
Courses
Suy luận cho hồi quy tuyến tính trong R
4 giờ
15.9K
Hồi quy tuyến tính là một trong những kỹ thuật học máy đơn giản nhất. Nó liên quan đến việc dự đoán giá trị của biến phụ thuộc dựa trên một hoặc nhiều biến độc lập.
Chẳng hạn, hồi quy tuyến tính có thể được áp dụng để dự đoán giá nhà dựa trên diện tích nhà hoặc dự đoán cân nặng của một người dựa vào chiều cao. Mô hình hồi quy tuyến tính được phân loại chủ yếu thành hai loại: hồi quy tuyến tính đơn và hồi quy tuyến tính đa biến.
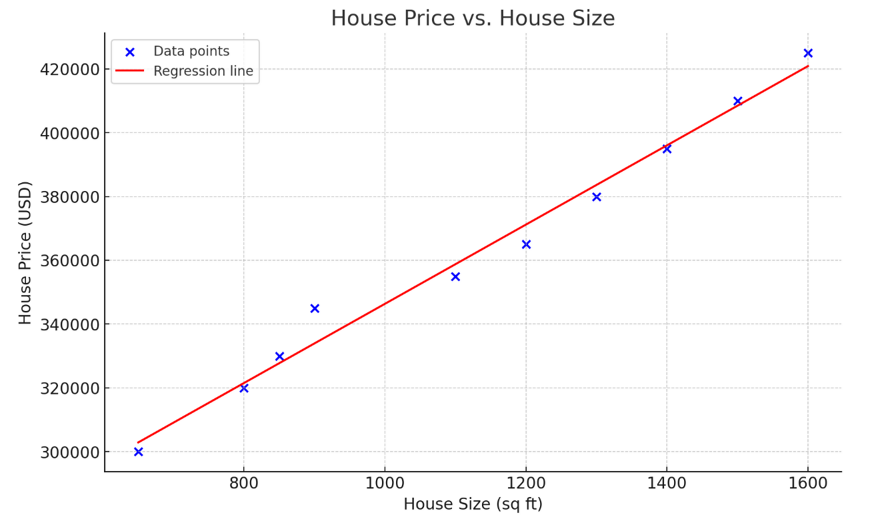
Hình ảnh bởi OpenAI
Biểu đồ trên biểu diễn hồi quy tuyến tính đơn, mô hình hóa mối quan hệ giữa diện tích nhà (biến độc lập) và giá nhà (biến phụ thuộc). Như quan sát từ trực quan hóa, nhà càng lớn thì càng đắt.
Phương trình của đường hồi quy là:
y = mx + c + ⍷
Nếu công thức trên trông quen thuộc, đó là vì bạn có lẽ đã học ở trường rằng y = mx + c là phương trình của một đường thẳng. Trong phương trình này:
⍷ biểu diễn phần dư hay sai số. Đây là chênh lệch giữa giá trị thực tế và giá trị được mô hình hồi quy dự đoán. Thành phần này phân biệt đường hồi quy với một đường thẳng tất định thuần túy, khiến mối quan hệ giữa x và y không thể dự đoán hoàn hảo.
Để có hướng dẫn chi tiết hơn về chủ đề này, hãy đọc bài viết giải thích những điều cốt lõi của hồi quy tuyến tính của chúng tôi.
Dưới đây là một số yếu tố khiến Excel trở thành công cụ hiệu quả để thực hiện hồi quy tuyến tính:
Tính đến năm 2024, theo Statista, có hơn 731.000 công ty tại Hoa Kỳ và còn nhiều hơn nữa trên toàn thế giới sử dụng Excel. Các cấp lãnh đạo ở mọi cấp độ tổ chức đều dùng Excel cho mục đích quản lý và báo cáo dữ liệu.
Bằng cách tạo các mô hình dự đoán như hồi quy tuyến tính trong Excel, các công ty có thể hợp nhất hoạt động báo cáo và mô hình dự đoán trong một nền tảng duy nhất. Điều này cho phép tổ chức tinh gọn quy trình làm việc thay vì phải liên tục chuyển đổi giữa môi trường lập trình và bảng tính Excel.
