Courses
Rで学ぶSupport Vector Machines
4時間
11K
線形モデルはシンプルで直感的ですが、データが線形分離できないと途端にうまくいきません。
そして現実世界のデータの多くは線形分離できません。どれだけ重みを調整しても、直線的な判別境界はうまく当てはまりません—クラスが重なり合うか、どんな直線でも誤りなしには分けられないパターンを形成します。モデルが仕事に対して単純すぎると分かっていても、いきなりニューラルネットに飛びつきたくない場合、ちょうどよい中間解があります。
サポートベクターマシン(SVM)は1つの「妙手」を提供します。データを高次元空間に射影すると、分離不可能に見えたものがしばしば分離可能になります。カーネルトリックは、SVMのようなカーネルベースのモデルが、実際には変換を明示的に行わずとも、あたかもデータが変換されたかのように動作できるようにする計算上の近道です。
この記事では、SVMの内部でカーネルトリックがどのように機能するのか、知っておくべきカーネル関数、そしてカーネル法を選ぶべきタイミングを具体的に解説します。
そもそもSVMとは?アルゴリズムの概要と使い方は、当社ブログのScikit-learnで学ぶサポートベクターマシンをご覧ください。
カーネルトリックは、高次元の特徴空間での内積を、データを明示的にそこへ写像せずに計算する方法です。
つまり、実際にデータ点を変換してから計算するわけではありません。元の入力に対して直接働くカーネル関数を使い、その計算の結果がどうなるかを求めます。
覚えておくべきなのは、カーネルトリックはドット積に依存するモデルにしか適用できないという点です。汎用的な機械学習テクニックではありません。内部でドット積を使わないモデルには適用できません。ほとんどのモデルは使いません。
SVM、ガウス過程、カーネルPCAは、このカーネルトリックが効く代表例です。ただし、これを「ほとんどの機械学習モデルが使う」と言うのは誤りです。
線形モデルは線形の判別境界しか学習できません。これは厳格な制約であり、理解しやすく解釈しやすい理由でもあります。
しかし、多くの実データは線形分離できません。クラスをきれいに分割する直線(または超平面)は存在しません。そこでカーネルトリックを使い、データを高次元空間に射影すると、同じデータが分離可能になることがあります。
明白なアプローチは、新しい特徴を作って各点を高次元空間に写像し、そこからモデルを学習することです。これは機能しますが、コストが増大します。何千次元もの空間に写像する場合、その変換後ベクトルの保存と計算は高価になります。
カーネルトリックでは、各データ点について完全な変換φ(x)を計算する代わりに、K(x, x′)—同じ内積結果を直接返すカーネル関数—を計算します。
SVMは、2つのクラス間のマージンを最大化する判別境界を見つけます。
その境界を見つけるために、SVMは最適化問題を解きます。双対形式では、この最適化はデータ点そのものではなく、データ点間のドット積のみに依存します。双対目的関数は次のようになります:

双対目的関数
ここで、α_iは学習される重み、y_iはクラスラベル、⟨x_i, x_j⟩は2つのデータ点間のドット積です。SVMに必要なのはデータ点間の類似度(ペアごとの近さ)だけです。
SVMに必要なのがドット積だけなら、元の空間で計算したドット積を与える必要はありません。⟨x_i, x_j⟩の代わりに、カーネル関数K(x_i, x_j)を差し替えます:

カーネル関数を用いた式
SVMの処理はまったく同じです。ただ、より豊かな特徴空間で動いていると思い込んでいるだけです。
それがカーネルトリックの核心です。
標準的なやり方は、各データ点を高次元空間に変換する写像φ(x)を定義し、その空間でドット積を計算することです:

写像
しかし、φ(x)を明示的に計算するのは高コストになり得ます。場合によっては、写像先の空間が何千次元、あるいは無限次元になることもあります。
カーネルトリックはその手順を省略します。
φ(x)を計算してからドット積を取る代わりに、次を満たすカーネル関数K(x, x′)を直接計算します:

カーネル関数の計算
結果は同一ですが、計算コストは低くなります。
K(x, x′)は類似度関数だと考えてください。元の空間の2つのデータ点を受け取り、それらがどれほど似ているかを数値で返します—ただし、それははるかに豊かな空間で比較したことに対応しています。モデルはデータが変換されたかのように振る舞いますが、実際には変換されていません。
すべてのカーネル関数が同じように働くわけではありません。各カーネルはデータ点間の類似度の概念を異なる形で定義し、それにより判別境界の形も変わります。いくつか紹介します。

