
Program
Pengembang Python
28 Hr
Ketika para praktisi data membahas penyimpanan data saat ini, sebagian besar waktu mereka merujuk pada di mana data disimpan, apakah pada berkas lokal, basis data SQL atau NoSQL, atau di cloud. Namun, aspek penting lain terkait penyimpanan data adalah bagaimana data disimpan.
Bagaimana penyimpanan data sering berlangsung pada level yang lebih rendah, di inti bahasa pemrograman. Hal ini berkaitan dengan desain alat yang kita gunakan, bukan cara menggunakan alat tersebut. Meski begitu, mengetahui cara data disimpan sangat penting untuk memahami mekanisme dasar yang memungkinkan pekerjaan berjalan. Selain itu, pengetahuan ini dapat membantu kita mengambil keputusan yang lebih baik untuk meningkatkan kinerja komputasi.
Jika Anda benar-benar tertarik pada hashmap, serta linked list, stack, queue, dan graph, daftar di DataCamp agar Anda dapat mengikuti kursus Data Structures and Algorithms in Python kami.
Untuk mendefinisikan hashmap, kita terlebih dahulu perlu memahami apa itu hashing. Hashing adalah proses mengubah key apa pun atau rangkaian karakter menjadi nilai lain. Hasilnya biasanya berupa nilai yang lebih pendek dan berdimensi tetap, sehingga secara komputasional lebih mudah digunakan dibandingkan key asli.
Hashmap, juga dikenal sebagai hashtable, merupakan salah satu implementasi hashing yang paling umum. Hashmap menyimpan pasangan key-value (misalnya, ID karyawan dan nama karyawan) dalam sebuah daftar yang dapat diakses melalui indeksnya. Dapat dikatakan bahwa hashmap adalah struktur data yang memanfaatkan teknik hashing untuk menyimpan data secara asosiatif. Ini adalah struktur data yang dioptimalkan sehingga memungkinkan operasi data yang lebih cepat, termasuk penyisipan, penghapusan, dan pencarian.
Gagasan di balik hashmap adalah mendistribusikan entri (pasangan key/value) ke seluruh array bucket. Diberikan sebuah key, fungsi hashing akan menghitung indeks yang khas yang menunjukkan di mana entri tersebut dapat ditemukan. Penggunaan indeks alih-alih key asli membuat hashmap sangat cocok untuk berbagai operasi data, termasuk penyisipan, penghapusan, dan pencarian data.
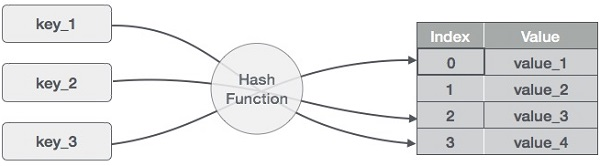
Cara kerja hashmap. Gambar oleh Penulis
Untuk menghitung nilai hash, atau cukup disebut hash, fungsi hash menghasilkan nilai baru sesuai dengan algoritma hashing matematis. Karena pasangan key-value secara teori tidak terbatas, fungsi hashing akan memetakan key berdasarkan ukuran tabel yang diberikan.
Ada banyak fungsi hash yang tersedia, masing-masing dengan kelebihan dan kekurangannya. Tujuan utama fungsi hash adalah selalu mengembalikan nilai yang sama untuk input yang sama.
Yang paling umum antara lain sebagai berikut:
Python mengimplementasikan hashmap melalui tipe data bawaan dictionary. Seperti hashmap, dictionary menyimpan data dalam pasangan {key:value}. Setelah Anda membuat dictionary (lihat bagian berikut), Python akan menerapkan fungsi hash yang sesuai di balik layar untuk menghitung hash dari setiap key.
Dictionary Python memiliki fitur-fitur berikut:
Jadi, jika Anda pernah bertanya-tanya tentang perbedaan antara hashmap vs dictionary, jawabannya sederhana. Dictionary hanyalah implementasi asli hashmap di Python. Sementara hashmap adalah struktur data yang dapat dibuat menggunakan berbagai teknik hashing, dictionary adalah hashmap khusus berbasis Python, yang desain dan perilakunya ditentukan dalam kelas dict milik Python.
