Track
Младший инженер данных в SQL
30 ч
Традиционное хранилище данных разворачивается на собственных серверах, как правило, требует высоких первоначальных затрат, квалифицированной команды для его обслуживания и тщательного планирования для удовлетворения растущего спроса из‑за жёстких ограничений масштабирования ресурсов в традиционных дата‑центрах.
Облачное хранилище данных, напротив, управляется и размещается у облачного провайдера. Примеры: Google BigQuery, Amazon Redshift и Snowflake.
Обычно облачное хранилище данных имеет ряд преимуществ перед традиционными:
Пример построчной базы данных:

Пример колоночной базы данных:

Построчные базы данных хорошо подходят для выборки полных строк, вставки записей и обновлений. Но им сложно справляться с аналитическими нагрузками.
Например, если вы запрашиваете три столбца из таблицы с 50 столбцами, построчная база данных всё равно считывает все 50 столбцов для каждой строки. Колоночная база данных читает только нужные три столбца, что значительно быстрее для аналитики, такой как прогнозирование ассортимента или разовые отчёты.
Построчные базы данных обычно лучше подходят для обработки онлайн‑транзакций (OLTP), а колоночные — для онлайн‑аналитической обработки (OLAP).
Итоги сравнения:
|
Построчная база данных |
Колоночная база данных |
||||||
|
Хранение |
По строкам |
По столбцам |
|||||
|
Извлечение данных |
Полные записи |
Соответствующие столбцы |
|||||
|
Типичное применение |
OLTP |
OLAP |
|||||
|
Быстрые операции |
Вставка, обновления, выборка по ключу |
Запросы для отчётности |
|||||
|
Загрузка данных |
Обычно по одной записи |
Обычно пакетно |
|||||
|
Популярные варианты |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery разделяет вычислительный движок и хранилище, поэтому каждое может масштабироваться независимо. Результат: вы можете выполнять запросы к терабайтам данных за секунды и к петабайтам — за минуты.
Когда BigQuery выполняет запрос, движок распределяет работу параллельно, сканирует соответствующие таблицы в хранилище, объединяет результаты и возвращает итоговый набор данных.

С момента запуска BigQuery Google добавил ряд функций, которые выводят его за рамки традиционного хранилища данных:
Песочница BigQuery позволяет попробовать BigQuery без указания банковской карты и создания платёжного аккаунта. В этом разделе я покажу, как получить доступ к BigQuery и настроить ваш первый проект с помощью песочницы.
Доступ к BigQuery осуществляется через Google Cloud Console. Вам понадобится войти под аккаунтом Google (или создать его). После входа появится приветственный экран:
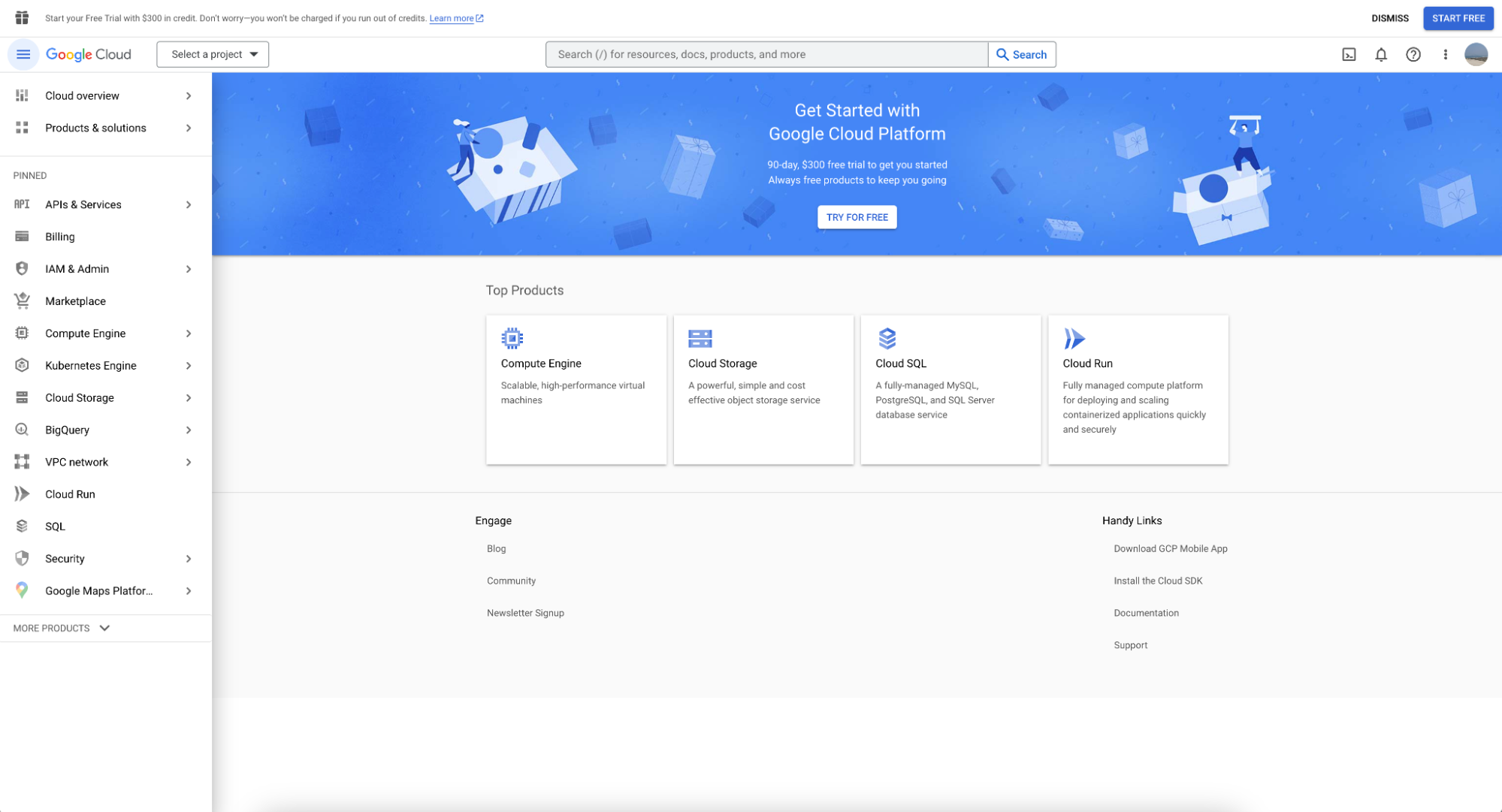
Найти BigQuery можно в левой панели меню. Нажмите — и вы попадёте на экран ниже:

Чтобы использовать песочницу BigQuery, сначала создайте проект, нажав «Select Project».

Затем нажмите «New Project»:

Нужно указать название проекта; в этом руководстве мы используем datacamp-guide-project

На странице BigQuery теперь отображается уведомление о песочнице, подтверждающее, что вы успешно включили BigQuery Sandbox.

Теперь, когда песочница BigQuery включена, вы можете использовать новый проект для загрузки и выполнения запросов к данным, а также для запросов к публичным наборам данных Google.
Прежде чем создавать таблицу, в новом проекте нужно создать набор данных. Набор данных — это контейнер верхнего уровня для организации и управления доступом к набору таблиц и представлений. Чтобы создать набор данных, нажмите значок «Actions» у проекта:

Для целей этого руководства в поле «Dataset ID» укажем «main».

Создать таблицу можно с помощью SQL. BigQuery использует GoogleSQL, совместимый с ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Также можно использовать интерфейс консоли BigQuery:

Примечание: В среде песочницы вставка данных недоступна. Если хотите попробовать вставлять данные, включите бесплатную пробную версию. В следующих разделах мы сосредоточимся на выполнении запросов к публичным наборам данных, доступным в Google Cloud.
Чтобы выполнить запрос к публичному набору данных, выполните шаги ниже:
1. Нажмите «Add» рядом с Explorer.

2. Затем выберите набор данных.

3. Введите в поиск «Google Trends» и выберите Google Trends, затем нажмите кнопку «View dataset».

4. Появится bigquery-public-data с длинным списком наборов данных. Отметьте bigquery-public-data звёздочкой, чтобы он закрепился в проводнике.

