track
Associate Data Engineer i SQL
30 timmar
Ett traditionellt datalager distribueras on-premise, vilket vanligtvis kräver höga startkostnader, ett kompetent team för att hantera det och noggrann planering för att möta ökande efterfrågan på grund av den rigida naturen hos traditionell resurskalning i datacenter.
Ett molnbaserat datalager, däremot, hanteras och hostas av en molnleverantör. Exempel inkluderar Google BigQuery, Amazon Redshift och Snowflake.
Ett molnbaserat datalager har i regel flera fördelar jämfört med traditionella datalager:
Exempel på en radorienterad databas:

Exempel på en kolumnorienterad databas:

Radorienterade databaser fungerar bra för uppslag av hela rader, insättning av poster och uppdateringar. Men de har det svårare med analytiska arbetslaster.
Om du till exempel frågar tre kolumner från en tabell med 50 kolumner läser en radorienterad databas ändå alla 50 kolumner för varje rad. En kolumnorienterad databas läser bara de tre kolumner du behöver, vilket är mycket snabbare för analyser som produktprognoser eller ad hoc-rapportering.
Radorienterade databaser lämpar sig i regel väl för online transaction processing (OLTP), och kolumnorienterade databaser för online analytical processing (OLAP).
Sammanfattning av jämförelsen:
|
Radorienterad databas |
Kolumnorienterad databas |
||||||
|
Lagring |
Per rad |
Per kolumn |
|||||
|
Datahämtning |
Fullständiga poster |
Relevanta kolumner |
|||||
|
Typisk användning |
OLTP |
OLAP |
|||||
|
Snabba operationer |
Insättning, uppdateringar, uppslag |
Frågor för rapporteringsändamål |
|||||
|
Lasta data |
Vanligtvis en post i taget |
Vanligtvis i batch |
|||||
|
Populära alternativ |
Postgres, MySQL, Oracle, Microsoft SQL Server |
Snowflake, Google BigQuery, Amazon Redshift |
|||||
BigQuery separerar sin beräkningsmotor från lagringen, så att varje del kan skalas oberoende. Resultatet: du kan fråga terabyte av data på sekunder och petabyte på minuter.
När BigQuery kör en fråga distribuerar frågemotorn arbetet parallellt, skannar relevanta tabeller i lagringen, sammanfogar resultaten och returnerar den slutliga datamängden.

Sedan BigQuery lanserades har Google lagt till flera funktioner som tar det bortom ett traditionellt datalager:
BigQuery-sandboxen låter dig prova BigQuery utan att ange kreditkort eller skapa ett faktureringskonto. I det här avsnittet går jag igenom hur du får åtkomst till BigQuery och sätter upp ditt första projekt med sandboxen.
Du kommer åt BigQuery via Google Cloud Console. Du behöver logga in med ett Google-konto (eller skapa ett). När du loggat in bör en välkomstskärm visas:
Du hittar BigQuery i den vänstra menyraden. Klicka på det för att komma till följande vy:

För att använda BigQuery-sandboxen skapar du först ett projekt genom att klicka på ”Select Project”.

Klicka sedan på ”New Project”:

Du behöver ange ett projektnamn; i den här guiden använder vi datacamp-guide-project

Ett meddelande om sandbox visas nu på BigQuery-sidan, vilket visar att du har aktiverat BigQuery-sandboxen.

Nu när BigQuery-sandboxen är aktiverad kan du använda ditt nya projekt för att ladda data och köra frågor samt fråga Googles publika dataset.
Innan du skapar en tabell behöver du skapa ett dataset i ditt nya projekt. Ett dataset är en behållare på högsta nivån som används för att organisera och styra åtkomst till en uppsättning tabeller och vyer. För att skapa ett dataset, klicka på projektets ”Actions”-ikon:

I den här guiden fyller vi i ”Dataset ID” med ”main”.

Du kan skapa en tabell med SQL. BigQuery använder GoogleSQL, som följer ANSI-standarden.
CREATE TABLE datacamp-guide-project.main.users (
id INT64 NOT NULL,
first_name STRING NOT NULL,
middle_name STRING,
last_name STRING NOT NULL,
active_account BOOL NOT NULL
);Du kan också använda gränssnittet i BigQuery Console:

Observera: Det går inte att infoga data i en sandbox-miljö. Om du vill prova att infoga data behöver du aktivera den kostnadsfria provperioden. Nästa avsnitt fokuserar på att fråga publika dataset som ingår i Google Cloud.
Följ stegen nedan för att fråga ett publikt dataset:
1. Klicka på ”Add” bredvid Explorer.

2. Välj sedan ett dataset.

3. Sök efter ”Google Trends” och välj Google Trends, följt av att klicka på knappen ”View dataset”.

4. bigquery-public-data visas med en lång lista över dataset. Stjärnmarkera bigquery-public-data så att det blir ”klistrigt” i explorern