Banyak bahasa pemrograman modern, seperti Python, Java, dan C++, mendukung hashmap. Di Python, hashmap diimplementasikan melalui dictionary, sebuah struktur data yang banyak digunakan dan kemungkinan besar sudah Anda kenal. Pada bagian berikut, kita akan membahas dasar-dasar dictionary, cara kerjanya, dan cara mengimplementasikannya menggunakan berbagai paket Python.
Mari kita lihat beberapa operasi dictionary yang paling umum. Untuk mengetahui lebih lanjut cara menggunakan dictionary, lihat Tutorial Dictionary Python kami.
Membuat dictionary di Python cukup sederhana. Anda hanya perlu menggunakan kurung kurawal dan memasukkan pasangan key-value yang dipisahkan dengan koma. Alternatifnya, Anda dapat menggunakan fungsi bawaan dict(). Mari kita buat dictionary yang memetakan ibu kota ke negara:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Penting untuk diingat bahwa sebuah key harus unik dalam dictionary; tidak boleh ada duplikasi. Namun, jika terjadi duplikasi key, alih-alih menghasilkan error, Python akan menganggap kemunculan key terakhir sebagai yang valid dan mengabaikan pasangan key-value pertama. Coba lihat sendiri:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Untuk mencari informasi di dictionary kita, kita perlu menentukan key di dalam tanda kurung siku, dan Python akan mengembalikan nilai yang terkait, seperti berikut:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainJika Anda mencoba mengakses key yang tidak ada dalam dictionary, Python akan memunculkan error. Untuk mencegah hal ini, Anda dapat mengakses key menggunakan metode .get(). Jika key tidak ada, metode ini hanya akan mengembalikan nilai None:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneMari tambahkan pasangan ibu kota-negara baru:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}Sintaks yang sama dapat digunakan untuk memperbarui nilai yang terkait dengan sebuah key. Mari perbaiki nilai untuk Berlin:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Sekarang mari kita hapus salah satu pasangan dalam dictionary kita
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Atau, jika Anda ingin menghapus semua pasangan key-value dalam dictionary, Anda dapat menggunakan metode .clear():
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Jika Anda ingin mengambil semua pasangan key-value, gunakan metode .items(), dan Python akan mengembalikan daftar iterable berupa tuple:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinDemikian pula, jika Anda ingin mengambil daftar iterable berisi key dan value, Anda dapat menggunakan metode .keys() dan .values():
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYHashmap adalah struktur data yang kuat dan digunakan hampir di mana-mana dalam dunia digital. Di bawah ini Anda dapat menemukan daftar aplikasi dunia nyata dari hashmap:
Hashmap adalah struktur data yang sangat serbaguna dan efisien. Namun, mereka juga memiliki masalah dan keterbatasan. Untuk mengatasi tantangan umum yang terkait dengan hashmap, penting untuk mengingat beberapa pertimbangan dan praktik yang baik.
Ini masuk akal: jika isi key berubah, fungsi hash akan mengembalikan hash yang berbeda, sehingga Python tidak akan dapat menemukan nilai yang terkait dengan key tersebut.
Hashing hanya bekerja jika setiap item dipetakan ke lokasi unik di tabel hash. Namun terkadang, fungsi hash dapat mengembalikan output yang sama untuk input yang berbeda. Misalnya, jika Anda menggunakan fungsi hash pembagian, bilangan bulat yang berbeda mungkin memiliki fungsi hash yang sama (menghasilkan sisa yang sama saat menerapkan operasi modulo), sehingga menimbulkan masalah yang disebut collision. Collision harus diselesaikan, dan ada beberapa teknik yang tersedia. Untungnya, dalam kasus dictionary, Python menangani potensi collision di balik layar.
Load factor didefinisikan sebagai rasio jumlah elemen dalam tabel terhadap jumlah total bucket. Ini adalah ukuran untuk memperkirakan seberapa baik data terdistribusi. Secara umum, semakin merata data terdistribusi, semakin kecil kemungkinan terjadinya collision. Sekali lagi, dalam kasus dictionary, Python secara otomatis menyesuaikan ukuran tabel ketika ada penyisipan atau penghapusan pasangan key-value baru.
