tracks
주니어 데이터 엔지니어 in SQL
30
전통적 데이터 웨어하우스는 온프레미스에 배포되며, 일반적으로 높은 초기 비용, 이를 관리할 숙련된 팀, 그리고 전통적 데이터 센터 리소스 확장의 경직성으로 인한 수요 증가에 맞춘 철저한 계획이 필요합니다.
반면 클라우드 데이터 웨어하우스는 클라우드 서비스 제공업체가 호스팅하고 관리합니다. 예로는 Google BigQuery, Amazon Redshift, Snowflake가 있습니다.
일반적으로 클라우드 데이터 웨어하우스는 전통적 데이터 웨어하우스에 비해 다음과 같은 장점을 갖습니다.
행 지향 데이터베이스 예시:

컬럼 지향 데이터베이스 예시:

행 지향 데이터베이스는 전체 행 조회, 레코드 삽입, 업데이트에 유리합니다. 하지만 분석 워크로드에는 약합니다.
예를 들어 50개 컬럼이 있는 테이블에서 3개 컬럼만 조회하더라도, 행 지향 데이터베이스는 각 행에 대해 여전히 50개 컬럼을 모두 읽습니다. 반면 컬럼 지향 데이터베이스는 필요한 3개 컬럼만 읽기 때문에 제품 수요 예측이나 애드혹 리포팅 같은 분석에 훨씬 빠릅니다.
행 지향 데이터베이스는 보통 온라인 트랜잭션 처리(OLTP)에, 컬럼 지향 데이터베이스는 온라인 분석 처리(OLAP)에 적합합니다.
비교 요약:
|
행 지향 데이터베이스 |
컬럼 지향 데이터베이스 |
||||||
|
저장 방식 |
행 기준 |
컬럼 기준 |
|||||
|
데이터 조회 |
완전한 레코드 |
해당 컬럼 |
|||||
|
일반적 적용 |
OLTP |
OLAP |
|||||
|
빠른 작업 |
삽입, 업데이트, 조회 |
리포팅 목적의 쿼리 |
|||||
|
데이터 적재 |
보통 레코드 단위 |
보통 배치 단위 |
|||||
|
대표 옵션 |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery는 컴퓨트 엔진과 스토리지를 분리해 각각을 독립적으로 확장합니다. 그 결과 테라바이트급 데이터는 수초, 페타바이트급 데이터는 수분 내에 쿼리할 수 있습니다.
BigQuery가 쿼리를 실행하면, 쿼리 엔진이 작업을 병렬로 분산하고 스토리지의 관련 테이블을 스캔한 뒤 결과를 병합해 최종 데이터 세트를 반환합니다.

출시 이후 Google은 BigQuery를 전통적 데이터 웨어하우스를 넘어 확장하는 여러 기능을 추가했습니다.
BigQuery 샌드박스를 사용하면 청구 계정이나 신용카드 없이 BigQuery를 체험할 수 있습니다. 이 섹션에서는 샌드박스를 사용해 BigQuery에 접근하고 첫 프로젝트를 설정하는 방법을 살펴봅니다.
BigQuery는 Google Cloud Console을 통해 접근할 수 있습니다. Google 계정으로 로그인(또는 생성)해야 합니다. 로그인하면 환영 화면이 표시됩니다.
왼쪽 메뉴에서 BigQuery를 찾을 수 있습니다. 클릭하면 아래 화면으로 이동합니다.

BigQuery 샌드박스를 사용하려면 먼저 ‘Select Project’를 클릭해 프로젝트를 생성합니다.

이어서 ‘New Project’를 클릭합니다.

프로젝트 이름을 입력해야 합니다. 이 가이드에서는 datacamp-guide-project를 사용합니다.

이제 BigQuery 페이지에 샌드박스 사용 알림이 표시되며, BigQuery 샌드박스가 성공적으로 활성화되었음을 보여줍니다.