Nếu bạn là người mới trong lĩnh vực dữ liệu, chỉ nghĩ đến việc xây dựng một mô hình dự đoán thôi cũng có thể thấy đáng ngại do phải viết mã. Excel đơn giản hóa quy trình này, cho phép bạn làm việc trong giao diện vốn đã quen thuộc. Với Excel, việc xây dựng mô hình hồi quy tuyến tính trở nên đơn giản, chỉ cần vài cú nhấp chuột.
Excel cung cấp khả năng trực quan hóa mạnh mẽ, cho phép bạn vẽ biểu đồ mối quan hệ giữa các biến để hiểu rõ hơn. Ngoài ra, nó đơn giản hóa việc tạo báo cáo, giúp dễ dàng nhúng biểu đồ vào bài thuyết trình PowerPoint để truyền đạt hiệu quả với các bên liên quan.
Trước khi bắt đầu hướng dẫn này, hãy tải xuống bộ dữ liệu tại kho GitHub này. Bộ dữ liệu này được OpenAI tạo riêng cho mục đích giáo dục. Nắm được các thao tác bảng tính cơ bản, như nhập dữ liệu, áp dụng công thức đơn giản và di chuyển giữa các trang tính, sẽ giúp bạn theo dõi hướng dẫn này tốt hơn.
Trước hết, chúng ta cần bật Data Analysis ToolPak trong Excel. Đây là một chương trình bổ trợ (add-in) cung cấp nhiều công cụ phân tích dữ liệu, bao gồm công cụ chúng ta sẽ dùng cho hồi quy tuyến tính.
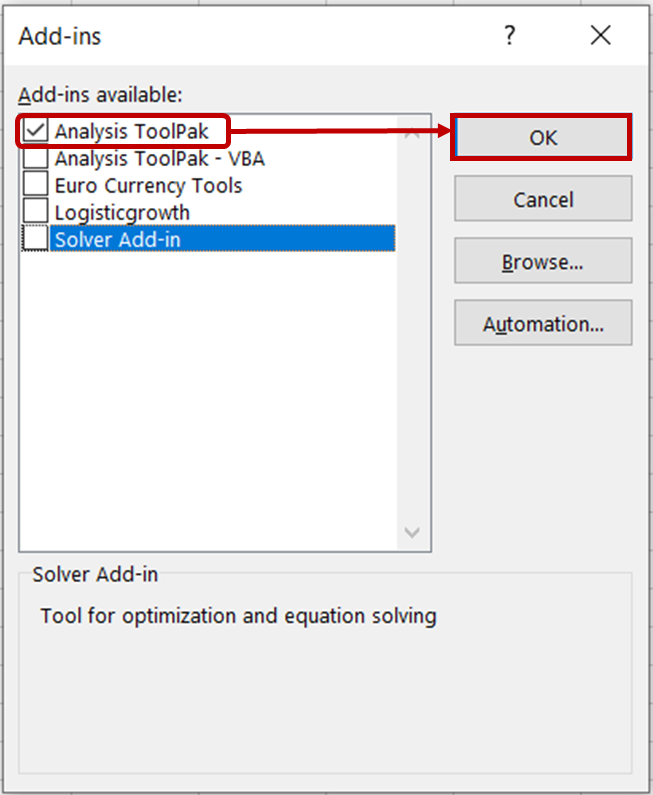
Để thực hiện, trước tiên hãy mở tệp Excel và đi tới File -> Options. Trong hộp thoại Options, chọn Add-ins -> Excel Add-ins và nhấp Go:
Trong hộp thoại Add-ins, tích chọn Analysis ToolPak và nhấp OK.
Giờ bạn sẽ thấy các công cụ Data Analysis trong thẻ Data.
Sau khi đã bật Data Analysis ToolPak, chúng ta có thể tiến hành thực hiện hồi quy tuyến tính trên bộ dữ liệu. Mở bộ dữ liệu doanh số kem và đi tới thẻ Data. Trong nhóm Analysis, nhấp vào Data Analysis.

Sau đó, chọn Regression từ danh sách các công cụ phân tích và nhấp OK.
