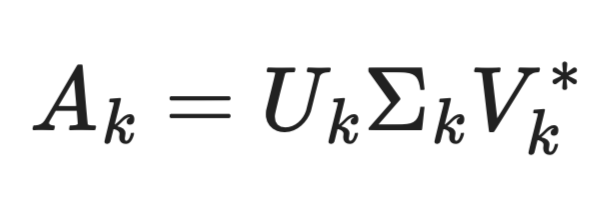
Ранг‑k приближение матрицы
Теорема Эккарта—Юнга гарантирует, что такое ранговое приближение является наилучшей возможной матрицей ранга k к исходной A (в метрике нормы Фробениуса). Иными словами, если вы сжимаете матрицу до k измерений, SVD даёт лучший возможный результат.
Если присмотреться, SVD встречается гораздо чаще, чем можно подумать.
Идея всегда одна: взять большую матрицу, оставить существенные части и убрать остальное. Меняется лишь то, что считается «существенным» в зависимости от задачи.
Высокоразмерные датасеты сложны в работе и интерпретации. Больше признаков — дольше обучение и выше риск переобучения. SVD помогает избежать этого, уменьшая число измерений.
В общих чертах так: вы раскладываете матрицу данных, смотрите на сингулярные значения и сохраняете только первые k компонент. Малые сингулярные значения представляют шум и незначительные вариации, поэтому их удаление почти не ухудшит качество данных. В итоге остаётся компактное представление, сохраняющее большую часть исходной структуры.
Именно так работает метод главных компонент (PCA). PCA центрирует данные и применяет к результату SVD. Главные компоненты — это правые сингулярные векторы, а сингулярные значения показывают, какую долю дисперсии объясняет каждая компонента.
У компаний вроде Netflix и Amazon есть огромные матрицы «пользователь—объект», где большинство ячеек пусты. Пользователь оценивает лишь несколько фильмов из тысяч — матрица разреженная. SVD помогает «заполнить пробелы».
Идея в разложении матрицы оценок на предпочтения пользователей и характеристики объектов. Матрица U отражает, что важно для каждого пользователя (жанр, темп, тон), а V* — что предлагает каждый объект. Сингулярные значения в \Sigma масштабируют эти факторы по важности. Перемножив их обратно, вы получите предсказанные оценки для фильмов, которые пользователь ещё не видел.
На практике стандартный SVD напрямую не подходит для разреженных матриц, потому что трактует пропуски как нули. Поэтому применяются варианты, такие как усечённый SVD или методы факторизации матриц, которые работают только с наблюдаемыми значениями.
Чёрно‑белое изображение — это просто матрица значений пикселей. SVD позволяет сжать его, сохранив только самые важные сингулярные значения.
Предположим, у вас изображение 1000×1000. Полный SVD даёт 1000 сингулярных значений. Но если оставить только первые 50, вы реконструируете изображение всего из 50 компонент вместо 1000. Картинка будет немного «мыльной», но узнаваемой — а объём хранения сократится с 1 000 000 значений примерно до 100 500 (50 столбцов U + 50 сингулярных значений + 50 строк V*).
Больше сингулярных значений — лучше качество изображения, но меньше степень сжатия. Меньше значений — файлы компактнее, но потерь больше. Вы сами выбираете компромисс под свою задачу.
Чем больше матрица, тем выше вычислительные затраты.
Полный SVD для матрицы m x n имеет временную сложность O(mn²) (при допущении, что m >= n). Для небольших матриц это нормально. Для матрицы с миллионами строк и тысячами столбцов — очень дорого.
Память — ещё одно узкое место. Полный SVD выдаёт три плотные матрицы, и их одновременное хранение может превысить объём доступной ОЗУ.
Решение — не вычислять полный SVD без нужды. Усечённый SVD вычисляет только первые k сингулярных значений и соответствующих векторов — это значительно быстрее. В Python это делают scipy.sparse.linalg.svds и sklearn.decomposition.TruncatedSVD. Рандомизированный SVD идёт дальше и использует случайное сэмплирование для аппроксимации разложения — он хорошо работает, когда нужны только доминирующие компоненты.
SVD в большинстве случаев численно устойчив, но может испытывать трудности с некоторыми типами данных.
Один из примеров — сильно зашумлённые данные. Если отношение сигнал/шум низкое, верхние сингулярные значения не отделяются от шума. В результате вы либо сохраните шум в приближении, либо при усечении уменьшите сигнал.
Ещё одна проблема — плохо обусловленные матрицы. Когда отношение между наибольшим и наименьшим сингулярными значениями огромно (высокое число обусловленности), небольшие численные ошибки при вычислениях усиливаются. Это может приводить к недостоверным результатам, особенно при ограниченной точности с плавающей запятой.
