
Tracks
Nhà phát triển Python
28 giờ
Khi các chuyên gia dữ liệu nói về lưu trữ dữ liệu hiện nay, phần lớn họ đề cập đến nơi dữ liệu được lưu, như tệp cục bộ, cơ sở dữ liệu SQL hoặc NoSQL, hay đám mây. Tuy nhiên, một khía cạnh quan trọng khác liên quan đến lưu trữ dữ liệu là cách dữ liệu được lưu.
Cách lưu trữ dữ liệu thường diễn ra ở mức thấp hơn, ngay tại lõi của các ngôn ngữ lập trình. Nó liên quan đến thiết kế của các công cụ chúng ta dùng hơn là cách sử dụng chúng. Dẫu vậy, biết dữ liệu được lưu như thế nào là điều then chốt để hiểu cơ chế nền tảng giúp công việc trở nên khả thi. Hơn nữa, kiến thức này có thể giúp chúng ta đưa ra quyết định tốt hơn để cải thiện hiệu năng tính toán.
Nếu bạn thực sự quan tâm đến hashmaps, cũng như danh sách liên kết, ngăn xếp, hàng đợi và đồ thị, hãy đăng ký DataCamp để tham gia khóa Cấu trúc Dữ liệu và Thuật toán trong Python của chúng tôi.
Để định nghĩa hashmap, trước tiên chúng ta cần hiểu hashing là gì. Hashing là quá trình biến đổi bất kỳ khóa nào hoặc một chuỗi ký tự thành một giá trị khác. Kết quả thường là một giá trị ngắn hơn, có độ dài cố định, giúp việc xử lý tính toán dễ dàng hơn so với khóa ban đầu.
Hashmap, còn được gọi là hashtable, là một trong những cách triển khai hashing phổ biến nhất. Hashmap lưu trữ các cặp khóa - giá trị (ví dụ: mã nhân viên và tên nhân viên) trong một danh sách có thể truy cập thông qua chỉ mục của nó. Có thể nói hashmap là một cấu trúc dữ liệu tận dụng kỹ thuật băm để lưu trữ dữ liệu theo kiểu kết hợp. Đây là các cấu trúc dữ liệu được tối ưu hóa, cho phép thao tác dữ liệu nhanh hơn, bao gồm chèn, xóa và tìm kiếm.
Ý tưởng đằng sau hashmap là phân phối các mục nhập (cặp khóa/giá trị) vào một mảng các bucket. Với một khóa cho trước, một hàm băm sẽ tính toán một chỉ mục riêng biệt gợi ý nơi có thể tìm thấy mục nhập. Việc dùng chỉ mục thay vì khóa gốc khiến hashmap đặc biệt phù hợp cho nhiều thao tác dữ liệu, bao gồm chèn, xóa và tìm kiếm.
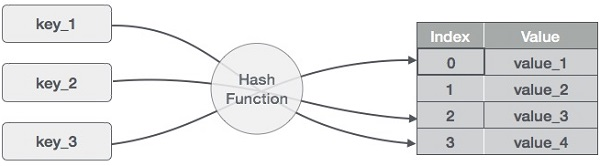
Hashmap hoạt động như thế nào. Ảnh: Tác giả
Để tính giá trị băm, hay đơn giản là hash, một hàm băm sẽ tạo ra các giá trị mới theo một thuật toán băm toán học. Vì các cặp khóa - giá trị về lý thuyết là không giới hạn, hàm băm sẽ ánh xạ các khóa dựa trên kích thước bảng cho trước.
Có nhiều hàm băm khác nhau, mỗi loại có ưu và nhược điểm riêng. Mục tiêu chính của một hàm băm là luôn trả về cùng một giá trị cho cùng một đầu vào.
Phổ biến nhất gồm:
Python triển khai hashmap thông qua kiểu dữ liệu từ điển (dictionary) tích hợp sẵn. Giống như hashmap, dictionary lưu dữ liệu theo cặp {key:value}. Sau khi bạn tạo dictionary (xem phần tiếp theo), Python sẽ áp dụng một hàm băm tiện dụng ở tầng dưới để tính hash cho mỗi khóa.