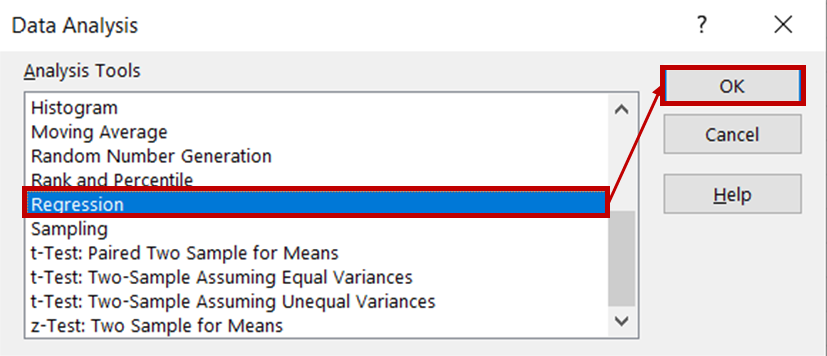
Trong hộp thoại hồi quy, đối với Input Y Range, chọn cột chứa dữ liệu doanh số kem. Đối với Input X range, chọn các cột chứa dữ liệu nhiệt độ và giá. Đảm bảo rằng ô Labels được tích chọn, vì điều này sẽ giúp Excel nhận diện tiêu đề và xử lý các hàng còn lại là dữ liệu số. Trong phần Output options , chọn New Worksheet Ply để xem kết quả hiển thị trong một trang tính mới.
Sau đó, nhấp OK để chạy phân tích hồi quy trên bộ dữ liệu.
Sau khi thực hiện hồi quy, bạn sẽ thấy một trang tính mới tự động xuất hiện trong tệp Excel, hiển thị một loạt bảng kết quả trông như thế này:
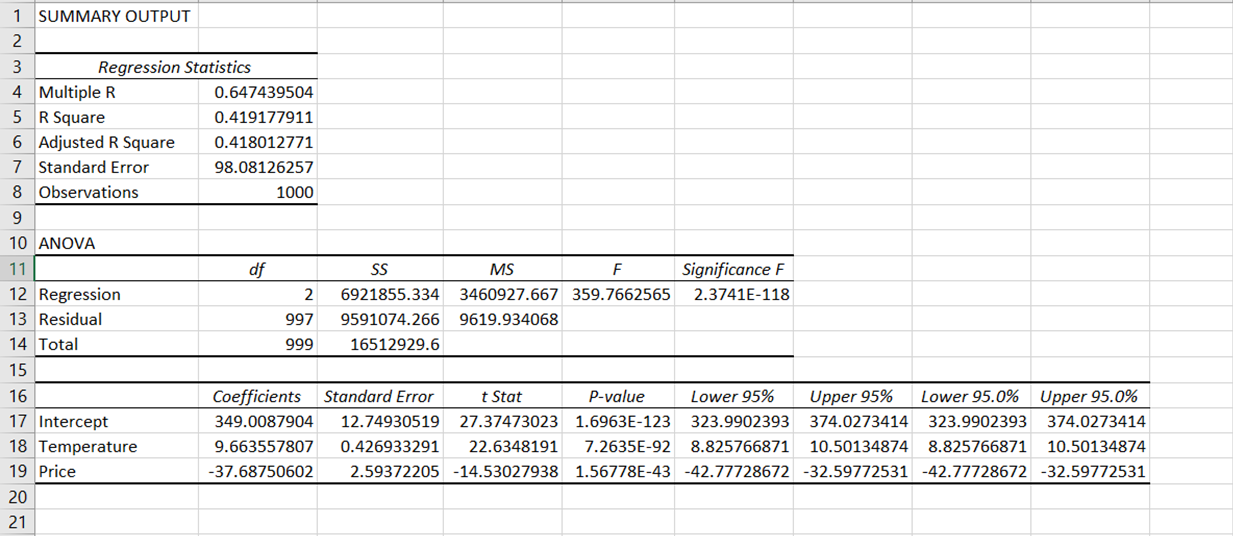
Kết quả đầu ra của hồi quy được phân tách thành nhiều thành phần: thống kê hồi quy, ANOVA, hệ số, sai số chuẩn, t Stat, P-value và khoảng tin cậy.
Hãy xem xét chi tiết từng thành phần:
Excel báo cáo các thống kê tóm tắt sau là kết quả của phân tích hồi quy:
Multiple R
Đây là hệ số tương quan đo lường độ mạnh và chiều hướng của mối quan hệ tuyến tính giữa các biến. Giá trị nằm trong khoảng từ -1 đến 1, với các giá trị gần -1 hoặc 1 cho thấy mối quan hệ mạnh và các giá trị gần 0 gợi ý không có tương quan.
