Course
Support Vector Machines in R
4 ч
11K
Линейные модели просты и понятны, но они перестают работать, как только данные нельзя разделить линейно.
А большинство реальных данных именно такие. Как ни настраивай веса, прямая граница решения плохо подходит: классы либо пересекаются, либо образуют такие узоры, которые никакая прямая не разделит без ошибок. Если вы понимаете, что модель слишком проста для задачи, но не хотите сразу переходить к нейросети, есть разумный компромисс.
У опорных векторных машин (SVM) есть один «трюк». Можно спроецировать данные в пространство большей размерности — и то, что казалось неразделимым, часто становится разделимым. Трюк с ядром — это вычислительная хитрость, позволяющая ядерным моделям, таким как SVM, работать так, как будто данные трансформированы, не выполняя явного преобразования.
В этой статье вы разберётесь, как именно работает трюк с ядром в SVM, какие ядерные функции стоит знать и когда ядерные методы действительно уместны.
Но что такое SVM на самом деле? Прочтите наш пост о Support Vector Machines в Scikit-learn, чтобы узнать всё об алгоритме и его применении.
Трюк с ядром — это способ вычислять скалярные произведения в пространстве признаков большей размерности без явного отображения данных в это пространство.
То есть вы не трансформируете точки данных и не проводите над ними вычисления. Вы находите, чему равнялся бы результат этих вычислений, используя ядерную функцию, которая работает напрямую с исходными входами.
Важно помнить, что трюк с ядром применим только к моделям, которые опираются на скалярные произведения между точками данных. Это не универсный приём для ML. Если модель внутренне не использует скалярные произведения, трюк с ядром к ней не применим. Большинство моделей его не используют.
SVM, гауссовские процессы и ядерный PCA — хорошие примеры, где этот трюк работает. Но не дайте себя убедить, что это «использует большинство моделей ML».
Линейные модели могут учить только линейные границы решений. Это их жёсткое ограничение, и именно оно делает их простыми для понимания и интерпретации.
Но большинство реальных наборов данных нельзя разделить линейно. Не существует прямой (или гиперплоскости), которая чисто разделит классы. С трюком с ядром, если спроецировать данные в пространство большей размерности, те же данные могут стать разделимыми.
Очевидный путь — явно преобразовать данные, создавая новые признаки, отображая каждую точку в пространство большей размерности и уже там обучать модель. Это работает, но стоимость растёт. Если вы переходите в пространство с тысячами размерностей, хранение и вычисления с такими векторами становятся дорогими.
С трюком с ядром вместо вычисления полного преобразования φ(x) для каждой точки вы вычисляете K(x, x′) — ядерную функцию, которая напрямую даёт тот же результат скалярного произведения.
SVM находит границу решения, максимизирующую зазор между двумя классами.
Чтобы найти такую границу, SVM решает задачу оптимизации. В двойственной форме оптимизация зависит только от скалярных произведений между точками данных, а не от самих точек. Двойственная целевая функция выглядит так:

Двойственная целевая функция
Где α_i — обученные веса, y_i — метки классов, а ⟨x_i, x_j⟩ — скалярное произведение двух точек данных. SVM нужны лишь попарные сходства между точками.
Если SVM нужны только скалярные произведения, не обязательно вычислять их в исходном пространстве. Вы заменяете ⟨x_i, x_j⟩ на ядерную функцию K(x_i, x_j):

Формула с ядерной функцией
SVM работает в точности так же. Он просто «считает», что действует в более богатом пространстве признаков.
И в этом весь смысл трюка с ядром.
Стандартный подход — определить отображение φ(x), которое переносит каждую точку в пространство большей размерности, а затем вычислять там скалярные произведения:

Отображение
Но явное вычисление φ(x) может быть дорогостоящим, а иногда отображённое пространство имеет тысячи или даже бесконечное число размерностей.
Трюк с ядром пропускает этот шаг.
Вместо вычисления φ(x) и последующего скалярного произведения вы напрямую считаете K(x, x′) — ядерную функцию, для которой выполняется:

Вычисление ядерной функции
Результат идентичен, но стоимость ниже.
Думайте о K(x, x′) как о функции сходства. Она берёт две точки в исходном пространстве и возвращает число, отражающее их схожесть — но так, как если бы вы сравнивали их в намного более богатом пространстве. Модель ведёт себя так, будто данные были преобразованы. На самом деле — нет.
Разные ядра работают по-разному. Каждое по-своему определяет схожесть точек данных, а значит, задаёт иной тип границы решения. Покажу несколько вариантов.