Dictionary trong Python có các đặc điểm sau:
Vì vậy, nếu bạn từng thắc mắc sự khác nhau giữa hashmap và dictionary, câu trả lời rất đơn giản. Dictionary chỉ là cách triển khai hashmap gốc của Python. Trong khi hashmap là một cấu trúc dữ liệu có thể được tạo bằng nhiều kỹ thuật băm khác nhau, dictionary là một hashmap cụ thể dựa trên Python, có thiết kế và hành vi được quy định trong lớp dict của Python.
Nhiều ngôn ngữ lập trình hiện đại như Python, Java và C++ đều hỗ trợ hashmap. Trong Python, hashmap được triển khai thông qua dictionary, một cấu trúc dữ liệu được dùng rộng rãi mà có lẽ bạn đã biết. Ở các phần sau, chúng ta sẽ điểm qua những điều cơ bản về dictionary, cách chúng hoạt động và cách triển khai bằng các gói Python khác nhau.
Hãy xem một số thao tác thường gặp với dictionary. Để tìm hiểu thêm cách dùng dictionary, xem Hướng dẫn Python Dictionaries của chúng tôi.
Tạo dictionary trong Python khá đơn giản. Bạn chỉ cần dùng dấu ngoặc nhọn và chèn các cặp khóa - giá trị, ngăn cách bằng dấu phẩy. Ngoài ra, bạn có thể dùng hàm tích hợp dict(). Hãy tạo một dictionary ánh xạ thủ đô với quốc gia:
# Create dictionary
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}
# Print the content of the dictionary
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Điều quan trọng cần nhớ là một khóa phải là duy nhất trong dictionary; không cho phép trùng lặp. Tuy nhiên, trong trường hợp khóa trùng, thay vì báo lỗi, Python sẽ lấy lần xuất hiện cuối cùng của khóa là hợp lệ và đơn giản bỏ qua cặp khóa - giá trị đầu tiên. Tự kiểm chứng nhé:
dictionary_capitals = {'Madrid': 'China', 'Lisboa': 'Portugal',
'London': 'United Kingdom','Madrid':'Spain'}
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom'}Để tìm thông tin trong dictionary, chúng ta cần chỉ định khóa trong ngoặc vuông, và Python sẽ trả về giá trị tương ứng, như sau:
# Search for data
print(dictionary_capitals['Madrid'])
# Expected output: SpainNếu bạn cố truy cập một khóa không có trong dictionary, Python sẽ ném lỗi. Để tránh điều này, bạn có thể truy cập khóa bằng phương thức .get(). Trong trường hợp khóa không tồn tại, sẽ chỉ trả về giá trị None:
print(dictionary_capitals.get('Prague'))
# Expected output: NoneHãy thêm một cặp thủ đô - quốc gia mới:
# Create a new key-value pair
dictionary_capitals['Berlin'] = 'Italy'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Italy'}Cú pháp tương tự có thể dùng để cập nhật giá trị gắn với một khóa. Hãy sửa giá trị của Berlin:
# Update the value of a key
dictionary_capitals['Berlin'] = 'Germany'
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'Lisboa': 'Portugal', 'London': 'United Kingdom', 'Berlin': 'Germany'}Bây giờ hãy xóa một cặp trong dictionary của chúng ta
# Delete key-value pair
del dictionary_capitals['Lisboa']
print(dictionary_capitals)
# Expected output:
# {'Madrid': 'Spain', 'London': 'United Kingdom', 'Berlin': 'Germany'}Hoặc, nếu bạn muốn xóa tất cả các cặp khóa - giá trị trong dictionary, bạn có thể dùng phương thức .clear():
dictionary_capitals.clear()
print(dictionary_capitals)
# Expected output: {}Nếu bạn muốn lấy tất cả các cặp khóa - giá trị, hãy dùng phương thức .items(), và Python sẽ trả về một danh sách có thể lặp gồm các tuple:
dictionary_capitals = {'Madrid': 'Spain', 'Lisboa': 'Portugal',