Trong phân tích của chúng ta, hệ số tương quan xấp xỉ 0,65, cho thấy mối tương quan dương ở mức độ vừa giữa biến phụ thuộc (doanh số kem) và các biến độc lập (giá và nhiệt độ).
R Square
R2 là thước đo thống kê cho biết dữ liệu khớp với mô hình hồi quy tốt đến mức nào. Đây là bình phương của hệ số tương quan Multiple R và biểu thị tỷ lệ phương sai của biến phụ thuộc có thể được giải thích bởi các biến độc lập.
R2 nằm trong khoảng từ 0 đến 1, với các giá trị gần 1 cho thấy mô hình phù hợp hơn. R2 của chúng ta xấp xỉ 0,419, nghĩa là khoảng 41,9% phương sai của doanh số kem có thể được mô hình giải thích.
Adjusted R Square
Đây là giá trị R-bình phương đã được điều chỉnh theo số lượng biến dự báo trong mô hình. Thông thường đây là thước đo tốt hơn khi so sánh các mô hình có số lượng biến dự báo khác nhau. Trong trường hợp của chúng ta, Adjusted R2 là 0,418. Con số này rất tương tự R2, cho thấy các biến độc lập đã đưa vào (nhiệt độ và giá) là phù hợp với mô hình và không gây ra mức phạt lớn.
Standard Error
Sai số chuẩn đo lường khoảng cách trung bình mà các giá trị quan sát được lệch so với đường hồi quy. Sai số chuẩn càng nhỏ càng tốt vì điều đó có nghĩa là đường hồi quy khớp với dữ liệu chặt chẽ hơn.
Trong trường hợp của chúng ta, sai số chuẩn xấp xỉ 98,05, cho thấy các giá trị doanh số kem thực tế lệch so với giá trị dự đoán khoảng 98,05 đơn vị.
Observations
Điều này đề cập đến tổng số điểm dữ liệu (hàng) được phân tích trong bộ dữ liệu, không bao gồm các tiêu đề.
ANOVA là viết tắt của Phân tích phương sai. Đây là một kỹ thuật thống kê cung cấp thông tin về mức độ biến thiên trong một mô hình hồi quy thông qua:
Bậc tự do (df)
Đại diện cho số lượng giá trị trong phép tính cuối cùng được tự do thay đổi. Trong bối cảnh ANOVA, df “Regression” là số lượng biến độc lập trong mô hình, ở đây là 2. df “Residual” được tính bằng cách lấy tổng số quan sát trừ đi số biến độc lập và 1. Trong trường hợp của chúng ta là 997.
Tổng bình phương (SS)
Đại lượng này định lượng mức biến thiên. “Regression SS” đo lường phần biến thiên của biến phụ thuộc có thể được mô hình giải thích. “Residual SS” biểu thị phần biến thiên chưa được giải thích.
Trung bình bình phương (MS)
Được tính bằng cách chia Tổng bình phương (SS) cho Bậc tự do (df).
F-statistic (F)
Thống kê này xác định ý nghĩa tổng thể của mô hình. Giá trị F cao hơn cho thấy mô hình phù hợp với dữ liệu tốt hơn.
Significance F
Đây là P-value đi kèm với F-statistic. P-value rất nhỏ (nhỏ hơn 0,05) cho thấy mô hình của bạn phù hợp với dữ liệu tốt hơn một mô hình không có biến độc lập. Trong trường hợp của chúng ta, giá trị Significance F nhỏ hơn 0,05, cho thấy mô hình phù hợp với dữ liệu.
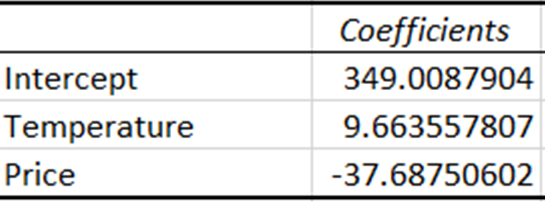
Các hệ số biểu thị mức thay đổi ước tính của biến phụ thuộc khi biến độc lập thay đổi một đơn vị.
Hệ số của nhiệt độ cho thấy với mỗi lần nhiệt độ tăng một đơn vị, doanh số tăng khoảng 9,66 đơn vị. Ngược lại, hệ số của giá cho thấy doanh số giảm khoảng 37,69 đơn vị khi giá tăng một đơn vị.