Решение — анализировать сингулярные значения перед усечением. Постройте их график и ищите явный «обрыв» между сигналом и шумом. Если спад плавный и «локтя» нет, SVD может быть не лучшим инструментом для этого датасета.
SVD — не единственная декомпозиция матриц и не всегда лучший выбор для любой задачи.
Каждая альтернатива ниже решает свой тип задач. Это не замены SVD, так как они основаны на других предположениях и ограничениях. Как всегда, правильный выбор зависит от вашей цели.
Собственное разложение наиболее близко к SVD. Оно раскладывает квадратную матрицу на собственные значения и собственные векторы:
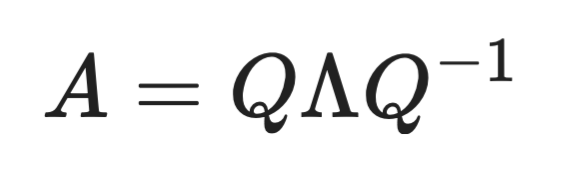
Формула собственного разложения
Где Q содержит собственные векторы, а \Lambda — диагональную матрицу из собственных значений.
Ограничение: оно работает только для квадратных матриц. Если ваша матрица данных имеет размер m x n, где m != n, собственное разложение неприменимо напрямую. SVD же работает для любой формы матриц, поэтому он более общий инструмент.
Для квадратных симметричных матриц (например, ковариационных) собственное разложение и SVD дают тесно связанные результаты. Сингулярные значения симметричной положительно полуопределённой матрицы совпадают с её собственными значениями. Поэтому при работе с ковариационными матрицами в PCA оба метода приводят к одинаковым результатам. Просто SVD обобщается на неквадратные случаи.
QR‑разложение делит матрицу на ортогональную матрицу Q и верхнетреугольную матрицу R:
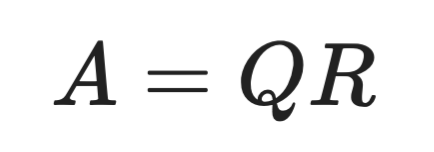
Формула QR‑разложения
Для некоторых задач оно быстрее SVD, особенно при решении систем линейных уравнений и задач наименьших квадратов.
Компромисс — в информации. QR не даёт сингулярных значений, поэтому не расскажет о ранге матрицы или о том, какие компоненты наиболее «весомы». Если вам нужно решить Ax = b и не важна внутренняя структура, QR — хороший выбор. Но если нужно понять или сжать данные, лучше подойдёт SVD.
NMF раскладывает матрицу на две матрицы с неотрицательными значениями:
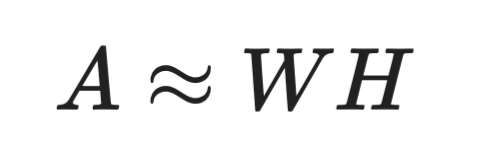
Формула NMF
Это ограничение делает NMF отличным выбором для данных, которые по природе неотрицательны (например, интенсивности пикселей или частоты слов). SVD таких ограничений не накладывает: в разложении могут появляться отрицательные значения, и иногда компоненты труднее интерпретировать.
NMF особенно популярен в текстовой аналитике и тематическом моделировании. Каждый столбец W может соответствовать теме, а каждая строка H показывает, насколько эта тема выражена в каждом документе. Неотрицательность означает, что темы строятся из аддитивных комбинаций слов, что делает их интерпретацию проще, чем у компонент SVD со смешанными знаками.
Минус в том, что NMF не гарантирует единственности решения, и результат зависит от инициализации. SVD всегда даёт один и тот же вывод для одинакового ввода.
Если ваша матрица слишком велика для полного SVD, но вам всё ещё нужны сингулярные значения, присмотритесь к рандомизированному SVD. Он использует случайные проекции, чтобы аппроксимировать первые k сингулярных значений и векторов без полного разложения. Такие библиотеки, как scikit-learn (TruncatedSVD) и fbpca от Facebook, реализуют этот подход, и он хорошо масштабируется к матрицам с миллионами строк.
Ниже на рисунке кратко показано, когда выбирать тот или иной метод.
