
Programma
Sviluppatore Python
28 h
Quando oggi chi lavora con i dati parla di archiviazione, quasi sempre si riferisce a dove vengono salvati i dati: file locali, database SQL o NoSQL, oppure il cloud. Tuttavia, un altro aspetto importante legato all’archiviazione dei dati è come vengono salvati.
Il come dell’archiviazione avviene spesso a un livello più basso, nel cuore stesso dei linguaggi di programmazione. Ha a che fare con il design degli strumenti che usiamo, più che con il loro utilizzo. Eppure, sapere come sono archiviati i dati è fondamentale per capire i meccanismi sottostanti che rendono possibile il lavoro. Inoltre, questa conoscenza può aiutarci a prendere decisioni migliori per migliorare le prestazioni di calcolo.
Se ti interessano davvero le hashmap, così come liste collegate, stack, code e grafi, iscriviti a DataCamp per seguire il nostro corso Data Structures and Algorithms in Python.
Per definire una hashmap, dobbiamo prima capire cos’è l’hashing. L’hashing è il processo di trasformazione di una qualsiasi chiave o stringa di caratteri in un altro valore. Il risultato è normalmente un valore più corto, di lunghezza fissa, che è computazionalmente più semplice da gestire rispetto alla chiave originale.
Le hashmap, note anche come hashtable, rappresentano una delle implementazioni più comuni dell’hashing. Le hashmap memorizzano coppie chiave-valore (ad esempio, ID dipendente e nome del dipendente) in un elenco accessibile tramite il suo indice. Si potrebbe dire che una hashmap è una struttura dati che sfrutta tecniche di hashing per archiviare i dati in modo associativo. Sono strutture dati ottimizzate che consentono operazioni sui dati più veloci, tra cui inserimento, eliminazione e ricerca.
L’idea alla base delle hashmap è distribuire le voci (coppie chiave/valore) in un array di bucket. Data una chiave, una funzione di hashing calcolerà un indice distinto che suggerisce dove trovare la voce. L’uso di un indice al posto della chiave originale rende le hashmap particolarmente adatte a molte operazioni sui dati, inclusi inserimento, rimozione e ricerca.
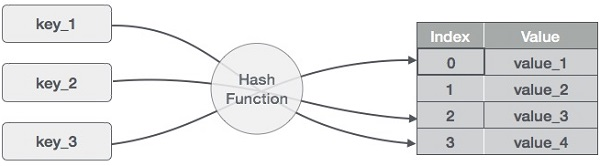
Come funziona una hashmap. Immagine dell’autore
Per calcolare il valore di hash, o semplicemente hash, una funzione di hash genera nuovi valori secondo un algoritmo matematico di hashing. Poiché in teoria le coppie chiave-valore sono illimitate, la funzione di hashing mapperà le chiavi in base a una data dimensione della tabella.
Esistono più funzioni di hash, ognuna con pro e contro. L’obiettivo principale di una funzione di hash è restituire sempre lo stesso valore per lo stesso input.
Le più comuni sono le seguenti:
Python implementa le hashmap tramite il tipo di dato nativo dizionario. Come le hashmap, i dizionari memorizzano i dati in coppie {chiave:valore}. Una volta creato il dizionario (vedi la sezione successiva), Python applicherà una comoda funzione di hash sotto il cofano per calcolare l’hash di ogni chiave.
I dizionari Python offrono le seguenti caratteristiche:
Quindi, se ti sei mai chiesto quali siano le differenze tra hashmap e dizionari, la risposta è semplice. Un dizionario è semplicemente l’implementazione nativa delle hashmap in Python. Mentre una hashmap è una struttura dati che può essere creata usando diverse tecniche di hashing, un dizionario è una particolare hashmap basata su Python, il cui design e comportamento sono specificati nella classe dict di Python.
Molti linguaggi di programmazione moderni, come Python, Java e C++, supportano le hashmap. In Python, le hashmap sono implementate tramite i dizionari, una struttura dati ampiamente usata che probabilmente conosci già. Nelle sezioni seguenti, tratteremo le basi dei dizionari, come funzionano e come implementarli utilizzando diversi pacchetti Python.
Vediamo alcune delle operazioni più comuni sui dizionari. Per approfondire l’uso dei dizionari, dai un’occhiata al nostro tutorial sui dizionari in Python.
Creare dizionari in Python è piuttosto semplice. Devi solo usare le parentesi graffe e inserire le coppie chiave-valore separate da virgole. In alternativa, puoi usare la funzione nativa dict(). Creiamo un dizionario che associa capitali a paesi:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}È importante ricordare che una chiave deve essere unica in un dizionario; non sono ammessi duplicati. Tuttavia, in caso di chiavi duplicate, invece di generare un errore, Python considererà valida l’ultima istanza della chiave e ignorerà semplicemente la prima coppia chiave-valore. Guarda tu stesso:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Per cercare informazioni nel nostro dizionario, dobbiamo specificare la chiave tra parentesi quadre e Python restituirà il valore associato, come segue:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainSe provi ad accedere a una chiave non presente nel dizionario, Python solleverà un errore. Per evitarlo, puoi accedere alle chiavi con il metodo .get(). In caso di chiave inesistente, restituirà semplicemente il valore None:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneAggiungiamo una nuova coppia capitale-paese:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}La stessa sintassi può essere usata per aggiornare il valore associato a una chiave. Correggiamo il valore associato a Berlin:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Ora eliminiamo una delle coppie nel nostro dizionario
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Oppure, se vuoi eliminare tutte le coppie chiave-valore nel dizionario, puoi usare il metodo .clear():
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Se vuoi recuperare tutte le coppie chiave-valore, usa il metodo .items(), e Python restituirà un elenco iterabile di tuple:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinAllo stesso modo, se vuoi ottenere un elenco iterabile con le chiavi e con i valori, puoi usare rispettivamente i metodi .keys() e .values():
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYLe hashmap sono strutture dati potenti, utilizzate quasi ovunque nel mondo digitale. Di seguito trovi un elenco di applicazioni reali delle hashmap:
Le hashmap sono strutture dati estremamente versatili ed efficienti. Tuttavia, presentano anche problemi e limitazioni. Per affrontare le sfide comuni associate alle hashmap, è importante tenere a mente alcune considerazioni e buone pratiche.