Sai số chuẩn đo lường khoảng cách trung bình giữa các giá trị quan sát được và đường hồi quy. Sai số chuẩn thấp hơn cho thấy mô hình tốt hơn.
Thống kê t là hệ số chia cho sai số chuẩn của nó. Giá trị t lớn hơn cho thấy hệ số khác không, ngụ ý rằng nó có ảnh hưởng lớn hơn đến biến phụ thuộc.
P-value cho chúng ta biết xác suất quan sát được một thống kê t cực trị như đã thấy, giả định rằng giả thuyết không đúng (tức hệ số của một biến độc lập bằng 0).
Nói đơn giản, t càng lớn và P-value càng nhỏ thì bằng chứng chống lại giả thuyết không càng mạnh, ủng hộ kết luận rằng các biến độc lập (giá và nhiệt độ) có ảnh hưởng có ý nghĩa thống kê đến biến phụ thuộc (doanh số kem).
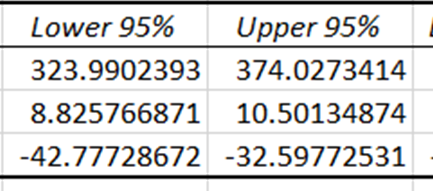
Khoảng tin cậy cung cấp giới hạn dưới và trên trong đó các hệ số thực sự của biến độc lập được kỳ vọng sẽ nằm, với mức tin cậy 95%. Vì khoảng tin cậy cho giá và nhiệt độ khác không, các hệ số này có ảnh hưởng có ý nghĩa thống kê trong việc dự đoán doanh số kem.
Trực quan hóa mối quan hệ giữa hai biến có thể cải thiện đáng kể hiểu biết của bạn về bộ dữ liệu. Mặc dù Analysis ToolPak của Excel cung cấp các thống kê tóm tắt chi tiết, biểu diễn đồ họa có thể ngay lập tức cho bạn thấy độ mạnh và chiều hướng của mối quan hệ giữa các biến.
Tạo biểu đồ phân tán với đường xu hướng là cách hiệu quả để trực quan hóa mối quan hệ này, và có thể hoàn thành trong chưa đầy năm phút. Kỹ thuật trực quan hóa này cho phép bạn thấy ngay lập tức một biến tác động đến biến kia như thế nào.
Sau đây là cách trực quan hóa mối quan hệ giữa “Doanh số kem” và “Nhiệt độ”:
Đầu tiên, bôi đen các ô chứa hai biến “Doanh số kem” và “Nhiệt độ”. Sau đó, đi tới thẻ “Insert” và nhấp vào biểu tượng biểu đồ “Scatter”:

Bạn sẽ thấy một biểu đồ phân tán đơn giản trông như sau:

Giờ hãy đổi tên biểu đồ để mô tả chính xác mối quan hệ mà chúng ta đang trực quan hóa. Chỉ cần nhấp vào tiêu đề biểu đồ và đổi thành “Mối quan hệ giữa doanh số kem và nhiệt độ.”
Tiếp theo, để thay đổi nhãn trục x, hãy vào “Chart Design.” Trong menu thả xuống “Add Chart Element”, chọn “Axis Titles” -> “Primary Horizontal”:
Nhấp vào tiêu đề trục mặc định xuất hiện và gõ “Doanh số kem” để dán nhãn chính xác cho trục. Thực hiện tương tự cho trục y bằng cách chọn “Primary Vertical” và thay tiêu đề trục bằng “Nhiệt độ:”

Lưu ý rằng dù biểu đồ phân tán cho thấy chiều hướng chung trong mối quan hệ giữa nhiệt độ và doanh số kem, các điểm dữ liệu dường như phân tán khá rộng. Để tóm lược mối quan hệ này tốt hơn, bao gồm cả chiều hướng tổng thể và độ dốc, hãy thêm đường xu hướng hay đường hồi quy tốt nhất.