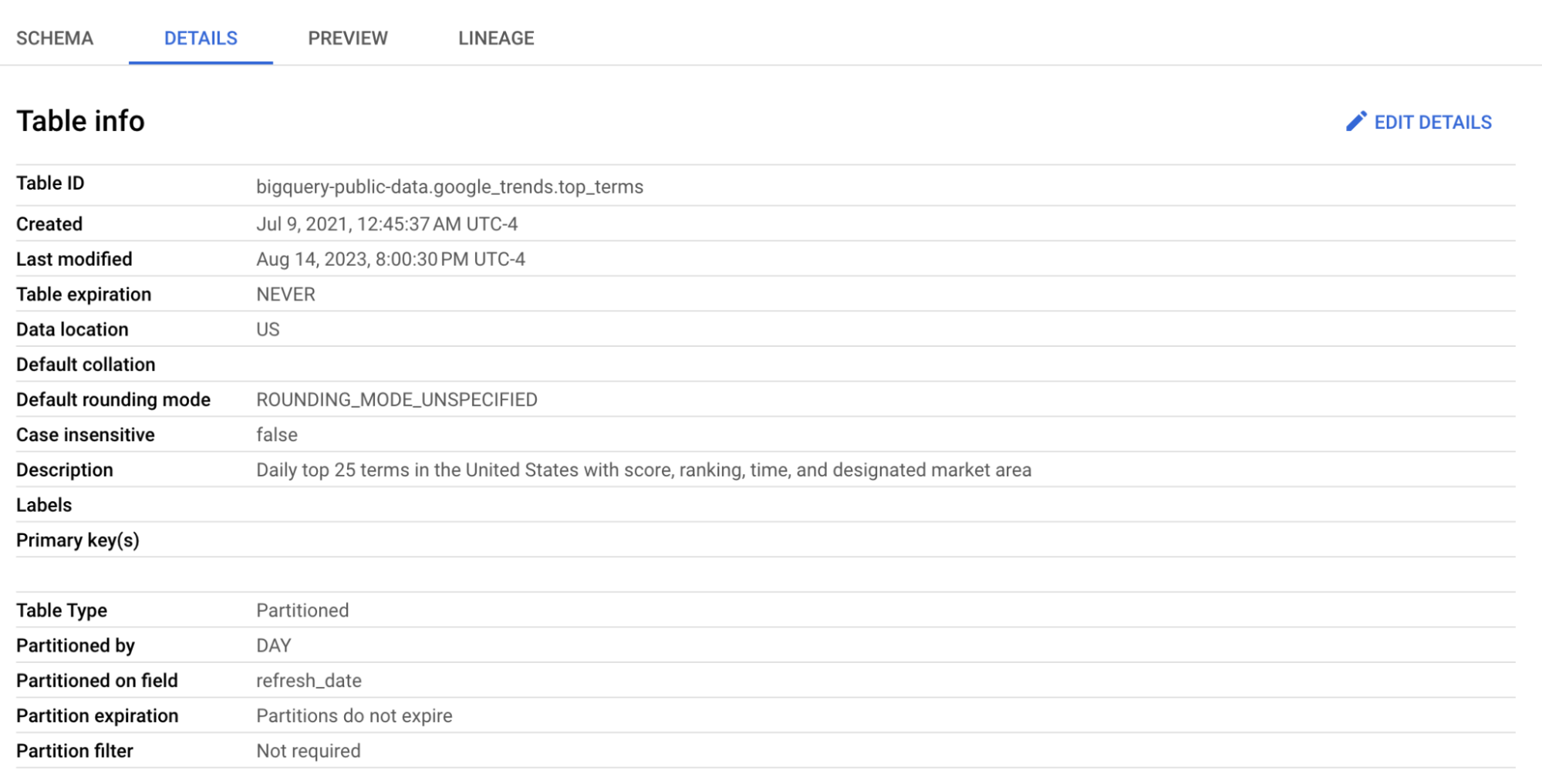
Мы будем использовать таблицу top_terms:

Откройте таблицу top_terms и изучите вкладки Details и Preview, чтобы лучше понять данные top_terms.

Можно выполнить запрос к этому набору данных. Пример ниже выбирает термины, которые занимали первую позицию за последние две недели:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termРезультаты (будут различаться):

Стоимость BigQuery включает две основные составляющие: вычисления (обработка запросов) и хранение.
| Компонент | Бесплатный уровень | Платная стоимость |
|---|---|---|
| Запросы по требованию | 1 ТиБ в месяц | $6.25 за ТиБ |
| Хранение (активное) | 10 ГиБ | $0.02 за ГиБ/мес |
| Хранение (долгосрочное) | 10 ГиБ | $0.01 за ГиБ/мес |
| Потоковые вставки | N/A | $0.05 за 200 МБ |
Для команд с предсказуемыми нагрузками BigQuery также предлагает фиксированную модель оплаты через резервирование ресурсов (BigQuery Editions). Актуальные ставки смотрите на официальной странице с ценами.
BigQuery — один из самых доступных способов начать работу с облачными хранилищами данных. Песочница предоставляет безопасную среду для экспериментов, а 1 ТиБ бесплатных запросов в месяц позволяет изучать публичные наборы данных без затрат. Когда потребуется больше, бесплатная пробная версия Google Cloud предоставляет кредиты на $300.
Если хотите развить полученные здесь навыки, рекомендую курс Introduction to BigQuery на DataCamp — он охватывает оптимизацию запросов и работу с большими наборами данных. Для более широкого взгляда на инженерию данных трек Data Engineer in Python охватывает весь конвейер — от загрузки до хранилища.
Также вы можете сравнить BigQuery с альтернативами в наших материалах BigQuery vs Redshift и BigQuery vs Snowflake, а для подготовки к собеседованиям — в гайде BigQuery interview questions.
Начните путь в инженерии данных уже сегодня!
Track
Course
Course