線形カーネル
線形カーネルは単なる標準的なドット積です。モデルは元の特徴空間に留まり、線形境界を学習します。つまり標準的な線形SVMと同等です。
データがすでに線形分離できる場合に使ってください。最も高速で、解釈もしやすい選択です。
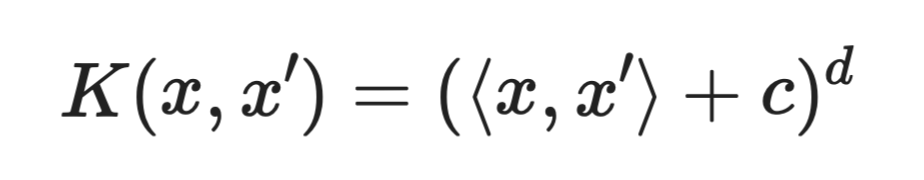
多項式カーネル
ここでcは定数、dは多項式の次数です。
多項式カーネルは特徴同士の相互作用を捉えます。例えば次数2なら、すべての特徴のペアの組み合わせを考慮します。これにより、相互作用項を手作業で作らなくても、曲線的な境界を学習できます。
次数が高いほど表現力は増しますが、過学習のリスクも高まります。

RBFカーネル
RBF(Radial Basis Function)カーネルは、実務で最も広く使われています。距離に基づいて類似度を測ります。近い2点は高いスコア、遠い2点は0に近いスコアになります。
興味深いのは、データを暗黙的に無限次元の空間に写像する点です。これにより、他のカーネルでは扱えない複雑で非線形な境界を捉える柔軟性が得られます。
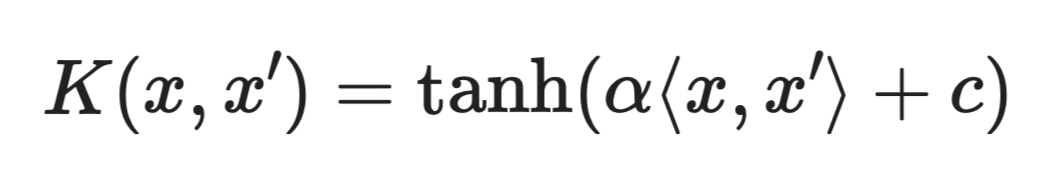
シグモイドカーネル
シグモイドカーネルはRBFや多項式に比べて使用頻度が低く、パラメータ設定によっては有効なカーネル関数に必要な数学的条件を満たさないことがあります。
古い文献で見かけることはありますが、実務ではRBFを起点にするのがほとんど常に賢明です。
SVMはカーネルトリックの最も一般的なアルゴリズムですが、それだけではありません。
同じアイデアを用いるモデルとして、例えば次があります:
いずれも必要なのはドット積だけなので、カーネル関数に置き換えることで、他の数式を変えずに非線形な振る舞いを得られます。
とはいえ、直感を養うにはSVMが最も分かりやすい例です。
どちらのアプローチも、特徴量が十分に表現力を持たない問題を解決しますが、やり方が異なります。
特徴量エンジニアリングでは、既存の特徴から新しい特徴を明示的に作ります。どの組み合わせが重要かを決めて計算し、データセットに追加して、拡張された特徴集合で学習します。モデルに何が入ったかを正確に把握できます。
カーネルトリックは、追加の特徴を定義・保存することなく、高次元空間で暗黙的に動作します。変換はカーネル関数で記述されます。
トレードオフは、解釈可能性と柔軟性のバランスにあります。
特徴量エンジニアリングは各特徴の意味が分かるため、透明性を保てます。カーネルトリックはより高い表現力を与えますが、暗黙の特徴空間は多くの場合、観察・説明が困難です。
解釈可能性が重要なら、特徴量エンジニアリングが無難です。複雑なパターンを理解する必要があり、モデルの個々の判断を逐一説明する必要がないなら、カーネルトリックの方が早く到達できます。
最も明白な利点は、線形モデルに非線形境界を学習させられることです。これがなければ、SVMは直線的な超平面でしかクラス分離できません。カーネルを用いれば、同じモデルで曲線的・複雑な判別境界を扱えます。
また、明示的な高次元計算のコストを回避できます。追加次元を保存・計算することなく、より豊かな特徴空間の表現力を得られます。暗黙の特徴空間が何千・無限次元に及ぶ問題では、このアプローチを可能にする鍵です。
さらに、カーネル法は中規模データセットでうまく機能する傾向があります。サンプルが数百万件ではないが、データが線形分離できないような場合、適切なカーネルを用いたSVMは堅実で信頼できる選択肢です。
最大の問題はスケールです。カーネルSVMの学習には、訓練データの全ての組に対してK(x_i, x_j)を計算する必要があります。これはO(n²)の計算で、メモリまで考えるとさらに悪化します。大規模データでは深刻なボトルネックになり得ます。
カーネル選択も簡単ではありません。RBFは良いデフォルトですが、常に正解とは限りません。不適切なカーネル—あるいはカーネルのハイパーパラメータ—を選ぶと、出発点より性能が悪くなることもあります。
解釈性も課題です。特徴量エンジニアリングなら各特徴の意味が分かりますが、カーネルトリックでは暗黙の特徴空間が不明瞭です。モデルは動作しますが、特定の判断をなぜ下したのかを説明するのは難しいのです。
さらに、多くの分野ではディープラーニングが主流になりました。ニューラルネットは大規模データを扱い、自ら特徴表現を学習し、手作業のカーネル選択なしにカーネル法をしばしば上回ります。画像分類、NLP、巨大データを扱うタスクでは、カーネル法が第一選択になることは稀です。
2026年の今でもカーネル法は廃れたわけではありませんが、かつてより専門的な場面に絞られてきています。
RBFカーネルを用いたSVMのようなカーネル法を選ぶべきなのは、次のような場合です:
限られたデータで汎化性能が必要な、構造化された表形式データの課題に適しています。そうしたケースでは、カーネルSVMがより複雑なモデルを上回ることもあります。
一方で、データセットが大きい、あるいは説明可能な予測が必要なら、カーネル法は最善ではありません。
カーネルトリックの効果を見る最良の方法は、線形SVMが失敗する様子を見て、カーネルで修正することです。
次の例では、2つの同心円からなるシンプルなデータセットを使います。片方のクラスが内側のリング、もう片方が外側のリングを形成します。これを直線で分離することはできません。線形SVMは必ず失敗します。
RBFカーネルを使うと、同じSVMがクラスを分ける円形の境界を描きます。変わったのはカーネル関数だけです。
完全な例は次のとおりです:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_circles
# Generate concentric circles dataset
np.random.seed(42)
X, y = make_circles(n_samples=300, noise=0.1, factor=0.4)
# Train both SVMs
svm_linear = SVC(kernel="linear", C=1)
svm_rbf = SVC(kernel="rbf", C=1, gamma="scale")
svm_linear.fit(X, y)
svm_rbf.fit(X, y)
print(f"Linear SVM accuracy: {svm_linear.score(X, y):.0%}")
print(f"RBF SVM accuracy: {svm_rbf.score(X, y):.0%}")
線形SVMとRBF SVMの精度比較
線形SVMはデータの中央をまっすぐ横切る境界を引きます。平面を二分しますが、問題の実際の構造にはまったく合いません。対照的にRBFカーネルは、データの形状に沿った円形の境界を生み出します。