Линейное ядро
Линейное ядро — это просто стандартное скалярное произведение. Модель остаётся в исходном пространстве признаков и учит линейную границу, что эквивалентно стандартному линейному SVM.
Используйте это ядро, когда данные уже линейно разделимы. Это самый быстрый и самый интерпретируемый вариант.
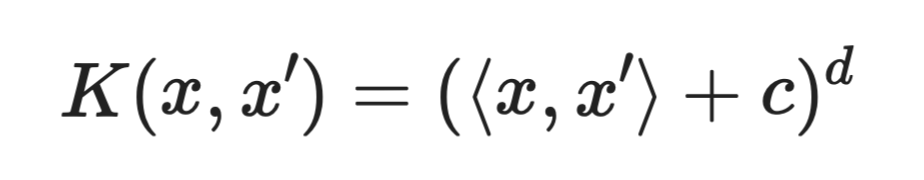
Полиномиальное ядро
Где c — константа, а d — степень полинома.
Полиномиальное ядро захватывает взаимодействия между признаками. Например, ядро степени 2 учитывает все попарные комбинации признаков. Это позволяет модели изучать изогнутые границы без ручного создания соответствующих признаков-взаимодействий.
Более высокие степени дают более выразительные границы, но повышают риск переобучения.

Ядро RBF
RBF (Radial Basis Function) — самое распространённое на практике ядро. Оно измеряет схожесть на основе расстояния: близкие точки получают высокий балл, далёкие — близкий к нулю.
Интересно то, что оно неявно отображает данные в бесконечномерное пространство. Это даёт ему достаточно гибкости для понимания сложных, нелинейных границ, с которыми другие ядра могут не справиться.
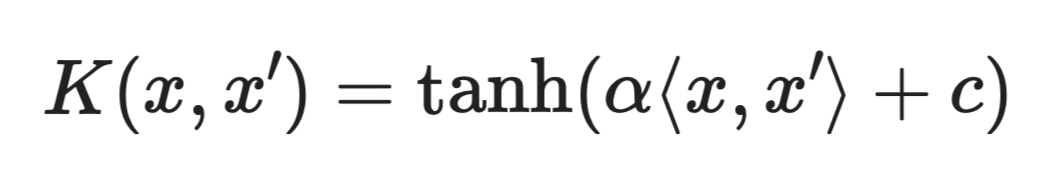
Сигмоидное ядро
Сигмоидное ядро используется реже, чем RBF или полиномиальные, и в зависимости от параметров не всегда удовлетворяет математическим условиям корректной ядерной функции.
Иногда встречается в старой литературе, но на практике RBF почти всегда лучшее отправное решение.
SVM — самый распространённый алгоритм для трюка с ядром, но не единственный.
Ещё несколько моделей используют ту же идею:
Во всех этих случаях модели нужны только скалярные произведения, поэтому можно подставить ядерную функцию и получить нелинейное поведение без изменения остальной математики.
Но SVM остаётся самым наглядным примером и лучшей точкой для формирования интуиции.
Оба подхода решают проблему недостаточной выразительности признаков, но делают это по-разному.
При построении признаков вы явно создаёте новые признаки из существующих. Вы решаете, какие комбинации важны, вычисляете их, добавляете в набор данных и обучаетесь на расширенном множестве признаков. Вы точно знаете, что попало в модель.
Трюк с ядром неявно работает в пространстве большей размерности, не требуя от вас определения или хранения дополнительных признаков. Преобразование описывается ядерной функцией.
Компромисс — между интерпретируемостью и гибкостью.
Построение признаков сохраняет прозрачность: вы знаете, что означает каждый признак. Трюк с ядром даёт большую выразительность, но неявное пространство признаков часто сложно изучать и объяснять.
Если интерпретируемость важна для вашего кейса, построение признаков — более безопасный выбор. Если нужно уловить сложные закономерности и не требуется объяснять каждое решение модели, трюк с ядром позволит достичь цели быстрее.
Главное преимущество — он позволяет линейным моделям учить нелинейные границы. Без него SVM может разделять классы только прямой гиперплоскостью. С ним та же модель справляется с изогнутыми, сложными границами решений.
Он также избегает затрат на явные вычисления в высоких размерностях. Вы получаете выразительность более богатого пространства признаков без хранения и вычислений по дополнительным измерениям. Для задач, где неявное пространство признаков имеет тысячи или бесконечное число размерностей, именно это делает подход вообще осуществимым.
Ядерные методы также нередко хорошо работают на наборах данных среднего размера. Когда у вас не миллионы примеров, но данные не разделяются линейно, SVM с хорошим ядром часто — надёжный и сильный выбор.
Главная проблема — масштаб. Обучение ядерного SVM требует вычислять K(x_i, x_j) для каждой пары точек данных. Это операция O(n²) — и с учётом памяти всё ещё хуже. На больших наборах данных это становится серьёзным узким местом.
Выбор ядра тоже нетривиален. RBF — хороший вариант по умолчанию, но не всегда подходящий. Неправильный выбор ядра или его гиперпараметров может привести к результатам хуже исходных.
Интерпретируемость — ещё один вопрос. При построении признаков вы знаете, что означает каждый признак. При трюке с ядром неявное пространство признаков неочевидно. Модель работает, но объяснить, почему она приняла конкретное решение, трудно.
И во многих областях глубокое обучение просто взяло верх. Нейросети справляются с большими наборами данных, сами учат представления признаков и часто превосходят ядерные методы без выбора ядра вручную. Для классификации изображений, обработки текста и любых задач с огромными объёмами данных ядерные методы редко бывают первым выбором сегодня.
В 2026 году ядерные методы не устарели, но стали более нишевыми, чем раньше.
К ядерному методу, например SVM с RBF-ядром, стоит обратиться, когда:
Они хорошо подходят для задач со структурированными, табличными данными, когда данных немного и нужна модель, которая хорошо обобщается без долгой настройки. В таких случаях ядерный SVM может превзойти более сложные модели.
Но если ваш набор данных велик или вам нужны объяснимые предсказания, ядерные методы — не лучший выбор.
Лучший способ увидеть, что делает трюк с ядром, — посмотреть, как линейный SVM проваливается, а затем исправить это ядром.
В примере ниже простой набор данных из двух концентрических окружностей: один класс образует внутреннее кольцо, другой — внешнее. Не существует прямой, которая их разделит. Линейный SVM неизбежно провалится.
С RBF-ядром тот же SVM проведёт круглую границу, разделяющую классы. Единственное, что изменилось, — ядерная функция.
Вот полный пример:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_circles
# Generate concentric circles dataset
np.random.seed(42)
X, y = make_circles(n_samples=300, noise=0.1, factor=0.4)
# Train both SVMs
svm_linear = SVC(kernel="linear", C=1)
svm_rbf = SVC(kernel="rbf", C=1, gamma="scale")
svm_linear.fit(X, y)
svm_rbf.fit(X, y)
print(f"Linear SVM accuracy: {svm_linear.score(X, y):.0%}")
print(f"RBF SVM accuracy: {svm_rbf.score(X, y):.0%}")
Точность линейного и RBF SVM
Линейный SVM рисует прямую границу посреди данных. Он делит плоскость пополам, что вовсе не отражает реальную структуру задачи. Напротив, RBF-ядро даёт круговую границу, повторяющую форму данных.

