course
Support Vector Machines in R
4 oră
11K
Modelele liniare sunt simple și intuitive, dar eșuează de îndată ce datele dumneavoastră nu sunt liniar separabile.
Iar majoritatea datelor din lumea reală nu sunt. Indiferent cum reglați ponderile, o frontieră de decizie dreaptă nu se potrivește bine – clasele fie se suprapun, fie formează tipare pe care nicio linie nu le poate separa fără erori. Dacă știți că modelul este prea simplu pentru sarcină, dar nu doriți să treceți direct la o rețea neuronală, există o variantă de mijloc bună.
Support Vector Machines oferă un „truc”. Puteți proiecta datele într-un spațiu cu dimensiune mai mare, iar ceea ce părea inseparabil devine adesea separabil. Trucul cu kernel este o scurtătură computațională care permite modelelor pe bază de kernel, precum SVM-urile, să funcționeze ca și cum datele ar fi fost transformate, fără a realiza vreodată explicit transformarea.
În acest articol, veți învăța exact cum funcționează trucul cu kernel în SVM-uri, care funcții kernel merită cunoscute și când merită folosite metodele pe bază de kernel.
Dar ce este exact SVM? Citiți articolul nostru despre Support Vector Machines cu Scikit-learn pentru a afla totul despre algoritm și cum se aplică.
Trucul cu kernel este o metodă de a calcula produse scalare într-un spațiu de caracteristici cu dimensiune mai mare fără a mapa explicit datele acolo.
Așadar, nu transformați de fapt punctele de date și apoi efectuați calcule pe ele. Calculați ceea ce rezultatul acelor calcule ar fi, folosind o funcție kernel care operează direct pe intrările originale.
Rețineți că trucul cu kernel se aplică doar modelelor care se bazează pe produse scalare între punctele de date. Nu este o tehnică ML universală. Dacă un model nu folosește intern produse scalare, trucul cu kernel nu se aplică. Majoritatea modelelor nu îl folosesc.
SVM-urile, procesele gaussiene și kernel PCA sunt câteva exemple bune unde acest truc funcționează. Dar să nu vă spună nimeni că este ceva „folosit de majoritatea modelelor ML”.
Modelele liniare pot învăța doar frontiere de decizie liniare. Aceasta este constrângerea lor dură și ceea ce le face ușor de înțeles și interpretat.
Dar majoritatea seturilor de date reale nu sunt liniar separabile. Nu există o linie dreaptă (sau un hiperplan) care să separe curat clasele. Însă, cu trucul cu kernel, dacă proiectați datele într-un spațiu cu dimensiune mai mare, aceleași date pot deveni separabile.
Abordarea evidentă este să transformați explicit datele creând caracteristici noi, mapând fiecare punct în spațiul cu dimensiune mai mare și antrenând modelul de acolo. Funcționează, dar costul crește. Dacă mapați într-un spațiu cu mii de dimensiuni, stocarea și calculul pe acei vectori transformați devin costisitoare.
Cu trucul cu kernel, în loc să calculați transformarea completă φ(x) pentru fiecare punct de date, calculați K(x, x′) – o funcție kernel care vă oferă direct același rezultat al produsului scalar.
Un SVM găsește frontiera de decizie care maximizează marja dintre două clase.
Pentru a găsi acea frontieră, SVM rezolvă o problemă de optimizare. Iar în forma sa duală, optimizarea depinde doar de produse scalare între punctele de date, nu de punctele în sine. Obiectivul dual arată astfel:

Funcția obiectiv duală
Unde α_i sunt ponderile învățate, y_i sunt etichetele claselor, iar ⟨x_i, x_j⟩ este produsul scalar între două puncte de date. SVM are nevoie doar de similaritățile perechi dintre punctele de date.
Dacă SVM are nevoie doar de produse scalare, nu trebuie să îi oferiți produse scalare calculate în spațiul original. Înlocuiți ⟨x_i, x_j⟩ cu o funcție kernel K(x_i, x_j):

Formulă cu funcție kernel
SVM rulează exact la fel. Doar că „crede” că operează într-un spațiu de caracteristici mai bogat.
Și despre asta este trucul cu kernel.
Abordarea standard ar fi să definiți o mapare φ(x) care transformă fiecare punct de date într-un spațiu cu dimensiune mai mare, apoi să calculați produsele scalare acolo:

Maparea
Dar calcularea explicită a lui φ(x) poate fi costisitoare, iar în unele cazuri spațiul mapat are mii sau chiar dimensiuni infinite.
Trucul cu kernel sare peste acel pas.
În loc să calculați φ(x) și apoi să faceți produsul scalar, calculați direct K(x, x′) – o funcție kernel care satisface:

Calculul funcției kernel
Rezultatul este identic, dar costul este mai mic.
Gândiți-vă la K(x, x′) ca la o funcție de similaritate. Ia două puncte de date în spațiul original și întoarce un număr care reflectă cât de similare sunt – dar într-un mod care corespunde comparării lor într-un spațiu mult mai bogat. Modelul se comportă ca și cum datele ar fi fost transformate. Doar că nu au fost.
Nu toate funcțiile kernel funcționează la fel. Fiecare definește o altă noțiune de similaritate între punctele de date, ceea ce înseamnă că fiecare are un alt tip de frontieră de decizie. Iată câteva.

Kernel liniar
Kernelul liniar este doar produsul scalar standard. Modelul rămâne în spațiul de caracteristici original și învață o frontieră liniară, ceea ce îl face echivalent cu un SVM liniar standard.
Folosiți acest kernel când datele sunt deja liniar separabile. Este cea mai rapidă opțiune și cea mai ușor de interpretat.
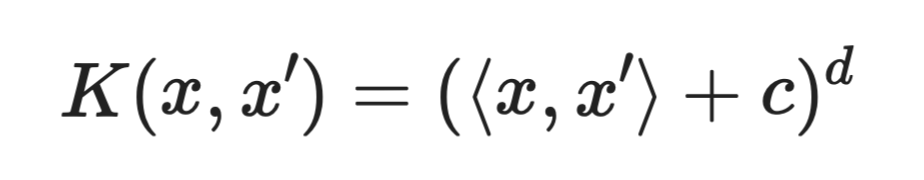
Kernel polinomial
Unde c este o constantă, iar d este gradul polinomului.
Kernelul polinomial surprinde interacțiunile dintre caracteristici. Un kernel de gradul 2, de exemplu, ia în considerare toate combinațiile perechi de caracteristici. Acest lucru permite modelului să învețe frontiere curbe fără a crea manual acei termeni de interacțiune.
Gradele mai mari înseamnă frontiere mai expresive, dar și un risc mai mare de supraînvățare.