線形SVMとRBF SVMの可視化比較
結論として、モデルがより複雑な構造を学んだわけではありません。構造を見つけやすい空間で動作しただけなのです。
よく見かける誤解がいくつかあるので、ここで触れておきます。
「カーネルトリックはすべてのモデルで使える」—使えません。カーネルトリックは、最適化でデータ点間のドット積に依存するモデルにしか適用できません。多くのモデル、例えば決定木、ランダムフォレスト、ニューラルネット、線形回帰などは、そのような形でドット積を使わないため、適用できません。
「データを文字通り変換する」—明示的にはしません。元のデータ点はそのままです。カーネル関数は、高次元空間でのドット積がどうなるかを計算しますが、実際に変換は行われません。データが拡張・保存されることもありません。
「常に性能が向上する」—状況によります。非線形な問題で小〜中規模のデータなら、良いカーネルが効くことがあります。大規模データでは、計算コストが利点を上回ることが多いです。既に線形分離できるデータなら、カーネルを足すのは単に複雑化するだけです。
いま機械学習で最も話題なのはカーネルトリックではありません。多くのベンチマークでディープラーニングが上位を占め、カーネル法が登場する場面は少なくなりました。
それでも、理解する価値のある基礎概念です。
SVMとカーネルトリックは、限られたサンプルの構造化データで強く、背後の数学が明快で理解しやすいことから、古典的機械学習の中心でした。類似度に基づく学習がどのように機能するか、最適化でドット積がなぜ重要かを知りたいなら、カーネルトリックは最も分かりやすい教材の一つです。
また、今でも実用の場があります。小規模データ、バイオインフォマティクスのような専門領域、手作り特徴を用いたテキスト分類、少ないデータでよく汎化するモデルが必要な課題—こうした領域ではカーネル法は依然 relevant(有用)です。
スケールや生データ量がものを言う分野では置き換えられましたが、適切な文脈では今でも良い道具です。
カーネルトリックは、「ドット積しか扱えないモデルから非線形の振る舞いを得る」ための特定の解法です。答えは、ドット積を、より豊かな特徴空間で同じ結果を返すカーネル関数に置き換えること—しかも実際にはそこへ行かないことです。
最も理解しやすいのはSVMの文脈です。双対形式では、この置き換えが明確かつ明示的になります。そこに慣れれば、より広いカーネル法のファミリーもずっと理解しやすくなります。
今日、注目を集めるのはディープラーニングであり、大規模問題にはそれが妥当です。しかし、カーネルトリックは幾何と類似度に基づく別種の思考法を体現しています。理解する価値はありますが、専門領域にいない限り、実務で頻繁に使うことはないでしょう。
では、なぜディープラーニングが主流になったのでしょうか?当社のDeep Learning in Python トラックに登録し、ニューラルネットがどのように大規模で複雑なモデル構築を可能にするかをご覧ください。
DataCampで学ぶ
Courses
Courses
Courses