Ha senso: se il contenuto della chiave cambia, la funzione di hash restituirà un hash diverso, quindi Python non sarà in grado di trovare il valore associato alla chiave.
L’hashing funziona solo se ogni elemento mappa a una posizione univoca nella tabella hash. Ma a volte le funzioni di hash possono restituire lo stesso output per input diversi. Ad esempio, se usi una funzione di hash per divisione, interi diversi possono avere la stessa funzione di hash (possono restituire lo stesso resto applicando la divisione modulo), creando così un problema chiamato collisione. Le collisioni vanno risolte e esistono diverse tecniche. Per fortuna, nel caso dei dizionari, Python gestisce le potenziali collisioni sotto il cofano.
Il load factor è definito come il rapporto tra il numero di elementi nella tabella e il numero totale di bucket. È una misura per stimare quanto sono ben distribuiti i dati. In linea di massima, più i dati sono distribuiti uniformemente, minore è la probabilità di collisioni. Anche qui, nel caso dei dizionari, Python adatta automaticamente la dimensione della tabella in caso di nuove inserzioni o eliminazioni di coppie chiave-valore.
Una buona funzione di hash dovrebbe minimizzare il numero di collisioni, essere facile da calcolare e distribuire uniformemente gli elementi nella tabella hash. Questo potrebbe essere ottenuto aumentando la dimensione della tabella o la complessità della funzione di hash. Sebbene sia pratico per un numero ridotto di elementi, non è fattibile quando il numero di elementi possibili è grande, poiché porterebbe a hashmap che consumano molta memoria e meno efficienti.
I dizionari sono ottimi, ma altre strutture dati potrebbero essere più adatte ai tuoi dati e alle tue esigenze specifiche. In fin dei conti, i dizionari non supportano operazioni comuni come indicizzazione, slicing e concatenazione, rendendoli meno flessibili e più difficili da usare in alcuni scenari.
Come già accennato, Python implementa le hashmap tramite i dizionari integrati. Tuttavia, è importante notare che esistono altri strumenti nativi di Python, oltre a librerie di terze parti, per sfruttare la potenza delle hashmap.
Vediamo alcuni degli esempi più popolari.
Ogni volta che provi ad accedere a una chiave non presente nel tuo dizionario, Python restituirà un KeyError. Un modo per evitarlo è cercare le informazioni usando il metodo .get(). Tuttavia, un modo ottimizzato è usare Defaultdict, disponibile nel modulo collections. Defaultdict e i dizionari sono quasi uguali. L’unica differenza è che Defaultdict non solleva mai un errore perché fornisce un valore predefinito per le chiavi inesistenti.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter è una sottoclasse di un dizionario Python progettata specificamente per contare oggetti hashable. È un dizionario in cui gli elementi sono memorizzati come chiavi e i loro conteggi come valori.
Ci sono diversi modi per inizializzare Counter:
Con una sequenza di elementi.
Con chiavi e conteggi in un dizionario.
Usando la mappatura nome:valore.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})La classe Counter offre una serie di metodi pratici per effettuare calcoli comuni.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, nota anche come sklearn, è una solida libreria open-source di machine learning per Python. È stata creata per semplificare l’implementazione di modelli di machine learning e statistici in Python.
Sklearn include vari metodi di hashing molto utili per i processi di feature engineering.
Uno dei più comuni è il metodo CountVectorizer. Viene usato per trasformare un testo in un vettore basato sulla frequenza di ciascuna parola presente nel testo. CountVectorizer è particolarmente utile nell’analisi del testo.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Esistono altri metodi di hashing in sklearn, tra cui FeatureHasher e DictVectorizer. Il nostro case study School Budgeting with Machine Learning in Python è un ottimo esempio per imparare come funzionano nella pratica.
Congratulazioni per aver completato questo tutorial sulle hashmap. Speriamo che ora tu abbia una comprensione migliore delle hashmap e dei dizionari Python. Se vuoi approfondire i dizionari e il loro uso in scenari reali, ti consigliamo vivamente di leggere il nostro tutorial sui dizionari in Python dedicato, così come il nostro tutorial sulle dictionary comprehension in Python.
Infine, se stai iniziando con Python e vuoi saperne di più, segui il corso di DataCamp Introduction to Data Science in Python e dai un’occhiata al nostro Python Tutorial for Beginners.
Inizia oggi il tuo percorso con Python!
Programma
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

