
Corso
Support Vector Machines in R
4 h
11K
I modelli lineari sono semplici e intuitivi, ma falliscono non appena i tuoi dati non sono linearmente separabili.
E la maggior parte dei dati del mondo reale non lo è. Per quanto tu regoli i pesi, un confine decisionale rettilineo non si adatta bene: le classi si sovrappongono o formano pattern che nessuna linea può separare senza errori. Se sai che il modello è troppo semplice per il compito ma non vuoi passare subito a una rete neurale, c'è una buona via di mezzo.
Le Support Vector Machine offrono un “trucco”. Puoi proiettare i tuoi dati in uno spazio a dimensionalità superiore, e ciò che sembrava inseparabile spesso diventa separabile. Il kernel trick è una scorciatoia computazionale che consente ai modelli basati su kernel, come le SVM, di operare come se i dati fossero trasformati, senza effettuare esplicitamente la trasformazione.
In questo articolo scoprirai esattamente come funziona il kernel trick all'interno delle SVM, quali funzioni kernel conoscere e quando vale la pena usare i metodi kernel.
Ma cos'è esattamente una SVM? Leggi il nostro post sul blog su Support Vector Machines con Scikit-learn per scoprire tutto sull'algoritmo e come applicarlo.
Il kernel trick è un metodo per calcolare i prodotti interni in uno spazio delle feature a dimensionalità superiore senza mappare esplicitamente i dati in quello spazio.
Quindi, in realtà non stai trasformando i tuoi punti dati per poi farci sopra i conti. Stai calcolando quale sarebbe il risultato di quei conti se li facessi, usando una funzione kernel che lavora direttamente sugli input originali.
Tieni a mente che il kernel trick si applica solo ai modelli che si basano sui prodotti scalari tra punti dati. Non è una tecnica ML generica. Se un modello non usa internamente i prodotti scalari, il kernel trick non si applica. La maggior parte dei modelli non li usa.
SVM, processi gaussiani e kernel PCA sono un paio di buoni esempi in cui questo kernel trick funziona. Ma non lasciare che qualcuno ti dica che è qualcosa che “la maggior parte dei modelli di ML usa”.
I modelli lineari possono apprendere solo confini decisionali lineari. È il loro vincolo rigido, ed è ciò che li rende facili da capire e interpretare.
Ma la maggior parte dei dataset reali non è linearmente separabile. Non esiste una linea retta (o un iperpiano) che separi nettamente le classi. Con il kernel trick, però, se proietti quei dati in uno spazio a dimensionalità superiore, gli stessi dati possono diventare separabili.
Il modo più ovvio per affrontare la cosa è trasformare esplicitamente i dati creando nuove feature, mappando ogni punto nello spazio a dimensionalità superiore e addestrando da lì il tuo modello. Funziona, ma il costo cresce. Se stai mappando a uno spazio con migliaia di dimensioni, archiviare e calcolare su quei vettori trasformati diventa costoso.
Con il kernel trick, invece di calcolare la trasformazione completa φ(x) per ogni punto dati, calcoli K(x, x′) - una funzione kernel che ti dà direttamente lo stesso risultato del prodotto interno.
Una SVM trova il confine decisionale che massimizza il margine tra due classi.
Per trovare quel confine, la SVM risolve un problema di ottimizzazione. E nella sua forma duale, l'ottimizzazione dipende solo dai prodotti scalari tra punti dati, non dai punti dati in sé. L'obiettivo duale appare così:

Funzione obiettivo duale
Dove α_i sono i pesi appresi, y_i sono le etichette di classe e ⟨x_i, x_j⟩ è il prodotto scalare tra due punti dati. Alla SVM servono solo le similarità tra coppie di punti.
Se alla SVM servono solo prodotti scalari, non devi fornirle quelli calcolati dallo spazio originale. Sostituisci ⟨x_i, x_j⟩ con una funzione kernel K(x_i, x_j):

Formula con funzione kernel
La SVM funziona esattamente allo stesso modo. Semplicemente “pensa” di operare in uno spazio di feature più ricco.
Ed è proprio questo il senso del kernel trick.
L'approccio standard sarebbe definire una mappatura φ(x) che trasforma ogni punto dati in uno spazio a dimensionalità superiore, quindi calcolare lì i prodotti scalari:

La mappatura
Ma calcolare esplicitamente φ(x) può essere costoso, e in alcuni casi lo spazio mappato ha migliaia o persino dimensioni infinite.
Il kernel trick salta quel passaggio.
Invece di calcolare φ(x) e poi fare il prodotto scalare, calcoli direttamente K(x, x′) - una funzione kernel che soddisfa:

Calcolo con funzione kernel
Il risultato è identico, ma il costo è inferiore.
Pensa a K(x, x′) come a una funzione di similarità. Prende due punti dati nello spazio originale e restituisce un numero che riflette quanto sono simili - ma in un modo che corrisponde a confrontarli in uno spazio molto più ricco. Il modello si comporta come se i dati fossero stati trasformati. Semplicemente non lo sono mai stati.
Non tutte le funzioni kernel funzionano allo stesso modo. Ognuna definisce una diversa nozione di similarità tra i punti dati, il che significa che ciascuna produce un diverso tipo di confine decisionale. Te ne mostro un paio.

Kernel lineare
Il kernel lineare è semplicemente un prodotto scalare standard. Il modello resta nello spazio delle feature originale e apprende un confine lineare, il che lo rende equivalente a una SVM lineare standard.
Usa questo kernel quando i tuoi dati sono già linearmente separabili. È l'opzione più veloce e la più facile da interpretare.
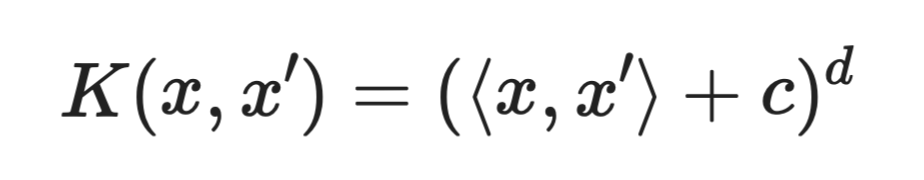
Kernel polinomiale
Dove c è una costante e d è il grado del polinomio.
Il kernel polinomiale cattura le interazioni tra feature. Un kernel di grado 2, ad esempio, considera tutte le combinazioni a coppie delle feature. Questo permette al modello di apprendere confini curvi senza che tu debba creare manualmente quei termini di interazione.
Gradi più alti significano confini più espressivi, ma anche maggior rischio di overfitting.