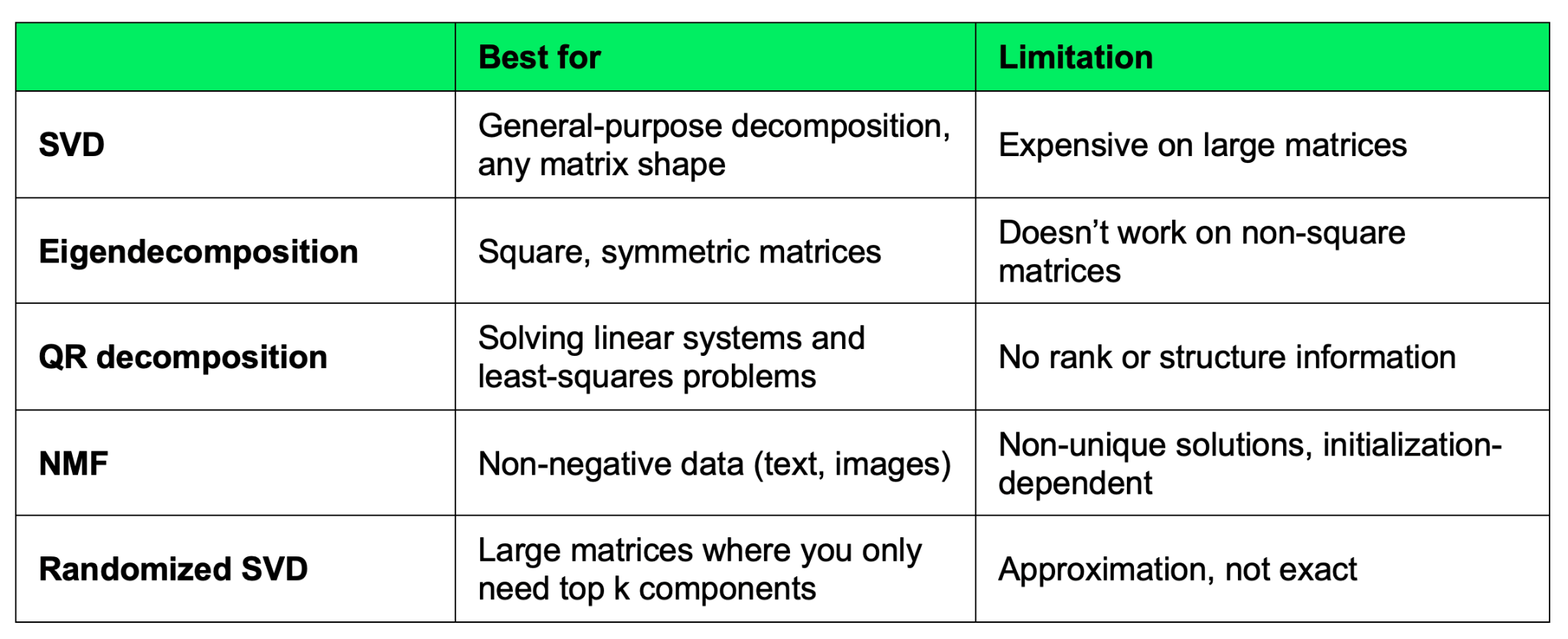
Альтернативы SVD
Есть пара типичных моментов, которые часто сбивают с толку начинающих дата‑саентистов.
Первое — это неверная интерпретация сингулярных значений. Большое сингулярное значение означает, что компонента объясняет значительную долю дисперсии в данных — это не обязательно «важность» в предметном смысле. Например, доминирующее сингулярное значение в матрице пользовательских оценок может отражать то, что большинство людей оценивают популярные фильмы, а не какую‑то осмысленную схему предпочтений. Всегда интерпретируйте сингулярные значения в контексте ваших данных, а не только их величину.
Второе — использование SVD без особой необходимости. На маленьких датасетах (пара сотен строк и несколько столбцов) SVD лишь усложняет процесс. Простые методы, такие как корреляционный анализ или базовый отбор признаков, часто справляются быстрее и с меньшим количеством кода. SVD отлично подходит для высокоразмерных данных с избыточной структурой — если ваш набор данных не про это, выбирайте более простые методы.
SVD разбивает любую матрицу на три компонента, показывающие её структуру. Сингулярные значения подсказывают, какие части данных наиболее значимы, а левые и правые сингулярные векторы показывают скрытые закономерности по строкам и столбцам.
Это разложение лежит в основе многих практических инструментов, которыми вы пользуетесь ежедневно. Рекомендательные системы используют его, чтобы предсказывать пропущенные оценки. Сжатие изображений — чтобы уменьшать размеры файлов при сохранении качества. Математика за ними почти одна и та же, хотя домены совершенно разные.
Но SVD подходит не всегда. Он дорог для больших матриц и может смешивать сигнал с шумом, когда сингулярные значения плохо отделяются. Кроме того, для маленьких датасетов это излишне сложно. Альтернативы вроде QR‑разложения, собственного разложения и NMF лучше справляются в ряде частных случаев.
Главное — понимать, когда использовать SVD, а когда проще обойтись другим методом. Чтобы получить это понимание, запишитесь на наш трек Machine Learning Scientist in Python и станьте востребованным специалистом в 2026 году.
Учитесь с DataCamp
Course
Course
Course