'London': 'United Kingdom', 'Berlin': 'Germany'}
print(dictionary_capitals.items())
# Expected output:
# dict_items([('Madrid', 'Spain'), ('Lisboa', 'Portugal'),
# ('London', 'United Kingdom'), ('Berlin', 'Germany')])# Iterate over key-value pairs
for key, value in dictionary_capitals.items():
print('the capital of {} is {}'.format(value, key))
# Expected output:
# the capital of Spain is Madrid
# the capital of Portugal is Lisboa
# the capital of United Kingdom is London
# the capital of Germany is BerlinTương tự, nếu bạn muốn lấy danh sách có thể lặp chỉ với khóa hoặc giá trị, bạn có thể dùng lần lượt các phương thức .keys() và .values():
print(dictionary_capitals.keys())
# Expected output:
# dict_keys(['Madrid', 'Lisboa', 'London', 'Berlin'])for key in dictionary_capitals.keys():
print(key.upper())
# Expected output:
# MADRID
# LISBOA
# LONDON
# BERLINprint(dictionary_capitals.values())
# Expected output:
# dict_values(['Spain', 'Portugal', 'United Kingdom', 'Germany'])for value in dictionary_capitals.values():
print(value.upper())
# Expected output:
# SPAIN
# PORTUGAL
# UNITED KINGDOM
# GERMANYHashmap là các cấu trúc dữ liệu mạnh mẽ, được dùng gần như ở mọi nơi trong thế giới số. Dưới đây là danh sách các ứng dụng thực tế của hashmap:
Hashmap là các cấu trúc dữ liệu cực kỳ linh hoạt và hiệu quả. Tuy nhiên, chúng cũng có vấn đề và hạn chế. Để giải quyết các thách thức thường gặp với hashmap, điều quan trọng là ghi nhớ một số cân nhắc và thực hành tốt.
Điều này hợp lý: nếu nội dung của khóa thay đổi, hàm băm sẽ trả về một hash khác, nên Python sẽ không thể tìm được giá trị gắn với khóa đó.
Hashing chỉ hoạt động nếu mỗi phần tử ánh xạ đến một vị trí duy nhất trong bảng băm. Nhưng đôi khi, các hàm băm có thể trả về cùng một đầu ra cho các đầu vào khác nhau. Ví dụ, nếu bạn dùng hàm băm chia, các số nguyên khác nhau có thể có cùng giá trị băm (chúng có thể cho cùng phần dư khi chia lấy dư), từ đó tạo ra vấn đề gọi là va chạm. Va chạm phải được xử lý, và có một số kỹ thuật để làm điều này. May mắn là, với dictionary, Python xử lý các va chạm tiềm ẩn ở tầng dưới.
Hệ số tải được định nghĩa là tỷ lệ giữa số phần tử trong bảng và tổng số bucket. Đây là thước đo để ước tính dữ liệu được phân phối tốt đến đâu. Theo kinh nghiệm, dữ liệu phân phối càng đều thì khả năng va chạm càng thấp. Một lần nữa, với dictionary, Python tự động điều chỉnh kích thước bảng khi có thêm hoặc xóa cặp khóa - giá trị.
Một hàm băm tốt sẽ giảm thiểu số va chạm, dễ tính toán và phân phối đều các phần tử trong bảng băm. Có thể đạt được điều này bằng cách tăng kích thước bảng hoặc độ phức tạp của hàm băm. Tuy hữu dụng với số lượng phần tử nhỏ, nhưng khi số phần tử khả dĩ lớn, điều này không khả thi vì sẽ dẫn tới hashmap tốn bộ nhớ và kém hiệu quả.
Dictionary rất tốt, nhưng có thể có các cấu trúc dữ liệu khác phù hợp hơn với dữ liệu và nhu cầu cụ thể của bạn. Cuối cùng, dictionary không hỗ trợ các thao tác phổ biến như indexing, slicing và concatenation, khiến chúng kém linh hoạt và khó làm việc hơn trong một số tình huống.
Như đã đề cập, Python triển khai hashmap thông qua dictionary tích hợp sẵn. Tuy nhiên, cũng cần lưu ý rằng có các công cụ gốc khác của Python, cũng như thư viện của bên thứ ba, để khai thác sức mạnh của hashmap.
Hãy xem một vài ví dụ phổ biến.
