
Programa
Engenheiro de dados associado em SQL
30 h
Um data warehouse tradicional é implantado on‑premise, normalmente exigindo altos custos iniciais, uma equipe qualificada para gerenciá-lo e planejamento rigoroso para atender ao aumento de demanda, devido à rigidez no escalonamento de recursos em data centers tradicionais.
Já um data warehouse em nuvem é gerenciado e hospedado por um provedor de serviços de nuvem. Exemplos incluem Google BigQuery, Amazon Redshift e Snowflake.
Normalmente, um data warehouse em nuvem oferece várias vantagens em relação aos tradicionais:
Exemplo de banco orientado a linhas:

Exemplo de banco orientado a colunas:

Bancos orientados a linhas funcionam bem para buscas de registros completos, inserções e atualizações. Mas têm dificuldades com cargas analíticas.
Por exemplo, se você consulta três colunas de uma tabela com 50 colunas, um banco orientado a linhas ainda lê todas as 50 colunas de cada linha. Um banco orientado a colunas lê somente as três colunas necessárias — muito mais rápido para análises como previsão de demanda de produtos ou relatórios ad hoc.
Bancos orientados a linhas costumam ser mais adequados para processamento de transações online (OLTP), enquanto bancos orientados a colunas são ideais para processamento analítico online (OLAP).
Resumo da comparação:
|
Banco orientado a linhas |
Banco orientado a colunas |
||||||
|
Armazenamento |
Por linha |
Por coluna |
|||||
|
Recuperação de dados |
Registros completos |
Colunas relevantes |
|||||
|
Aplicação típica |
OLTP |
OLAP |
|||||
|
Operações rápidas |
Inserção, updates, buscas |
Consultas para fins de relatório |
|||||
|
Carga de dados |
Geralmente um registro por vez |
Geralmente em lote |
|||||
|
Opções populares |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
O BigQuery separa seu mecanismo de computação do armazenamento, permitindo que cada um escale de forma independente. Resultado: você consegue consultar terabytes de dados em segundos e petabytes em minutos.
Quando o BigQuery executa uma consulta, o mecanismo distribui o trabalho em paralelo, varre as tabelas relevantes no armazenamento, consolida os resultados e retorna o conjunto final de dados.

Desde o lançamento, o Google adicionou vários recursos que expandem o BigQuery além de um data warehouse tradicional:
O sandbox do BigQuery permite testar o BigQuery sem informar um cartão de crédito ou criar uma conta de faturamento. Nesta seção, vou mostrar como acessar o BigQuery e configurar seu primeiro projeto usando o sandbox.
O BigQuery pode ser acessado pelo Google Cloud Console. Você precisa fazer login com uma conta Google (ou criar uma). Depois do login, uma tela de boas-vindas deve aparecer:
Você encontra o BigQuery no menu à esquerda. Ao clicar, você verá a tela abaixo:

Para usar o sandbox do BigQuery, primeiro crie um projeto clicando em “Select Project”.

Depois, clique em “New Project”:

Você precisará informar um nome para o projeto; neste guia, estamos usando datacamp-guide-project

Agora, um aviso do sandbox é exibido na página do BigQuery, indicando que você ativou o sandbox com sucesso.

Com o sandbox do BigQuery ativado, você já pode usar seu novo projeto para carregar dados e fazer consultas, além de consultar os conjuntos de dados públicos do Google.
Antes de criar uma tabela, você precisa criar um dataset no seu novo projeto. Um dataset é um contêiner de alto nível usado para organizar e controlar o acesso a um conjunto de tabelas e views. Para criar um dataset, clique no ícone “Actions” do projeto:

Para este guia, vamos preencher o “Dataset ID” com “main”.

Você pode criar uma tabela usando SQL. O BigQuery utiliza o GoogleSQL, que é compatível com ANSI.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Você também pode usar a interface do BigQuery Console:

Observação: não é possível inserir dados no ambiente de sandbox. Se quiser testar inserções, é preciso ativar o período de avaliação gratuito. As próximas seções focam em consultar conjuntos de dados públicos disponibilizados como parte do Google Cloud.
Para consultar um dataset público, siga os passos abaixo:
1. Clique em “Add” ao lado de Explorer.

2. Em seguida, escolha um dataset.

3. Pesquise por “Google Trends” e selecione Google Trends; depois clique no botão “View dataset”.

4. bigquery-public-data aparecerá com uma longa lista de datasets. Marque bigquery-public-data com estrela para que ele fique “fixo” no Explorer