Để thêm đường xu hướng vào biểu đồ này, chỉ cần nhấp vào bất kỳ điểm dữ liệu nào trên biểu đồ phân tán. Hành động này sẽ chọn tất cả các điểm dữ liệu trên biểu đồ. Sau đó, nhấp chuột phải vào các điểm dữ liệu đã chọn. Trong menu xuất hiện, chọn “Add Trendline:”

Bạn sẽ thấy một đường nét đứt xuất hiện trên biểu đồ, minh họa chiều hướng chung của mối quan hệ giữa các biến:
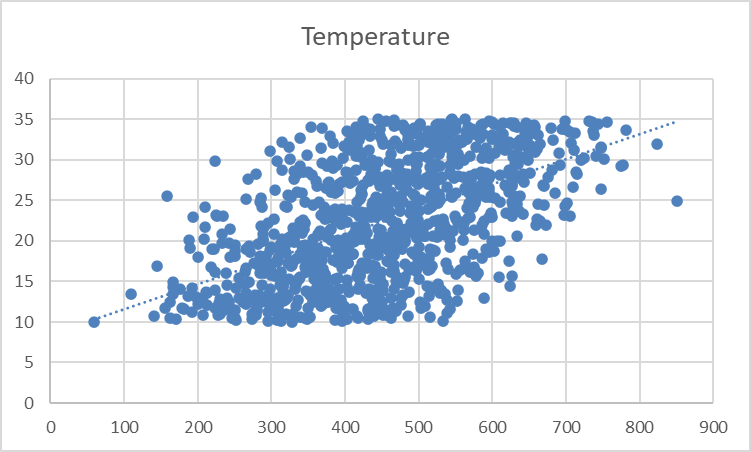
Đường xu hướng hiển thị khá mờ và nhẹ. Hãy điều chỉnh định dạng để dễ nhìn hơn.
Trước hết, nhấp vào đường xu hướng để chọn nó. Bảng tác vụ “Format Trendline” sẽ xuất hiện ở phía bên phải cửa sổ Excel của bạn. Trong bảng này, chọn tùy chọn “Fill & Line”. Sau đó, tăng độ dày của đường xu hướng lên 3pt và đổi màu thành đỏ:

Chúng ta đã tạo thành công một trực quan hóa để hiểu rõ hơn mối quan hệ giữa doanh số kem và nhiệt độ.
Chỉ cần nhìn vào biểu đồ trên, chúng ta có thể nhận thấy có mối quan hệ dương giữa nhiệt độ và doanh số kem. Khi nhiệt độ tăng, dường như doanh số kem cũng tăng theo, cho thấy nhiệt độ là một biến dự báo quan trọng của doanh số kem.
Lưu ý rằng quan sát này tương tự với kết luận chúng ta rút ra từ kết quả phân tích hồi quy ở phần trước.
Giờ đây bạn đã nắm vững cách thực hiện hồi quy tuyến tính trong Excel, diễn giải các thước đo thống kê khác nhau để đánh giá độ phù hợp của mô hình và trực quan hóa phân tích hồi quy bằng biểu đồ phân tán và đường xu hướng.
Nhưng hành trình chưa dừng lại ở đây.
Tin hay không thì tùy, chúng ta mới chỉ chạm tới bề mặt của mô hình dự đoán, và còn rất nhiều điều để học. Dưới đây là một số bước tiếp theo tiềm năng để đào sâu hiểu biết của bạn về chủ đề này.
Hãy thực hành các khái niệm bạn đã học trong bài viết này để đảm bảo không quên chúng. Ví dụ, lấy bộ dữ liệu được sử dụng trong hướng dẫn này và tạo một biểu đồ phân tán để minh họa mối quan hệ giữa doanh số kem và giá.
Bạn thậm chí có thể tiến thêm một bước bằng cách học cách hiển thị phương trình hồi quy trên đường xu hướng.
Như chúng ta đã đề cập trước đó trong bài viết này, việc Excel được sử dụng rộng rãi trong vô số tổ chức khiến kỹ năng này có nhu cầu cao. Nắm vững Excel có thể cải thiện đáng kể cơ hội việc làm của bạn trong nhiều ngành do mức độ ứng dụng rộng rãi của nó.
Nếu bạn gặp khó khăn khi theo dõi hướng dẫn này, hoặc nếu bạn chưa tự tin với các công thức trong Excel, hãy cân nhắc tham gia lộ trình học Excel Fundamentals của chúng tôi. Khóa học này sẽ giới thiệu cho bạn nhiều kỹ thuật trực quan hóa dữ liệu, pivot table, và các hàm logic như COUNTIFs và Nested IFs, mở đường hướng tới việc thành thạo Excel.
Bắt đầu hành trình hồi quy của bạn ngay hôm nay!
Courses
Courses