Kernel RBF
Kernelul RBF (Radial Basis Function) este cel mai folosit în practică. Măsoară similaritatea pe baza distanței. Două puncte apropiate primesc un scor mare, două puncte îndepărtate primesc un scor aproape de zero.
Ce îl face interesant este că mapează implicit datele într-un spațiu cu dimensiune infinită. Asta îi oferă suficientă flexibilitate pentru a înțelege frontiere complexe, neliniare, pe care alte kerneluri nu le pot gestiona.
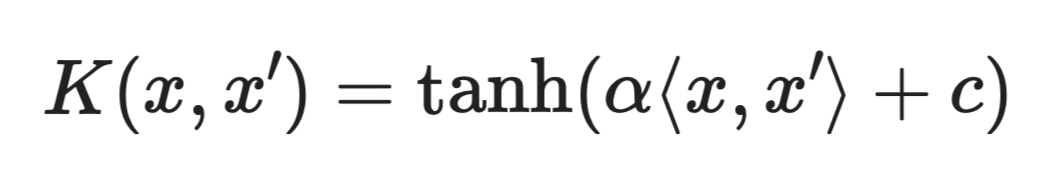
Kernel sigmoid
Kernelul sigmoid este folosit mai rar decât kernelurile RBF sau polinomiale și nu respectă întotdeauna condițiile matematice necesare pentru o funcție kernel validă, în funcție de alegerea parametrilor.
Apare ocazional în literatura mai veche, dar în practică, RBF este aproape întotdeauna un punct de plecare mai bun.
SVM este cel mai frecvent algoritm pentru trucul cu kernel, dar nu este singurul.
Câteva alte modele folosesc aceeași idee:
În toate aceste cazuri, modelul are nevoie doar de produse scalare, așa că puteți înlocui cu o funcție kernel și obține comportament neliniar fără a schimba restul matematicii.
Dar SVM rămâne exemplul cel mai clar și cel mai bun loc pentru a vă forma intuiția.
Ambele abordări rezolvă problema lipsei de expresivitate a caracteristicilor. Dar o fac în moduri diferite.
Cu ingineria de caracteristici, creați explicit caracteristici noi din cele existente. Decideți ce combinații contează, le calculați, le adăugați la setul de date și antrenați pe setul de caracteristici extins. Vedeți exact ce a intrat în model.
Trucul cu kernel operează implicit într-un spațiu cu dimensiune mai mare fără a defini sau stoca vreodată acele caracteristici suplimentare. Transformarea este descrisă de funcția kernel.
Compromisul ține de interpretabilitate versus flexibilitate.
Ingineria de caracteristici păstrează transparența, deoarece știți ce reprezintă fiecare caracteristică. Trucul cu kernel vă oferă capacități mai expresive, dar spațiul de caracteristici implicit este adesea greu de inspectat sau explicat.
Dacă interpretabilitatea contează pentru cazul dumneavoastră de utilizare, ingineria de caracteristici este alegerea mai sigură. Dacă aveți nevoie să înțelegeți tipare complexe și nu trebuie să explicați fiecare decizie a modelului, trucul cu kernel vă va duce mai repede acolo.
Cel mai evident este că permite modelelor liniare să învețe frontiere neliniare. Fără el, un SVM poate separa clasele doar cu un hiperplan drept. Cu el, același model poate gestiona frontiere de decizie curbe și complexe.
De asemenea, evită costul calculelor explicite în dimensiuni mari. Obțineți puterea expresivă a unui spațiu de caracteristici mai bogat fără a stoca sau calcula acele dimensiuni suplimentare. Pentru probleme în care spațiul implicit are mii sau dimensiuni infinite, acesta este motivul pentru care abordarea este posibilă.
Metodele pe bază de kernel tind, de asemenea, să funcționeze bine pe seturi de date de dimensiune medie. Când nu aveți milioane de exemple, dar datele nu sunt liniar separabile, un SVM cu un kernel bun este adesea o alegere solidă și fiabilă.
Cea mai mare problemă este scalarea. Antrenarea unui SVM cu kernel necesită calcularea K(x_i, x_j) pentru fiecare pereche de puncte de date. Este o operație O(n²) – și devine și mai rea când considerați memoria. Pe seturi de date mari, acest lucru poate deveni un blocaj major.
Alegerea kernelului nu este nici ea trivială. RBF este un implicit bun, dar nu întotdeauna cel potrivit. Alegerea kernelului greșit – sau a hiperparametrilor nepotriviți pentru un kernel – poate duce la performanțe mai slabe decât la început.
Interpretabilitatea este o altă problemă. Cu ingineria de caracteristici, știți ce înseamnă fiecare caracteristică. Cu trucul cu kernel, spațiul implicit al caracteristicilor nu este clar. Modelul funcționează, dar este greu de explicat de ce a luat o anumită decizie.
Și în multe domenii, deep learning pur și simplu a preluat conducerea. Rețelele neuronale gestionează seturi de date mari, își învață propriile reprezentări ale caracteristicilor și adesea depășesc metodele pe bază de kernel fără a necesita selecția manuală a kernelului. Pentru clasificarea imaginilor, NLP sau orice sarcină cu cantități masive de date, metodele pe bază de kernel sunt rareori prima alegere în prezent.
Metodele pe bază de kernel nu sunt depășite în 2026, dar au devenit mai specializate decât erau.
Ar trebui să alegeți o metodă pe bază de kernel, cum ar fi un SVM cu kernel RBF, atunci când:
Sunt o alegere bună pentru probleme cu date structurate, tabelare, în care aveți date limitate și aveți nevoie de un model care generalizează bine fără multă ajustare. În aceste cazuri, un SVM cu kernel poate încă depăși modele mai complexe.
Însă, dacă setul de date este mare sau aveți nevoie de predicții pe care le puteți explica, metodele pe bază de kernel nu sunt cea mai bună soluție.
Cel mai bun mod de a vedea ce face efectiv trucul cu kernel este să priviți un SVM liniar cum eșuează și apoi să îl reparați cu un kernel.
În exemplul de mai jos, aveți un set de date simplu cu două cercuri concentrice, unde o clasă formează un inel interior, iar cealaltă un inel exterior. Nu există nicio linie dreaptă care să le poată separa. Un SVM liniar va eșua de fiecare dată
Cu un kernel RBF, același SVM va trasa o frontieră circulară care separă clasele. Singurul lucru care s-a schimbat este funcția kernel.
Iată exemplul complet:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.svm import SVC
from sklearn.datasets import make_circles
# Generate concentric circles dataset
np.random.seed(42)
X, y = make_circles(n_samples=300, noise=0.1, factor=0.4)
# Train both SVMs
svm_linear = SVC(kernel="linear", C=1)
svm_rbf = SVC(kernel="rbf", C=1, gamma="scale")
svm_linear.fit(X, y)
svm_rbf.fit(X, y)
print(f"Linear SVM accuracy: {svm_linear.score(X, y):.0%}")
print(f"RBF SVM accuracy: {svm_rbf.score(X, y):.0%}")
Acuratețe SVM liniar versus RBF
SVM-ul liniar trasează o frontieră dreaptă prin mijlocul datelor. Împarte planul în două jumătăți, ceea ce nu corespunde deloc structurii reale a problemei. Kernelul RBF, în schimb, produce o frontieră circulară care urmează forma datelor.