이제 BigQuery 샌드박스가 활성화되었으므로, 새 프로젝트에서 데이터를 로드하고 쿼리할 수 있으며 Google 공개 데이터 세트도 쿼리할 수 있습니다.
테이블을 만들기 전에 새 프로젝트에서 데이터세트를 생성해야 합니다. 데이터세트는 테이블과 뷰 모음을 구성하고 접근을 제어하는 최상위 컨테이너입니다. 데이터세트를 생성하려면 프로젝트의 ‘Actions’ 아이콘을 클릭합니다.

이 가이드에서는 ‘Dataset ID’에 ‘main’을 입력합니다.

SQL을 사용해 테이블을 만들 수 있습니다. BigQuery는 ANSI 호환인 GoogleSQL을 사용합니다.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);또는 BigQuery 콘솔 인터페이스를 사용할 수도 있습니다.

참고: 샌드박스 환경에서는 데이터를 삽입할 수 없습니다. 데이터 삽입을 시도하려면 무료 체험을 활성화해야 합니다. 다음 섹션에서는 Google Cloud에서 제공하는 공개 데이터 세트를 쿼리하는 데 집중합니다.
공개 데이터 세트를 쿼리하려면 아래 단계를 따르세요.
1. Explorer 옆의 ‘Add’를 클릭합니다.

2. 그런 다음 데이터 세트를 선택합니다.

3. ‘Google Trends’를 검색해 선택하고, ‘View dataset’ 버튼을 클릭합니다.

4. bigquery-public-data에 긴 데이터 세트 목록이 표시됩니다. bigquery-public-data에 별표를 추가해 탐색기에서 “고정”되도록 하세요.

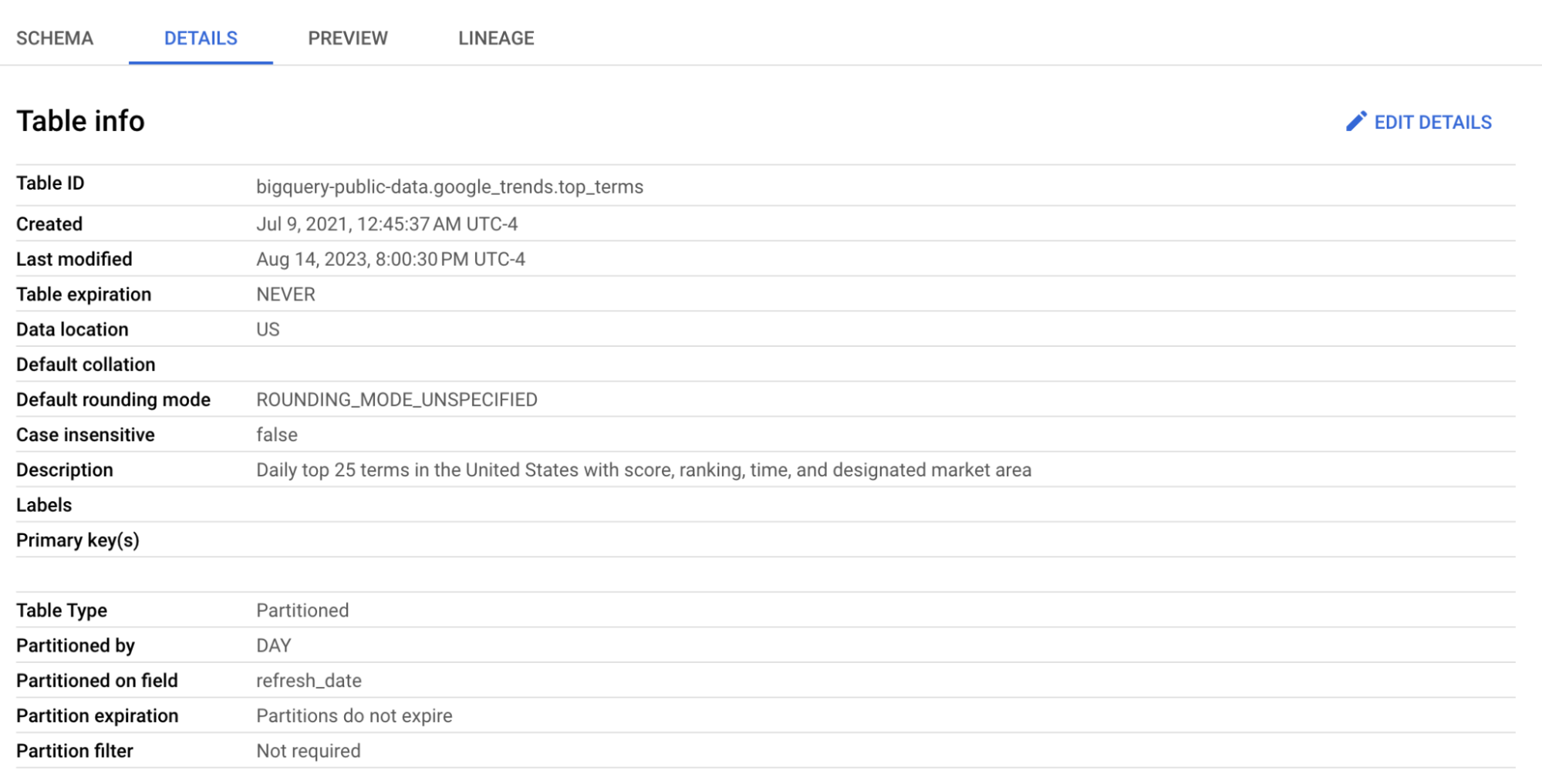
top_terms 테이블을 사용하겠습니다.

