
Leerpad
Python-ontwikkelaar
28 Hr
Als dataprofessionals het vandaag over gegevensopslag hebben, bedoelen ze meestal waar de data wordt opgeslagen: lokale bestanden, SQL- of NoSQL-databases of de cloud. Een ander belangrijk aspect van gegevensopslag is echter hoe data wordt opgeslagen.
Het hoe van gegevensopslag speelt zich vaak op een lager niveau af, in de kern van programmeertalen. Het heeft te maken met het ontwerp van de tools die we gebruiken, niet alleen met hoe we ze gebruiken. Toch is weten hoe data wordt opgeslagen cruciaal om de onderliggende mechanismen te begrijpen die ons werk mogelijk maken. Bovendien helpt deze kennis je betere beslissingen te nemen om de rekenprestaties te verbeteren.
Als je echt geïnteresseerd bent in hashmaps, maar ook in gelinkte lijsten, stacks, queues en grafen, meld je dan aan bij DataCamp zodat je onze cursus Data Structures and Algorithms in Python kunt volgen.
Om een hashmap te definiëren, moeten we eerst begrijpen wat hashen is. Hashen is het proces waarbij een gegeven sleutel of tekenreeks wordt omgezet in een andere waarde. Het resultaat is normaal gesproken een kortere waarde met vaste lengte, die computationeel eenvoudiger is om mee te werken dan de originele sleutel.
Hashmaps, ook wel hashtables genoemd, zijn een van de meest voorkomende implementaties van hashen. Hashmaps slaan key-valueparen op (bijv. werknemer-ID en werknemersnaam) in een lijst die via de index toegankelijk is. Je zou kunnen zeggen dat een hashmap een datastructuur is die hashingtechnieken inzet om data associatief op te slaan. Het zijn geoptimaliseerde datastructuren die snellere bewerkingen op data mogelijk maken, zoals invoegen, verwijderen en zoeken.
Het idee achter hashmaps is om de items (key/valueparen) te verdelen over een array van buckets. Gegeven een sleutel berekent een hashfunctie een unieke index die aangeeft waar het item kan worden gevonden. Het gebruik van een index in plaats van de oorspronkelijke sleutel maakt hashmaps bijzonder geschikt voor verschillende databewerkingen, waaronder invoegen, verwijderen en zoeken.
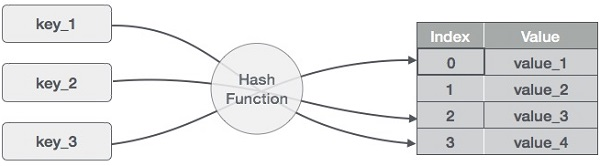
Hoe een hashmap werkt. Afbeelding door de auteur
Om de hashwaarde, of kortweg hash, te berekenen, genereert een hashfunctie nieuwe waarden volgens een wiskundig hashingalgoritme. Omdat key-valueparen in theorie onbeperkt zijn, zal de hashfunctie de sleutels toewijzen op basis van een gegeven tabelgrootte.
Er zijn meerdere hashfuncties beschikbaar, elk met voor- en nadelen. Het hoofddoel van een hashfunctie is om altijd dezelfde waarde voor dezelfde input terug te geven.
De meest gebruikelijke zijn de volgende:
Python implementeert hashmaps via het ingebouwde dictionary-datatype. Net als hashmaps slaan dictionaries data op in {key:value}-paren. Zodra je de dictionary maakt (zie de volgende sectie), past Python onder de motorkap een handige hashfunctie toe om de hash van elke sleutel te berekenen.
Python-dictionaries hebben de volgende eigenschappen:
Dus als je je ooit hebt afgevraagd wat het verschil is tussen hashmaps en dictionaries, is het antwoord simpel. Een dictionary is gewoon Pythons native implementatie van hashmaps. Waar een hashmap een datastructuur is die met verschillende hashingtechnieken kan worden gemaakt, is een dictionary een specifieke, Python-gebaseerde hashmap, waarvan het ontwerp en gedrag zijn vastgelegd in Pythons dict-klasse.
Veel moderne programmeertalen, zoals Python, Java en C++, ondersteunen hashmaps. In Python worden hashmaps geïmplementeerd via dictionaries, een veelgebruikte datastructuur die je waarschijnlijk al kent. In de volgende secties behandelen we de basis van dictionaries, hoe ze werken en hoe je ze implementeert met verschillende Python-pakketten.
Laten we enkele van de meest voorkomende dictionary-bewerkingen bekijken. Wil je meer weten over het gebruik van dictionaries, bekijk dan onze Python Dictionaries Tutorial.
Het maken van dictionaries in Python is vrij eenvoudig. Je gebruikt accolades en voegt de key-valueparen in, gescheiden door komma’s. Je kunt ook de ingebouwde functie dict() gebruiken. Laten we een dictionary maken die hoofdsteden aan landen koppelt:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Het is belangrijk te onthouden dat een sleutel uniek moet zijn in een dictionary; duplicaten zijn niet toegestaan. In het geval van dubbele sleutels geeft Python echter geen fout, maar beschouwt het de laatste instantie van de sleutel als geldig en negeert het eenvoudigweg het eerste key-valuepaar. Kijk zelf maar:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Om in onze dictionary te zoeken, geef je de sleutel tussen blokhaken op en Python retourneert de bijbehorende waarde, als volgt:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainAls je probeert een sleutel te benaderen die niet in de dictionary voorkomt, zal Python een fout geven. Om dit te voorkomen kun je sleutels ook benaderen met de .get()-methode. In het geval van een niet-bestaande sleutel retourneert die gewoon de waarde None:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneLaten we een nieuw paar hoofdstad-land toevoegen:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}Met dezelfde syntaxis kun je de waarde bij een sleutel bijwerken. Laten we de waarde bij Berlijn corrigeren:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Laten we nu een van de paren in onze dictionary verwijderen
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Als je alle key-valueparen in de dictionary wilt verwijderen, kun je de .clear()-methode gebruiken:
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Als je alle key-valueparen wilt ophalen, gebruik dan de .items()-methode; Python retourneert dan een iterabele lijst van tuples:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinAls je respectievelijk een iterabele lijst met de sleutels en de waarden wilt ophalen, kun je de methoden .keys() en .values() gebruiken:
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYHashmaps zijn krachtige datastructuren die bijna overal in de digitale wereld worden gebruikt. Hieronder vind je een lijst met realistische toepassingen van hashmaps:
Hashmaps zijn ongelooflijk veelzijdige en efficiënte datastructuren. Ze kennen echter ook problemen en beperkingen. Om de veelvoorkomende uitdagingen te tackelen, is het belangrijk om enkele aandachtspunten en good practices in gedachten te houden.