Kernel RBF
Il kernel RBF (Radial Basis Function) è il kernel più usato in pratica. Misura la similarità in base alla distanza. Due punti vicini ottengono un punteggio alto, due punti lontani un punteggio vicino a zero.
Ciò che lo rende interessante è che mappa implicitamente i dati in uno spazio a dimensioni infinite. Questo gli dà abbastanza flessibilità per comprendere confini complessi e non lineari che altri kernel non riescono a gestire.
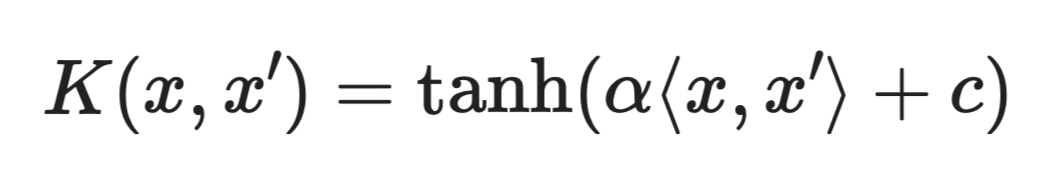
Kernel sigmoide
Il kernel sigmoide è meno usato rispetto a RBF o polinomiale e, a seconda delle scelte dei parametri, non soddisfa sempre le condizioni matematiche richieste per essere un kernel valido.
Compare occasionalmente nella letteratura più datata, ma in pratica l'RBF è quasi sempre un punto di partenza migliore.
Le SVM sono l'algoritmo più comune per il kernel trick, ma non sono l'unico.
Altri modelli usano la stessa idea:
In tutti questi casi, al modello servono solo prodotti scalari, quindi puoi sostituirli con una funzione kernel e ottenere un comportamento non lineare senza cambiare il resto della matematica.
Ma la SVM resta l'esempio più chiaro e il punto migliore da cui costruire intuizione.
Entrambi gli approcci risolvono il problema di feature non abbastanza espressive. Ma lo fanno in modo diverso.
Con il feature engineering, crei esplicitamente nuove feature da quelle esistenti. Decidi quali combinazioni contano, le calcoli, le aggiungi al dataset e addestri sul set di feature ampliato. Vedi esattamente cosa è entrato nel modello.
Il kernel trick opera implicitamente in uno spazio a dimensionalità superiore senza che tu definisca o memorizzi mai quelle feature extra. La trasformazione è descritta dalla funzione kernel.
Il compromesso si riduce a interpretabilità contro flessibilità.
Il feature engineering mantiene le cose trasparenti, perché sai cosa rappresenta ogni feature. Il kernel trick ti dà più capacità espressive, ma lo spazio delle feature implicito è spesso difficile da ispezionare o spiegare.
Se per il tuo caso d'uso l'interpretabilità è importante, il feature engineering è la scelta più sicura. Se devi comprendere pattern complessi e non ti serve spiegare ogni decisione del modello, il kernel trick ti porterà più velocemente al risultato.
Il più evidente è che consente ai modelli lineari di apprendere confini non lineari. Senza di esso, una SVM può separare le classi solo con un iperpiano rettilineo. Con esso, lo stesso modello può gestire confini decisionali curvi e complessi.
Evita anche il costo di calcoli espliciti ad alta dimensionalità. Ottieni la potenza espressiva di uno spazio delle feature più ricco senza memorizzare o calcolare quelle dimensioni extra. Per problemi in cui lo spazio implicito ha migliaia o dimensioni infinite, è questo a rendere l'approccio praticabile.
I metodi kernel tendono anche a funzionare bene su dataset di dimensioni medie. Quando non hai milioni di esempi ma i tuoi dati non sono linearmente separabili, una SVM con un buon kernel è spesso una scelta solida e affidabile.
Il problema più grande è la scalabilità. Addestrare una SVM kernel richiede di calcolare K(x_i, x_j) per ogni coppia di punti dati. È un'operazione O(n²) - e va peggio se consideri la memoria. Su dataset grandi, può diventare un collo di bottiglia serio.
La scelta del kernel non è banale. L'RBF è un buon default, ma non è sempre quello giusto. Scegliere il kernel sbagliato - o gli iperparametri sbagliati per un kernel - può portare a prestazioni peggiori di quelle di partenza.
L'interpretabilità è un altro problema. Con il feature engineering, sai cosa significa ogni feature. Con il kernel trick, lo spazio delle feature implicito non è chiaro. Il modello funziona, ma spiegare perché ha preso una decisione specifica è difficile.
E in molti domini, il deep learning ha semplicemente preso il sopravvento. Le reti neurali gestiscono dataset grandi, apprendono le proprie rappresentazioni delle feature e spesso superano i metodi kernel senza richiedere la selezione manuale del kernel. Per la classificazione di immagini, l'NLP o qualsiasi compito con enormi quantità di dati, i metodi kernel raramente sono la prima scelta oggi.
I metodi kernel non sono obsoleti nel 2026, ma sono diventati più specializzati di un tempo.
Dovresti scegliere un metodo kernel, come una SVM con kernel RBF, quando:
Sono una buona scelta per problemi con dati strutturati e tabellari in cui hai dati limitati e ti serve un modello che generalizzi bene senza troppo tuning. In questi casi, una SVM con kernel può ancora superare modelli più complessi.
Ma se il tuo dataset è grande, o ti servono predizioni spiegabili, i metodi kernel non sono la soluzione migliore.
Il modo migliore per vedere cosa fa davvero il kernel trick è osservare una SVM lineare fallire e poi risolvere il problema con un kernel.
Nell'esempio seguente, hai un dataset semplice con due cerchi concentrici, dove una classe forma un anello interno e l'altra un anello esterno. Non c'è alcuna linea retta che possa separarli. Una SVM lineare fallirà sempre
Con un kernel RBF, la stessa SVM traccerà un confine circolare che separa le classi. L'unica cosa che è cambiata è la funzione kernel.
Ecco l'esempio completo:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_circles
# Generate concentric circles dataset
np.random.seed(42)
X, y = make_circles(n_samples=300, noise=0.1, factor=0.4)
# Train both SVMs
svm_linear = SVC(kernel="linear", C=1)
svm_rbf = SVC(kernel="rbf", C=1, gamma="scale")
svm_linear.fit(X, y)
svm_rbf.fit(X, y)
print(f"Linear SVM accuracy: {svm_linear.score(X, y):.0%}")
print(f"RBF SVM accuracy: {svm_rbf.score(X, y):.0%}")
Accuratezza SVM lineare vs RBF
La SVM lineare traccia un confine rettilineo attraverso il centro dei dati. Divide il piano in due metà, cosa che non corrisponde affatto alla struttura reale del problema. Il kernel RBF, al contrario, produce un confine circolare che segue la forma dei dati.