Vizualizare SVM liniar versus RBF
În concluzie, modelul nu a învățat o structură mai complexă – a operat doar într-un spațiu în care structura a fost mai ușor de găsit.
Există câteva idei greșite despre trucul cu kernel care apar destul de des, așa că le abordez aici.
„Trucul cu kernel funcționează pentru toate modelele.” Nu. Trucul cu kernel se aplică doar modelelor care se bazează pe produse scalare între puncte de date în optimizarea lor. Majoritatea modelelor – arbori de decizie, păduri aleatorii, rețele neuronale, regresie liniară – nu folosesc produse scalare în acest fel, deci trucul nu li se aplică.
„Transformă literalmente datele.” Nu explicit. Punctele de date originale rămân exact așa cum sunt. Funcția kernel calculează ceea ce produsul scalar ar fi într-un spațiu cu dimensiune mai mare, dar nicio transformare nu are loc în practică. Datele nu sunt niciodată extinse sau stocate diferit.
„Îmbunătățește întotdeauna performanța.” Depinde. Pentru probleme neliniare cu seturi de date mici spre medii, un kernel bun poate face diferența. Pe seturi mari, costul computațional depășește adesea beneficiul. Iar dacă datele sunt deja liniar separabile, adăugarea unui kernel doar crește complexitatea.
Trucul cu kernel nu este cea mai discutată idee în ML în prezent. Deep learning este în top pentru majoritatea benchmark-urilor, iar metodele pe bază de kernel apar rar.
Dar rămâne un concept fundamental care merită înțeles.
SVM-urile și trucul cu kernel au fost centrale în ML clasic pentru că funcționează bine pe date structurate, tabelare, cu puține eșantioane, iar matematica din spatele lor este clară și bine înțeleasă. Dacă doriți să înțelegeți cum funcționează învățarea bazată pe similaritate sau de ce contează produsele scalare în optimizare, trucul cu kernel este unul dintre cele mai clare exemple de studiat.
Are, de asemenea, utilizări reale. Seturi de date mici, domenii specializate precum bioinformatica sau clasificarea textelor cu caracteristici construite manual și probleme în care aveți nevoie de un model care generalizează bine fără multe date – acestea sunt zone în care metodele pe bază de kernel sunt încă relevante.
Kernelul a fost înlocuit în domeniile în care contează cel mai mult scara și volumul brut de date. În contextul potrivit, rămâne un instrument bun.
Trucul cu kernel rezolvă o problemă specifică: cum să obțineți un comportament neliniar dintr-un model care știe doar să lucreze cu produse scalare. Răspunsul este să înlocuiți acele produse scalare cu o funcție kernel care calculează același rezultat într-un spațiu de caracteristici mai bogat – fără a ajunge de fapt acolo.
Este cel mai util de înțeles în contextul SVM-urilor, unde formularea duală face substituția clară și explicită. Odată ce vă simțiți confortabil cu asta, familia mai largă de metode pe bază de kernel va începe să aibă mult mai mult sens.
Astăzi, deep learning primește cea mai mare parte a atenției și, pentru probleme la scară mare, pe bună dreptate. Dar trucul cu kernel reprezintă un alt mod de gândire – bazat pe geometrie și similaritate. Merită înțeles, însă, dacă nu lucrați într-un domeniu specializat, probabil îl veți folosi rar în practică.
Dar de ce anume a preluat deep learning conducerea? Înscrieți-vă la parcursul Deep Learning in Python pentru a vedea cum vă permit rețelele neuronale să construiți modele complexe la scară.
Învățați cu DataCamp
course
course
course