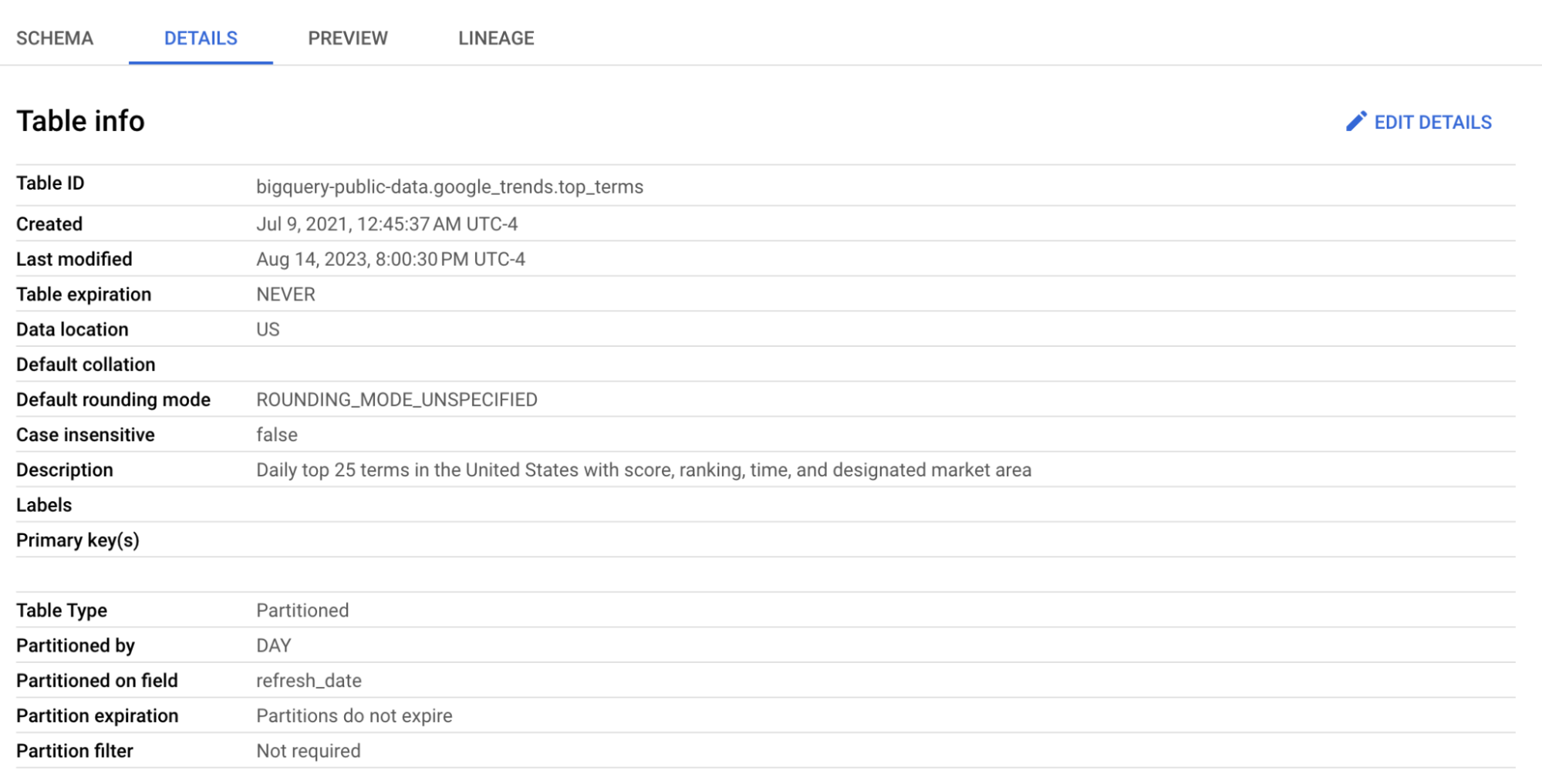
Vi använder tabellen top_terms:

Klicka på tabellen top_terms för att öppna den och granska flikarna Details och Preview för att lära dig mer om datan i top_terms.

Du kan fråga datasetet, exempel nedan för att hämta termer som rankade på första plats under de senaste två veckorna:
SELECT
term
FROM
bigquery-public-data.google_trends.top_terms
WHERE
rank = 1
AND refresh_date >= DATE_SUB(CURRENT_DATE(), INTERVAL 2 WEEK)
GROUP BY
termResultat (varierar):

BigQuerys prissättning har två huvudkomponenter: beräkning (frågebearbetning) och lagring.
| Komponent | Kostnadsfritt nivå | Betald prissättning |
|---|---|---|
| On-demand-frågor | 1 TiB per månad | $6.25 per TiB |
| Lagring (aktiv) | 10 GiB | $0.02 per GiB/månad |
| Lagring (långsiktig) | 10 GiB | $0.01 per GiB/månad |
| Strömmande insättningar | Ej tillämpligt | $0.05 per 200 MB |
För team med förutsägbara arbetslaster erbjuder BigQuery även flat-rate-prissättning via kapacitetsreservationer (BigQuery Editions). Se den officiella prissidan för aktuella priser.
BigQuery är en av de mest lättillgängliga ingångarna till datalagring i molnet. Sandboxen ger dig en riskfri miljö att experimentera i, och 1 TiB kostnadsfria frågor per månad innebär att du kan utforska publika dataset utan att spendera något. När du behöver mer ger Google Clouds kostnadsfria provperiod 300 dollar i krediter.
Om du vill bygga vidare på det du lärt dig här rekommenderar jag kursen Introduction to BigQuery på DataCamp, som täcker frågeoptimering och arbete med större dataset. För en bredare bild av data engineering täcker spåret Data Engineer in Python hela kedjan från insamling till datalagring.
Du kan också utforska hur BigQuery står sig mot alternativ i våra jämförelser BigQuery vs Redshift och BigQuery vs Snowflake, eller förbereda dig för intervjuer med vår guide till intervjufrågor om BigQuery.
Kom igång med data engineering idag!
track
course
course