
Track
Associate Data Engineer in SQL
30 hr
A traditional data warehouse is deployed on-premise, typically requiring high upfront costs, a skilled team to manage it, and proper planning to meet increasing demand due to the rigid nature of traditional data center resource scaling.
A cloud data warehouse, by contrast, is managed and hosted by a cloud services provider. Examples include Google BigQuery, Amazon Redshift, and Snowflake.
Typically, a cloud data warehouse has several advantages over traditional data warehouses:
Example of a row-oriented database:

Example of a column-oriented database:

Row-oriented databases work well for full row lookups, inserting records, and updates. But they struggle with analytical workloads.
For example, if you query three columns from a 50-column table, a row-oriented database still reads all 50 columns for every row. A column-oriented database reads only the three columns you need, which is much faster for analytics like product forecasting or ad-hoc reporting.
Row-oriented databases are typically well suited for online transaction processing (OLTP), and column-oriented databases for online analytical processing (OLAP).
Summary of comparison:
|
Row-oriented database |
Column-oriented database |
||||||
|
Storage |
By Row |
By Column |
|||||
|
Data retrieval |
Complete records |
Relevant columns |
|||||
|
Typical application |
OLTP |
OLAP |
|||||
|
Fast operations |
Insertion, Updates, Lookups |
Querying for reporting purposes |
|||||
|
Load data |
Typically a record at a time |
Typically in a batch |
|||||
|
Popular options |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery separates its compute engine from storage, so each can scale independently. The result: you can query terabytes of data in seconds and petabytes in minutes.
When BigQuery runs a query, the query engine distributes the work in parallel, scanning the relevant tables in storage, merging results, and returning the final data set.

Since BigQuery launched, Google has added several features that extend it beyond a traditional data warehouse:
The BigQuery sandbox lets you try BigQuery without providing a credit card or creating a billing account. In this section, I'll walk through how to access BigQuery and set up your first project using the sandbox.
BigQuery can be accessed through the Google Cloud Console. You will need to log in with a Google account (or create one). Once logged in, a welcome screen should appear:
You can find BigQuery in the left menu bar. Clicking on it will take you to the screen below:

In order to use the BigQuery sandbox, first create a project by clicking on ‘Select Project.’

Followed by clicking on ‘New Project’:

You’ll need to provide a project name; for this guide, we’re using datacamp-guide-project

A sandbox notice is now displayed on the BigQuery page, showing you have successfully enabled the BigQuery sandbox.

With the BigQuery sandbox now enabled, you can use your new project to load data and query as well as query Google public datasets.
Before creating a table, you need to create a dataset in your new project. A dataset is a top-level container used to organize and control access to a set of tables and views. To create a dataset, click on the project’s ‘Actions’ icon:

For the purpose of this guide, we’ll fill in ‘Dataset ID’ with ‘main’.

You can create a table using SQL. BigQuery uses GoogleSQL, which is ANSI compliant.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);You can also use the BigQuery Console interface:

Note: It is not possible to insert data while in a sandbox environment. If you want to try inserting data, you need to enable the free trial. The next sections focus on querying public datasets provided as part of Google Cloud.
To query a public dataset follow the steps below:
1. Click ‘Add’ next to Explorer.

2. Then, choose a dataset.

3. Search for ‘Google Trends’ and choose Google Trends, followed by clicking the ‘View dataset’ button.

4. bigquery-public-data will show up with a long list of datasets. Star bigquery-public-data so that it becomes “sticky” in the explorer