top_terms 테이블을 클릭해 열고, Details와 Preview를 확인해 top_terms 데이터에 대해 더 알아보세요.

아래 예시처럼, 최근 2주 동안 1위에 오른 용어를 가져오도록 데이터 세트를 쿼리할 수 있습니다.
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
term결과(변동 가능):

BigQuery 가격은 크게 컴퓨트(쿼리 처리)와 스토리지 두 가지 구성 요소로 이뤄집니다.
| 구성 요소 | 무료 등급 | 유료 요금 |
|---|---|---|
| 온디맨드 쿼리 | 월 1 TiB | TiB당 $6.25 |
| 스토리지(활성) | 10 GiB | GiB/월당 $0.02 |
| 스토리지(장기) | 10 GiB | GiB/월당 $0.01 |
| 스트리밍 삽입 | N/A | 200 MB당 $0.05 |
워크로드가 예측 가능한 팀의 경우, BigQuery는 용량 예약(BigQuery Editions)을 통한 정액 요금제도 제공합니다. 최신 요금은 공식 가격 페이지를 확인하세요.
BigQuery는 클라우드 데이터 웨어하우징으로 진입하기 가장 쉬운 방법 중 하나입니다. 샌드박스는 위험 없이 실험할 수 있는 환경을 제공하며, 월 1 TiB의 무료 쿼리 한도로 비용 없이 공개 데이터 세트를 탐색할 수 있습니다. 더 필요할 때는 Google Cloud의 무료 체험을 통해 $300 크레딧을 받을 수 있습니다.
여기서 배운 내용을 확장하고 싶다면 DataCamp의 Introduction to BigQuery 코스를 권장합니다. 쿼리 최적화와 대규모 데이터 세트 작업을 다룹니다. 더 넓은 관점에서 데이터 엔지니어링을 살펴보고 싶다면 Data Engineer in Python 트랙에서 수집부터 웨어하우징까지 전체 파이프라인을 학습하세요.
또한 BigQuery vs Redshift, BigQuery vs Snowflake 비교 글을 통해 대안을 함께 살펴보거나, BigQuery 면접 질문 가이드로 인터뷰를 준비할 수 있습니다.
지금 바로 데이터 엔지니어링을 시작하세요!
tracks
courses
courses