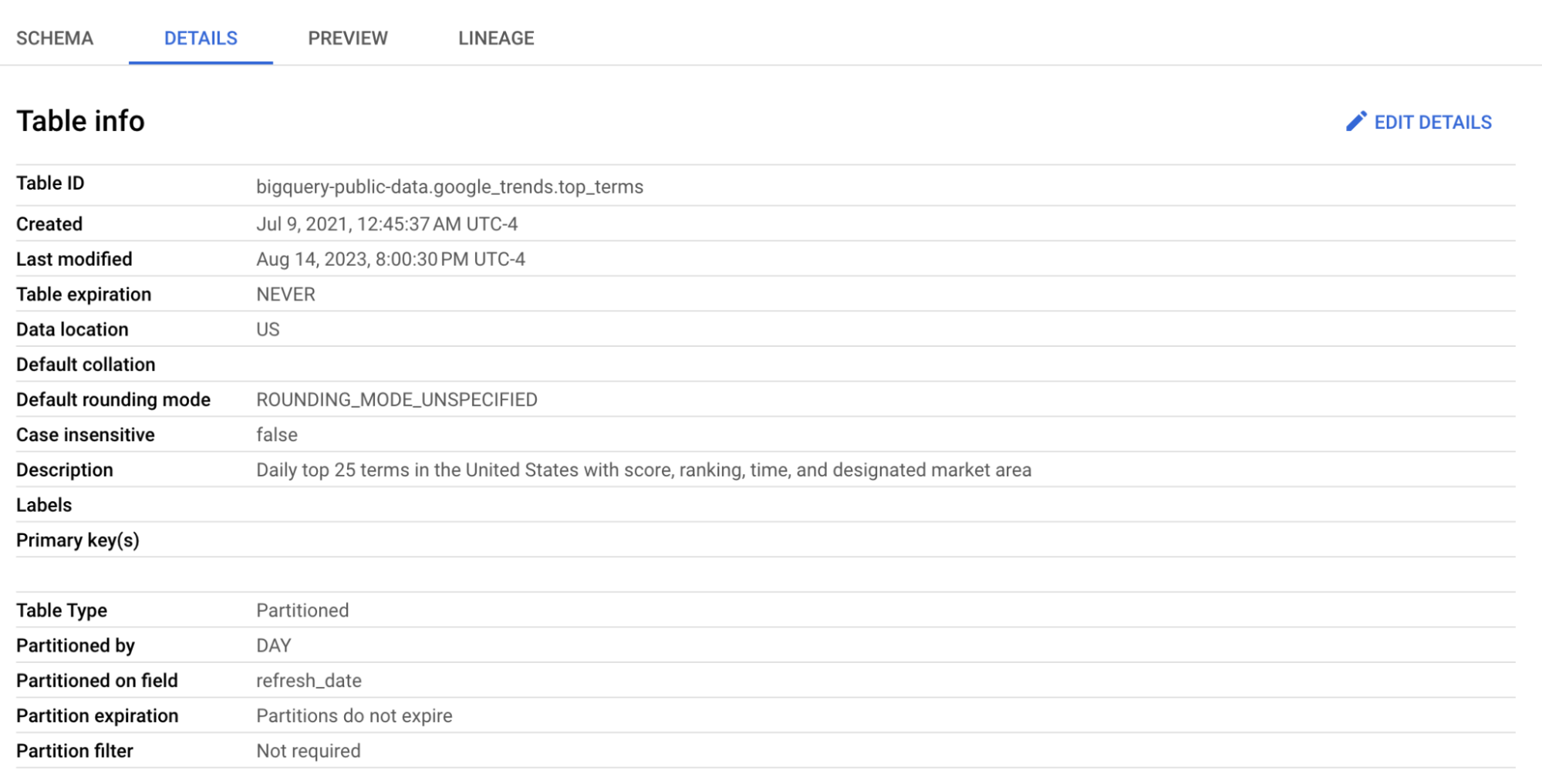
Usaremos a tabela top_terms:

Clique na tabela top_terms para abrir e inspecione as abas Details e Preview para conhecer melhor os dados de top_terms.

Você pode consultar o dataset. Exemplo abaixo para buscar termos que ficaram em primeira posição nas últimas duas semanas:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termResultados (podem variar):

A precificação do BigQuery tem dois componentes principais: computação (processamento de consultas) e armazenamento.
| Componente | Camada gratuita | Preço pago |
|---|---|---|
| Consultas sob demanda | 1 TiB por mês | US$ 6,25 por TiB |
| Armazenamento (ativo) | 10 GiB | US$ 0,02 por GiB/mês |
| Armazenamento (longo prazo) | 10 GiB | US$ 0,01 por GiB/mês |
| Inserções em streaming | N/D | US$ 0,05 por 200 MB |
Para times com cargas previsíveis, o BigQuery também oferece preços em taxa fixa por meio de reservas de capacidade (BigQuery Editions). Consulte a página oficial de preços para valores atualizados.
O BigQuery é um dos pontos de entrada mais acessíveis para data warehousing em nuvem. O sandbox oferece um ambiente sem riscos para experimentar, e o 1 TiB de consultas gratuitas por mês permite explorar datasets públicos sem gastar nada. Quando precisar de mais, o teste gratuito do Google Cloud oferece US$ 300 em créditos.
Se quiser evoluir a partir do que aprendeu aqui, recomendo o curso Introduction to BigQuery na DataCamp, que aborda otimização de consultas e trabalho com datasets maiores. Para uma visão mais ampla de engenharia de dados, a trilha Data Engineer in Python cobre todo o pipeline, da ingestão ao data warehousing.
Você também pode ver como o BigQuery se compara a alternativas em nossas comparações BigQuery vs Redshift e BigQuery vs Snowflake, ou se preparar para entrevistas com nosso guia de perguntas de entrevista sobre BigQuery.
Comece com engenharia de dados hoje mesmo!
Programa
Curso
Curso
blog
Wendy Gittleson
12 min
blog
Wendy Gittleson
15 min
Tutorial
DataCamp Team
Tutorial
Sejal Jaiswal
Tutorial
Javier Canales Luna
Tutorial
Tim Lu