Визуализация: линейный SVM vs. RBF SVM
В итоге модель не выучила более сложную структуру — она просто «работала» в пространстве, где эту структуру проще найти.
Есть несколько заблуждений о трюке с ядром, которые часто встречаются, — разберём их здесь.
«Трюк с ядром работает для всех моделей». Нет. Он применим только к моделям, в оптимизации которых используются скалярные произведения между точками данных. Большинство моделей — деревья решений, случайные леса, нейросети, линейная регрессия — не используют скалярные произведения таким образом, значит, трюк к ним не применим.
«Он буквально преобразует данные». Неявно — нет. Ваши исходные точки остаются как есть. Ядерная функция вычисляет, чему равнялось бы скалярное произведение в пространстве большей размерности, но на практике никакого преобразования не происходит. Данные нигде не расширяются и не хранятся иначе.
«Он всегда улучшает качество». Зависит от задачи. На нелинейных проблемах с малыми и средними наборами данных хорошее ядро может помочь. На больших — вычислительные издержки часто перевешивают пользу. А если данные уже линейно разделимы, добавление ядра лишь усложняет модель.
Сейчас о трюке с ядром говорят не так много. В большинстве бенчмарков лидирует глубокое обучение, и ядерные методы почти не упоминаются.
Но это по-прежнему базовая концепция, которую стоит понимать.
SVM и трюк с ядром были центральными в классическом ML, потому что хорошо работают на структурированных табличных данных с ограниченным числом примеров, а математика за ними чистая и понятная. Если вы хотите понять, как работает обучение на сходстве или почему важны скалярные произведения в оптимизации, трюк с ядром — один из самых наглядных примеров для изучения.
У него остаются и практические применения. Небольшие наборы данных, специализированные области вроде биоинформатики или классификации текста с ручными признаками, а также задачи, где нужна хорошо обобщающаяся модель при малом объёме данных, — это те случаи, где ядерные методы по-прежнему актуальны.
Ядра вытеснены в областях, где важны масштаб и объём сырьевых данных. В нужном контексте это всё ещё хороший инструмент.
Трюк с ядром решает конкретную задачу: как получить нелинейное поведение от модели, которая умеет работать только со скалярными произведениями. Ответ — заменить эти скалярные произведения ядерной функцией, которая вычисляет тот же результат в более богатом пространстве признаков — без фактического перехода туда.
Лучше всего понимать это в контексте SVM, где двойственная формулировка делает подстановку чистой и явной. Освоив это, вы гораздо легче разберётесь с более широкой семьёй ядерных методов.
Сегодня главное внимание уделяется глубокому обучению, и для задач большого масштаба это оправдано. Но трюк с ядром представляет иной тип мышления — основанный на геометрии и сходстве. Его стоит понимать, хотя если вы не работаете в специализированной области, на практике вы будете пользоваться им редко.
Но почему именно глубокое обучение заняло лидирующие позиции? Запишитесь на наш трек по Deep Learning на Python, чтобы увидеть, как нейросети позволяют строить сложные модели в масштабе.
Учитесь с DataCamp
Course
Course
Course