Mỗi lần bạn cố truy cập một khóa không có trong dictionary, Python sẽ trả về KeyError. Một cách để tránh điều này là tìm kiếm thông tin bằng phương thức .get(). Tuy nhiên, một cách tối ưu là dùng Defaultdict trong mô-đun collections. Defaultdict và dictionary gần như giống nhau. Khác biệt duy nhất là Defaultdict không bao giờ báo lỗi vì nó cung cấp giá trị mặc định cho các khóa không tồn tại.
from collections import defaultdict
# Defining the dict
capitals = defaultdict(lambda: "The key doesn't exist")
capitals['Madrid'] = 'Spain'
capitals['Lisboa'] = 'Portugal'
print(capitals['Madrid'])
print(capitals['Lisboa'])
print(capitals['Ankara'])
# Expected output:
# Spain
# Portugal
# The key doesn't existCounter là một lớp con của dictionary trong Python, được thiết kế riêng để đếm các đối tượng có thể băm. Đây là một dictionary mà các phần tử được lưu làm khóa, còn số lần xuất hiện được lưu làm giá trị.
Có nhiều cách để khởi tạo Counter:
Bằng một dãy phần tử.
Bằng các khóa và số đếm trong một dictionary.
Sử dụng ánh xạ name:value.
from collections import Counter
# a new counter from an iterable
c1 = Counter(['aaa','bbb','aaa','ccc','ccc','aaa'])
# a new counter from a mapping
c2 = Counter({'red': 4, 'blue': 2})
# a new counter from keyword args
c3 = Counter(cats=4, dogs=8)
# print results
print(c1)
print(c2)
print(c3)
# Expected output:
# Counter({'aaa': 3, 'ccc': 2, 'bbb': 1})
# Counter({'red': 4, 'blue': 2})
# Counter({'dogs': 8, 'cats': 4})Lớp Counter đi kèm một loạt phương thức tiện lợi để thực hiện các phép tính thường gặp.
print('keys of the counter: ', c3.keys())
print('values of the counter: ',c3.values())
print('list with all elements: ', list(c3.elements()))
print('number of elements: ', c3.total()) # number elements
print('2 most common occurrences: ', c3.most_common(2)) # 2 most common occurrences
# Expected output:
# keys of the counter: dict_keys(['cats', 'dogs'])
# values of the counter: dict_values([4, 8])
# list with all elements: ['cats', 'cats', 'cats', 'cats', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs', 'dogs']
# number of elements: 12
# 2 most common occurrences: [('dogs', 8), ('cats', 4)]Scikit-learn, còn gọi là sklearn, là một thư viện máy học Python mã nguồn mở, mạnh mẽ. Nó được tạo ra để đơn giản hóa quá trình triển khai các mô hình máy học và thống kê trong Python.
Sklearn có nhiều phương pháp băm rất hữu ích cho các quy trình kỹ thuật đặc trưng.
Một trong những phương pháp phổ biến là CountVectorizer. Nó được dùng để biến đổi văn bản cho trước thành một vector dựa trên tần suất của mỗi từ xuất hiện trong toàn bộ văn bản. CountVectorizer đặc biệt hữu ích trong bối cảnh phân tích văn bản.
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
documents = ["Welcome to this new DataCamp Python course",
"Welcome to this new DataCamp R skill track",
"Welcome to this new DataCamp Data Analyst career track"]
# Create a Vectorizer Object
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(documents)
# print unique values
print('unique words: ', vectorizer.get_feature_names_out())
# print sparse matrix with word frequency
pd.DataFrame(X.toarray(), columns = vectorizer.get_feature_names_out())
# Expected output:
# unique words: ['analyst' 'career' 'course' 'data' 'datacamp' 'new' 'python' 'skill'
# 'this' 'to' 'track' 'welcome']
Có các phương pháp băm khác trong sklearn, bao gồm FeatureHasher và DictVectorizer. Nghiên cứu tình huống Lập ngân sách cho trường học với Máy học trong Python của chúng tôi là ví dụ hay để bạn học cách chúng hoạt động trong thực tế.
Chúc mừng bạn đã hoàn thành hướng dẫn về hashmap. Hy vọng giờ đây bạn hiểu rõ hơn về hashmap và dictionary trong Python. Nếu muốn tìm hiểu thêm về dictionary và cách dùng chúng trong các tình huống thực tế, chúng tôi khuyến nghị bạn đọc Hướng dẫn Python Dictionaries chuyên sâu và Hướng dẫn Python Dictionary Comprehension.
Cuối cùng, nếu bạn mới bắt đầu với Python và muốn học thêm, hãy tham gia khóa Giới thiệu Khoa học Dữ liệu với Python của DataCamp và xem Hướng dẫn Python cho Người mới bắt đầu.
Bắt đầu hành trình Python của bạn ngay hôm nay!
Tracks
Courses
Courses