Dat is logisch: als de inhoud van de sleutel verandert, geeft de hashfunctie een andere hash terug en kan Python de bij de sleutel horende waarde niet meer vinden.
Hashen werkt alleen als elk item naar een unieke locatie in de hashtabel wordt gemapt. Soms kunnen hashfuncties echter dezelfde output voor verschillende inputs teruggeven. Als je bijvoorbeeld een deelmodemethode gebruikt, kunnen verschillende gehele getallen dezelfde hash hebben (ze kunnen dezelfde rest opleveren bij deling modulo), wat een probleem veroorzaakt dat collision wordt genoemd. Collisions moeten worden opgelost en er bestaan verschillende technieken. In het geval van dictionaries handelt Python mogelijke collisions gelukkig onder de motorkap af.
De load factor is de verhouding tussen het aantal elementen in de tabel en het totale aantal buckets. Het is een maatstaf om in te schatten hoe gelijkmatig de data is verdeeld. Vuistregel: hoe gelijkmatiger de data is verdeeld, hoe kleiner de kans op collisions. Ook hier past Python bij dictionaries de tabelgrootte automatisch aan bij het invoegen of verwijderen van key-valueparen.
Een goede hashfunctie minimaliseert het aantal collisions, is eenvoudig te berekenen en verdeelt de items gelijkmatig over de hashtabel. Dit kan door de tabelgrootte te vergroten of de hashfunctie complexer te maken. Hoewel dit praktisch is bij kleine aantallen items, is het niet haalbaar wanneer het aantal mogelijke items groot is, omdat dit zou leiden tot geheugenintensieve en minder efficiënte hashmaps.
Dictionaries zijn geweldig, maar andere datastructuren zijn mogelijk geschikter voor jouw specifieke data en behoeften. Uiteindelijk ondersteunen dictionaries geen standaardbewerkingen zoals indexeren, slicen en concatenatie, waardoor ze in bepaalde situaties minder flexibel en lastiger te gebruiken zijn.
Zoals al genoemd, implementeert Python hashmaps via ingebouwde dictionaries. Het is echter goed om te weten dat er ook andere native Python-tools en externe libraries zijn om de kracht van hashmaps te benutten.
Laten we enkele van de meest populaire voorbeelden bekijken.
Elke keer dat je probeert een sleutel te benaderen die niet in je dictionary voorkomt, geeft Python een KeyError. Een manier om dit te voorkomen is door met de .get()-methode te zoeken. Een efficiëntere manier is echter het gebruik van Defaultdict, beschikbaar in de module collections. Defaultdict en dictionaries zijn bijna hetzelfde. Het enige verschil is dat Defaultdict nooit een fout geeft, omdat het een standaardwaarde levert voor niet-bestaande sleutels.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter is een subklasse van een Python-dictionary die specifiek is ontworpen voor het tellen van hashbare objecten. Het is een dictionary waarbij elementen als sleutels worden opgeslagen en hun tellingen als waarden.
Er zijn verschillende manieren om Counter te initialiseren:
Met een sequentie van items.
Met sleutels en tellingen in een dictionary.
Met behulp van naam:waarde-mapping.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})De Counter-klasse heeft een reeks handige methoden om veelvoorkomende berekeningen te maken.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, ook wel sklearn genoemd, is een open-source, robuuste Python-machinelearningbibliotheek. Ze is ontwikkeld om het implementeren van machine learning- en statistische modellen in Python te vereenvoudigen.
Sklearn bevat diverse hashingmethoden die erg nuttig kunnen zijn bij feature engineering.
Een van de meest gebruikte is de methode CountVectorizer. Deze wordt gebruikt om tekst om te zetten in een vector op basis van de frequentie van elk woord dat in de volledige tekst voorkomt. CountVectorizer is bijzonder handig in tekstanalyse.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Er zijn andere hashingmethoden in sklearn, waaronder FeatureHasher en DictVectorizer. Onze casestudy School Budgeting with Machine Learning in Python is een mooi voorbeeld om te leren hoe ze in de praktijk werken.
Gefeliciteerd met het afronden van deze tutorial over hashmaps. We hopen dat je nu een beter begrip hebt van hashmaps en Python-dictionaries. Als je meer wilt leren over dictionaries en hoe je ze in echte scenario’s gebruikt, raden we je onze Python Dictionaries Tutorial en onze Python Dictionary Comprehension Tutorial van harte aan.
Ben je net begonnen met Python en wil je meer leren, volg dan DataCamps cursus Introduction to Data Science in Python en bekijk onze Python Tutorial for Beginners.
Begin vandaag nog met je Python-reis!
Leerpad
Cursus
Cursus
blog
Adel Nehme
15 min
