track
Inginer de date asociat în SQL
30 oră
Un depozit de date tradițional este implementat on-premise, necesitând de obicei costuri inițiale mari, o echipă calificată pentru a-l gestiona și o planificare adecvată pentru a face față cererii în creștere, din cauza naturii rigide a scalării resurselor în centrele de date tradiționale.
Prin contrast, un depozit de date în cloud este gestionat și găzduit de un furnizor de servicii cloud. Exemple includ Google BigQuery, Amazon Redshift și Snowflake.
De obicei, un depozit de date în cloud are mai multe avantaje față de cele tradiționale:
Exemplu de bază de date orientată pe rânduri:

Exemplu de bază de date orientată pe coloane:

Bazele de date orientate pe rânduri funcționează bine pentru căutări ale rândurilor complete, inserarea de înregistrări și actualizări. Însă au dificultăți cu sarcinile analitice.
De exemplu, dacă interoghezi trei coloane dintr-un tabel cu 50 de coloane, o bază de date orientată pe rânduri tot va citi toate cele 50 de coloane pentru fiecare rând. O bază de date orientată pe coloane citește doar cele trei coloane de care ai nevoie, ceea ce este mult mai rapid pentru analize precum prognoza produselor sau raportarea ad-hoc.
Bazele de date orientate pe rânduri sunt de obicei potrivite pentru procesarea tranzacțională online (OLTP), iar bazele orientate pe coloane pentru procesarea analitică online (OLAP).
Rezumatul comparației:
|
Bază de date orientată pe rânduri |
Bază de date orientată pe coloane |
||||||
|
Stocare |
Pe rând |
Pe coloană |
|||||
|
Regăsire date |
Înregistrări complete |
Coloane relevante |
|||||
|
Aplicație tipică |
OLTP |
OLAP |
|||||
|
Operații rapide |
Inserare, actualizări, căutări |
Interogări pentru raportare |
|||||
|
Încărcare date |
De obicei, o înregistrare pe rând |
De obicei, în lot |
|||||
|
Opțiuni populare |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery separă motorul de procesare de stocare, astfel încât fiecare să poată scala independent. Rezultatul: poți interoga terabytes de date în câteva secunde și petabytes în câteva minute.
Când BigQuery rulează o interogare, motorul de interogare distribuie munca în paralel, scanează tabelele relevante din stocare, îmbină rezultatele și returnează setul final de date.

De la lansarea BigQuery, Google a adăugat mai multe funcții care îl extind dincolo de un depozit de date tradițional:
Sandbox-ul BigQuery îți permite să încerci BigQuery fără să furnizezi un card de credit sau să creezi un cont de facturare. În această secțiune, îți arăt cum să accesezi BigQuery și să-ți configurezi primul proiect folosind sandbox-ul.
Poți accesa BigQuery prin Consola Google Cloud. Va trebui să te autentifici cu un cont Google (sau să creezi unul). După autentificare, ar trebui să apară un ecran de bun venit:
Găsești BigQuery în bara de meniu din stânga. Dacă dai clic pe el, vei ajunge pe ecranul de mai jos:

Pentru a folosi sandbox-ul BigQuery, creează mai întâi un proiect dând clic pe „Select Project”.

Apoi dă clic pe „New Project”:

Va trebui să oferi un nume de proiect; pentru acest ghid folosim datacamp-guide-project

Pe pagina BigQuery este acum afișată o notificare despre sandbox, indicând că ai activat cu succes sandbox-ul BigQuery.

Acum că ai activat sandbox-ul BigQuery, poți folosi noul tău proiect pentru a încărca date și a interoga, precum și pentru a interoga seturile de date publice Google.
Înainte de a crea un tabel, trebuie să creezi un set de date în noul tău proiect. Un set de date este un container de nivel superior folosit pentru a organiza și controla accesul la un set de tabele și vizualizări. Pentru a crea un set de date, dă clic pe pictograma „Actions” a proiectului:

În scopul acestui ghid, vom completa „Dataset ID” cu „main”.

Poți crea un tabel folosind SQL. BigQuery folosește GoogleSQL, care este conform cu ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Poți folosi și interfața BigQuery Console:

Notă: Nu este posibil să inserezi date în mediul sandbox. Dacă vrei să încerci inserarea de date, trebuie să activezi perioada de probă gratuită. Secțiunile următoare se concentrează pe interogarea seturilor de date publice oferite ca parte a Google Cloud.
Pentru a interoga un set de date public, urmează pașii de mai jos:
1. Dă clic pe „Add” lângă Explorer.

2. Apoi alege un set de date.

3. Caută „Google Trends” și alege Google Trends, apoi dă clic pe butonul „View dataset”.

4. bigquery-public-data va apărea cu o listă lungă de seturi de date. Pune o steluță la bigquery-public-data ca să rămână „lipit” în explorer