SVM lineare vs RBF visualizzate
In conclusione, il modello non ha appreso una struttura più complessa: ha semplicemente operato in uno spazio in cui la struttura era più semplice da trovare.
Ci sono un paio di fraintendimenti sul kernel trick che compaiono abbastanza spesso, quindi li affronto qui.
"Il kernel trick funziona per tutti i modelli." Non è così. Il kernel trick si applica solo ai modelli che, nell'ottimizzazione, si basano sui prodotti scalari tra punti dati. La maggior parte dei modelli - alberi decisionali, random forest, reti neurali, regressione lineare - non usa i prodotti scalari in quel modo, quindi il kernel trick non si applica.
"Trasforma letteralmente i dati." Non esplicitamente. I tuoi punti dati originali restano esattamente come sono. La funzione kernel calcola quale sarebbe il prodotto scalare in uno spazio a dimensionalità superiore, ma in pratica non avviene alcuna trasformazione. I dati non vengono mai espansi o memorizzati in modo diverso.
"Migliora sempre le prestazioni." Dipende. Su problemi non lineari con dataset piccoli o medi, un buon kernel può fare la differenza. Su dataset grandi, il costo computazionale spesso supera il beneficio. E se i tuoi dati sono già linearmente separabili, aggiungere un kernel introduce solo complessità.
Il kernel trick non è l'idea più discussa nell'ML in questo momento. Il deep learning è in cima alle classifiche per la maggior parte dei benchmark, e i metodi kernel compaiono di rado.
Ma resta un concetto fondamentale che vale la pena capire.
Le SVM e il kernel trick sono stati centrali nel ML classico perché funzionano bene con dati strutturati e tabellari con pochi campioni, e la matematica alla loro base è pulita e ben compresa. Se vuoi capire come funziona l'apprendimento basato sulla similarità, o perché i prodotti scalari contano nell'ottimizzazione, il kernel trick è uno degli esempi più chiari da studiare.
Ha anche ancora usi reali. Dataset piccoli, domini specializzati come la bioinformatica o la classificazione di testo con feature create a mano, e problemi in cui serve un modello che generalizzi bene senza molti dati: sono ambiti in cui i metodi kernel sono ancora rilevanti.
Il kernel è stato sostituito nei domini in cui scala e volume di dati grezzi contano di più. Nel contesto giusto, resta uno strumento valido.
Il kernel trick risolve un problema specifico: come ottenere un comportamento non lineare da un modello che sa lavorare solo con prodotti scalari. La risposta è sostituire quei prodotti scalari con una funzione kernel che calcoli lo stesso risultato in uno spazio delle feature più ricco - senza andarci davvero.
È più utile capirlo nel contesto delle SVM, dove la formulazione duale rende la sostituzione chiara ed esplicita. Una volta che ci prendi la mano, l'ampia famiglia dei metodi kernel inizierà a sembrarti molto più sensata.
Oggi il deep learning riceve la maggior parte dell'attenzione, e per problemi su larga scala è giusto così. Ma il kernel trick rappresenta un modo di pensare diverso - basato su geometria e similarità. Vale la pena capirlo, ma a meno che tu non lavori in un ambito specializzato, difficilmente lo userai spesso in pratica.
Ma perché esattamente il deep learning ha preso il sopravvento? Iscriviti al nostro percorso Deep Learning in Python per vedere come le reti neurali ti permettono di costruire modelli complessi su larga scala.
Impara con DataCamp
Corso
Corso
Corso
blog
Abid Ali Awan
10 min
blog
Tim Lu
12 min
blog
Abid Ali Awan
15 min