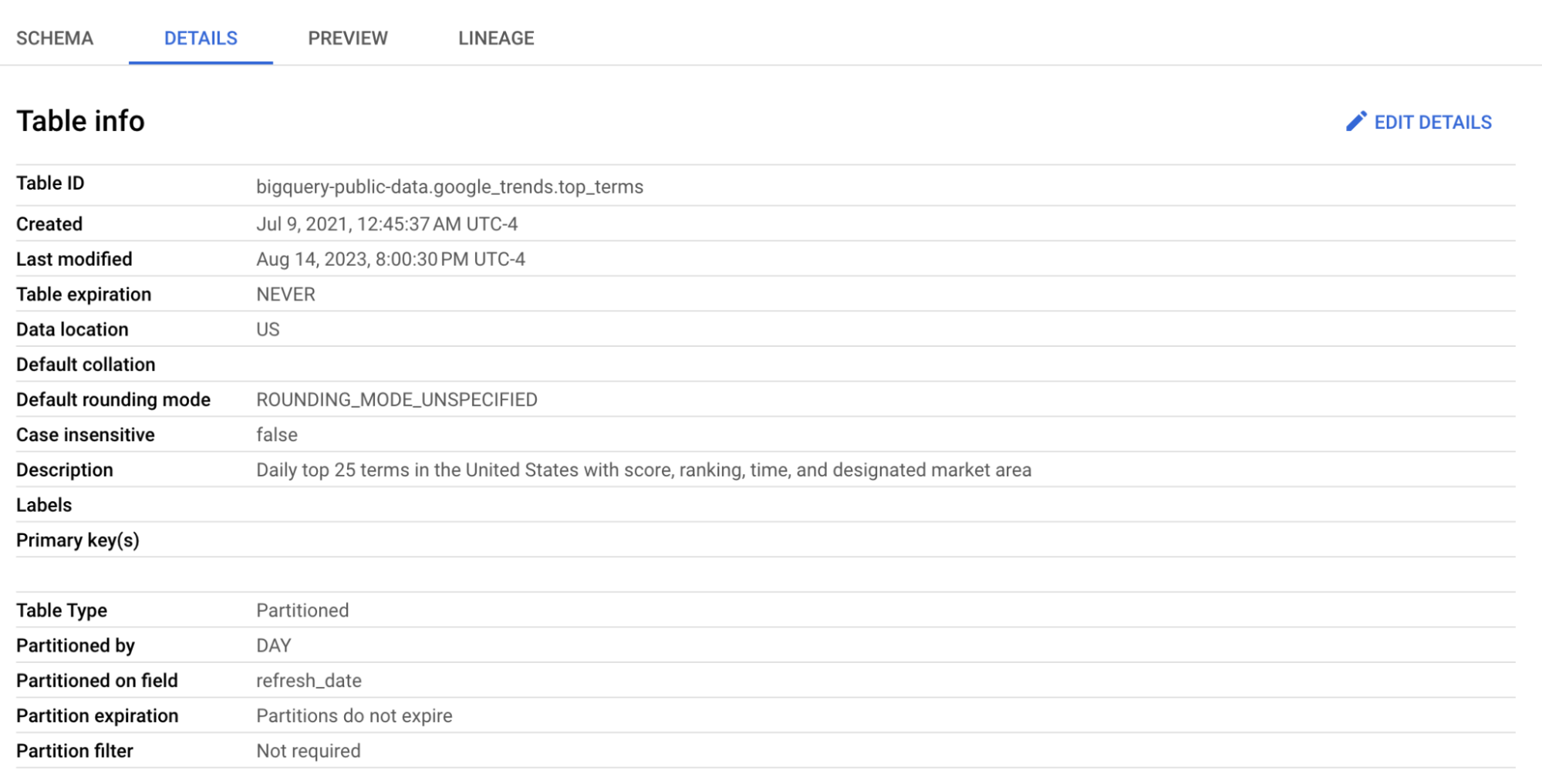
We will use the table top_terms:

Click the top_terms table to open, and inspect the Details and Preview table to learn more about top_terms data.

You can query the dataset, example below to fetch terms that ranked in first position in the last two weeks:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termResults (will vary):

BigQuery pricing has two main components: compute (query processing) and storage.
| Component | Free tier | Paid pricing |
|---|---|---|
| On-demand queries | 1 TiB per month | $6.25 per TiB |
| Storage (active) | 10 GiB | $0.02 per GiB/month |
| Storage (long-term) | 10 GiB | $0.01 per GiB/month |
| Streaming inserts | N/A | $0.05 per 200 MB |
For teams with predictable workloads, BigQuery also offers flat-rate pricing through capacity reservations (BigQuery Editions). Check the official pricing page for current rates.
BigQuery is one of the most accessible entry points into cloud data warehousing. The sandbox gives you a risk-free environment to experiment, and the 1 TiB of free queries per month means you can explore public datasets without spending anything. When you need more, Google Cloud's free trial provides $300 in credits.
If you want to build on what you've learned here, I recommend the Introduction to BigQuery course on DataCamp, which covers query optimization and working with larger datasets. For a broader view of data engineering, the Data Engineer in Python track covers the full pipeline from ingestion to warehousing.
You can also explore how BigQuery compares to alternatives in our BigQuery vs Redshift and BigQuery vs Snowflake comparisons, or get ready for interviews with our BigQuery interview questions guide.
Get Started with Data Engineering Today!
Track
Course
Course
blog
Tim Lu
12 min
Tutorial
Josep Ferrer
Tutorial
Aryan Irani
Tutorial
Alexis Perrier
code-along
Eduardo Oliveira
code-along
Kelsey McNeillie