Fungsi hash yang baik akan meminimalkan jumlah collision, mudah dihitung, dan mendistribusikan item secara merata di tabel hash. Ini dapat dilakukan dengan meningkatkan ukuran tabel atau kompleksitas fungsi hash. Meskipun praktis untuk jumlah item yang kecil, hal ini tidak layak ketika jumlah item yang mungkin sangat besar, karena akan menghasilkan hashmap yang boros memori dan kurang efisien.
Dictionary memang hebat, tetapi struktur data lain mungkin lebih cocok untuk data dan kebutuhan spesifik Anda. Pada akhirnya, dictionary tidak mendukung operasi umum seperti indexing, slicing, dan concatenation, sehingga membuatnya kurang fleksibel dan lebih sulit digunakan dalam skenario tertentu.
Seperti telah disebutkan, Python mengimplementasikan hashmap melalui dictionary bawaan. Namun, penting untuk dicatat bahwa ada alat Python native lainnya, serta pustaka pihak ketiga, untuk memanfaatkan kekuatan hashmap.
Mari kita lihat beberapa contoh paling populernya.
Setiap kali Anda mencoba mengakses key yang tidak ada dalam dictionary, Python akan mengembalikan KeyError. Salah satu cara mencegah hal ini adalah dengan mencari informasi menggunakan metode .get(). Namun, cara yang lebih dioptimalkan adalah menggunakan Defaultdict, yang tersedia di modul collections. Defaultdict dan dictionary hampir sama. Satu-satunya perbedaannya adalah Defaultdict tidak pernah memunculkan error karena menyediakan nilai default untuk key yang tidak ada.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter adalah subclass dari dictionary Python yang dirancang khusus untuk menghitung objek yang dapat di-hash. Ini adalah dictionary di mana elemen disimpan sebagai key dan hitungannya disimpan sebagai value.
Ada beberapa cara untuk menginisialisasi Counter:
Dengan urutan item.
Dengan key dan hitungan dalam dictionary.
Menggunakan pemetaan name:value.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})Kelas Counter hadir dengan serangkaian metode praktis untuk melakukan perhitungan umum.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, juga dikenal sebagai sklearn, adalah pustaka machine learning Python yang tangguh dan bersumber terbuka. Pustaka ini dibuat untuk membantu menyederhanakan proses penerapan model machine learning dan statistik di Python.
Sklearn hadir dengan berbagai metode hashing yang bisa sangat berguna untuk proses rekayasa fitur.
Salah satu yang paling umum adalah metode CountVectorizer. Metode ini digunakan untuk mengubah teks tertentu menjadi vektor berdasarkan frekuensi setiap kata yang muncul dalam keseluruhan teks. CountVectorizer sangat membantu dalam konteks analisis teks.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Ada metode hashing lain di sklearn, termasuk FeatureHasher dan DictVectorizer. Studi kasus School Budgeting with Machine Learning in Python kami adalah contoh yang sangat baik untuk mempelajari cara kerjanya dalam praktik.
Selamat telah menyelesaikan tutorial tentang hashmap ini. Kami harap Anda sekarang memiliki pemahaman yang lebih baik tentang hashmap dan dictionary Python. Jika Anda ingin mempelajari lebih lanjut tentang dictionary dan cara menggunakannya dalam skenario nyata, kami sangat menyarankan Anda membaca Tutorial Dictionary Python khusus kami, serta Tutorial Python Dictionary Comprehension.
Terakhir, jika Anda baru memulai belajar Python dan ingin mempelajari lebih jauh, ikuti kursus Introduction to Data Science in Python dari DataCamp dan lihat Python Tutorial for Beginners kami.
Mulai Perjalanan Python Anda Hari Ini!
Program
Kursus
Kursus
blogs
David Woods
13 mnt
blogs
Dario Radečić
15 mnt
blogs
Hugo Bowne-Anderson
13 mnt
blogs
Javier Canales Luna
14 mnt