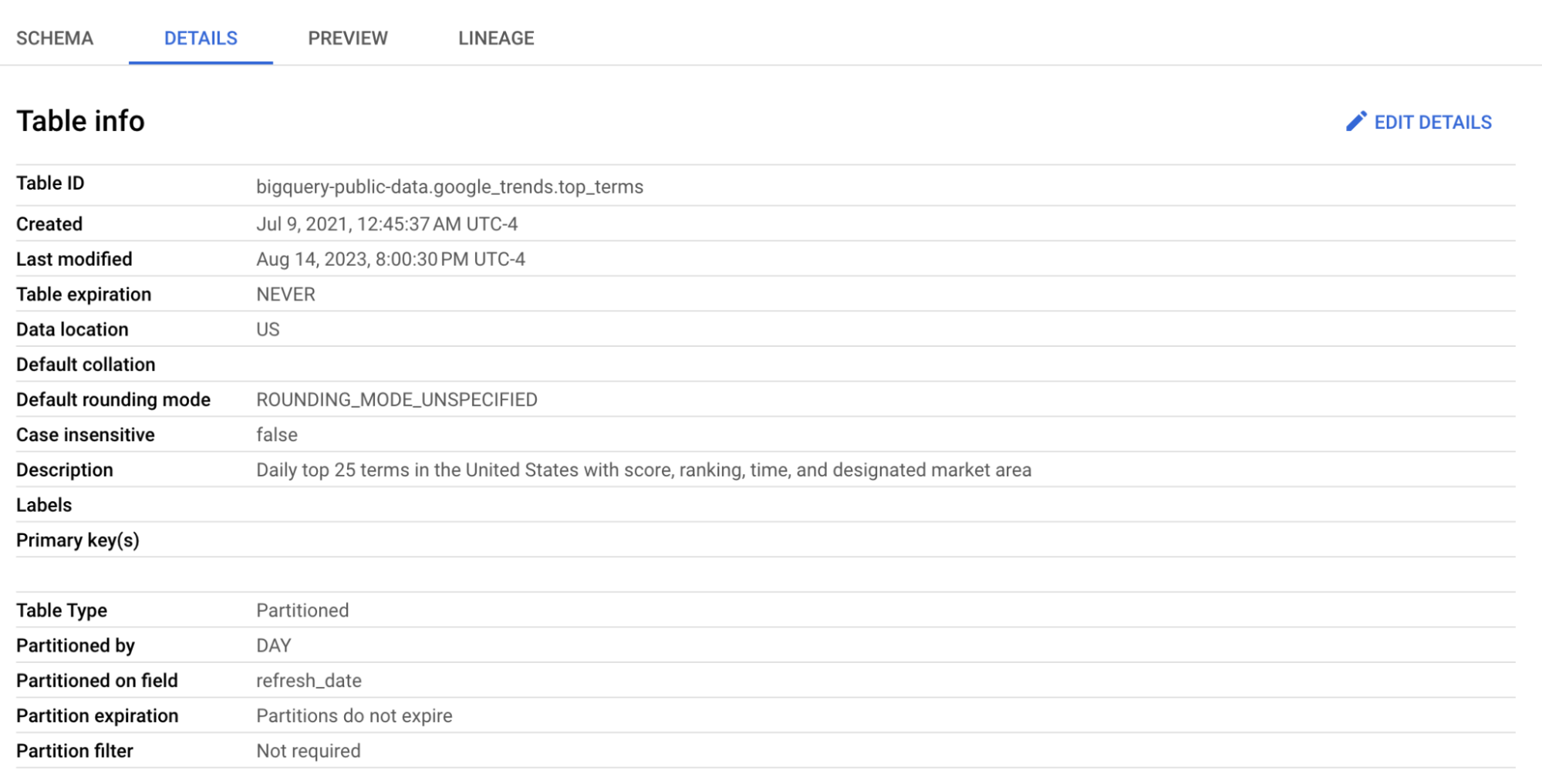
Vom folosi tabelul top_terms:

Dă clic pe tabelul top_terms pentru a-l deschide și inspectează filele Details și Preview ca să afli mai multe despre datele din top_terms.

Poți interoga setul de date; exemplu mai jos pentru a prelua termenii care s-au clasat pe prima poziție în ultimele două săptămâni:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termRezultate (vor varia):

Structura de prețuri BigQuery are două componente principale: procesare (executarea interogărilor) și stocare.
| Componentă | Plan gratuit | Preț plătit |
|---|---|---|
| Interogări la cerere | 1 TiB pe lună | $6.25 per TiB |
| Stocare (activă) | 10 GiB | $0.02 per GiB/lună |
| Stocare (pe termen lung) | 10 GiB | $0.01 per GiB/lună |
| Inserări în flux | N/A | $0.05 per 200 MB |
Pentru echipe cu sarcini de lucru previzibile, BigQuery oferă și prețuri forfetare prin rezervări de capacitate (BigQuery Editions). Verifică pagina oficială de prețuri pentru tarifele actuale.
BigQuery este unul dintre cele mai accesibile puncte de intrare în depozitarea de date în cloud. Sandbox-ul îți oferă un mediu fără riscuri pentru a experimenta, iar 1 TiB de interogări gratuite pe lună înseamnă că poți explora seturi de date publice fără să cheltui nimic. Când ai nevoie de mai mult, perioada de probă gratuită a Google Cloud îți oferă credite de 300 $.
Dacă vrei să construiești pe baza a ceea ce ai învățat aici, îți recomand cursul Introducere în BigQuery pe DataCamp, care acoperă optimizarea interogărilor și lucrul cu seturi de date mai mari. Pentru o perspectivă mai amplă asupra ingineriei de date, traseul Data Engineer in Python acoperă întregul pipeline, de la ingestie la depozitare.
Poți explora și cum se compară BigQuery cu alternativele în materialele noastre BigQuery vs Redshift și BigQuery vs Snowflake, sau te poți pregăti pentru interviuri cu ghidul nostru de întrebări pentru interviuri BigQuery.
Începe azi cu ingineria datelor!
track
course
course